使用ElasticSearch搭建日志系统
如果:
• 你有很多台机器
• 你有各种各样的Log
只要满足这两个条件其中之一,那么一套日志系统是很有必要的。优秀的日志系统可以让你及时发现问题,轻松追查故障原因,进而提高生产力。
本文简单介绍一下怎么用Elastic Search全家桶搭出一套日志系统。Elastic Search全家桶几乎可以说,就是设计出来干这个事的:
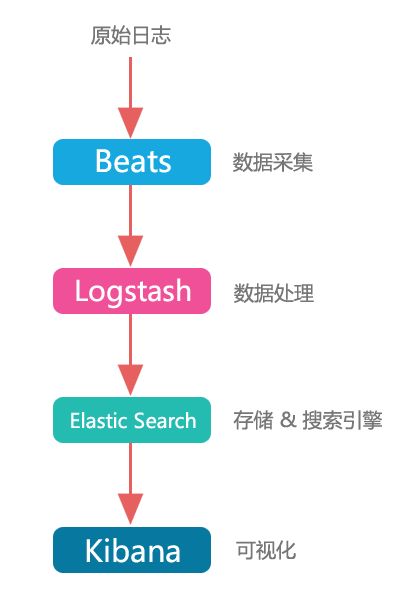
让我们来研究一下全家桶的每个成员:
• Beats
官方定义是"Data Shippers for Elasticsearch",还来个slogan叫"Collect, Parse & Ship",说得云里雾里的。其实说白了,就是数据采集。
Beats是一系列叫XXXbeat的小工具,最常用的是Filebeat。这套东西原先是Logstash的一个模块,后来单独拆了出来,又根据不同的功能衍生了几个分支。
Filebeat是个很轻量级的工具,主要干这么三件事:
• 监听本机指定日志文件的新增条目,类似`tail -f`
• 做最原始的过滤和处理
• 怼去Logstash,或者Elastic Search,又或者其他地方
go语言写的(好评)。安装出来,你会发现这套工具异常简单粗暴。一个可执行文件,一个配置文件,没了。
• Logstash
官方定义是"Process Any Data, From Any Source",这个很清晰很好,问题是slogan叫"Collect, Enrich & Transport Data"。大哥你的Collect关键词跟Beats兄弟重了啊!
Logstash是用来做数据处理的(也可以用来做数据采集,我相信这是历史原因导致的),功能非常强大。它敢吹"Process Any Data, From Any Source"是有道理的,因为官方文档上,目前(20160924)支持的数据源有:
"beats couchdb_changes drupal_dblog elasticsearch exec eventlog file ganglia gelf generator graphite github heartbeat heroku http http_poller irc imap jdbc jmx kafka log4j lumberjack meetup pipe puppet_facter relp rss rackspace rabbitmq redis salesforce snmptrap stdin sqlite s3 sqs stomp syslog tcp twitter unix udp varnishlog wmi websocket xmpp zenoss zeromq"
支持输出到:
"boundary circonus csv cloudwatch datadog datadog_metrics email elasticsearch elasticsearch_java exec file google_bigquery google_cloud_storage ganglia gelf graphtastic graphite hipchat http irc influxdb juggernaut jira kafka lumberjack librato loggly mongodb metriccatcher nagios null nagios_nsca opentsdb pagerduty pipe riemann redmine rackspace rabbitmq redis riak s3 sqs stomp statsd solr_http sns syslog stdout tcp udp webhdfs websocket xmpp zabbix zeromq"
至于数据处理本身,功能也是有够多的,我就不贴了。实在不满意,还可以自己撸袖写插件。
• Kibana
"See the Value in Your Data","Explore & Visualize Your Data"。有点被营销加工过的味道。
Kibana这玩意,我一开始是为了用ES的Marvel插件看集群运行状态而装的。第一感觉是,ES全家桶怎么一个绑一个,真麻烦。跑通后闲置了一段时间,之后偶然来玩了下Kibana本身的功能,就发现...挺厉害啊。
Kibana出报表的整个流程分为3步:
• 第一步:写query,在Elastic Search里搜出一批数据
• 第二步:使用搜出来的数据,创建图表
• 第三步:拼接多个图表,做成一个报表
建什么报表,就是看使用者的想象力了。我一开始是做了搜索相关的报表,像是最近一小时热搜关键词,最近一小时缓存命中率什么的。后来发现,Kibana的潜力真是无穷无尽。
Kibana加上Elastic Search,可以做实时数据分析。而且因为Elastic Search本质是个高性能搜索引擎,所以出数据很快。
现在让我们把这几个成员组装到一起。
可以看到,Beats + Logstash + Elastic Search + Kibana,可以做一套非常强大的日志系统。
官方给的图:
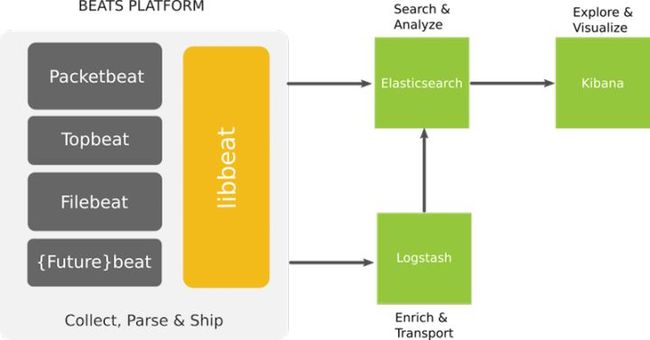
一套日志系统,高可用,可横向扩展,高自定义,出来的图表还好看,你说吼不吼啊!
具体怎么组装ES全家桶的,还是推荐各位上官网看文档,或者搜其他教程,或者直接把全家桶download下来把玩。毕竟日志系统里面最核心的ES索引设计,是跟着具体业务走的。本文提供一些经验:
• 不一定全家桶都要用
在数据量不大、或者做抽样的时候,完全可以不用Beats和Logstash,数据直接用HTTP RESTful接口怼Elastic Search。如果是一些监控类的脚本,可以直接在shell里一句curl搞定,非常适合运维同学使用。
• 大数据量下的配置
数据量到了一定规模的时候,全家桶组合拳会开始体现价值。
Beats是简单高可用的,瓶颈一般会出现在Logstash(吃CPU)和Elastic Search(吃磁盘IO)上。Logstash好办,而Elastic Search在加机器的时候如果分片数量过少,会影响效果。所以建议一开始就给索引(index)配置较大的分片数量(shards)。
Elastic Search的ttl属性有点问题,如果要按时间分片的话,建议直接从索引这一层来操刀。例如搜索日志的索引名字就叫search-log-20160924。自己造个轮子,定时创建新的索引、删除过期的索引。
• 能不能不用Elastic Search
当然可以,Beats跟Logstash单独拿出来用也是很不错的工具。数据存储和分析未必要走-> ES -> Kibana这条路。可以感受到,Elastic Search逐渐成为Elastic Stack的概念了,不仅仅是搜索,而是整套数据解决方案。