Web框架简介
Web开发是Python语言应用领域的重要部分,也是目前最主要的Web开发语言之一,在其二十多年的历史中出现了数十种Web框架,比如Django、Tornado、Flask、Twisted、Bottle和Web.py等,有的历史悠久,有的发展迅速,还有的已经停止维护.
Django:

发布于2003年,是当前Python世界里最负盛名且最成熟的Web框架,最初被用来制作在线新闻的Web站点,Django的各模板之间结合得比较紧密,所以在功能强大的同时又是一个相对封闭的系统(依然可以自定义的),但是其健全的在线文档和开发社区,使开发者遇到问题能找到解决办法.
Tornado:

一个强大的、支持协程、高效并发且可扩展的Web服务器,发布于2009年9月,应用于FriendFeed、Facebook等社交网站。它的强项在于可以利用异步协程机制实现高并发的服务。
Flask:

Python Web框架家族里比较年轻的一个,发布于2010年,它吸收了其他框架的优点并且把自己的主要领域定义在了微小项目上,以短小精干,简洁明了著称。
Twisted:

一个有着十多年历史的开源事件驱动框架。它不像前三种着眼于Web应用开发,而是适用从传输层到自定义应用协议的所有类型的网络程序的开发,并能在不同的操作系统上提供很高的运行效率。但是,目前对Python3的支持有限,建议使用Python2.7。
MVC和MTV框架
MVC
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示
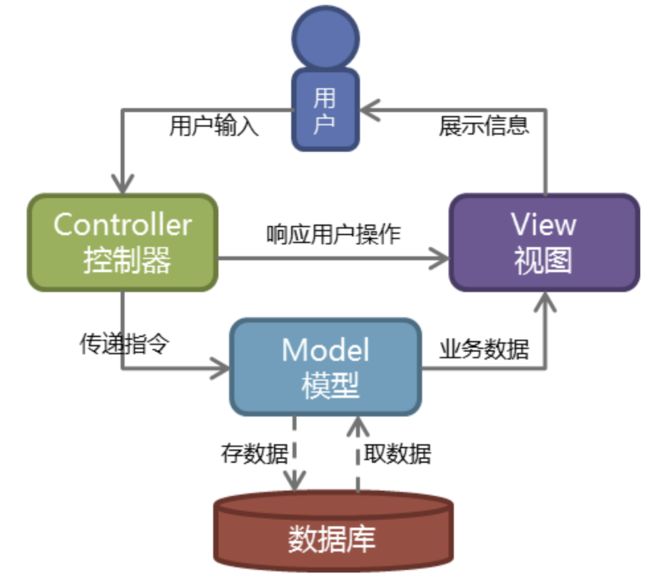
MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
# M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
# T 代表模板 (Template):负责如何把页面展示给用户(html)。
# V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示:
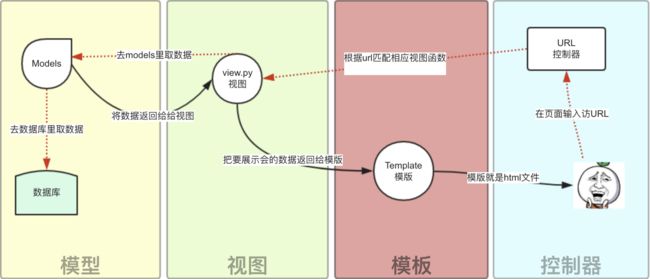
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
选择框架的原则
- 选择更主流的框架。因为它们的文档更齐全,技术积累更多,社区更繁盛,能得到更好的帮助和支持。
- 选择更活跃的框架。关注项目在GitHub等环境中的更新频率、Issue和Pull Request的响应情况。如果一个项目长期没有更新,或者有一堆的问题需要解决但是没有得到响应,就不应该是你学习的对象。
- 选择能够满足需求的框架。没有最好的框架,只有更合适的框架。你所选择的Web框架不仅需要满足当前的需求,还要充分考虑项目发展一段时间后的情况,即前瞻性,避免盲目选择而导致将来推倒重来的情况。
- 选择时效性好的框架。在学习和使用框架的时候经常需要查阅和参考各种网络上的文章、博客和教程,但是需要注意他们的发表时间。有些框架的相关文章已经很老了,很久没更新了,应该放弃这种框架;有的框架一直以来都有不断的新文章、新博客出现,就是比较不错的选择。
- 选择入门友好的框架。这条只对新手适用。详细的框架文档、官方教程对新手来说都是极大的帮助和鼓励.
为什么选择Django?
首先介绍一下Django,Django具有以下特点:
- 功能完善、要素齐全:该有的、可以没有的都有,自带大量常用工具和框架,无须你自定义、组合、增删及修改。
- 完善的文档:经过十多年的发展和完善,Django有广泛的实践案例和完善的在线文档。开发者遇到问题时可以搜索在线文档寻求解决方案。
- 强大的数据库访问组件:Django的Model层自带数据库ORM组件,使得开发者无须学习其他数据库访问技术(SQL、pymysql、SQLALchemy等)。
- 灵活的URL映射:Django使用正则表达式管理URL映射,灵活性高。新版的2.0,进一步提高了URL编写的优雅性。
- 丰富的Template模板语言:类似jinjia模板语言,不但原生功能丰富,还可以自定义模板标签,并且与其ORM的用法非常相似。
- 自带后台管理系统admin:只需要通过简单的几行配置和代码就可以实现一个完整的后台数据管理控制平台。
- 完整的错误信息提示:在开发调试过程中如果出现运行错误或者异常,Django可以提供非常完整的错误信息帮助定位问题。
根据前面的选择原则我们逐条对比一下:
# 1. 主流、活跃程序:
# 从GitHub的数据来看,Django的开发非常活跃,迭代速度也非常快
# 2. 是否可以满足需求:
# Django以要素齐全、工具丰富、框架庞大著称,基本上别的框架有的他有,别的框架没有的他也有,
# 如果Django满足不了需求,那么别的框架同时也一样.
# 3. 时效性:
# Django有很长的开发喝实践过程,或早或晚的文档、教程、帮助、博客等等非常多,资料更新速度也很快.
# 4. 入门友好程度
# 一个框架能否流行起来,对新手入门友好非常关键.Django在这一点做的非常好.
Django的不足
Django也有一些缺点:
框架庞大,被认为不够精简,捆绑的内容太多
首先,对于新手,Django集成好的工具和部件,让你无须再费脑力去学习如何安装、调试、集成、兼容别的工具,Django帮你都集成好了,而且保证兼容性,可用性和方便性,就好比联想一体机,开机即用,效率也高,而一些如flask的框架,虽然精简,但是你要自己安装各种工具、ORM、插件等等,好比DIY电脑,在用之前,要知道买什么配件,怎么搭配,怎么组装,怎么配置效率才高,将新手的热情消耗在非关键性的内容上.
其次,对于老手,Django也是开放的,你完全可以关闭不必要的功能,忽略不使用的组件,或者自定义希望的组件,包括ORM和Template在内,都可以自由选择.在异步通信方面略有欠缺
从本质上来讲,Tornado在异步协程机制实现高并发的服务上要强一些,Django在这方面有追赶的目标,但这不是说Django就差到不能用了.
基于Python进行Web开发的技术栈
想要熟练地使用Django进行Web开发,设计生产环境可用的,能够应付一定规模访问量的Web应用,开发者要学会的远远不止Django本身,Python基础、环境搭建、前端语言、API设计、网站架构、系统管理、持续集成、服务化数据处理、并发处理等等,都是相关的只是领域,包括但不限于以下的内容:
# 熟悉Python语言
# 对前端的HTML\CSS\JavaScript比较熟悉
# 对网络基础,比如HTTP、TCP/IP等比较熟悉
# 熟悉数据库、缓存、消息队列等技术的使用场景和使用方法
# 日常能使用Linux或Mac系统工作(Windows标配)
# 有性能优化经验,能快速定位问题
# 除此之外,还要对业务有深刻理解,能够写出可维护性足够高的代码,当然,以上都是对经验丰富的开发者而言,
# 对于新手刚入门者,我们朝着这个目标努力学习就好
# 下面是基于Python的Web开发技术栈
# 1、web应用
# 运行在浏览器上的应用
# 2、c/s b/s 架构
# client/server:客户端服务器架构,C++
# brower/server:浏览器服务器架构,Java、Python
# 底层均是基于socket
# 3、Python Web框架
# a.socket b.页面路由 c.模板渲染
# Django a用的wsgiref b自己写的 c自己写的 功能全面
# Flask a用的第三方 b自己写的 c自己写的 小而轻
# Tornado a自己写的 b自己写的 c自己写的 支持高并发

Django简介
Django是什么?
Django 是一个高级的 Python 网络框架,可以快速开发安全和可维护的网站。由经验丰富的开发者构建,Django负责处理网站开发中麻烦的部分,因此你可以专注于编写应用程序,而无需重新开发。
它是免费和开源的,有活跃繁荣的社区,丰富的文档,以及很多免费和付费的解决方案。
Django可以使你的应用具有以下优点
完备性
Django遵循“功能完备”的理念,提供开发人员可能想要“开箱即用”的几乎所有功能。因为你需要的一切都是一个”产品“的一部分,它们都可以无缝结合在一起,遵循一致性设计原则,并且具有广泛和最新的文档
通用性
Django 可以(并已经)用于构建几乎任何类型的网站—从内容管理系统和维基,到社交网络和新闻网站。它可以与任何客户端框架一起工作,并且可以提供几乎任何格式(包括 HTML,Rss源,JSON,XML等)的内容。你正在阅读的网站就是基于Django。
在内部,尽管它为几乎所有可能需要的功能(例如几个流行的数据库,模版引擎等)提供了选择,但是如果需要,它也可以扩展到使用其他组件。
安全性
Django 帮助开发人员通过提供一个被设计为“做正确的事情”来自动保护网站的框架来避免许多常见的安全错误。例如,Django提供了一种安全的方式来管理用户账户和密码,避免了常见的错误,比如将session放在cookie中这种易受攻击的做法(取而代之的是cookies只包含一个密钥,实际数据存储在数据库中)或直接存储密码而不是密码哈希。
密码哈希是通过密码散列函数发送密码而创建的固定长度值。 Django 能通过运行哈希函数来检查输入的密码-就是-将输出的哈希值与存储的哈希值进行比较是否正确。然而由于功能的“单向”性质,即使存储的哈希值受到威胁,攻击者也难以解决原始密码。(但其实有彩虹表-译者观点)
默认情况下,Django可以防范许多漏洞,包括SQL注入,跨站点脚本,跨站点请求伪造和点击劫持
可扩展
Django使用基于组件的"无共享"架构(架构的每一部分独立于其他架构,因此可以根据需要进行替换或更改)在不用部分之间有明确的分隔意味着它可以通过任何级别添加硬件来扩展服务: 缓存服务器,数据库服务器或应用程序服务器,一些最繁忙的网站已经成功地缩放了Django,以满足他们的需求(例如Instagram和Disqus,仅举两个例子,可自行添加)
可维护性
Django代码编写时遵照设计原则和模式,鼓励创建可维护和重复使用的代码,特别是他用了不要重复自己(DRY)原则,所以没有不必要的重复,减少了代码的数量.Django还将相关功能分组到可重用的"应用程序"中,并且在较低程序级别将相关代码分组
灵活性
Django使用Python编写的,他在许多平台上运行,意味着你不受任务特定的服务器平台的限制,并且可以在许多种类的Linux,Windows和Mac OsX上运行应用程序,此外,Django得到许多网络托管商的好评,他们经常提供特定的基础设施和托管Django网站的文档.
Django的出生
Django最初由2003年到2005年间由负责创建和维护报纸网站的网络团队开发。在创建了许多网站后,团队开始考虑并重用许多常见的代码和设计模式。这个共同的代码演变一个通用的网络开发框架,2005年7月被开源“Django”项目。
Django不断发展壮大——从2008年9月的第一个里程碑版本(1.0)到最近发布的(1.11)-(2017)版本。每个版本都添加了新功能和错误修复,从支持新类型的数据库,模版引擎和缓存,到添加“通用”视图函数和类(这减少了开发人员必须编写的代码量)一些编程任务。
Django有多欢迎
服务器端框架的受欢迎程度没有任何可靠和明确的测量(尽管Hot Frameworks网站 尝试使用诸如计算每个平台的GitHub项目数量和StackOverflow问题的机制来评估流行度)。一个更好的问题是Django是否“足够流行”,以避免不受欢迎的平台的问题。它是否继续发展?如果您需要帮助,可以帮您吗?如果您学习Django,有机会获得付费工作吗?
基于使用Django的流行网站数量,为代码库贡献的人数以及提供免费和付费支持的人数,那么是的,Django是一个流行的框架
使用Django的流行网站包括:Disqus,Instagram,骑士基金会,麦克阿瑟基金会,Mozilla,国家地理,开放知识基金会,Pinterest和开放栈.
Django是特定?
Web框架通常将自己称为"特定" 或"无限制".
特定框架是对处理任何特定任务的"正确方法" 有意见的框架,他们经常支持特定领域的快速发展(解决特定类型的问题),因为正确的做法是通常被很好的理解和记录在案,然而,他们在解决其主要领域之外的问题可能不那么灵活,并且倾向于为可以使用那些组件和方法提供较少的选择.
相比之下,无限制的框架对于将组件粘合在一起以实现目标或甚至应使用那些组件的最佳方式限制较少,它们使开发人员更容易使用最合适的工具来完成特定任务,尽管您需要自己查找这些组件。
Django“有点有意义”,因此提供了“两个世界的最佳”。它提供了一组组件来处理大多数Web开发任务和一个(或两个)首选的使用方法。然而,Django的解耦架构意味着您通常可以从多个不同的选项中进行选择,也可以根据需要添加对全新的支持
原生Socket服务
demo1
-- index.html
-- server.py
基础socket服务
import socket
# 利用socket建立服务器对象
server = socket.socket()
# 设置ip和端口
server.bind(('127.0.0.1', 8001))
# 设置监听
server.listen(5)
print('服务器设置成功')
print('浏览器访问:http://127.0.0.1:8001')
while True:
# 阻塞等待客户端数据
client, address = server.accept()
# 接收数据
data = client.recv(1024)
print('接收到数据: ', data)
# 返回数据
client.send(b'Normal Socket Web')
# 关闭连接(必须关闭每一次连接)
client.close()
浏览器错误:发送的响应无效,原因:响应不满足http协议
# 请求发来的数据
b'GET / HTTP/1.1\r\n
Host: 127.0.0.1:8001\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
Cookie: csrftoken=szfYLDVuqvRhlveNpNE2rp1GYOcI5x7mRNfvkRWTMRNRwWxXMZWOhL1MqknYJ7jg; sessionid=3pphvmw2icub0bea7nn02u6wev17k4uw\r\n
\r\n'
http协议
什么是http协议
# HTTP(HyperText Transport Protocol)是超文本传输协议
# 基于TCP/IP协议基础上的应用层协议,底层实现仍为socket
# 基于请求-响应模式:通信一定是从客户端开始,服务器端接收到客户端一定会做出对应响应
# 无状态:协议不对任何一次通信状态和任何数据做保存
# 无连接:一次连接只完成一次请求-响应,请求-响应完毕后会立即断开连接
http工作原理(事务)
# 一次http操作称之为一个事务,工作过程可分为四步
# 1.客户端与服务端建立连接
# 2.客户端发生一个http协议指定格式的请求
# 3.服务器端接收请求后,响应一个http协议指定格式的响应
# 4.客户端将服务器的响应显示展现给用户
请求报文
POST / HTTP/1.1\r\n
Host: 127.0.0.1:8001\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
\r\n
usr=abc&pwd=123
响应报文
# 响应行 响应头 响应体
HTTP/1.1 200 OK\r\n
Content-type:text/html\r\n
\r\n
Login Success
修改返回数据,完善响应体
# 字符串
client.send(b'HTTP/1.1 200 OK\r\n')
client.send(b'\r\n')
client.send(b'Normal Socket Web')
# html代码,请求头要设置支持html代码
client.send(b'HTTP/1.1 200 OK\r\n')
client.send(b'Content-type:text/html\r\n')
client.send(b'\r\n')
client.send(b'Normal Socket Web
')
# html文件(同级目录建立一个index.html页面)
client.send(b'HTTP/1.1 200 OK\r\n')
client.send(b'Content-type:text/html\r\n')
client.send(b'\r\n')
# 利用文件方式读取页面
with open('index.html', 'rb') as f:
dt = f.read()
client.send(dt)
修改接受数据,模拟后台路由
# 分析接收到的数据
data = client.recv(1024)
# 保证接收到的数据作为字符串进行以下处理
data = str(data, encoding='utf-8')
# 拆分出地址位
route = data.split('\r\n')[0].split(' ')[1]
# 匹配地址,做出不同的响应
if route == '/index':
with open('index.html', 'rb') as f:
dt = f.read()
elif route == '/login': # 新建login页面
with open('login.html', 'rb') as f:
dt = f.read()
else:
dt = b'404'
client.send(dt)
状态码
# 1打头:消息通知
# 2打头:请求成功
# 3打头:重定向
# 4打头:客户端错误
# 5打头:服务器端错误
框架演变
目录结构
part2
-- favicon.ico
-- index.html
-- manage.py=
manage.py
import socket
import pymysql
# 响应头
RESP_HEADER = b'HTTP/1.1 200 OK\r\nContent-type:text/html\r\n\r\n'
# 请求处理
def index():
# 以字节方式读取文件
with open('index.html', 'rb') as f:
dt = f.read()
return dt
def ico():
with open(favicon.jpeg, 'rb') as f:
dt = f.read()
return dt
def user():
# 数据库操作
conn = pymysql.connect(host='127.0.0.1', port=3306, db='django', user='root', password='root')
cur = conn.cursor(pymysql.cursors.DictCursor)
cur.execute('select * from user')
users = cur.fetchall()
print(users)
users = '''%d:%s
%d:%s''' % (users[0]['id'], users[0]['name'], users[1]['id'], users[1]['name'])
return users.encode('utf-8')
# 设置路由
urls = {
# 请求路径与请求处理函数一一对应
'/index': index,
favicon.jpeg: ico,
'/user': user
}
# 设置socket
def serve(host, port):
server = socket.socket()
server.bind((host, port))
print('start:http://' + host + ':' + str(port))
server.listen(5)
while True:
sock, addr = server.accept()
data = sock.recv(1024)
data = str(data, encoding='utf-8')
print(data)
route = data.split('\r\n')[0].split(' ')[1]
resp = b'404'
if route in urls:
resp = urls[route]()
sock.send(RESP_HEADER)
sock.send(resp)
sock.close()
# 启服务
if __name__ == '__main__':
serve('127.0.0.1', 8002)
项目演变
目录结构
03_proj
-- template
-- index.html
-- user.html
favicon.ico
start.py
urls.py
views.py
index.html
{{ name }}
user.html
id
name
password
{% for user in users%}
{{user.id}}
{{user.name}}
{{user.password}}
{% endfor %}
start.py
from wsgiref.simple_server import make_server
from urls import urls
def app(env, response):
print(env)
# 设置响应头
response("200 OK", [('Content-type', 'text/html')])
route = env['PATH_INFO']
print(route)
data = urls['error']()
if route in urls:
data = urls[route]()
# 返回二进制响应体
return [data]
if __name__ == '__main__':
server = make_server('127.0.0.1', 8003, app)
print('start:http://127.0.0.1:8003')
server.serve_forever()
urls.py
from views import *
urls = {
'/index': index,
'/favicon.ico': ico,
'/user': user,
'error': error
}
views.py
import pymysql
# 利用jinja2来渲染模板,将后台数据传给前台
from jinja2 import Template
def index():
with open('templates/index.html', 'r') as f:
dt = f.read()
tem = Template(dt)
resp = tem.render(name='主页')
return resp.encode('utf-8')
def ico():
with open('favicon.ico', 'rb') as f:
dt = f.read()
return dt
def user():
# 数据库操作
conn = pymysql.connect(host='127.0.0.1', port=3306, db='django', user='root', password='root')
cur = conn.cursor(pymysql.cursors.DictCursor)
cur.execute('select * from user')
users = cur.fetchall()
print(users)
with open('templates/user.html', 'r') as f:
dt = f.read()
tem = Template(dt)
resp = tem.render(users=users)
return resp.encode('utf-8')
def error():
return b'404'
Django代码是什么样的?
在传统的数据驱动网站中,Web应用程序会等待来自Web浏览器(或其他客户端)的HTTP请求,当接收到请求时,应用程序根据URL和可能的Post数据或GET数据中的信息确定需要的内容,根据需要,可以从数据库读取或写入信息,或执行满足需求所需的其他任务,然后,该应用程序将返回对Web浏览器的响应,通常将检索到的数据插入HTML模板中的占位符来动态创建用于浏览器显示的HTML页面.
Django网络应用程序通常将处理每个步骤的代码分组到单独的文件中.
URLs: 虽然可以通过单个功能来吹每个URL的请求,但是编写单独的视图函数来处理每个资源是更加可维护的.URL映射器用于根据URL将HTTP请求重定向到相应的视图,URL映射器还可以匹配出现在URL中的字符串或数字的特写模式,并将其作为数据传递给视图功能.
View: 视图是一个请求处理函数,他接受HTTP请求并返回HTTP响应,视图通过模型访问满足请求所需的数据,并将响应的格式委托给模板.
Models: 模型是定义应用程序数据结构的Python对象,并提供在数据库中管理(添加,修改,删除)和查询记录的机制.
Templates: 模板是定义文件(例如HTML页面)的结构或布局的文本文件,用于表示实际内容的占位符,一个视图可以使用HTML模板,从数据填充他动态地创建一个HTML页面模型,可以使用模板来定义任何类型的文件的结构: 不一定是HTML.
此种组织被Django称为"模型视图模板(MVT)"架构,他与更加熟悉的Model View Controller架构有许多相似之处.
1.将请求发送到正确的视图(urls.py)
URL映射器通常存储在名为urls.py的文件中,在下面示例中,mapper(urlpatterns)定义了特定URL模式和相应视图函数之间的映射列表,如果接收到具有与指定模式匹配的URL(例如 r'&$',下面)的HTTP请求,则将调用相关联的视图功能(例如views.index)并传递请求.
urlpatterns = [
url(r'^$', views.index),
url(r'^([0-9]+)/$', views.best),
]
# 注意:
# 该urlpatterns对象的列表url()功能,在Python中,使用方括号定义列表,项目以逗号分隔,
# 并可能有一个可选的逗号,例如:[item1,item2,item3,].
# 该模式的奇怪的语法称为正则表达式
# 第二个参数url()是当模式匹配时,将被调用的另一个函数,符号views.index表示该函数被调用,
# index()并且可以在被调用的模块中找到views(即在一个名为views.py的文件中.)
2.处理请求(views.py)
视图是web应用程序的核心,从web客户端接收HTTP请求并返回HTTP响应,在两者之间,他们编制框架的其他资源来访问数据库,渲染模板等.
下面例子显示了一个最小的视图功能index(),这可以通过我们的URL映射器在上一节调用.
像所有视图函数一样,他接受一个HttpRequest对象作为参数(request)并返回一个HttpResponse对象,在这种情况下,我们对请求不做任何事情,我们的响应只是返回一个硬编码的字符串,我们会向您显示一个请求.
## filename:views.py(Django视图函数)
从django.http导入HttpResponse
def index(request):
#Get HttpRequest-request参数
#使用请求中的信息执行操作。
#Return HttpResponse
return HttpResponse('你好,Django!')
# 注意:
# Python模块是函数的'库',存储在单独的文件中,我们可能想在我们的代码块中使用他们,
# 在这里我们只从django.http模块导入了HttpResponse对象,使我们可以在视图中使用它:
# from django.http import HttpResponse
# 还有其他方法可以从模块导入一些或所有对象.
# 如上所示,使用def关键字声明函数,在函数名称后面的括号列出命名参数: 整行以冒号结尾,
# 注意下一行是否都进行了缩进,缩进很重要,因为他指定代码行在该特定块内(强制缩进是Python的一个关键特征),
# 也是Python代码很容易阅读的一个原因).
# 视图通常存储在一个名为views.py的文件中
3.定义数据模型(models.py)
Django Web应用程序通过被称为模型的Python对象来管理和查询数据,模型定义存储数据的结构,包括字段类型以及字段可能的最大值,默认值,选择列表选项,文档帮助文本,表单的标签文本等,模型的定义与底层数据库无关,你可以选择其中一个作为项目设置的一部分,一旦你选择了要使用的数据库,你就不需要直接与之交谈,只需编写模型结构和其他代码,Django可以处理与数据库通信的所有辛苦的工作.
下面的代码片段为Team对象展示了一个非常简单的Django模型,本Team类是从Django的类派生models.Model,他将团队名称和团队级别定义为字符字段,并为每个记录指定了要存储的最大字符数,team_level可以是几个值中的一个,因此,我们将其定义为一个选择片段,并在被展示的数据和被存储的数据之间建立映射,并设置一个默认值.
# filename: models.py
from django.db import models
class Team(models.Model):
team_name = models.CharField(max_length=40)
TEAM_LEVELS = (
('U09', 'Under 09s'),
('U10', 'Under 10s'),
('U11', 'Under 11s'),
... #list other team levels
)
team_level = models.CharField(max_length=3,choices=TEAM_LEVELS,default='U11')
# 注意:
# Python支持'面向对象编程',这是一种编程风格,我们将代码组织到对象中,
# 其中包括用于对该对象进行操作的相关数据和功能,对象也可以从其他对象继承/扩展/派生,
# 允许相关对象之间的共同行为被共享,在Python中,我们使用关键字Class定义对象的‘蓝图’,
# 我们可以根据类中的模型创建类型的多个特定实例.
# 例如,我们有个Team类,它来自于Model类,这意味着他是一个模型,并且将包含模型的所有方法,
# 但是我们也可以给他自己的专门功能,在我们的模型中,我们定义了数据库需要存储我们的数据字段,
# 给出他们的具体名称,Django使用这些定义(包括字段名称)来创建底层数据库.
4.查询数据(views.py)
Django模型提供了一个而用于搜索数据库的简单查询API,这可以使用不同的标准(例如,精确,不区分大小写,大于等等)来匹配多个字段,并且可以支持复杂语句(例如,您可以在拥有一个团队的U11团队上指定搜索名称为以'Fr'开头或以'al'结尾).
代码片段显示了一个视图函数(资源处理程序),用于显示我们所有的U09团队,粗体显示如何使用模型查询API过滤所有记录,其中该team_level字段具有正确的文本'U09'(请注意,该条件如何filter()作为参数传递给该函数,该字段名称和匹配类型由双下划线: team_level_exact)
## filename: views.py
from django.shortcuts import render
from .models import Team
def index(request):
list_teams = Team.objects.filter(team_level__exact="U09")
context = {'youngest_teams': list_teams}
return render(request, '/best/index.html', context)
此功能使用render()功能创建HttpResponse发送回浏览器的功能,这个函数是一个快捷方式: 他通过组合指定的HTML模板和一些数据来插入模板(在名为'context'的变量中提供)来创建一个HTML文件.
5.呈现数据(HTML模板)
模板系统允许你指定输出文档的结构,使用占位符{% if youngest_teams%}来生成页面填写的数据,模板通常用于创建HTML,但也可以创建其他类型的文档,Django支持其原生模板系统和另一种流行的Python库(称为jinja2)开箱即用(如果需要,也可以支持其他系统).
代码片段显示render()了上一节函数调用的HTML模板的外观,这个模板已经被写入这样的想法,即他将被访问一个列表变量,youngest_teams当他被渲染时:
## filename: best/templates/best/index.html
{% if youngest_teams %}
{% for team in youngest_teams %}
- {{ team.team_name }}
{% endfor %}
{% else %}
No teams are available.
{% endif %}
前面部分显示了几乎每个Web应用程序将使用的主要功能: URL映射,视图,模型和模板.
Django提供的其他内容呢包括:
# 表单: HTML表单用于收集用户数据以便在服务器上进行处理,Django简化了表单创建,验证和处理.
# 用户身份验证和权限: Django包含了一个强大的用户身份验证和权限系统,该系统已经构建了安全性.
# 缓存: 与提供静态内容相比,动态创建内容需要更大的计算强度(也更缓慢),DJango提供灵活的缓存,
# 以便你可以存储所有或部分的页面,如无必要,不会重新呈现网页.
# 管理网站: 当你使用基本骨架创建应用时,就已经默认包含了一个Django管理站点,它十分轻松创建了一个管理页面,
# 使网站管理员能够创建、编辑和查看站点中的任何数据模型.
# 序列化数据: Django可以轻松的将数据序列化,并支持XML或JSON格式,
# 这会有助于创建一个Web服务(Web服务指数据纯粹为其他应用程序或站点所用,
# 并不会在自己的站点中显示),或是有助于创建一个由客户端代码处理和呈现所有数据的网站
6. MVC和MTV
Example1
tree mvc_demo/
mvc_demo/
├── Controller
│ ├── account.py
│ └── __pycache__
│ └── account.cpython-36.pyc
├── Model
├── Socket_Demo11.py
└── View
└── index.html
Controller/account.py
cat mvc_demo/Controller/account.py
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
# 2020/1/17 10:38
def handle_index():
import time
v = str(time.time())
f = open('View/index.html',mode='rb')
data=f.read()
f.close()
data = data.replace(b'@u',v.encode('utf-8'))
return [data,]
def handle_date():
return ['Hello,Date!
'.encode('utf-8'), ]
View/index.html
cat mvc_demo/View/index.html
Title
INDEX @u
Socket_Demo1.py
cat mvc_demo/Socket_Demo11.py
from wsgiref.simple_server import make_server
from Controller import account
URL_DICT = {
"/index": account.handle_index,
"/date": account.handle_date,
}
def RunServer(environ, start_response):
# environ 封装了客户端发来的所有数据
# start_response 封装要返回用户的数据,响应头、状态码
start_response('200 OK', [('Content-Type', 'text/html')])
current_url = environ['PATH_INFO']
func = None
if current_url in URL_DICT:
func = URL_DICT[current_url]
if func:
return func()
else:
return ['404
'.encode('utf-8')]
if __name__ == '__main__':
httpd = make_server('', 8001, RunServer)
print("Serving HTTP on port 8000...")
httpd.serve_forever()
访问测试
cd mvc_demo/
python3 Socket_Demo11.py
Serving HTTP on port 8000...
127.0.0.1 - - [17/Jan/2020 11:13:10] "GET /index HTTP/1.1" 200 161
curl localhost:8001/index
Title
INDEX 1579230790.0229425
# MVC
# Model View Controller
# 数据库 模板文件 业务处理
# MTV
# Model Template View
# 数据库 模板文件 业务处理
Django生命周期
# 用户请求 ----> URL对应关系(匹配) ----> 视图函数 ----> 返回用户字符串
# 用户请求 ----->URL对应关系(匹配) ----> 视图函数 ----> 打开一个HTML文件,读取内容
# 1.浏览器发送请求
# 2.wsgi服务器接收到请求,将请求解析交给Django
# 3.Django中间件过滤请求信息,交给路由匹配,如果匹配成功
# 4.路由完成业务逻辑的分发,到指定app下views中指定的视图函数,可以去数据库里面取数据,
# 5.视图函数完成具体的业务逻辑,和模板渲染,返回字符串响应结果
# 6.将处理结果通过服务器返回给浏览器
Django简单部署操作
CMD: Django安装与项目的创建
# 安装:pip3 install django==2.2
# 查看版本号:django-admin --version
# 新建项目:1.前往目标目录 2.django-admin startproject proj_name
# 项目目录,包含项目最基本的一些配置
# 项目名:
|--项目同名文件夹
|---- __init__.py 模块的配置文件
|---- settings.py 配置总文件
|---- urls.py url配置文件,主路由
|---- wsgi.py (web server gateway interface),
# 服务器网关接口,python应用与web服务器直接通信的接口
# templates:模板文件夹,存放html文件的(页面),支持使用Django模板语言(DTL),也可以使用第三方(jinja2)
# manage.py:项目管理器,与项目交互的命令行工具集的入口,查看支持的所有命令python3 manage.py
如果是windows电脑会发现pythonx.exe的目录下多了一个django_admin.exe
我们可以cd到那个目录,使用下面命令创建第一个django项目.
django-admin.exe startproject mysite
然后我们可以使用下面命令将此项目运行起来
python.exe C:\Users\You-Men\AppData\Local\Programs\Python\Python37-32\Scripts\mysite\manage.py runserver浏览器访问上面提示信息的地址就会出现下面页面了.
如果觉得使用django-admin工具麻烦可以加入环境变量.
将django-admin那个目录加入到系统环境变量的PATH里面,注意用;分号隔开.
app应用的创建
1.Django是面向应用开发,在应用中完成具体的业务逻辑
2.什么是应用app: 就好比项目中的一个功能模块,一个项目可以拥有多个功能模块,但至少得有一个,Django称之为app
3.如何创建app(在项目目录下):python3 manage.py startapp app01
migrations:数据迁移(移植)模块,内容都是由Django自动生成
# __init__.py
# admin.py:应用的后台管理系统配置
# apps.py:django 1.9后,本应用的相关配置
# models.py:数据模型模块,使用ORM框架,类似于MVC模式下的Model层
# tests.py:自动化测试模块,可以写自动化测试脚本
# views.py:执行相应的逻辑代码模块
Django目录介绍
django-admin startproject mysite
tree mysite/
mysite/
├── manage.py
└── mysite
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
# 各文件和目录解释:
# 外层的mysite/目录与Django无关,只是你项目的容器,可以任意重命名,[工程名称]
# manage.py: 一个命令行工具,用于与Django进行不同方式的交互脚本,非常重要
# 内部的mysite/目录是真正的项目文件包裹目录,他的名字是你引用内部文件的包名,例如: mysite.urls.
# mysite/__init__.py: 一个定义包的空文件
# mysite/setting.py: 项目的主配置文件,非常重要.
# mysite/urls.py: 路有文件,所有的任务都是从这里开始分配,相当于Django驱动站点的内容表格,非常重要.
# mysite/wsgi.py: 一个基于WSGI的web服务器进入点,提供底层的网络通信功能,通常不用关心,
# 但是上线时候不要使用wsgi,使用uwsgi,通常再配合nginx。
python3 manage.py startapp cmdb
tree cmdb/
cmdb/
├── admin.py
├── apps.py
├── __init__.py
├── migrations
│ └── __init__.py
├── models.py
├── tests.py
└── views.py
# app
# migrations: 数据修改表结构
# admin: Django为我们提供的后台管理
# apps: 配置当前app
# models: ORM写指定的类,通过命令创建数据库结构
# test: 单元测试
# views: 业务逻辑代码
Django初始化配置
配置数据库
# 安装pymysql
sudo wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate
sudo python get-pip.py
sudo pip install pymysql
sudo pip3 install pymysql
# 数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'youmen_db',
'USER':'root',
'PASSWORD':'ZHOUjian.20',
'HOST':'116.196.83.113',
'PORT':'3306',
}
}
静态文件
# 新建一个与templates同级文件夹,配置文件添加
STATICFILES_DIRS=os.path.join(BASE_DIR,'static'),
# 静态文件检索的文件夹
# 语言和时区
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai' #
USE_I18N = True #internationalization 国际化 支持多语言
USE_L10N = True #本地化,比如农历
USE_TZ = True
#修改: 配置文件:
ALLOWED_HOSTS = ['*'] #允许所有访问
ALLOWED_HOSTS = ['192,168,0.114','127.0.0.1'] #列表为了防止黑客入侵,只允许列表中的ip地址访问
#表示此Django站点可以投放的主机/域名的字符串列表。这是防止HTTP主机头部攻击的安全措施
# (如果需要调用js,css文件可以配置一下settings.py,html文件就可以调用static里面的css,js文件了)
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'),
)
启动项目
# 终端: python3 manage.py runserver 127.0.0.1:8801
python manage.py runserver # 启动
python manage.py runserver 0.0.0.0:8080 #启动改变端口号和外部访问:
python manage.py makemigrations # 生成迁移文件
python manage.py migrate # 执行迁移,存到数据库
django-admin startapp xxx # 新建一个app
Django后台管理(admin)界面
uls.py
from django.contrib import admin
from django.urls import path
urlpatterns = [
url('admin/',admin.site.urls),
]
app/models.py
from django.db import models
# Create your models here.
class UserType(models.Model):
name = models.CharField(max_length=32)
class UserInfo(models.Model):
username=models.CharField(max_length=32)
pwd=models.CharField(max_length=32)
email=models.CharField(max_length=32)
user_type=models.ForeignKey(UserType,on_delete=models.CASCADE)
admin.py
from django.contrib import admin
# Register your models here.
from cmdb import models
admin.site.register(models.UserInfo)
项目运行起来,访问IP:PORT/admin即可访问登录页面,但是需要先创建一个超级用户
# 先将之前models.py文件的表创建出来**
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser
Username (leave blank to use 'you-men'): youmen
Email address: [email protected]
Password:
Password (again):
Django示例之登录页面
定义路由规则
url.py
"login" --> 函数名
# Example
from django.conf.urls import url
from django.contrib import admin
from cmdb import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login',views.login),
url(r'^home',views.home)
]
定义视图函数
# app下views.py
# 获取用户请求的发来数据
# def func(request):
# request.method GET / POST
# http://127.0.0.1:8000/home?pid=123&name=nginx
# request.GET.get('',None) # 获取用户请求发来的数据
# request.POST.get('',None)
# request.FILES.get('files') # 此处files对应
# checkbox等多选内容(值)
# request.POST.getlist()
# GET获取数据 POST: 提交数据
# 返回用户数据
# return HttpResponse('字符串')
# return render(request,"HTTP模板的路径")
# return redirect('url路径') # return redirect('/login') # 此处/代指前面的地址.
# Example
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import redirect
# Create your views here.
from django.shortcuts import HttpResponse
def login(request):
# 包含用户提交的所有信息
# 获取用户提交方法
# print(request.method)
error_msg = ""
if request.method == "POST":
# 用户通过POST提交过来的数据通过request.GET.get('',None)获取
user = request.POST.get('user',None)
pwd = request.POST.get('pwd',None)
if user == 'root' and pwd == '123':
# 去跳转到
return redirect(home);
else:
error_msg = "用户名或密码错误"
# 用户密码不匹配
return render(request,'login.html',{'error_msg':error_msg})
USER_LIST = [
{'username':'alex','email': 'Tom','gender':'男'},
{'username':'alex','email': 'Tom','gender':'男'},
{'username':'alex','email': 'Tom','gender':'男'},
]
# for index in range(20):
# temp = {'username':'alex' + str(index) ,'email': 'Tom','gender':'男'}
# USER_LIST.append(temp)
def home(request):
if request.method == "POST":
# 获取用户提交的数据 POST请求中
u = request.POST.get('username')
e = request.POST.get('email')
g = request.POST.get('gender')
temp = {'username':u, "email":e,'gender':g}
USER_LIST.append(temp)
return render(request,'home.html',{'user_list': USER_LIST})
# def home(request):
模板渲染
特殊的模板语言
分别对应前面view.py当中的变量
home.html
Title
{% for row in user_list %}
{{ row.username }}
{{ row.email }}
{{ row.gender }}
{% endfor %}
login.html
Title
Django示例之注册页面
registerd功能页面
views.py
from django.shortcuts import render,HttpResponse,redirect
import os
# Create your views here.
def index(request):
return HttpResponse('index')
error_masg = ""
def registered(request):
if request.method == "GET":
print(request.method)
return render(request,'registered.html')
elif request.method == "POST":
obj = request.FILES.get('files')
print(obj,type(obj),obj.name)
file_path = os.path.join('upload',obj.name)
f = open(file_path,mode='wb')
for i in obj.chunks():
f.write(i)
f.close()
return render(request,'registered.html')
# 文件上传功能需要在from标签注明enctype="multipart/form-data"
registerd.html
Title
URL路由系统
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表。你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
基本格式
from django.conf.urls import url
#循环urlpatterns,找到对应的函数执行,匹配上一个路径就找到对应的函数执行,就不再往下循环了,并给函数传一个参数request,和wsgiref的environ类似,就是请求信息的所有内容
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
# 参数说明
# 正则表达式: 一个正则表达式字符串
# views视图函数: 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
# 参数: 可选的要传递给视图函数的默认参数(字典形式)
# 别名: 一个可选的name参数
注意
from django.urls import path
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles//', views.year_archive),
path('articles///', views.month_archive),
path('articles////', views.article_detail),
]
无名分组
场景设置
假如我们做了图书管理系统,图书管理系统是这样设置的,首页给我们展示满世界排名靠前面的书,当你想看那一年的书,你的url就应该拼接上哪一年,并且将此年份传递给后端逻辑,也就是对应的views函数中。比如你的首页为127.0.0.1:8000/book/,当你想看2003年有哪些书时,你访问的url就对应为127.0.0.1:8000/book/2003/,这也是前后端间接传递数据,那么这种需求如何完成呢?我们先写一个views函数,与对应的html。
URL配置
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^index/', views.login),
# 无名分组 (给应用视图函数传递位置参数)
url(r'books/(\d{4})/', views.year_books), # 完全匹配
url(r'^books/(\d{4})/(\d{2})/', views.year_mouth_books),
url(r'^books/(\d{4})/(\d{2})/(\d{2})', views.year_mouth_day_books),
]
我为什么不写2003?而写\d{4}? 你直接写2003就相当于写死了,如果用户想看2004、2005、2006....等,你要写一堆的url吗,是不是在articles后面写一个正则表达式/d{4}/就行啦。
但是此时你写的还是有问题的,我之前说过,你此时写的url路由匹配是模糊匹配,你如果是这样写的url,当从浏览器输入127.0.0.1:8000/book/2003/12/08它还是映射到year_books这个函数的,因为url遵循轮询机制:
所以针对上面的情况,我们应该将这些URL设定为完全匹配
注意事项
# 1. urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续。
# 2. 若要从URL中捕获一个值,只需要在它周围放置一对圆括号(分组匹配)。
# 3. 不需要添加一个前导的反斜杠(也就是写在正则最前面的那个/),因为每个URL 都有。例如,应该是^books而不是 ^/books。
# 4. 每个正则表达式前面的'r' 是可选的但是建议加上。
# 5. ^books& 以什么结尾,以什么开头,严格限制路径。
# 是否开启URL访问地址后面没有/跳转至带有/的路径的配置项
APPEND_SLASH=True
Django settings.py配置文件中默认没有 APPEND_SLASH 这个参数,但 Django 默认这个参数为 APPEND_SLASH = True。 其作用就是自动在网址结尾加'/'。其效果就是:我们定义了urls.py:
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^blog/$', views.blog),
]
# 访问 http://www.example.com/blog 时,默认将网址自动转换为 http://www.example/com/blog/ 。
# 如果在settings.py中设置了 APPEND_SLASH=False,此时我们再请求 http://www.example.com/blog 时就会提示找不到页面。
# 注意:无名分组传递给views函数的为位置参数。
有名分组
上面的示例使用简单的正则表达式分组匹配(通过圆括号)来捕获URL中的值并以位置参数形式传递给视图。
在更高级的用法中,可以使用分组命名匹配的正则表达式组来捕获URL中的值并以关键字参数形式传递给视图。
在Python的正则表达式中,分组命名正则表达式组的语法是
(?P,其中pattern) name是组的名称,pattern是要匹配的模式。
URL配置
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^articles/(?P[0-9]{4})/$', views.year_archive),
#某年的,(?P[0-9]{4})这是命名参数(正则命名匹配还记得吗?),
# 那么函数year_archive(request,year),形参名称必须是year这个名字。
# 而且注意如果你这个正则后面没有写$符号,即便是输入了月份路径,也会被它拦截下拉,因为它的正则也能匹配上
url(r'^articles/(?P[0-9]{4})/(?P[0-9]{2})/$', views.month_archive),
#某年某月的
url(r'^articles/(?P[0-9]{4})/(?P[0-9]{2})/(?P[0-9]{2})/$', views.article_detail),
# 某年某月某日的
]
# 这个实现与前面的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给视图函数
Views配置
def year_article(request, year=2000):
print(year)
return HttpResponse(f'出版年限:{year}')
def year_mouth_article(request, year, mouth):
print(year, mouth)
return HttpResponse(f'出版年限:{year},出版月份:{mouth}')
def year_mouth_day_article(request, year, mouth, day):
print(year, mouth, day)
return HttpResponse(f'出版年限:{year},出版月份:{mouth},出版天数:{day}')
注意: 命名分组是url设置的组名对应views函数的参数,这是关键字参数,也可以对应views函数的默认值参数。
在实际应用中,使用分组命名匹配的方式可以让你的URLconf 更加明晰且不容易产生参数顺序问题的错误,但是有些开发人员则认为分组命名组语法太丑陋、繁琐。
至于究竟应该使用哪一种,你可以根据自己的喜好来决定。
URLconf匹配的位置
URLconf 在请求的URL 上查找,将它当做一个普通的Python 字符串。不包括GET和POST参数以及域名。
例如,http://www.example.com/myapp/ 请求中,URLconf 将查找myapp/。
在http://www.example.com/myapp/?page=3 请求中,URLconf 仍将查找
myapp/。URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的
POST、GET、HEAD等等 —— 都将路由到相同的函数.
捕获的参数永远是字符串
每个在URLconf中捕获的参数都作为一个普通的Python字符串传递给视图,无论正则表达式使用的是什么匹配方式。例如,下面这行URLconf 中:
url(r'^articles/(?P[0-9]{4})/$', views.year_archive),
传递到视图函数views.year_archive()中的year参数永远是一个字符串类型
视图函数中指定默认值
# urls.py中
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^blog/$', views.page),
url(r'^blog/page(?P[0-9]+)/$', views.page),
]
# views.py中,可以为num指定默认值
def page(request, num="1"):
pass
在上面的例子中,两个URL模式指向相同的view - views.page - 但是第一个模式并没有从URL中捕获任何东西。
如果第一个模式匹配上了,page()函数将使用其默认参数num=“1”,如果第二个模式匹配,page()将使用正则表达式捕获到的num值。
URL分发
创建项目urls.py
from django.conf.urls import url,include
from app01 import views
urlpatterns = [
# 首页
url(r'^$',views.base),
url('^app01/',include('app01.urls')),
]
aap01应用的urls.py
from django.conf.urls import url
from app01 import views
urlpatterns = [
url('^login/',views.login),
]
app01应用的views.py
from django.shortcuts import render
from django.shortcuts import redirect
def login(request):
return render(request,'login1.html')
def base(request):
return render(request,'base.html')
传递额外参数到视图函数
URLconfs 具有一个钩子,让你传递一个Python 字典作为额外的参数传递给视图函数。
django.conf.urls.url()函数可以接收一个可选的第三个参数,它是一个字典,表示想要传递给视图函数的额外关键字参数。
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^blog/(?P[0-9]{4})/$', views.year_archive, {'foo': 'bar'}),
# 注意,这就像一个命名分组一样,你的函数里面的必须有一个形参,形参必须叫做foo才行,如果是命名分组的url,那么foo参数写在函数的哪个位置都行,如果不是命名分组,那么都是将这个形参写在参数的最后。
]
Views视图函数
一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应。
响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片。
无论视图本身包含什么逻辑,都要返回响应。代码写在哪里也无所谓,只要它在你当前项目目录下面。除此之外没有更多的要求了——可以说“没有什么神奇的地方”。为了将代码放在某处,大家约定成俗将视图放置在项目(project)或应用程序(app)目录中的名为
views.py的文件中。
一个简单的视图
下面是一个以HTML文档的形式返回当前日期和时间的视图
from django.http import HttpResponse
import datetime
def current_datetime(request):
now = datetime.datetime.now()
html = "It is now %s." % now
return HttpResponse(html)
首先,我们从django.http模块引入了HttpResponse类,以及Python的datetime库.
接着,我们定义了current_datetime函数,他就是视图函数,每个视图函数都使用HttpRequest对象作为第一个参数,并且通常称之为request.
注意,视图函数的名称并不重要,不需要用一个统一的命名方式来命名,以便让Django识别它,我们将其命名为current_datetime,是因为这个名称能够比较准确地反映出他实现的功能.
这个视图会返回一个HttpResponse对象,其中包含生成的响应,每个视图函数都负责返回一个HttpResponse对象
DJango使用功能请求和响应对象来通过系统传递状态.
当浏览器向服务端请求一个页面时,Django创建一个HttpRequest对象,该对象包含关于请求的元数据,然后, Django加载相应的视图,将这个HttpRequest对象作为第一个参数传递给视图函数.
每个视图负责返回一个HttpResponse对象
请求对象
简单过程
当一个页面被请求时,Django就会创建一个包含本次请求源信息(请求报文中的请求行,首部信息,内容主体等)
请求相关的常用值
# path_info 返回用户访问url,不包括域名
# method 请求中使用的HTTP方法的字符串表示,全大写表示
# GET 包含所有HTTP GET参数的类字典对象
# POST 包含所有HTTP POST参数的类字典对象
# body 请求体,byte类型 request.POST的数据就是从body里面提取到的
上传文件示例
def upload(request):
"""
保存上传文件前,数据需要存放在某个位置。默认当上传文件小于2.5M时,django会将上传文件的全部内容读进内存。从内存读取一次,写磁盘一次。
但当上传文件很大时,django会把上传文件写到临时文件中,然后存放到系统临时文件夹中。
:param request:
:return:
"""
if request.method == "POST":
# 从请求的FILES中获取上传文件的文件名,file为页面上type=files类型input的name属性值
filename = request.FILES["file"].name
# 在项目目录下新建一个文件
with open(filename, "wb") as f:
# 从上传的文件对象中一点一点读
for chunk in request.FILES["file"].chunks():
# 写入本地文件
f.write(chunk)
return HttpResponse("上传OK")
方法
1.HttpRequest.get_host()
根据从HTTP_X_FORWARDED_HOST(如果打开 USE_X_FORWARDED_HOST,默认为False)和 HTTP_HOST 头部信息返回请求的原始主机。
如果这两个头部没有提供相应的值,则使用SERVER_NAME 和SERVER_PORT,在PEP 3333 中有详细描述。
USE_X_FORWARDED_HOST:一个布尔值,用于指定是否优先使用 X-Forwarded-Host 首部,仅在代理设置了该首部的情况下,才可以被使用。
例如:"127.0.0.1:8000"
注意:当主机位于多个代理后面时,get_host() 方法将会失败。除非使用中间件重写代理的首部。
2.HttpRequest.get_full_path()
返回 path,如果可以将加上查询字符串。
例如:"/music/bands/the_beatles/?print=true"
3.HttpRequest.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None)
返回签名过的Cookie 对应的值,如果签名不再合法则返回django.core.signing.BadSignature。
如果提供 default 参数,将不会引发异常并返回 default 的值。
可选参数salt 可以用来对安全密钥强力攻击提供额外的保护。max_age 参数用于检查Cookie 对应的时间戳以确保Cookie 的时间不会超过max_age 秒。
>>> request.get_signed_cookie('name')
'Tony'
>>> request.get_signed_cookie('name', salt='name-salt')
'Tony' # 假设在设置cookie的时候使用的是相同的salt
>>> request.get_signed_cookie('non-existing-cookie')
...
KeyError: 'non-existing-cookie' # 没有相应的键时触发异常
>>> request.get_signed_cookie('non-existing-cookie', False)
False
>>> request.get_signed_cookie('cookie-that-was-tampered-with')
...
BadSignature: ...
>>> request.get_signed_cookie('name', max_age=60)
...
SignatureExpired: Signature age 1677.3839159 > 60 seconds
>>> request.get_signed_cookie('name', False, max_age=60)
False
4.HttpRequest.is_secure()
如果请求时是安全的,则返回True;即请求通是过 HTTPS 发起的。
5.HttpRequest.is_ajax()
如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串'XMLHttpRequest'。
大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。
如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware,
你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。
Example1
from django.shortcuts import render,HttpResponse,redirect
# Create your views here.
def index(request):
print(request.method) #请求方式
print(request.path) #请求路径,不带参数的
print(request.POST) #post请求数据 字典格式
print(request.GET) #get的请求数据 字典格式
print(request.META) #请求头信息,将来用到哪个咱们再说哪个
print(request.get_full_path()) #获取请求路径带参数的,/index/?a=1
print(request.is_ajax()) #判断是不是ajax发送的请求,True和False
'''
Django一定最后会响应一个HttpResponse的示例对象
三种形式:
HttpResponse('字符串') 最简单
render(页面) 最重要
2.1 两个功能
-- 读取文件字符串
-- 嵌入变量(模板渲染) html里面:{{ name }} , {'name':'太白'}作为render的第三个参数,想写多个变量{'name':'太白','hobby':['篮球','羽毛球']....}
redirect() 重定向 最难理解,某个网站搬家了,网址变了,访问原来的网址就重定向到一个新网址,就叫做重定向,网站自己做的重定向,你访问还是访问的你之前的,
你自己啥也不用做,浏览器发送请求,然后服务端响应,然后服务端告诉浏览器,你直接跳转到另外一个网址上,那么浏览器又自动发送了另外一个请求,发送到服务端,
服务端返回一个页面,包含两次请求,登陆成功后跳转到网站的首页,网站首页的网址和你login登陆页面的网址是不用的。
'''
return render(request,'index.html',{'name':'太白'})
# return HttpResponse('ok')
响应对象HttpResponse
与Django自动创建的HttpRequest对象相比,HttpResponse对象使我们的职责范围了,我们写的每个视图都需要实例化,填充和返回一个HttpResponse.
HttpResponse类位于django.http模块中
简单实用
传递字符串
from django.http import HttpResponse
response = HttpResponse("Here's the text of the Web page.")
response = HttpResponse("Text only, please.", content_type="text/plain")
设置或删除响应头信息
response = HttpResponse()
response['Content-Type'] = 'text/html; charset=UTF-8'
del response['Content-Type']
# 属性
# HttpResponse.content; 响应内容
# HttpResponse.charset; 响应内容的编码
# HttpResponse.status_code; 响应的状态码
具体响应方法
响应对象主要有三种形式
HttpResponse()
render()
redirect()
HttpResponse
HttpResponse()括号内直接跟一个具体的字符串作为响应体,比较直接很简单,一般使用后面两种形式.
render
结合一个给定的模板和一个指定的上下文字典,并返回一个渲染后的HttpResponse对象
from django.shortcuts import render
def my_view(request):
# 视图的代码写在这里
return render(request, 'myapp/index.html', {'foo': 'bar'})
# 上面的代码等同于
from django.http import HttpResponse
from django.template import loader
def my_view(request):
# 视图代码写在这里
t = loader.get_template('myapp/index.html')
c = {'foo': 'bar'}
return HttpResponse(t.render(c, request))
redirect
比如登录成功之后,跳转到别的页面,这不是你操作的而是后台帮你操作的,为的是用户体验。还有一种情况:web网站每一段时间代码就需要更新,但是有时候更新不了了,就需要重新写一个页面,这样就会自动给你跳转到新的url上,老得网站不会维护了,还有你经常访问的网址由于某种不可描述的原因有危险了,这是需要我们重定向新的网址 哈哈
那么为什么不给他新的?原来的老用户只是知道你的老网站。当然这只是一些情况,其实redirect具体用法还有很多,他的参数可以是:
# 1. 一个模型:将调用模型的get_absolute_url() 函数
# 2.一个视图,可以带有参数:将使用urlresolvers.reverse 来反向解析名称
# 3.一个绝对的或相对的URL,将原封不动的作为重定向的位置。
# 默认返回一个临时的重定向;传递permanent=True 可以返回一个永久的重定向。
我们可以用多种方式使用redirect()函数
1.传递一个具体的ORM对象
# 将调用ORM对象的get_absolute_url()方法来获取重定向的URL;
from django.shortcuts import redirect
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object)
2. 传递一个视图的名称
# views 示例
def my_view(request):
...
return redirect('home')
def home(request):
return HttpResponse('跳转成功!')
# urls示例:
urlpatterns = [
url(r'home/', views.home, name='home'), # 起别名,这样以后无论url如何变化,访问home直接可以映射到home函数
]
3.传递要重定向到的一个具体的网址
def my_view(request):
...
return redirect('/index')
4. 当然也可以是一个完整的网址
def my_view(request):
...
return redirect('http://example.com/')
重定向状态码
# 301和302的区别。
# 301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取
# (用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。
# 他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;
# 302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301
# 重定向原因:
#(1)网站调整(如改变网页目录结构);
#(2)网页被移到一个新地址;
#(3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
# 这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的
# 网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
# 简单来说就是:
# 响应状态码:301,为临时重定向,旧地址的资源仍然可以访问。
# 响应状态码:302,为永久重定向,旧地址的资源已经被永久移除了,这个资源不可访问了。
# 对普通用户来说是没什么区别的,它主要面向的是搜索引擎的机器人。
# A页面临时重定向到B页面,那搜索引擎收录的就是A页面。
# A页面永久重定向到B页面,那搜索引擎收录的就是B页面。
Django的CBV和FBV
FBV(function base views) 就是在视图里使用函数处理请求。之前都是FBV模式写的代码,所以就不写例子了。
CBV(class base views) 就是在视图里使用类处理请求。
Python是一个面向对象的编程语言,如果只用函数来开发,有很多面向对象的优点就错失了(继承、封装、多态)。所以Django在后来加入了Class-Based-View。可以让我们用类写View。这样做的优点主要下面两种:
- 提高了代码的复用性,可以使用面向对象的技术,比如Mixin(多继承)
- 可以用不同的函数针对不同的HTTP方法处理,而不是通过很多if判断,提高代码可读性
CBV演示简单登录流程
views视图函数
from django.shortcuts import render,HttpResponse
from django.views import View # 从django.views模块中引用View类
class Login(View):
"""
自己定义get post方法,方法名不能变。这样只要访问此url,get请求自动执行get方法,post请求自动执行post方法,与我们写的FBV
if request.method == 'GET' or 'POST' 一样。
"""
def get(self, request):
return render(request, 'login.html')
def post(self, request):
username = request.POST.get('username')
password = request.POST.get('password')
if username.strip() == 'taibai' and password.strip() == '123':
return HttpResponse('登录成功')
return render(request, 'login.html')
url路由
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^login/', views.Login.as_view()),
# 引用views函数重的Login类,然后调用父类的as_view()方法
]
# CBV传参,和FBV类似,有名分组,无名分组
# url写法:无名分组的
# url(r'^cv/(\d{2})/', views.Myd.as_view(),name='cv'),
# url(r'^cv/(?P\d{2})/', views.Myd.as_view(name='xxx'),name='cv'),
# 如果想给类的name属性赋值,前提你的Myd类里面必须有name属性(类属性,
# 定义init方法来接受属性行不通,但是可以自行研究一下,看看如何行通,意义不大),
# 并且之前类里面的name属性的值会被覆盖掉
templates的html
Bootstrap 101 Template
你好 欢迎来到plus会所,请先登录
视图函数的装饰器
面试有问过,如果你用CBV模式,你的get或者post方法是从哪里执行的? 能否在get执行之前或者之后做一些特殊的操作?
你的get或者post方法都是在源码的dispatch方法中执行的,我们可以利用重写父类的dispatch方法,就能够对get和post请求搞事情了。但是如果我想单独对某个请求方法搞事情,那么只能加上装饰器了。
FBV装饰器
对于FBV这种开发方式,加上装饰器很简单,就是我们之前讲过的方式,这种比较简单,这里就直接展示view视图函数的代码即可
def wrapper(func):
def inner(*args,**kwargs):
print('请求来了!')
ret = func(*args,**kwargs)
print('请求走了!')
return ret
return inner
@wrapper
def home(request):
print('执行home函数')
return render(request, 'home.html')
CBV装饰器
方法一: 直接加装饰器
因为template,urls很简单,此处只展示views函数
views视图函数
def wrapper(func):
def inner(*args,**kwargs):
print('请求来了!')
ret = func(*args,**kwargs)
print('请求走了!')
return ret
return inner
class Login(View):
@wrapper
def get(self, request):
print('get 方法')
return render(request, 'login.html')
def post(self, request):
username = request.POST.get('username')
password = request.POST.get('password')
if username.strip() == 'taibai' and password.strip() == '123':
return HttpResponse('登录成功')
return render(request, 'login.html')
'''
执行流程:
请求来了!
执行home函数
请求走了!
'''
方法二: 借助method_decorator模块
from django.utils.decorators import method_decorator
def wrapper(func):
def inner(*args,**kwargs):
print('请求来了!')
ret = func(*args,**kwargs)
print('请求走了!')
return ret
return inner
class Login(View):
@method_decorator(wrapper)
def get(self, request):
print('get 方法')
return render(request, 'login.html')
def post(self, request):
username = request.POST.get('username')
password = request.POST.get('password')
if username.strip() == 'taibai' and password.strip() == '123':
return HttpResponse('登录成功')
return render(request, 'login.html')
方式三: 给所有方法都加上装饰器
在我们的源码dispatch方法。我们可以在子类中重写父类的dispatch方法,因为无论执行什么请求方法(post,get,push,delete等等)都是dispatch方法利用反射调用的。所以,我们给此方法加上装饰器即可。
class Login(View):
@wrapper
def dispatch(self, request, *args, **kwargs):
ret = super().dispatch(request, *args, **kwargs)
return ret
方式四: 直接在类上加装饰器(不常用)
注意
# 注意csrf-token装饰器的特殊性,在CBV模式下它只能加在dispatch上面(后面再说)
# 下面这是csrf_token的装饰器:
# @csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置csrfToken全局中间件。
# @csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
# 注意:from django.views.decorators.csrf import csrf_exempt,csrf_protect
Django的模板系统
什么是模版系统?这里做一个简单解释。要想明白什么是模版系统,那么我们得先分清楚静态页面和动态页面。我们之前学过的都是静态页面,所谓的静态页面就是浏览器向后端发送一个请求,后端接收到这个请求,然后返回给浏览器一个html页面,这个过程不涉及从数据库取出数据渲染到html页面上,只是单纯的返回一个页面(数据全部在html页面上)。而动态页面就是在给浏览器返回html页面之前,需要后端与数据库之间进行数据交互,然后将数据渲染到html页面上在返回给浏览器。言外之意静态页面不涉及数据库,动态页面需要涉及从数据库取出数据。那么模版系统是什么呢?如果你只是单纯的写静态页面,也就没必有必要用模版系统了,只用动态页面才需要模版系统。
简单来说,模版系统就是在html页面想要展示的数据库或者后端的数据的标签上做上特殊的占位(类似于格式化输出),通过render方法将这些占位的标签里面的数据替换成你想替换的数据,然后再将替换数据之后的html页面返回给浏览器,这个就是模版系统。
模板渲染的官方文档
关于模板渲染你只需要记两种特殊符号(语法):
{{ }}和 {% %}
变量相关的用{{}},逻辑相关的用{%%}。
变量
Example1
url
from django.conf.urls import url,include
from app01 import views
urlpatterns = [
# 首页
url(r'^$',views.base),
url('^app01/',include('app01.urls')),
]
# Django_Demo1/app01/urls.py (第二个app应用的urls.py)
from django.conf.urls import url
from app01 import views
urlpatterns = [
url('^login/',views.login),
]
views
render第三个参数接受一个字典的形式,通过字典的键值对index.html页面进行渲染,这也就是模板渲染
from django.shortcuts import render
from django.shortcuts import redirect
def login(request):
name = "幽梦"
age = 20
name_list = ['幽梦', 'flying', ]
dic = {'幽梦': 18, 'flying': 21}
return render(request, 'login1.html', {'name': name, 'age': age, 'name_list': name_list, 'dic_class': dic})
login1.html
Title
欢迎来到You-Men博客
- {{ name }}
- {{ age }}
- {{ name_list }}
- {{ dic_class }}

语法
在Django的模板语言中按此语法使用: {{ 变量名 }}
当模板引擎遇到一个变量,他将计算这个变量,然后用结果替换掉他本身, 变量的命名包括任何字母数字以及下划线("_")的组合. 变量名称中不能有空格或标点字符.
深度查询点符(.)在模板语言中有特殊的含义,当模板系统遇到点("."),他将以这样的顺序查询:
# 字典查询(Dictionary lookup)
# 属性或方法查询(Attribute or method lookup)
# 数字索引查询(Numeric index lookup)
万能的点
通过简单示例我们已经知道模板系统对于变量的渲染是如何做到的,非常简单,下面将演示一下深入的渲染,我们不想将整个列表或字典渲染到html,而是将列表里的元素,或者字典的某个值渲染到html页面中,就可以通过万能的点
views
from django.shortcuts import render
from django.shortcuts import redirect
def home(request):
name = "幽梦"
age = 20
name_list = ['幽梦', 'flying', '红玫瑰','紫玫瑰','白玫瑰']
dic = {'幽梦': 18, 'flying': 21,"黄玫瑰":22}
return render(request, 'home.html', locals())
def base(request):
return render(request, 'base.html')
html
Title
欢迎来到You-Men博客
- {{ name }}
- {{ age }}
- {{ name_list.2 }}
- {{ dic.黄玫瑰 }}
过滤器
1. 什么是过滤器?
有的时候我们通过render渲染到html的数据并不是我们最终想要的数据,比如后端向前端传递的数据为hello,但我们想要hello显示为HELLO,这个可以后端提前处理的, 诸如此类需求我们可以通过过滤器来解决.
2. 语法
# 过滤器的语法: {{ value | filter_name:参数 }}
# 使用管道符"|"来应用过滤器
# 例如: {{ name|lower }}会将name变量应用lower过滤器之后再显示他的值,lower在这里的作用就是将文本全部都变为小写.
# 注意事项:
# 1. 过滤器支持"链式"操作,即一个过滤器的输出作为另一个过滤器的输入.
# 2. 过滤器可以接受参数,例如: {{ ss|truncatewords:30 }},这将显示ss的前三十个词
# 3. 过滤器参数包含空格的话,必须用引号包裹起来,比如使用逗号和空格去连接一个一个列表中的元素, 如{{ list|join:',' }}
# 4. '|'左右没有空格!没有空格 ! 没有空格
# Django的模板语言中提供了大约六十个内置过滤器
常用过滤器
1. default: 如果一个变量是false或者为空,或者给定的默认值,否则,使用变量的值
views:
a = '' # 没有变量a或者变量a为空
html: # 显示啥也没有
{{ value|default:"啥也没有"}}
2. length: 返回值的长度,作用于字符串和列表
views:
name_list = ['幽梦', 'flying', '红玫瑰','紫玫瑰','白玫瑰']
return render(request, 'home.html', { 'name_list':name_list})
html:
{{ name_list|length }} # 显示为5
3. filesizeformat: 将值格式化为一个"人类可读的"文件尺寸(例如'13kb','4.1M','102bytes')
views:
value = 1048576
html:
{{ value|filesizeformat }} # 显示为1.0MB
4. slice: 切片,支持python中可以用切片的所有数据类型
views:
name_list = ['王阔', '天琪', '傻强', '志晨', '健身哥']
s = '太白金星讲师'
html:
{{ name_list|slice:'1:3' }} # ['天琪', '傻强']
{{ s|slice:'1::2' }} # '白星师'
5. date: 时间格式化
# views
time = datetime.datetime.now()
return render(request, 'home.html', { 'time':time })
# html
{{ time|date:"Y-m-d H:i:s" }}
truncatechars: 如果字符串字符多余指定的字符数量,那么会被截断,截断的字符串将以可翻译的省略号序列("...")结尾
# views:
describe = '1999年3月,马云正式辞去公职,后来被称为18罗汉的马云团队回到杭州,凑够50万元人民币'
# html:
{{ describe|truncatechars:9 }} # 1999年3...
# 截断9个字符,三个点也算三个字符
# 我们浏览网页可以经常看到一个链接下面有一段注释,然后就是...
truncatewords: 在一定数量的字后截断字符串,是截多少个单词
views:
words = 'i love you my country china'
html:
{{ words|truncatewords:3 }} # i love you...
cut: 移除value中所有的与给出变量相同的字符串
views:
words = 'i love you my country china'
html:
{{ words|cut:3 }} # iloveyou
join: 设定连接符将可迭代对象的元素连接在一起与字符串的join方法相同
views:
name_list = ['王阔', '天琪', '傻强', '志晨', '健身哥']
dic = {'name':'太白','age': 18}
tu = (1, 2, 3)
html:
{{ name_list|join:'_'}}
{{ dic|join:','}}
{{ tu|join:'+'}}
'''
王阔_天琪_傻强_志晨_健身哥
name,age
1+2+3
'''
safe
Django的模板中在进行模板渲染的时候会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全,django担心这是用户添加的数据,比如如果有人给你评论的时候写了一段js代码,这个评论一提交,js代码就执行啦,这样你是不是可以搞一些坏事儿了,写个弹窗的死循环,那浏览器还能用吗,是不是会一直弹窗啊,这叫做xss攻击,所以浏览器不让你这么搞,给你转义了。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。
我们去network那个地方看看,浏览器看到的都是渲染之后的结果,通过network的response的那个部分可以看到,这个a标签全部是特殊符号包裹起来的,并不是一个标签,这都是django搞得事情。
很多网站,都会对你提交的内容进行过滤,一些敏感词汇、特殊字符、标签、黄赌毒词汇等等,你一提交内容,人家就会检测你提交的内容,如果包含这些词汇,就不让你提交,其实这也是解决xss攻击的根本途径,例如博客园:
timesnce
将日期格式设为自该日期起的时间(例如, "四天,5小时")
采用一个可选参数,他是一个包含用作比较点的日期的变量(不带参数,比较点为现在)。 例如,如果since_12是表示2012年6月28日日期实例,并且comment_date是2018年3月1日日期实例:
views:
year_12 = datetime.datetime.now().replace(year=2012, month=6, day=28)
year_18 = datetime.datetime.now().replace(year=2018, month=3, day=1)
html:
{{ year_12|timesince:year_18}}
'''
5 years, 8 months
'''
# 如果year_18不写,默认就是距现在的时间段
timeuntil
似于timesince,除了它测量从现在开始直到给定日期或日期时间的时间。 例如,如果今天是2006年6月1日,而conference_date是保留2006年6月29日的日期实例,则{{ conference_date | timeuntil }}将返回“4周”。
使用可选参数,它是一个包含用作比较点的日期(而不是现在)的变量。 如果from_date包含2006年6月22日,则以下内容将返回“1周”:
{{ conference_date|timeuntil:from_date }}
更多内置过滤器(此链接页面最下面的内置过滤器):https://docs.djangoproject.com/en/1.11/ref/templates/builtins/#filters
标签Tags
现在我们已经可以从后端通过模版系统替换掉前端的数据了,但是如果只是替换掉数据,确实不够灵活,比如,我们要想在前端页面展示可迭代对象name_list = ['王阔', '天琪', '傻强', '志晨', '健身哥']每个元素,你如和展示呢?
# 前端页面
- {{ name_list.0 }}
- {{ name_list.1 }}
- {{ name_list.2 }}
- {{ name_list.3 }}
这样写明显很low,我们要是可以用上for循环就好了。Django这么强大的框架,不可能想不到这点的,这里模版系统给我们提供了另一种标签,就是可以在html页面中进行for循环以及if判断等等。
标签看起来像是这样的:
{% tag %}。标签比变量更加复杂:一些在输出中创建文本,一些通过循环或逻辑来控制流程,一些加载其后的变量将使用到的额外信息到模版中。与python语法不同的是:一些标签需要开始和结束标签 (例如{% tag %} ...标签 内容 ... {% endtag %})。学习下面几种标签之前,我们要重新写一个url、views以及html,方便分类学习不与上面的变量产生冲突。
for标签
基本语法
{% for 变量 in render的可迭代对象 %}
{{ 变量 }}
{% endfor %}
# 例如:
{% for foo in name_list %}
{{ foo }}
{% endfor %}
view
import datetime
from django.shortcuts import render
from django.shortcuts import redirect
def home(request):
name = "幽梦"
age = 20
size = 2342314
time = datetime.datetime.now()
name_list = ['幽梦', 'flying', '红玫瑰','紫玫瑰','白玫瑰']
dic = {'幽梦': 18, 'flying': 21,"黄玫瑰":22}
return render(request, 'home.html', { 'name_list':name_list })
html
Title
欢迎来到You-Men博客
{{ name }}
{{ age }}
{% for i in name_list %}
- {{ i }}
{% endfor %}
{{ dic }}
遍历一个列表
{% for foo in name_list %}
- {{ foo }}
{% endfor %}
反向遍历一个列表
{% for foo in name_list reversed %}
{{ foo }}
{% endfor %}
遍历一个字典: 有items,keys,values参数
{% for key,value in dic.items %}
- {{ key }}: {{ value }}
{% endfor %}
{% for key in dic.keys %}
- {{ key }}
{% endfor %}
{% for value in dic %}
- {{ value }}
{% endfor %}
forloop
模版系统给我们的for标签还提供了forloop的功能,这个就是获取循环的次数,有多种用法:
forloop.counter # 当前循环的索引值(从1开始),forloop是循环器,通过点来使用功能
forloop.counter0 # 当前循环的索引值(从0开始)
forloop.revcounter # 当前循环的倒序索引值(从1开始)
forloop.revcounter0 # 当前循环的倒序索引值(从0开始)
forloop.first # 当前循环是不是第一次循环(布尔值)
forloop.last # 当前循环是不是最后一次循环(布尔值)
forloop.parentloop # 本层循环的外层循环的对象,再通过上面的几个属性来显示外层循环的计数等
{% for foo in name_list %}
- {{ forloop.counter }} {{ foo }}
{% endfor %}
{% for foo in name_list %}
{{ forloop.counter0 }}
- {{ foo }}
{% endfor %}
{% for foo in name_list %}
- {{ forloop.revcounter }} {{ foo }}
{% endfor %}
{% for foo in name_list %}
- {{ forloop.first }} {{ foo }}
{% endfor %}
for..empty..组合
如果遍历的可迭代对象是空的或者就没有这个对象,利用这个组合可以提示用户
{% for foo in aaa %}
- {{ foo }}
{% empty %}
- 查询的内容啥也没有
{% endfor %}
{% for foo in value %}
- {{ foo }}
{% empty %}
- 查询的内容啥也没有
{% endfor %}
IF标签
基本语法
{% ``if %}会对一个变量求值,如果它的值是“True”(存在、不为空、且不是boolean类型的false值),对应的内容块会输出。
{% if 条件 %}
结果
{% elif 条件 %}
结果
{% else %}
结果
{% endif %}
elif和else一定要在if endif里面,设置多个elif或者没有elif,有没有else都可以
{% if dic.age > 18 %}
可以干点儿该做的事儿了~
{% elif dic.age < 18 %}
小孩子,懂什么
{% else %}
风华正茂的年龄~
{% endif %}
条件也可以与过滤功能配合
% if name_list|length > 4 %}
列表元素超过4个
{% else %}
列表元素太少!
{% endif %}
条件也可以加逻辑运算符
if语句支持 and 、or、==、>、<、!=、<=、>=、in、not in、is、is not判断,注意条件两边都有空格。
with
使用一个简单地名字缓存一个复杂的变量,多用于给一个复杂的变量起别名,当你需要一个
昂贵的方法(比如访问数据库)很多次的时候是非常有用的,记住 ! 等号的左右不要加空格! !
{% with total=business.employees.count %}
{{ total }}
{% endwith %}
{% with business.employees.count as total %}
{{ total }}
{% endwith %}
forloop.first, forloop.last,forloop.parentloop
forloop.first
{% for foo in name_list %}
{% if forloop.first %}
{{ foo }}
{% else %}
只有第一次循环打印
{% endif %}
{% endfor %}
forloop.parenloop: 一定注意! 他是返回本此循环的外层循环对象,这个对象可以调用forloop的各种方法进行获取相应的数据
测试此方法,我们要在views函数加一个数据类型: lis = [['A', 'B'], ['C', 'D'], ['E', 'F']]
{% for i in lis %}
{% for j in i %}
{# {{ forloop.parentloop }}
#}
{{ forloop.parentloop.counter }} {{ forloop.counter }} {{ j }}
{% endfor %}
{% endfor %}
注意事项
# 1. Django的模板语言不支持连续判断,即不支持以下写法:
{% if a > b > c %}
...
{% endif %}
# 2. Django的模板语言中属性的优先级大于方法
def xx(request):
d = {"a": 1, "b": 2, "c": 3, "items": "100"}
return render(request, "xx.html", {"data": d})
# 如上,我们在使用render方法渲染一个页面的时候,传的字典d有一个key是items并且还有默认的 d.items() 方法,此时在模板语言中:
{{ data.items }}
# 默认会取d的item key的值
csrf_token标签
这个标签是不是非常熟悉?之前我们以post方式提交表单的时候,会报错,还记得我们在settings里面的中间件配置里面把一个csrf的防御机制给注销了啊,本身不应该注销的,而是应该学会怎么使用它,并且不让自己的操作被forbiden,通过这个标签就能搞定。
当我们加上此标签之后,再次发出get请求,render返回给我们的页面中多了一个隐藏的input标签,并且这个标签里面有个一键值对:
键:name,值:随机的一堆密文。 那么这个是干什么用的呢?其实他的流程是这样的:
第一次发送get请求,在views视图函数返回给你login.html页面之前,render会将csrf_token标签替换成一个隐藏的input标签,此标签的键值对就是上面那个键值对并且Django将这个键值对保存在内存;当你再次进行post请求时,他会验证你的form表单里面的隐藏的input标签的键值对是否与我内存中存储的键值对相同,如果相同,你是合法的提交,允许通过;如果不相同,则直接返回给你forbidden页面。这就好比说,第一次get请求,他返回你一个盖戳的文件,当你在进行post请求时他会验证是不是那个盖戳的文件。他的目的就是你提交post请求时,必须是从我给你的get请求返回的页面提交的。为什么这么做呢?是因为有人登录你的页面时是可以绕过的get请求返回的页面直接进行post请求登录的,比如说爬虫。直接通过requests.post('/login/')直接请求的,这样是没有csrftoken的,这样就直接拒绝了。
说了这么多,目的就是一个:验证当你post提交请求时,是不是从我给你(你通过get请求的)页面上提交的数据。
我们可以写一个简单爬虫验证以下
import requests
ret = requests.post('http://127.0.0.1:8000/login/',
data={'username': 'taibai', 'password': '123'}
)
print(ret.content)
# 如果你保留这这个验证,则通过爬虫是登录不成功的,只能返回你一个forbidden的html页面。
# 如果你将settings那个中间件注释掉,那么就可以成功访问了:
模板继承
模版就是django提供的用于html发送浏览器之前,需要在某些标签进行替换的系统,而继承我们立马就会想到这是面向对象的三大特性之一。其实模版继承就是拥有这两个特性的模版的高级用法。
一般管理系统都是这样的布局,这个就是固定的导航条和侧边栏。无论我点击侧边栏里的那个按钮,这两部分不会更换只会改变中间的内容。
那么接下来我们实现一个这样的布局。
我们要准备4个html页面:base.html、menu1.html、menu2.html、menu3.html,这四个页面的导航条与左侧侧边栏一样,每个页面对应一个url。并且每个页面的左侧侧边栏菜单一、菜单二、菜单三可以实现跳转:跳转到menu1.html、menu2.html、menu3.html三个页面。而顶端导航条只是样式即可。接下来借助于Django,我们实现这四个页面并对应urls可以跑通流程。
urls
urlpatterns = [
url(r'^base/', views.base),
url(r'^menu1/', views.menu1),
url(r'^menu2/', views.menu2),
url(r'^menu3/', views.menu3),
]
views
def base(request):
return render(request, 'base.html')
def menu1(request):
return render(request, 'menu1.html')
def menu2(request):
return render(request, 'menu2.html')
def menu3(request):
return render(request, 'menu3.html')
html
base.html:
Bootstrap 101 Template
menu1.html:
Bootstrap 101 Template
menu2.html:
Bootstrap 101 Template
menu3.html
Bootstrap 101 Template
base menu1 menu2 menu3
上面我的的需求虽然完成了但是有没有什么没问题?你会发现html重复代码太多了,如果领导不瞎,最晚后天你就可以领盒饭了。
2. 母版继承示例
所以针对与我上面的需求,很显然你现在所拥有的知识点已经解决不了了。那么接下来就是本节的重点:模版继承。根据这个知识点名字的特点,我们应该想到,我们可不可以建立一个父类,然后让所有的子孙类都继承我的父类,这样我就可以节省很多代码了,让我的代码非常的清新、简单。这里的父类就不叫父类了他有一个专有名词:母版。
接下来我们先创建一个母版。(最好不要将base页面直接作为母版,母版就是只设置公用的部分,其他一概不要。)
Bootstrap 101 Template
接下来,我们将base menu1 menu2 menu3这四个页面全部清空,然后在每个页面的最上面加上这么一行代码:接下来,我们将base menu1 menu2 menu3这四个页面全部清空,然后在每个页面的最上面加上这么一行代码:
{% extends 'master_edition.html' %}
这个就实现了我要继承母版master_edition.html。
3. 自定制效果
现在已经完成了继承母版,这个只是减少了重复代码,还没有实现每个页面自定制的一些内容,如果你想要实现自定制的内容怎么做?类似于模版系统你是不是应该在母版的具体位置做一个标识,然后在自己的页面对应的地方进行自定制?那么这个类似于%占位符的特定的标识叫做钩子。这几个页面只是在menu div不同,所以我们就在这里做一个钩子就行了。
在母版的html对应位置:
block endblock就是对应的钩子,content是此钩子的名字。
然后在base menu1 menu2 menu3的页面上(此时就以base页面举例):
{% block content %}
base页面首页
{% endblock %}
这样你的代码是不是非常的简单了?
那么我们不仅可以在对应的html标签设置钩子,还可以在css、js设定对应的钩子。所以母版继承中一般设定钩子的地方就是三部分: html、css、js。
以css举例:
我们将base页面的顶端导航条的背景颜色设置成红色:
首先现在母版页面对应的位置设置钩子:
然后找到base页面:
{% block nav %}
.nav{
background-color: red;
}
{% endblock %}
这样你的base页面的导航条就变成红色啦!
4. 保留母版内容并添加新特性
还有一个情况我们也会遇到,就是我既要留住母版的内容,又要在自己的html添加一些新的标签。这个我们在面向对象时是不是也遇到过?当时用什么方法既执行父类方法又可以执行子类方法?super!在这里我们也用super!
母版html:
base.html
{% block content %}
{{ block.super }}
base页面首页
{% endblock %}
在钩子里面加上{{ block.super }}即可
注意
- 如果你在模版中使用
{% extends %}标签,它必须是模版中的第一个标签。其他的任何情况下,模版继承都将无法工作,模板渲染的时候django都不知道你在干啥。 - 在base模版中设置越多的
{% block %}标签越好。请记住,子模版不必定义全部父模版中的blocks,所以,你可以在大多数blocks中填充合理的默认内容,然后,只定义你需要的那一个。多一点钩子总比少一点好。 - 如果你发现你自己在大量的模版中复制内容,那可能意味着你应该把内容移动到父模版中的一个
{% block %}中。 - If you need to get the content of the block from the parent template, the
{{ block.super }}variable will do the trick. This is useful if you want to add to the contents of a parent block instead of completely overriding it. Data inserted using{{ block.super }}will not be automatically escaped (see the next section), since it was already escaped, if necessary, in the parent template. 将子页面的内容和继承的母版中block里面的内容同时保留。 - 不能在一个模版中定义多个相同名字的
block标签。 - 结束一个钩子时可以标注此钩子的名字,比如 {% endblock content%}这样就可以结束此钩子不至于将其他的block钩子一并结束。
组件
组件就是将一组常用的功能封装起来,保存在单独的html文件中,(如导航条,页尾信息等)其他页面需要此组功能时,按如下语法导入即可。 这个与继承比较类似,但是‘格局’不同,继承是需要写一个大的母版,凡是继承母版的一些html基本上用的都是母版页面的布局,只有一部分是自己页面单独展现的,这好比多以及排布好的多个组件。
{% include 'xx.html' %}
比如我们写一个nav导航条组件
Bootstrap 101 Template
然后我们在创建流程去使用我们的组件
urls:
url(r'^component/', views.component),
views:
def component(request):
return render(request,'component.html')
component页面:
Bootstrap 101 Template
{% include 'nav.html' %}
你好,世界!
我是componet页面
组件和插件的区别
# 组件是提供某一完整功能的模块,如: 编辑器组件,QQ空间提供的关注组件等
# 而插件更倾向封闭某一个功能方法的函数
# 这两者的区别在JavaScript里区别很小,组件这个名词用的不多,一般统称插件
Django之ORM操作
web开发的分工模式
DBA(数据库管理员)+应用层开发。
一般中大型公司(或者数据量巨大、读取数据的需求频繁并且追求极致效率的公司)会有专门的DBA管理数据库,编写sql语句,对于应用层开发来说,不用写sql语句,直接调用他写的接口就行。所以在这种公司一般来说,开发人员应该'供'着DBA,因为你想写入或者取出的数据需要依赖于DBA去执行,或者是你写的比较复杂的sql语句需要让DBA帮你看一下,效率行不行、是不是需要优化等等,这就需要看你们的交情或者其心情了。哈哈(开个玩笑)。
应用程序开发+sql语句编写。
这种情况多存在于小公司,没有专门设置DBA岗位,要求开发人员什么都会一些,linux、数据库、前端等等,这样成本降低并且减少由于部门之间的沟通带来的损失,提高工作流程效率。
应用程序开发+ORM。
这种模式sql不用你写,你直接写类、对象,应为你对这些更加游刃有余。然后通过你写的类、对象,等等通过相应的转换关系直接转化成对应的原生sql语句,这种转化关系就是ORM:对象-关系-映射。你直接写一个类就是创建一张表,你实例化一个对象就是增加一条数据,这样以来,既可以避开写sql语句的麻烦,而且可以提升我们的开发效率。
Django的ORM简介
MTV或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动.
ORM是“对象-关系-映射”的简称。(Object Relational Mapping,简称ORM)(将来会学一个sqlalchemy,是和他很像的,但是django的orm没有独立出来让别人去使用,虽然功能比sqlalchemy更强大,但是别人用不了)
类对象--->sql--->pymysql--->mysql服务端--->磁盘,orm其实就是将类对象的语法翻译成sql语句的一个引擎,明白orm是什么了,剩下的就是怎么使用orm,怎么来写类对象关系语句。
这样开发效率肯定是提升了,但是也有一点点缺陷就是通过ORM转化成的sql语句虽然是准确的,但是不一定是最优的。
原生SQL和Python的ORM代码对比
#sql中的表
#创建表:
CREATE TABLE employee(
id INT PRIMARY KEY auto_increment ,
name VARCHAR (20),
gender BIT default 1,
birthday DATA ,
department VARCHAR (20),
salary DECIMAL (8,2) unsigned,
);
#sql中的表纪录
#添加一条表纪录:
INSERT employee (name,gender,birthday,salary,department)
VALUES ("alex",1,"1985-12-12",8000,"保洁部");
#查询一条表纪录:
SELECT * FROM\\ employee WHERE age=24;
#更新一条表纪录:
UPDATE employee SET birthday="1989-10-24" WHERE id=1;
#删除一条表纪录:
DELETE FROM employee WHERE name="alex"
#python的类
class Employee(models.Model):
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
gender=models.BooleanField()
birthday=models.DateField()
department=models.CharField(max_length=32)
salary=models.DecimalField(max_digits=8,decimal_places=2)
#python的类对象
#添加一条表纪录:
emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部")
emp.save()
#查询一条表纪录:
Employee.objects.filter(age=24)
#更新一条表纪录:
Employee.objects.filter(id=1).update(birthday="1989-10-24")
#删除一条表纪录:
Employee.objects.filter(name="alex").delete()
ORM单表操作
1 . 创建一个django项目
2 . 通过类创建数据表
从django.db 引入models模块,创建表通过构建一个类去设定,数据库中不区分大小写,所以你的UserInfo在数据库中直接编译成了userinfo,此类必须继承models.Model类,通过设定类的静态属性就会转化成sql语句。
注意装mysql需要远程授权
grant all privileges on *.* to admin@"%" identified by 'ZHOUjian.21' with grant option;
flush privileges;
3 . 修改settings.py配置文件
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'cmdb',
'USER': 'admin',
'PASSWORD': 'ZHOUjian.20',
'HOST': '121.36.43.223',
'PORT': '3306',
}
}
# 使用pymysql注意到__init.py加入以下两行代码
import pymysql
pymysql.install_as_MySQLdb()
注意
注意:NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。接下来,我们要提前先给mysql创建cmdb的数据库
4 . 通过类创建数据表
从django.db 引入models模块,创建表通过构建一个类去设定,数据库中不区分大小写,所以你的UserInfo在数据库中直接编译成了userinfo,此类必须继承models.Model类,通过设定类的静态属性就会转化成sql语句。
from django.db import models
# Create your models here.
class UserInfo(models.Model):
"""
下面几个类的属性通过ORM映射就对应成了:
create table userinfo(
id int primary key auto_increment,
name varchar(16),
age int,
current_date date)
"""
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=16)
age = models.IntegerField()
current_date = models.DateField()
5 . 在对应的数据库中生成表结构
上面我们已经通过类构建了一个表,但是还没有对应的生成真实的数据库中的表结构,所以我们要将上面的类生成真生的数据库中的表结构。对应只有行代码。
在terminal输入指令:
python manage.py makemigrations
接下来我们会发现migrations出现一个0001_initial.py的文件,这个文件是执行上述命令之后产生的脚本文件,这个文件就是一个记录
这个指令其实就是执行第一个指令生成的记录也就是那个脚本文件,然后就会在你对应的数据库中生成一个真正的表,生成的表名字前面会自带应用的名字,例如:你的userinfo表在数据表里面叫做:cmdb_userinfo。
同步执行指令的原理
在执行 python manager.py makemigrations时
Django 会在相应的 app 的migrations文件夹下面生成 一个python脚本文件
在执行 python manager.py migrate 时 Django才会生成数据库表,那么Django是如何生成数据库表的呢?
Django是根据 migrations下面的脚本文件来生成数据表的
每个migrations文件夹下面有多个脚本,那么django是如何知道该执行那个文件的呢,django有一张django-migrations表,表中记录了已经执行的脚本,那么表中没有的就是还没执行的脚本,则 执行migrate的时候就只执行表中没有记录的那些脚本。
有时在执行 migrate 的时候如果发现没有生成相应的表,可以看看在 django-migrations表中看看 脚本是否已经执行了,
可以删除 django-migrations 表中的记录 和 数据库中相应的 表 , 然后重新 执行
Django的ORM系统体现在框架内就是模型层。想要理解模型层的概念,关键在于理解用Python代码的方式来定义数据库表的做法!一个Python的类,就是一个模型,代表数据库中的一张数据表!Django奉行Python优先的原则,一切基于Python代码的交流,完全封装SQL内部细节。
Example1
1.创建django程序:
# 终端命令: django-admin startproject sitename
# IDE创建django程序本质上都是自动那个上述命令
# 其他常用命令
python manage.py runserver 0.0.0.0
python manage.py startapp appname
python manage.py syncdb
python manage.py makemigrations
python manage.py migrate
python manage.py createuperuser
2.创建cmdbapp应用
python manage.py startapp cmdb
3.模板
TEMPLATE_DIRS = (
'DIRS': [os.path.join(BASE_DIR,'templates')],
)
4.静态文件
STATICFILES_DIRS = (
os.path.join(BASE_DIR,'static')
)
5. 修改数据库引擎
settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'cmdb',
]
6.创建一个模型
一个模型(model)就是一个单独的、确定的数据的信息源,包含了数据的字段和操作方法。通常,每个模型映射为一张数据库中的表。
基本的原则如下:
# 每个模型在Django中的存在形式为一个Python类
# 每个模型都是django.db.models.Model的子类
# 模型的每个字段(属性)代表数据表的某一列
# Django将自动为你生成数据库访问API
/Django_ORM_Demo/cmdb/models.py
from django.db import models
# Create your models here.
class UserInfo(models.Model):
"""
下面几个类的属性通过ORM映射就对应成了:
create table userinfo(
id int primary key auto_increment,
name varchar(16),
age int,
current_date date)
"""
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=16)
age = models.IntegerField()
current_date = models.DateField()
python manage.py migrate
python manage.py makemigrations
注意
# 表名`myapp_person`由Django自动生成,默认格式为“项目名称+下划线+小写类名”,你可以重写这个规则。
# Django默认自动创建自增主键`id`,当然,你也可以自己指定主键。
# 上面的SQL语句基于`PostgreSQL`语法。
通常,我们会将模型编写在其所属app下的models.py文件中,没有特别需求时,请坚持这个原则,不要自己给自己添加麻烦。
创建了模型之后,在使用它之前,你需要先在settings文件中的
INSTALLED_APPS处,注册models.py文件所在的myapp。看清楚了,是注册app,不是模型,也不是models.py。如果你以前写过模型,可能已经做过这一步工作,可跳
ORM字段
<1> CharField
字符串字段, 用于较短的字符串.
CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数.
<2> IntegerField
#用于保存一个整数.
<3> DecimalField
一个浮点数. 必须 提供两个参数:
参数 描述
max_digits 总位数(不包括小数点和符号)
decimal_places 小数位数
举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段:
models.DecimalField(..., max_digits=5, decimal_places=2)
要保存最大值一百万(小数点后保存10位)的话,你要这样定义:
models.DecimalField(..., max_digits=17, decimal_places=10) #max_digits大于等于17就能存储百万以上的数了
admin 用一个文本框()表示该字段保存的数据.
<4> AutoField
一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段;
自定义一个主键:my_id=models.AutoField(primary_key=True)
如果你不指定主键的话,系统会自动添加一个主键字段到你的 model.
<5> BooleanField
A true/false field. admin 用 checkbox 来表示此类字段.
<6> TextField
一个容量很大的文本字段.
admin 用一个