Python3.X 爬虫实战(动态页面爬取解析)
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
1 背景
不知不觉关于 Python 3.X 爬虫系列已经介绍了如下系列:
《正则表达式基础》
《Python3.X 爬虫实战(先爬起来嗨)》
《Python3.X 爬虫实战(静态下载器与解析器)》
《Python3.X 爬虫实战(并发爬取)》
《Python3.X 爬虫实战(缓存与持久化)》
到此关于 Python3.x 静态页面爬虫的基础核心基本已经介绍的差不多了,剩下的就是一些自己个性化的需求了,譬如爬取数据分析等,这种我们后面还会专门来说的。然而我们在该系列的《Python3.X 爬虫实战(静态下载器与解析器)》一文时给自己留了一个锅,这篇我们的重点就是来背这个锅———动态页面爬取解析。之所以叫动态页面爬取解析其实是相对于静态下载器与解析器来说的,因为有时候我们使用静态下载器与解析器对一些要爬取的页面进行解析时竟然没有任何数据,其实大多原因都是我们要爬取的元素是 JS 动态生成的,譬如我们爬取今日头条页面,你会发现今日头条随着我们手指上滑其页面会无限制的上拉加载更多,也就是常说的瀑布流,这时候我们就会觉得该系列前面介绍的爬取方式似乎完全无能为力了,所以我们需要寻求新的爬取解析方式,也就是动态页面爬取解析,其流行的核心主流思路是动态页面逆向分析爬取和模拟浏览器行为爬取,本篇会详细探讨说明。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】

2 Python3.X 动态页面逆向分析爬取
以这种方式进行动态页面的爬取实质就是对页面进行逆向分析,其核心就是跟踪页面的交互行为 JS 触发调度,分析出有价值、有意义的核心调用(一般都是通过 JS 发起一个 HTTP 请求),然后我们使用 Python 直接访问逆向到的链接获取价值数据。下面我们以一个实战从头到尾来演示一遍如何逆向分析爬取动态网页今日头条的数据,目标是爬取今日头条搜索出来 list(譬如搜索美女、风景)中每个头条文章点进去详情页的所有大图,然后把他们分类下载下来,首先我们看下今日头条搜索界面如下:
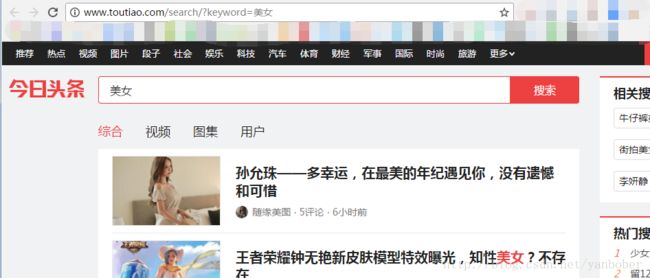
我们爬虫要干的事就是仿照上面在搜索框输入“美女”,然后点击搜索得到结果,然后对于结果页面挨个点进去详情页面,然后把详情页面里的大图都爬取下载下来。这时候如果你上来就按照我们前面系列介绍的静态分析你会发现我们点击完搜索以后上面页面的源码中这个列表只有有限的几十项,如下:
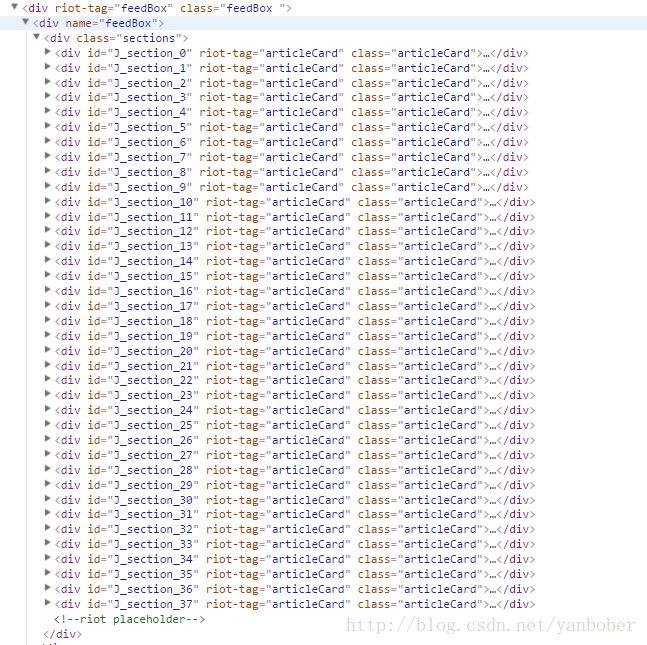
然而我们期望的搜索结果可不是这点啊,所以我们尝试上滑网页会发现怎么页面的链接没变,但是每次上拉到底部就会自动加载更多 item 出来,纳尼,静态爬取遇到这种情况只能懵逼啊,所以我们接下来需要做的就是来逆向分析下我们要爬取的整个过程,使用 FireBug 等来跟踪一下,我们上滑页面时会发现每次要滑到底部页面自动加载时 FireBug 会有如下反馈:

看到这幅图我们简单分析会发现当上拉加载更多时每次都会触发 JS 访问一个接口去请求一个 JSON 数据回来,然后再通过 JS 动态插到了上面第二幅图源码的 可以看到参数 offset 一猜就是偏移量(不信自己可以修改使用 PostMan 看下返回数据),format 为数据返回 JSON 格式,keyword 就是我们输入的关键词,autoload 没整明白,但是无伤大雅,照着传即可, count 就是每次请求返回多少个 item,cur_tab 就是搜索页面下面的分类,1 代表综合;到此我们这个动态页面的逆向第一步(页面动态数据来源)已经分析出来了,接下来我们仔细观察上面那个链接的返回值会发现 JSON 体中会有一个 data 字段的 Object 列表,这个列表其实就是我们每次上拉加载更多网页刷新数据的来源,我们会发现上拉加载更多显示出来的 item 如下: [该实例对应源码 spider_opt_analysis.py 点我获取] 可以看到下面就是我们通过对动态网页今日头条进行逆向分析后爬取的结果(体验可以获取源码直接运行): 到此关于动态网页逆向分析爬取的技巧就介绍完了,除过上面这个实例以外其实我们在前面已经用过一点动态网页逆向分析了,具体留作彩蛋可以自己琢磨下我们前面系列文章的 CsdnDiscussSpider 实例中 JS 提交那段逻辑。总归我们可以发现,某种意义上来看通过逆向爬取动态网页虽然比静态页面稍显麻烦,但是其稳定性似乎要比静态网页稳定,因为大多可直接逆向的动态网页数据都是采用标准 RESTFUL API 设计的,爬取解析 API 接口数据一般比匹配解析网页源码要可靠的多;但是有时候我们无法避免使用动静结合的方式,譬如上面爬取今日头条的例子其实还可以做到先动态逆向只获取文章详情页面链接,然后再使用我们前面静态页面爬取解析的技巧去访问文章详情页面获取里面大图,因为获取 item 列表是动态页面,而点击 item 进入的文章页面是静态页面。 【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】 上面我们介绍了动态页面爬取解析的逆向分析爬取方式,我们会惊讶的发现对于单一化动态网站(譬如今日头条,仅仅就是资讯流和详情页面)的逆向相对来说还是比较容易的,其逆向出来的 API 参数很好理解,只有个别看起来无关紧要的参数我们无法猜出含义,但是没有影响我们的爬虫工作。然后现实总是错综复杂的,如果我们要爬取的是一些使用航母级别技术的动态网站怎么办呢,这些网站一般都非常复杂,我们如果还想使用类似 Firebug 等工具对其逆向可能时间和人力成本有点过于昂贵 ;所以对于这类网站采用上面的逆向分析手段可能不是那么适合了,所以就出现了动态页面爬取的另一种方式———模拟浏览器渲染爬取。 这种方式已经烂大街了,但是这也许是一种折中方案,因为该方式最大的问题就是非常慢,因为它是加载完网页所有资源并渲染好页面后才可以操作,Selenium 本身的定位是用来进行自动化测试的。Selenium 可以按指定的命令自动操作,而 PhantomJS 是基于 Webkit 的无界面浏览器,它能在不可见的内存中完成浏览器的常见功能,所以我们可以利用 Selenium 和 PhantomJS 来实现一个强大到可以处理 JS、Cookie、Header 和任何我们真实情况需要做的事。要用好这种方式我们必须要时刻记得查阅 Selenium 文档 和 PhantomJS 文档,关于环境配置等里面都有介绍,这里不再 BB。下面我们就来写一个实战爬虫方便我们爬取自己 QQ 空间所有相册的所有图片,然后把图片都下载下来,因为 QQ 空间我们已经不常用了,但是舍不得里面各种相册的各种照片,又不可能一张一张去手动点击下载,所以我们就有了下面基于 Selenium 和 PhantomJS 的爬虫(呜呜,看起来更像是在给 QQ 空间 WEB 写自动化测试),如下(如果跑起来有诡异 bug,建议增加相关强制等待或者隐式等待时长即可): 替换 QQ 帐号密码后运行上面脚本我们等待后会得到如下结果: 可以发现,我们所有相册的图片都自动被爬取下来按照 QQ 空间相册名字分类存储在了本地磁盘,完全解放了双手,但是明显能感觉到的就是这种方式的爬虫是比较慢的,因为需要等待元素渲染,但是在有些时候这是不得不选择的一种折中方案,譬如 QQ 空间这个动态页面,想要逆向分析难度有点大,所以选择这种方案。 模拟浏览器行为爬取除过上面介绍的 Selenium 结合 PhantomJS 方式外其实还有其他的框架,不过其原理归根结底基本都类似,譬如 通过介绍上面几种动态页面的爬取方式我们很容易会得出一个结论,能用逆向分析就尽量逆向,其稳定性和效率别的方案是没法比拟的。通常对于爬虫有句口口相传的真理,会点击使用浏览器 F12 大法就能解决百分之九十的爬虫问题,其他百分之十就需要我们动动脑子了。对于动态页面爬取更是这个道理了,能逆向就尽量逆向,逆向不了就寻找折中方案,折中方案里能使用深度控制 JS 脚本执行方案就尽量(难度略大),其次就是标准的基于浏览器自动化测试框架爬取。 【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】 前面静态页面爬取系列文章有人对于模拟登录提交有疑惑,这里要说明的是那里的例子虽然是在说静态页面,实质登录提交 FORM 表单算是动态页面的事情了,所以我们这里对于爬虫过程中的 FORM 表单问题再罗嗦几句。 关于 WEB FORM 如果还不了解其实真的该补补基础了,对于爬虫 FORM 表单的提交其实还是使用 F12 大法分析网页,譬如我们看下 GitHub 的登录 FORM,如下: 想必懂点 WEB 开发的小伙伴都知道编写 WEB 页面 FORM 表单常见的套路就是除过可见的 FORM 元素外很多时候还会采用 hide 的 FORM 元素一同作为 FORM 提交,保证提交接口非交互参数的传递。所以我们可以看到 Github 登录页面的 FORM 里面除过存在可见的 input 元素以外还存在 hide 的 input 元素,input 元素的 name 属性就是提交时的 key 值,FORM 标签的 accept-charset 属性表示编码格式、action 属性表示表单数据的提交 所以对应的我们爬虫 POST 提交数据为: 这样就可以登录了,不过还有一点要注意,既然登录就是一种状态,所以我们在发起爬虫登录时不要忘记开启 Cookie,这个很重要,原理就不解释了,这样就可以下次自动登录,关于使用 Python 直接获取浏览器 Cookie 来实现自动登录其实也不用过多强调了,获取浏览器 Cookie 的方式也有很多种,甚至可以选择使用 Python 的 browsercookie 模块来获取 Cookie。 上面演示了自己编写代码开启 Cookie 及分析 FORM 表单提交和构造 dict 对象编码提交表单的过程,在实际小爬虫中关于 Cookie 我们可以自己封装一个类来处理,这样会方便许多,不过 Python 还提供了一个更加便捷的 Mechanize 模块来处理表单提交,非常遗憾的是这个模块不支持 Python3.X 版本,所以对于我们这个系列就没必要介绍了,感兴趣的可以自己使用低版本的 Python 玩玩。 算是一个答疑,就此打住,打球去了! 【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】 ^-^当然咯,看到这如果发现对您有帮助的话不妨扫描二维码赏点买羽毛球的小钱(现在球也挺贵的),既是一种鼓励也是一种分享,谢谢! http://www.toutiao.com/search_content/?offset=20&format=json&keyword=美女&autoload=true&count=20&cur_tab=1

这个 item 的数据就是 JSON 里 data 列表的一项,其左侧缩略图取值字段为 image_url,标题取值字段为 title,左侧来源取值字段为 source,其他类似,当我们点击这个 item 进入正文时会发现跳转正文的链接也在这个 JSON 里,用的是 article_url 字段,当我们进入文章详情去看里面的所有大图链接会惊讶的发现原来都提前预加载数据了,这些大图链接也来自刚才那个 JSON 里,对应的字段是 image_detail 里的 url 值,棒极了,我们完全逆向成功了,而且可以预测出这个爬虫应该会相对稳定,因为通过我们对这个动态页面的逆向会发现我们接下来的爬虫完全不需要面对网页 DOM 解析,而完全是标准的 RESTFUL API 调用,很赞,我们通过这个逆向就可以写出爬虫程序了,下面给出完整程序。# coding=utf-8
import json
import os
import re
import urllib
from urllib import request
'''
Python3.X 动态页面爬取(逆向解析)实例
爬取今日头条关键词搜索结果的所有详细页面大图片并按照关键词及文章标题分类存储图片
'''
class CrawlOptAnalysis(object):
def __init__(self, search_word="美女"):
self.search_word = search_word
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.100 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'www.toutiao.com',
'Referer': 'http://www.toutiao.com/search/?keyword={0}'.format(urllib.parse.quote(self.search_word)),
'Accept': 'application/json, text/javascript',
}
def _crawl_data(self, offset):
'''
模拟依据传入 offset 进行分段式上拉加载更多 item 数据爬取
'''
url = 'http://www.toutiao.com/search_content/?offset={0}&format=json&keyword={1}&autoload=true&count=20&cur_tab=1'.format(offset, urllib.parse.quote(self.search_word))
print(url)
try:
with request.urlopen(url, timeout=10) as response:
content = response.read()
except Exception as e:
content = None
print('crawl data exception.'+str(e))
return content
def _parse_data(self, content):
'''
解析每次上拉加载更多爬取的 item 数据及每个 item 点进去详情页所有大图下载链接
[
{'article_title':XXX, 'article_image_detail':['url1', 'url2', 'url3']},
{'article_title':XXX, 'article_image_detail':['url1', 'url2', 'url3']}
]
'''
if content is None:
return None
try:
data_list = json.loads(content)['data']
print(data_list)
result_list = list()
for item in data_list:
result_dict = {'article_title': item['title']}
url_list = list()
for url in item['image_detail']:
url_list.append(url['url'])
result_dict['article_image_detail'] = url_list
result_list.append(result_dict)
except Exception as e:
print('parse data exception.'+str(e))
return result_list
def _save_picture(self, page_title, url):
'''
把爬取的所有大图下载下来
下载目录为./output/search_word/page_title/image_file
'''
if url is None or page_title is None:
print('save picture params is None!')
return
reg_str = r"[\/\\\:\*\?\"\<\>\|]" #For Windows File filter: '/\:*?"<>|'
page_title = re.sub(reg_str, "", page_title)
save_dir = './output/{0}/{1}/'.format(self.search_word, page_title)
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
save_file = save_dir + url.split("/")[-1] + '.png'
if os.path.exists(save_file):
return
try:
with request.urlopen(url, timeout=30) as response, open(save_file, 'wb') as f_save:
f_save.write(response.read())
print('Image is saved! search_word={0}, page_title={1}, save_file={2}'.format(self.search_word, page_title, save_file))
except Exception as e:
print('save picture exception.'+str(e))
def go(self):
offset = 0
while True:
page_list = self._parse_data(self._crawl_data(offset))
if page_list is None or len(page_list) <= 0:
break
try:
for page in page_list:
article_title = page['article_title']
for img in page['article_image_detail']:
self._save_picture(article_title, img)
except Exception as e:
print('go exception.'+str(e))
finally:
offset += 20
if __name__ == '__main__':
#模拟今日头条搜索关键词爬取正文大图
CrawlOptAnalysis("美女").go()
CrawlOptAnalysis("旅游").go()
CrawlOptAnalysis("风景").go()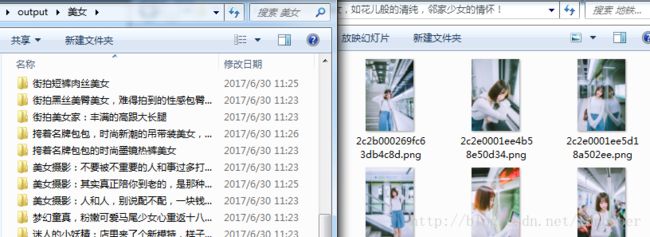
3 Python3.X 模拟浏览器行为爬取
3-1 Selenium 与 PhantomJS 方式
[该实例对应源码 spider_selenium_phantomjs.py 点我获取]import os
import time
from urllib import request
from PIL import Image
from selenium import webdriver
'''
爬取自己 QQ 空间所有照片
不怎么用 QQ 空间, 但是舍不得空间的照片,一张一张下载太慢,所以按照相册趴下来硬盘留念
'''
class SpiderSelenium(object):
def __init__(self, qq='', pwd=None):
self.driver = webdriver.PhantomJS() #Run in Ubuntu, Windows need set executable_path.
self.driver.maximize_window()
self.qq = qq
self.pwd = pwd
print('webdriver start init success!')
def __del__(self):
try:
self.driver.close()
self.driver.quit()
print('webdriver close and quit success!')
except:
pass
def _need_login(self):
'''
通过判断页面是否存在 id 为 login_div 的元素来决定是否需要登录
:return: 未登录返回 True,反之
'''
try:
self.driver.find_element_by_id('login_div')
return True
except:
return False
def _login(self):
'''
登录 QQ 空间,先点击切换到 QQ 帐号密码登录方式,然后模拟输入 QQ 帐号密码登录,
接着通过判断页面是否存在 id 为 QM_OwnerInfo_ModifyIcon 的元素来验证是否登录成功
:return: 登录成功返回 True,反之
'''
self.driver.switch_to.frame('login_frame')
self.driver.find_element_by_id('switcher_plogin').click()
self.driver.find_element_by_id('u').clear()
self.driver.find_element_by_id('u').send_keys(self.qq)
self.driver.find_element_by_id('p').clear()
self.driver.find_element_by_id('p').send_keys(self.pwd)
self.driver.find_element_by_id('login_button').click()
try:
self.driver.find_element_by_id('QM_OwnerInfo_ModifyIcon')
return True
except:
return False
def _auto_scroll_to_bottom(self):
'''
将当前页面滑动到最底端
'''
js = "var q=document.body.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(6)
def _get_gallery_list(self, picture_callback):
'''
从相册列表点击一个相册进入以后依次点击该相册里每幅图片然后回调,依此重复各个相册
所有注释掉的 self.driver.get_screenshot_as_file 与 self.driver.page_source 仅仅为了方便调试观察
:param picture_callback: 回调函数,当点击一个相册的一幅大图时回调
'''
time.sleep(5)
self._auto_scroll_to_bottom()
#self.driver.get_screenshot_as_file('my_qzone_gallery_screen.png')
self.driver.switch_to.frame('app_canvas_frame')
elements = self.driver.find_elements_by_xpath("//a[@class='c-tx2 js-album-desc-a']")
gallery_count = len(elements)
index = 0
while index < gallery_count:
print('WHILE index='+str(index)+', gallery_count='+str(gallery_count))
self._auto_scroll_to_bottom()
elements = self.driver.find_elements_by_xpath("//a[@class='c-tx2 js-album-desc-a']")
if index >= len(elements):
print('WHILE index='+str(index)+', elements='+str(len(elements)))
break
print('size='+str(len(elements)))
#self.driver.get_screenshot_as_file('pppp' + str(hash(elements[index])) + '.png')
gallery_title = elements[index].text
elements[index].click()
time.sleep(5)
self._auto_scroll_to_bottom()
#self.driver.get_screenshot_as_file('a_gallery_details_list' + str(hash(elements[index])) + '.png')
pic_elements = self.driver.find_elements_by_xpath("//*[@class='item-cover j-pl-photoitem-imgctn']")
for pic in pic_elements:
pic.click()
time.sleep(5)
#self.driver.get_screenshot_as_file('details_' + str(hash(elements[index])) + '_' + str(hash(pic)) + '.png')
self.driver.switch_to.default_content()
pic_url = self.driver.find_element_by_id('js-img-border').find_element_by_tag_name('img').get_attribute('src')
print(gallery_title + ' ---> ' + pic_url)
if not picture_callback is None:
picture_callback(gallery_title, pic_url)
self.driver.find_element_by_class_name('photo_layer_close').click()
self.driver.switch_to.frame('app_canvas_frame')
self.driver.back()
time.sleep(10)
index += 1
def crawl_pictures(self):
'''
开始爬取 QQ 空间相册里图片
'''
self.driver.get('http://user.qzone.qq.com/{0}/photo'.format(self.qq))
self.driver.implicitly_wait(20)
if self._need_login():
if self._login():
self._get_gallery_list(self._download_save_pic)
print("========== QQ " + str(self.qq) + " 的相册爬取下载结束 ===========")
else:
print('login with '+str(self.qq)+' failed, please check your account and password!')
else:
print('already login with '+str(self.qq))
def _download_save_pic(self, gallery_title, pic_url):
'''
下载指定 url 链接的图片到指定的目录下,图片文件后缀自动识别
:param gallery_title: QQ 空间相册名
:param pic_url: 该相册下一张详情图片的 url
'''
if gallery_title is None or pic_url is None:
print('save picture params is None!')
return
save_dir = './output/{0}/'.format(gallery_title)
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
save_file = save_dir + str(hash(gallery_title)) + '_' + str(hash(pic_url))
if os.path.exists(save_file):
return
try:
with request.urlopen(pic_url, timeout=30) as response, open(save_file, 'wb') as f_save:
f_save.write(response.read())
new_stuffer_file = save_file + '.' + Image.open(save_file).format.lower()
os.rename(save_file, new_stuffer_file)
print('Image is saved! gallery_title={0}, save_file={1}'.format(gallery_title, new_stuffer_file))
except Exception as e:
print('save picture exception.'+str(e))
if __name__ == '__main__':
SpiderSelenium('请用你的QQ号替换', '请用你的QQ密码替换').crawl_pictures()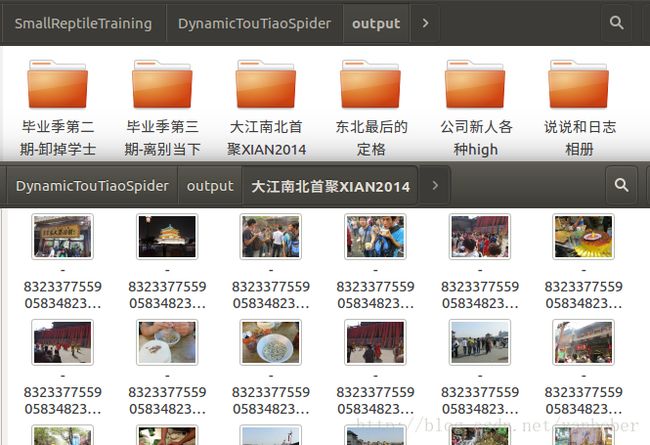
3-2 其他方式
Splash、PyV8、Ghost、execjs 等,其 API 用法和上面 Selenium 大同小异,只是写法有差异而已,这里不再一一给出详细例子,感兴趣可以自己去搜搜相关官方文档照着爬爬,没啥特别的。3-3 对比总结
4 动态页面爬取其他事项
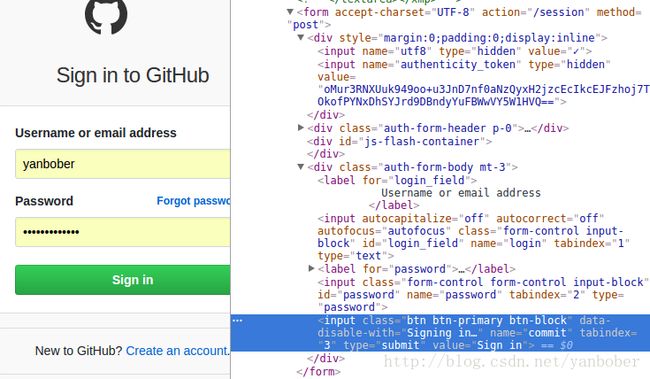
地址( # 表示当前 URL,其他值就是当前 URL + 值)、method 属 性表示 HTTP 的请求方式(这里为 POST),所以我们可以发现抓取的登录提交信息和我们上面分析的一致,如下: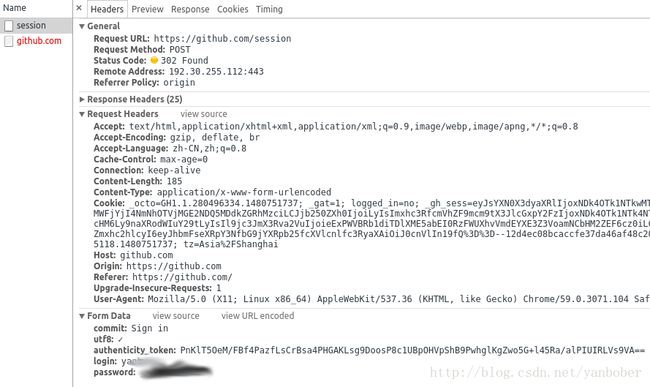
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': 'PnKlT5OeM/FBf4PazfLsCrBsa4PHGAKLsg9DoosP8c1UBpOHVpShB9PwhglKgZwo5G+l45Ra/alPIUIRLVs9VA==',
'login': '[account]',
'password': '[password]'
}
#编码很重要
data = urllib.urlencode(data)

【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】