机器学习集成学习 Ensemble Learning(常用集成算法汇总)
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting)或改进预测(stacking)的效果。集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
目前主要的集成学习算法类型有Voting, Bagging, Boost , Stacking。
目录
一、Voting 投票
二、Bagging
三、Boosting
五、stacking
一、Voting 投票
1、voting原理
假设有1000种分类器,每个分类器预测的正确率只有50.5%,如果以预测类别最多的作为预测结果,则准确率可达到60%,如果有10000种分类器,则准确率可达到84%左右。该结果的前提是分类器彼此独立,但是现实中它们都在同一个数据集上进行训练,可能会犯同样的错误,所以准确率会有降低。
2、Voting可以分为硬投票法(Harding Voting)和软投票法(Soft Voting)
-- 硬投票法
根据分类器预测的结果出现最多的类别作为预测值。
-- 软投票法
如果所有分类器都能够估算出类别的概率,那么对所有分类器的类别概率求平均,然后给出平均概率最高的类别作为预测。
通常来说,它比硬投票法的表现更优,因为它给予那些高度自信的投票更高的权重。
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
lr = LogisticRegression()
dt = DecisionTreeClassifier()
svm = SVC() # 若是soft voting,则probability=True
voting = VotingClassifier(
estimators=[('lr',lr),('rf',dt),('svc',svm)],
voting='hard' # 软投票法,voting='soft'
)二、Bagging
1、原理
bagging中每个基学习器采用的是相同的算法,分别在各自随机抽取(有放回的采样)的子数据集上进行训练,预测的结果出现最多的类别作为预测值。
# bootstrap = True 为bagging,bootstrap=False为pasting(无放回采样)
# max_samples设置为整数表示的就是采样的样本数,设置为浮点数表示的是max_samples*x.shape[0]
bag_clf = BaggingClassifier(
SVC(),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1
# ,oob_score=True
)2、随机森林 RandomFroest
随机森林是决策树的集成,通常用bagging方法进行训练。
# 如果基分类器是决策树,那么该bagging算法就是随机森林
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1
)
# 上面等同于sklearn提供的RF的API
rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1)
rnd_clf.fit(X, y)
print(rnd_clf.__class__.__name__, '=', accuracy_score(y, y_hat))三、Boosting
Boosting算法要涉及到两个部分,加法模型和前向分步算法。加法模型就是说强分类器由一系列弱分类器线性相加而成;前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。
1、AdaBoost
每一轮如何改变训练数据的权值:AdaBoost改变了训练数据的权值,也就是样本的概率分布,其思想是将关注点放在被错误分类的样本上,减小上一轮被正确分类的样本权值,提高那些被错误分类的样本权值。然后,再根据所采用的一些基本机器学习算法进行学习,比如逻辑回归。
如何将弱分类器组合成一个强分类器:AdaBoost采用加权多数表决的方法,加大分类误差率小的弱分类器的权重,减小分类误差率大的弱分类器的权重。这个很好理解,正确率高分得好的弱分类器在强分类器中当然应该有较大的发言权。
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
rf = DecisionTreeClassifier()
model = AdaBoostClassifier(base_estimator=rf,n_estimators=50,algorithm="SAMME.R", learning_rate=0.5)
model.fit(X_train,y_train)
y_train_hat = model.predict(X_train)2、GBDT
GBDT模型是一个集成模型,基分类器采用CART,集成方式为Gradient Boosting。GBDT基于boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。它不像AdaBoost那样在每个迭代中调整实例权重,而是让新的预测器针对前一个预测器的残差进行拟合。
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
gbdt = GradientBoostingRegressor(max_depth=5, n_estimators=3, learning_rate=1.0)3、XGBoost
XGBoost的核心思想是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数f(x),去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数。最后只需要将每棵树对应的分数加起来就是该样本的预测值。
XGBoost对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想没有大的变化。
import xgboost as xgb
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
model =xgb.XGBClassifier(max_depth=3,learning_rate=0.3,n_estimators=6,silent=True,objective='binary:logistic')
model.fit(X_train,y_train)
# 训练集上准确率
train_preds = model.predict(X_train)
train_accuracy = accuracy_score(y_train, train_preds)
# 测试集上准确率
preds = model.predict(X_test)
test_accuracy = accuracy_score(y_test, preds)
print("Test Accuracy: %.2f%%" % (test_accuracy * 100.0))-- 使用GridSearchCV(网格搜索交叉验证)搜索最优参数
from sklearn.model_selection import GridSearchCV
model = xgb.XGBClassifier(learning_rate=0.1, silent=True, objective='binary:logistic')
param_grid = {
'n_estimators': range(1, 51, 1),
'max_depth':range(1,10,1)
}
clf = GridSearchCV(model, param_grid, "accuracy",cv=5)
clf.fit(X_train, y_train)
print(clf.best_params_, clf.best_score_)-- 我们设置验证valid集,当我们迭代过程中发现在验证集上错误率增加,则提前停止迭代
from sklearn.model_selection import train_test_split
X_train_part, X_validate, y_train_part, y_validate = train_test_split(X_train, y_train, test_size=0.3,random_state=0)
# 设置boosting迭代计算次数
num_round = 100
bst =xgb.XGBClassifier(max_depth=2, learning_rate=0.1, n_estimators=num_round, silent=True, objective='binary:logistic')
eval_set =[(X_validate, y_validate)]
bst.fit(X_train_part, y_train_part, early_stopping_rounds=10, eval_metric="error",
eval_set=eval_set, verbose=True)
results = bst.evals_result()-- 错误率可视化
results = bst.evals_result()
#print(results)
epochs = len(results['validation_0']['error'])
x_axis = range(0, epochs)
# plot log loss
plt.plot(x_axis, results['validation_0']['error'], label='Test')
plt.ylabel('Error')
plt.xlabel('Round')
plt.title('XGBoost Early Stop')
plt.show()-- 学习曲线
# 设置boosting迭代计算次数
num_round = 100
# 没有 eraly_stop
bst =xgb.XGBClassifier(max_depth=2, learning_rate=0.1, n_estimators=num_round, silent=True, objective='binary:logistic')
eval_set = [(X_train_part, y_train_part), (X_validate, y_validate)]
bst.fit(X_train_part, y_train_part, eval_metric=["error", "logloss"], eval_set=eval_set, verbose=True)
# retrieve performance metrics
results = bst.evals_result()
#print(results)
epochs = len(results['validation_0']['error'])
x_axis = range(0, epochs)
# plot log loss
fig, ax = plt.subplots()
ax.plot(x_axis, results['validation_0']['logloss'], label='Train')
ax.plot(x_axis, results['validation_1']['logloss'], label='Test')
ax.legend()
plt.ylabel('Log Loss')
plt.title('XGBoost Log Loss')
plt.show()
# plot classification error
fig, ax = plt.subplots()
ax.plot(x_axis, results['validation_0']['error'], label='Train')
ax.plot(x_axis, results['validation_1']['error'], label='Test')
ax.legend()
plt.ylabel('Classification Error')
plt.title('XGBoost Classification Error')
plt.show()
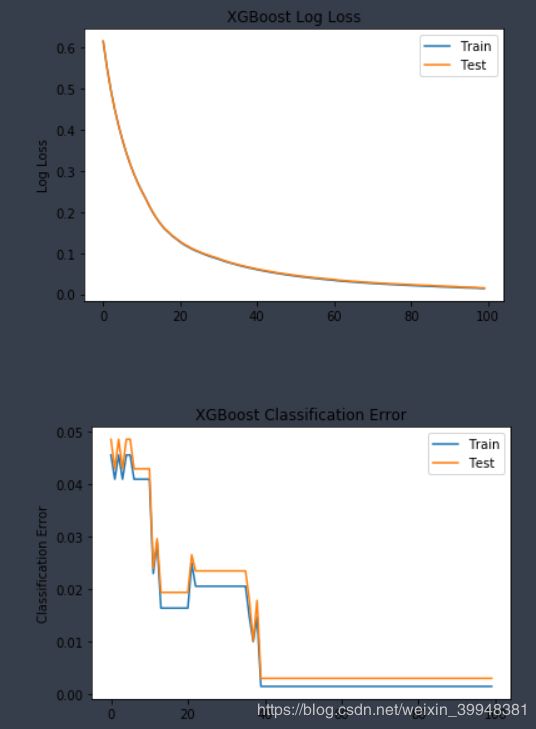
注:xgboost详细参数讲解及代码实现,传送门在此。
五、stacking
stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。
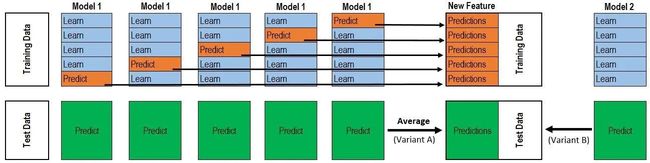
如图所示,我们现在用5折交叉验证来训练数据,model1要做满5次训练和预测。
第一次,M1,拿traindata的800行做训练集,200行做验证集,然后预测出200行的数据a1。
第二次,M1,拿traindata的800行做训练集,200行做验证集,然后预测出200行的数据a2。
第三次,M1,拿traindata的800行做训练集,200行做验证集,然后预测出200行的数据a3。
第四次,M1,拿traindata的800行做训练集,200行做验证集,然后预测出200行的数据a4。
第五次,M1,拿traindata的800行做训练集,200行做验证集,然后预测出200行的数据a5。
然后将a1到a5拼接起来,得到一列,共1000行的数据。
针对测试集testdata有两种方法,一种是全部训练完成后,一次性预测输出200行数据;另一种是M1每次做完训练就那testdata中的数据做预测,一种得到5次200行的数据,然后做平均,得到一列200行的数据。
如果有10个基模型,那么根据traindata会得到10列数据,作为x,原来traindata中的label作为y(很多文章都没说这点,导致初学者有很多误解),然后再放到一个模型中做训练。而根据testdata会得到10列200行的数据,作为测试数据。
最后,将训练好的模型预测10列200行的数据,得到的最终结果就是最后需要的数据。
# sklearn并没有集成stacking,使用前需用如下命令安装 pip install mlxtend
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y.ravel(), train_size=0.8, random_state=0)
# 定义基分类器
clf1 = KNeighborsClassifier(n_neighbors=5)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
# 定义最后输出的分类器
lr = LogisticRegression()
# 定义堆叠后的模型
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr,use_probas=True)
# 对每一个类分类器进行打分
for model in [clf1,clf2,clf3,lr,sclf]:
model.fit(X_train,y_train)
y_test_hat = model.predict(X_test)
print(model.__class__.__name__,',test accuarcy:',accuracy_score(y_test,y_test_hat))