Elasticsearch原理(五):Master机制及脑裂分析
Elasticsearch并不像其他工具那样依赖zookeeper,它自己内部有一套维护集群的体系。本文主要研讨Elasticsearch中Master的选举机制。
Elasticsearch中Master的作用
Elasticsearch中的Master并不像mysql、hadoop集群的master那样,它既不是集群数据的唯一流入点,也不是所有元数据的存放点。所以,一般情况下Elasticsearch的Master负载是很低的。
Elasticsearch的Master有一项工作是其他节点做不到的,那就是维护集群状态。
集群状态中包括以下信息:
- 集群层面的设置
- 集群内有哪些节点
- 各索引的设置,映射,分析器和别名等
- 索引内各分片所在的节点位置
上述的集群状态信息,由Master节点进行维护,并且同步到集群中所有节点。也就是说集群中的任何节点都存储着集群状态信息,但只有Master能够改变信息。我们可以通过接口读取它,如:/_cluster/state
集群状态的修改通过Master节点完成,比如索引的创建删除,mapping的修改等等。如果我们设置了dynamic=true,这个时候如果发现新字段,数据节点是需要跟Master通信,通知Master修改Mapping。这个时候的index写入是阻塞的。等Master修改了集群状态之后,再同步到所有节点,才可以继续写入。
对于这一点可以给出两点优化经验:
- 对于已知的mapping,可以选择禁用动态修改,这样就不会导致写入过程中,由于mapping的改变而导致性能的下降。后果就是不符合mapping规则的写入,最终结果是写入失败。禁用:”dynamic”:”strict”
- 对于每天需要大批量新建索引的场景,比如日志。我们可以选择在业务峰值很低的时间点把index预建出来,这样就会降低高峰时期新建索引对性能的影响。这对于field过多的bulk请求尤其重要。
对于数据的写入,Elasticsearch是通过_routing计算hash,然后除分片数,简单的取余来得知一条数据应该放在哪个分片里,加上现在集群每个节点都会存储集群状态,那么,整个集群里,任意节点都可以知道一条数据该往哪个节点分片上存储了。反之也知道该去哪个分片读。所以,Elasticsearch数据的读写是不需要发送请求到master节点,任何节点都可以作为数据读写的切入点。
关于Elasticsearch的Master选举机制
Elasticsearch的Master与其它类似Hbase的Master选举机制并不一样,Hbase是依赖zookeeper,集群启动后每个节点都会向zookeeper组册,zookeeper保证只有一个节点会注册成为Master。当Master挂掉之后,zookeeper会从其他注册节点中再选举一个Master出来。
Elasticsearch并不依赖zookeeper,Elasticsearch自带有一套选举机制。如果是集群扩容加一个节点进来,那么肯定会跟随之前集群已有的Master。如果是集群刚刚启动,这个时候就需要进行Master的选举。
选举算法
Bully算法
比较常见的一种算法,它假定所有的节点都有一个唯一id,并对根据id进行排序。然后选举出最大的id,作为Master。这种方法的弊端是容易造成一种反复选举的情况。比如最大的id负载过大,导致假死,这个时候选举出第二大的最为Master。过一会第一大的id恢复了,又选最大的作为Master,然后又假死,反反复复。
Elasticsearch的解决方法是通过推迟选举直到当前Master失效之后,才会进行新的Master选举。但是这种做法也有个弊端,就是会产生脑裂,同时选举多个Master出来。这里Elasticsearch的做法是采用投票过半数的方式来决定Master,避免脑裂。关于脑裂文章的最后会详细说明。
选举流程
流程图
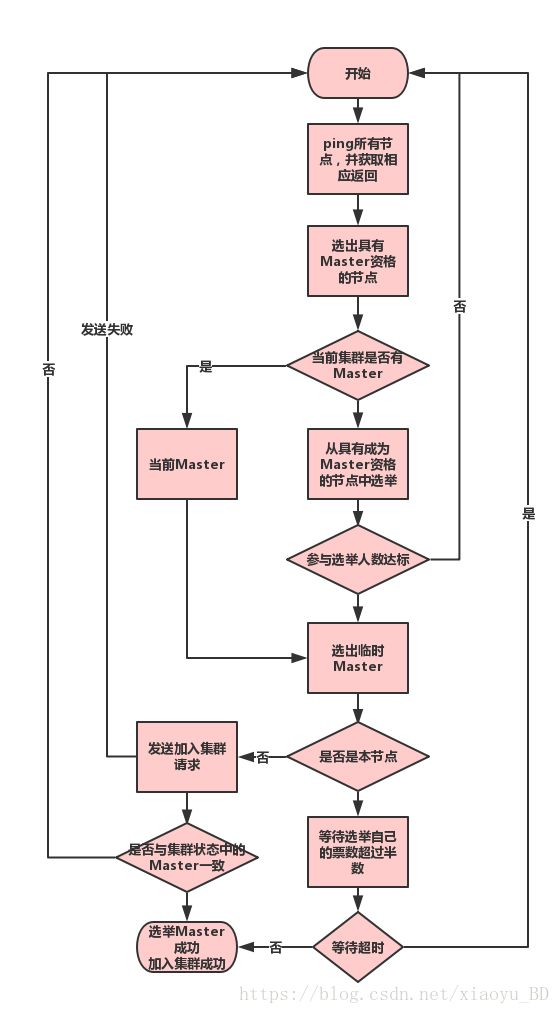
这里说的投票其实就是发起加入集群的请求,在 addIncomingJoin 过程统计投票,收到的连接被存储到 joinRequestAccumulator。
在 checkPendingJoinsAndElectIfNeeded 中检查投票是否足够,其中会过滤掉没有 Master 资格节点的投票。
源码参考:
https://github.com/elastic/elasticsearch/blob/237650e9c054149fd08213b38a81a3666c1868e5/server/src/main/java/org/elasticsearch/discovery/zen/NodeJoinController.java
public synchronized void addIncomingJoin(DiscoveryNode node, MembershipAction.JoinCallback callback) {
ensureOpen();
joinRequestAccumulator.computeIfAbsent(node, n -> new ArrayList<>()).add(callback);
}
public synchronized boolean isEnoughPendingJoins(int pendingMasterJoins) {
final boolean hasEnough;
if (requiredMasterJoins < 0) {
// requiredMasterNodes is unknown yet, return false and keep on waiting
hasEnough = false;
} else {
assert callback != null : "requiredMasterJoins is set but not the callback";
hasEnough = pendingMasterJoins >= requiredMasterJoins;
}
return hasEnough;
}
private Map getPendingAsTasks() {
Map tasks = new HashMap<>();
joinRequestAccumulator.entrySet().stream().forEach(e -> tasks.put(e.getKey(), new JoinTaskListener(e.getValue(), logger)));
return tasks;
}
public synchronized int getPendingMasterJoinsCount() {
int pendingMasterJoins = 0;
for (DiscoveryNode node : joinRequestAccumulator.keySet()) {
if (node.isMasterNode()) {
pendingMasterJoins++;
}
}
return pendingMasterJoins;
} 流程说明
1) 首先节点会ping所有节点,并获取PingResponse(结果返回)。
源码参考地址:
https://github.com/elastic/elasticsearch/blob/db6e8c736d92582fe56024993450ce0a987b498d/server/src/main/java/org/elasticsearch/discovery/zen/ZenDiscovery.java
private DiscoveryNode findMaster() {
logger.trace("starting to ping");
List fullPingResponses = pingAndWait(pingTimeout).toList();
if (fullPingResponses == null) {
logger.trace("No full ping responses");
return null;
}
if (logger.isTraceEnabled()) {
StringBuilder sb = new StringBuilder();
if (fullPingResponses.size() == 0) {
sb.append(" {none}");
} else {
for (ZenPing.PingResponse pingResponse : fullPingResponses) {
sb.append("\n\t--> ").append(pingResponse);
}
}
logger.trace("full ping responses:{}", sb);
}
...
private ZenPing.PingCollection pingAndWait(TimeValue timeout) {
final CompletableFuture response = new CompletableFuture<>();
try {
zenPing.ping(response::complete, timeout);
} catch (Exception ex) {
// logged later
response.completeExceptionally(ex);
}
try {
return response.get();
} catch (InterruptedException e) {
logger.trace("pingAndWait interrupted");
return new ZenPing.PingCollection();
} catch (ExecutionException e) {
logger.warn("Ping execution failed", e);
return new ZenPing.PingCollection();
}
} 2) 过滤掉所有master节点
3) 创建了三张表
- ActiveNodes: ping 结果 + localnode
- NodesJoinedAtleastOnceBefore: 如果以前已加入群集,则将其添加到此列表中(内存已有 clusterState, 非磁盘中的),可能包含 localnode
- pingMasters: 主节点列表, ping 返回的节点中指示的 master 节点,正常是重复的同一个节点,不包含 localnode,因为可能会在没有任何其他节点的检查/验证的情况下,在ZenDiscover # innerJoinCluster()中进行选举
其中,joinedOnceActiveNodes.size <= activeNodes.size,差别在于是否含有 localnode, 其他的内容都一样,都是来自ping 的结果。
4) 如果pingMasters不为空,当前集群认为存在 Master
- 在这些pingMasters中选择主
- 此列表不包含本地节点如果 pingMasters 为空, 当前集群认为不存在 Master
- 首先在 NodesJoinedAtleastOnceBefore 中选举
- 如果没有选中,则在 ActiveNodes 上进行选举
5) 选出临时Master之后,并不是最后确认的Master,而是需要对其进行投票。
6) 如果是本节点选择作为Master,则
- 等待其他节点的投票数超过半数
- 如果等待超时后投票数没有超过半数,则认为选举失败,重新开始
- 成功选举自己为Master之后,发送集群状态到所有节点
源码参考地址:
https://github.com/elastic/elasticsearch/blob/db6e8c736d92582fe56024993450ce0a987b498d/server/src/main/java/org/elasticsearch/discovery/zen/ZenDiscovery.java
if (transportService.getLocalNode().equals(masterNode)) {
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1); // we count as one
logger.debug("elected as master, waiting for incoming joins ([{}] needed)", requiredJoins);
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,
new NodeJoinController.ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
synchronized (stateMutex) {
joinThreadControl.markThreadAsDone(currentThread);
}
}
@Override
public void onFailure(Throwable t) {
logger.trace("failed while waiting for nodes to join, rejoining", t);
synchronized (stateMutex) {
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
}
);
}
7) 如果是其他节点选为Master,则
- 停止连接数的累加
- 向Master发送请求,申请加入集群。
- 获取集群状态,如果集群状态中与选择的Master不一致,则重新开始
源码参考地址:
https://github.com/elastic/elasticsearch/blob/db6e8c736d92582fe56024993450ce0a987b498d/server/src/main/java/org/elasticsearch/discovery/zen/ZenDiscovery.java
if (transportService.getLocalNode().equals(masterNode)) {
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1); // we count as one
logger.debug("elected as master, waiting for incoming joins ([{}] needed)", requiredJoins);
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,
new NodeJoinController.ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
synchronized (stateMutex) {
joinThreadControl.markThreadAsDone(currentThread);
}
}
@Override
public void onFailure(Throwable t) {
logger.trace("failed while waiting for nodes to join, rejoining", t);
synchronized (stateMutex) {
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
}
);
}
选举时间
- 集群重启
- Master挂掉,其他节点检测到Master死亡,会触发重新选举。
新Master获取最新集群状态
新选举出的Master并不一定具备最新的集群状态,它是通过gateway 模块来实现集群状态的持久化和恢复。流程如下:
- 枚举集群中所有具备成为Master 资格的节点列表
- 通过listGatewayMetaState获取这些节点上存储的集群状态
- 通过版本号确定最新的集群状态并使用
脑裂
通过本文的描述,脑裂应该很容易理解了,就是一个集群分裂成两个集群,出现了两个Master。这里如果要避免脑裂要配置discovery.zen.minimum_master_nodes=N/2+1。这个配置的意思是说在选举Master的过程中,需要多少个节点通信,说白点就是票数。如果达不到N/2+1,就是超过半数,就会选举失败,重新选举。
如下图:
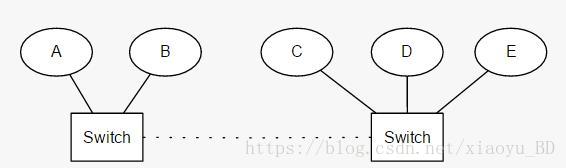
这里ab无法选择Master。
关于脑裂的优化:
#一个节点多久ping一次,默认1s
discovery.zen.fd.ping_interval: 1s
##等待ping返回时间,默认30s
discovery.zen.fd.ping_timeout: 10s
##ping超时重试次数,默认3次
discovery.zen.fd.ping_retries: 3
##选举时需要的节点连接数
discovery.zen.minimum_master_nodes=N/2+1总结
本文讲述了Elasticsearch中Master的作用和选举机制,Elasticsearch是如何实现不依赖zookeeper来维护集群Master。包括整个选举流程,脑裂的原理和如何避免脑裂。
更多:Elasticsearch深入理解专栏
——————————————————————————————————
作者:桃花惜春风
转载请标明出处,原文地址:
https://blog.csdn.net/xiaoyu_BD/article/details/82016395
如果感觉本文对您有帮助,您的支持是我坚持写作最大的动力,谢谢!