小白入门计算机视觉系列——ReID(一):什么是ReID?如何做ReID?ReID数据集?ReID评测指标?
ReID(一):什么是ReID?如何做ReID?ReID数据集?ReID评测指标?
小白入门系列是我和朋友准备一起做的一块内容,分模块分专题·,比如计算机视觉中的目标检测,ReID,OCR,语义分割以及大火大热的AutoML等等。
本次带来的是计算机视觉中比较热门的重点的一块,行人重识别(也叫Person ReID),车辆重识别和行人重识别类似,有很多的共同之处,所以以下统称该任务为ReID。
1.什么是ReID?
ReID,也就是 Re-identification,其定义是利用算法,在图像库中找到要搜索的目标的技术,所以它是属于图像检索的一个子问题。
为什么会有这个方向呢?来看大背景:随着社会的发展,公共安全成为全社会的一个共同话题,与之相辅相成的视频监控系统也得到了大量的普及。视频监控系统可以直观的再现目标场景,可作为公安侦破案件的强力辅助。在执法部门的工作中,目标的识别和定位是及其关键的一步,然而现有的监控部署下,这个关键步骤几乎是靠着人力完成的。在这个讲究数据和效率的时代,通过人工观察监控录像查找结果显然存在着很大的资源浪费以及效率的低下。另外,由于摄像头的分辨率等硬件缺陷,很难得到清晰的人身图像,因此,已经大力推广的人脸识别技术已不再适用此场景。由于传统人工查询的不便性以及人脸识别的无法应用,研究者思考如何发明一项更合适的技术来取代人脸识别,能在监控领域以机器代替人力分析呢?故此,行人重识别(P-edestrian Re-identification,ReID)的研究也应随之展开。
说白了,在监控拍不到人脸的情况下,ReID可以代替人脸识别来在视频序列中找到我要找到目标对象。那么他的应用就很广了,可以做安防,可以做个人定位,在商场上可以配合推荐系统,搭建出个性化的推荐服务等等。下面一张图可以生动的解释它在安防的一个应用场景。

ReID的概念最早在2006年的CVPR会议上被提出。2007年首个ReID数据集VIPeR被公布,之后越来越多的不同场景下的数据集先后被开源了出来,这些数据集也一定程度上推动了ReID的发展。
在2015年左右,深度学习还没有大热大火之前,ReID的研究大部分都是基于的特征的阶段,对于人工特征,如颜色、HOG特征等,之后的度量学习是寻找特征之间的最佳近似度,但这种方法学习复杂的场景数据效果不佳。随着AlphaGo取得令人瞩目的成就,以及最新硬件支持技术的发展也带来了深度学习的高产阶段,深度学习也逐渐渗透到人工智能的各个方面,包括ReID,利用深度学习的方法可以很好的学习出黑盒性质的特征,在一些方面可以超过了人类的识别水平,因而深度学习在CV中的应用已成为相关研究者关注的热点。
2017年和2018年ReID得到快速发展,在国内外各类顶级计算机视觉会议和顶级期刊上每年都有多篇ReID的文章。迁移学习的火热也使得在大数据量和算力下训练好的模型可以作为网络的初始化,使得网络的性能大大改善。对抗生成网络的出现也给ReID带来了新道路;虽然目前来说,ReID主流的方法仍然属于监督学习,但是迁移学习以及GAN网络也将是一个很有前景的方向。
2.如何做ReID?
从前面讲的,我们已经大致知道ReID是干什么的了,似乎就是去检索出一个目标对象。这里我会具体去讲这个任务如何去做。
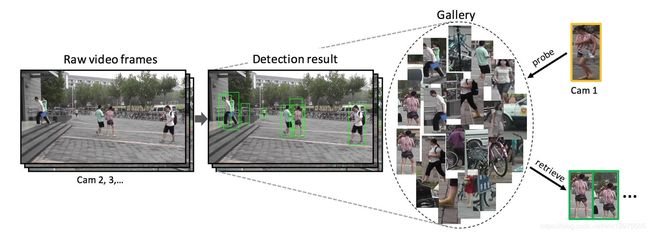
上面这张图向我们展示了ReID的一个任务过程,首先要做的是Detection,也就是检测出行人,其实这一步数据集已经帮我们做到了,下面介绍数据集的时候会讲到不同数据集采用的不同的目标检测方法以及ID的标注方式。剩下的部分,就是要去训练一个特征提取网络,根据特征所计算的度量距离得到损失值,我们选用一个优化器去迭代找到loss最小值,并不断更新网络的参数达到学习的效果。在测试的时候,我们用将要检索的图片(称为query或者probe),在底库gallery中,根据计算出的特征距离进行排序,选出最TOP的几张图片,来达到目标检索的目的。下面两张图分别是训练阶段和测试阶段的示意图:


测试阶段中,我们利用训练后的网络计算特征从所有搜索到的图像中提取特征,并计算搜索图与地库之间的特征距离。然后根据计算出的距离对它们进行排序。排名越高,相似性越高,上图中,绿色边框的是正确检索的结果,红色边框的是错误检索的结果。
3.ReID数据集?
ReID的数据集已经完成的任务是行人检测以及对应的ID标注,因此一个数据集的好坏对于ReID的研究是至关重要的。目前学术界最常用的数据集有三个:Market1501、DukeMTMC-reID、CUHK-03。
1)Market-1501

Market-1501 数据集在清华大学校园中采集,夏天拍摄,在 2015 年构建并公开。它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的 1501 个行人、32668 个检测到的行人矩形框。每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。训练集有 751 人,包含 12,936 张图像,平均每个人有 17.2 张训练数据;测试集有 750 人,包含 19,732 张图像,平均每个人有 26.3 张测试数据。3368 张查询图像的行人检测矩形框是人工绘制的,而 gallery 中的行人检测矩形框则是使用DPM检测器检测得到的。该数据集提供的固定数量的训练集和测试集均可以在single-shot或multi-shot测试设置下使用。
目录结构
Market-1501
├── bounding_box_test
├── 0000_c1s1_000151_01.jpg
├── 0000_c1s1_000376_03.jpg
├── 0000_c1s1_001051_02.jpg
├── bounding_box_train
├── 0002_c1s1_000451_03.jpg
├── 0002_c1s1_000551_01.jpg
├── 0002_c1s1_000801_01.jpg
├── gt_bbox
├── 0001_c1s1_001051_00.jpg
├── 0001_c1s1_009376_00.jpg
├── 0001_c2s1_001976_00.jpg
├── gt_query
├── 0001_c1s1_001051_00_good.mat
├── 0001_c1s1_001051_00_junk.mat
├── query
├── 0001_c1s1_001051_00.jpg
├── 0001_c2s1_000301_00.jpg
├── 0001_c3s1_000551_00.jpg
└── readme.txt
目录介绍
1) “bounding_box_test”——用于测试集的 750 人,包含 19,732 张图像,前缀为 0000 表示在提取这 750 人的过程中DPM检测错的图(可能与query是同一个人),-1 表示检测出来其他人的图(不在这 750 人中)
2) “bounding_box_train”——用于训练集的 751 人,包含 12,936 张图像
3) “query”——为 750 人在每个摄像头中随机选择一张图像作为query,因此一个人的query最多有 6 个,共有 3,368 张图像
4) “gt_query”——matlab格式,用于判断一个query的哪些图片是好的匹配(同一个人不同摄像头的图像)和不好的匹配(同一个人同一个摄像头的图像或非同一个人的图像)
5) “gt_bbox”——手工标注的bounding box,用于判断DPM检测的bounding box是不是一个好的box
命名规则
以 0001_c1s1_000151_01.jpg 为例
1) 0001 表示每个人的标签编号,从0001到1501;
2) c1 表示第一个摄像头(camera1),共有6个摄像头;
3) s1 表示第一个录像片段(sequece1),每个摄像机都有数个录像段;
4) 000151 表示 c1s1 的第000151帧图片,视频帧率25fps;
5) 01 表示 c1s1_001051 这一帧上的第1个检测框,由于采用DPM检测器,对于每一帧上的行人可能会框出好几个bbox。00 表示手工标注框
2)DukeMTMC-reID
DukeMTMC-reID 于杜克大学内采集。DukeMTMC 数据集是一个大规模标记的多目标多摄像机行人跟踪数据集。它提供了一个由 8 个同步摄像机记录的新型大型高清视频数据集,具有 7,000 多个单摄像机轨迹和超过 2,700 多个独立人物,DukeMTMC-reID 是 DukeMTMC 数据集的行人重识别子集,并且提供了人工标注的bounding box。
目录结构
DukeMTMC-reID
├── bounding_box_test
├── 0002_c1_f0044158.jpg
├── 3761_c6_f0183709.jpg
├── 7139_c2_f0160815.jpg
├── bounding_box_train
├── 0001_c2_f0046182.jpg
├── 0008_c3_f0026318.jpg
├── 7140_c4_f0175988.jpg
├── query
├── 0005_c2_f0046985.jpg
├── 0023_c4_f0031504.jpg
├── 7139_c2_f0160575.jpg
└── CITATION_DukeMTMC.txt
└── CITATION_DukeMTMC-reID.txt
└── LICENSE_DukeMTMC.txt
└── LICENSE_DukeMTMC-reID.txt
└── README.md
目录介绍
从视频中每 120 帧采样一张图像,得到了 36,411 张图像。一共有 1,404 个人出现在大于两个摄像头下,有 408 个人 (distractor ID) 只出现在一个摄像头下。
1) “bounding_box_test”——用于测试集的 702 人,包含 17,661 张图像(随机采样,702 ID + 408 distractor ID)
2) “bounding_box_train”——用于训练集的 702 人,包含 16,522 张图像(随机采样)
3) “query”——为测试集中的 702 人在每个摄像头中随机选择一张图像作为 query,共有 2,228 张图像
命名规则
以 0001_c2_f0046182.jpg 为例
1) 0001 表示每个人的标签编号;
2) c2 表示来自第二个摄像头(camera2),共有 8 个摄像头;
3) f0046182 表示来自第二个摄像头的第 46182 帧。
3)CUHK03
CUHK03是第一个足以进行深度学习的大规模行人重识别数据集,该数据集的图像采集于香港中文大学校园。数据以”cuhk-03.mat”的 MAT 文件格式存储,含有 1467 个不同的人物,由 5 对摄像头采集。

目录结构
CUHK-03
├── “detected”── 5 x 1 cell
├── 843x10 cell
├── 440x10 cell
├── 77x10 cell
├── 58x10 cell
├── 49x10 cell
├── “labeled”── 5 x 1 cell
├── 843x10 cell
├── 440x10 cell
├── 77x10 cell
├── 58x10 cell
├── 49x10 cell
├── “testsets”── 20 x 1 cell
├── 100 x 2 double matrix
目录介绍
(1)”detected”—— 5 x 1 cells,由机器标注,每个 cell 中包含一对摄像头组采集的照片,如下所示:
每个摄像头组由 M x 10 cells 组成,M 为行人索引,前 5 列和后 5 列分别来自同一组的不同摄像头。
cell 内每个元素为一幅 H x W x 3 的行人框图像(uint8 数据类型),个别图像可能空缺,为空集。
843x10 cell ——> 摄像头组pair 1。
440x10 cell ——> 摄像头组pair 2。
77x10 cell ——> 摄像头组pair 3。
58x10 cell ——> 摄像头组pair 4。
49x10 cell ——> 摄像头组pair 5。
(2)”labeled”—— 5 x 1 cells,行人框由人工标注,格式和内容和”detected”相同。
(3)”testsets”—— 20 x 1 cells,测试协议,由 20 个 100 x 2 double 类型矩阵组成 (重复二十次)。
100 x 2 double,100 行代表 100 个测试样本,第 1 列为摄像头 pair 索引,第 2 列为行人索引。
4.ReID评测指标?
这里需要参考周志华老师西瓜书的第二章内容。看过这本书的同学都知道,Cumulative Matching Characteristics (CMC) 是目前计算机视觉领域最流行的性能评估方法。在ReID任务中,考虑一个简单的 single-gallery-shot 情形(即单个对象图像的检索),每个数据集中的ID(gallery ID)只有一个实例. 对于每一次的识别(query), 算法将根据要查询的图像(query) 到所有gallery samples的距离从小到大排序。比如说Market-1501中 Query 和 gallery 集可能来自相同的摄像头视角,但是对于每个query identity, 他/她的来自同一个摄像头的 gallery samples 会被排除掉。对于每个 gallery identity,他们不会只随机采样一个instance. 这意味着在计算CMC时, query 将总是匹配 gallery 中“最简单”的正样本,而不关注其他更难识别的正样本。bounding_box_test 文件夹是 gallery 样本,bounding_box_train 文件夹是 train 样本,query 文件夹是 query 样本。
所以,如果在 multi-gallery-shot 情形下,CMC评估具有缺陷。因此,也使用 mAP(mean average precsion)作为评估指标。mAP可认为是PR曲线下的面积,即平均的查准率。
(关于这里面mAP,CMC,ROC,PR曲线,查准率(precision),查全率(recall)等是啥请参考西瓜书2.3节)
所以,这里我们一般采用两个指标:
- 首次命中率(rank-1):表示在候选库中得到与检索目标相似度排名最高的图片为目标行人的概率。
- 平均精度均值(mAP):对于一些数据集来说,一张probe图像在gallery中可能有多张相匹配的图像,而mAP则是同时考虑了准确率和召回率,更能客观反映模型的性能。
下一篇将结合理论和代码讲述如何构建一个baseline网络,包括迁移学习finetune一个backbone,以及几个训练模型的tricks。