webrtc-自定义视频流-实现篇(基于release-54)
我所使用的webrtc是release-54版本,后续我也看过release-56版本的代码,发现有许多的代码差别很大,所以如果版本不同很大可能无法直接使用代码,请注意。我所开发的webrtc是基于centos7进行开发的,所以如果我没有特意标注的情况下都指的是linux下的webrtc,看官请知悉。
- 总记
- 步骤
- 1.整体介绍
- 2.EncodedImage和CodecSpecificInfo
- 3.RTPFragmentationHeader
- 4.去除原生捕获
- 结语
总记
根据上一篇所说,我所使用的方法就是“码流伪装法”(自称)。本质是通过在码流打包发送的位置伪装成编码器发送过来的视频流,借助后续的rtp_rtcp模块(负责打包发送RTP的模块)将视频发送出去。我们的主角是一个叫做VideoSendStream的类(webrtc\video\video_send_stream.cc),Webrtc里面有很多名字很接近的类你可能会晕乎乎的。这个类负责的工作就是接收编码器发送过来的数据,在将数据推送给rtp_rtcp模块。
步骤
1.整体介绍
类方法:
EncodedImageCallback::Result VideoSendStream::OnEncodedImage(
const EncodedImage& encoded_image,
const CodecSpecificInfo* codec_specific_info,
const RTPFragmentationHeader* fragmentation)就是原本webrtc的编码器在帧编码完成后的回调接口。这个方法一共需要三个参数:
1.encoded_image
视频的各种数据,包括数据buffer,数据大小,视频高宽和时间戳等等。
2.codec_specific_info
视频数据类型,我用的是webrtc::kVideoCodecH264,还有比如kVideoCodecVP8等类型
3.fragmentation
视频数据分片头信息,用于RTP的包内部多个帧的提取。(如果我没记错的话,vp8这个参数是空的。目前我没有验证手段。)
阅读一下这个函数的代码,就会发现,他的核心其实是这句:
EncodedImageCallback::Result result = payload_router_.OnEncodedImage(
encoded_image, codec_specific_info, fragmentation);这个 payload_router_ 是一个处理编码器返回数据的一个封装类。他在整理获得的数据之后就会调用RtpRtcp模块进行打包发送RTP包。
所以我们只要能够将我们的视频数据封装成上面三个参数的形式,再直接调用这个 payload_router_.OnEncodedImage 方法,就可以伪装成编码器返回的视频数据发送出去了。
2.EncodedImage和CodecSpecificInfo
EncodedImage的成员比较通俗易懂。CodecSpecificInfo也就是简单的一个参数,我们就放在一起说。
下图中的m_image就是一个EncodedImage,一些需要处理的成员主要如下所示:
m_image_._encodedWidth = width;
m_image_._encodedHeight = height;
m_image_._size = CalcBufferSize(kI420, m_image_._encodedWidth, m_image_._encodedHeight);
m_image_._buffer = buffer;//数据区指针
m_image_._completeFrame = true;
m_image_._length = buffer_length;//数据长度
m_image_._timeStamp = time_stamp;//时间戳
//m_image_.capture_time_ms_ = time_stamp;//视频捕获时间,并没有什么用
m_codec_specific_info_.codecType = webrtc::kVideoCodecH264;这些参数名大部分简单粗暴,一眼就能知道他是干什么的。需要注意的主要是以下两个:
timeStamp(时间戳)
时间戳对于实时流来说简直是心跳一样的存在。时间戳异常的话,轻则播放紊乱,重则丧失播放能力!但是其实我实测过,只要你的帧率生成且网络稳定的话,这个时间戳只要是递增的就可以,没有什么要求。当你设置为简单加一递增时,视频会一到达就播放,所以视频播放会取决于网络和编码情况。如果你要精准的控制时间的话可以用clock_->CurrentNtpInMilliseconds() * 90。官方代码就是这么计算时间戳的(虽然我已经找不到在哪。。。所以一开发还是用Windows好啊,断点调试,调用栈一看,清清楚楚)。
size(缓冲区空间大小)
这个size的值其实并没有什么关系,这个是buffer的最大值,所以要是设置大一点顶多是浪费空间。这里我用到的CalcBufferSize是在webrtc\modules\video_coding\codecs\h264\h264_encoder_impl.cc里面的一个计算方法。这个文件里面就是原本webrtc中EncodedImage包装的地方,我就是直接仿造这个里面的函数H264EncoderImpl::Encode实现的,如果有什么不清楚的话可以直接看这个文件。
3.RTPFragmentationHeader
上面说过RTPFragmentationHeader是要存储H264的分帧情况的头,那为什么需要这个头呢?我们先简单介绍一下webrtc里面默认生成的H264视频流的格式

webrtc默认使用的H264格式如上图所示,视频帧只有I帧和P帧。每个I帧之前都会附带一对SPS和PPS信息(我猜测是由于怕网络传输丢失,所以需要注意补充视频信息)。原始webrtc会将SPS、PPS和I帧三个帧一起打包给RTP_RTCP模块。为了接收端接收到数据后可能将这三个数据快速区分开来,所以需要加上这个头信息。
我们知道H264是通过“001”或者”0001”的起始码来区分帧的。而webrtc并不需要这些起始码,所以我们需要将每帧的真实数据的开头位置赋值给fragmentationOffset,再把每帧的长度赋值给fragmentationLength。
生成这个头信息的代码如下所示,这里我已经将视频数据的信息收集到了m_fram_info里面:
RTPFragmentationHeader frag_header;
RTPFragmentationHeader* frag_p = &frag_header;
int offset = m_fram_info->startcodeprefix_len;
if (m_fram_info->nal_unit_type == 1) {//判断为p帧
frag_p->VerifyAndAllocateFragmentationHeader(1);//申请一个帧的头
frag_p->fragmentationOffset[0] = offset;//设置纯数据的起始位置
frag_p->fragmentationLength[0] = buffer_length - offset;//设置视频数据长度(去除起始码)
m_image_._frameType = kVideoFrameDelta;
}
else if (m_fram_info->nal_unit_type == 7) {//判断为I帧
frag_p->VerifyAndAllocateFragmentationHeader(3);//申请3个帧的头
frag_p->fragmentationOffset[0] = offset;//SPS偏移位置为起始码长度
frag_p->fragmentationOffset[1] = m_fram_info->SPS_length + offset;//PPS偏移位置为SPS的完整长度加PPS起始码长度
frag_p->fragmentationOffset[2] = m_fram_info->SPS_length + m_fram_info->PPS_length + offset;//I帧偏移位置为前两帧的长度加I帧的起始码长度
frag_p->fragmentationLength[0] = m_fram_info->SPS_length;
frag_p->fragmentationLength[1] = m_fram_info->PPS_length;
frag_p->fragmentationLength[2] = buffer_length - m_fram_info->SPS_length - m_fram_info->PPS_length;
m_image_._frameType = kVideoFrameKey;
}当然,你也能猜到。这个头不只是这么用,你可以将好几帧打包到一个包里面一起发送,只要你能把头信息给处理清楚。不过由于我们的场景对于实时性要求极高,所以不能在这边等待多帧一起发送。
自此我们就将视频数据封装完了。再下来你只要调用
payload_router_.OnEncodedImage(m_image_, &m_codec_specific_info_, frag_p);将数据丢出去就大功告成了。等等,好像还没有,那原本的摄像头数据怎么办呢?
4.去除原生捕获
Webrtc的集体功能的代码其实都集中在目录 webrtc中
这个目录里面的结构我就不一一解释了,只提几个咱们用到的的:
| 文件夹名 | 功能 |
|---|---|
| examples | demo程序 |
| call | 各组件建调度核心模块 |
| video | 视频相关模块 |
进入目录
webrtc\examples\peerconnection\client
这个目录存放的就是peerconnection_client程序的业务层代码。
我们的开发在这个peerconnection_client上进行修改。
webrtc\examples\peerconnection\client\conductor.cc
整个上层业务的代码都在这个文件里面实现。我们就需要在这个文件里面添加音视频的信息。这文件中有我们的好朋友Conductor::AddStreams,相信看过webrtc源码的人都知道这个函数,且对这个函数研究了很久。
一开始我一直企图在这个VideoTrack上面做手脚来完成自定义视频流。最后被盘根错节的代码打的服服帖帖,直接把整个函数都删除了,那我们要如何在这里添加视频发送的参数而不启动原生的捕获呢?答案是:
void ConductorTest::AddStreams() {
peer_connection_->CreateSender("video","1");//lyn 2016/9/28
peer_connection_->CreateSender("audio","1");
}其实这个Sender是没有什么实际功能的,这里添加这两个的作用只是为了在生成offer的时候让offer中带上video和audio的信息。peerconnection在处理offer的时候发现有视频信息,就会去生成VideoSendStream对象了。
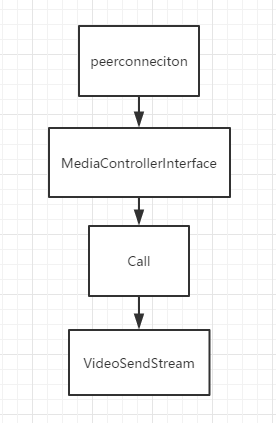
下面的图是VideoSendStream的引用持有顺序,如果你要查看他去Call.cc。如果你要在Conductor操作他,也可以这样一路通下去。
结语
现在你关闭掉了原生视频捕获,在视频发送里,你已经可以无法无天了。我推荐你可以先从文件里面读入视频文件来测试发送。我是llsxily,一个曾经看webrtc看到哭的人,你可以叫我橘子。