ICML 2018 | 腾讯AI Lab详解16篇入选论文
感谢阅读腾讯AI Lab微信号第30篇文章。我们将深度解析机器学习领域顶会ICML 2018收录的16篇腾讯AI Lab论文。
7月10日至15日,第 35 届国际机器学习会议(ICML 2018)将在瑞典斯德哥尔摩举行。ICML是机器学习领域最顶级的学术会议,今年共收到2473篇投递论文,比去年的1676篇提高47.6%,增幅显著。最终入围论文共621篇,接收率25%,与去年26%持平。
这是腾讯AI Lab第二次参与这一顶级会议,共有16篇论文入选,去年则入选4篇,均位居国内企业前列。我们将在下文中分三类介绍这些文章——新模型与新框架、分布式与去中心化、及机器学习优化方法与理论研究。有的研究具有多重贡献,并不严格按照研究内容区分。
第一部分:新模型与新框架
1、用于强化学习的基于反馈的树搜索
Feedback-based Tree Search for Reinforcement Learning
论文地址:https://arxiv.org/abs/1805.05935
蒙特卡洛树搜索(MCTS)已经在游戏智能体方面取得了很大的成功(比如 AlphaGo),但对于 Atari 或 MOBA 等需要快速决策的视频游戏,树搜索的速度却太慢了。针对这一问题,该论文提出了一种新型的基于模型的强化学习技术,可在原无限范围的马尔可夫决策过程的小型有限范围版本批量上迭代式地应用 MCTS。在以离策略的方式完成强化学习训练之后,智能体无需进一步的树搜索就能实现快速实时的决策。
研究者将这一思想融合到了一个基于反馈的框架中,其中 MCTS 会使用其根节点处生成的观察结果来更新自己的叶节点评估器。其反馈过程如下图所示:(1)从一批采样的状态(三角形)开始运行一组树搜索,(2)使用第 k 次迭代时的策略函数近似(PFA)πk 和价值函数近似(VFA)Vk 的叶估计被用于树搜索过程,(3)使用树搜索结果更新 πk+1 和 Vk+1。

研究者对该方法进行了理论分析,结果表明当样本量足够大且进行了足够多的树搜索时,估计得到的策略能够接近最优表现。这也是对基于批 MCTS 的强化学习方法的首个理论分析。
研究者还使用深度神经网络实现了这种基于反馈的树搜索算法并在《王者荣耀》1v1 模式上进行了测试。为了进行对比,研究者训练了 5 个操控英雄狄仁杰的智能体,结果他们提出的新方法显著优于其它方法,下图给出了他们的方法训练的智能体相对于其它智能体随时间的金币比值变化。
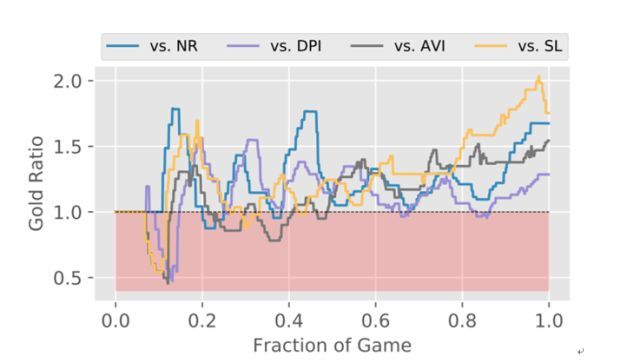
其中,NR 是指没有 rollout 但参数设置与该论文的新方法一样的智能体,DPI 是使用了直接策略迭代的智能体,AVI 是使用了近似价值迭代的智能体,SL 是一个在大约 10 万对人类游戏数据的状态/动作对上通过监督学习训练得到的智能体。
2、通过学习迁移实现迁移学习
Transfer Learning via Learning to Transfer
论文地址:
https://ai.tencent.com/ailab/media/publications//icml/148_Transfer_Learning_via_Learning_to_Transfer.pdf
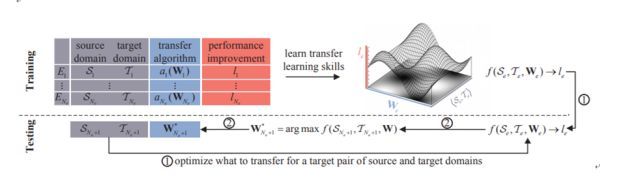
迁移学习的三个核心研究问题是:何时迁移、如何迁移和迁移什么。为特定的迁移任务选择合适的迁移算法往往需要高成本的计算或相关领域的专业知识。为了能更有效地找到适合当前任务的迁移算法,研究者根据人类执行迁移学习的方式,设计了一种可根据之前的迁移学习经历提升新领域之间的迁移学习有效性的新框架:学习迁移(L2T:Learning to Transfer)。
L2T 分为两个阶段。在第一个阶段,每个迁移学习经历都会被编码成三个组件:一对源域和目标域、它们之间被迁移的知识(被参数化为隐含特征向量)、迁移学习带来的性能提升比。然后再从所有经历中学习一个反射函数(reflection function),该函数能将领域对和它们之间被迁移的知识映射到性能提升比。研究者相信这个反射函数就具备决定迁移什么和如何迁移的迁移学习能力。在第二个阶段,新出现的领域对之间所要迁移的内容则可以通过最大化所学习到的反射函数的值而得到优化。
为了证明这种迁移学习方法的优越性,研究者在 Caltech-256 和 Sketches 这两个图像数据集上对 L2T 框架进行了实验评估。下图给出了 L2T 及另外 9 种基准方法在 6 个源域和目标域对上的分类准确度。
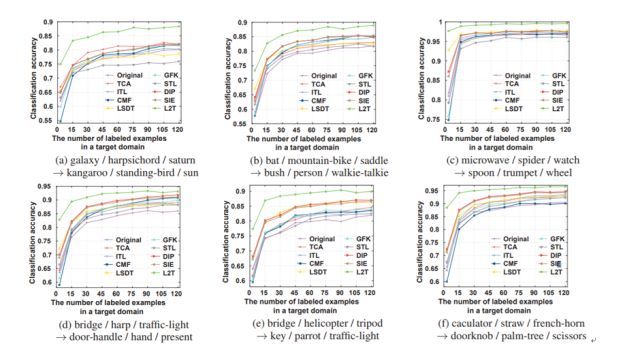
可以看到,不管源域与目标域有较紧密的联系(比如 (a) 中的“galaxy”、“saturn”和“sun”)还是没有显著关联(比如 (c) 和 (f)),L2T 方法的表现都明显优于其它所有基准方法。
3、通过强化学习实现端到端的主动目标跟踪
End-to-end Active Object Tracking via Reinforcement Learning
论文地址:https://arxiv.org/abs/1705.10561
目标跟踪的目标是根据视频的初始帧中的目标标注定位该目标在连续视频中的位置。对于移动机器人和无人机等视角会变动的平台或目标会离开当前拍摄场景的情况,跟踪目标时通常还需要对摄像头的拍摄角度进行持续调整。该论文提出了一种使用强化学习的端到端的主动目标跟踪方法,可直接根据画面情况调整摄像头角度。具体而言,研究者使用了一个 ConvNet-LSTM 网络,其输入为原始视频帧,输出为相机运动动作(前进、向左等)。

上图展示了这个 ConvNet-LSTM 网络的架构,其中的强化学习部分使用了一种当前最佳的强化学习算法 A3C。
因为在现实场景上训练端到端的主动跟踪器还无法实现,所以研究者在 ViZDoom 和 Unreal Engine 进行了模拟训练。在这些虚拟环境中,智能体(跟踪器)以第一人称视角观察状态(视觉帧)并采取动作,然后环境会返回更新后的状态(下一帧)。研究者还设计了一个新的奖励函数以让智能体更加紧跟目标。
实验结果表明,这种端到端的主动跟踪方法能取得优异的表现,并且还具有很好的泛化能力,能够在目标运动路径、目标外观、背景不同以及出现干扰目标时依然稳健地执行主动跟踪。另外,当目标偶尔脱离跟踪时(比如目标突然移动),该方法还能恢复对目标的跟踪。下表给出了不同跟踪方法在 ViZDoom 环境的几个不同场景上的表现比较,其中 AR 表示累积奖励(类似于精确度),EL 表示 episode 长度(类似于成功跟踪的持续帧数)。
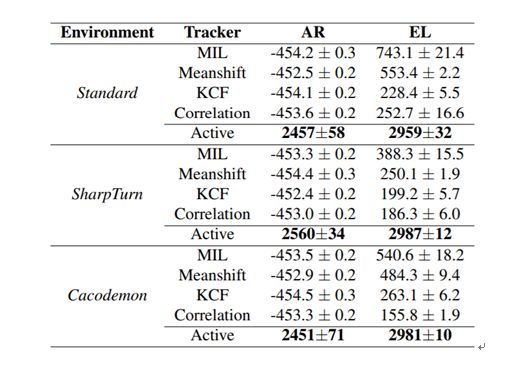
最后,研究者还在 VOT 数据集上执行了一些定性评估,结果表明从虚拟场景学习到的跟踪能力也有望迁移到真实世界场景中。
4、使用局部坐标编码的对抗学习
Adversarial Learning with Local Coordinate Coding
论文地址:https://arxiv.org/abs/1806.04895
生成对抗网络(GAN)是近来一个非常热门的研究方向,也实现了一些成功应用。但 GAN 仍有一些局限性:很多研究都使用了简单的先验分布,GAN 在隐含分布的维度上的泛化能力是未知的。针对这些问题,研究者基于对图像的流形假设提出了一种全新的生成模型,该模型使用了局部坐标编码(LCC),可提升 GAN 在生成拟真图像上的表现。
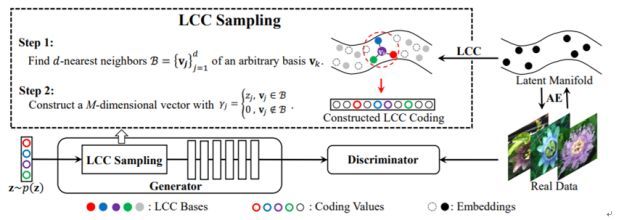
上图展示了该论文提出的 LCC-GAN 方案。研究者首先使用了一个自动编码器(AE)在隐含流形上学习了嵌入来获取数据中的含义信息。然后,他们又使用 LCC 学习一组基数来在该隐含流形上构建局部坐标系统。之后,他们再通过使用一个与一组编码相关的线性函数来近似生成器而将 LCC 引入了 GAN。基于这种近似,他们再通过利用在隐含流形上的局部信息而提出了一种基于 LCC 的采样方法。LCC-GAN 的具体训练过程如下:

其中 LCC 采样方法分为两个步骤:(1)给定一个局部坐标系,我们随机选择一个隐含点(可以是一个基(basis)),然后找到其 d-最近邻点;(2)我们构建一个 M 维向量作为采样的 LCC 编码。其中,该向量的每个元素都对应于那个基的权重。
研究者用 PyTorch 实现了 LCC-GAN 并通过大量基于真实世界数据集的实验对该方法进行了评估。结果表明 LCC-GAN 的表现优于其它多种 GAN 方法(Vanilla GAN、WGAN、Progressive GAN)。下图展示了 LCC-GAN 和 Progressive GAN 基于 CelebA 数据集的人脸生成结果比较。

研究者还推导了 LCC-GAN 的泛化界限,并证明维度较小的输入就足以实现优良的泛化表现。
5、一种可变度量超松弛混合临近外梯度方法的算法框架
An Algorithmic Framework of Variable Metric Over-Relaxed Hybrid Proximal Extra-Gradient Method
论文地址:https://arxiv.org/abs/1805.06137
极大单调算子包含(maximal monotone operator inclusion)问题是非平滑凸优化和凸凹鞍点优化的 Karush-Kuhn-Tucker(KKT)广义方程的一种扩展,其包含大量重要的优化问题并且在统计学、机器学习、信号与图像处理等领域有广泛的应用。在该论文中,研究者关注的算子包含问题是:
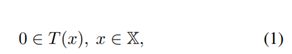
其中, X是一个有限维度的线性向量空间,T:X⇉X是一个极大单调算子。
针对这一问题,研究者提出了一种可变度量超松弛混合临近外梯度方法(VMOR-HPE)的新型算法框架,能保证在解决该问题时的全局收敛。不同于已有的混合临近外梯度(HPE)方法,该框架能根据一种全新的相对误差准则来生成迭代序列,并且还在外梯度步骤中引入了一种超松弛的步长来提升其收敛速度。尤其值得一提的是,这个外梯度步长和超松弛步长都可以事先设定为固定常量,而不是从某个投影问题中获取的值,这能减少很多计算量。

研究者还提供了该框架的迭代复杂度和局部线性收敛速率,从理论上证明一个较大的超松弛步长有助于加速 VMOR-HPE。并且,研究者在文中严格证明了VMOR-HPE算法框架包含大量一阶原始算法和一阶原始-对偶算法为特例。此外,研究者还将 VMOR-HPE 应用到了一类 具有线性等式约束的多块可分复合凸优化问题的KKT 广义方程上,得到了一种尺度化的外梯度校正步骤的临近交替方向乘子法(PADMM-EBB),在该步骤中的尺度化矩阵是通过一种分块式的 Barzilai-Borwein 线搜索技术生成的。该算法的迭代格式如下:

PADMM-EBB 算法
最后,研究者在合成和真实数据集上进行了实验,将 PADMM-EBB 应用在了非负双图正则化低秩表征问题上,结果表明该方法是有效的。
研究表明,这种 VMOR-HPE 算法框架能为原始与原始-对偶算法提供新见解并可用作证明它们的收敛性、迭代复杂度和局部线性收敛速率的强大分析技术。
第二部分:分布式与去中心化
6、针对次模函数最小化的元素安全筛选算法
Safe Element Screening for Submodular Function Minimization
下载地址:https://arxiv.org/abs/1805.08527
次模函数可以看成是离散函数中的凸函数,其在众多领域中有着重要应用,比如:机器学习、计算机视觉和信号处理。然而,在大规模实际应用中,次模函数最小化问题的求解依然是一个具有挑战性的问题。在本文中,我们第一次尝试将大规模稀疏学习中新兴的筛选方法扩展到次模函数最小化中,以加快它的求解过程。通过仔细研究次模函数最小化问题和其对应凸问题之间的关系以及该凸问题最优解的估计,我们提出了一种新颖安全的元素筛选算法,能够在优化过程中迅速检测出一定包含在最优解中的元素(我们称为活跃元素)以及一定不包含在最优解中的元素(不活跃元素)。通过删除不活跃元素和固定活跃元素,问题规模得以显著减小,从而我们能够在不损失任何精度的情况下大大减少计算量。据我们所知,我们的方法是次模函数最优化领域乃至组合优化领域中的第一个筛选算法。因此,我们的方法为加速次模函数最小化算法提供了一种新思路。在合成数据集和实际数据集上的实验结果均证实我们的算法能够显著加速次模函数最小化问题的求解。

研究者首先研究了 SFM 和对应的凸近端问题之间的关系,还研究了这些近端问题的准确原始最优估计。基于该研究,他们提出了一种全新的安全筛选方法:不活动和活动元素筛选(IAES)。该框架由两个筛选规则构成:不活动元素筛选(IES)和活动元素筛选(AES);这两个规则在 IAES 框架中是交替执行的,如下算法 2 所示。

最终该框架可快速识别确保可在优化过程中被包含(活动元素)在 SFM 的最终最优解之内或被排除在外(不活动元素)的元素。然后,研究者可移除不活动元素并固定活动元素,从而大幅降低问题规模,进而在不降低准确度的前提下显著降低计算成本。
该研究为加速 SFM 算法指出了一个新方向。研究者在合成和真实数据集上进行了实验,结果表明他们所提出的方法确实能实现显著加速。下表给出了在图像分割任务上求解 SFM 的运行时间结果(单位:秒)。

可以看到,IAES 带来的加速效果非常明显,最高甚至可达 30.7 倍!
7、生成对抗网络的复合函数梯度学习
Composite Functional Gradient Learning of Generative Adversarial Models
论文地址:https://arxiv.org/abs/1801.06309
生成对抗网络(GAN)已经得到了非常广泛的研究和使用,但由于不稳定问题,GAN 往往难以训练。从数学上看,GAN 求解的是一种最小最大优化问题。而这篇论文则首先提出了一个不依赖于传统的最小最大形式的生成对抗方法理论。该理论表明,使用一个强大的鉴别器可以学习到优良的生成器,并使得每一个函数梯度(functional gradient)步骤之后真实数据分布和生成数据分布之间的 KL 散度都能得到改善,直至收敛到零。
基于这一理论,研究者提出了一种稳定的新型生成对抗方法,即复合函数梯度学习(CFG);如算法 1 所示。

在此基础上,研究者又提出了渐进式 CFG(ICFG,见算法 2)以及更进一步的近似式 ICFG(xICFG,见算法 3)。其中 ICFG 是以渐进方式使用生成器的更新一点一点地逐步更新鉴别器,使得生成器可以不断提供新的更有难度的样本,从而防止鉴别器过拟合。而 xICFG 则能通过训练一个固定大小的近似器(近似 ICFG 所获得的生成器的行为)来对 ICFG 得到的生成器进行压缩,从而提升效率。

研究者还发现,通常的使用 logistic 模型的 GAN 与使用一种极端设置的 xICFG 的特例高度相关,即:GAN 的生成器更新等效于粗略近似 T=1 的 ICFG 得到的生成器。这个视角是理解 GAN 的不稳定性的新角度,即:GAN 的不稳定性源自 T 过小以及粗略近似。
研究者进行了图像生成的实验,结果表明他们提出的新方法是有效的。下图给出了各种方法生成的图像的质量(inception 分数)随训练时间的变化情况。
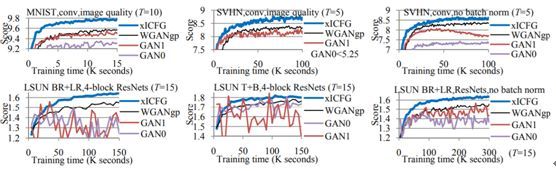
可以看到,尽管 GAN1(使用了 logd 技巧的 GAN)在 LSUN 数据集上偶尔有更优的表现,但 xICFG 的表现总体更优且更稳定。
8、用于高斯图模型中最优估计的图非凸优化
Graphical Nonconvex Optimization for Optimal Estimation in Gaussian Graphical Model
论文地址:https://arxiv.org/abs/1706.01158
高斯图模型已被广泛用于表示一组变量之间的成对的条件依赖关系。graphical lasso 是估计高斯图模型的最常用方法之一。但是,它还未达到理想的收敛速度。具体而言,一般认为 graphical lasso 的谱范数中的最优收敛率大约为
其中 n 是样本规模,d 是节点数量,s 是实际的图中的边数。
在这篇论文中,研究者提出了用于高斯图模型中的最优估计的图非凸优化。然后又通过一系列自适应的凸程序来近似求解。研究者指出,尽管新提出的方法求解的是一系列凸程序,但研究表明在某些规律性条件下,这种新提出的用于估计稀疏集中度矩阵的估计器能实现 的理想收敛率,就好像非零位置事先已知一样。算法 1 展示了这个近似求解过程。然后,通过使用估计的边际方差来重新调整逆相关矩阵,可以得到该集中度矩阵的一个估计器,其谱范数收敛率大约为 和 中的最大值。

算法 1 可使用 glasso 等现有的 R 语言软件包实现。
这种新提出的方法在计算上是可行的,并且能得到能实现理想收敛速度的估计器。使用凸程序通过序列近似引入的统计误差可以使用稀疏模式的概念来进一步提升。
研究者分析了新提出的估计器的理论性质,还将这种新方法扩展到了半参数图模型中,并通过数值研究表明新提出的估计器在估计高斯图模型方面的表现优于其它常用方法。
9、用于大型多类分类问题的候选项与噪声估计
Candidates v.s. Noises Estimation for Large Multi-Class Classification Problem
论文地址:https://arxiv.org/abs/1711.00658
图像分类和语言建模等很多任务的类别数量往往很大,采样是应对这类任务的常用方法,能够帮助降低计算成本和提升训练速度。这篇论文对这一思想进行了扩展,提出了一种使用一个类别子集(候选项类别,其余类别被称为噪声类别——会被采样用于表示所有噪声)的用于多类分类问题的方法:候选项与噪声估计(CANE)。
研究者表明 CANE 总是能保持一致的表现并且很有计算效率。此外,当被观察到的标签有很高的概率属于被选择的候选项时,所得到的估计器会有很低的统计方差,接近最大似然估计器的统计方差。
研究者通过两个具体算法展现了 CANE 方法的优越性。其一是用于 CANE 的一般随机优化过程(算法 1):

另外,研究者还使用了一种树结构(叶表示类别)来促进对候选项选择的快速波束搜索(算法 2)。这种波束搜索具有更低的复杂度,能快速得到预测结果,还能自然地输出最靠前的多项预测。

研究者实验了 CANE 方法在有大量类别的多类分类问题和神经语言建模任务中的应用。下图展示了各种方法在不同分类数据集上的测试准确度随 epoch 的变化情况。可以看到,有更大候选项集的 CANE 在准确度方面基本优于其它方法,有时甚至能超过 softmax 方法。而且 CANE 方法的收敛速度明显胜过噪音对比估计(NCE)和 Blackout。
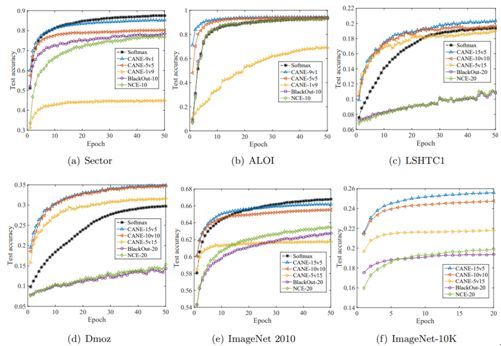
下图则给出了神经语言建模实验的结果。可以看到,CANE 方法的收敛速度比 NCE 和 Blackout 更快,同时还达到了与 softmax 方法同等的困惑度。
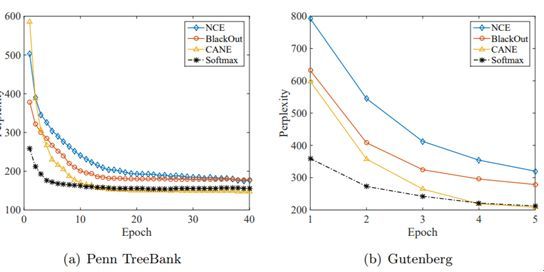
总体而言,实验结果表明 CANE 的预测准确度优于 NCE 及其变体方法和多种之前最佳的树分类器,同时其速度也显著优于标准的 O(K) 方法。
10、使用演示的策略优化
Policy Optimization with Demonstrations
论文地址:
https://ai.tencent.com/ailab/media/publications//icml/152_Policy_Optimization_with_Demonstrations.pdf
对强化学习方法而言,探索仍然是一个突出的难题,尤其是在奖励信号稀疏的环境中。目前针对这一问题的研究方向主要有两个:1)通过鼓励智能体访问之前从未见过的状态来重塑原来的奖励函数;2)使用从某个专家策略采样的演示轨迹来引导学习过程。从演示中学习的方法看起来有克服探索难题的希望,但这通常需要难以收集的质量很高的演示。
结合这两种思路,研究者提出了一种有效地利用可用演示来引导探索的方法,即强制所学到的策略与当前演示之间的占有率匹配。这种方法背后的直观思想是,当奖励信号不可用时,智能体应该在早期学习阶段模拟所演示的行为,从而实现探索。在获得了足够多的能力之后,智能体就可以自己探索新状态了。这实际上是一种动态的固有奖励机制,可被引入强化学习用于重塑原生的奖励。
基于此,研究者开发了一种全新的使用演示的策略优化(POfD)方法,可从演示数据获取知识来提升探索效果。研究表明 POfD 能隐式地塑造动态奖励并助益策略提升。此外,它还可以与策略梯度方法结合起来得到当前最佳的结果。

研究者在一系列常见的基准稀疏奖励任务上进行了实验。结果发现,他们提出的方法的表现甚至可媲美用在理想密集奖励环境中的策略梯度方法;而且即使演示很少且不完美,这种新方法依然表现优异。下面两张图给出了新提出的 POfD 方法与几种强基准方法分别在具有离散动作空间和连续工作空间的稀疏环境中的学习曲线。
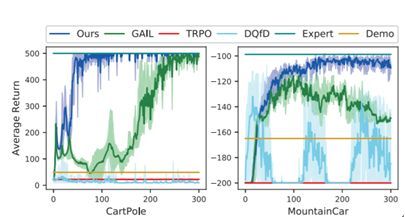
各种方法在具有连续动作空间的稀疏环境中的学习曲线
11、边密度屏障:组合推理中的计算-统计权衡
The Edge Density Barrier: Computational-Statistical Tradeoffs in Combinatorial Inference
统计推理的一大最主要目标是确定变量之间的依赖结构,即推理底层图模型的结构。这篇论文关注的是一个更加具体的推理问题:检验底层图中是否有特定的组合结构。
尽管对这一问题的信息论极限的研究已有很多了,但能否通过有效的算法得到这样的极限很大程度仍未被研究过。此外,检验问题(尤其是图模型的组合结构)的构建方式对信息论极限的可达成性的影响方式也并不明朗。
为了理解这两个问题,研究者在这篇论文中描述了图模型中组合推理的这种基本极限;并基于一种 oracle 计算模型量化研究了达到这个信息论极限所需的最小计算复杂度。
研究证明,要在空图上检验团(clique)、最近邻图、完美匹配等常见组合结构,或在小团上检验大团,信息论极限是无法通过一般的可实现算法达到的。
更重要的是,研究者定义了名为弱边密度 µ 和强边密度 µ' 的结构量。根据定义,边集的弱边密度表征了可从一个无效(null)变到另一个图的关键边的密集程度。这能反应这两个图的差异水平。强边密度是另一个表征这两个图的差异水平的量,且总是不小于弱边密度。下面给出了 µ 和 µ' 的定义:
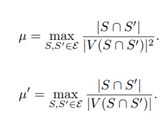
这两个结构量的一大突出性质是它们仅依赖于被测试的组合结构的拓扑性质。它们能帮助研究者理解组合推理问题的结构性质决定其计算复杂度的方式。研究表明,如果 µ 远小于 µ',则信息论下界和计算有效的下界之间会存在明显差距。下面给出了 4 个案例的具体最优比率;可以看到,这些案例都存在统计与计算的权衡。

本研究也是首个确定和解释无向图模型中组合推理问题的统计和计算之间的基本权衡的研究。
第三部分:机器学习优化方法与理论研究
12、异步去中心化并行随机梯度下降
Asynchronous Decentralized Parallel Stochastic Gradient Descent
论文地址:https://arxiv.org/abs/1710.06952
最常用的分布式机器学习系统要么是同步的,要么就是中心化异步的。AllReduce-SGD 这样的同步算法在异构环境中表现很差,而使用参数服务器的异步算法则存在很多问题,其中包括工作器(worker)很多时参数服务器的通信问题以及当参数服务器的流量拥堵时收敛性下降的问题。
研究者在这篇论文中提出了一种异步去中心化并行随机梯度下降(AD-PSGD),能在异构环境中表现稳健且通信效率高并能维持最佳的收敛速率。理论分析表明 AD-PSGD 能以和 SGD 一样的最优速度收敛,并且能随工作器的数量线性提速。下面是该算法的工作过程:

研究者使用 Torch 和 MPI 在多达 128 个 P100 GPU 的 IBM S822LC 集群上实现和评估了 AD-PSGD。实验结果表明,AD-PSGD 的表现优于最佳的去中心化并行 SGD(D-PSGD)、异构并行 SGD(A-PSGD)和标准的数据并行 SGD(AllReduce-SGD)。AD-PSGD 在异构环境中的表现往往能超出其它方法多个数量级。
下图给出了在 ImageNet 数据集上基于 ResNet-50 模型得到的训练损失和每 epoch 训练时间情况。可以看到,AD-PSGD 和 AllReduce-SGD 的收敛情况接近,都优于 D-PSGD。在使用 64 个工作器时,AD-PSGD 每 epoch 耗时 264 秒,而另外两种方法每 epoch 耗时会超过 1000 秒。

下图则展示了各种方法在 CIFAR10 上为 VGG(通信密集型)和 ResNet-20(计算密集型)模型带来的加速情况。可以明显看到 AD-PSGD 一直都有最优的表现。
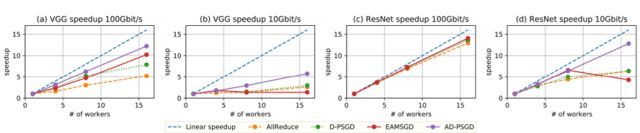
AD-PSGD 是首个在超过 100 个 GPU 的规模上达到接近 AllReduce-SGD 的 epoch 收敛速度的异步算法。
13、D2:在去中心化数据上的去中心化训练
D2: Decentralized Training over Decentralized Data
论文地址:https://arxiv.org/abs/1803.07068
以去中心化的方式训练机器学习模型近来得到了很大的研究关注。在使用多个工作器训练机器学习模型时(其中每一个都会从自己的数据源收集数据),从各个不同的工作器收集的数据也各不相同时这些数据是最有用的。但是,近期的很多去中心化并行随机梯度下降(D-PSGD)研究都假设托管在不同工作器上的数据并没有很大的差异——否则这些方法的收敛速度会非常慢。
研究者在这篇论文中提出了一种全新的去中心化并行随机梯度下降算法 D2,该算法是为各工作器之间数据差异很大的情况(可以说是“去中心化”数据)设计的。

D2 基于标准的 D-PSGD 算法,但添加了一个降低方差的组件。在这种 D2 算法中,每个工作器都会存储上一轮迭代的随机梯度和局部模型,并将它们与当前的随机梯度和局部模型线性地结合到一起。这能将收敛速度改善,其中 ζ2 是不同工作器上的数据差异,σ2 是每个工作器内的数据方差,n 是工作器的数量,T 是迭代次数。
研究者在图像分类任务上对 D2 进行了评估,其中每个工作器都仅能读取一个有限标签集的数据。实验结果表明 D2 的表现显著优于 D-PSGD。下面给出了在无数据混洗(unshuffled)情况下(不同工作器之间的数据差异最大)的不同分布式训练算法的收敛性比较。
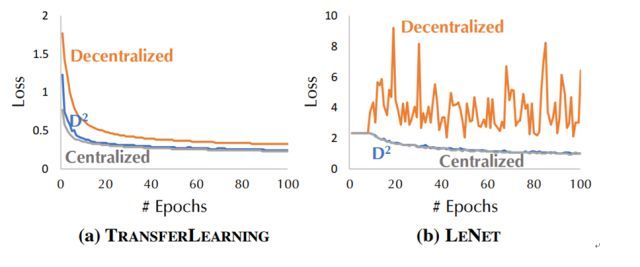
可以看到,D-PSGD 算法的收敛速度比中心化方法慢,而 D2 也比 D-PSGD 快很多,并且损失非常接近中心化算法。
14、实现更高效的随机去中心化学习:更快收敛和稀疏通信
Towards More Efficient Stochastic Decentralized Learning: Faster Convergence and Sparse Communication
论文地址:https://arxiv.org/abs/1805.09969
去中心化优化问题近来得到了越来越大的关注。大多数现有方法都是确定性的,具有很高的每次迭代成本,并且收敛速度与问题条件数呈二次关系。此外,为了确保收敛还必需密集的通信,即使数据集是稀疏的也是如此。
在这篇论文中,研究者将去中心化优化问题泛化成了一个单调算子根查找问题,并提出了一种名为去中心化随机反向聚合(DSBA)的算法。

在 DSBA 的计算步骤,每个节点都会计算一个随机近似的单调算子的预解式(resolvent),以降低对问题条件数的依赖程度。这样的预解式接受脊回归等问题中的闭式解。在 DSBA 的通信步骤,每个节点都接收连续迭代之间差异的非零分量,以重建其临近节点的迭代。因为 ℓ2-relaxed AUC 最大化问题等效于凸凹函数的极小极大问题,其微分是一个单调算子,因此能无缝地适配 DSBA 的形式。
该算法具有以下优势:(1)能以与问题条件数呈线性的速度以几何方式收敛,(2)可以仅使用稀疏通信实现。此外,DSBA 还能处理 AUC 最大化等无法在去中心化设置中高效解决的学习问题。研究者在论文中也给出了对该算法的收敛性分析。
研究者在凸最小化和 AUC 最大化上进行了实验,结果表明新提出的方法是有效的。下图给出了 DSBA 与几种之前最佳方法在 logistic 回归上的结果比较
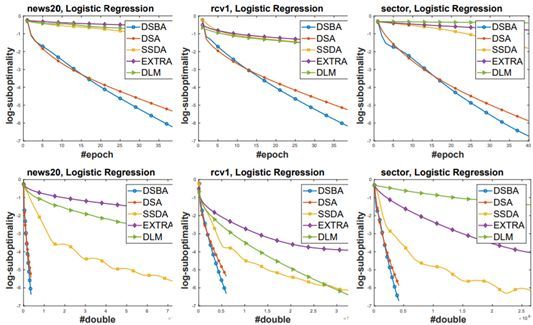
可以看到,DSBA 的表现是最优的,而且能以更低的计算成本更快地收敛。
15、误差补偿式量化 SGD 及其在大规模分布式优化中的应用
Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization
论文地址:https://arxiv.org/abs/1806.08054
这一轮机器学习热潮的出现很大程度上得益于计算机处理能力的指数级发展以及出现了可用于训练模型的海量数据。为了有效地完成海量数据的训练,往往需要用到分布式优化方法,其中包括数据并行化的处理方法。但在这样的分布式框架中,各个节点之间的通信速度往往会成为整体性能的关键制约因素。目前的常见解决方法是对节点之间的通信信息进行压缩,但这会引入量化误差。
为了解决这一问题,这篇论文提出通过使用累积的所有之前的量化误差的误差反馈方案来补偿当前的局部梯度。研究者将该方法称为“误差补偿式量化随机梯度下降(ECQ-SGD)”。实验结果表明这种方法能实现比很多基准方法更快更稳定的收敛。下面是该算法的工作过程:

在量化完成之后,总体通信成本会降至 32+dr 比特(r ≪ 32),远少于原来的 32 位全精度梯度所需的 32d 比特;其中 d 是原向量的维度;其中 s 是非零量化级别的数量:s 越大,则量化越细粒度,通信成本也就越高。下图给出了在 ILSVRC-12 数据集上训练 ResNet-50 模型时,使用不同数量的 GPU 的吞吐量情况比较:
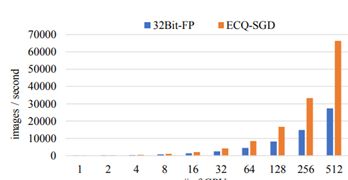
在使用 512 个 GPU 进行训练时,ECQ-SGD 相对于普通 SGD 实现了 143.5% 的加速(每秒各 66.42k 与 27.28k 张图像)。如果节点之间的带宽更小,这样的优势还会更加显著。
研究者还在该论文中提供了该方法的理论保证:分析了其收敛行为并证明了其相对于其它之前最佳方法的优势。
16、使用联网智能体的完全去中心化多智能体强化学习
Fully Decentralized Multi-Agent Reinforcement Learning with Networked Agents
论文地址:https://arxiv.org/abs/1802.08757
在多智能体强化学习(MARL)问题中,多个智能体的联合行动会影响它们所处的共同环境。在每个状态,每个智能体都会执行一个动作,这些动作共同决定了环境的下一个状态和每个智能体的奖励。此外,这些智能体可能针对的是不同的任务,会有不同的奖励函数;但每个智能体都只能观察自己的奖励。每个智能体都会基于局部观察到的信息以及从网络中的临近智能体接受到的信息各自做出决策。在这种设置内,所有智能体的整体目标是通过与其临近智能体交换信息而最大化在整个网络上的全局平均回报。
针对这一问题的中心化方法存在可扩展性和稳健性等方面的问题,因此,研究者在这篇论文中基于一种用于 MARL 的全新策略梯度定理提出了两种去中心化 actor-critic 算法;结合函数近似,可应用于状态和智能体数量都非常大的大规模 MARL 问题。
基于动作-价值函数的联网式 actor-critic 算法

基于状态-价值 TD 误差的联网式 actor-critic 算法
具体来说,actor 步骤是由每个智能体单独执行的,无需推断其它智能体的策略。对于 critic 步骤,研究者提出了一种在整个网络通过通信实现的共识更新(consensus update),即每个智能体都会与其网络中的临近智能体共享其价值函数的估计,从而得到一个共识估计。这个估计又会被用在后续的 actor 步骤中。通过这种方式,每个智能体的局部信息都能散布到整个网络,从而最大化整个网络层面的奖励。
这种算法是完全渐进式的,可以以一种在线形式实现。研究者还提供了当价值函数位于线性函数类别内近似求取时的算法收敛性分析。
研究者使用线性和非线性函数近似执行了大量模拟实验,对所提出的算法进行了验证。下图给出了当使用神经网络进行函数近似时,在协同导航任务上的全局平均奖励。其中 Central-1 和 Central-2 分别是算法 1 和算法 2 对应的中心化方法。
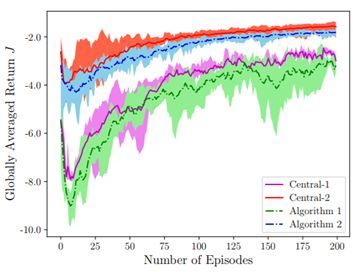
研究者表示该研究是首个使用函数近似的联网智能体的完全去中心化 MARL 算法研究。
