ElasticSearch为啥那么快?总结一下
思考问题:
- 为什么搜索是近实时的?
- 为什么文档的CRUD是实时的?
下图是云上一个集群
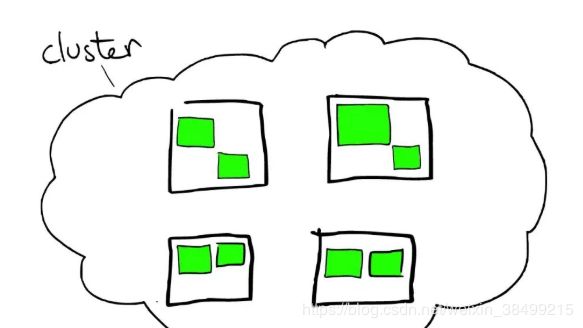
集群中有多个节点
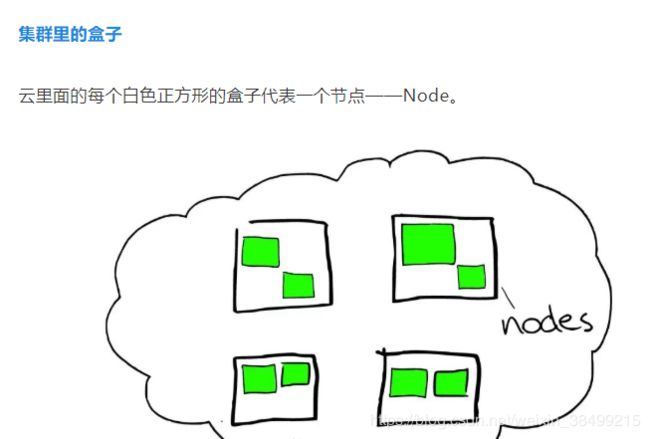
索引可以跨节点组成
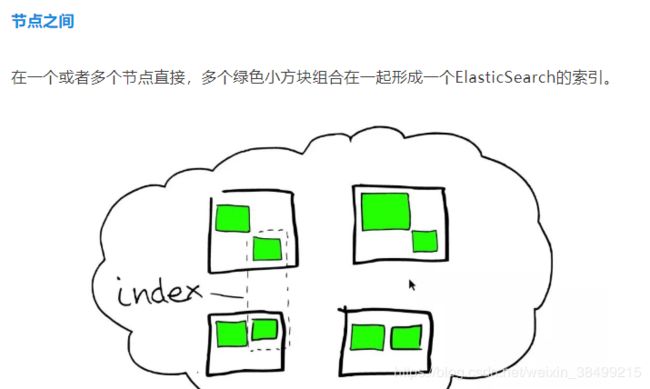
在一个索引下,存储着分片,分片实际上是Lucene Index.
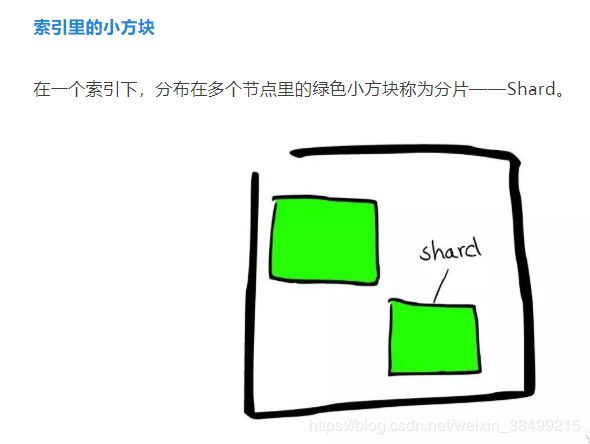
Shard分片里面存储着segment,可以看成是Lucene内部的mini-index

那么segment有啥呢?
-
Inverted Index
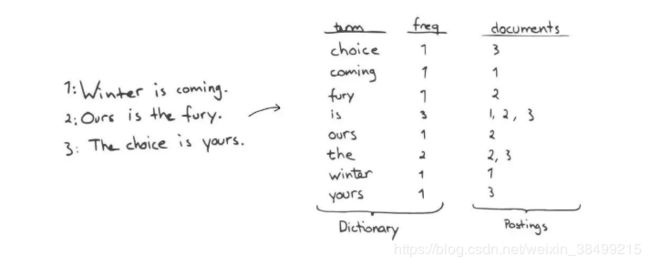
主要包括两部分:倒排索引
1.一个有序的数据字典Dict(term:freq 是Key:Value)
2.与单词Term对应的Postings,即存在这个单词的文件
-
自动补全
如果要查找以“c”开头的字母,可以简单通过二分查找找到相关的词

但如果是要查找包含"our"字母的单词,系统会扫描整个Inverted Index

possible solution: -
把Term翻转,就可以看作以后缀作为搜索条件
-
(60.6384, 6.5017) -> u4u8gyykk 对于地理位置信息可以转化为GEOHASH
-
对于数字而言,可以生成多重形式的Term
-
Stored Fields
如果要查找包含某个特定标题内容的文件,就需要使用Stored Fields,本质上这是一个Key-value,key为标题名称,value为整个文档

- Document Values
用来解决排序,聚合,facet问题。因为可能会读取大量不需要的信息。
可以使用Document Values.本质上是个传统的列式存储

为了提高效率,es还可以把索引下某一个Doucment Value全部送到内存中,充分利用缓存,这也是为什么es如此耗内存
搜索segment的时候会发生什么?
Lucene会搜索所有的segment然后把每个segment的搜索结果返回,最后合并呈现给客户。
segment需要拥有以下特性:
1.segment不可变
2.delete操作,Lucene只会把segment对应的标志位置删除,但是segment文件本身不删除
3.update?对于更新来说,本质上是先删除,然后重新索引
4.压缩,Lucene实现了主流的压缩方式
5.Lucene会把所有的信息做缓存
- Cache
es怎么利用缓存?
当es对一个文件做索引的时候,会为文件建立相应的缓存,并且定期刷新这些数据,这些文件就可以被搜索到。
随着时间增加,会产生很多segments,所以最后es会把segment删掉。
举个例子:
这里有两个segment,会发生merge
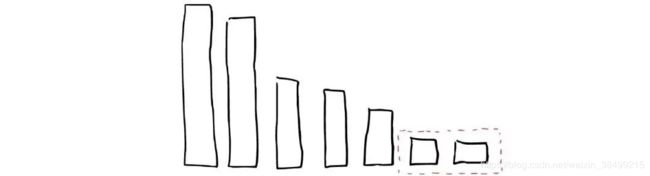
然后被合并的两个segment最终会被删除,然后合并成一个新的segment.这时候这个新的segment在缓存中处于冷数据,其他segment属于warm数据。
- 如何在分片(shard)搜索?
es从Shard中搜索过程与Lucene Segment中搜索过程类似
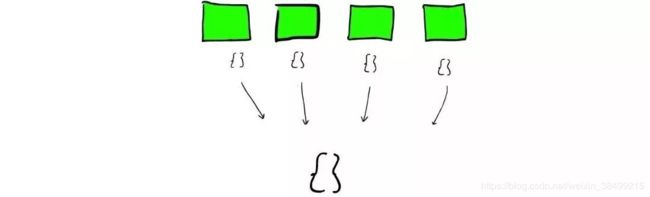
与Lucene Segment中搜索不同的是,Shard可能是分布在不同的节点上,所以搜索与返回结果的时候,所有信息会经过网络传输,因此不同节点网络传输速度也是es的一个性能瓶颈
1次搜索查找2个Shard = 2次分别搜索Shard
- 对于日志文件处理
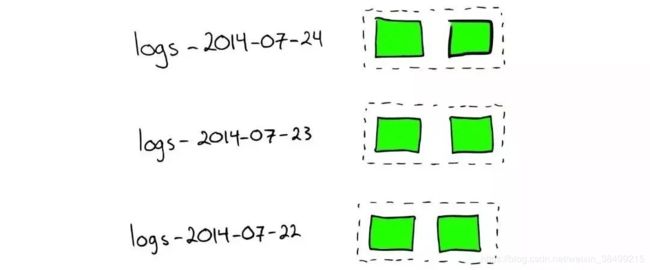
如果想要搜索特定日期产生的日志,可以通过根据时间戳对日志文件进行分块与索引。
如果要删除旧数据,只要删除老的索引就行。
-
如何做Scaling?
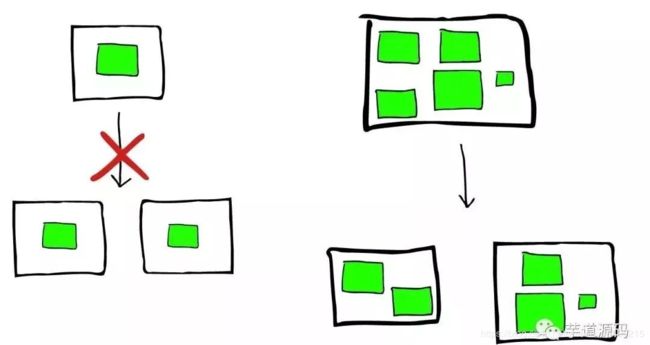
-
Shard不会进行更加进一步的划分,但是Shard可能会被转移到不同节点上。
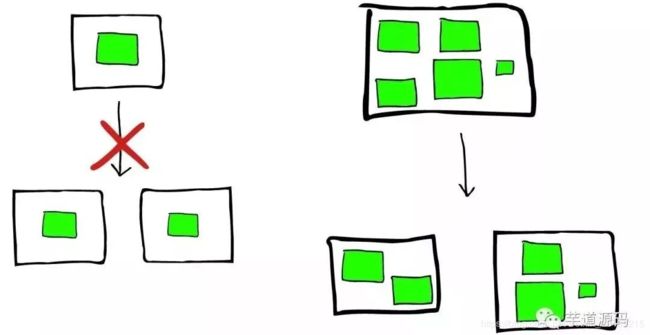
但是如果集群节点压力增长到一定程度,我们会考虑增加新的节点,这就要求我们对所有数据进行重新索引,性能损耗会比较大。
- 节点分配与Shard优化
为更重要的数据索引节点分配性能更好的机器
同时要确保每个Shard有副本信息replica
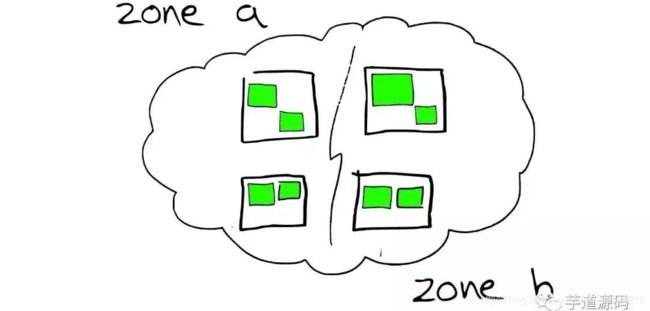
- 路由 routing
每个节点都会保存一份路由表,所以当请求到任何一个节点,es都有能力把请求转发到期望节点的Shard进一步处理
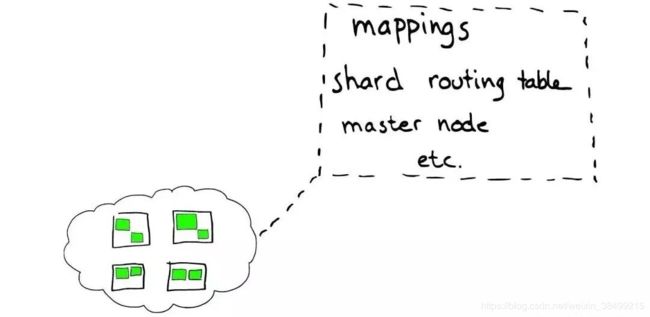
我们从请求开始过一遍整个过程
es的请求都是要通过RESTful API发起

- 请求分发
收到请求后,可能会被分发到集群中的任意一个节点
这个时候集群中的协调者Coordinator就叫做上帝节点
作用:根据索引决定请求被路由到哪个核心节点
以及哪个副本是可用的
搜索之前。。。
es会把Query转换成Lucene Query
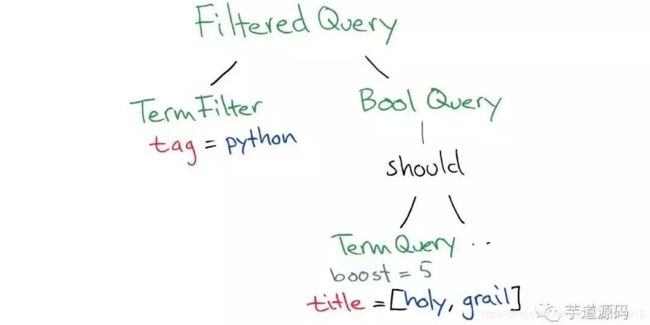
然后sql会在所有的segment中执行计算
- 找到segment之后怎么返回?
沿着刚才的路径沿路返回:
segment-> shard -> 路由回上帝节点-> 上帝节点返回给客户端
Part2: es 基本概念
| 关系型数据库 | es |
|---|---|
| 数据库 | 索引 |
| 表 | 类型(type,es7.x废弃) |
| 行 | 文档 |
| 列(Columns) | 字段(Fields) |
| 表 | mapping |
field: 用于表达信息所在的位置(如在标题中,在文章中,在url中)
集群: 由一个或者多个节点组成,对外提供服务
节点:可以存储数据,也可以参与集群的索引和搜索功能
复制:高可用,解决单点问题
分片:每个索引都有多个分片,每个分片都是一个Lucene索引,用于水平分割扩展数据
- 主分片
每个文档存储在一个分片,存储文档的时候,系统会先存储在主分片中,然后复制到不同的副本中.
- 副本分片
索引
对于B+/B-树,RBT的比较,可以参考
RBTree
- 什么是倒排索引?

| Term | Posting List |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
倒排索引包含了啥?
每一个term 对应了一个posting list,就是出现过这个term的文档的编号,注意posting list的编号是有序的
- Posting List
posting list是一个int的数组,存储了所有符合某个term的文档id
- Term Dict
为了能够快速找到某个term,需要使用二分法以logN时间复杂度查找某个term
- Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能.
es更绝,直接把term组织成term index,直接压缩放在内存中,不用读磁盘
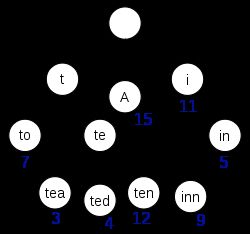
term index会包含term的前缀,通过term index可以快速定位到term dict的某个offset,然后根据term dict的某个term查找对应的posting list
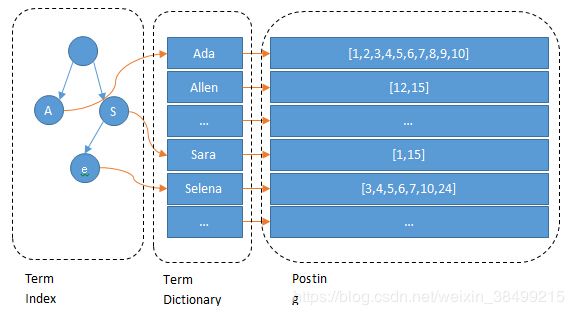
term index本质上就是一棵树,不需要存下所有的term,而仅仅是它们的一些前缀与term dictionary与block之间的映射关系.
接下来我们介绍es设计的压缩技术,以及es是用哪一种数据结构来做字典呢?
在此之前,我们总结一下有哪些数据结构适合来做字典?
| 数据结构 | 状态 |
|---|---|
| Array/List | 二分法不平衡 |
| HashMap/TreeMap | 性能高,内存损耗大 |
| Skip List | 适合高并发场景 |
| Trie | 公共前缀树 |
| Double Array Trie | 适合做中文词典 |
| 三叉树 | 每一个node有3个节点,兼具省空间和查询快的优点 |
| FST | 有限状态转移机 |
- Finite State Transducer
es使用FST来压缩term index
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2)查询速度快。O(len(str))的查询时间复杂度。
无权FST的构建过程:
- 插入"cat"

- 插入"deep"
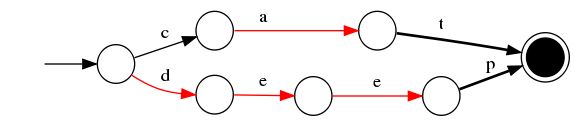
- 插入"do",与deep做最大前缀匹配
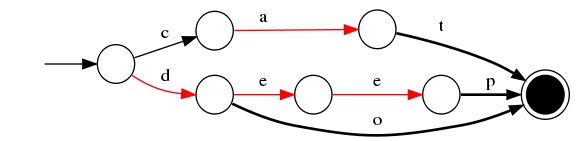
- 插入"dogs"
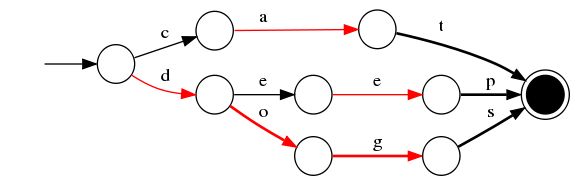
以下是有权重FST的构建,字母后面的数字代表权重
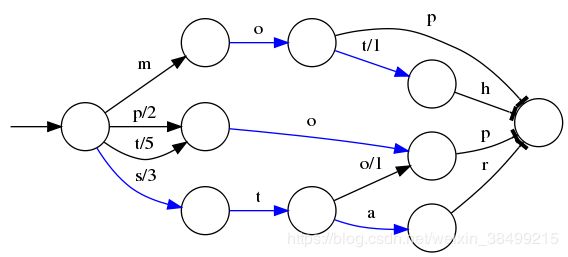
- posting list是怎么压缩呢?
如果我们是对性别做索引,因为性别只有两种,每个posting list都会有至少百万个文档id,那么传统关系型数据库会哭晕在厕所
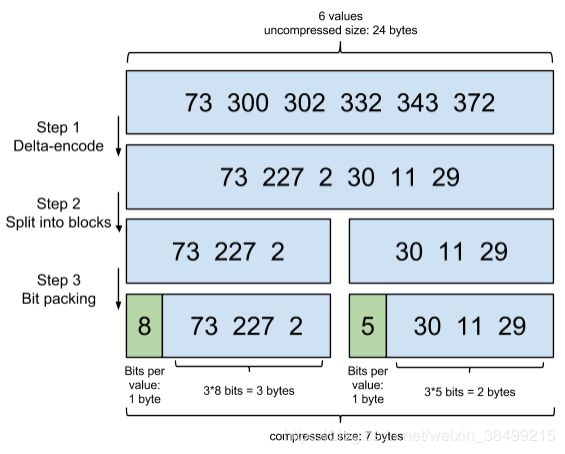
step1: 把原来排序的大数转化为小数,即仅存储增量值
step2: 分到不同的block 存储
step3: 精打细算使用bit,
例如 73 227 2 这个blcok,那么最多需要8bit来存储(0-255)
例如 30 11 29 最多需要5bit来存储(0-31)
然后需要额外一个byte来存储这个block用多少bit来存数据
另外一种方法是
- Roaring bitmaps 位图压缩算法
什么叫位图?
例如对于某个posting list:
[1,3,4,7,10]
对应可以使用
[1,0,1,1,0,0,1,0,0,1]
来表示,即某个数字代表这个数字的位为1
bitmap缺点是,存储空间会随着文档个数线性增长
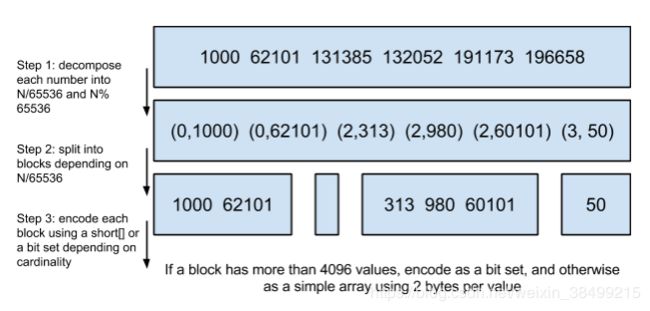
step 1: 将排序后的文档index做 N/65536,化为(商,余数)形式
step 2: 根据商来划分不同的block
为什么这里用65536?
余数就是0-65535,也就是2^16-1,刚好是两个字节,可以直接用short来存储不同的数字
为什么一个块大于4096个数字的时候,用bitset来存,小于4096是用short?
65526 / (2*8) 保证每个数字都能用short来存
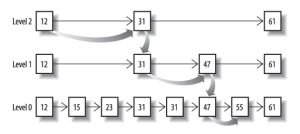
- 如果对多个field索引做联合查询呢?
1.可以利用跳表
把一个有序链表level0,选出其中几个元素到level1,以此类推
查询效率与二叉树类似
2.可以利用上面提到的bitset做"&"操作
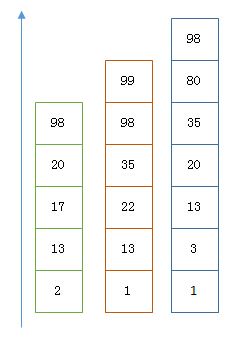
如果要用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找是否存在,最后得到交集的结果
如果使用bitset,更加直观,直接按位做"&",得到结果就是最后交集
- 总结
把磁盘数据尽量写入内存中,
从而尽可能减少磁盘随机读取IO次数
然后使用各种奇怪的压缩算法来压缩倒排索引的数据结构
优化
1.建立索引的优化
- 默认对所有字段建立索引,所以不需要索引的字段,需要明确定义出来
- 对于String 类型字段,不需要analysis的也需要明确定义
- 避免ID随机性太大的情况
2.分片
索引在es中是一组文档的集合
分片指的是,因为es是个分布式搜索引擎,所以索引通常会分布在不同的节点.这些分布在不同节点上的数据就是分片,es会自动管理和组织分片,并且在必要的时候对分片数据进行reblance
副本是保持高可用
分片配置不能随意改变,如果要改动就需要reindex
- 每个分片本质上就是一个Lucene索引,因此会消耗相应的文件句柄,内存和CPU资源
- 每个搜索请求会调度到索引的每个分片中,所以分片要尽可能分散在不同节点,当分片开始竞争相同的硬件资源的时候性能就会下降
ref
https://www.zhuanzhi.ai/document/4f97036243052fd5577c0ecf188b06dd
https://www.jianshu.com/p/b50d7fdbe544
https://www.cnblogs.com/dreamroute/p/8484457.html