SQL基础篇(一)
一,了解SQL
我们可以把 SQL 语言按照功能划分成以下的 4 个部分:
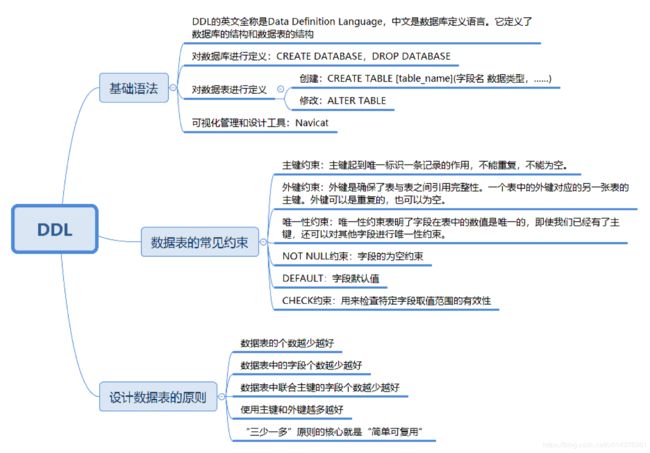
- DDL,英文叫做 Data Definition Language,也就是数据定义语言,它用来定义我们的数据库对象,包括数据库、数据表和列。通过使用 DDL,我们可以创建,删除和修改数据库和表结构。
- DML,英文叫做 Data Manipulation Language,数据操作语言,我们用它操作和数据库相关的记录,比如增加、删除、修改数据表中的记录。
- DCL,英文叫做 Data Control Language,数据控制语言,我们用它来定义访问权限和安全级别。
- DQL,英文叫做 Data Query Language,数据查询语言,我们用它查询想要的记录,它是 SQL 语言的重中之重。在实际的业务中,我们绝大多数情况下都是在和查询打交道,因此学会编写正确且高效的查询语句,是学习的重点。
SQL 语言定义了我们的需求,而不同的 DBMS(数据库管理系统)则会按照指定的 SQL 帮我们提取想要的结果。
我们在创建 DBMS 之前,还需要对它进行设计,对于 RDBMS 来说采用的是 ER 图(Entity Relationship Diagram),即实体 - 关系图的方式进行设计。ER 图评审通过后,我们再用 SQL 语句或者可视化管理工具(如 Navicat)创建数据表。实体 - 关系图有什么用呢?它是我们用来描述现实世界的概念模型,在这个模型中有 3 个要素:实体、属性、关系。实体就是我们要管理的对象,属性是标识每个实体的属性,关系则是对象之间的关系。
比如我们创建了“英雄”这个实体,那么它下面的属性包括了姓名、职业、最大生命值、初始生命值、最大魔法值、初始魔法值和攻击范围等。同时,我们还有“用户”这个实体,它下面的属性包括用户 ID、登录名、密码、性别和头像等。“英雄”和“用户”这两个实体之间就是多对多的关系,也就是说一个英雄可以从属多个用户,而一个用户也可以拥有多个英雄。除了多对多之外,也有一对一和一对多的关系。
关于 SQL 大小写的问题,我总结了下面两点:
- 表名、表别名、字段名、字段别名等都小写;
- SQL 保留字、函数名、绑定变量等都大写。
SELECT name, hp_max FROM heros WHERE role_main = '战士'SELECT、FROM、WHERE 这些常用的 SQL 保留字都采用了大写,而 name、hp_max、role_main 这些字段名,表名都采用了小写。此外在数据表的字段名推荐采用下划线命名,比如 role_main 这种。
二,DBMS
DBMS 的英文全称是 DataBase Management System,数据库管理系统,实际上它可以对多个数据库进行管理,所以你可以理解为 DBMS = 多个数据库(DB) + 管理程序。
DBMS分类:
-
关系型数据库绝对是 DBMS 的主流,其中使用最多的 DBMS 分别是 Oracle、MySQL 和 SQL Server。
-
NoSQL 泛指非关系型数据库,包括了键值型数据库、文档型数据库、搜索引擎和列存储等,除此以外还包括图形数据库。
-
键值型数据库通过 Key-Value 键值的方式来存储数据,其中 Key 和 Value 可以是简单的对象,也可以是复杂的对象。Key 作为唯一的标识符,优点是查找速度快,在这方面明显优于关系型数据库,同时缺点也很明显,它无法像关系型数据库一样自由使用条件过滤(比如 WHERE),如果你不知道去哪里找数据,就要遍历所有的键,这就会消耗大量的计算。键值型数据库典型的使用场景是作为内容缓存。Redis 是最流行的键值型数据库。
-
文档型数据库用来管理文档,在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录,MongoDB 是最流行的文档型数据库。
-
搜索引擎也是数据库检索中的重要应用,常见的全文搜索引擎有 Elasticsearch、Splunk 和 Solr。虽然关系型数据库采用了索引提升检索效率,但是针对全文索引效率却较低。搜索引擎的优势在于采用了全文搜索的技术,核心原理是“倒排索引”。
-
列式数据库是相对于行式存储的数据库,Oracle、MySQL、SQL Server 等数据库都是采用的行式存储(Row-based),而列式数据库是将数据按照列存储到数据库中,这样做的好处是可以大量降低系统的 I/O,适合于分布式文件系统,不足在于功能相对有限。
列式数据库将数据按照列进行存储,因为每列的数据格式是相同的,在存储过程时,可以使用有效的压缩算法进行压缩存储,在读取时,可以只读取需要的列到内存中,但如果是行式数据库,就需要将整行数据读入内存中,所以说列式数据库按照列式存储数据会大量降低系统的IO。

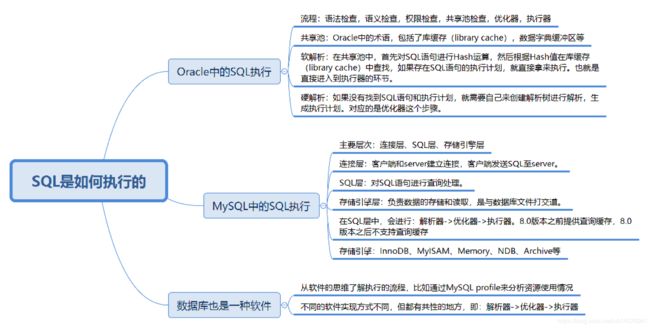
三,SQL是如何执行的
1,Oracle 中的 SQL 是如何执行的
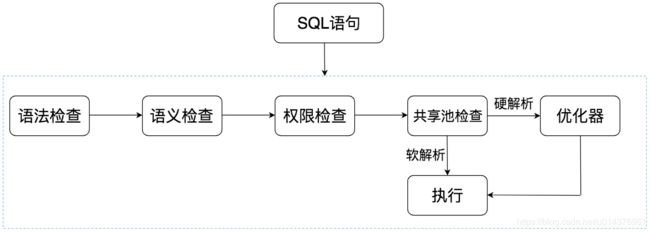
- 语法检查:检查 SQL 拼写是否正确,如果不正确,Oracle 会报语法错误。
- 语义检查:检查 SQL 中的访问对象是否存在。比如我们在写 SELECT 语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证 SQL 语句没有错误。
- 权限检查:看用户是否具备访问该数据的权限。
- 共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存 SQL 语句和该语句的执行计划。Oracle 通过检查共享池是否存在 SQL 语句的执行计划,来判断进行软解析,还是硬解析。那软解析和硬解析又该怎么理解呢?在共享池中,Oracle 首先对 SQL 语句进行 Hash 运算,然后根据 Hash 值在库缓存(Library Cache)中查找,如果存在 SQL 语句的执行计划,就直接拿来执行,直接进入“执行器”的环节,这就是软解析。
- 如果没有找到 SQL 语句和执行计划,Oracle 就需要创建解析树进行解析,生成执行计划,进入“优化器”这个步骤,这就是硬解析。
- 优化器:优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
- 执行器:当有了解析树和执行计划之后,就知道了 SQL 该怎么被执行,这样就可以在执行器中执行语句了。
共享池是 Oracle 中的术语,包括了库缓存,数据字典缓冲区等。我们上面已经讲到了库缓存区,它主要缓存 SQL 语句和执行计划。而数据字典缓冲区存储的是 Oracle 中的对象定义,比如表、视图、索引等对象。当对 SQL 语句进行解析的时候,如果需要相关的数据,会从数据字典缓冲区中提取。库缓存这一个步骤,决定了 SQL 语句是否需要进行硬解析。为了提升 SQL 的执行效率,我们应该尽量避免硬解析,因为在 SQL 的执行过程中,创建解析树,生成执行计划是很消耗资源的。
在 Oracle 中,绑定变量是它的一大特色。绑定变量就是在 SQL 语句中使用变量,通过不同的变量取值来改变 SQL 的执行结果。这样做的好处是能提升软解析的可能性,不足之处在于可能会导致生成的执行计划不够优化,因此是否需要绑定变量还需要视情况而定。
SQL> select * from player where player_id = 10001;
SQL> select * from player where player_id = :player_id;这两个查询语句的效率在 Oracle 中是完全不同的。如果你在查询 player_id = 10001 之后,还会查询 10002、10003 之类的数据,那么每一次查询都会创建一个新的查询解析。而第二种方式使用了绑定变量,那么在第一次查询之后,在共享池中就会存在这类查询的执行计划,也就是软解析。因此我们可以通过使用绑定变量来减少硬解析,减少 Oracle 的解析工作量。
2,MySQL 中的 SQL 是如何执行的
MySQL 是典型的 C/S 架构,即 Client/Server 架构,服务器端程序使用的 mysqld。整体的 MySQL 流程如下图所示:
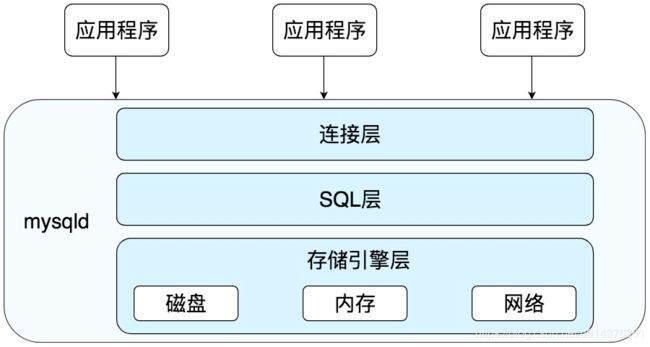
- 连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
- SQL 层:对 SQL 语句进行查询处理;
- 存储引擎层:与数据库文件打交道,负责数据的存储和读取。
其中 SQL 层与数据库文件的存储方式无关:

- 查询缓存:Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃了这个功能。一旦数据表有更新,缓存都将清空,因此只有数据表是静态的时候,或者数据表很少发生变化时,使用缓存查询才有价值,否则如果数据表经常更新,反而增加了 SQL 的查询时间。
- 解析器:在解析器中对 SQL 语句进行语法分析、语义分析。
- 优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据全表检索,还是根据索引来检索等。
- 执行器:在执行之前需要判断该用户是否具备权限,如果具备权限就执行 SQL 查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
与 Oracle 不同的是,MySQL 的存储引擎采用了插件的形式,每个存储引擎都面向一种特定的数据库应用环境。同时开源的 MySQL 还允许开发人员设置自己的存储引擎,下面是一些常见的存储引擎:
- InnoDB 存储引擎:它是 MySQL 5.5 版本之后默认的存储引擎,最大的特点是支持事务、行级锁定、外键约束等
- MyISAM 存储引擎:在 MySQL 5.5 版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特点是速度快,占用资源少。
- Memory 存储引擎:使用系统内存作为存储介质,以便得到更快的响应速度。不过如果 mysqld 进程崩溃,则会导致所有的数据丢失,因此我们只有当数据是临时的情况下才使用 Memory 存储引擎。
- NDB 存储引擎:也叫做 NDB Cluster 存储引擎,主要用于 MySQL Cluster 分布式集群环境,类似于 Oracle 的 RAC 集群。
- Archive 存储引擎:它有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做仓库。
数据库的设计在于表的设计,而在 MySQL 中每个表的设计都可以采用不同的存储引擎,我们可以根据实际的数据处理需要来选择存储引擎,这也是 MySQL 的强大之处
3,总结
RDBMS 之间有相同的地方,也有不同的地方。
- 相同的地方在于 Oracle 和 MySQL 都是通过解析器→优化器→执行器这样的流程来执行 SQL 的。
- 但 Oracle 和 MySQL 在进行 SQL 的查询上面有软件实现层面的差异。Oracle 提出了共享池的概念,通过共享池来判断是进行软解析,还是硬解析。而在 MySQL 中,8.0 以后的版本不再支持查询缓存,而是直接执行解析器→优化器→执行器的流程,这一点从 MySQL 中的 show profile 里也能看到。同时 MySQL 的一大特色就是提供了各种存储引擎以供选择,不同的存储引擎有各自的使用场景,我们可以针对每张表选择适合的存储引擎。
四,DDL创建数据库&数据表
1,DDL 的基础语法及设计工具
在 DDL 中,我们常用的功能是增删改,分别对应的命令是 CREATE、DROP 和 ALTER。需要注意的是,在执行 DDL 的时候,不需要 COMMIT,就可以完成执行任务。
(1)对数据库进行定义
CREATE DATABASE nba; // 创建一个名为nba的数据库
DROP DATABASE nba; // 删除一个名为nba的数据库(2)对数据表进行定义
CREATE TABLE [](字段名 数据类型,......)(3)使用 Navicat 来创建和操作数据库和数据表
假如还是针对 player 这张表,我们想设计以下的字段:

按照上面的设计需求,我们可以使用 Navicat 软件进行设计,如下所示:

我们还可以对 player_name 字段进行索引,索引类型为Unique。使用 Navicat 设置如下:

这样一张 player 表就通过可视化工具设计好了。我们可以把这张表导出来,可以看看这张表对应的 SQL 语句是怎样的。方法是在 Navicat 左侧用右键选中 player 这张表,然后选择“转储 SQL 文件”→“仅结构”,这样就可以看到导出的 SQL 文件了,代码如下:
DROP TABLE IF EXISTS `player`;
CREATE TABLE `player` (
`player_id` int(11) NOT NULL AUTO_INCREMENT,
`team_id` int(11) NOT NULL,
`player_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`height` float(3, 2) NULL DEFAULT 0.00,
PRIMARY KEY (`player_id`) USING BTREE,
UNIQUE INDEX `player_name`(`player_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;(4)修改表结构
添加字段,比如我在数据表中添加一个 age 字段,类型为int(11)
ALTER TABLE player ADD (age int(11));修改字段名,将 age 字段改成player_age
ALTER TABLE player RENAME COLUMN age to player_age修改字段的数据类型,将player_age的数据类型设置为float(3,1)
ALTER TABLE player MODIFY (player_age float(3,1));删除字段, 删除刚才添加的player_age字段
ALTER TABLE player DROP COLUMN player_age;2,数据表的常见约束
(1)首先是主键约束
主键起的作用是唯一标识一条记录,不能重复,不能为空,即 UNIQUE+NOT NULL。一个数据表的主键只能有一个。主键可以是一个字段,也可以由多个字段复合组成。在上面的例子中,我们就把 player_id 设置为了主键。
(2)其次还有外键约束
外键确保了表与表之间引用的完整性。一个表中的外键对应另一张表的主键。外键可以是重复的,也可以为空。比如 player_id 在 player 表中是主键,如果你想设置一个球员比分表即 player_score,就可以在 player_score 中设置 player_id 为外键,关联到 player 表中。
(3)唯一性约束
唯一性约束表明了字段在表中的数值是唯一的,即使我们已经有了主键,还可以对其他字段进行唯一性约束。需要注意的是,唯一性约束和普通索引(NORMAL INDEX)之间是有区别的。唯一性约束相当于创建了一个约束和普通索引,目的是保证字段的正确性,而普通索引只是提升数据检索的速度,并不对字段的唯一性进行约束。
(4)NOT NULL 约束
对字段定义了 NOT NULL,即表明该字段不应为空,必须有取值
(5)DEFAULT,表明了字段的默认值
如果在插入数据的时候,这个字段没有取值,就设置为默认值。比如我们将身高 height 字段的取值默认设置为 0.00,即DEFAULT 0.00。
(6)CHECK 约束,用来检查特定字段取值范围的有效性
CHECK 约束的结果不能为 FALSE,比如我们可以对身高 height 的数值进行 CHECK 约束,必须≥0,且<3,即CHECK(height>=0 AND height<3)。设计数据表的原则
3,设计数据表的原则
“三少一多”原则:
(1)数据表的个数越少越好
RDBMS 的核心在于对实体和联系的定义,也就是 E-R 图(Entity Relationship Diagram),数据表越少,证明实体和联系设计得越简洁,既方便理解又方便操作。
(2)数据表中的字段个数越少越好
字段个数越多,数据冗余的可能性越大。设置字段个数少的前提是各个字段相互独立,而不是某个字段的取值可以由其他字段计算出来。当然字段个数少是相对的,我们通常会在数据冗余和检索效率中进行平衡。
(3)数据表中联合主键的字段个数越少越好
设置主键是为了确定唯一性,当一个字段无法确定唯一性的时候,就需要采用联合主键的方式(也就是用多个字段来定义一个主键)。联合主键中的字段越多,占用的索引空间越大,不仅会加大理解难度,还会增加运行时间和索引空间,因此联合主键的字段个数越少越好。
(4)使用主键和外键越多越好
数据库的设计实际上就是定义各种表,以及各种字段之间的关系。这些关系越多,证明这些实体之间的冗余度越低,利用度越高。这样做的好处在于不仅保证了数据表之间的独立性,还能提升相互之间的关联使用率。
你应该能看出来“三少一多”原则的核心就是简单可复用。简单指的是用更少的表、更少的字段、更少的联合主键字段来完成数据表的设计。可复用则是通过主键、外键的使用来增强数据表之间的复用率。因为一个主键可以理解是一张表的代表。键设计得越多,证明它们之间的利用率越高。
4,总结
我们在创建数据表的时候,会对数据表设置主键、外键和索引。你能说下这三者的作用和区别吗?
- 主键:唯一标识一条记录,不能重复,不能为空。主键就好比是我的身份证
- 外键:确保了表于表之间引用的完整性,可以重复,可以为空。外键就好比我在各种团队组织中的身份,如在单位是员工和管理者、在家是儿子和丈夫、在协会是会员和委员等;
- 索引:提升数据检索速度
主键是索引的一种,而且是唯一索引的一种。而外键并非是索引,是两表之间的链接。
五,使用SELECT检索数据
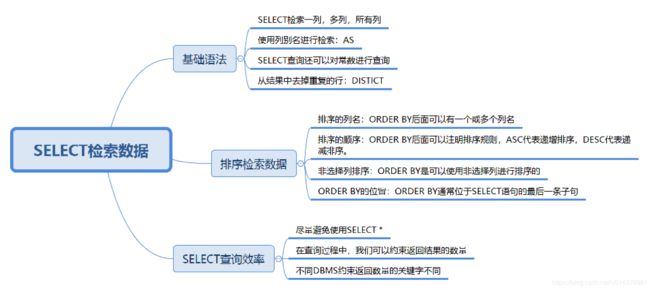
1,SELECT 查询的基础语法
- 查询列
我们想要检索有哪些英雄,他们的最大生命、最大法力、最大物攻和最大物防分别是多少
SQL:SELECT name, hp_max, mp_max, attack_max, defense_max FROM heros
如果我们记不住所有的字段名称,可以使用 SELECT * 帮我们检索出所有的列:
SQL:SELECT * FROM heros- 起别名
我们在进行检索的时候,可以给英雄名、最大生命、最大法力、最大物攻和最大物防等取别名:
SELECT name AS n, hp_max AS hm, mp_max AS mm, attack_max AS am, defense_max AS dm FROM heros- 查询常数
SELECT 查询还可以对常数进行查询。对的,就是在 SELECT 查询结果中增加一列固定的常数列。比如说,我们想对 heros 数据表中的英雄名进行查询,同时增加一列字段platform,这个字段固定值为“王者荣耀”,可以这样写:
SELECT '王者荣耀' as platform, name FROM heros- 去除重复行
比如我们想要看下 heros 表中关于攻击范围的取值都有哪些:
SELECT DISTINCT attack_range FROM heros这里有两点需要注意:
- DISTINCT 需要放到所有列名的前面,如果写成SELECT name, DISTINCT attack_range FROM heros会报错。
- DISTINCT 其实是对后面所有列名的组合进行去重
2,排序检索数据
使用 ORDER BY 子句有以下几个点需要掌握:
- 排序的列名:ORDER BY 后面可以有一个或多个列名,如果是多个列名进行排序,会按照后面第一个列先进行排序,当第一列的值相同的时候,再按照第二列进行排序,以此类推。
- 排序的顺序:ORDER BY 后面可以注明排序规则,ASC 代表递增排序,DESC 代表递减排序。如果没有注明排序规则,默认情况下是按照 ASC 递增排序。
- 非选择列排序:ORDER BY 可以使用非选择列进行排序,所以即使在 SELECT 后面没有这个列名,你同样可以放到 ORDER BY 后面进行排序。
- ORDER BY 的位置:ORDER BY 通常位于 SELECT 语句的最后一条子句,否则会报错。
假设我们想要显示英雄名称及最大生命值,按照最大生命值从高到低的方式进行排序:
SELECT name, hp_max FROM heros ORDER BY hp_max DESC 3,约束返回结果的数量
使用 LIMIT 关键字。比如我们想返回英雄名称及最大生命值,按照最大生命值从高到低排序,返回 5 条记录即可。
SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 54,SELECT 的执行顺序
其中你需要记住 SELECT 查询时的两个顺序:
- 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...- SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num #顺序5
FROM player JOIN team ON player.team_id = team.team_id #顺序1
WHERE height > 1.80 #顺序2
GROUP BY player.team_id #顺序3
HAVING num > 2 #顺序4
ORDER BY num DESC #顺序6
LIMIT 2 #顺序7(1)首先,你可以注意到,SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
(2)当我们拿到了查询数据表的原始数据,也就是最终的虚拟表 vt1,就可以在此基础上再进行 WHERE 阶段。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表 vt2。
(3)然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4。
(4)当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT 阶段。首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表 vt5-1 和 vt5-2。
(5)当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段,得到虚拟表 vt6。
(6)最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段,得到最终的结果,对应的是虚拟表 vt7。当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
5,什么情况下用 SELECT*,如何提升 SELECT 查询效率?
当我们初学 SELECT 语法的时候,经常会使用SELECT *,因为使用方便。实际上这样也增加了数据库的负担。所以如果我们不需要把所有列都检索出来,还是先指定出所需的列名,因为写清列名,可以减少数据表查询的网络传输量,而且考虑到在实际的工作中,我们往往不需要全部的列名,因此你需要养成良好的习惯,写出所需的列名。
6,总结
关于执行顺序的问题
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7对于这个语句,我还有一点疑问:既然HAVING的执行是在SELECT之前的,那么按理说在执行HAVING的时候SELECT中的count(*)应该还没有被计算出来才对啊,为什么在HAVING中就直接使用了num>2这个条件呢?
实际上在Step4和Step5之间,还有个聚集函数的计算。
如果加上这个计算过程,完整的顺序是:
1、FROM子句组装数据
2、WHERE子句进行条件筛选
3、GROUP BY分组
4、使用聚集函数进行计算;
5、HAVING筛选分组;
6、计算所有的表达式;
7、SELECT 的字段;
8、ORDER BY排序
9、LIMIT筛选
所以中间有两个过程是需要计算的:聚集函数 和 表达式。其余是关键字的执行顺序,如文章所示。六,SQL数据过滤
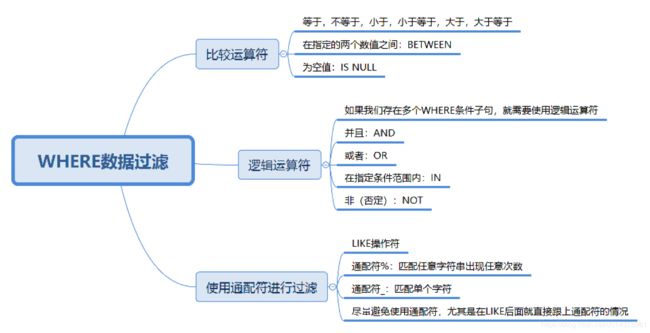
1,比较运算符
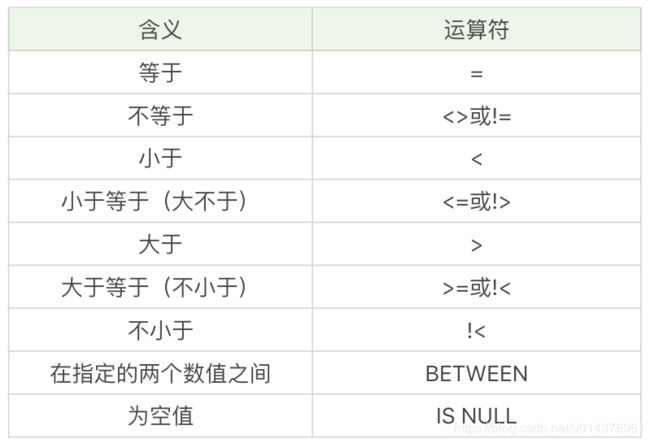
想要查询所有最大生命值在 5399 到 6811 之间的英雄:
SQL:SELECT name, hp_max FROM heros WHERE hp_max BETWEEN 5399 AND 68112,逻辑运算符
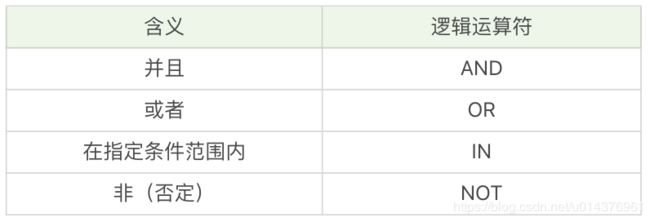
假设想要筛选最大生命值大于 6000,最大法力大于 1700 的英雄,然后按照最大生命值和最大法力值之和从高到低进行排序。
SELECT name, hp_max, mp_max FROM heros WHERE hp_max > 6000 AND mp_max > 1700
ORDER BY (hp_max+mp_max) DESC假设我们想要查询最大生命值加最大法力值大于 8000 的英雄,或者最大生命值大于 6000 并且最大法力值大于 1700 的英雄
SELECT name, hp_max, mp_max FROM heros WHERE (hp_max+mp_max) > 8000 OR
hp_max > 6000 AND mp_max > 1700 ORDER BY (hp_max+mp_max) DESC当 WHERE 子句中同时存在 OR 和 AND 的时候,AND 执行的优先级会更高,也就是说 SQL 会优先处理 AND 操作符,然后再处理 OR 操作符。
如果我想要查询主要定位或者次要定位是法师或是射手的英雄,同时英雄的上线时间不在 2016-01-01 到 2017-01-01 之间。
SELECT name, role_main, role_assist, hp_max, mp_max, birthdate
FROM heros
WHERE (role_main IN ('法师', '射手') OR role_assist IN ('法师', '射手'))
AND DATE(birthdate) NOT BETWEEN '2016-01-01' AND '2017-01-01'
ORDER BY (hp_max + mp_max) DESC3,使用通配符进行过滤
如果我们想要匹配任意字符串出现的任意次数,需要使用(%)通配符。比如我们想要查找英雄名中包含“太”字的英雄都有哪些:
SELECT name FROM heros WHERE name LIKE '%太%'如果我们想要匹配单个字符,就需要使用下划线 _ 通配符。%和 _ 的区别在于,%代表零个或多个字符,而 _ 只代表一个字符。比如我们想要查找英雄名除了第一个字以外,包含‘太’字的英雄有哪些。
SQL:SELECT name FROM heros WHERE name LIKE '_%太%'你能看出来通配符还是很有用的,尤其是在进行字符串匹配的时候。不过在实际操作过程中,我还是建议你尽量少用通配符,因为它需要消耗数据库更长的时间来进行匹配。即使你对 LIKE 检索的字段进行了索引,索引的价值也可能会失效。如果要让索引生效,那么 LIKE 后面就不能以(%)开头,比如使用LIKE '%太%'或LIKE '%太'的时候就会对全表进行扫描。如果使用LIKE '太%',同时检索的字段进行了索引的时候,则不会进行全表扫描。
4,总结
比较运算符是对数值进行比较,不同的 DBMS 支持的比较运算符可能不同,你需要事先查阅相应的 DBMS 文档。逻辑运算符可以让我们同时使用多个 WHERE 子句,你需要注意的是 AND 和 OR 运算符的执行顺序。通配符可以让我们对文本类型的字段进行模糊查询,不过检索的代价也是很高的,通常都需要用到全表扫描,所以效率很低。只有当 LIKE 语句后面不用通配符,并且对字段进行索引的时候才不会对全表进行扫描。
实际工作中不同人写的 SQL 语句的查询效率差别很大,保持高效率的一个很重要的原因,就是要避免全表扫描,所以我们会考虑在 WHERE 及 ORDER BY 涉及到的列上增加索引。
思考题:
1,要避免全表扫描,所以我们会考虑在 WHERE 及 ORDER BY 涉及到的列上增加索引。where 条件字段上加索引是可以明白的,但是为什么 order by 字段上还要加索引呢?这个时候已经通过 where条件过滤得到了数据,已经不需要在筛选过滤数据了,只需要在排序的时候根据字段排序就好了。
关于ORDER BY字段是否增加索引:
在MySQL中,支持两种排序方式:
- Index排序:索引可以保证数据的有序性,因此不需要再进行排序。
- FileSort排序:一般在内存中进行排序,占用CPU较多。如果待排结果较大,会产生临时文件I/O到磁盘进行排序,效率较低。
FileSort和Index排序,Index排序的效率更高。所以使用ORDER BY子句时,应该尽量使用Index排序,避免使用FileSort排序。
当然具体优化器是否采用索引进行排序,你可以使用explain来进行执行计划的查看。
优化建议:
- SQL中,可以在WHERE子句和ORDER BY子句中使用索引,目的是在WHERE子句中避免全表扫描,ORDER BY子句避免使用FileSort排序。当然,某些情况下全表扫描,或者FileSort排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。一般情况下,优化器会帮我们进行更好的选择,当然我们也需要建立合理的索引。
- 尽量Using Index完成ORDER BY排序。如果WHERE和ORDER BY相同列就使用单索引列;如果不同使用联合索引。
- 无法Using Index时,对FileSort方式进行调优。
2,平日因业务考核需要,一条查询语句查询条件需要写 30 多个 like "%A%" ,语句跑起来特别慢,请问有什么优化方法吗?
- 建立索引
- 使用函数来替代LIKE,如果是MySQL的话:可以考虑locate, position, instr, find_in_set;如果是SQL Server,可以考虑charindex, patindex
3,对where语句建索引是什么意思 通过sql语句怎么实现?
如果你使用了WHERE子句,对于某个字段进行了条件筛选,那么这个字段你可以通过建立索引的方式进行SQL优化。因为我们在进行SQL优化的时候,应该尽量避免全表扫描。所以当我们使用WHERE子句对某个字段进行了条件筛选时,如果我们没有对这个字段建立索引,就会进入到全表扫描,因此可以考虑对这个字段建立索引。
当然你也需要注意 索引是否会失效。因此除了考虑建立字段索引以外,你还需要考虑:
- 不要在WHERE子句后面对字段做函数处理,同时也避免对索引字段进行数据类型转换
- 避免在索引字段上使用<>,!=,以及对字段进行NULL判断(包括 IS NULL, IS NOT NULL)
- 在索引字段后,慎用IN和NOT IN,如果是连续的数值,可以考虑用BETWEEN进行替换。因为在WHERE子句中,如果对索引字段进行了函数处理,或者使用了<>,!=或NULL判断等,都会造成索引失效。
七,SQL函数
1,算术函数

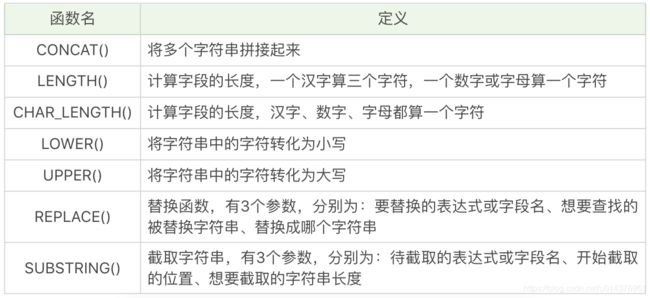
2,字符串函数
3,日期函数
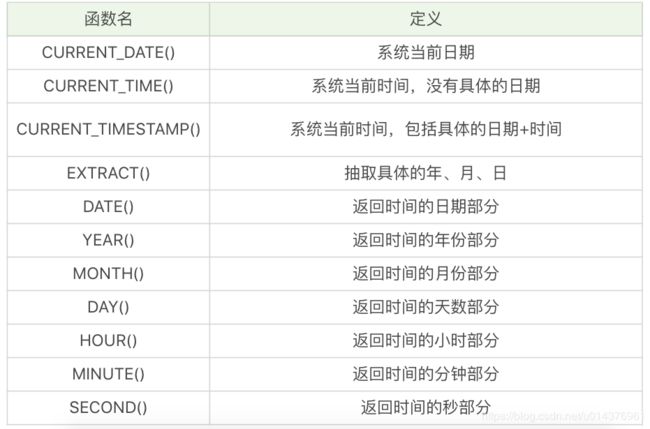
SELECT EXTRACT(YEAR FROM '2019-04-03'),运行结果为 2019
4,转换函数

SELECT CAST(123.123 AS INT),运行结果会报错。
SELECT CAST(123.123 AS DECIMAL(8,2)),运行结果为 123.12。
SELECT COALESCE(null,1,2),运行结果为 1。5,示例
假如我们想要知道最大生命值最大的是哪个英雄,以及对应的数值,就需要分成两个步骤来处理:首先找到英雄的最大生命值的最大值,即SELECT MAX(hp_max) FROM heros,然后再筛选最大生命值等于这个最大值的英雄,如下所示。
SQL:SELECT name, hp_max FROM heros
WHERE hp_max = (SELECT MAX(hp_max) FROM heros)
假设我们需要知道在 2016 年 10 月 1 日之后上线英雄的平均最大生命值、平均最大法力和最高物攻最大值。同样我们需要先筛选日期条件,即WHERE DATE(birthdate)>'2016-10-01',然后再选择AVG(hp_max), AVG(mp_max), MAX(attack_max)字段进行显示。
SELECT AVG(hp_max), AVG(mp_max), MAX(attack_max) FROM heros
WHERE DATE(birthdate)>'2016-10-01'6,为什么使用 SQL 函数会带来问题
尽管 SQL 函数使用起来会很方便,但我们使用的时候还是要谨慎,因为你使用的函数很可能在运行环境中无法工作,这是为什么呢?
我们在使用 SQL 语言的时候,不是直接和这门语言打交道,而是通过它使用不同的数据库软件,即 DBMS。DBMS 之间的差异性很大,远大于同一个语言不同版本之间的差异。实际上,只有很少的函数是被 DBMS 同时支持的。比如,大多数 DBMS 使用(||)或者(+)来做拼接符,而在 MySQL 中的字符串拼接函数为Concat()。大部分 DBMS 会有自己特定的函数,这就意味着采用 SQL 函数的代码可移植性是很差的,因此在使用函数的时候需要特别注意。
八,子查询
1,什么是关联子查询,什么是非关联子查询
- 子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行,那么这样的子查询叫做非关联子查询。
- 如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就称为关联子查询。
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询。比如我们想要查找每个球队中大于平均身高的球员有哪些,并显示他们的球员姓名、身高以及所在球队 ID。
SELECT player_name, height, team_id FROM player AS a
WHERE height > (SELECT avg(height) FROM player AS b
WHERE a.team_id = b.team_id)2,EXISTS 子查询
比如我们想要看出场过的球员都有哪些,并且显示他们的姓名、球员 ID 和球队 ID。
在这个统计中,是否出场是通过 player_score 这张表中的球员出场表现来统计的,如果某个球员在 player_score 中有出场记录则代表他出场过,这里就使用到了 EXISTS 子查询,即EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id),然后将它作为筛选的条件,实际上也是关联子查询,即:
SELECT player_id, team_id, player_name FROM player
WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)3,集合比较子查询

假设我们想要看出场过的球员都有哪些,可以采用 IN 子查询来进行操作:
SELECT player_id, team_id, player_name FROM player
WHERE player_id in (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)既然 IN 和 EXISTS 都可以得到相同的结果,那么我们该使用 IN 还是 EXISTS 呢?
我们可以把这个模式抽象为:
SELECT * FROM A WHERE cc IN (SELECT cc FROM B);
SELECT * FROM A WHERE EXIST (SELECT cc FROM B WHERE B.cc=A.cc);
实际上在查询过程中,在我们对 cc 列建立索引的情况下,我们还需要判断表 A 和表 B 的大小。
- 如果表 A 比表 B 大,那么 IN 子查询的效率要比 EXIST 子查询效率高,因为这时 B 表中如果对 cc 列进行了索引,那么 IN 子查询的效率就会比较高。
- 同样,如果表 A 比表 B 小,那么使用 EXISTS 子查询效率会更高,因为我们可以使用到 A 表中对 cc 列的索引,而不用从 B 中进行 cc 列的查询。
- IN表是外边和内表进行hash连接,是先执行子查询。EXISTS是对外表进行循环,然后在内表进行查询。
因此如果外表数据量大,则用IN,如果外表数据量小,也用EXISTS。IN有一个缺陷是不能判断NULL,因此如果字段存在NULL值,则会出现返回,因为最好使用NOT EXISTS。
如果我们想要查询球员表中,比印第安纳步行者(对应的 team_id 为 1002)中任何一个球员身高高的球员的信息,并且输出他们的球员 ID、球员姓名和球员身高,该怎么写呢?首先我们需要找出所有印第安纳步行者队中的球员身高,即SELECT height FROM player WHERE team_id = 1002,
SELECT player_id, player_name, height FROM player
WHERE height > ANY (SELECT height FROM player WHERE team_id = 1002)如果我们想要知道比印第安纳步行者(对应的 team_id 为 1002)中所有球员身高都高的球员的信息,并且输出球员 ID、球员姓名和球员身高,该怎么写呢?
SELECT player_id, player_name, height FROM player
WHERE height > ALL (SELECT height FROM player WHERE team_id = 1002);4,将子查询作为计算字段
查询每个球队的球员数,也就是对应 team 这张表,我需要查询相同的 team_id 在 player 这张表中所有的球员数量是多少。
SELECT team_name, (SELECT count(*) FROM player WHERE player.team_id = team.team_id)
AS player_num FROM team;5,总结

九,连接
1,在 SQL92 中是如何使用连接的
SQL92 中的 5 种连接方式,它们分别是笛卡尔积、等值连接、非等值连接、外连接(左连接、右连接)和自连接。
- 笛卡尔积
笛卡尔积也称为交叉连接,英文是 CROSS JOIN,它的作用就是可以把任意表进行连接,即使这两张表不相关。但我们通常进行连接还是需要筛选的,因此你需要在连接后面加上 WHERE 子句,也就是作为过滤条件对连接数据进行筛选。
- 等值连接
两张表的等值连接就是用两张表中都存在的列进行连接。我们也可以对多张表进行等值连接。
针对 player 表和 team 表都存在 team_id 这一列,我们可以用等值连接进行查询
SELECT player_id, player.team_id, player_name, height, team_name FROM player, team
WHERE player.team_id = team.team_id
SELECT player_id, a.team_id, player_name, height, team_name FROM player AS a, team AS b
WHERE a.team_id = b.team_id
- 非等值连接
当我们进行多表查询的时候,如果连接多个表的条件是等号时,就是等值连接,其他的运算符连接就是非等值查询。
我们知道 player 表中有身高 height 字段,如果想要知道每个球员的身高的级别,可以采用非等值连接查询:
SELECT p.player_name, p.height, h.height_level
FROM player AS p, height_grades AS h
WHERE p.height BETWEEN h.height_lowest AND h.height_highest- 外连接
除了查询满足条件的记录以外,外连接还可以查询某一方不满足条件的记录。两张表的外连接,会有一张是主表,另一张是从表。在 SQL92 中采用(+)代表从表所在的位置,而且在 SQL92 中,只有左外连接和右外连接,没有全外连接。
- 左外连接,就是指左边的表是主表,需要显示左边表的全部行,而右侧的表是从表,(+)表示哪个是从表。
SELECT * FROM player, team where player.team_id = team.team_id(+);
相当于 SQL99 中的:
SELECT * FROM player LEFT JOIN team on player.team_id = team.team_id;
- 右外连接,指的就是右边的表是主表,需要显示右边表的全部行,而左侧的表是从表。
SELECT * FROM player, team where player.team_id(+) = team.team_id;
相当于 SQL99 中的:
SELECT * FROM player RIGHT JOIN team on player.team_id = team.team_id- 自连接
自连接可以对多个表进行操作,也可以对同一个表进行操作。也就是说查询条件使用了当前表的字段。
比如我们想要查看比布雷克·格里芬高的球员都有谁,以及他们的对应身高:
SELECT b.player_name, b.height FROM player as a , player as b
WHERE a.player_name = '布雷克-格里芬' and a.height < b.height2,总结

你不妨拿案例中的 team 表做一道动手题,表格中一共有 3 支球队,现在这 3 支球队需要进行比赛,请用一条 SQL 语句显示出所有可能的比赛组合。

#分主客队
SELECT CONCAT(kedui.team_name, ' VS ', zhudui.team_name) as '客队 VS 主队' FROM team as zhudui LEFT JOIN team as kedui on zhudui.team_id<>kedui.team_id;
客队 VS 主队
------------------------------------
底特律活塞 VS 印第安纳步行者
底特律活塞 VS 亚特兰大老鹰
印第安纳步行者 VS 底特律活塞
印第安纳步行者 VS 亚特兰大老鹰
亚特兰大老鹰 VS 底特律活塞
亚特兰大老鹰 VS 印第安纳步行者
#不分主客队
SELECT a.team_name as '队伍1' ,'VS' , b.team_name as '队伍2' FROM team as a ,team as b where a.team_id3,SQL99 标准中的连接查询
(1)交叉连接
我们可以通过下面这行代码得到 player 和 team 这两张表的笛卡尔积的结果:
ELECT * FROM player CROSS JOIN team如果多张表进行交叉连接,比如表 t1,表 t2,表 t3 进行交叉连接,可以写成下面这样:
SELECT * FROM t1 CROSS JOIN t2 CROSS JOIN t3(2)自然连接
你可以把自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中所有相同的字段,然后进行等值连接。
如果我们想把 player 表和 team 表进行等值连接,相同的字段是 team_id:
SQL92:
SELECT player_id, a.team_id, player_name, height, team_name
FROM player as a, team as b:
WHERE a.team_id = b.team_id
SQL96:
SELECT player_id, team_id, player_name, height, team_name
FROM player NATURAL JOIN team (3)ON 连接
ON 连接用来指定我们想要的连接条件,针对上面的例子,它同样可以帮助我们实现自然连接的功能:
SELECT player_id, player.team_id, player_name, height, team_name
FROM player JOIN team ON player.team_id = team.team_id当然你也可以 ON 连接进行非等值连接,比如我们想要查询球员的身高等级,需要用 player 和 height_grades 两张表:
SQL99:
SELECT p.player_name, p.height, h.height_level
FROM player as p JOIN height_grades as h
ON height BETWEEN height_lowest AND height_highest
SQL92:
SELECT p.player_name, p.height, h.height_level
FROM player AS p, height_grades AS h
WHERE p.height BETWEEN h.height_lowest AND h.height_highest一般来说在 SQL99 中,我们需要连接的表会采用 JOIN 进行连接,ON 指定了连接条件,后面可以是等值连接,也可以采用非等值连接。
(4)USING 连接
当我们进行连接的时候,可以用 USING 指定数据表里的同名字段进行等值连接。比如:
SELECT player_id, team_id, player_name, height, team_name
FROM player JOIN team USING(team_id)(5)外连接
SQL99 的外连接包括了三种形式:
- 左外连接:LEFT JOIN 或 LEFT OUTER JOIN
- 右外连接:RIGHT JOIN 或 RIGHT OUTER JOIN
- 全外连接:FULL JOIN 或 FULL OUTER JOIN
左外连接:
SQL92:
SELECT * FROM player, team where player.team_id = team.team_id(+)
SQL96:
SELECT * FROM player LEFT JOIN team ON player.team_id = team.team_id右外连接:
SQL92:
SELECT * FROM player, team where player.team_id(+) = team.team_id
SQL96:
SELECT * FROM player RIGHT JOIN team ON player.team_id = team.team_id全外连接:
SELECT * FROM player FULL JOIN team ON player.team_id = team.team_id全外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
(6)自连接
比如我们想要查看比布雷克·格里芬身高高的球员都有哪些,在两个 SQL 标准下的查询如下。
SQL92:
SELECT b.player_name, b.height FROM player as a , player as b
WHERE a.player_name = '布雷克-格里芬' and a.height < b.height
SQL96:
SELECT b.player_name, b.height FROM player as a
JOIN player as b ON a.player_name = '布雷克-格里芬' and a.height < b.height4,SQL99 和 SQL92 的区别
至此我们讲解完了 SQL92 和 SQL99 标准下的连接查询,它们都对连接进行了定义,只是操作的方式略有不同。我们再来回顾下,这些连接操作基本上可以分成三种情况:
- 内连接:将多个表之间满足连接条件的数据行查询出来。它包括了等值连接、非等值连接和自连接。
- 外连接:会返回一个表中的所有记录,以及另一个表中匹配的行。它包括了左外连接、右外连接和全连接。
- 交叉连接:也称为笛卡尔积,返回左表中每一行与右表中每一行的组合。在 SQL99 中使用的 CROSS JOIN。
你能看出在 SQL92 中进行查询时,会把所有需要连接的表都放到 FROM 之后,然后在 WHERE 中写明连接的条件。而 SQL99 在这方面更灵活,它不需要一次性把所有需要连接的表都放到 FROM 之后,而是采用 JOIN 的方式,每次连接一张表,可以多次使用 JOIN 进行连接。
使用 SQL99 标准,因为层次性更强,可读性更强,比如:
SELECT ...
FROM table1
JOIN table2 ON table1和table2的连接条件
JOIN table3 ON table2和table3的连接条件SQL99 采用的这种嵌套结构非常清爽,即使再多的表进行连接也都清晰可见。如果你采用 SQL92,可读性就会大打折扣。
最后一点就是,SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 和 JOIN USING。它们在实际中是比较常用的,省略了 ON 后面的等值条件判断,让 SQL 语句更加简洁。
5,使用SQL连接的问题
除了一些常见的语法问题,还有一些关于连接的性能问题需要你注意:
(1) 控制连接表的数量
多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。
(2)在连接时不要忘记 WHERE 语句
多表连接的目的不是为了做笛卡尔积,而是筛选符合条件的数据行,因此在多表连接的时候不要忘记了 WHERE 语句,这样可以过滤掉不必要的数据行返回。
(3)使用自连接而不是子查询
我们在查看比布雷克·格里芬高的球员都有谁的时候,可以使用子查询,也可以使用自连接。一般情况建议你使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。你可以这样理解:子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表进行条件判断,因此在大部分 DBMS 中都对自连接处理进行了优化。
6,总结

请你编写 SQL 查询语句,查询不同身高级别(对应 height_grades 表)对应的球员数量(对应 player 表)。
SELECT h.height_level, count(*) AS num
FROM height_grades AS h LEFT JOIN player AS p
ON p.height BETWEEN h.height_lowest AND h.height_highest
GROUP BY height_level;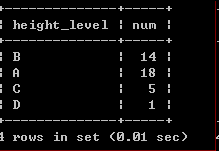
十,视图
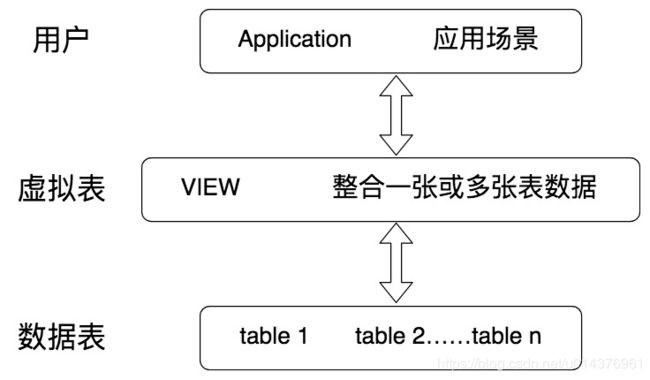
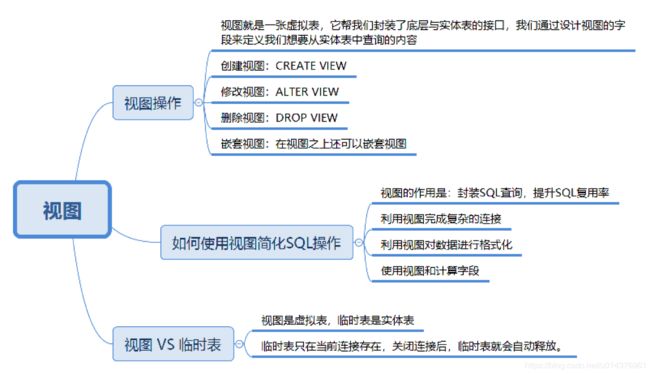
视图作为一张虚拟表,帮我们封装了底层与数据表的接口。它相当于是一张表或多张表的数据结果集。视图的这一特点,可以帮我们简化复杂的 SQL 查询,比如在编写视图后,我们就可以直接重用它,而不需要考虑视图中包含的基础查询的细节。同样,我们也可以根据需要更改数据格式,返回与底层数据表格式不同的数据。
1,创建视图:CREATE VIEW
CREATE VIEW view_name AS
SELECT column1, column2
FROM table
WHERE condition我们以 NBA 球员数据表为例。我们想要查询比 NBA 球员平均身高高的球员都有哪些,显示他们的球员 ID 和身高。假设我们给这个视图起个名字 player_above_avg_height,那么创建视图可以写成:
CREATE VIEW player_above_avg_height AS
SELECT player_id, height
FROM player
WHERE height > (SELECT AVG(height) from player)当视图创建之后,它就相当于一个虚拟表,可以直接使用:
SELECT * FROM player_above_avg_height2,修改视图:ALTER VIEW
ALTER VIEW view_name AS
SELECT column1, column2
FROM table
WHERE condition你能看出来它的语法和创建视图一样,只是对原有视图的更新。比如我们想更新视图 player_above_avg_height,增加一个 player_name 字段,可以写成:
ALTER VIEW player_above_avg_height AS
SELECT player_id, player_name, height
FROM player
WHERE height > (SELECT AVG(height) from player)3,删除视图:DROP VIEW
比如我们想把刚才创建的视图删除,可以使用:
DROP VIEW player_above_avg_height4,利用视图完成复杂的连接
有两张表,分别为 player 和 height_grades。其中 height_grades 记录了不同身高对应的身高等级。这里我们可以通过创建视图,来完成球员以及对应身高等级的查询。首先我们对 player 表和 height_grades 表进行连接,关联条件是球员的身高 height(在身高等级表规定的最低身高和最高身高之间),这样就可以得到这个球员对应的身高等级,对应的字段为 height_level。然后我们通过 SELECT 得到我们想要查询的字段,分别为球员姓名 player_name、球员身高 height,还有对应的身高等级 height_level。然后把取得的查询结果集放到视图 player_height_grades 中,即:
CREATE VIEW player_height_grades AS
SELECT p.player_name, p.height, h.height_level
FROM player as p JOIN height_grades as h
ON height BETWEEN h.height_lowest AND h.height_highest以后我们进行查询的时候,可以直接通过视图查询,比如我想查询身高介于 1.90m 和 2.08m 之间的球员及他们对应的身高:
SELECT * FROM player_height_grades WHERE height >= 1.90 AND height <= 2.085,利用视图对数据进行格式化
我们经常需要输出某个格式的内容,比如我们想输出球员姓名和对应的球队,对应格式为 player_name(team_name),就可以使用视图来完成数据格式化的操作:
CREATE VIEW player_team AS
SELECT CONCAT(player_name, '(' , team.team_name , ')') AS player_team
FROM player JOIN team WHERE player.team_id = team.team_id首先我们将 player 表和 team 表进行连接,关联条件是相同的 team_id。我们想要的格式是player_name(team_name),因此我们使用 CONCAT 函数,即CONCAT(player_name, '(' , team.team_name , ')'),将 player_name 字段和 team_name 字段进行拼接,得到了拼接值被命名为 player_team 的字段名,将它放到视图 player_team 中。
6,使用视图与计算字段
如果我想要统计每位球员在每场比赛中的二分球、三分球和罚球的得分,可以通过创建视图完成:
CREATE VIEW game_player_score AS
SELECT game_id, player_id, (shoot_hits-shoot_3_hits)*2 AS shoot_2_points,
shoot_3_hits*3 AS shoot_3_points, shoot_p_hits AS shoot_p_points, score FROM player_score7,总结
使用视图有很多好处,比如安全、简单清晰。
- 安全性:虚拟表是基于底层数据表的,我们在使用视图时,一般不会轻易通过视图对底层数据进行修改,即使是使用单表的视图,也会受到限制,比如计算字段,类型转换等是无法通过视图来对底层数据进行修改的,这也在一定程度上保证了数据表的数据安全性。同时,我们还可以针对不同用户开放不同的数据查询权限,比如人员薪酬是个敏感的字段,那么只给某个级别以上的人员开放,其他人的查询视图中则不提供这个字段。
- 简单清晰:视图是对 SQL 查询的封装,它可以将原本复杂的 SQL 查询简化,在编写好查询之后,我们就可以直接重用它而不必要知道基本的查询细节。同时我们还可以在视图之上再嵌套视图。这样就好比我们在进行模块化编程一样,不仅结构清晰,还提升了代码的复用率。
- 另外,我们也需要了解到视图是虚拟表,本身不存储数据,如果想要通过视图对底层数据表的数据进行修改也会受到很多限制,通常我们是把视图用于查询,也就是对 SQL 查询的一种封装。那么它和临时表又有什么区别呢?在实际工作中,我们可能会见到各种临时数据。比如你可能会问,如果我在做一个电商的系统,中间会有个购物车的功能,需要临时统计购物车中的商品和金额,那该怎么办呢?这里就需要用到临时表了,临时表是真实存在的数据表,不过它不用于长期存放数据,只为当前连接存在,关闭连接后,临时表就会自动释放。
视图的作用:
- 视图隐藏了底层的表结构,简化了数据访问操作,客户端不再需要知道底层表的结构及其之间的关系。
- 视图提供了一个统一访问数据的接口。(即可以允许用户通过视图访问数据的安全机制,而不授予用户直接访问底层表的权限),从而加强了安全性,使用户只能看到视图所显示的数据。
- 视图还可以被嵌套,一个视图中可以嵌套另一个视图。
注意:视图总是显示最新的数据!每当用户查询视图时,数据库引擎通过使用视图的 SQL 语句重建数据。