Hadoop-HDFS学习课件
Hadoop-HDFS学习课件
- HDFS基本概念
- 前沿
- HDFS的概念和特性
- HDFS-shell
- shell客户端使用
- 客户端支持的命令参数
- HDFS-JAVA-API操作
- 依赖引入
- windows下开发说明
- 文件的增删操作
- 使用流的形式访问文件
- HDFS原理篇
- HDFS上传数据流程
- 概述
- 详细流程图
- 详细步骤
- HDFS读数据流程
- 概述
- 详细流程图
- 详细步骤解析
- namenode工作机制
- namenode的职责
- 元数据存放的几种形式
- 元数据的checkpoint
- datanode工作机制
- datanode工作职责
- HDFS应用场景
- 案例增强技术
- 需求
- 分析
- 代码实现
HDFS基本概念
前沿
- 设计思想:分而治之: 将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析;
- 在大数据系统中的作用:为各类分布式原酸框架(如:mapreduce,spark,flink…)提供数据存储服务。
HDFS的概念和特性
HDFS,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件。
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
- HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
- HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
- 目录结构及文件分块信息(元数据)的管理由namenode节点承担,namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)。
- 文件的各个block的存储管理由datanode节点承担,datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)。
- HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改(不支持从中间插入数据,支持追加)。
重点概念:文件切块,副本存放,元数据
HDFS-shell
shell客户端使用
HDFS提供shell命令行客户端,使用方法如下:
hadoop fs -ls /
或者
hdfs dfs -ls /
客户端支持的命令参数
| 参数 | 示例 | 功能 |
|---|---|---|
| help | hadoop fs -help | 输出这个命令参数手册 |
| ls | hadoop fs -ls / | 显示目录信息 |
| mkdir | hadoop fs -mkdir -p /aa/bb/cc | 在hdfs上创建目录 |
| appendToFile | hadoop fs -appendToFile /hello.txt /hello.txt | 追加一个文件到已经存在的文件末尾(节点大于3) |
| cat | hadoop fs -cat /hello.txt | 显示文件内容 |
| tail | hadoop fs -tail /weblog/access_log.1 | 显示一个文件的末尾 |
| text | hadoop fs -text /weblog/access_log.1 | 以字符形式打印一个文件的内容 |
| chgrp chmod chown |
hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt |
linux文件系统中的用法一样,对文件所属权限 |
| cp | hadoop fs -cp path1 path2 | 从hdfs上拷贝文件到hdfs |
| mv | hadoop fs path1 path2 | 移动文件 |
| get | hadoop fs -get hdfspath localpath | 从hdfs上下载数据到本地 |
| put | hadoop fs -put localpath hdfspath | 从本地上传文件到hdfs上 |
| copyFromLocal | 同put | 同put |
| copyToLocal | t同get | 同get |
| rm | hadoop fs -rm -r path | 删除文件或者目录 |
| rmdir | hadoop fs -rmdir path | 删除空目录 |
| df | hadoop fs -df -h / | 统计文件系统的可用空间信息 |
| du | hadoop fs -du -s -h /path | 统计文件夹的大小信息 |
| count | hadoop fs -count /aaa/ | 统计一个指定目录下的文件节点数量 |
| moveFromLocal | hadoop fs -moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd | 从本地剪切粘贴到hdfs |
| moveToLocal | hadoop fs -moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt | 从hdfs剪切粘贴到本地 |
| setrep | hadoop fs -setrep 3 /file | 设置文件的副本数量 |
HDFS-JAVA-API操作
依赖引入
引入依赖,可以是maven,也可以使用jar的形式;使用jar的形式导入的jar包在安装目录下面的share/hadoop//.jar,maven的形式如下:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.3version>
dependency>
编译打包插件如下(可以不加入):
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
<executions>
<execution>
<phase>compilephase>
<goals>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
configuration>
execution>
executions>
plugin>
plugins>
build>
windows下开发说明
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
A、在windows的某个目录下解压一个hadoop的安装包
B、将安装包下的lib和bin目录用对应windows版本平台编译的本地库替换
C、在window系统中配置HADOOP_HOME指向你解压的安装包
D、在windows系统的path变量中加入hadoop的bin目录
文件的增删操作
使用java代码对文件进行增删操作
package cn.pengpeng.day02;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
/**
* 对文件的增删操作
* @author pengpeng
*
*/
public class TestHdfs {
FileSystem fs = null;
//@Before
public void init(){
/**
* 默认的配置 默认配置是放在jar里面
* 可以放置配置文件到resource文件夹里面 core-site.xml hdfs-site.xml yarn-site.xml ....
* 手动设置
*/
Configuration conf = new Configuration();
conf.set("dfs.replication", "1");
conf.set("dfs.blocksize", "64m");
//URI 就是连接namenode
//fs就是一个客户端,用来操作hdfs文件系统的
try {
fs = FileSystem.get(new URI("hdfs://bigdata3901:9000"), conf, "root");
} catch (IOException | InterruptedException | URISyntaxException e) {
e.printStackTrace();
}
}
/**
* 上传文件
* @throws Exception
* @throws IllegalArgumentException
*/
//@Test
public void upLoad() throws IllegalArgumentException, Exception{
fs.copyFromLocalFile(new Path("d:\\data\\http.log"), new Path("/"));
}
/**
* 下载数据
* 这里面会出现异常 linux 和 hadoop 有一个转换工具
* 首先解压一个hadoop安装包 再解压一个windows编译后的hadoop文件
* 把解压后的文件bin文件夹下的文件拷贝到 hadoop的bin目录下
* 然后配置环境变量 (HADOOP_HOME path)
* 重启eclipse
*
* 如果还不好好使
* 把解压出来的bin目录下的文件 放到 C:\Windows\System32 下
* @throws IOException
* @throws IllegalArgumentException
*/
//@Test
public void downLoad() throws IllegalArgumentException, IOException{
fs.copyToLocalFile(new Path("/bikes.log"), new Path("d:\\tmp\\"));
}
/**
* 删除文件
* @throws IOException
* @throws IllegalArgumentException
*/
//@Test
public void delete() throws IllegalArgumentException, IOException{
fs.delete(new Path("/hdfspath"), true);
}
/**
* 创建文件夹
* @throws IOException
* @throws IllegalArgumentException
*/
//@Test
public void mkdir() throws IllegalArgumentException, IOException{
fs.mkdirs(new Path("/test"));
}
/**
* 改名,移动
* @throws IOException
* @throws IllegalArgumentException
*/
//@Test
public void rename() throws IllegalArgumentException, IOException{
//既能改名,也能移动 ,,移动需要提前创建好父文件夹
fs.rename(new Path("/hadoop.tgz"), new Path("/test/hadoop.tgz"));
}
/**
* 列出文件状态列表
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
//@Test
public void listFile() throws FileNotFoundException, IllegalArgumentException, IOException{
//返回值 是一个迭代器 hasNext() 判断是否有下一个值 next() 获取到下一个值
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus fileInfo = listFiles.next();
System.out.println("文件名:"+fileInfo.getPath().getName());
System.out.println("文件长度:"+fileInfo.getLen());
System.out.println("块大小:"+fileInfo.getBlockSize());
System.out.println("文件修改的时间:"+fileInfo.getAccessTime());
System.out.println("副本数量:"+fileInfo.getReplication());
BlockLocation[] blockLocations = fileInfo.getBlockLocations();
//文件快的分布
for (BlockLocation blockLocation : blockLocations) {
System.out.println(blockLocation);
}
System.out.println("-----------------------------");
}
}
/**
* 列出文件,以及文件夹
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
//@Test
public void listStatus() throws FileNotFoundException, IllegalArgumentException, IOException{
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileInfo : listStatus) {
if(fileInfo.isDirectory()){
System.out.println("这是一个文件夹");
}
if(fileInfo.isFile()){
System.out.println("这是一个文件");
}
System.out.println("文件名:"+fileInfo.getPath().getName());
System.out.println("文件长度:"+fileInfo.getLen());
System.out.println("块大小:"+fileInfo.getBlockSize());
System.out.println("文件修改的时间:"+fileInfo.getAccessTime());
System.out.println("副本数量:"+fileInfo.getReplication());
}
}
//@After
public void close(){
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
使用流的形式访问文件
package cn.pengpeng.day02;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* 流的形式上传下载
* @author pengpeng
*
* 监控一个文件夹,定时的吧文件夹下面的文件上传到hdfs上
*
*/
public class StreamTest {
FileSystem fs = null;
//@Before
public void init() throws Exception{
//指定下hadoop的用户名 如果没有指定默认使用当前用户(windows)
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://bigdata3901:9000");
fs = FileSystem.get(conf);
}
/**
* 写文件,使用流的形式写入
* @throws Exception
* @throws
*/
//@Test
public void writeFile() throws Exception{
//FSDataOutputStream extends java.io.OutputStream 封装一层(增强一些方法)
FSDataOutputStream output = fs.create(new Path("/test/writeFile.txt"));
output.writeUTF("hello");
output.writeBoolean(true);
output.writeUTF("word");
output.flush();
output.close();
}
/**
* 读数据
*
* @throws Exception
*/
//@Test
public void readFile() throws Exception{
//FSDataInputStream extends java.io.InputStream
FSDataInputStream input = fs.open(new Path("/test/writeFile.txt"));
String readUTF = input.readUTF();
boolean readBoolean = input.readBoolean();
String readUTF2 = input.readUTF();
System.out.println(readUTF);
System.out.println(readBoolean);
System.out.println(readUTF2);
input.close();
}
/**
* 使用流的形式上传,或者下载一个文件
* 流上传数据
* 1:创建本地的流 FileInputStream
* 2:创建一个跟hdfs交互的流 FSDataOutputStream
* 3:循环的读数据(本地) 向 集群中写入 (hdfs)
*
*
* 作业:下载
* 如果出现乱码情况() 想使用buffer字符流
*
* @throws Exception
* @throws Exception
*/
//@Test
public void writeFile2() throws Exception{
FileInputStream input = new FileInputStream("d:\\data\\ip.txt");
FSDataOutputStream output = fs.create(new Path("/test/streamFile.txt"));
byte[] b = new byte[4096];
int len = 0;
while((len = input.read(b))!=-1){
output.write(b, 0, len);
}
output.flush();
input.close();
output.close();
}
//@After
public void close() throws Exception{
fs.close();
}
}
HDFS原理篇
HDFS上传数据流程
概述
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
详细流程图
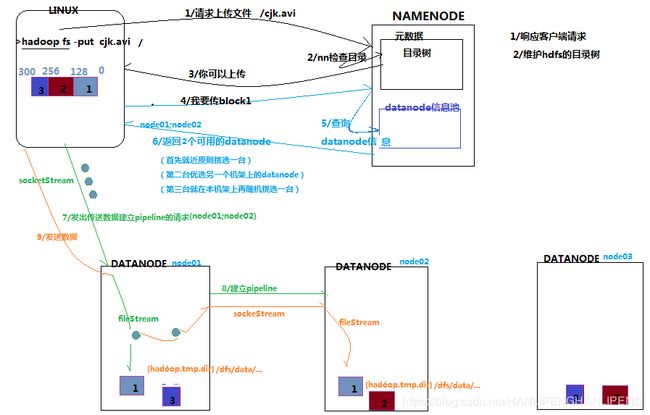
详细步骤
- 根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求第一个 block该传输到哪些datanode服务器上
- namenode返回3个datanode服务器ABC
- client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读数据流程
概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
详细流程图

详细步骤解析
- 跟namenode通信查询元数据,找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件
namenode工作机制
namenode的职责
- 负责客户端请求的响应
- 元数据的管理(查询,修改)
元数据存放的几种形式
- 内存中有一份完整的元数据(内存meta data)
- 磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
- 用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中。
元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)。
详细流程图如下:
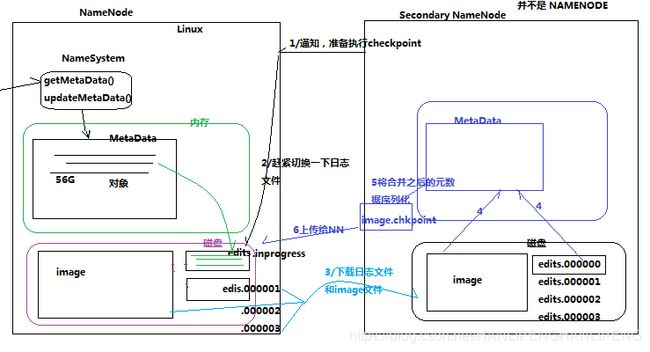
datanode工作机制
datanode工作职责
- 存储管理用户的文件块数据
- 定期向namenode汇报自身所持有的block信息(通过心跳信息上报)。当集群中发生某些block副本失效时,会在其他节点上恢复副本数量。
HDFS应用场景
- 存储日志数据,为数据分析做数据支撑。
- 结合web系统存储文档性数据(pdf,word等)。
案例增强技术
需求
分析
代码实现
问题:
- 集群容量不够了怎么进行扩容。
- 如果有一些datanode宕机,该怎么办
- 小文件适合HDFS存储吗