Solr快速入门第四讲——Solr managed-schema配置文件详解
前言
本讲原意是想向大家介绍Solr中schema.xml配置文件的,但是在Solr 5.5以上版本中没有schema.xml这个配置文件了,而是出现了一个叫managed-schema的配置文件。所以,本讲将向大家介绍managed-schema这个配置文件,主要包括managed-schema配置文件中的使用实例、应用技巧、基本知识点总结以及需要注意的事项,还是具有一定的参考价值的,需要的朋友可以参考一下。
schema介绍
schema翻译过来即模式,它是集合/内核中字段的定义,主要是让Solr知道集合/内核包含哪些字段、字段的数据类型以及该字段是否存储索引。
schema文件是在SolrConfig中的架构工厂定义,有两种定义模式,也就是说Solr中提供了两种方式来配置schema,但两者只能选其一。接下来,我将会详细介绍这两种定义模式。
两种定义模式
默认的托管模式
Solr默认使用的就是托管模式。也就是说当在solrconfig.xml配置文件中没有显式声明
<schemaFactory class="ManagedIndexSchemaFactory">
<bool name="mutable">truebool>
<str name="managedSchemaResourceName">managed-schemastr>
schemaFactory>
当然,也可以显式的声明schema文件,但是,当显式的声明schema文件的时候,文件的名字不能是managed-schema也不能是schema.xml。同时schema文件的名字要与solrconfig.xml配置文件中声明的schema文件名一样。
经典的schema.xml模式
这种模式的配置方式是在solrconfig.xml配置文件中显式配置一个ClassicIndexSchemaFactory。
<schemaFactory class="ClassicIndexSchemaFactory"/>
ClassicIndexSchemaFactory需要使用schema.xml配置文件,并且不允许在运行时对架构进行任何编程式更改。而且该schema.xml文件必须手动编辑,编辑完后需要重载集合/内核才会生效。
两种模式的区别
- 区别一:两种模式下,schema文件的格式形式不同,默认的托管模式下的schema文件名字必须是managed-schema;而经典的schema.xml模式下的schema文件名字必须是schema.xml。
- 区别二:两种模式下,solrconfig.xml配置文件中的
两种模式之间的相互切换
这两种模式之间是可以切换的,比如用于升级操作,从旧版本到新版本的升级。接下来,我会详细讲解切换方式。
从经典的schema.xml模式切换到默认的托管模式
只需要将solrconfig.xml配置文件中显示配置的
当Solr服务器启动的时候,会检测是否存在managed-schema文件,如果存在,那么这个managed-schema文件就是将要被读取的文件;如果managed-schema文件不存在,那么Solr服务器就会将schema.xml文件中的内容读取并将内容写入新建的managed-schema文件,然后将schema.xml文件重命名为schema.xml.bak。
从默认的托管模式切换到经典的schema.xml模式
从默认的托管模式切换到经典的schema.xml模式,只须三步即可实现。
- 第一步:将managed-schema文件重命名为schema.xml;
- 第二步:在solrconfig.xml配置文件中显示的配置
- 第三步:重新启动Solr服务器。
managed-schema配置文件详解
在Solr家里面的核内的conf目录下有两个配置文件是我们要掌握的,一个是solrconfig.xml核心配置文件,另外一个就是managed-schema配置文件。
你不仅想问,managed-schema配置文件中配置的到底是些什么东西呢?该配置文件在Solr Core的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型,主要包括很多field字段、唯一ID、fieldType字段类型和其他的一些缺省设置。我们先了解下managed-schema配置文件的大致结构。
<schema version="1.6">
<field .../>
<dynamicField .../>
<uniqueKey>iduniqueKey>
<copyField .../>
<fieldType ...>
<analyzer type="index">
<tokenizer .../>
<filter ... />
analyzer>
<analyzer type="query">
<tokenizer .../>
<filter ... />
analyzer>
fieldType>
schema>
field(字段)
字段定义
其实,在managed-schema配置文件中配置了大量的域。如果你不信的话,可以打开managed-schema配置文件看看,很快你将会看到它里面配置了大量的域。

这里我将会选取几个域进行详细介绍。先来看看如下配置是个什么意思?
<field name="_version_" type="plong" indexed="false" stored="false"/>
以上配置的意思就是说配置了一个域,名字叫_version_,类型是plong类型(注意:这里的plong是别名)。以plong为关键字继续在managed-schema配置文件中查找,你就能很快找到它的位置了。

这就说明了名字为_version_的这个域,是LongPoint类型的(之前在学习Lucene时介绍过)。从该域的配置中还可以看到indexed和stored属性明确地设置为了false,这表明该域既不索引也不存储。
想一想,之前我们在学习Lucene时,创建索引的时候,要想构建一个Long数值型的Field,是不是要像下面这样写代码?
// 1. 数值类型可以使用XxxPoint添加到索引中
document.add(new LongPoint("fileSize", file_size)); // file_size表示文件大小
// 2. 如果该域还想要被存储,那么就需要再使用StoreField来构建它
document.add(new StoredField("fileSize", file_size));
// 3. 添加排序支持
document.add(new NumericDocValuesField("fileSize", file_size));
现在就不必这么麻烦了,Solr中的managed-schema配置文件已经帮我们配置好了,使用的时候,就直接用_version_这个名字,然后填写好对应的域值,就OK了。
再继续往下看,会看到有如下这样一个配置:
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
以上配置的是id域,可以发现该域中required属性的值为true(即必须),这又意味着什么呢?之前我们在学习Lucene时,id是不必须的,但是这实际上是因为当我们将文档对象扔进索引库的时候,会自动为每个文档创建索引,即每个文档都有一个唯一的编号,就是文档id。而使用Solr的时候,它就不再自己创建这个域了,因此就得我们自个儿指定了。咱自个儿指定,就要求咱必须给它来一个id,而且这个id是必须的。
如果你要是对于文档对象的id还不是理解很透彻,那么可以对比数据库来进行理解,它就相当于数据库表中的主键id。Lucene是自己生成,类似自增长;Solr是在managed-schema配置文件中进行配置,需要我们自己进行指定,类似于assigned。总而言之,以后在用Solr保存一个数据的时候,一定记得要给id。
接着再继续往下看,会看到有如下这样一个配置:
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>
可以看到以上配置的title域中multiValued属性的值为true,这意味着什么呢?如果某个域要存储多个值,那么multiValued属性的值设置为true即可。Solr允许一个域存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图)。就拿title域来说,我们可以向该域中存储多个值,就像下面这样。
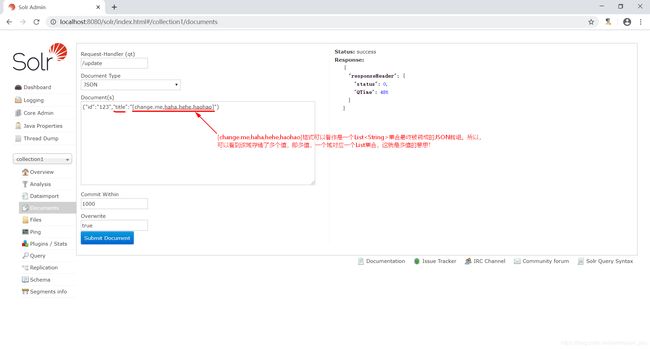
最后使用Solr查询,我们可以看出返回给客户端的是数组,类似于下图这样。
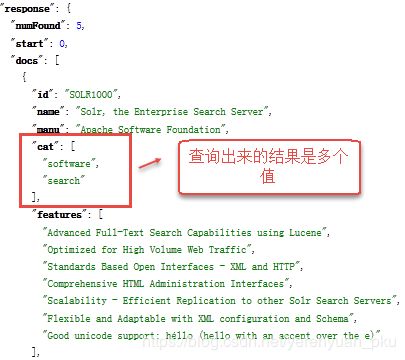
但在这里我查询出来的是下面这个鬼样,有点不符合预期,可能是创建索引的时候,向Solr服务器发送的JSON格式的数据写的有问题。
字段属性
字段定义可以具有以下属性:
- name:该字段的名称。字段名称只能由字母、数字或下划线字符组成,不能以数字开头。目前这并不是严格执行的,但其他字段名称将不具备所有组件的第一类支持,并且不保证向后的兼容性。以下划线开头和结尾的名字为保留字段名,如_version_。每个字段都必须要有一个name;
- type:字段的fieldType名,而且必须,该属性的值为fieldType标签中定义的name属性的值;
- default:默认值,非必须。如果提交的文档中没有该字段的值,则自动会为文档添加这个默认值。相当于传统数据库中的字段默认值。
除此之外,字段还有很多可选属性,如下列表所示。

其实,字段还有很多可选属性我没介绍到,主要是这些属性咱也不熟,一股脑地罗列出来,难免怕大家接受不了,所以这里就不介绍那么多了,真的要是遇到了,再去Google或者百度也不迟。不过,大家要注意以下四点:
- 上述属性是field字段本身就有的;
- field字段中有一个type属性,该属性会指向一个fieldType标签,该标签内部也会有上述描述的那些属性;
- 若field中某个属性在引用的fieldType中也存在,则以field中定义的属性为准;
- 一般来说,使用fieldType中定义的属性就已经够用了,如果字段比较特殊,可以在字段层面定义属性,用来覆盖掉fieldType中的属性。
dynamicField(动态字段)
为了防止以上的域依然不够用,所以这才有了dynamicField(动态字段)。你可能要问了,动态字段到底是什么呢?如果模式中有近百个字段需要定义,其中有很多字段的定义都是相同的,那么重复地定义就十分的麻烦,因此可以定一个规则,字段名以某前缀开头或结尾的是相同的定义配置,那这些重复字段就只需要配置一个,保证提交的字段名称遵守这个前缀或后缀即可,这就是动态字段。例如,整型字段都是一样的定义,则可以定义一个如下的动态字段。
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
温馨提示:动态字段只能用符号*通配符进行表示,且只有前缀和后缀两种方式。
其实说白了,动态字段就是不用指定具体的名称,只须定义字段名称的规则即可。例如,定义一个dynamicField,name为*_s,type为string,那么在使用这个字段的时候,任何以_s结尾的字段都被认为是符合这个定义的,比方说name_s、gender_s、school_i等。
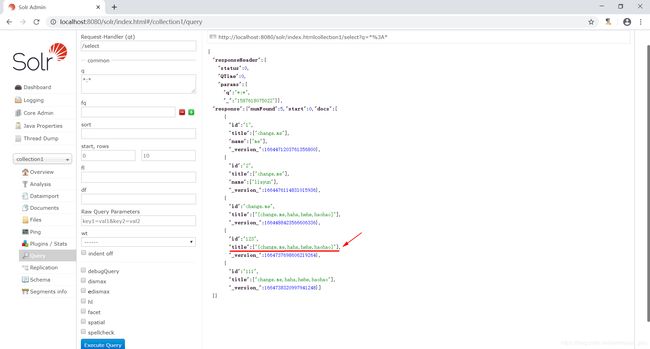
多说无益,咱还是用一个例子来说明一下。查看managed-schema配置文件,你会发现有如下一个dynamicField。

那么咱们在创建索引时,就可以像下图这样做了。
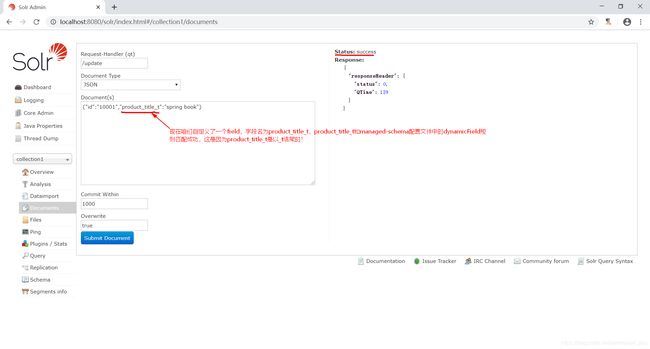
然后咱们再搜索一下索引,此时,就能看到返回给客户端的结果就是下图这样子的了。

你有没有思考过这样一个问题:提前设定好这些域的目的到底是什么?managed-schema配置文件中配置的域,就是我们要使用的域,意思就是说我们在使用Solr进行开发,在用任何一个域的时候,这个域一定得要在managed-schema配置文件中提前配置好。如果你曾经没配置过,而且又用了一个没配置过的域,那么这时就会报错,因为Solr服务器本身就不认识这个域。这就是为什么Solr要在managed-schema配置文件帮我们配置大量的域的原因。
虽然managed-schema配置文件中配置了很多域,但是你可以直接使用,也可以自己自行配置,即自定义域。例如,可以自定义一个如下域。
![]()
这样,咱们就可以像下图所示那样创建索引了。
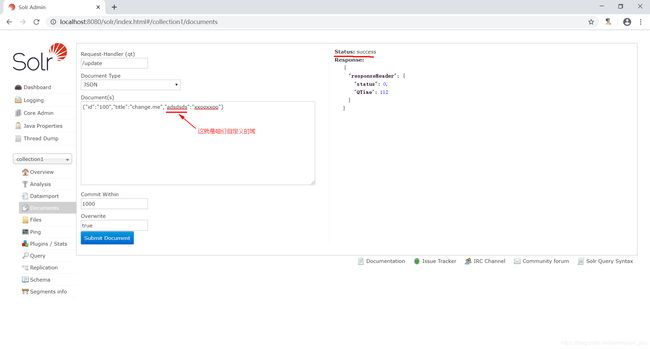
结论:没有配置过的域不能用,配置过的域就能用。
uniqueKey(唯一主键)
Solr中默认定义唯一主键key为id域,如下所示。
![]()
Solr在删除、更新索引时使用id域进行判断,当然了,我们也可以自定义唯一主键,例如指定商品ID为唯一主键(类似于传统数据库的主键ID)。
<uniqueKey>productId<uniqueKey>
这里,我还要提醒大家注意以下三点。
- 在创建索引时必须指定唯一约束;
- 这里的唯一主键是指业务主键,并不是Document的主键;
- 唯一主键字段不可以是保留字段、复制字段,且不能分词。
copyField(复制字段)
在managed-schema配置文件中,你会看到如下配置。
![]()
以上就是这一小节中我要介绍到的复制字段,这个字段是什么意思,又有什么作用呢?复制字段允许将一个或多个字段的值填充到一个字段中。它的用途通常来说有两种:
- 将多个字段内容填充到一个字段,来进行搜索;
- 对同一个字段内容进行不同的分词过滤,创建一个新的可搜索字段。
接下来,我会举一个例子来演示一下复制字段是如何定义的。比如,现在有一个需求,想要输入关键字搜索标题(title)和内容(content)。为了解决这样的需求,首先应定义如下几个名字为title、content以及text的域。

然后,将title域和content域中的内容复制到text域中,如下图所示。

这样就定义好了一个复制字段。现在根据关键字只搜索text域中的内容就相当于搜索title域和content域了。
回想一下,在之前咱们学习Lucene时,实现的查找文档的需求的案例代码。我们在搜索的时候,指定了在fileName域中去搜索"lucene",而如果要搜索内容,那么我们就要指定到内容的域中去搜索,意思就是说,域不同,搜索的时候我们就要在指定的域中进行搜索。但是,我们在实际开发过程中面对的需求,往往是不知道在哪个域中进行搜索或者不指定域进行搜索。这个时候,我们要想搜索文件名字和文件内容中都包含有"lucene"的文档,只能进行遍历,这样显然不好,性能也会大大降低,而这个复制域的出现就帮我们解决了这个问题,因为复制域的作用就是将多个域中的内容复制到一个域中去,在搜索的时候,只须搜索复制域就OK了。
总归一句话:复制域,就是说白了,当你搜索的时候,想搜两个域,但能不能把这两个域合并在一下,就搜一个域呢!
fieldType(字段类型)
在讲解fieldType时,我可能没有别人讲的那么详细,只是稍微会介绍下,毕竟功力不够,如果读者想要更加深入地去了解fieldType,可以去翻阅别人写的博客,这里,给大家先说声抱歉。
浏览managed-schema配置文件时,你或许会看到如下配置。

可以看到以上fieldType节点包含有name、class、positionIncrementGap等一些属性。下面我会详细解释下这几个属性。
- name:字段类型fieldType的名称(必填)。该值用于字段定义中的type属性中。强烈建议名称仅包含字母、数字或下划线字符,不能以数字开头;
- class:用于存储和索引此类型数据的实现类的类名(必填)。关于该属性的取值,你应注意如下两点:
- 可以用"solr"作为前缀包含的类名称。Solr会自动找出哪些软件包可以搜索这个类实现类负责确保字段被正确处理。在managed-schema配置文件中,字符串solr是org.apache.solr.schema或者org.apache.solr.analysis的简写形式。所以,solr.TextField实际上是org.apache.solr.schema.TextField;
- 如果你使用的是第三方类,那么可能需要具有完全限定的类名称。比如,solr.TextField的完全限定类名是org.apache.solr.schema.TextField。
- positionIncrementGap:对于多值字段,指定多个值之间的距离,这可以防止虚假词组匹配。此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
在定义fieldType的时候,最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。仔细看以上名为text_general的fieldType,你将会看到:
- 在索引分析器中,使用的是solr.StandardTokenizerFactory标准分词器、solr.StopFilterFactory停用词过滤器以及solr.LowerCaseFilterFactory小写过滤器;
- 在搜索分析器中,使用的是solr.StandardTokenizerFactory标准分词器、solr.StopFilterFactory停用词过滤器以及solr.LowerCaseFilterFactory小写过滤器,除此之外,这里还用到了solr.SynonymGraphFilterFactory同义词过滤器。
最后,我们在配置IK分词器的时候,将会按照这个模板来进行配置。下一讲就会讲到这个知识点,敬请期待哟!