【ICDE2020】SeqFM: 基于多视图自注意力的动态序列感知CTR预测模型
本文由来自昆士兰大学,格里菲斯大学和国立交通大学联合发表在ICDE2020上的一篇文章,题目为Sequence-Aware Factorization Machines for Temporal Predictive Analytics
主要提出了一种同时结合了特征交互中的顺序依赖和保持DNN的非线性表达能力的FM based模型SeqFM,在建模特征交互和动态行为序列时使用了多视图的自注意力机制。
下面将从论文背景,模型结构,实验对比以及个人总结几个方面为大家介绍这篇文章~
背景
-
背景
在广告和推荐场景中,通常存在着大量的稀疏类别型特征变量。基于因子分解机的方法(DeepFM,DCN,xDeepFM等)能够有效的捕获稀疏类别变量之间的高阶特征交互,减轻了算法工程师手工构造交叉特征的压力。
然而,除了类别特征和稠密值特征外,还有大量动态的行为序列类型的特征。现有的基于FM的模型在处理这样的序列时,大多忽略了行为之间的顺序,即将其当作一个行为集合进行建模处理,因此无法有效捕获动态行为序列特征的序列依赖性和内在的模式。
因此提出Sequence-Aware FM模型,通过建模数据中的序列依赖关系来对蕴含时序特征的数据进行建模分析。 -
举例说明SeqFM与传统的FM-based方法的区别
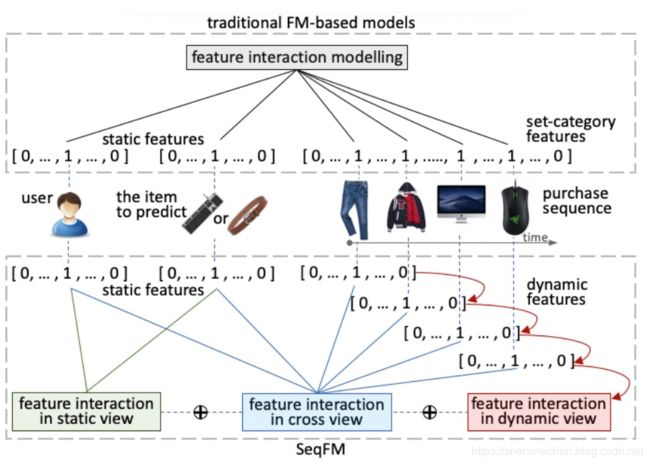
本文使用了一个简单的例子来说明SeqFM相比于传统的FM based方法的改进,假设用户购买过 [ 裤 子 , 外 套 , 显 示 器 , 鼠 标 ] [裤子,外套,显示器,鼠标] [裤子,外套,显示器,鼠标]。由于目前大部分FM-based模型大多假设了序列数据是无序的,即这些属于动态特征的序列中的每一个item都被同等的对待了,因此模型很难区分当用户接下来会购买腰带还是键盘,因为序列集合中都有和这两个相似的商品,动态特征的序列属性难以被捕获。
-
SeqFM
如上图所示,SeqFM使用了一个多视图学习机制。
由于静态特征和动态特征中包含了不同的信息,使用三个不同的视图来进行特征交互的建模。由于使用CNN或者RNN来进行序列建模计算时间和存储需求都较高,SeqFM在每个视图内部采用了self attention机制。
对于动态视图和交叉视图,使用mask self attention单元分别保留动态特征序列的时间方向属性并屏蔽不相关的特征交互。
在通过multi view self attention机制编码特征之间的高阶交互后,使用一个参数共享的残差连接神经网络从特征交互中提取更多的隐含信息,最后输出模型得分。
模型结构
这里特征划分为两大部分,静态特征 G ∘ G^{\circ} G∘(如用户画像特征,用户性别)和动态特征 G ▹ G^{\triangleright} G▹(如用户历史上有过行为的商品)。
这里需要注意的是动态特征 G ▹ G^{\triangleright} G▹是按时间顺序构造的。在特征矩阵 G ▹ G^{\triangleright} G▹中,若行号 i < j i
使用 n ▹ n^{\triangleright} n▹表示动态特征序列的最大长度,如果实际长度大于 n ▹ n^{\triangleright} n▹,那么取最近的 n ▹ n^{\triangleright} n▹个特征。如果少于 n ▹ n^{\triangleright} n▹,那么在矩阵 G ▹ G^{\triangleright} G▹中从上到下(从行为发生时间远到近)填充零向量。
SeqFM的形式化表示为
y ^ = w 0 + [ G ∘ w ∘ ; G ▹ w ▹ ] 1 + f ( G ∘ , G ▹ ) \hat y=w_0+[G^{\circ} w^{\circ};G^{\triangleright} w^{\triangleright}]\mathbf{1}+f(G^{\circ},G^{\triangleright} ) y^=w0+[G∘w∘;G▹w▹]1+f(G∘,G▹)
其中
w 0 w_0 w0是全局偏置项
中间 [ G ∘ w ∘ ; G ▹ w ▹ ] 1 [G^{\circ} w^{\circ};G^{\triangleright} w^{\triangleright}]\mathbf{1} [G∘w∘;G▹w▹]1为对应的一次项线性特征
f ( G ∘ , G ▹ ) f(G^{\circ},G^{\triangleright} ) f(G∘,G▹)为本文提出的多视图自注意力因子分解机制。
下面详细介绍SeqFM模型的细节。
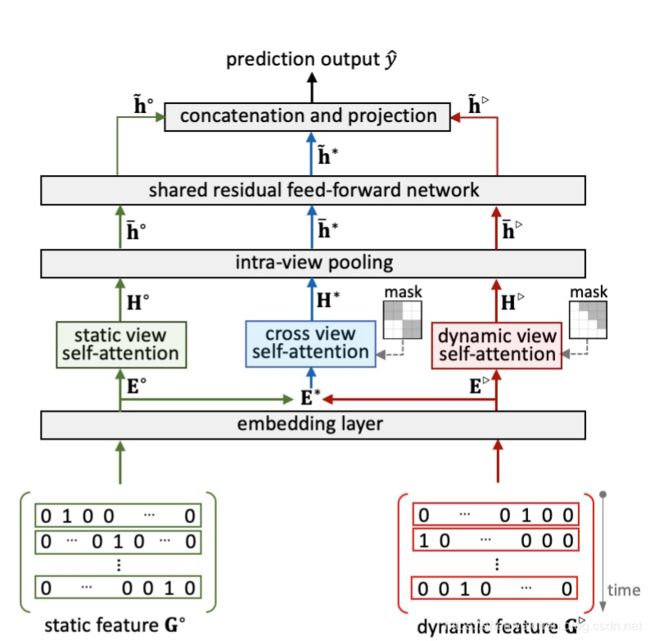
Embedding Layer
将特征划分为静态特征 G ∘ G^{\circ} G∘和动态特征 G ▹ G^{\triangleright} G▹,分别经过embedding后得到 E ∘ E^{\circ} E∘和 E ▹ E^{\triangleright} E▹。
Static View With Self-Attention
H ∘ = s o f t m a x ( Q ∘ K ∘ T d ) V ∘ H^{\circ}=softmax(\frac{Q^{\circ}{K^{\circ}}^T}{\sqrt{d}})V^{\circ} H∘=softmax(dQ∘K∘T)V∘
其中 Q ∘ = E ∘ W Q ∘ Q^{\circ}=E^{\circ}W^{\circ}_Q Q∘=E∘WQ∘, K ∘ = E ∘ W K ∘ K^{\circ}=E^{\circ}W^{\circ}_K K∘=E∘WK∘, V ∘ = E ∘ W V ∘ V^{\circ}=E^{\circ}W^{\circ}_V V∘=E∘WV∘,分别是由输入的embedding矩阵 E ∘ E^{\circ} E∘经过线性变换得到。
这里关于self attention原理和实现有疑问的同学可以参考我之前写的另一篇文章
AutoInt:使用Multi-head Self-Attention进行自动特征学习的CTR模型
里面有详尽的说明~
Dynamic View with Self-Attention
在Dynamic View中,由于 n ▹ n^{\triangleright} n▹个动态特征中天然具有序列依赖关系,第 i i i个动态特征( i ≤ n ▹ i\leq n^{\triangleright} i≤n▹)只会和处于位置 j ( j ≤ i ) j(j\leq i) j(j≤i)的前序特征发生交互。
也就是说特征交互在dynamic视图中是具有方向性的,只存在前向特征交互。
为了实现这样的功能,采用了masked self attention 机制
H ▹ = s o f t m a x ( Q ▹ K ▹ T d + M ▹ ) V ∘ H^{\triangleright}=softmax(\frac{Q^{\triangleright}{K^{\triangleright}}^T}{\sqrt{d}}+M^{\triangleright})V^{\circ} H▹=softmax(dQ▹K▹T+M▹)V∘
其中 M ▹ ∈ { − ∞ , 0 } n ▹ × n ▹ M^{\triangleright}\in \left\{-\infty,0 \right\}^{n^{\triangleright}\times n^{\triangleright}} M▹∈{−∞,0}n▹×n▹是一个常量矩阵,其作用是只允许动态特征 e i ▹ e^{\triangleright}_i ei▹和 e j ▹ e^{\triangleright}_j ej▹的交互发生在 j ≤ i j\leq i j≤i的时候。
对于矩阵 M ▹ M^{\triangleright} M▹中的元素,当且仅当 i ≥ j i\geq j i≥j的时候 m i j ▹ m^{\triangleright}_{ij} mij▹取0,其余均取 − ∞ -\infty −∞。
通过添加注意力mask矩阵 M ▹ M^{\triangleright} M▹,对于第 i i i个特征,它与第 i + 1 i+1 i+1个特征开始的后面的特征交互分数为 − ∞ -\infty −∞,第 i − 1 i-1 i−1及其前面的特征交互分数保持不变。
因此经过softmax层后,能够确保第 i i i个特征只和相对于它自身的历史特征 j ≤ i j \leq i j≤i存在非0的交互得分。
Cross View with Self-Attention
H ∗ = s o f t m a x ( Q ∗ K ∗ T d + M ∗ ) V ∗ H^{*}=softmax(\frac{Q^{*}{K^{*}}^T}{\sqrt{d}}+M^{*})V^{*} H∗=softmax(dQ∗K∗T+M∗)V∗
这里的 E ∗ ∈ R n ∘ + n ▹ E^* \in R^{n^{ \circ}+n^{ \triangleright}} E∗∈Rn∘+n▹是由 E ∘ E^{ \circ} E∘和 E ▹ E^{ \triangleright} E▹垂直拼接而成的,与Dynamic View不同的是,这里的attention mask矩阵的构造是这样的
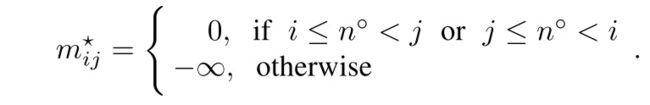
cross view self-attention mask屏蔽了相同类别特征内部的特征交互,只允许跨类别的特征交互(静态特征和动态特征之间)。
Intra-View Pooling Operation
在经过三个视图得到特征交互的表示后,将这些表达向量输入到intra-view pooling layer中,这一层将所有的交互向量压缩成一个向量
h ˉ v i e w = 1 n v i e w ∑ i = 1 n v i e w h i v i e w \bar h^{view}=\frac{1}{n^{view}}\sum_{i=1}^{n^{view}}h^{view}_i hˉview=nview1∑i=1nviewhiview
其中 n v i e w n^{view} nview表示每个视图内部的特征组个数, h i v i e w h^{view}_i hiview为视图内第 i i i个特征向量, h ˉ v i e w \bar h^{view} hˉview是经过池化操作后得到的压缩表示向量。
Shared Residual Feed-Forward Network Work
这里使用一个共享参数的残差全连接神经网络,还使用了Layer Normalization和Dropout等训练技巧。
- 残差连接可以将低层的特征传递高高层。
- Layer Normalization归一化可以让网络的训练过程更加稳定以及加速训练。
- Dropout起到了一定的正则化和集成学习的作用
View-Wise Aggregation
在输出得到最终的logit之前,通过水平拼接三个视图产生的隐向量得到最终的聚合向量 h a g g = [ h ~ ∘ ; h ▹ ; h ∗ ] h^{agg}=[\widetilde h^{\circ};h^{\triangleright};h^{*}] hagg=[h ∘;h▹;h∗]
这里得到的 h a g g ∈ R 1 × 3 d h^{agg}\in R^{1\times 3d} hagg∈R1×3d,是一个一维的长向量。
Output Layer
通过一个向量内积操作得到最终的得分
f ( G ∘ , G ▹ ) = < p , h a g g > f(G^{\circ},G^{\triangleright})=
实验对比
离线实验
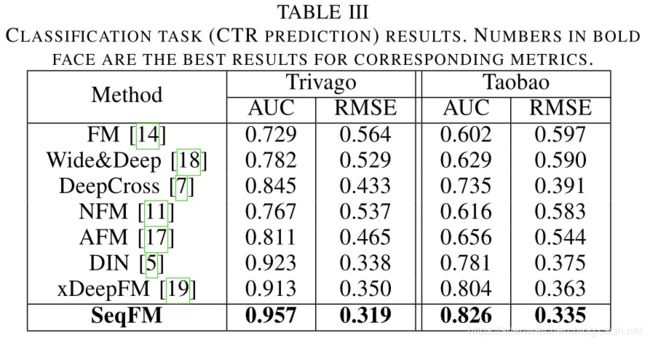
作者在不同的任务和不同的数据集上均进行了大量实验,验证了本文提出的SeqFM的有效性,也验证了本文提出的SeqFM在处理动态序列特征时相比于传统的基于FM的方法简单的将所有动态特征作为普通无序集合特征处理对于时序预测分析更有帮助。
实验选取的baseline方法对比目前较为主流的方法,如Wide&Deep,NFM,xDeepFM及DIN等,在分类任务中选取了recsys2019挑战赛和淘宝的公开数据集,具有一定代表性。
-
分类任务
-
排序任务
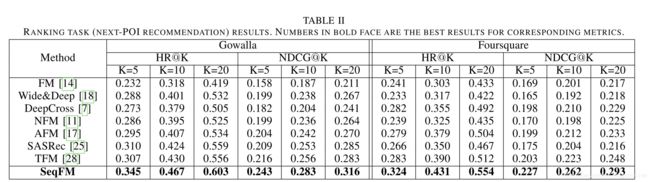
-
回归任务
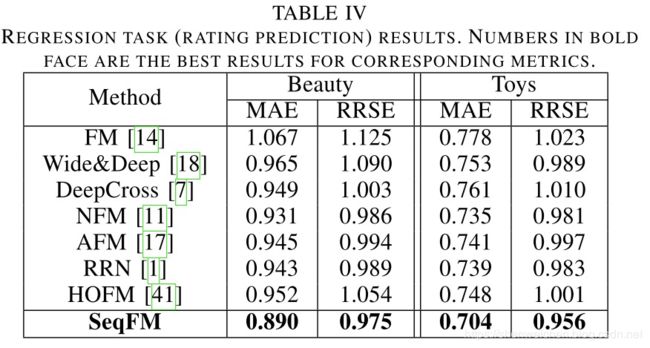
关键组件的重要性
这里SV,DV,CV分别代表本文中提出的三种不同的视图,RC代表残差连接,LN代表Layer Normalization。
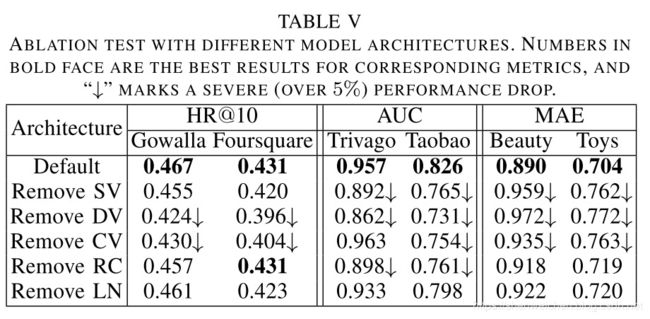
这里 ↓ \downarrow ↓标记里严重的(相对5%)指标相对下降。
-
去掉Static View下跌很容易理解,相当于丢失了很多基础的特征组合。
-
去掉Dynamic View后在分类任务中有非常严重的指标下跌Trivago(10%)和Taobao(12%)。作者给出的解释是这些数据集中包含大量的点击行为日志,这些动态特征序列携带着每个用户的长期偏好信息。
-
去掉 Cross View后的下跌说明了 Cross View中静态特征和动态特征之间的自注意力机制对于模型的最终表现是有贡献的。
-
去掉Residual Connections说明了残差连接确实有助于将低层的信息继续传递给高层并且得到有效的保留。
-
去掉Layer Normalization说明特征的归一化会带来更好的结果。
个人总结
- 本文提出的SeqFM是第一个同时结合了特征交互中的顺序依赖和保持DNN的非线性表达能力的FM based模型,之前的工作大多侧重于建模特征的高阶交互或捕捉动态行为序列中蕴含的信息。
- SeqFM中的Static View应该可以替换成其他特征交互组件,如FM,CrossNet及CIN等,具有一定扩展性。
- 相比于传统的直接将序列特征拼接静态特征输入全连接网络,SeqFM分别在动态序列特征内部和静态特征与动态特征之间进行了特征交互,保留了更多的信息。
- 建模动态特征使用mask self-attention,相比于rnn basd方法提升了计算效率也避免了可能存在的长期依赖问题。不过没有将SeqFM和一些rnn basd方法进行对比。
- 本文不是第一个使用self attention对序列建模的方法,没有将SeqFM和使用self attention的其他序列建模方法进行对比实验。
- Shared FFN在减少模型参数的同时不知道相对于非共享参数对模型效果的影响如何,这里如果有进行过对比就更好了。
参考资料
- Sequence-Aware Factorization Machines for Temporal Predictive Analytics
作者在论文里给出了代码链接,不过访问好像问题,大家可以先关注下deepctr的代码仓库,之后我会更新在这里https://github.com/shenweichen/deepctr
想要了解更多关于推荐系统,ctr预测算法的同学,欢迎大家关注我的公众号 浅梦的学习笔记,关注后回复“加群”一起参与讨论交流!
. . . . . . . 