深信服面试准备题库
sangfor面试准备
(已拿offer)(已离职)
Linux网络编程
1.域套接字比流式套接字快的原因?
UNIX域套接字用于同一台pc上运行的进程之间通信,它仅仅复制数据,不执行协议处理,不需要增加删除网络报头,无需计算校验和,不产生顺序号,无需发送确认报文。
unix域套接字地址结构如下定义:
#include 没有端口和IP地址等信息
2.connect实现了什么?UDP是否可以使用?
tcp使用connect函数,经过三次握手建立连接
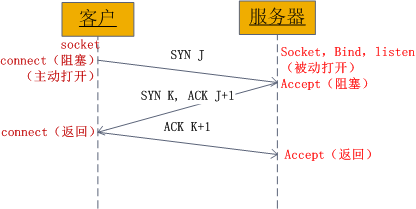
UDP可以使用,在UDP收发数据有两种方式:
- socket->sendto/recvfrom
- socket->connect->send/recv
UDP socket使用connect仅仅是指定了唯一的IP地址和端口号,没有三次握手。这样做的目的是限制socket仅能与一个对端交换数据报。
3.TCP socket接收数据怎么实现的,recv的返回值
可以使用read或recv,recv函数的声明如下
/* Read N bytes into BUF from socket FD.
Returns the number read or -1 for errors.
This function is a cancellation point and therefore not marked with
__THROW. */
extern ssize_t recv (int __fd, void *__buf, size_t __n, int __flags);
返回值有:
- >0 成功接收的数据大小
- =0 对方连接关闭
- -1 错误,需要获取错误码errno
4.recv函数错误怎么处理,错误码errno有哪些?
while(1)
{
cnt = (int)recv(m_socket, pBuf,RECVSIZE, 0);
if( cnt >0 )
{
//正常处理数据
}
else
{
if((cnt<0) &&(errno == EAGAIN||errno == EWOULDBLOCK||errno == EINTR))
//这几种错误码,认为连接是正常的,继续接收
{
continue;//继续接收数据
}
break;//跳出接收循环
}
}
常见的错误码errno有
- EINTR 阻塞操作被取消阻塞的调用打断
- ETIMEOUT
- 操作超时
- 服务器做了读数据做了超时限制,读时发生了超时
- EAGAIN
- send返回值小于要发送的数据数目
- recv返回值小于请求的长度时说明缓冲区已经没有可读数据
- 当socket是非阻塞时,如返回此错误,表示写缓冲队列已满,可以做延时后再重试
- EWOULDBLOCK 资源暂时不可用
- EPIPE socket关闭
5.read/write和send/recv区别
在功能上,read/write是recv/send的子集。read/wirte是更通用的文件描述符操作,而recv/send在socket领域则更“专业”一些。
如果有如下几种需求,则read/write无法满足,必须使用recv/send:
- 为接收和发送进行一些选项设置
- 从多个客户端中接收报文
- 发送带外数据(out-of-band data)
6.tcp里面的time_wait状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xuWfm0OF-1582258488789)(https://blog.jiar.vip/2017/08/24/TCP%E5%9B%9B%E6%AC%A1%E6%8C%A5%E6%89%8B%E7%AE%80%E4%BB%8B/tcp_hand_wave_detail.png)]
TIME_WAIT 状态,超时时间占用了 2MSL(Maximum segment lifetime) ,在 Linux 上固定是 60s
有这个状态是两方面的原因
-
一个数据报在发送途中或者响应过程中有可能成为残余的数据报,因此必须等待足够长的时间避免新的连接会收到先前连接的残余数据报,而造成状态错误。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-19RImwR0-1582258488790)(http://blog.qiusuo.im/images/duplicate-segment.png)]
-
确保被动关闭方已正常关闭
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XS74ohqW-1582258488790)(http://blog.qiusuo.im/images/last-ack.png)]
但是这样也造成了主动关闭方进入 TIME-WAIT 状态后,无论对方是否收到 ACK ,都需要等待 60s 。耗费内存、CPU及端口。为了解决这个问题,TCP协议推出了一个扩展,在 TCP Header 中可以添加2个4字节的时间戳字段,第一个是发送方的时间戳,第二个是接受方的时间戳。这样就可以避免上面两种情况。
- 防止残余报文混入新连接。得益于时间戳的存在,残余的TCP报文由于时间戳过旧,直接被抛弃。
- 当被动关闭方收到三次握手的 SYN ,得益于时间戳的存在,并不是回应一个 RST ,而是回应 FIN+ACK,而此时主动关闭方正在 SYN-SENT 状态,对于突如其来的 FIN+ACK,直接回应一个 RST ,被动关闭方接受到这个 RST 后,连接就关闭被回收了。当主动关闭方再次发起 SYN 时,就可以三次握手建立正常的连接
关于TIME_WAIT数量太多。从上面的描述我们可以知道,TIME_WAIT是个很重要的状态,但是如果在大并发的短链接下,TIME_WAIT 就会太多,这也会消耗很多系统资源。只要搜一下,你就会发现,十有八九的处理方式都是教你设置两个参数,一个叫tcp_tw_reuse,另一个叫tcp_tw_recycle的参数,这两个参数默认值都是被关闭的,后者recyle比前者resue更为激进,resue要温柔一些。另外,如果使用tcp_tw_reuse,必需设置tcp_timestamps=1,否则无效。
6.epoll的水平触发和边缘触发
epoll是实现I/O多路复用的一种方法,有水平触发(level trigger,LT,默认)和边缘触发(edge trigger,ET)两种工作模式,区别在于两种模式的返回就绪状态的时间不同。
- 水平触发
- 读:缓冲内容不为空返回读就绪
- 写:缓冲区还不满返回写就绪
- 边缘触发
- 读:
- 缓冲区由不可读变为可读
- 新数据到达,缓冲区中待读数据变多时
- 写:
- 当缓冲区由不可写变为可写
- 当有旧数据被发送走,即缓冲区中的内容变少的时候
- 读:
epoll之所以高效,是因为epoll将用户关心的文件描述符放到内核里的一个事件表中,而不是像select/poll每次调用都需要重复传入文件描述符集或事件集。比如当一个事件发生(比如说读事件),epoll无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入就绪队列的描述符集合就行了。
C/C++语言基础
1.new和malloc的区别?
new/delete是C++操作符,malloc/free是库函数new自行计算需要空间的大小,malloc需要指定大小new从自由存储区分配内存,malloc从堆上分配内存new在分配内存时调用构造函数,delete在释放内存时调用析构函数,malloc只分配内存不做初始化- 在分配内存失败时,
new抛出bac_alloc异常,malloc则返回NULL
2.能不能用内存比较的方法比较两个struct对象
不能,struct对象由于内存对齐会有内存间隙,所以就算所以成员变量都相等,内存比较还是得到不相等的结果。
我觉得可以先memset初始化之后再使用对象,然后就可以用memcmp来对比。(有指针的话不行)
或者选择重载==运算符,一一比较所有成员变量是否相等
3.strcpy与memcpy的区别
- 复制的内容不同
- strcpy无需指定长度
4.strcpy有什么缺点
如果参数dest所指的内存空间不够大,可能会造成缓冲溢出的错误情况。
5.C如何使用cpp文件的函数?
C调C++函数:
// C++ code:
extern "C" void f(int);
void f(int i){...}
混合调用时,在C++的.h和.cpp文件中写入
#ifdef __cplusplus
extern "C" {
#endif
//一段代码
#ifdef __cplusplus
}
#endif
6.对于大的数组,如何使用局部变量?
malloc
7.不同文件中如何引用外部变量?
定义全局变量,其他文件extern声明该变量
8.C++中拷贝构造函数形参用值来进行传递有什么影响?
不能使用值来传递
如果拷贝构造函数中的参数不是一个引用,即形如CClass(const CClass c_class),那么就相当于采用了传值的方式(pass-by-value),而传值的方式会调用该类的拷贝构造函数,从而造成无穷递归地调用拷贝构造函数。因此拷贝构造函数的参数必须是一个引用。
9.递归时栈溢出怎么办?
- 将递归转化为非递归
- 增大栈空间
10.任何递归都可以用非递归实现么?
不是,算法书上有介绍一个双递归Ackerman函数就没有非递归方式的定义
A ( 1 , 0 ) = 2 A ( 0 , m ) = 1 A ( n , 0 ) = n + 2 A ( n , m ) = A ( A ( n − 1 , m ) , m − 1 ) A(1,0)=2\\ A(0,m)=1\\ A(n,0)=n+2\\ A(n,m)=A(A(n-1,m),m-1) A(1,0)=2A(0,m)=1A(n,0)=n+2A(n,m)=A(A(n−1,m),m−1)
但是理论上所有递归可以改写成循环,也可以避免栈溢出
11.如何获得当前执行文件的路径
int main(int argc, char const *argv[])
{
cout << argv[0] << endl;
return 0;
}
12.printf怎么实现可变参数
void my_printf(char *val, ...)
{
int ch;
va_list arg;
va_start(arg, val);
while (*val != '\0')
{
switch (*val)
{
case '%': //遇到%执行switch case语句
{
if (*(val + 1) == 'c') //输出字符
{
ch = va_arg(arg, char);
putchar(ch);
val++; //指针变量向下偏移一个单位
}
else if (*(val + 1) == 'd')
{
ch = va_arg(arg, char); //输出整形
printd(ch);
val++;
}
else if (*(val + 1) == 's') //输出字符串
{
char *p = va_arg(arg, char *);
while (*p != '\0')
{
putchar(*p);
p++;
}
val++; //指向头一变量的下一个字符
}
else
putchar('%');
break;
}
default:
{
putchar(*val);
break;
}
}
val++;
}
va_end(arg);
}
13.struct内存对齐
struct A
{
char a;
long b;
char c;
double d;
};
struct B
{
char a;
char c;
long b;
double d;
};
sizeof(A)=24,sizeof(B)=16
14.fopen文件操作中,文本模式和二进制模式有何区别,换行模式有什么区别?
在Linux下两者没有区别,换行模式为\n
但是在Windows下换行模式为\r\n,若使用文本模式打开,系统会将所有\r\n转换为\n,写入时则将所有\n转换为\r\n写入,如果以二进制读写就不会发生这样的转换。
所以以
数据结构与算法
1.一步可以上一级台阶也可以上两级台阶,问从1上到第n级有多少种走法,解法有几种?
斐波那契数列:f[n]=f[n-1]+f[n-2]
可以用递归或循环,也可以用公式
F ( n ) = 1 5 ∗ ( ( 1 + 5 2 ) n + 1 − ( 1 − 5 2 ) n + 1 ) F(n)=\frac{1}{\sqrt{5}}*((\frac{1+\sqrt{5}}{2})^{n+1}-(\frac{1-\sqrt{5}}{2})^{n+1}) F(n)=51∗((21+5)n+1−(21−5)n+1)
2.对于N个点的网络,求任意两点的最短路径
如果查询次数很少则用单源最短路Dijkstra,查询次数很多则用Floyd
3.Dijkstra的思想
贪心。每次选择不在集合中的最近的点加入集合,然后对其他不在集合中的点进行松弛操作,直到所有点都加入集合
4.手写二分
int arr[maxn];
int n;
int bs(int x)
{
int lo=0,hi=n-1,mid;
while(lo<=hi)
{
mid=lo+((hi-lo)>>1);
if(arr[mid]==x)
return mid;
if(arr[mid]>x)
hi=mid-1;
else
lo=mid+1;
}
return -1;
}
5.4亿个数,你只有1G内存,你怎么判断某个数已经出现?
int的取值范围是 − 2 31 至 2 31 − 1 -2^{31}至2^{31}-1 −231至231−1,我们可以连续申请 2 32 b i t = 2 30 b y t e = 1 G 2^{32} bit = 2^{30} byte = 1G 232bit=230byte=1G内存,这样,每个bit都可以对应一个int数字,将这1G内存初始化为0,接下来每次处理一个数字,就给它所对应的bit设为1,查询时就只要看其对应的bit值,当然0会有两个bit对应所以特殊处理一下。
6.一个公交站在1分钟内有车经过概率是p,问3分钟内有车经过概率
正向考虑每分钟出现车的概率:
P = p + ( 1 − p ) ∗ p + ( 1 − p ) ∗ ( 1 − p ) ∗ p P=p+(1-p)*p+(1-p)*(1-p)*p P=p+(1−p)∗p+(1−p)∗(1−p)∗p
反向考虑:
P = 1 − ( 1 − p ) 3 P=1-(1-p)^3 P=1−(1−p)3
7.快排的原理
如果不考虑随机化,每次选择当前范围的第一个数作为标杆,然后再将这个范围的所有比它小的数放到他左边,大的放到他右边,由这个标杆的现在位置划分出两个范围,分别对这两个范围的数再重复这样的操作,直到范围大小为1
8.两个水晶球怎么测试出100层楼那个是水晶球破碎的临界点
DP
9.堆排序的思想
堆是一颗完全二叉树,每次建堆的完成后,堆顶(根节点)为最小值,将堆顶取出,把二叉树的最后一个节点移到根节点,再次建堆,重复此过程直到堆的大小为1
第一次建堆是从最后一个非叶子节点向前遍历,以后都从根节点
建堆的过程:由此节点开始,对比左右子节点,若有比根节点大的,则交换这两个节点,并从被交换的节点继续迭代
10.象棋中,马从A点跳到B点的最小次数
BFS