Ceph rbd 存储原理
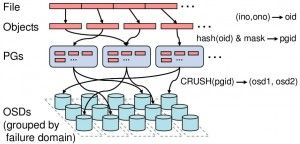
Ceph存储逻辑架构图
创建一个rbd
[root@node1 ~]# rbd create bar --size 2048
[root@node1 ~]# rados -p rbd ls
rbd_header.86f46b8b4567
rbd_directory
rbd_id.bar
rbd_children
rbd_info
rbd_trash
系统创建名为bar的rbd时会为期生成一个id,如:86f46b8b4567,那么该id的生成是否有一定的规则?是否每次生成的id是固定不变的?
经过如下反复验证:
[root@node1 ~]# rbd create bar --size 2048
[root@node1 ~]# rados -p rbd ls|grep rbd_header
rbd_header.add26b8b4567
[root@node1 ~]# rbd rm bar
Removing image: 100% complete...done.
[root@node1 ~]# rbd create bar --size 2048
[root@node1 ~]# rados -p rbd ls|grep rbd_header
rbd_header.add46b8b4567
[root@node1 ~]# rbd rm bar
Removing image: 100% complete...done.
[root@node1 ~]# rbd create bar --size 2048
[root@node1 ~]# rados -p rbd ls|grep rbd_header
rbd_header.87066b8b4567
[root@node1 ~]#
add26b8b4567
add46b8b4567
87066b8b4567
所以,通过验证发现其前4位会发生变化,后8位会固定不变,不变部分如何计算出还需以后再深入研究.
rbd_id.bar是什么文件?
[root@node1 ~]# rados -p rbd get rbd_id.bar rbd_id.bar
[root@node1 ~]# hexdump -vC rbd_id.bar
00000000 0c 00 00 00 38 37 30 66 36 62 38 62 34 35 36 37 |....870f6b8b4567|
00000010
[root@node1 ~]# file rbd_id.bar
rbd_id.bar: data
[root@node1 ~]# cat rbd_id.bar
870f6b8b4567
由以上输出得知,rbd_id.bar内保存的是为该rbd生成的id(870f6b8b4567),该值将用来作为此rbd切割成多个对象文件(如4M)的前缀的一部分,可以通过以下信息确认:
[root@node1 ~]# rbd info rbd/bar
rbd image 'bar':
size 2GiB in 512 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.870f6b8b4567
format: 2
features: layering
flags:
create_timestamp: Wed Apr 10 16:21:14 2019
block_name_prefix: rbd_data.870f6b8b4567
至此我们可以简单理解为通过文件:“rbd_id.”+ rbd名称 然后读取到其id值,即找到了入口.
向rbd写入数据
格式化该块设备,格式化也是个写入数据的过程,会将一些文件系统信息写入
[root@node2 ~]# rbd map bar
/dev/rbd0
[root@node2 ~]# mkfs.xfs /dev/rbd0
[root@node1 ~]# rados -p rbd ls|sort
rbd_children
rbd_data.870f6b8b4567.0000000000000000
rbd_data.870f6b8b4567.0000000000000001
rbd_data.870f6b8b4567.0000000000000040
rbd_data.870f6b8b4567.0000000000000080
rbd_data.870f6b8b4567.00000000000000c0
rbd_data.870f6b8b4567.0000000000000100
rbd_data.870f6b8b4567.0000000000000101
rbd_data.870f6b8b4567.0000000000000102
rbd_data.870f6b8b4567.0000000000000140
rbd_data.870f6b8b4567.0000000000000180
rbd_data.870f6b8b4567.00000000000001c0
rbd_data.870f6b8b4567.00000000000001ff
rbd_directory
rbd_header.870f6b8b4567
rbd_id.bar
rbd_info
rbd_trash
[root@node1 ~]#
我们发现新增了12个数据文件,其前缀都为rbd_data.870f6b8b4567,索引值为0-1ff,索引值共512个,这个值正是前面我们由创建时指定的2048M/4M=512得来.
每个对象文件对应的PG
一个rbd文件,由若干个4M大小的碎片组成,每个碎片独立存储,存储的第一步是对象->pg的映射,其过程如下:
-
通过对象名称(rbd_data.870f6b8b4567.0000000000000000)生成32位hash值.
如:hash(rbd_data.870f6b8b4567.0000000000000000) = 49fe99ae -
通过取余运算确定几号pg
which_pg = hash_value mode pg_num
如:49fe99ae mod 8 = 6
pg_num可以通过ceph osd pool get rbd pg_num获得.示例如下:
[root@node1 ~]# ceph osd map rbd rbd_data.870f6b8b4567.0000000000000000
osdmap e130 pool 'rbd' (9) object 'rbd_data.870f6b8b4567.0000000000000000' -> pg 9.49fe99ae (9.6) -> up ([1,2,0], p1) acting ([1,2,0], p1)
以上输出:pg 9.49fe99ae (9.6) 说明
对象的hash值为:49fe99ae
pool id 为:9
所属pg为:6
pg对应的osd
OSD是通过以下算法得出:
OSDs_for_pg = crush(pg)
returns a list of OSDs
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
示例:
[root@ceph-node1 bar]# ceph osd map rbd rbd_data.10b36b8b4567.000000000000005d
osdmap e20 pool 'rbd' (0) object 'rbd_data.10b36b8b4567.000000000000005d' -> pg 0.f7337263 (0.23) -> up ([1,2,0], p1) acting ([1,2,0], p1)
以上输出:up ([1,2,0], p1) 说明该对象存在于osd 1 2 0上
对象在osd上的存储
由上一步骤得知,对象存在于1、2、0号osd上,即三副本,那么到任何一个osd上都可以找到该对象.
[root@ceph-node1 ~]# cd /var/lib/ceph/osd/ceph-0/current/0.23_head
[root@ceph-node1 0.23_head]# ls
__head_00000023__0 rbd\udata.10b36b8b4567.000000000000005d__head_F7337263__0
[root@ceph-node1 0.23_head]# md5sum rbd\\udata.10b36b8b4567.000000000000005d__head_F7337263__0
\885b4ad54fd3252539a8a0509395371f rbd\\udata.10b36b8b4567.000000000000005d__head_F7337263__0
[root@ceph-node1 0.23_head]#
[root@ceph-node1 ~]# rados -p rbd get rbd_data.10b36b8b4567.000000000000005d rbd_data.10b36b8b4567.000000000000005d
[root@ceph-node1 ~]# md5sum rbd_data.10b36b8b4567.000000000000005d
885b4ad54fd3252539a8a0509395371f rbd_data.10b36b8b4567.000000000000005d
由以上输出得知使用rados get到的数据文件与osd实际存储的是同一个文件.