PS:本文已收录到1.1K Star数开源学习指南——《大厂面试指北》,如果想要了解更多大厂面试相关的内容及获取《大厂面试指北》离线PDF版,请扫描下方二维码码关注公众号“大厂面试”,谢谢大家了!项目地址:https://github.com/NotFound9/interviewGuide
《大厂面试指北》项目截图:
获取《大厂面试指北》离线PDF版,请扫描下方二维码关注公众号“大厂面试”

面试题:高并发场景下,如何保证缓存与数据库一致性?
问题分析
我们日常开发中,对于缓存用的最多的场景就像下图一样,可能仅仅是对数据进行缓存,减轻数据库压力,缩短接口响应时间。

这种方案在不需要考虑高并发得去写缓存,高并发得读写缓存时,是不会有问题,但是如果是在高并发场景下,要保证缓存和数据库的一致性,至少需要解决以下问题:
高并发写时的数据不一致问题
高并发读写时,请求执行各步骤的顺序是不可控的。假设此时有一个请求A,B都在在执行写流程,请求A是需要将某个数据改成1,请求B是需要将某个数据改为2,执行操作如下时就会导致数据不一致的问题:
1.请求A执行操作1.1删除缓存。
2.请求A执行操作1.2更新数据库,将值改为1。
3.请求B执行操作1.1删除缓存。
4.请求B执行操作1.2更新数据库,将值改为2
5.假设说请求B所在服务器网络延迟比较低,请求B先更新缓存,此时缓存中的key对应的value是2。
6.请求A更新缓存,将缓存中B更新的数据进行覆盖,将key对应的值改为1。
此时数据库中是B修改后的数据,值为2,而缓存中的数据是1,这样在缓存过期钱,用户读到的都是脏数据,与数据库不一致。
高并发读写时的数据不一致的问题
高并发读写时,请求执行各步骤的顺序是不可控的。假设此时有一个请求A在执行写流程,将原值由1改成2,请求B执行读流程,执行操作如下时就会导致数据不一致的问题:
1.写请求A执行1.1操作删除缓存key,value是原值1。
2.读请求B执行2.1操作发现缓存中没有数据,就去执行2.2操作读数据库,读到旧数据,值为1。
3.写请求A执行1.2操作更新数据库,将数据由1改为2。
4.写请求A执行1.3操作更新缓存,此时缓存中的数据key对应的value是2。
5.读请求B执行2.3操作更新缓存,将之前读到的旧数据1设置到缓存中,此时缓存中的数据key对应的value是1。
所以如果说读请求B所在服务器网络延迟比较高,去执行2.3操作比写请求A晚,就会导致写请求A更新完缓存后,读请求B使用之前读到的旧数据去更新缓存,此时缓存中数据就与数据库中的不一致。
解决方案
保证数据一致性,网上有很多种方案,例如:
1.先删除缓存,再更新数据库。
2.先更新数据库,再删除缓存。
3.先删除缓存,再更新数据库,然后异步延迟一段时间再去删一次缓存。
但是这些方案都是存在各种各样的问题,这里篇幅有限,只给出目前相对正确的三套方案,目前的这些方案也有自己的局限性。
方案1.写请求串行化
写请求
1.写请求更新之前先获取分布式锁,获得之后才能去数据库更新这个数据,获取不到就进行等待,超时后就返回更新失败。
2.更新完之后去刷新缓存,如果刷新失败,放到内存队列中进行重试(重试时取数据库最新数据更新缓存)。
读请求
读请求发现缓存中没有数据时,直接去读取数据库,读完更新缓存。
总结
这种技术方案通过对写请求的实现串行化来保证数据一致性,但是会导致吞吐量变低。比较适合银行相关的业务,因为对于银行项目来说,保证数据一致性比可用性更加重要,就像是去存款机存钱,取钱时,为了保证账户安全,都是会让用户执行操作后,等待一段时间才能获得反馈,这段时间其实取款机是不可用的。
方案2.先更新数据库,异步删除缓存,删除失败后重试
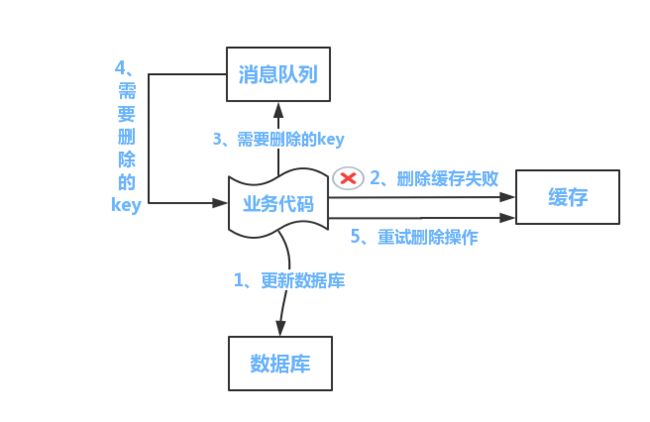
1.先更新数据库
2.异步删除缓存(如果数据库是读写分离的,那么删除缓存时需要延迟删除,否则可能会在删除缓存时,从库还没有收到更新后的数据,其他读请求就去从库读到旧数据然后设置到缓存中。)
3.删除缓存失败时,将删除的key放到内存队列或者是消息队列中进行异步重试
发散思考
在更新完数据库后,我们为什么不直接更新,而是采用删除缓存呢?
这是因为直接更新缓存的话,在高并发场景下,有多个更新请求时,难以保证后更新数据库的请求会后更新缓存,也就是上面的高并发写问题。如果采用删除缓存,可以让下次读时读取数据库,更新缓存,保证一致性。
方案3.业务项目更新数据库,其他项目订阅binlog更新
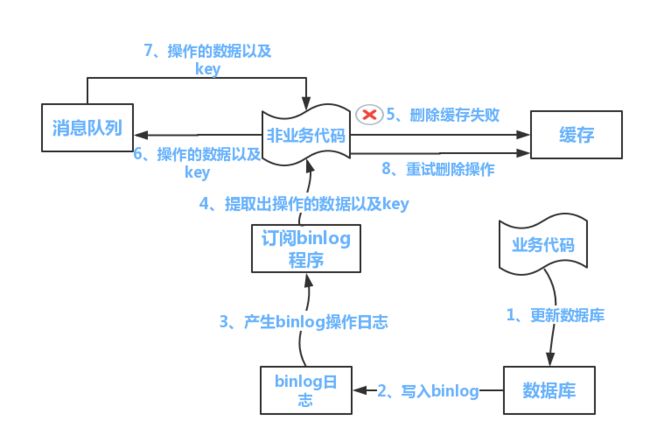
1.业务项目直接更新数据库。
2.cannal项目会读取数据库的binlog,然后解析后发消息到kafka。
3.然后缓存更新项目订阅topic,从kafka接收到更新数据库操作的消息后,更新缓存,更新缓存失败时,新建异步线程去重试或者将操作发到消息队列,后续再进行处理。
总结:
但是这种方案在更新数据库后,缓存中还是旧值,必须等缓存更新项目消费消息后,更新缓存,缓存中才是最新值。所以更新操作完成与更新生效之间会有一定的延迟。
最后
大家有了解其他的技术方案,欢迎进群一起讨论!
评论里面有朋友问延时双删策略是什么?
这里解释一下:延时双删策略就是先删除缓存,再更新数据库,再异步过一小段时间后删除缓存(时间取决于MySQL主从同步的时间)。
是因为MySQL如果是读写分离时(写请求写主库,读请求读从库),我们更新主库后,需要一段时间,从库才会收到更新。
如果是写请求更新主库后,第二次立即删除缓存,MySQL从库还没有收到更新,还是旧数据,那么读请求直接从库读到旧数据,设置到缓存的数据就是旧数据,就会数据不一致,所以这也是延时双删策略提出的初衷。

参考链接:
https://www.cnblogs.com/-wenli/p/11474164.html
https://www.cnblogs.com/rjzheng/p/9041659.html