2019独角兽企业重金招聘Python工程师标准>>> 
一、高并发概述
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
常见参考点:
1.静态多还是动态多 2.读多写多3.什么业务逻辑
高可用、扩展性、负载均衡
二、常见的互联网分层架构
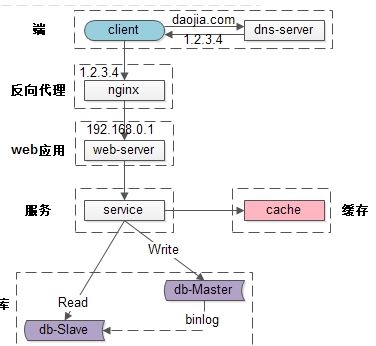
1、DNS(Domain Name System,域名系统)轮询,万维网上作为域名和IP地址相互映射的一个分布式数据库,DNS协议运行在UDP协议之上,使用端口号53。DNS解析同一个域名可以访问不同的IP地址;实现简单、成本低、粒度太粗、负载均衡算法少;DNS-server只负责域名解析ip;这个ip对应的服务是否可用,DNS-server是不保证的。DNS负载均衡可以实现在地域上的流量均衡
1.硬件负载均衡:F5和A10价格在20w~50w之间;并发大概能到200万/秒到800万/秒;Networks的公司开发的四~七层交换机,硬件负载均衡主要用于大型服务器集群中的负载需求。
2.LVS(Linux Virtual Server)软件负载均衡:并发大概能到80万/秒;LVS是linux内核的4层负载均衡;和协议无关
3.Ngnix软件负载均衡:并发大概能到5万/秒;Ngnix是7层负载均衡;支持HTTP和e-mail协议;Nginx 只负责了单机内多实例的负载均衡,考虑到 Nginx 工作在 7 层的开销远高于 LVS/DR 模式,所以一般在一个 Nginx 后面挂的实例数也不会超过 10 个。而软件负载均衡大多是基于机器层面的流量均衡。
常用的均衡算法有哪些?
-
轮询策略:按顺序轮询的、有随机轮询的、还有按照权重来轮询的。前两种比较好理解,第三种按照权重来轮询,是指给每台后端服务设定一个权重值,比如性能高的服务器权重高一些,性能低的服务器给的权重低一些
-
负载度策略:先去评估后端每台服务器的负载压力情况,对于压力比较大的后端服务器转发的请求就少一些,对于压力比较小的后端服务器可以多转发一些请求给它。弊端是需要动态的评估后端服务器的负载压力
-
响应策略:负载均衡器」会优先将请求转发给当前时刻响应最快的后端服务器。
那「负载均衡器」是怎么知道哪一台后端服务在当前时刻响应能力最佳呢?
这就需要「负载均衡器」不停的去统计每一台后端服务器对请求的处理速度了,比如一分钟统计一次,生成一个后端服务器处理速度的排行榜。然后「负载均衡器」根据这个排行榜去转发服务。那么这里的问题就是统计的成本了 -
哈希策略:将请求中的某个信息进行hash计算,然后根据后端服务器台数取模,得到一个值,算出相同值的请求就被转发到同一台后端服务器中。能保证同一个IP来源或者同一个用户永远会被送到同一个后端服务器上了,一般用于处理缓存、会话等功能的时候特别好用。
三、数据库
1.读写分离(主库从库)
MySQL支持主从同步,实时将主库的数据增量复制到从库,而且一个主库可以连接多个从库同步。利用此特性,我们在应用服务端对每次请求做读写判断,若是写请求,则把这次请求内的所有DB操作发向主库;若是读请求,则把这次请求内的所有DB操作发向从库。因系统压力主要是读请求,而从库又可水平扩展,当从库压力太时,可直接添加从库机器,缓解读请求压力。 暂时解决了MySQL压力问题,同时也带来了新的挑战,业务高峰期MySQL可能会出现主从延迟,极端情况,主从延迟高达10秒。
优化MySQL参数,比如增大innodb_buffer_pool_size(缓存池大小),让更多操作在MySQL内存中完成,减少磁盘操作。
使用高性能CPU主机。
数据库使用物理主机,避免使用虚拟云主机,提升IO性能。
使用SSD磁盘,提升IO性能。SSD的随机IO性能约是SATA硬盘的10倍。
业务代码优化,将实时性要求高的某些操作,使用主库做读操作。
2.数据横向和垂直方向分离,主库大表(订单表)
(1)做冷数据和热数据区分
-
热数据:3个月内的订单数据,查询实时性较高;
-
冷数据A:3个月 ~ 12个月前的订单数据,查询频率不高;对于这类数据可以存储在ES中,利用搜索引擎的特性基本上也可以做到比较快的查询
-
冷数据B:1年前的订单数据,几乎不会查询,只有偶尔的查询需求;对于这类不经常查询的数据,可以存放到Hive中;
(2)热数据如何再进一步拆分
a.按业务拆分
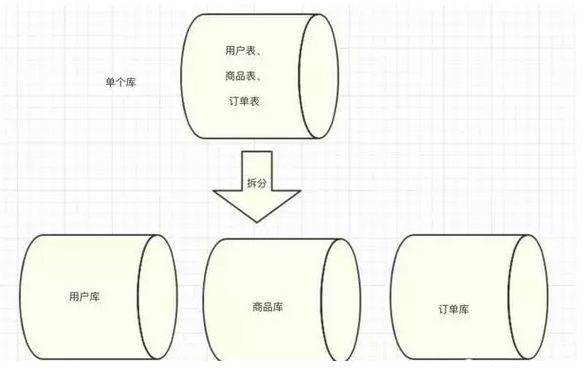
b.分库分表
根据order_id 进行分表规则,或根据user_id 进行分表规则,或根据商家id进行分表规则,具体要结合查询业务。
3.分布式锁的核心问题
(1)CAP理论:一致性、可扩展性、分区容错性
由于节点之间网络通信不可靠、节点处理时间无法保证;
一致性:强一致性、最终一致性,实践中,要保障系统满足不同程度的一致性,核心过程往往需要通过共识算法来达成。
事件发生的先后顺序十分重要,这也是解决分布式系统领域很多问题的核心秘诀:把多件事情进行排序,而且这个顺序还得是大家都认可的。最后一个合法性看似绕口,但是其实比较容易理解,即达成的结果必须是节点执行操作的结果。仍以卖票为例,如果两个售票处分别决策某张票出售给张三和李四,那么最终达成一致的结果要么是张三,要么是李四,而绝对不能是其他人。
(2)分布式事务
解决方案一:两阶段提交协议可以很好得解决分布式事务问题,它可以使用 XA 来实现,如TTC(try-commit-cancel)
解决方案二:消息中间件也可称作消息系统 (MQ),将消息实现幂等性,可实现消息的多次发送(订阅模式)
(3)负责均衡算法:随机、轮询、根据机器性能权重、根据最少连接数方法等
(4)分布式锁
基于数据库实现分布式锁
基于缓存(Redis,memcached,tair)实现分布式锁(基于 SETNX)
基于Zookeeper实现分布式锁(基于InterProcessMutex)
下面针对zookeeper实现分布式锁分析:基于zookeeper临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。
判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。
当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
来看下Zookeeper能不能解决前面提到的问题。
-
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
-
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
-
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
-
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
Curator提供的InterProcessMutex是分布式锁的实现。acquire方法用户获取锁,release方法用于释放锁。
使用Zookeeper实现分布式锁的优点
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
使用Zookeeper实现分布式锁的缺点
性能上不如使用缓存实现分布式锁。
4.分布式查询问题
使用汇总表。
5.分布式ID 唯一性
使用全局唯一 ID:GUID;
为每个分片指定一个 ID 范围。
6.数据库缓存层的优化
使用mysql查询缓存:query_cache_type:(0:不使用查询缓存,1:始终使用,2:按需使用);修改缓存大小:query_cache_size