中文自然语言处理入门实战
课程介绍
NLP 作为 AI 技术领域中重要的分支,随着其技术应用范围不断扩大,在数据处理领域占有越来越重要的地位。本达人课,作为中文自然语言处理边学边实战的入门级教程,以小数据量的“简易版”实例,通过实战带大家快速掌握 NLP 在中文方面开发的基本能力。
本课程共包含 22 篇。各篇之间并没有紧密耦合,但是整个内容还是遵循一定的开发流程。
比如,按照中文语料处理的过程,在获取到语料之后开始分词,分词之后可以进行一些统计和关键字提取,并通过数据可视化手段熟悉和了解你的数据。
紧接着通过词袋或者词向量,把文本数据转换成计算机可以计算的矩阵向量。后续从机器学习简单的有监督分类和无监督聚类入手,到深度学习中神经网络的应用,以及简易聊天机器人和知识图谱的构建。带你直观深入、高效地了解 NLP 开发的流程,全方位提升你的技术实力与思维方式。
课程示例数据下载地址:Github。
作者介绍
宿永杰,现就职于某知名互联网公司担任数据挖掘工程师,PC 端全栈开发工程师,擅长 Java 大数据开发 、Python、SQL 数据挖掘等,参与过客户画像、流量预测以及自然语言处理等项目的开发。
课程内容
开篇词:中文自然语言处理——未来数据领域的珠穆朗玛峰
人工智能或许是人类最美好的梦想之一。追溯到公元前仰望星空的古希腊人,当亚里士多德为了解释人类大脑的运行规律而提出了联想主义心理学的时候,他恐怕不会想到,两千多年后的今天,人们正在利用联想主义心理学衍化而来的人工神经网络,构建的超级人工智能成为最能接近梦想的圣境,并一次又一次地挑战人类大脑认知的极限。
在以大数据、云计算为背景的技术框架支撑下,互联网发展极为迅速,过去一个技术或者行业热点从诞生到消亡需要几年乃至更长的时间,但是最近几年,其生命周期在不断缩短,大多数的热点从产生到消亡只需要1-2年,有些仅仅是半年甚至几个月的时间。互联网行业越来越凸显出快鱼吃慢鱼的特点。从技术本身也有体现,比如2012-2014年是移动互联网的热潮,Android 和 iOS App 开发工程师当时非常流行。随后,2015大数据、云计算之年,2016年后大数据时代,2017年被称为人工智能元年,2018年炒得最火的是区块链和币圈。在互联网以这种迅雷不及掩耳之势的发展速度下,作为初学者就很容易被各种技术概念迷惑,找不到自己想要的突破口和深入的领域,即便是计算机从业者有时候也分不清到底如何定位自己未来的技术方向。
下面,我们先从中国互联网的发展历程说起。
从1994诞生(加入国际互联网)到现在才短短的24年,就在这24年里,我们经历了4次非同凡响、一次比一次更彻底的发展大高潮。
第一次互联网大浪潮(1994年—2000年),以四大门户和搜索为代表,能做网站的工程师就可以被称为技术牛人;第二次互联网大浪潮(2001年—2008年),从搜索到 PC 端社交化网络的发展,我们的社交形态发生了根本的变化,从线下交流正转变为线上交流,大量的数据开始生成;第三次互联网大浪潮(2009年—2014年)PC 端互联网到移动互联网,此时各种 App 如雨后春笋般的冒出来,尽管后来有很多 App 都死了,但是移动互联网几乎颠覆了整个中国老百姓个人生活和商业形态,改变着我们每一个人的生活、消费、社交、出行方式等。
那第四次是什么呢?没错,第四次互联网大浪潮(2015—至今),是在前3次发展基础上,以大数据、云计算为背景发展起来的人工智能技术革命,分布式计算让大数据处理提速,而昔日陨落的巨星深度学习此刻再次被唤醒,并很快在图像和语音方面取得重大突破,但在自然语言方面却显得有些暗淡,突破并不是很大。尽管有很多人都去从事计算机视觉、语音等方面的工作,但随着 AI 的继续发展,NLP 方向正显得越来越重要。
接着,我们总结一下数据领域成就和挑战。
有一个不可否认的事实,当前从事互联网的人们已经制造出了海量的数据,未来还将继续持续,其中包括结构化数据、半结构化和非结构化数据。我发现,对于结构化数据而言,在大数据、云计算技术“上下齐心”的大力整合下,其技术基本趋向成熟和稳定,比如关系型数据库以及基于 Hadoop 的 HDFS 分布式文件系统、Hive 数据仓库和非关系型数据库 Hbase,以及 Elasticsearch 集群等数据存储的关系数据库或者 NoSQL,可以用来管理和存储数据;基于 MapReduce、Spark 和 Storm、Flink 等大数据处理框架可以分别处理离线和实时数据等。而半结构化、非结构化的数据,除了以 ELK 为代表的日志处理流程,过去在其它限定领域基于规则和知识库也取得了一定的成果,因其自身的复杂性,未来更多领域应用都具有很大的困难和挑战。
最后,我们看看国内外人工智能领域的工业现状。
今年5月19日有幸在北京国家会议中心参加了2018全球人工智能技术大会(GAITC)。在大会上,从中国科学院院士姚期智提出人工智能的新思维开始,其重点讲述了人工神经网络为代表的深度学习以及量子计算机将是未来发展的新思维;紧接着中国工程院院士李德毅分享了路测的学问——无人驾驶的后图灵测试,提出未来无人驾驶挑战应该是让无人驾驶具有司机的认知、思维和情感,而不是当前以 GPS 定位和动力学解决无人驾驶的问题;接下来微软全球资深副总裁王永东向我们展示的微软小冰,大家一起见证了微软小冰在社交互动、唱歌、作诗、节目主持和情感方面不凡的表现,而本人也真实测试了一下,小冰现在的表现已经非常优秀了。然而要达到一个成年自然人的水平,在某些方面还不能完全表现出人的特性。下面这幅图是微软小冰的个人介绍,有兴趣可以在微信公众号关注小冰,进行体验。

人工智能产业的快速发展,资本市场大量资金涌入,促使中国人工智能领域投融资热度快速升温,这充分表明资本市场对于人工智能发展前景的认可。《2018年人工智能行业创新企业 Top100》发布,据榜单显示:进入2018年人工智能行业创新企业前十名的企业分别是:百度、阿里云、美图秀秀、华大基因、科大讯飞、微鲸科技、华云数据、爱驰亿维、青云、七牛云。作为人工智能的一个重要组成部分,自然语言处理(NLP)的研究对象是计算机和人类语言的交互,其任务是理解人类语言并将其转换为机器语言。在目前的商业场中,NLP 技术用于分析源自邮件、音频、文件、网页、论坛、社交媒体中的大量半结构化和非结构化数据,市场前景巨大。
为什么说未来数据领域的珠穆朗玛峰是中文自然语言处理?
正是基于上面对中国互联网发展的总结,对当前数据领域所面临的挑战以及资本市场对人工智能的认可分析,未来数据领域的重点是自然语言处理技术及其在智能问答、情感分析、语义理解、知识图谱等应用方面的突破。对于我们国内中文来说,如何更好的把前面所说的应用在中文处理上,显得更为重要和急迫,所以我认为未来数据领域的珠穆朗玛峰是中文自然语言处理 。
作为初学者,我们目前又面临这样的尴尬,网上大部分自然语言处理内容都是英文为基础,大多数人先是学好了英语的处理,回头来再处理中文,却发现有很大的不同,这样不仅让中文自然语言处理学习者走了弯路,也浪费了大量时间和精力。中文的处理比英文复杂的多,网上中文相关资料少之又少,国内纯中文自然语言处理书籍只有理论方面的,却在实战方面比较空缺,这让中文自然语言处理的研究开发工作感到举步维艰,很难下笔。
关于本达人课
本课程共包含19节(包括开篇词)。

各小节之间并没有紧密耦合,但是整个内容还是遵循一定的开发流程。比如,按照中文语料处理的过程,在获取到语料之后开始分词,分词之后可以进行一些统计和关键字提取,并通过数据可视化手段熟悉和了解你的数据。紧接着通过词袋或者词向量,把文本数据转换成计算机可以计算的矩阵向量。后续从机器学习简单的有监督分类和无监督聚类入手,到深度学习中神经网络的应用,以及简易聊天机器人和知识图谱的构建。带你直观深入、高效地了解 NLP 开发的流程,全方位提升你的技术实力与思维方式。
因此,本达人课,作为中文自然语言处理初学者边学边实战的入门级教程,希望从中文实际出发,针对中文语料以小数据量的“简易版”实例,通过实战带大家快速掌握 NLP 在中文方面开发的基本能力。当然作为读者, 我默认你已经掌握 Python 编程语言和有一定的机器学习理论知识,当然不会也没关系,可以边学边做,还是那句老话:“只要功夫深铁杵磨成针”。
点击了解更多《中文自然语言处理入门》
课程寄语
无论是初入 AI 行业的新人,还是想转行成为 AI 领域的技术工程师,都可以从本场达人课中,收获中文自然语言处理相关知识。因为篇幅原因,本课程无法包含 NLP 的所有知识以及比较前沿的知识,但是我会在讲好每节课的前提下,尽量分享一些比较前沿的知识来作为补充。
第01课:中文自然语言处理的完整机器处理流程
2016年全球瞩目的围棋大战中,人类以失败告终,更是激起了各种“机器超越、控制人类”的讨论,然而机器真的懂人类吗?机器能感受到人类的情绪吗?机器能理解人类的语言吗?如果能,那它又是如何做到呢?带着这样好奇心,本文将带领大家熟悉和回顾一个完整的自然语言处理过程,后续所有章节所有示例开发都将遵从这个处理过程。
首先我们通过一张图(来源:网络)来了解 NLP 所包含的技术知识点,这张图从分析对象和分析内容两个不同的维度来进行表达,个人觉得内容只能作为参考,对于整个 AI 背景下的自然语言处理来说还不够完整。

有机器学习相关经验的人都知道,中文自然语言处理的过程和机器学习过程大体一致,但又存在很多细节上的不同点,下面我们就来看看中文自然语言处理的基本过程有哪些呢?
获取语料
语料,即语言材料。语料是语言学研究的内容。语料是构成语料库的基本单元。所以,人们简单地用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的替代品。我们把一个文本集合称为语料库(Corpus),当有几个这样的文本集合的时候,我们称之为语料库集合(Corpora)。(定义来源:百度百科)按语料来源,我们将语料分为以下两种:
1.已有语料
很多业务部门、公司等组织随着业务发展都会积累有大量的纸质或者电子文本资料。那么,对于这些资料,在允许的条件下我们稍加整合,把纸质的文本全部电子化就可以作为我们的语料库。
2.网上下载、抓取语料
如果现在个人手里没有数据怎么办呢?这个时候,我们可以选择获取国内外标准开放数据集,比如国内的中文汉语有搜狗语料、人民日报语料。国外的因为大都是英文或者外文,这里暂时用不到。也可以选择通过爬虫自己去抓取一些数据,然后来进行后续内容。
语料预处理
这里重点介绍一下语料的预处理,在一个完整的中文自然语言处理工程应用中,语料预处理大概会占到整个50%-70%的工作量,所以开发人员大部分时间就在进行语料预处理。下面通过数据洗清、分词、词性标注、去停用词四个大的方面来完成语料的预处理工作。
1.语料清洗
数据清洗,顾名思义就是在语料中找到我们感兴趣的东西,把不感兴趣的、视为噪音的内容清洗删除,包括对于原始文本提取标题、摘要、正文等信息,对于爬取的网页内容,去除广告、标签、HTML、JS 等代码和注释等。常见的数据清洗方式有:人工去重、对齐、删除和标注等,或者规则提取内容、正则表达式匹配、根据词性和命名实体提取、编写脚本或者代码批处理等。
2.分词
中文语料数据为一批短文本或者长文本,比如:句子,文章摘要,段落或者整篇文章组成的一个集合。一般句子、段落之间的字、词语是连续的,有一定含义。而进行文本挖掘分析时,我们希望文本处理的最小单位粒度是词或者词语,所以这个时候就需要分词来将文本全部进行分词。
常见的分词算法有:基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词方法和基于规则的分词方法,每种方法下面对应许多具体的算法。
当前中文分词算法的主要难点有歧义识别和新词识别,比如:“羽毛球拍卖完了”,这个可以切分成“羽毛 球拍 卖 完 了”,也可切分成“羽毛球 拍卖 完 了”,如果不依赖上下文其他的句子,恐怕很难知道如何去理解。
3.词性标注
词性标注,就是给每个词或者词语打词类标签,如形容词、动词、名词等。这样做可以让文本在后面的处理中融入更多有用的语言信息。词性标注是一个经典的序列标注问题,不过对于有些中文自然语言处理来说,词性标注不是非必需的。比如,常见的文本分类就不用关心词性问题,但是类似情感分析、知识推理却是需要的,下图是常见的中文词性整理。

常见的词性标注方法可以分为基于规则和基于统计的方法。其中基于统计的方法,如基于最大熵的词性标注、基于统计最大概率输出词性和基于 HMM 的词性标注。
4.去停用词
停用词一般指对文本特征没有任何贡献作用的字词,比如标点符号、语气、人称等一些词。所以在一般性的文本处理中,分词之后,接下来一步就是去停用词。但是对于中文来说,去停用词操作不是一成不变的,停用词词典是根据具体场景来决定的,比如在情感分析中,语气词、感叹号是应该保留的,因为他们对表示语气程度、感情色彩有一定的贡献和意义。
特征工程
做完语料预处理之后,接下来需要考虑如何把分词之后的字和词语表示成计算机能够计算的类型。显然,如果要计算我们至少需要把中文分词的字符串转换成数字,确切的说应该是数学中的向量。有两种常用的表示模型分别是词袋模型和词向量。
词袋模型(Bag of Word, BOW),即不考虑词语原本在句子中的顺序,直接将每一个词语或者符号统一放置在一个集合(如 list),然后按照计数的方式对出现的次数进行统计。统计词频这只是最基本的方式,TF-IDF 是词袋模型的一个经典用法。
词向量是将字、词语转换成向量矩阵的计算模型。目前为止最常用的词表示方法是 One-hot,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。还有 Google 团队的 Word2Vec,其主要包含两个模型:跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words,简称 CBOW),以及两种高效训练的方法:负采样(Negative Sampling)和层序 Softmax(Hierarchical Softmax)。值得一提的是,Word2Vec 词向量可以较好地表达不同词之间的相似和类比关系。除此之外,还有一些词向量的表示方式,如 Doc2Vec、WordRank 和 FastText 等。
特征选择
同数据挖掘一样,在文本挖掘相关问题中,特征工程也是必不可少的。在一个实际问题中,构造好的特征向量,是要选择合适的、表达能力强的特征。文本特征一般都是词语,具有语义信息,使用特征选择能够找出一个特征子集,其仍然可以保留语义信息;但通过特征提取找到的特征子空间,将会丢失部分语义信息。所以特征选择是一个很有挑战的过程,更多的依赖于经验和专业知识,并且有很多现成的算法来进行特征的选择。目前,常见的特征选择方法主要有 DF、 MI、 IG、 CHI、WLLR、WFO 六种。
模型训练
在特征向量选择好之后,接下来要做的事情当然就是训练模型,对于不同的应用需求,我们使用不同的模型,传统的有监督和无监督等机器学习模型, 如 KNN、SVM、Naive Bayes、决策树、GBDT、K-means 等模型;深度学习模型比如 CNN、RNN、LSTM、 Seq2Seq、FastText、TextCNN 等。这些模型在后续的分类、聚类、神经序列、情感分析等示例中都会用到,这里不再赘述。下面是在模型训练时需要注意的几个点。
1.注意过拟合、欠拟合问题,不断提高模型的泛化能力。
过拟合:模型学习能力太强,以至于把噪声数据的特征也学习到了,导致模型泛化能力下降,在训练集上表现很好,但是在测试集上表现很差。
常见的解决方法有:
- 增大数据的训练量;
- 增加正则化项,如 L1 正则和 L2 正则;
- 特征选取不合理,人工筛选特征和使用特征选择算法;
- 采用 Dropout 方法等。
欠拟合:就是模型不能够很好地拟合数据,表现在模型过于简单。
常见的解决方法有:
- 添加其他特征项;
- 增加模型复杂度,比如神经网络加更多的层、线性模型通过添加多项式使模型泛化能力更强;
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
2.对于神经网络,注意梯度消失和梯度爆炸问题。
评价指标
训练好的模型,上线之前要对模型进行必要的评估,目的让模型对语料具备较好的泛化能力。具体有以下这些指标可以参考。
1.错误率、精度、准确率、精确度、召回率、F1 衡量。
错误率:是分类错误的样本数占样本总数的比例。对样例集 D,分类错误率计算公式如下:

精度:是分类正确的样本数占样本总数的比例。这里的分类正确的样本数指的不仅是正例分类正确的个数还有反例分类正确的个数。对样例集 D,精度计算公式如下:

对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(True Positive)、假正例(False Positive)、真反例(True Negative)、假反例(False Negative)四种情形,令 TP、FP、TN、FN 分别表示其对应的样例数,则显然有 TP+FP++TN+FN=样例总数。分类结果的“混淆矩阵”(Confusion Matrix)如下:

准确率,缩写表示用 P。准确率是针对我们预测结果而言的,它表示的是预测为正的样例中有多少是真正的正样例。定义公式如下:

精确度,缩写表示用 A。精确度则是分类正确的样本数占样本总数的比例。Accuracy 反应了分类器对整个样本的判定能力(即能将正的判定为正的,负的判定为负的)。定义公式如下:

召回率,缩写表示用 R。召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。定义公式如下:
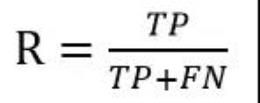
F1 衡量,表达出对查准率/查全率的不同偏好。定义公式如下:
![]()
2.ROC 曲线、AUC 曲线。
ROC 全称是“受试者工作特征”(Receiver Operating Characteristic)曲线。我们根据模型的预测结果,把阈值从0变到最大,即刚开始是把每个样本作为正例进行预测,随着阈值的增大,学习器预测正样例数越来越少,直到最后没有一个样本是正样例。在这一过程中,每次计算出两个重要量的值,分别以它们为横、纵坐标作图,就得到了 ROC 曲线。
ROC 曲线的纵轴是“真正例率”(True Positive Rate, 简称 TPR),横轴是“假正例率”(False Positive Rate,简称FPR),两者分别定义为:


ROC 曲线的意义有以下几点:
- ROC 曲线能很容易的查出任意阈值对模型的泛化性能影响;
- 有助于选择最佳的阈值;
- 可以对不同的模型比较性能,在同一坐标中,靠近左上角的 ROC 曲所代表的学习器准确性最高。
如果两条 ROC 曲线没有相交,我们可以根据哪条曲线最靠近左上角哪条曲线代表的学习器性能就最好。但是实际任务中,情况很复杂,若两个模型的 ROC 曲线发生交叉,则难以一般性的断言两者孰优孰劣。此时如果一定要进行比较,则比较合理的判断依据是比较 ROC 曲线下的面积,即AUC(Area Under ROC Curve)。
AUC 就是 ROC 曲线下的面积,衡量学习器优劣的一种性能指标。AUC 是衡量二分类模型优劣的一种评价指标,表示预测的正例排在负例前面的概率。
前面我们所讲的都是针对二分类问题,那么如果实际需要在多分类问题中用 ROC 曲线的话,一般性的转化为多个“一对多”的问题。即把其中一个当作正例,其余当作负例来看待,画出多个 ROC 曲线。
模型上线应用
模型线上应用,目前主流的应用方式就是提供服务或者将模型持久化。
第一就是线下训练模型,然后将模型做线上部署,发布成接口服务以供业务系统使用。
第二种就是在线训练,在线训练完成之后把模型 pickle 持久化,然后在线服务接口模板通过读取 pickle 而改变接口服务。
模型重构(非必须)
随着时间和变化,可能需要对模型做一定的重构,包括根据业务不同侧重点对上面提到的一至七步骤也进行调整,重新训练模型进行上线。
参考文献
- 周志华《机器学习》
- 李航《统计学习方法》
- 伊恩·古德费洛《深度学习》
点击了解更多《中文自然语言处理入门》
第02课:简单好用的中文分词利器 jieba 和 HanLP
前言
从本文开始,我们就要真正进入实战部分。首先,我们按照中文自然语言处理流程的第一步获取语料,然后重点进行中文分词的学习。中文分词有很多种,常见的比如有中科院计算所 NLPIR、哈工大 LTP、清华大学 THULAC 、斯坦福分词器、Hanlp 分词器、jieba 分词、IKAnalyzer 等。这里针对 jieba 和 HanLP 分别介绍不同场景下的中文分词应用。
jieba 分词
jieba 安装
(1)Python 2.x 下 jieba 的三种安装方式,如下:
全自动安装:执行命令
easy_install jieba或者pip install jieba/pip3 install jieba,可实现全自动安装。半自动安装:先下载 jieba,解压后运行
python setup.py install。手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录。
安装完通过 import jieba 验证安装成功与否。
(2)Python 3.x 下的安装方式。
Github 上 jieba 的 Python3.x 版本的路径是:https://github.com/fxsjy/jieba/tree/jieba3k。
通过 git clone https://github.com/fxsjy/jieba.git 命令下载到本地,然后解压,再通过命令行进入解压目录,执行 python setup.py install 命令,即可安装成功。
jieba 的分词算法
主要有以下三种:
- 基于统计词典,构造前缀词典,基于前缀词典对句子进行切分,得到所有切分可能,根据切分位置,构造一个有向无环图(DAG);
- 基于DAG图,采用动态规划计算最大概率路径(最有可能的分词结果),根据最大概率路径分词;
- 对于新词(词库中没有的词),采用有汉字成词能力的 HMM 模型进行切分。
jieba 分词
下面我们进行 jieba 分词练习,第一步首先引入 jieba 和语料:
import jieba content = "现如今,机器学习和深度学习带动人工智能飞速的发展,并在图片处理、语音识别领域取得巨大成功。"(1)精确分词
精确分词:精确模式试图将句子最精确地切开,精确分词也是默认分词。
segs_1 = jieba.cut(content, cut_all=False)print("/".join(segs_1))其结果为:
现如今/,/机器/学习/和/深度/学习/带动/人工智能/飞速/的/发展/,/并/在/图片/处理/、/语音/识别/领域/取得/巨大成功/。
(2)全模式
全模式分词:把句子中所有的可能是词语的都扫描出来,速度非常快,但不能解决歧义。
segs_3 = jieba.cut(content, cut_all=True) print("/".join(segs_3))结果为:
现如今/如今///机器/学习/和/深度/学习/带动/动人/人工/人工智能/智能/飞速/的/发展///并/在/图片/处理///语音/识别/领域/取得/巨大/巨大成功/大成/成功//
(3)搜索引擎模式
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
segs_4 = jieba.cut_for_search(content) print("/".join(segs_4))结果为:
如今/现如今/,/机器/学习/和/深度/学习/带动/人工/智能/人工智能/飞速/的/发展/,/并/在/图片/处理/、/语音/识别/领域/取得/巨大/大成/成功/巨大成功/。
(4)用 lcut 生成 list
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 Generator,可以使用 for 循环来获得分词后得到的每一个词语(Unicode)。jieba.lcut 对 cut 的结果做了封装,l 代表 list,即返回的结果是一个 list 集合。同样的,用 jieba.lcut_for_search 也直接返回 list 集合。
segs_5 = jieba.lcut(content) print(segs_5)结果为:
['现如今', ',', '机器', '学习', '和', '深度', '学习', '带动', '人工智能', '飞速', '的', '发展', ',', '并', '在', '图片', '处理', '、', '语音', '识别', '领域', '取得', '巨大成功', '。']
(5)获取词性
jieba 可以很方便地获取中文词性,通过 jieba.posseg 模块实现词性标注。
import jieba.posseg as psg print([(x.word,x.flag) for x in psg.lcut(content)])结果为:
[('现如今', 't'), (',', 'x'), ('机器', 'n'), ('学习', 'v'), ('和', 'c'), ('深度', 'ns'), ('学习', 'v'), ('带动', 'v'), ('人工智能', 'n'), ('飞速', 'n'), ('的', 'uj'), ('发展', 'vn'), (',', 'x'), ('并', 'c'), ('在', 'p'), ('图片', 'n'), ('处理', 'v'), ('、', 'x'), ('语音', 'n'), ('识别', 'v'), ('领域', 'n'), ('取得', 'v'), ('巨大成功', 'nr'), ('。', 'x')]
(6)并行分词
并行分词原理为文本按行分隔后,分配到多个 Python 进程并行分词,最后归并结果。
用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数 。jieba.disable_parallel() # 关闭并行分词模式 。注意: 并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。目前暂不支持 Windows。
(7)获取分词结果中词列表的 top n
from collections import Counter top5= Counter(segs_5).most_common(5) print(top5)结果为:
[(',', 2), ('学习', 2), ('现如今', 1), ('机器', 1), ('和', 1)]
(8)自定义添加词和字典
默认情况下,使用默认分词,是识别不出这句话中的“铁甲网”这个新词,这里使用用户字典提高分词准确性。
txt = "铁甲网是中国最大的工程机械交易平台。" print(jieba.lcut(txt))结果为:
['铁甲', '网是', '中国', '最大', '的', '工程机械', '交易平台', '。']
如果添加一个词到字典,看结果就不一样了。
jieba.add_word("铁甲网") print(jieba.lcut(txt))结果为:
['铁甲网', '是', '中国', '最大', '的', '工程机械', '交易平台', '。']
但是,如果要添加很多个词,一个个添加效率就不够高了,这时候可以定义一个文件,然后通过 load_userdict()函数,加载自定义词典,如下:
jieba.load_userdict('user_dict.txt') print(jieba.lcut(txt))结果为:
['铁甲网', '是', '中国', '最大', '的', '工程机械', '交易平台', '。']
注意事项:
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型。
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。
HanLP 分词
pyhanlp 安装
其为 HanLP 的 Python 接口,支持自动下载与升级 HanLP,兼容 Python2、Python3。
安装命令为 pip install pyhanlp,使用命令 hanlp 来验证安装。
pyhanlp 目前使用 jpype1 这个 Python 包来调用 HanLP,如果遇到:
building '_jpype' extensionerror: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft VisualC++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
则推荐利用轻量级的 Miniconda 来下载编译好的 jpype1。
conda install -c conda-forge jpype1 pip install pyhanlp未安装 Java 时会报错:
jpype.jvmfinder.JVMNotFoundException: No JVM shared library file (jvm.dll) found. Try setting up the JAVAHOME environment variable properly.
HanLP 主项目采用 Java 开发,所以需要 Java 运行环境,请安装 JDK。
命令行交互式分词模式
在命令行界面,使用命令 hanlp segment 进入交互分词模式,输入一个句子并回车,HanLP 会输出分词结果:

可见,pyhanlp 分词结果是带有词性的。
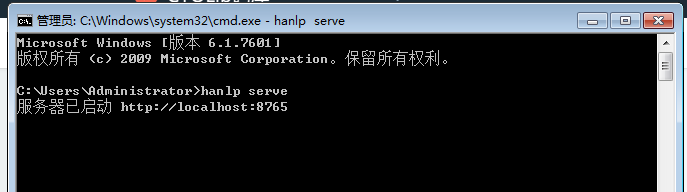
服务器模式
通过 hanlp serve 来启动内置的 HTTP 服务器,默认本地访问地址为:http://localhost:8765 。

也可以访问官网演示页面:http://hanlp.hankcs.com/。
通过工具类 HanLP 调用常用接口
通过工具类 HanLP 调用常用接口,这种方式应该是我们在项目中最常用的方式。
(1)分词
from pyhanlp import * content = "现如今,机器学习和深度学习带动人工智能飞速的发展,并在图片处理、语音识别领域取得巨大成功。" print(HanLP.segment(content))结果为:
[现如今/t, ,/w, 机器学习/gi, 和/cc, 深度/n, 学习/v, 带动/v, 人工智能/n, 飞速/d, 的/ude1, 发展/vn, ,/w, 并/cc, 在/p, 图片/n, 处理/vn, 、/w, 语音/n, 识别/vn, 领域/n, 取得/v, 巨大/a, 成功/a, 。/w]
(2)自定义词典分词
在没有使用自定义字典时的分词。
txt = "铁甲网是中国最大的工程机械交易平台。" print(HanLP.segment(txt))结果为:
[铁甲/n, 网/n, 是/vshi, 中国/ns, 最大/gm, 的/ude1, 工程/n, 机械/n, 交易/vn, 平台/n, 。/w]
添加自定义新词:
CustomDictionary.add("铁甲网") CustomDictionary.insert("工程机械", "nz 1024") CustomDictionary.add("交易平台", "nz 1024 n 1") print(HanLP.segment(txt))结果为:
[铁甲网/nz, 是/vshi, 中国/ns, 最大/gm, 的/ude1, 工程机械/nz, 交易平台/nz, 。/w]
当然了,jieba 和 pyhanlp 能做的事还有很多,关键词提取、自动摘要、依存句法分析、情感分析等,后面章节我们将会讲到,这里不再赘述。
参考文献:
- https://github.com/fxsjy/jieba
- https://github.com/hankcs/pyhanlp
点击了解更多《中文自然语言处理入门》
第03课:动手实战中文文本中的关键字提取
第04课:了解数据必备的文本可视化技巧
第05课:面向非结构化数据转换的词袋和词向量模型
第06课:动手实战基于 ML 的中文短文本分类
第07课:动手实战基于 ML 的中文短文本聚类
第08课:从自然语言处理角度看 HMM 和 CRF
第09课:一网打尽神经序列模型之 RNN 及其变种 LSTM、GRU
第10课:动手实战基于 CNN 的电影推荐系统
第11课:动手实战基于 LSTM 轻松生成各种古诗
第12课:完全基于情感词典的文本情感分析
第13课:动手制作自己的简易聊天机器人
第14课:动手实战中文命名实体提取
第15课:基于 CRF 的中文命名实体识别模型实现
第16课:动手实战中文句法依存分析
第17课:基于 CRF 的中文句法依存分析模型实现
第18课:模型部署上线的几种服务发布方式
第19课:知识挖掘与知识图谱概述
第20课:Neo4j 从入门到构建一个简单知识图谱
第21课:中文自然语言处理的应用、现状和未来
Chat:NLP 中文短文本分类项目实践(上)
NLP 中文短文本分类项目实践(下)
阅读全文: http://gitbook.cn/gitchat/column/5b10b073aafe4e5a7516708b