使用Python,创建你的第一个实用型入门机器学习项目(上)
前言
注:本文分上、下两部分。
你是否想使用Python来进行机器学习,但是你又不知从何处入门。本文将引导你从无到有创建一个实用型机器学习项目。
如果您是机器学习初学者,并且希望最终开始使用Python,那么本教程就是为您设计的。
这篇文章是个分步教程,在这篇文章中,您将使用Python完成您的第一个机器学习项目。
来吧,少年,让我们开始吧,学习完本教程,你一定会有意想不到的收获。
在这个分步教程中,您将:
下载并安装Python SciPy,并获得Python中机器学习最有用的软件包。
使用统计摘要和数据可视化加载数据集并了解其结构。
创建6个机器学习模型,挑选最好的,并建立准确性可靠的,对其有信心的模型。

你的第一个分步机器学习项目
你如何启动Python的机器学习?
学习机器学习的最佳方式是设计和完成小型项目。不是么?
Python入门时可能会感到恐惧
Python是一种流行且强大的解释型语言。 与R不同,Python是一种完整的语言和平台,可用于研发和开发生产系统。
还有很多模块和库可供选择,提供多种方式来完成每项任务,它在机器学习的领域有某些压倒性优势。
开始使用Python进行机器学习的最佳方式是完成一个项目。
它会迫使你安装并启动Python解释器(至少)。
它将让您全面了解如何通过一个小型项目。
它会给你信心,也许会继续你自己的小项目。
机器学习初学者需要一个小型的端到端项目
书籍和课程有时令人沮丧。 它们给你很多零散的“食谱”和片段,但你永远不会看到它们是如何融合在一起的。
当您将机器学习应用于自己的数据集时,恭喜您,您正在开发一个项目。
机器学习项目可能不是线性的,但它有许多众所周知的步骤:
定义问题。
准备数据。
评估算法。
改善结果。
展现结果。
真正接触新平台或新工具的最佳方法是通过机器学习项目进行端到端的工作,并涵盖关键步骤。 即从加载数据,汇总数据,评估算法和做出一些预测。
如果可以这样做,则可以在数据集之后使用数据集上的模板。 一旦你有了更多的信心,你可以填补进一步数据准备和改进结果任务等空白。
开始你的机器学习中的“Hello World”项目
在机器学习项目中,开始使用新工具的最佳小项目是“虹膜花的分类项目”(例如虹膜数据集:https://archive.ics.uci.edu/ml/datasets/Iris)。
这是一个很好的项目,因为它很好理解。
属性是数字的,所以你必须弄清楚如何加载和处理数据。
这是一个分类问题,使您可以练习一种更简单的监督式学习算法。
这是一个多级分类问题(多名义),可能需要一些专门的处理。
它只有4个属性和150行,这意味着它很小,很容易适应内存(和屏幕或A4页面)。
所有的数字属性都是相同的单位和相同的比例,不需要任何特殊的缩放或变换来开始。
让我们开始使用Python中的hello world机器学习项目。
Python中的机器学习:分步教程(从这里开始)
在本节中,我们将通过一个小型机器学习项目进行端到端的工作。
以下是我们将要讨论的内容的概述:
安装Python和SciPy平台。
加载数据集。
总结数据集。
可视化数据集。
评估一些算法。
做一些预测。
慢慢来,贯穿每一步。尝试自己输入命令或复制并粘贴命令以加快速度。
1. 下载,安装和启动Python SciPy
如果你的系统尚未安装Python和SciPy,请首先安装Python和SciPy。
我不想详细说明这一点,因为其他许多文章已经有了。 这已经非常简单了,特别是如果你是开发人员。 如果您确实需要帮助,请在评论中提问。请参考下面的文章来安装Python和SciPy,还有其它相关库。
https://www.toutiao.com/i6527849716116357639/
2. 加载数据集
我们将使用虹膜花数据集。 这个数据集很有名,因为它几乎是每个人都用作机器学习和统计中的“hello world”数据集。
该数据集包含了对虹膜花的150个观察结果。 有四列测量的花朵以厘米为单位。 第五列是观察到的花的种类。 所有观察到的花属于三种物种之一。
您可以在维基百科上了解有关此数据集的更多信息:
https://en.wikipedia.org/wiki/Iris_flower_data_set
在这一步中,我们将从CSV文件URL中加载虹膜数据:
https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
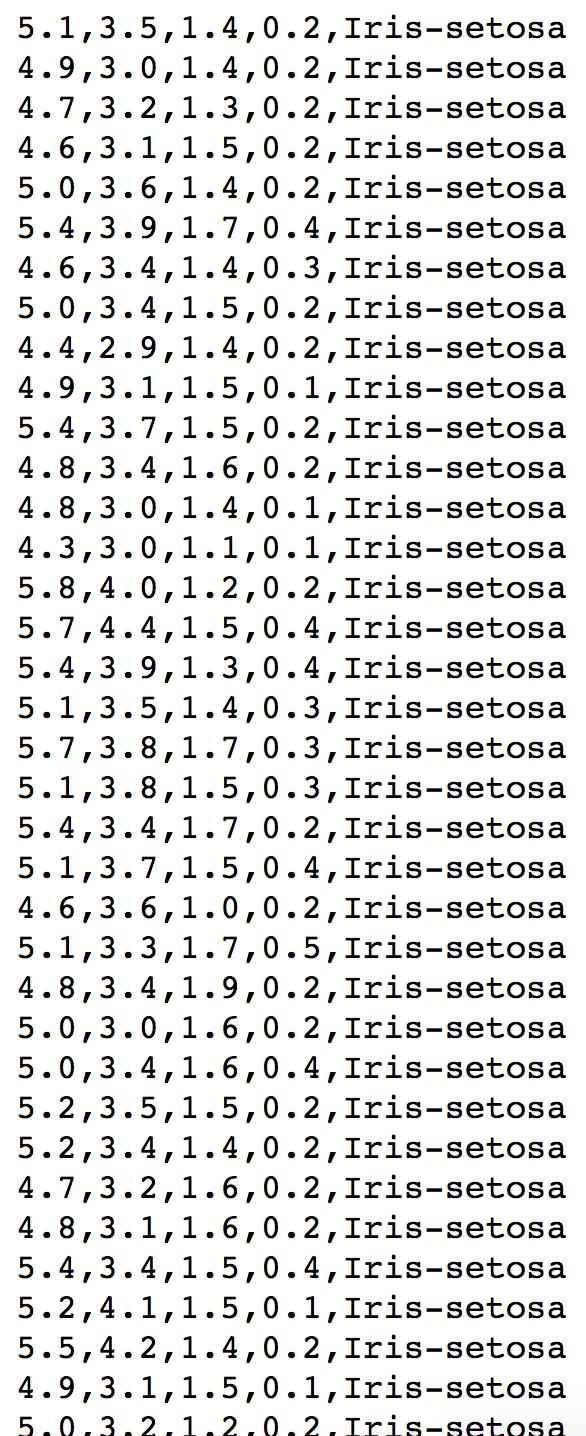
部分虹膜数据
2.1 导入库
首先,让我们导入本教程中要使用的所有模块,函数和对象。
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
import pandas
from pandas.plotting import scatter_matrix
一切都应该加载没有错误。 如果您有错误,请停止。 在继续之前,您需要一个有效的SciPy环境。 请参阅下午有关设置您的环境的建议。
https://www.toutiao.com/i6527849716116357639/
2.2 加载数据集
我们可以直接从UCI Machine Learning存储库加载数据。
我们正在使用pandas来加载数据。 下一步,我们还将使用pandas以描述统计和数据可视化的方式探索数据。
请注意,我们在加载数据时指定每列的名称。 这将有助于我们稍后探索数据。
dataset_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(dataset_url, names=names)
这个数据集加载应该没有问题。
如果确实有网络问题,可以将iris.data(https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data)文件下载到工作目录中,并使用相同的方法加载它,将URL更改为本地文件名。
3 总结数据集
现在是时候看看数据了。
在这一步中,我们将用几种不同的方式来看看数据:
数据集的维度。
查看、预览数据。
所有属性的统计汇总。
按类变量分解数据。
别担心,每看一个数据就是一个命令。 这些是有用的命令,您可以在未来的项目中反复使用这些命令。
3.1 数据集的维度
我们可以通过shape属性快速了解数据包含多少个实例(行)以及多少个属性(列)。
# shape
print(dataset.shape)
你应该看到150个实例和5个属性:
(150, 50)
3.2 查看、预览数据
实际观察你的数据也是一个好主意,可以使你获得一些感性的认识。
print(dataset.head(20))
你应该看到数据的前20行:
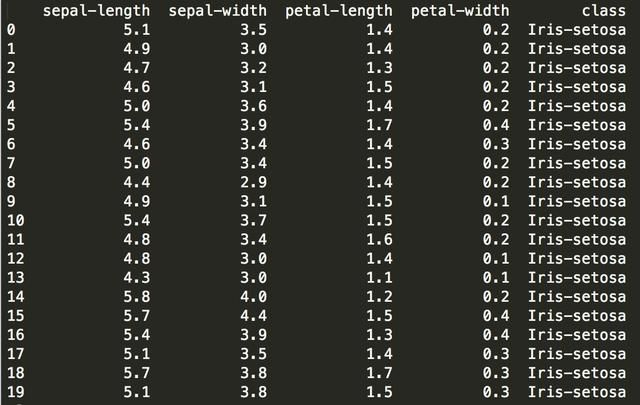
预览数据
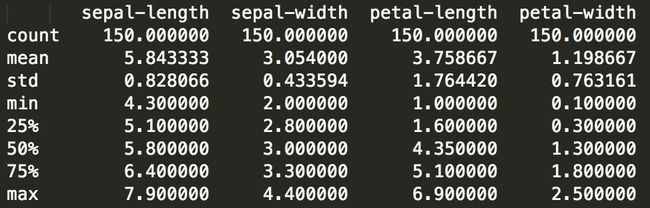
3.3 统计摘要
现在我们可以看看每个属性的摘要。
这包括计数,平均值,最小值和最大值以及一些百分位数。
print(dataset.describe())
我们可以看到所有的数值具有相同的尺度(厘米),并且在0和8厘米之间具有相似的范围。
3.4 数据类型的分布
现在我们来看看属于每个类的实例(行)的数量。 我们可以将此视为绝对计数。
print(dataset.groupby('class').size())

4. 数据可视化,模型和期望
本内容将在下篇文章中介绍,敬请期待。
注:本文分上、下两部分。