HBase | HBase从介绍到Java客户端开发
文章目录
- HBase入门认识
- HBase介绍
- HBase
- HBase架构
- RegionServer集群结构
- HBase逻辑存储结构
- HBase物理存储结构
- HBase安装
- 前期准备
- HBase安装步骤
- Hbase启动
- HBase验证
- 备份master
- HBase命令
- 下文演示中使用的数据
- HBase 命令介绍
- HBase Shell命令介绍
- status命令
- 命名空间namespace相关命令
- 介绍
- create_namespace命令
- drop_namespace命令
- describe_namespace命令
- list_namespace命令
- list命令
- 创建hbase用户表
- 删除用户表
- put命令
- HbaseShell使用Java的Api
- 表赋给临时变量
- get命令
- scan命令
- scan-filter相关命令
- scan其他参数
- count命令
- delete命令
- truncate命令
- describe命令
- Java客户端
- Java客户端
- HBaseAdmin
- HTable,HTableDescriptor
- Put,Get,Scan,Delete
- HBase连接池
- Java客户端编程
- HBaseAdmin类详细介绍
- HTable类和连接池详细介绍
由于文章内容较多,常需要用到目录索引,友情提示:页面右侧有个快捷展开目录的功能,浏览过程中可以随时查看目录。
HBase入门认识
HBase介绍
- HBase是参考google的bigtable的一个开源产品,建立在hdfs之上的一个提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
- 是一种介于nosql和RDBMs之间的一种数据库系统,仅支持通过rowkey和range进行数据的检索,主要存储非结构化数据和半结构化数据。
- HBase和Hadoop一样,目标是通过横向扩展,添加普通机器来增加存储性能和计算性能。
- HBase特点:大(一个表可以有上亿行以及百万级的行)、面向行存储、稀疏(由于null不占用存储空间,所有表结果可以设计的非常稀疏)。
HBase
- HBase使用Zookeeper进行集群节点管理,当然HBase自身集成了一个ZK系统,不过一般情况在实际生产环境中不使用。
- HBase由master和regionserver两类节点(如果使用HBase自带的zk服务,那么还有HQuorumPeer进程)。
- Hbase支持提供backup master进行master备份。其中master节点负责和zk进行通信以及存储regionserver的相关位置信息,regionserver节点实现具体对数据的操作,最终数据存储在hdfs上。
HBase架构
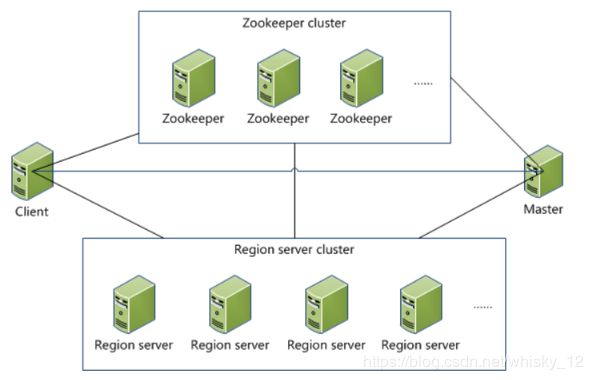
RegionServer集群结构
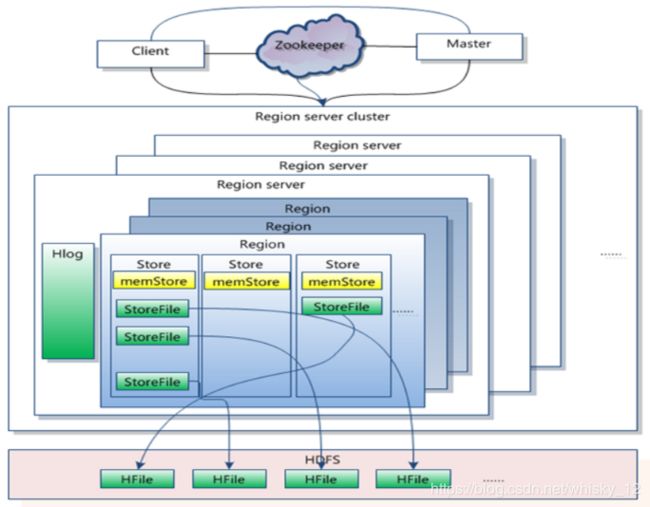
HBase逻辑存储结构
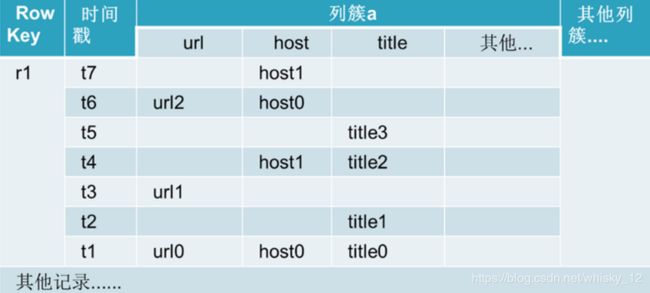
HBase物理存储结构
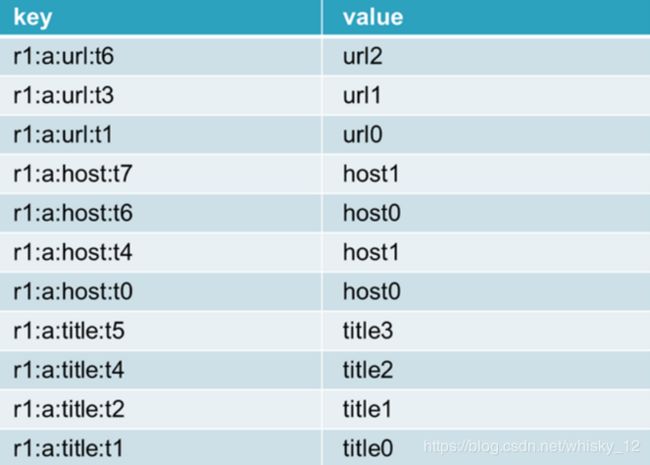
key:rowkey:列簇:列名:时间戳
HBase安装
前期准备
- HBase有三种安装方式,第一种独立模式,第二种是分布式模式(集成zookeeper),第三种是分布式模式(独立zookeeper)。
- 安装步骤:
- 安装jdk,至少1.6(版本u18除外)。
- 安装ssh免密码登录。
- 修改hostname和hosts,hbase通过hostname获取ip地址。
- Hadoop安装。
- 生成环境集群(NTP + ulimit&nproc + hdfs的dfs.datanode.max.xcievers)
- hbase下载安装
HBase安装步骤
- 下载hbase,选择版本hbase-0.98.6-cdh5.3.6,下载地址http://archive.cloudera.com/cdh5/cdh/5/。
- 解压压缩包到目录/home/hadoop/bigdater/下。
- 在hbase的根目录下创建一个文件夹hbase来存储临时文件和pid等。默认/tmp。
- 修改配置信息 h b a s e . h o m e / c o n f / h b a s e − s i t e . x m l 和 {hbase.home}/conf/hbase-site.xml和 hbase.home/conf/hbase−site.xml和{hbase.home}/conf/hbase-env.sh文件。

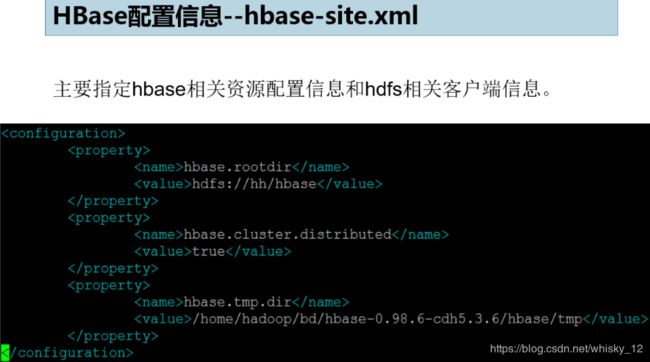
hbase.rootdir
hdfs://oda.com/hbase
hbase.cluster.distributed
true
hbase.tmp.dir
/home/jlu/bd/hbase-0.98.6-cdh5.3.6/hbase/tmp
-
指定regionserver节点hostname,修改文件regionservers。
-
创建到hdfs-site.xml的软连接(即在$HADOOP_HOME/etc/hadoop下创建hbase-site.xml的软连接)或者配置连接hdfs的配置信息(推荐)。
-
添加hbase相关信息到环境变量中(vi ~/.bash_profile)。

-
启动hbase集群并验证。
**大写的ps.**为防止后期编程,hadoop缺少jar包,建议在hadoop-env.sh上添加如下配置

Hbase启动
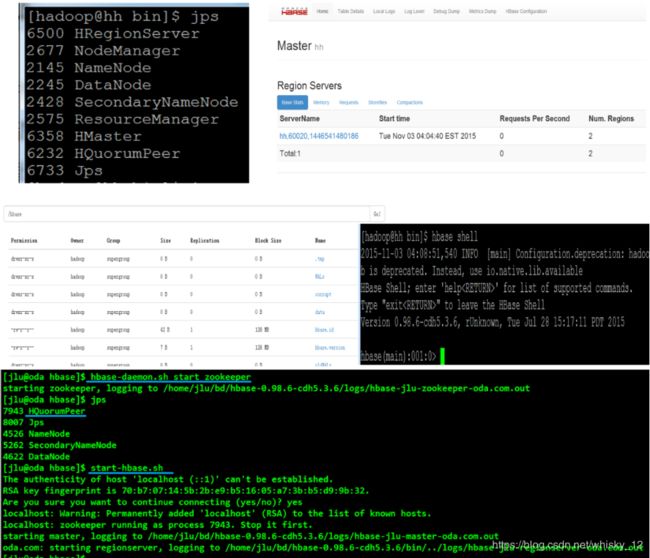
- 启动集群命令: start-hbase.sh
- 停止集群命令: stop-hbase.sh
- 单独启动/停止进程命令: (单独的启动master或者regionserver)
hbase-daemon.sh (start|stop) (master|regionserver|zookeeper)
hbase-daemons.sh (start|stop) (regionserver|zookeeper)
HBase验证
验证分为四种方式:
- jsp查看是否有hbase的正常启动。
- web界面查看是否启动成功。http://192.168.162.121:60010/
- shell命令客户端查看是否启动成功。
- 查看hbase是否安装成功,查看hdfs文件下是否有hbase的文件夹。
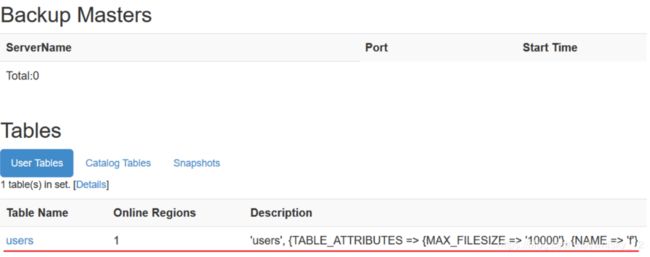
备份master
- 如果需要使用hbase的多master结构,那么需要在conf文件夹下添加backup-masters文件,然后一行一个主机名,和regionservers是一样的;
- 或者在hbase-env.sh中添加变量HBASE_BACKUP_MASTERS,对应value为backup-masters存储路径(启动命令一样)。
HBase命令
下文演示中使用的数据
create 'users','f'
put 'users', 'row1', 'f:id', '1'
put 'users', 'row1', 'f:name', 'zhangsan'
put 'users', 'row1', 'f:age', 18
put 'users', 'row1', 'f:phone', '021-11111111'
put 'users', 'row1', 'f:email', '[email protected]'
put 'users', 'row2', 'f:id', '2'
put 'users', 'row2', 'f:name', 'lisi'
put 'users', 'row2', 'f:email', '[email protected]'
put 'users', 'row2', 'f:address', 'shanghai'
put 'users', 'row3', 'f:id', '3'
put 'users', 'row3', 'f:name', 'lili'
put 'users', 'row3', 'f:age', 25
put 'users', 'row3', 'f:country', 'china'
put 'users', 'row3', 'f:email', '[email protected]'
put 'users', 'row4', 'f:id', '4'
put 'users', 'row4', 'f:name', 'user4'
put 'users', 'row5', 'f:id', '5'
put 'users', 'row5', 'f:name', 'user5'
put 'users', 'row6', 'f:id', '6'
put 'users', 'row6', 'f:name', 'user6'
put 'users', 'row7', 'f:id', '7'
put 'users', 'row7', 'f:name', 'user7'
put 'users', 'row8', 'f:id', '8'
put 'users', 'row8', 'f:name', 'user8'
put 'users', 'row9', 'f:id', '9'
put 'users', 'row9', 'f:name', 'user9'
put 'users', 'row10', 'f:id', '10'
put 'users', 'row10', 'f:name', 'user10'
HBase 命令介绍
- HBase命令主要分为两大类,
- 第一类是指操作hbase表的相关的shell命令;
- 第二类是提供hbase其他相关服务的命令。
- 第一类命令全部在****hbase** shell命令中,那么第二类命令主要以thrift/thrift2等服务为主**。

HBase Shell命令介绍
- HBase的Shell命令是以JRuby为核心编写的,主要分为DDL和DML两大类,除此两类之外还有一起其他的命令运维相关的命令,比如snapshots等。
- 当我们进入hbase的shell命令客户端的时候,我们可以通过help命令查看帮助信息,也可以通过help命令查看具体命令的使用方法。
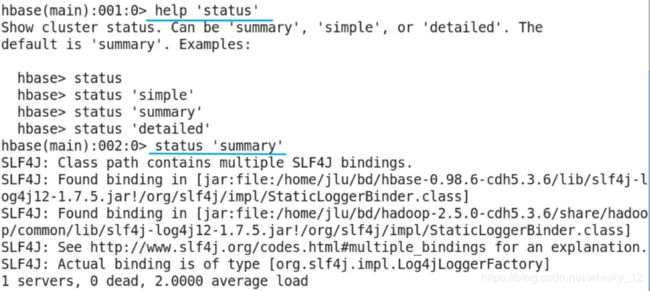
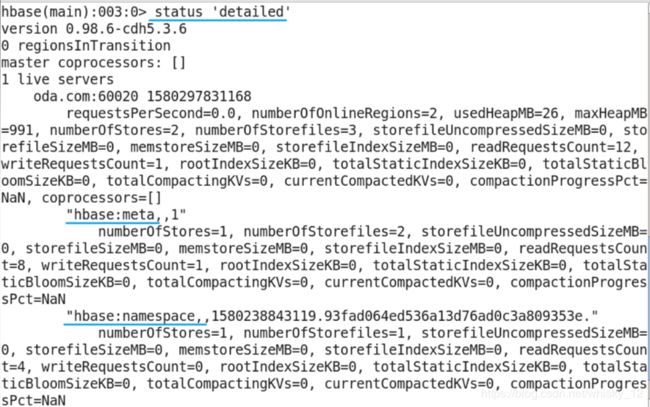
status命令
- 作用:查看hbase集群状态信息。
- 参数:simple(简洁),summary(概述),detailed(详细,具体到表);默认是summary。
命名空间namespace相关命令
介绍
- 作用:类似关系型数据库中的database,作用是将hbase的表按照业务作用分割开,有益于维护。Hbase默认有两个命名空间,分别是hbase和default。其中hbase命名空间存储hbase自身的表信息,default存储用户创建的表。
- 命令:
- create_namespace(创建命名空间),
- alter_namespace(命名空间修改),
- describe_namespace(显示命名空间描述信息),
- drop_namespace(删除命名空间,前提是该命名空间是空的),
- list_namespace(显示所有命名空间),
- list_namespace_tables(显示对于命名空间中的table名称)。
create_namespace命令
- 作用:创建命名空间。
- 示例:create_namespace ‘bigdater’, {‘comment’=>‘this is ourself namespace’,‘keyname’=>‘valuename’}

drop_namespace命令
- 作用:删除指定命名空间;注意删除的命名空间内不能有table存在,也就是说只能删除空的namespace。
- 示例:drop_namespace ‘bigdater’

describe_namespace命令
- 作用:显示命名空间的相关信息。
- 示例:describe_namespace ‘bigdater’

list_namespace命令
- 作用:显示所有存在的命名空间。
- 示例:list_namespace或者list_namespace ‘regex_str’
list命令
- 作用:显示hbase表名称,类似mysql中的show tables;
- 可以通过指定命名空间来查看对应命名空间中的表,默认是显示所有用户表,也支持模糊匹配。类似命令list_namespace_tables查看对应命名空间内有那些表。

创建hbase用户表
- 命令格式:create ‘[namespace_name:]table_name’, ‘family_name_1’,…‘family_name_n’(family_name_1表示列簇名)
- 如果不给定namespace的名称,默认创建在default命名空间中。
- 示例:create ‘bigdater:test’,‘f’

删除用户表
- 删除用户表之前需要将表设置为disable的,然后才可以删除。
- 其实在hbase中如果需要对已有表进行ddl操作,均需要将其disable,在ddl操作完成后,再进行enable操作即可。
- 命令格式:
- disable ‘[namespace_name:]table_name’
- drop ‘[namespace_name:]table_name’
- 示例:
- disable ‘bigdater:test’
- drop ‘bigdater:test’
- 命令格式:

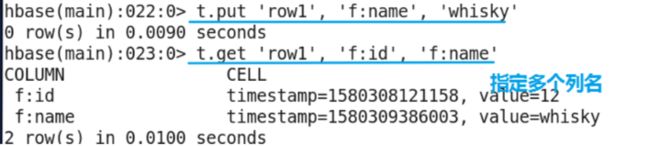
put命令
- 在默认命名空间中创建users表,然后在这个表的基础上进行操作。hbase的put命令是进行数据添加的命令。
命令格式:
put ‘[namespace_name:]table_name’, ‘rowkey’, ‘family:[column]’, ‘value’ [, timestamp] [, {ATTRIBUTES=>{‘mykey’=>‘myvalue’}, VISIBILITY=>‘PRIVATE|SECRET’}]
示例:put ‘users’,‘row1’,‘f:id’,‘1’

HbaseShell使用Java的Api
表赋给临时变量

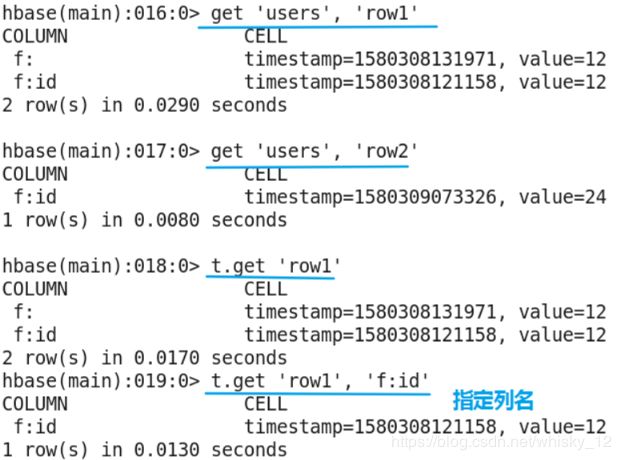
get命令
- get命令的作用是获取对应表中对应rowkey的数据。默认获取最新版本的全部列数据,可以通过时间戳指定版本信息,也可以指定获取的列。
- 命令格式:
get ‘[namespace_name:]table_name’, ‘rowkey’ - 示例:get ‘users’,‘row1’
scan命令
- scan命令是hbase的另外一种检索方式,是通过范围查找hbase中的数据。默认情况下是获取table的全部数据,可以通过指定column和filter等相关信息进行数据的过滤。
- 命令格式:
scan ‘[namespace_name:]table_name’ - 示例:scan ‘users’
scan-filter相关命令
-
scan提供多种filter命令,常用filter命令如下:ColumnPrefixFilter,MultipleColumnPrefixFilter,RowFilter,SingleColumnValueFilter,SingleColumnValueExcludeFilter等。
-
需要注意的是:在指定的value之前需要加’binary:’,比如:scan ‘users’,{FILTER=>“SingleColumnValueFilter(‘f’,‘id’,=,'binary:1)”}
-
MultipleColumnPrefixFilter匹配多个列前缀
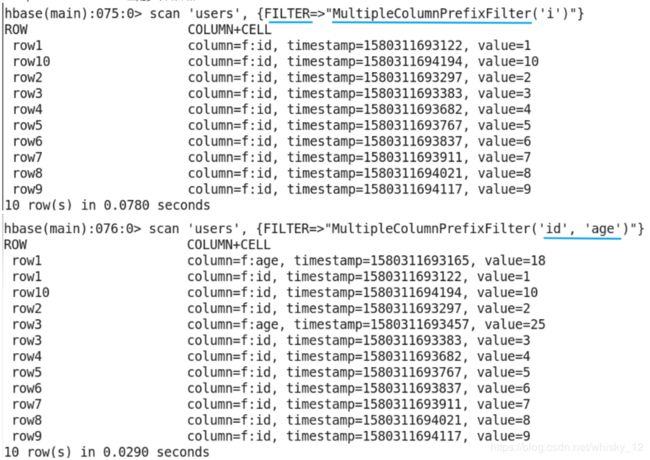
-
RowFilter需要两个参数

-
SingleColumnValueFilter最常用,需要的参数也比较多,图中,因为id存的是字符串类型,所以按字典序比较过滤

-
多个过滤条件结合使用

scan其他参数
- scan命令除了使用filter外,我们还可以定义我们需要的column,开始扫描的rowkey,结束扫描的rowkey,获取行数等信息。
- eg:
- scan ‘users’, {COLUMN=>[‘f:id’,‘f:name’]}
- scan ‘users’, {STARTROW=>‘row1’,ENDROW=>‘row2’}
- scan ‘users’, {LIMIT=>1}
- 限制输出三条记录(row1开头的都属于一条)
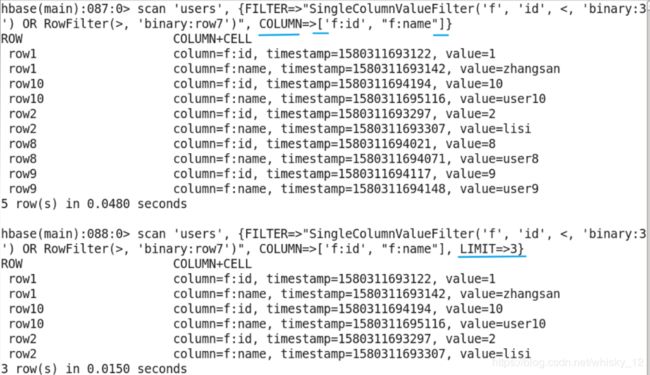
- 指定开始rowkey并限制输出三条记录
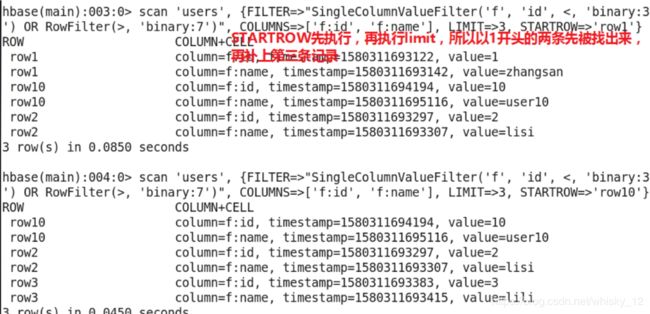
- STARTROW和ENDROW

count命令
- count命令是统计hbase表行数的一个命令,由于相当于一个内置的mapreduce程序,所以当数据量比较大的时候可以选择使用协处理器方式计算行数。
- 命令格式:
- count ‘[namespace:]table_name’ [INTERVAL => 1000,] [CACHE => 10]
- 默认情况下INTERVAL是1000(间隔数),CACHE是10。
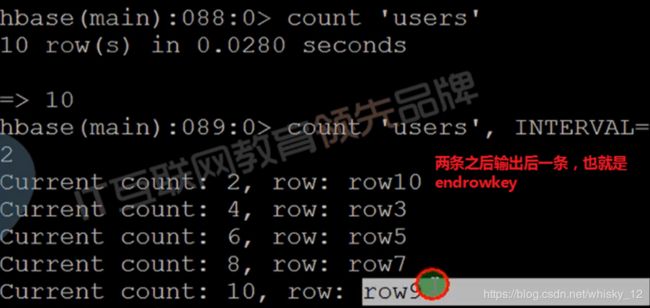
delete命令
- delete命令是删除指定table的指定rowkey的指定列,也就是说delete命令适合删除列的情况。
- 命令格式:
- delete ‘[namespace:]table_name’, ‘rowkey’, ‘family:column’
- 如果需要删除当然rowkey的所有列数据,那么可以使用deleteall命令。

truncate命令
- truncate命令的作用是清空数据库,当我们数据库中的数据比较多的时候,我们可以选择该命令将数据库清空。
- 命令格式: truncate ‘[namespace_name:]table_name’
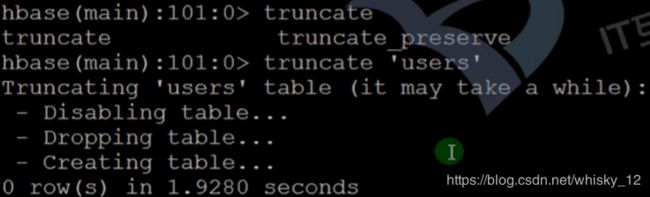
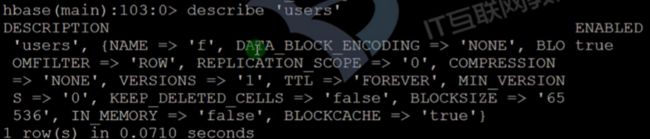
describe命令
- 查看描述信息
- 也可以直接通过web界面查看
Java客户端
Java客户端
Java客户端其实就是shell客户端的一种实现,操作命令基本上就是shell客户端命令的一个映射。Java客户端使用的配置信息是被映射到一个HBaseConfiguration的实例对象中的,当使用该类的create方法创建实例对象的时候,会从classpath路径下获取hbase-site.xml文件并进行配置文件内容的读取,同时会读取hadoop的配置文件信息。也可以通过java代码指定命令信息,只需要给定zk的相关环境变量信息即可。代码如下:
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "hh1,hh2.."); // 第二个参数是主机名
HBaseAdmin
HBaseAdmin类是主要进行DDL操作相关的一个接口类,主要包括命名空间管理,用户表管理。通过该接口我们可以创建、删除、获取用户表,也可以进行用户表的分割、紧缩等操作。
HTable,HTableDescriptor
HTable是hbase中的用户表的一个映射的java实例,我们可以通过该类进行表数据的操作,包括数据的增删查改,也就是在这里我们可以类似shell中put,get和scan进行数据的操作。
HTableDescriptor是hbase用户表的具体描述信息类,一般我们创建表获取获取(给定)表信息,就是通过该类进行的。
Put,Get,Scan,Delete
- Put类是专门提供插入数据的类。
- Get类是专门提供根据rowkey获取数据的类。
- Scan是专门进行范围查找的类。
- Delete是专门进行删除的类。
HBase连接池
在web应用中,如果我们之间使用HTable来操作hbase,那么在创建连接和关闭连接的时候,一定会浪费资源。那么HBase提供了一个连接池的基础,主要涉及到的类和接口包括:HConnection,HConnectionManager,HTableInterface,ExecutorService四个。
- 其中HConnection就是hbase封装好的hbase连接池,
- HConnectionManager是管理连接池的一个类,
- HTableInterface是在类HTable的基础上进行的一个接口抽象,
- ExecutorService是jdk的线程池对象。
Java客户端编程
HBaseAdmin类详细介绍
- 测试创建表


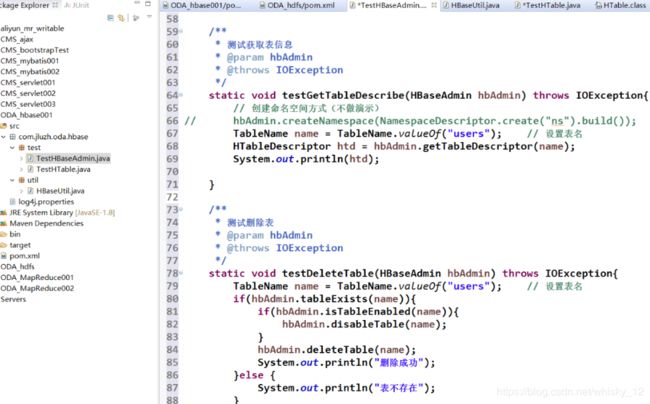
 - 获取表信息以及删除表
- 获取表信息以及删除表
HTable类和连接池详细介绍
package com.jluzh.oda.hbase.test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.NavigableMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter;
import org.apache.hadoop.hbase.util.Bytes;
import com.jluzh.oda.hbase.util.HBaseUtil;
public class TestHTable {
static byte[] family = Bytes.toBytes("f");
public static void main(String[] args) {
Configuration conf = HBaseUtil.getHBaseConfiguration();
try {
// testUseHTable(conf);
testUseHbaseConnectionPool(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
// 集中调用测试方法
static void testUseHTable(Configuration conf) throws IOException {
HTable hTable = new HTable(conf, "users");
try {
// testPut(hTable);
// testGet(hTable);
// testDelete(hTable);
testScan(hTable); // 参数是实现了接口的类实例
} finally {
hTable.close();
}
}
// 最好还是使用线程池
static void testUseHbaseConnectionPool(Configuration conf) throws IOException {
ExecutorService threads = Executors.newFixedThreadPool(10); // 10个线程
HConnection pool = HConnectionManager.createConnection(conf, threads);
HTableInterface hTable = pool.getTable("users");
try {
// testPut(hTable); // 参数是实现了接口的类实例
// testGet(hTable);
// testDelete(hTable);
testScan(hTable);
} finally {
hTable.close(); // 每次htable操作完 关闭 其实是放到pool中
pool.close(); // 最终的时候关闭
}
}
/**
* 测试scan
*
* @param hTable;接口
* @throws IOException
*/
static void testScan(HTableInterface hTable) throws IOException{
Scan scan = new Scan();
// 增加起始row key
scan.setStartRow(Bytes.toBytes("row1"));
scan.setStopRow(Bytes.toBytes("row5"));
// 使用指定布尔运算符求值的筛选器的有序列表
FilterList list = new FilterList(Operator.MUST_PASS_ALL); // 相当于AND
byte[][] prefixes = new byte[2][]; // 过滤前缀
prefixes[0] = Bytes.toBytes("id");
prefixes[1] = Bytes.toBytes("name");
// 创建多重列前缀过滤器实例
MultipleColumnPrefixFilter mcpf = new MultipleColumnPrefixFilter(prefixes);
list.addFilter(mcpf); // 添加过滤器
scan.setFilter(list); // scan操作设置过滤器
// Returns a scanner on the current table as specified
// by the {@link Scan} object.
ResultScanner rs = hTable.getScanner(scan);
Iterator iter = rs.iterator();
while (iter.hasNext()) {
// Single row result of a {@link Get} or {@link Scan} query.
Result result = iter.next();
printResult(result);
}
}
/**
* 打印result对象
*
* @param result
*/
static void printResult(Result result) {
System.out.println("*********************" + Bytes.toString(result.getRow())); // 获取rowkey
//
// getMap(): 将族映射到其限定符和值的所有版本。
NavigableMap>> map = result.getMap();
// 遍历map
for (Map.Entry>> entry : map.entrySet()) {
String family = Bytes.toString(entry.getKey()); // 获取family
for (Map.Entry> columnEntry : entry.getValue().entrySet()) {
String column = Bytes.toString(columnEntry.getKey()); // 获取column
String value = "";
if ("age".equals(column)) {
value = "" + Bytes.toInt(columnEntry.getValue().firstEntry().getValue());
} else {
value = Bytes.toString(columnEntry.getValue().firstEntry().getValue());
}
System.out.println(family + ":" + column + ":" + value);
}
}
}
/**
* 测试put操作
*
* @param hTable
* @throws IOException
*/
static void testPut(HTableInterface hTable) throws IOException {
// 单个put
Put put = new Put(Bytes.toBytes("row1"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("11"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("zhangsan"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("age"), Bytes.toBytes(27));
put.add(Bytes.toBytes("f"), Bytes.toBytes("phone"), Bytes.toBytes("021-11111111"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("email"), Bytes.toBytes("[email protected]"));
hTable.put(put); // 执行put
// 同时put多个
Put put1 = new Put(Bytes.toBytes("row2"));
put1.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("2"));
put1.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("user2"));
Put put2 = new Put(Bytes.toBytes("row3"));
put2.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("3"));
put2.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("user3"));
Put put3 = new Put(Bytes.toBytes("row4"));
put3.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("4"));
put3.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("user4"));
List list = new ArrayList();
list.add(put1);
list.add(put2);
list.add(put3);
hTable.put(list); // 执行多个put
// 检测put,条件成功就插入,要求rowkey是一样的。
Put put4 = new Put(Bytes.toBytes("row5"));
put4.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("7"));
hTable.checkAndPut(Bytes.toBytes("row5"), Bytes.toBytes("f"), Bytes.toBytes("id"), null, put4);
System.out.println("插入成功");
}
/**
* 测试get命令
*
* @param hTable
* @throws IOException
*/
static void testGet(HTableInterface hTable) throws IOException {
// Create a Get operation for the specified row.
Get get = new Get(Bytes.toBytes("row1"));
// Single row result of a {@link Get} or {@link Scan} query.
Result result = hTable.get(get); // 执行get
// Get the latest version of the specified column.
byte[] buf = result.getValue(family, Bytes.toBytes("id")); // 获取id
System.out.println("id:" + Bytes.toString(buf));
buf = result.getValue(family, Bytes.toBytes("age")); // 获取age
System.out.println("age:" + Bytes.toInt(buf));
buf = result.getValue(family, Bytes.toBytes("name"));
System.out.println("name:" + Bytes.toString(buf));
buf = result.getRow();
System.out.println("row:" + Bytes.toString(buf));
}
/**
* 测试delete
*
* @param hTable
* @throws IOException
*/
static void testDelete(HTableInterface hTable) throws IOException {
// Create a Delete operation for the specified row.
Delete delete = new Delete(Bytes.toBytes("row3"));
// 删除列
delete = delete.deleteColumn(family, Bytes.toBytes("id"));
// 直接删除family
// delete.deleteFamily(family);
hTable.delete(delete); // 删除rowkey(Delete delete = new Delete(Bytes.toBytes("row3"));)
System.out.println("删除成功");
}
}