机器学习方法检测恶意文件
1. 恶意文件的传统检测方法
恶意文件检测在机器学习方法流行之前,一直是杀毒引擎的黑箱技术,很少为外界所周知。对于一般粗浅的应用者而言,最简单的做法是有两种:
1. 寻找各种开源的病毒库或者威胁情报网站,收集恶意文件的MD5值,作为黑名单使用。
2. 同时集成各种知名的杀毒软件或者沙箱,然后保存每个杀毒软件或沙箱对恶意文件的执行结果,然后综合所有的执行结果做综合判定:设置判定规则,或者用机器学习的方法做模型判定。
2. 机器学习的恶意文件检测
那么更智能的机器学习方法如何做恶意文件检测呢?论文《Deep Neural Network Based Malware Detection Using Two Dimensional Binary Program Features》给出了使用深度学习检测恶意程序的具体方法,在论文中他们描述了具体的特征提取方法,并在约40万程序上进行了测试,检出率达到95%,误报率为0.1%。
随后《Web安全之强化学习与GAN》一书总结了上述论文的特征提取方法,以及如何用Python工具做具体的实现。这里作为读书笔记记录如此,便于以后温故而知新。
2.1 PE首部特征提取
2.1.1 特征直方图
本质上PE文件也是二进制文件,可以当作一连串字节组成的文件。字节直方图又称为ByteHistogram,它的核心思想是,定义一个长度为256维的向量,每个向量依次为0x00,0x01一直到0xFF,分别代表 PE文件中0x00,0x01一直到0xFF对应的个数。例如经过统计,0x01有两个,0x03和0x05对应的各一个,假设直方图维度为8,所以对应的直方图为:[0,2,0,1,0,0,1,0,0]
Python中实现自己直方图非常方便,主要是numPy提供了一个非常强大的函数:
numpy.bincount(x, weights=None, minlength=None)numpy.bincount专门用于以字节为单位统计个数,比如统计0~7出现的个数:
>>> np.bincount(np.array([0, 1, 1, 3, 2, 1, 7])) array([1, 3, 1, 1, 0, 0, 0, 1], dtype=int32)其中, minlength参数用于指定返回的统计数组的最小长度,不足最小长度的会自动补0,比如统计0~7出现的个数,但是指定minlength为10:
>>> np.bincount(np.array([0, 1, 1, 3, 2, 1, 7]),minlength=10) array([1, 3, 1, 1, 0, 0, 0, 1, 0, 0], dtype=int32)实际使用时,单纯统计直方图非常容易过拟合,因为字节直方图对于PE文件的二进制特征过于依赖,PE文件增加一个无意义的0字节都会改变直方图;另外PE文件中不同字节的数量可能差别很大,数 量占优势的字节可能会大大弱化其他字节对结果的影响,所以需要对直方图进行标准化处理。一种常见的处理方式是,增加一个维度的变量,用于统计PE文件的字节总数,同时原有直方图按照字节总数取 平均值。
2.1.2 字节熵直方图
若信源符号有n种取值:U1 ,U2 ,U3 ,…,Un ,对应概率为:P1 ,P2 ,P3 ,…,Pn ,且各种符号的出现彼此独立。这时,信源的信息熵定义如下:

通常,log是以2为底。
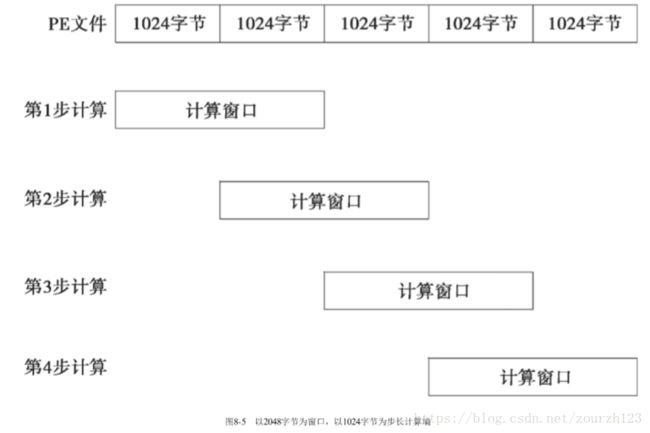
PE文件同样可以使用字节的信息熵来当作特征。我们把PE文件当作一个字节组成的数组,如图8-5所示,在这个数组上以2048字节为窗口,以1024字节为步长计算熵。
2.1.3 文本特征
恶意文件通常在文本特征方面与正常文件有所区分,比如硬编码上线IP和C&C域名等,我们进一步提取PE文件的文本特征,下面我们先总结需要关注的文本特征。
- 可读字符串个数
- 平均可读字符串长度
- 可读字符直方图,由于可读字符的个数为96个,所以我们定义一个长度为96的向量统计其直方图。
- 可读字符信息熵.
- C盘路径字符串个数,恶意程序通常对被感染系统的根目录有一定的文件操作行为,表现在可读字符串中,可能会包含硬编码的C盘路径,我们将这类字符串的个数作为一个维度。
- 注册表字符串个数,恶意程序通常对被感染系统的注册表有一定的文件操作行为,表现在可读字符串中,可能会包含硬编码的注册表值,我们将这类字符串的个数作为一个维度。注册表字符串一般包含"HKEY_"字串,例如:self._registry = re.compile(b'HKEY_')
- URL字符串个数,恶意程序通常从指定URL下载资源,最典型的就是下载者病毒,表现在可读字符串中,可能会包含硬编码的URL,我们将这类字符串的个数作为一个维度:self._urls = re.compile(b'https?://', re.IGNORECASE)
- ·MZ头的个数,例如:self._mz = re.compile(b'MZ')
2.1.4 解析PE结构特征
上面提到的字节直方图、字节熵直方图和文本特征直方图都可以把PE文件当作字节数组处理即可获得。但是有一些特征我们必须按照PE文件的格式进行解析后才能获得,比较典型的就是文件信息。我 们定义需要关注的文件信息包括以下几种:
- 是否包含debug信息。
- 导出函数的个数。
- 导入函数的个数。
- 是否包含资源文件。
- 是否包含信号量。
- 是否启用了重定向。
- 是否启用了TLS回调函数。
- 符号个数。
我们使用lief库解析PE文件:binary = lief.PE.parse(bytez)
我们定义一个维度为9的向量记录我们关注的文件信息:
return np.asarray([
binary.virtual_size,
binary.has_debug,
len(binary.exported_functions),
len(binary.imported_functions),
binary.has_relocations,
binary.has_resources,
binary.has_signature,
binary.has_tls,len(binary.symbols),
]).flatten().astype(self.dtype)2.1.5.文件头信息
PE文件头中的信息也是非常重要的信息,下面我们对关注的内容做出说明。
- PE文件的创建时间,例如:[binary.header.time_date_stamps]
- 机器码 ,每个CPU拥有唯一的机器码,虽然PE文件把机器码定义为一个WORD类型,即2个字节。一种特征定义方式就是直接把机器码当成一个数字处理;另外一种方式就是类似词袋的处理方式,定义一个固定 长度为N的词袋,把机器码转换成一个维度为N的向量,例如:FeatureHasher(10, input_type="string", dtype=self.dtype).transform( [[str(binary.header.machine)]]).toarray(),
- 文件属性,文件属性中包含大量重要信息,比如文件是否是可运行的状态,是否为DLL文件等。例如:FeatureHasher(10, input_type="string", dtype=self.dtype).transform( [[str(c) for c in binary.header.characteristics_list]]).toarray()
- 该PE文件所需的子系统,例如:FeatureHasher(10, input_type="string", dtype=self.dtype).transform( [[str(binary.optional_header.subsystem)]]).toarray()
- 该PE文件所需的DLL文件的属性。 例如:FeatureHasher(10, input_type="string", dtype=self.dtype).transform( [[str(c) for c in binary.optional_header.dll_characteristics_lists]]).toarray()
- Magic,例如:FeatureHasher(10, input_type="string", dtype=self.dtype).transform( [[str(binary.optional_header.magic)]]).toarray()
- 映像的版本号,版本号有两个维度:[binary.optional_header.major_image_version], [binary.optional_header.minor_image_version]
- 链接器的版本号,使用其版本号作为两个维度:[binary.optional_header.major_linker_version], [binary.optional_header.minor_linker_version]
- 所需子系统版本号,例如:binary.optional_header.major_subsystem_version], [binary.optional_header.minor_subsystem_version]
- 所需操作系统的版本号,[binary.optional_header.major_operating_system_version], [binary.optional_header.minor_operating_system_version]
- 代码段的长度,[binary.optional_header.sizeof_code]
- 所有文件头的大小,[binary.optional_header.sizeof_headers]
2.1.6 导出表
导出表包含导出函数的入口信息,与文件属性处理方式相同:
FeatureHasher(128, input_type="string",dtype=self.dtype).transform([binary.exported_functions]).toarray().flatten().astype(self.dt)2.1.7.导入表
导入表中保存的是函数名和其驻留DLL名等动态链接所需的信息,与导出表处理方式类似,我们分别将导入的库文件以及导入的函数使用FeatureHasher转换成维度为256和1024的向量:
libraries = [l.lower() for l in binary.libraries]
imports = [lib.name.lower() + ':' + e.name for lib in binary.imports for e in lib.entries]
return np.concatenate([
FeatureHasher(256, input_type="string", dtype=self.dtype).transform([libraries]).toarray(),
FeatureHasher(1024, input_type="string", dtype=self.dtype).transform([imports]).toarray() ],
axis=-1).flatten().astype(self.dtype)其中,为了解决不同库具有同名函数的问题,我们把导入函数和对应的库使用冒号连接成新的字符串。
2.2 PE节中的特征提取
整个PE的文件结构如下:

之前提取的的是除节头和节区之外的特征。本节提取节头和节区的特征。
2.2.1 节头特征提取
- 节的个数:len(binary.sections)
- 长度为0的节的个数:sum(1 for s in binary.sections if s.size == 0)
- 名称为空的节的个数:sum(1 for s in binary.sections if s.name == "")
- 可读可执行的节的个数。可读可执行,在lief中表示为:lief.PE.SECTION_CHARACTERISTICS.MEM_READ 和lief.PE.SECTION_CHARACTERISTICS.MEM_EXECUTE
- 统计可读可执行的节的个数的方法为:sum(1 for s in binary.sections if s.has_characteristic(lief.PE.SECTION_CHARAC TERISTICS. MEM_READ) and s.has_characteristic(lief.PE.SECTION_CHARACTERISTICS.MEM_EXECUTE))
- 可写的节的个数:sum(1 for s in binary.sections if s.has_characteristic( lief.PE.SECTION_CHARACTERISTICS.MEM_WRITE))
2.2.2 节大小的特征
节的大小包括两部分:一个是节在物理文件中的大小,一个是节在内存中的大小。
section_sizes = [(s.name, len(s.content)) for s in binary.sections]
section_vsize = [(s.name, s.virtual_size) for s in binary.sections]然后使用FeatureHasher均转换成维度为50的向量:
FeatureHasher(50, input_type="pair", dtype=self.dtype).transform( [section_sizes]).toarray(),
FeatureHasher(50, input_type="pair", dtype=self.dtype).transform( [section_entropy]).toarray(),
FeatureHasher(50, input_type="pair", dtype=self.dtype).transform( [section_vsize]).toarray()2.2.3 节的熵
统计节的熵:并使用FeatureHasher均转换成维度为50的向量:
section_entropy = [(s.name, s.entropy) for s in binary.sections]
FeatureHasher(50, input_type="pair", dtype=self.dtype).transform( [section_entropy]).toarray()
2.2.4.节的入口点名称和属性
根据节的入口点(entry point),找到入口点的名称和属性。
entry = binary.section_from_offset(binary.entrypoint)
if entry is not None:
entry_name = [entry.name]
entry_characteristics = [str(c)
for c in entry.characteristics_lists]
else:
entry_name = []
entry_characteristics = []将入口点的名称和属性使用FeatureHasher转换成维度为50的向量:
FeatureHasher(50, input_type="string", dtype=self.dtype).transform( [entry_name]).toarray()
FeatureHasher(50, input_type="string", dtype=self.dtype).transform([entry_characteristics]).toarray()2.3 检测模型
恶意程序的检测过程是个典型的二分类问题,工业界和学术届经常使用的方法包括多层感知机(MLP)、卷积神经网络(CNN)、梯度提升决策树(GBDT)和XGBoost。