OpenCV 文字检测与识别模块
OpenCV 文字检测与识别模块
该模块在扩展模块中,需自行下载
下载地址:https://github.com/opencv/opencv_contrib/tree/4.0.0
说明文档:
文字检测 https://docs.opencv.org/4.0.0/da/d56/group__text__detect.html
文字识别 https://docs.opencv.org/4.0.0/d8/df2/group__text__recognize.html
参考文章:https://github.com/opencv/opencv_contrib/blob/master/modules/text/samples/text_recognition_cnn.cpp
https://github.com/opencv/opencv_contrib/blob/master/modules/text/samples/webcam_demo.cpp
文字检测
1.textDetectorCNN
OpenCV的文字检测模块textDetectorCNN中使用了TextBoxes:具有单个深度神经网络的快速文本检测器 链接地址为: https://github.com/MhLiao/TextBoxes
其中已经训练过的文件:
| 函数名 | 内容 | 地址 |
|---|---|---|
| modelWeightsFilename | 描述分类器体系结构的prototxt文件的相对或绝对路径。 | textbox.prototxt 在下载的扩展模块源码中opencv_contrib/modules/text/samples/textbox.prototxt |
| modelWeightsFilename | 包含caffe-binary形式的模型的预训练权重的文件的相对或绝对路径。 | TextBoxes_icdar13.caffemodel http://pan.baidu.com/s/1qY73XHq |
cv::Mat temp;
src.convertTo(temp, CV_8UC3, 1);//src 输入图像
cv::imshow("src", temp);
dst1 = temp.clone();
cv::Ptr detector= cv::text::TextDetectorCNN::create("textbox.prototxt", "TextBoxes_icdar13.caffemodel");
std::vector < cv::Rect > boxes;//识别区域
std::vector < float > sources;//评估分数
detector->detect(temp, boxes, sources);
float threshold = 0.5;
for (int i = 0; i < boxes.size(); i++)
{
if (sources[i] > threshold)
{
cv::Rect rect = boxes[i];
cv::rectangle(dst1, rect, cv::Scalar(255, 0, 0), 2);
}
}
cv::imshow("Text detection result", dst1);
原图

结果

文字识别
1.OCRHolisticWordRecognizer
OCRHolisticWordRecognizer类提供了分段词语的功能。给定预定义的词汇表,使用DictNet来选择给定输入图像的最可能的词。
DictNet详细描述于:Max Jaderberg等:使用卷积神经网络阅读野外文本,IJCV 2015 http://arxiv.org/abs/1412.1842
模型文件下载地址:https://pan.baidu.com/s/1jl1g6lrNyCl8tM1BbLk6-Q bng0
https://pan.baidu.com/s/10yjRfrRALcQFLBfYKoXq5w 21gq
wordSpotter = (cv::text::OCRHolisticWordRecognizer::create("dictnet_vgg_deploy.prototxt", "dictnet_vgg.caffemodel", "dictnet_vgg_labels.txt"));
dst1 = src.clone();
for (size_t i = 0; i < textBoxes.size(); i++)
{
cv::Mat wordImg;
cv::cvtColor(src(textBoxes[i]), wordImg, cv::COLOR_BGR2GRAY);
std::string word;
std::vector confs;
wordSpotter->run(wordImg, word, NULL, NULL, &confs);//检测
cv::Rect currrentBox = textBoxes[i];
cv::rectangle(dst1, currrentBox, cv::Scalar(0, 255, 255), 2, cv::LINE_AA);
int baseLine = 0;
cv::Size labelSize = cv::getTextSize(word, cv::FONT_HERSHEY_PLAIN, 1, 1, &baseLine);
int yLeftBottom = currrentBox.y>labelSize.height? currrentBox.y: labelSize.height;
cv::rectangle(dst1, cv::Point(currrentBox.x, yLeftBottom - labelSize.height),
cv::Point(currrentBox.x + labelSize.width, yLeftBottom + baseLine), cv::Scalar(255, 255, 255), cv::FILLED);
cv::putText(dst1, word, cv::Point(currrentBox.x, yLeftBottom), cv::FONT_HERSHEY_PLAIN, 1, cv::Scalar(0, 0, 0), 1, cv::LINE_AA);
}
cv::imshow("Text recognition", dst1);
结果

(极值区域)文本定位与识别法
与上方的卷积神经网络识别,存在识别不稳定的问题。
void textRecognize(int REGION_TYPE,int GROUPING_ALGORITHM)
{
cv::Mat gray;
std::vector channels;
cv::cvtColor(src, gray, cv::COLOR_BGR2GRAY);
std::vector > regions(2);
channels.clear();
channels.push_back(gray);
channels.push_back(255 - gray);
regions[0].clear();
regions[1].clear();
switch (REGION_TYPE)
{
case 0: // ERStats
parallel_for_(cv::Range(0, (int)channels.size()), Parallel_extractCSER(channels, regions, er_filters1, er_filters2));
break;
case 1: // MSER
std::vector > contours;
std::vector bboxes;
cv::Ptr mser = cv::MSER::create(21, (int)(0.00002*gray.cols*gray.rows), (int)(0.05*gray.cols*gray.rows), 1, 0.7);
mser->detectRegions(gray, contours, bboxes);
//Convert the output of MSER to suitable input for the grouping/recognition algorithms
if (contours.size() > 0)
MSERsToERStats(gray, contours, regions);
break;
}
// Detect character groups
std::vector< std::vector > nm_region_groups;
textBoxes.clear();
switch (GROUPING_ALGORITHM)
{
case 0: // exhaustive_search
erGrouping(src, channels, regions, nm_region_groups, textBoxes, cv::text::ERGROUPING_ORIENTATION_HORIZ);
break;
case 1: //multioriented
erGrouping(src, channels, regions, nm_region_groups, textBoxes, cv::text::ERGROUPING_ORIENTATION_ANY, "./trained_classifier_erGrouping.xml", 0.5);
break;
}
/*Text Recognition (OCR)*/
int bottom_bar_height = src.rows / 7;
cv::copyMakeBorder(src, dst1, 0, bottom_bar_height, 0, 0, cv::BORDER_CONSTANT, cv::Scalar(150, 150, 150));
float scale_font = (float)(bottom_bar_height / 85.0);
std::vector detections;//只有字体的图片
cv::Mat temp;
src.convertTo(temp, CV_8UC1, 1);
for (int i = 0; i < (int)textBoxes.size(); i++)//字体的矩形数量
{
cv::rectangle(dst1, textBoxes[i].tl(), textBoxes[i].br(), cv::Scalar(255, 255, 0), 3);
cv::Mat group_img = cv::Mat::zeros(src.rows + 2, src.cols + 2, CV_8UC1);
er_draw(channels, regions, nm_region_groups[i], group_img);
group_img(textBoxes[i]).copyTo(group_img);
copyMakeBorder(group_img, group_img, 15, 15, 15, 15, cv::BORDER_CONSTANT, cv::Scalar(0));
detections.push_back(group_img);
}
cv::imshow("text find", dst1);
std::vector outputs((int)detections.size());
std::vector< std::vector > boxes((int)detections.size());
std::vector< std::vector > words((int)detections.size());
std::vector< std::vector > confidences((int)detections.size());
float min_confidence1 = 0.f, min_confidence2 = 0.f;
min_confidence1 = 51.f;
min_confidence2 = 60.f;
// parallel process detections in batches of ocrs.size() (== num_ocrs)
for (int i = 0; i < (int)detections.size(); i = i + (int)num_ocrs)
{
cv::Range r;
if (i + (int)num_ocrs <= (int)detections.size())
r = cv::Range(i, i + (int)num_ocrs);
else
r = cv::Range(i, (int)detections.size());
// NM_chain_features + KNN
parallel_for_(r, Parallel_OCR(detections, outputs, boxes, words, confidences, decoders));
}
showText(outputs);
for (int i = 0; i < (int)detections.size(); i++)
{
outputs[i].erase(remove(outputs[i].begin(), outputs[i].end(), '\n'), outputs[i].end());
//cout << "OCR output = \"" << outputs[i] << "\" length = " << outputs[i].size() << endl;
if (outputs[i].size() < 3)
continue;
for (int j = 0; j < (int)boxes[i].size(); j++)
{
boxes[i][j].x += textBoxes[i].x - 15;
boxes[i][j].y += textBoxes[i].y - 15;
if ((words[i][j].size() < 2) ||
((words[i][j].size() == 2) && (words[i][j][0] == words[i][j][1])) ||
isRepetitive(words[i][j]))
continue;
cv::rectangle(dst1, boxes[i][j].tl(), boxes[i][j].br(), cv::Scalar(255, 0, 255), 3);
cv::Size word_size = cv::getTextSize(words[i][j], cv::FONT_HERSHEY_SIMPLEX, (double)scale_font, (int)(3 * scale_font), NULL);
cv::rectangle(dst1, boxes[i][j].tl() - cv::Point(3, word_size.height + 3), boxes[i][j].tl() + cv::Point(word_size.width, 0), cv::Scalar(255, 0, 255), -1);
cv::putText(dst1, words[i][j], boxes[i][j].tl() - cv::Point(1, 1), cv::FONT_HERSHEY_SIMPLEX, scale_font, cv::Scalar(255, 255, 255), (int)(3 * scale_font));
}
}
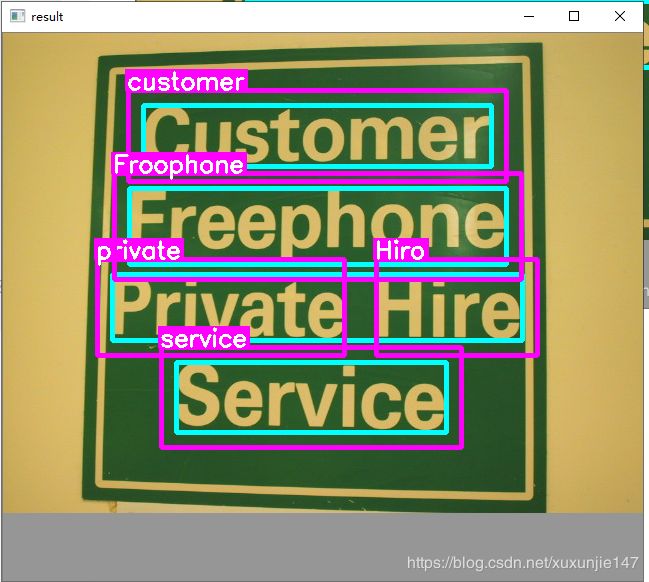
cv::imshow("result", dst1);
}
void er_draw(std::vector &channels, std::vector > ®ions, std::vector group, cv::Mat& segmentation)
{
for (int r = 0; r < (int)group.size(); r++)
{
cv::text::ERStat er = regions[group[r][0]][group[r][1]];
if (er.parent != NULL) // deprecate the root region
{
int newMaskVal = 255;
int flags = 4 + (newMaskVal << 8) + cv::FLOODFILL_FIXED_RANGE + cv::FLOODFILL_MASK_ONLY;
cv::floodFill(channels[group[r][0]], segmentation, cv::Point(er.pixel%channels[group[r][0]].cols, er.pixel / channels[group[r][0]].cols),
cv::Scalar(255), 0, cv::Scalar(er.level), cv::Scalar(0), flags);
}
}
}
bool isRepetitive(const std::string& s)
{
int count = 0;
int count2 = 0;
int count3 = 0;
int first = (int)s[0];
int last = (int)s[(int)s.size() - 1];
for (int i = 0; i < (int)s.size(); i++)
{
if ((s[i] == 'i') ||
(s[i] == 'l') ||
(s[i] == 'I'))
count++;
if ((int)s[i] == first)
count2++;
if ((int)s[i] == last)
count3++;
}
if ((count > ((int)s.size() + 1) / 2) || (count2 == (int)s.size()) || (count3 > ((int)s.size() * 2) / 3))
{
return true;
}
return false;
}
原图

文本定位图

文本识别图