抖音用户信息爬取案例
抓包。抓到了一个share_url
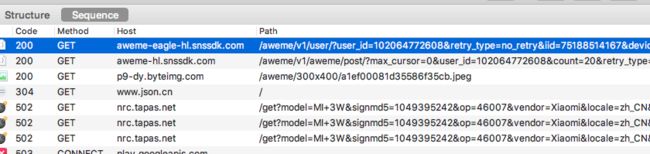
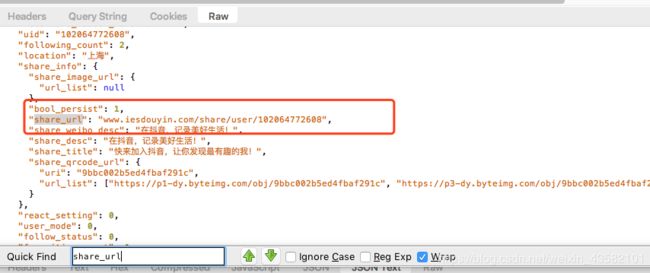
我访问过去看了下,
https://www.iesdouyin.com/share/user/102064772608
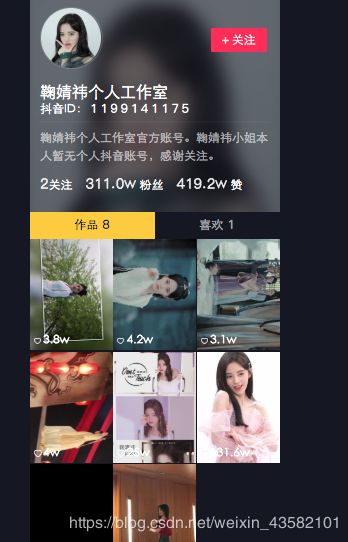
有数据的。那就拿数据。
然后发现它的数字做了字符集映射。
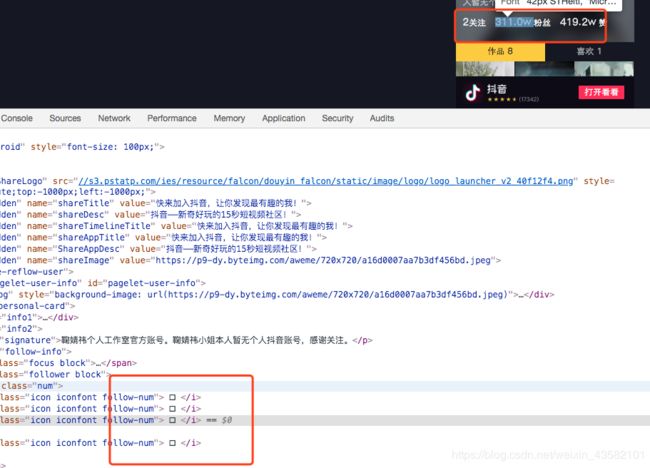
搞他。
下载.ttf的文件,s3a.bytecdn.cn/ies/resource/falcon/douyin_falcon/static/font/iconfont_da2e2ef.ttf,这个便用font creator软件打开,看到这个图片我们就明白了字体与数字的关系

既然我们看到num_对应数字1,num_8对应数字7,那这个num_8们怎么得到,与‘ ’有啥关系?
2.这个时候,需要大家安装pip install fontTools,使用fontTool打开ttf文件转化成xml文件,
采用下面代码
from fontTools.ttLib import TTFont
font_1 = TTFont('douyin.ttf')
font_1.saveXML('font_1.xml')
我们看到了font_1.xml,

这就能看出来了。
import re
def getDouyinNum(douIDNumCode):
mapCode2Font = {
'0xe602': 'num_',
'0xe603': 'num_1',
'0xe604': 'num_2',
'0xe605': 'num_3',
'0xe606': 'num_4',
'0xe607': 'num_5',
'0xe608': 'num_6',
'0xe609': 'num_7',
'0xe60a': 'num_8',
'0xe60b': 'num_9',
'0xe60c': 'num_4',
'0xe60d': 'num_1',
'0xe60e': 'num_',
'0xe60f': 'num_5',
'0xe610': 'num_3',
'0xe611': 'num_2',
'0xe612': 'num_6',
'0xe613': 'num_8',
'0xe614': 'num_9',
'0xe615': 'num_7',
'0xe616': 'num_1',
'0xe617': 'num_3',
'0xe618': 'num_',
'0xe619': 'num_4',
'0xe61a': 'num_2',
'0xe61b': 'num_5',
'0xe61c': 'num_8',
'0xe61d': 'num_9',
'0xe61e': 'num_7',
'0xe61f': 'num_6',
}
mapFont2Num = {
'num_': 1,
'num_1': 0,
'num_2': 3,
'num_3': 2,
'num_4': 4,
'num_5': 5,
'num_6': 6,
'num_7': 9,
'num_8': 7,
'num_9': 8,
}
douIDNum = ''
map1 = {}
if douIDNumCode == '':
return ''
for i in douIDNumCode:
j = i.replace(' &#', '0').replace('; ', '')
map1[j] = str(mapFont2Num[mapCode2Font[j]])
return map1
def req(share_id):
url2= 'https://www.iesdouyin.com/share/user/{}'.format(share_id)
headers ={
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/74.0.3729.169 Safari/537.36"
}
res=requests.get(url2,verify=False,headers=headers)
return res
def parse(res):
description_header = re.findall('抖音ID: (.*?) ',res.text,re.S)
description_back = re.findall('(.*?)',res.text,re.S)
mapDict = getDouyinNum(douIDNumCode=description_back)
res = description_header[0]
for i,j in mapDict.items():
res = res.replace(' &#'+i[1:]+'; ',j)
print(res)
if __name__ == '__main__':
res = req(102064772608)
parse(res)
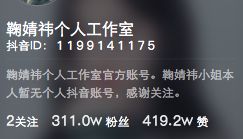
2019年8月更新(完整版):
检测到最近很多同学都在看这篇文章,我就重新写了一遍,思路还是跟上面一样,这次获取的是所有的用户信息。

如果有用,还请点赞或者留言 ?
import re
import requests
from lxml import etree
'''
抖音用户基本信息 -> 请求share来获取数据
'''
def handle_decode(input_data):
# 匹配icon font
regex_list = [
{'name': [' ', ' ', ' '], 'value': 0},
{'name': [' ', ' ', ' '], 'value': 1},
{'name': [' ', ' ', ' '], 'value': 2},
{'name': [' ', ' ', ' '], 'value': 3},
{'name': [' ', ' ', ' '], 'value': 4},
{'name': [' ', ' ', ' '], 'value': 5},
{'name': [' ', ' ', ' '], 'value': 6},
{'name': [' ', ' ', ' '], 'value': 7},
{'name': [' ', ' ', ' '], 'value': 8},
{'name': [' ', ' ', ' '], 'value': 9},
]
for i1 in regex_list:
for i2 in i1['name']:
input_data = re.sub(i2, str(i1['value']), input_data) # 把正确value替换到自定义字体上
html = etree.HTML(input_data)
douyin_info = {}
# 获取昵称
douyin_info['nick_name'] = html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]
# 获取抖音ID
douyin_id = html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']//text()")
douyin_info['douyin_id'] = ''.join(douyin_id).replace('抖音ID:', '').replace(' ', '')
# 职位类型
try:
douyin_info['job'] = html.xpath("//div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text()")[0].strip()
except:
pass
# 描述
douyin_info['describe'] = html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text()")[0].replace('\n', ',')
# 关注
douyin_info['follow_count'] = html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text()")[0].strip()
# 粉丝
fans_value = ''.join(html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()"))
unit = html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['fans'] = str(float(fans_value) / 10) + 'w'
else:
douyin_info['fans'] = fans_value
# 点赞
like = ''.join(html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']//i[@class='icon iconfont follow-num']/text()"))
unit = html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['like'] = str(float(like) / 10) + 'w'
else:
douyin_info['like'] = like
return douyin_info
def handle_douyin_info(url):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
response = requests.get(url=url, headers=header)
return handle_decode(response.text)
if __name__ == '__main__':
url = 'https://www.iesdouyin.com/share/user/102064772608'
print(handle_douyin_info(url))
Fiddler抓取抖音视频数据:https://blog.csdn.net/weixin_43582101/article/details/89600007
抖音分享页面signature值:https://blog.csdn.net/weixin_43582101/article/details/103087046
抖音热搜和话题对应数据:https://blog.csdn.net/weixin_43582101/article/details/103791795
抖音用户视频爬虫案例: https://blog.csdn.net/weixin_43582101/article/details/105946844