【计算机视觉笔记】图像检索学习 (Content Based Image Retrieval)
论文跟踪:Awesome image retrieval papers https://github.com/willard-yuan/awesome-cbir-papers
综述:SIFT Meets CNN: A Decade Survey of Instance Retrieval
github Overview:
- Guide-CBIR
- CBIR_LeaderBoard
- https://github.com/willard-yuan/willard-yuan.github.io/tree/master/_posts
SIFT Meets CNN: A Decade Survey of Instance Retrieval
基于内容的图像检索任务(CBIR)长期以来一直是计算机视觉领域重要的研究课题,自20世纪90年代早期以来,研究人员先后设计了图像的全局特征,局部特征,卷积特征的方法对CBIR任务进行探索和研究,并取得了卓越的成果。
Abstract
在基于内容的图像检索技术(CBIR)发展早期,研究人员大多基于图像的全局特征进行研究。2003年以来,由于SIFT特征在图像变换(尺度、方向变化)问题中的优异表现,基于局部描述算子(如SIFT描述算子)的图像检索方法一直被广泛研究。最近,基于卷积神经网络(CNN)的图像表示方法吸引了越来越多的关注,同时这种方法也展现出了令人赞叹的性能。我们领域正处于快速发展时期,本文对实例检索近十多年来的进展进行了综合且全面的调查研究,主要展示了基于SIFT和CNN特征的两类主要方法。
对SIFT一类的方法,我们根据字典本大小,将相关文献按照字典的大/中/小规模进行组织。
对CNN一类的方法,我们主要依据预训练模型,微调模型和混合模型进行分类和讨论。预训练模型和微调模型方法采用了单通道的图像输入方法而混合模型则采用了基于块的特征提取策略。
本篇综述选取了在现代实例检索任务中先前的各类工作,展现了该任务中的里程碑时刻,并提出了关于SIFT与CNN的内在联系的见解。在分析与比较了各种方法在几个数据集上的检索性能后,我们分别讨论了通用实例检索和专用实例检索任务未来的发展前景。
Introduction
基于内容的图像检索任务(CBIR)是计算机视觉领域一项由来已久的研究课题。CBIR研究在20世纪90年代早期正式开始,研究人员根据诸如纹理、颜色这样的视觉特征对图像建立索引,在这一时期大量的算法和图像检索系统被提出。其中一种简单明了的策略就是提取出图像的全局描述符,这种策略在1990s和2000s早期是图像检索社区研究的重点。然而,众所周知,全局描述符这种方法在诸如光照,形变,遮挡和裁剪这些情况下难以达到预想的效果。这些缺陷也导致了图像检索准确率的低下,也局限了全局描述符算法的应用范围。恰在这时,基于局部特征的图像检索算法给解决这一问题带来了曙光。
本篇综述主要关注于实例级的图像检索任务。在这个任务中,给定一张物体/场景/建筑类型的待查询图片,查询出包含拍摄自不同角度、光照或有遮挡的,含有相同物体/场景/建筑的图片。实例检索不同于类别检索任务,因为后者的目标是检索出同类别的图片。接下来,如果没有特别指出的话,“图像检索”和“实例检索”两个名词可以相互替代。
在图1中我们展示了多年来实例检索任务中的里程碑时刻,并且在图中着重标出了基于SIFT特征和CNN特征算法的提出的时间。2000年可以认为是大部分传统方法结束的时间节点,当时Smeulders等撰写了“图像检索早期发展的终结”这篇综述。三年后(2003),词袋模型(BoW)进入图像检索社区的视野,并在2004年结合了SIFT方法符被应用于图像分类任务。这后来的近10年时间里,社区见证了BoW模型的优越性,它给图像检索任务带来了各种提升。在2012年,Krizhevsky等人使用AlexNet神经网络模型在ILSRVC 2012上取得了当时世界上最高的识别准确率。从那以后,研究的重心开始向基于深度学习特别是卷积神经网络(CNN)的方法转移。
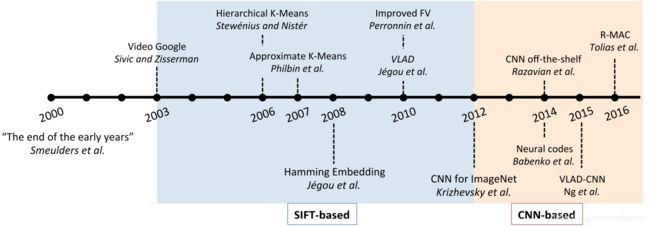
基于SIFT特征的方法大多依赖于BoW模型。BoW模型最初是为解决文档建模问题而提出的,因为文本本身就是由单词组成的。它通过累加单词响应到一个全局向量来给文档建立单词直方图。在图像领域,尺度不变(SIFT)特征的引入使得BoW模型变得可行。最初,SIFT由检测器和描述符组成,但现在描述符被单独提取出来使用。在这篇综述中,如果没有特别指明的话,SIFT往往是指128维的描述符(OpenCV的SIFT实现也是默认生成128维向量),这也是社区的惯例。通过一个预训练的字典(译者注:补充说明一下,在工业界的项目中,待检索的图像往往有特定的范围,使用特定范围内的有代表性的图片构建出预训练字典可以取得比较好的效果),局部特征被量化表示为视觉词汇。一张图片能够被表示成类似文档的形式,这样就可以使用经典的权重索引方案。
近几年,CNN这种层次结构模型在许多视频相关的任务上取得的成绩远好于手工特征,基于SIFT特征的模型的风头似乎被CNN盖过了。基于CNN的检索模型通常计算出紧密的图像表示向量,并使用欧氏距离或ANN(approximate nearest neighbor)查找算法进行检索。最近的文献可能会直接使用预训练好的CNN模型或微调后应用于特定的检索任务。这些方法大多只将图像输入到网络中一次就可以获取描述符。一些基于图像块的方法则是将图像多次输入到网络中,这和SIFT方法的习惯有些类似;在这篇综述中,我们将这些方法称为混合型方法。
CATEGORIZATION METHODOLOGY
根据不同的视觉表示方法,本文将检索文献大致分为两类:基于SIFT特征的和基于CNN特征的方法。进一步地,我们将基于SIFT的方法根据编码本大小又分为大,中,小编码本三类。我们注意到,编码本的大小与所选取的编码方法紧密相关。基于CNN的方法分为使用预训练的模型,微调的模型以及混合模型方法。他们的异同点列于表1。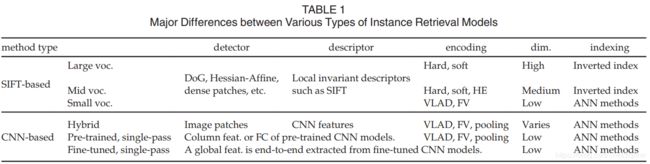
基于SIFT的方法在2012年之前一直是研究的重点(当然近年来也有不少相关的杰出工作)。这一类方法通常使用如Hessian-Affine这种探测器,同时也使用SIFT这种描述符。编码本将局部特征映射到一组向量中。基于编码本大小,我们将基于SIFT的方法分为如下三类。
-
使用小型编码本。视觉词汇少于几千个,紧凑编码向量在降维和编码之前生成。
-
使用中型编码本。鉴于BoW的稀疏性和视觉词汇的低区分度,使用倒排索引和二进制签名方法。准确率和效率间的权衡是影响算法的主要因素。
-
使用大型编码本。鉴于BoW直方图的稀疏性和视觉词汇的高区分度,在算法中使用了倒排索引和存储友好型的签名方式。在编码本的生成和编码中使用了类似的方法。
基于CNN的方法使用CNN模型提取特征,建立紧凑向量(固定长度)。它们也分为三类:
-
混合型方法。图像块被多次输入进CNN用于特征提取。编码与索引方法和基于SIFT的检索方法近似。
-
使用预训练的模型。通过在大规模图像集(例如ImageNet)上预训练的CNN模型进行单通道传播提取特征。使用紧凑编码/池化技术进行检索。
-
使用微调的模型。在训练图像与目标数据库具有相似的分布的训练集上,对CNN模型进行微调。通过单通道CNN模型,运用端到端的方法提取出CNN特征。这种视觉表示方法提升了模型的区分能力。
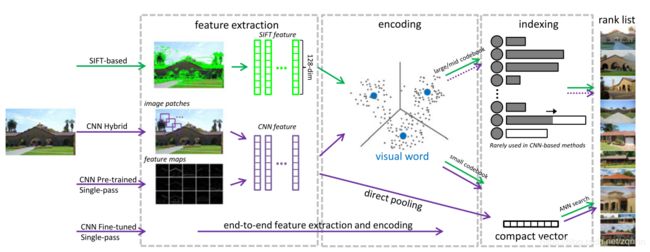 基于SIFT和CNN的检索模型的一般流程——在这两种方法中,在小码本下,采用编码/池来产生紧凑的矢量。 在基于SIFT的方法中,在大/中型码本下需要倒排索引。 CNN功能也可以使用微调的CNN模型以端到端的方式进行计算。
基于SIFT和CNN的检索模型的一般流程——在这两种方法中,在小码本下,采用编码/池来产生紧凑的矢量。 在基于SIFT的方法中,在大/中型码本下需要倒排索引。 CNN功能也可以使用微调的CNN模型以端到端的方式进行计算。
SIFT-BASED IMAGE RETRIEVAL
局部特征提取。假设我们有一个含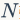 张图片的画廊
张图片的画廊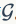 。指定一个特征检测器,我们从稀疏的感兴趣点或密集的图像块中提取局部描述符。我们用
。指定一个特征检测器,我们从稀疏的感兴趣点或密集的图像块中提取局部描述符。我们用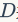 来表示局部描述符,用
来表示局部描述符,用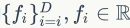 表示图像中被检测的区域。
表示图像中被检测的区域。
编码本的训练。基于SIFT的方法离线训练编码本。编码本中的每一个视觉词汇位于子空间的中心,这称为“沃罗诺伊单元”。更大的码本对应于更精细的划分,从而产生更多区分性的视觉词,反之亦然。假设已有一些局部描述符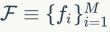 从无标签的训练集中计算出。例如k-means这样的基准方法就是将
从无标签的训练集中计算出。例如k-means这样的基准方法就是将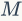 个点聚类成
个点聚类成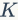 簇,得到的个视觉词汇即编码本的大小。
簇,得到的个视觉词汇即编码本的大小。
特征编码。一个局部描述符 通过特征编码过程
通过特征编码过程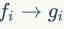 被映射到嵌入特征
被映射到嵌入特征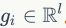 。在使用k-means方法时,可以根据
。在使用k-means方法时,可以根据 到视觉词汇的距离进行编码。对于大规模的编码本,硬量化和软量化方法都是很好的选择。前者量化得到只有一个非零条目的嵌入特征
到视觉词汇的距离进行编码。对于大规模的编码本,硬量化和软量化方法都是很好的选择。前者量化得到只有一个非零条目的嵌入特征 ,后者则是将量化表示为少量的视觉词汇。在汇总所有的局部嵌入特征后就得到了一个全局签名。对于中等规模的编码本来说,可以通过额外的二值签名保护原始信息。当使用小规模编码本时,大多使用VLAD,FV之类的编码方法(VLAD可以理解为是BOF和FV的折中,BOF是把特征点做kmeans聚类,然后用离特征点最近的一个聚类中心去代替该特征点,损失较多信息;FV是对特征点用GMM建模,GMM实际上也是一种聚类,只不过它是考虑了特征点到每个聚类中心的距离,也就是用所有聚类中心的线性组合去表示该特征点,在GMM建模的过程中也有损失信息;VLAD像BOF那样,只考虑离特征点最近的聚类中心,同时保存了每个特征点到离它最近的聚类中心的距离;像FV那样,VLAD考虑了特征点的每一维的值,对图像局部信息有更细致的刻画)。
,后者则是将量化表示为少量的视觉词汇。在汇总所有的局部嵌入特征后就得到了一个全局签名。对于中等规模的编码本来说,可以通过额外的二值签名保护原始信息。当使用小规模编码本时,大多使用VLAD,FV之类的编码方法(VLAD可以理解为是BOF和FV的折中,BOF是把特征点做kmeans聚类,然后用离特征点最近的一个聚类中心去代替该特征点,损失较多信息;FV是对特征点用GMM建模,GMM实际上也是一种聚类,只不过它是考虑了特征点到每个聚类中心的距离,也就是用所有聚类中心的线性组合去表示该特征点,在GMM建模的过程中也有损失信息;VLAD像BOF那样,只考虑离特征点最近的聚类中心,同时保存了每个特征点到离它最近的聚类中心的距离;像FV那样,VLAD考虑了特征点的每一维的值,对图像局部信息有更细致的刻画)。
局部特征提取
局部不变特征旨在精确匹配图像之间的局部结构。 基于SIFT的方法通常共享由特征检测器和描述符组成的类似特征提取步骤。
局部检测器。感兴趣点检测器旨在于在多样的图像场景中定位出一系列特征稳定的局部区域。在检索社区中,寻找图像的仿射协变区域(affine-covariant regions)一直是首选方法。它之所以称之为“协变的”是因为检测区域随着仿射变化而改变,因此区域描述符具有不变性。这种仿射协变区域检测器和以关键点为中心的海森检测器(Hessian detector)不同,当然也和以寻找尺度不变区域为目标的高斯差分检测器(DoG detector) 不同。适应于局部强度模式的椭圆区域由仿射检测器探测到。这就确保了相同的图像局部结构即使是因为视角变化而产生形变时也能被检测到,视角形变问题也是图像检索任务中的常见问题。在里程碑事件中,我们也提到了最稳定连通域(MSER)检测器和仿射拓展的海尔-拉普拉斯检测器( affine extended Harris-Laplace detector)这两种具有仿射不变性的区域检测器。鉴于海森仿射检测器在解决视角变化问题中的优异性能,社区认为它是要优于DoG检测器的。为了解决这些仿射协变区域方向模糊的问题,重力假设方法应运而生。这种方法抛弃了方向估计的思路,并在建筑物数据集上的效果不断改善。在图像检索中也尝试了其他的非仿射检测器,例如拉普拉斯-高斯(LOG)和海尔检测器。对于表明光滑的物体,仅有少量的关键点会产生响应,因此可以用物体边缘作为局部特征描述。
另一方面,针对密集区域检测器也有不少研究。在对比了密集采样图像块和探测图像块两种方法后,Sicre等指出前者表现更优。为了恢复密集采样图像块的旋转不变性,提出了图像块主旋转角方法。各种密集采样策略以及关键点检测器的综合比较可以在《A comparison of dense region detectors for image search and fine-grained classification》这篇文献中查阅到。
局部描述符。局部描述符使用一系列检测区域对局部图像内容进行编码。SIFT描述符一直以来都是大家默认使用的描述符。这种128维的向量在匹配准确率上从众多描述符中脱颖而出。更进一步地,PCA-SIFT描述符将特征向量的维度从128维减少到36维,通过增加特征建立计算量和降低区分度来加快匹配速度。另一种改进方法是RootSIFT,它首先将SIFT描述符进行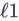 归一化,随后对每个元素开方。RootSIFT现在是基于SIFT的检索方法惯用方法。除了SIFT之外,SURF描述符也被广泛应用。SURF描述符结合了海森-拉普拉斯检测器和局部梯度直方图。积分图技巧可以用于加速特征的计算(译者注:积分图技巧会对原图像首先生成一张积分图,这种通过空间换取时间的策略,在计算图像的诸如海尔特征时可以大幅提高计算速度)。SURF可以取得和SIFT近乎一样的准确率,同时SURF计算速度更快。文献《A comparison of sift, pca-sift and surf》对SIFT,PCA-SIFT和SURFF进行了比较。为了进一步加快匹配速度,二值描述符用汉明距离替代了欧氏距离。
归一化,随后对每个元素开方。RootSIFT现在是基于SIFT的检索方法惯用方法。除了SIFT之外,SURF描述符也被广泛应用。SURF描述符结合了海森-拉普拉斯检测器和局部梯度直方图。积分图技巧可以用于加速特征的计算(译者注:积分图技巧会对原图像首先生成一张积分图,这种通过空间换取时间的策略,在计算图像的诸如海尔特征时可以大幅提高计算速度)。SURF可以取得和SIFT近乎一样的准确率,同时SURF计算速度更快。文献《A comparison of sift, pca-sift and surf》对SIFT,PCA-SIFT和SURFF进行了比较。为了进一步加快匹配速度,二值描述符用汉明距离替代了欧氏距离。
除了手工特征,一些研究人员也提出了学习式的方案来提高局部描述符特征的区分度。例如,Philbin等提出了一种非线性的变换使得投影SIFT描述符为真实匹配产生更小的差异。Simoyan等更进一步地设计了学习池化区域和线性描述符投影的方案来改进Philbin等的方案。
使用小规模编码本进行检索
小规模编码本一般包含几千、几百甚至更少的视觉词汇,因此编码本生成以及编码算法的时间复杂度不高。这方面一些有代表性的工作包括BoW、VLAD和FV。我们主要讨论了VLAD和FV模型,同时根据《Multiple measurements and joint dimensionality reduction for large scale image search with short vectors》 这篇文献综合评价了BoW压缩向量。
生成编码本
聚类时的算法复杂度很大程度上依赖于编码本的大小。用VLAD或FV生成的编码本通常很小,一般是64,128,256。在VLAD中使用平面k-means聚类算法生成编码本。在FV中使用GMM算法,例如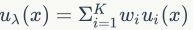 ,式中
,式中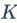 表示高斯混合曲线的数目,通过极大似然估计算法训练得到。GMM用个混合高斯分布曲线描述特征空间,这同时也可以表示为
表示高斯混合曲线的数目,通过极大似然估计算法训练得到。GMM用个混合高斯分布曲线描述特征空间,这同时也可以表示为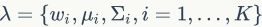 ,其中
,其中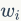 ,
,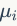 和
和 别表示混合权重,均值向量和高斯曲线的协方差矩阵。
别表示混合权重,均值向量和高斯曲线的协方差矩阵。
编码方法
因为小规模编码本尺寸小的缘故,相对复杂的和存储信息的方法可以在这上面使用。我们在这个小节中主要调研了FV,VLAD方法及其发展。使用预先训练的GMM模型,FV描述局部特征和GMM中心之间的平均一阶和二阶差异。它的维度是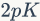 ,其中
,其中 是局部描述符的维度,是GMM编码本的长度。FV通常进行指数归一化(power normalization)以抑制突发性问题。在这一步,FV的每一部分在的非线性变换由参数
是局部描述符的维度,是GMM编码本的长度。FV通常进行指数归一化(power normalization)以抑制突发性问题。在这一步,FV的每一部分在的非线性变换由参数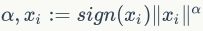 表征。接下来使用
表征。接下来使用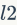 归一化,这样FV就从各方面得到提升。例如,Koniusz等人用每个描述符的空间坐标和相关的可调权重来对其进行扩充。在《Revisiting the fisher vector for fine-grained classification》这篇文献中,更大的编码本(将近4096)表现出比小编码本更好的分类准确率,当然计算花费同时也增大了。为了修正局部区域独立同分布这一假设,Cinbis等人提出了非独立同分布模型,这个工作抑制了突发事件的影响,同时也改进了指数归一化的效果。
归一化,这样FV就从各方面得到提升。例如,Koniusz等人用每个描述符的空间坐标和相关的可调权重来对其进行扩充。在《Revisiting the fisher vector for fine-grained classification》这篇文献中,更大的编码本(将近4096)表现出比小编码本更好的分类准确率,当然计算花费同时也增大了。为了修正局部区域独立同分布这一假设,Cinbis等人提出了非独立同分布模型,这个工作抑制了突发事件的影响,同时也改进了指数归一化的效果。
VLAD编码方案由Jégou提出,可以认为VLAD是FV的简化版本。VLAD量化将局部特征量化为最近邻视觉词汇,同时记录下两者的距离。由于编码本规模小,因此最近邻检索方案可行。在残差向量被总和池化聚合后进行归一化。VLAD的维度是 。同样,研究人员对VLAD在多方面进行了改进。Jégou和Chum提出使用PCA和白化(在表5中表示为
。同样,研究人员对VLAD在多方面进行了改进。Jégou和Chum提出使用PCA和白化(在表5中表示为 )去消除视觉词语共现现象,并且训练多个编码本以减少量化带来的损失。Arandjelovi
)去消除视觉词语共现现象,并且训练多个编码本以减少量化带来的损失。Arandjelovi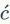 等从三个方面拓展了VLAD:1)归一化每个粗糙聚类中的残差和,称为内部归一化,2)通过词汇自适应来解决数据集迁移问题,3)用多VLAD模型(multi-VLAD)来解决小目标发掘问题。Delhumeau等提出应该将残差向量归一化,而不是求残差和;他们还提倡在每个Voronoi格内进行PCA降维,而不是像《Aggregating local image descriptors into compact codes》中所提出的降维方案。《Improving large-scale image retrieval through robust aggregation of local descriptors》中提出应该使用软任务和经验性地为每个等级学习最佳权重来改进硬量化方案。
等从三个方面拓展了VLAD:1)归一化每个粗糙聚类中的残差和,称为内部归一化,2)通过词汇自适应来解决数据集迁移问题,3)用多VLAD模型(multi-VLAD)来解决小目标发掘问题。Delhumeau等提出应该将残差向量归一化,而不是求残差和;他们还提倡在每个Voronoi格内进行PCA降维,而不是像《Aggregating local image descriptors into compact codes》中所提出的降维方案。《Improving large-scale image retrieval through robust aggregation of local descriptors》中提出应该使用软任务和经验性地为每个等级学习最佳权重来改进硬量化方案。
注意到许多常规的方法对VLAD,FV,BoW,局部约束线性编码(LLC)以及单项嵌入这些嵌入方法有益。Tolias等人提出结合SIFT描述符,用方向协变嵌入的方法来对SIFT特征主方向进行编码。它通过在感兴趣的区域内使用几何线索来实现与弱几何一致性(WGC)相似的协方差属性,使得与主方向相似的匹配点被加权,反之亦然。三角嵌入方法只考虑了输入向量的方向而没有考虑其大小。Jégou等人同样也提出了一种限制映射向量之间干扰的民主聚合的方法。除了类似民主聚合的思想,Murray和Perronnin提出,通过均衡池化向量和每个编码表示之间的相似性优化广义最大池化(GMP)方法。
BoW,VLAD和FV的复杂度基本一致。我们忽视线下训练时间和SIFT特征提取时间。在视觉词汇分配这一步中,VLAD(FV)模型中每一个特征(高斯曲线)需要计算和每一个视觉词汇的距离(soft assignment coefficient),因此这一步的计算复杂度为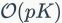 。并且其他步骤的计算复杂度都要小于。考虑到是以求和池化方式进行的嵌入,因此编码过程总的计算复杂度为
。并且其他步骤的计算复杂度都要小于。考虑到是以求和池化方式进行的嵌入,因此编码过程总的计算复杂度为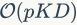 ,其中
,其中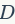 表示图像中提取的特征的数目。三角嵌入式VLAD的一个变异体,它和VLAD的计算复杂度相似,都是。multi-VLAD的计算复杂度也是,但是它匹配过程的复杂度过大。分层的VLAD的计算复杂度是
表示图像中提取的特征的数目。三角嵌入式VLAD的一个变异体,它和VLAD的计算复杂度相似,都是。multi-VLAD的计算复杂度也是,但是它匹配过程的复杂度过大。分层的VLAD的计算复杂度是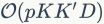 ,其中
,其中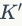 表示第二个编码本的大小。在特征聚类这一步,GMP和民主聚合方案都有很高的计算复杂度。GMP的复杂度是
表示第二个编码本的大小。在特征聚类这一步,GMP和民主聚合方案都有很高的计算复杂度。GMP的复杂度是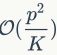 ,式中是
,式中是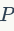 特征嵌入的维度, 民主聚类方法的计算复杂度主要来源于Sinkhorn算法。
特征嵌入的维度, 民主聚类方法的计算复杂度主要来源于Sinkhorn算法。
最似最近邻检索
由于VLAD/FV嵌入的维度相当高,因此研究人员提出了高效的压缩和最似最近邻检索(ANN)算法。例如,主成分分析(PCA)算法常适用于降维任务,特别是使用PCA降维后检索的准确度甚至会提高。对于基于哈希的最似最近邻方法,Perronnin等人使用标准二值编码方法,如局部敏感哈希(LSH)和谱哈希(spectral hashing)。然而,在使用SIFT和GIST特征数据库进行测试时,谱哈希方法被证明要优于乘积量化方法。在这些基于量化的最似最近邻算法中,PQ算法表现得最为出色。关于VLAD和PQ算法的详细研究可以参见《A comprehensive study over vlad and product quantization in large-scale image retrieval》。同样,PQ算法后来也被不断改进。Douze等人提出对聚类中心重新排序,使得相邻的中心具有较小的汉明距离。该方法与基于汉明距离的最似最近邻检索相兼容,这为PQ算法提供了显著的加速。我们参阅了《A survey on learning to hash》作为ANN方法的调研报告基础。
我们还提到一种新兴的ANN算法,群组测试算法。简要地说,该算法将数据库分组,每组都由一个组向量表示。通过查询和组向量之间的比较计算出一个组包含正确匹配的可能性。因为组向量数目远少于数据库向量,因此检索时间大大缩短。Iscen等提出直接找出数据库中最优组向量,而不用精确地分组,这个方案减少了内存的消耗。
使用大规模编码本进行检索
一个大规模编码本可能含有1百万个甚至更多的视觉词汇。其中一些步骤和小编码本方案比起来有很大的差异。
生成编码本
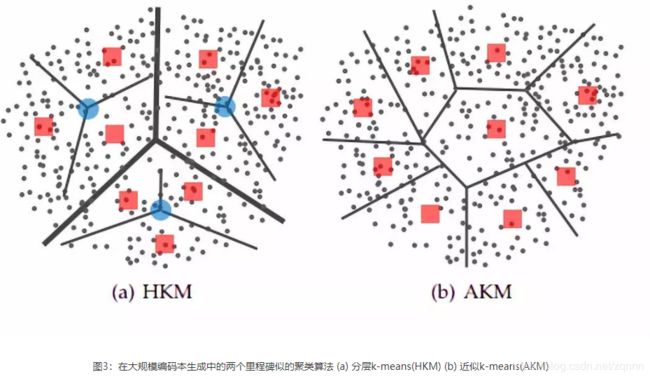
在将数据分配到大量集群中,近似方法是至关重要的。在检索社区中,两个有代表性的工作是:分层k-means(HKM)和近似k-means(AKM),如图1和图3所示。HKM方法在2006年提出,HKM分层次地应用标准k-means方法进行特征训练。HKM首先将特征空间中的点划分为几个簇,接着递归地将每个簇划分为更多的群集。在每次递归时,每个点都要被归类为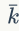 个簇中的某一个,聚类树的深度为
个簇中的某一个,聚类树的深度为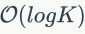 ,其中
,其中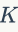 是期望得到的聚类簇数目。HKM的计算复杂度是
是期望得到的聚类簇数目。HKM的计算复杂度是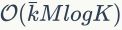 ,其中
,其中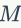 是训练样本数。当很大的时候,HKM的计算复杂度远小于扁平k-means(flat k-means)
是训练样本数。当很大的时候,HKM的计算复杂度远小于扁平k-means(flat k-means)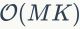 的计算复杂度(译者注:显然大规模编码本的
的计算复杂度(译者注:显然大规模编码本的 要远小于)。另一个里程碑式的大规模编码本生成算法是AKM。该方法利用随机K-D树对K聚类中心进行索引,使得在分配步骤中能够高效地使用ANN搜索。在AMK算法中,分配步骤的花费可以表示为,其中
要远小于)。另一个里程碑式的大规模编码本生成算法是AKM。该方法利用随机K-D树对K聚类中心进行索引,使得在分配步骤中能够高效地使用ANN搜索。在AMK算法中,分配步骤的花费可以表示为,其中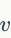 是K-D树中要访问的最近簇的候选数。因此AKM的计算复杂度与HKM相当,并且当K较大时,明显小于扁平k-means算法。实验表明AKM的量化误差要低于HKM,因此它要要优于HKM算法。在大多数基于AKM的方法中,最似最近邻检索算法选用FLANN。
是K-D树中要访问的最近簇的候选数。因此AKM的计算复杂度与HKM相当,并且当K较大时,明显小于扁平k-means算法。实验表明AKM的量化误差要低于HKM,因此它要要优于HKM算法。在大多数基于AKM的方法中,最似最近邻检索算法选用FLANN。
特征编码(量化)
特征编码与编码本聚类是相互交错的,ANN检索对两者都至关重要。在AKM和HKM等一些经典方法中应用的ANN技术可用于聚类和编码中。在大规模编码本中,关键是要平衡量化误差和计算复杂度两者。在编码步骤中,诸如FV,稀疏编码的信息存留式编码方法大都不可行,因为它们的计算复杂度过高。因此,如何在保证量化效率的同时减少量化误差仍是一个极具挑战的问题。
对ANN方法来说,最早的解决方案是沿着分层树结构量化局部特征。不同级别的量化树节点被赋予不同的权重。然而,由于高度不平衡的树结构,该方法优于基于k-d树的量化方法:一个视觉词被分配给每个局部特征,使用从码书构建的k-d树来进行快速ANN搜索。对这种硬量化方案的一种改进是Philbin等人提出的软量化方案,这种方案将一个特征量化为几个最近的视觉词汇。由式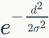 指出,每个指定的视觉单词的权重与它到特征的距离呈负相关,其中d是描述符和聚类中心之间的距离。虽然软量化是基于欧几里得距离,但Mikulik等人提出通过无监督的匹配特征集为每个视觉单词找到相关的视觉单词。基于概率模型,这些备选词往往包含匹配特征的描述符。为了减少软量化的存储成本和查询视觉词汇的数量,Cai等提出当局部特征离最近的视觉词汇距离很远时,该特征可以被丢弃而且不会带来性能的下降。为了进一步加速量化,标量量化提出局部特征在没有明确训练的编码本的情况下被量化。浮点向量是二值化的,并且所得的二进制向量的第一维直接转换为十进制数作为视觉词汇。在高量化误差和低召回率的情况下,标量量化使用位翻转(bit-flop)来为局部特征生成数百个视觉词汇。
指出,每个指定的视觉单词的权重与它到特征的距离呈负相关,其中d是描述符和聚类中心之间的距离。虽然软量化是基于欧几里得距离,但Mikulik等人提出通过无监督的匹配特征集为每个视觉单词找到相关的视觉单词。基于概率模型,这些备选词往往包含匹配特征的描述符。为了减少软量化的存储成本和查询视觉词汇的数量,Cai等提出当局部特征离最近的视觉词汇距离很远时,该特征可以被丢弃而且不会带来性能的下降。为了进一步加速量化,标量量化提出局部特征在没有明确训练的编码本的情况下被量化。浮点向量是二值化的,并且所得的二进制向量的第一维直接转换为十进制数作为视觉词汇。在高量化误差和低召回率的情况下,标量量化使用位翻转(bit-flop)来为局部特征生成数百个视觉词汇。
特征加权
TF-IDF. 视觉词汇在编码本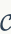 中往往被分配给指定的权重。称为频率与逆文档频率(TF-IDF),这种策略被集成在BoW编码中。TF定义如下:
中往往被分配给指定的权重。称为频率与逆文档频率(TF-IDF),这种策略被集成在BoW编码中。TF定义如下:

式中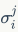 是视觉词汇
是视觉词汇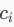 在图像
在图像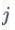 中出现的次数。另一方面,IDF通过全局统计来表明给定视觉词汇(对文档)的贡献。视觉词汇经典的IDF计算公式如下:
中出现的次数。另一方面,IDF通过全局统计来表明给定视觉词汇(对文档)的贡献。视觉词汇经典的IDF计算公式如下:
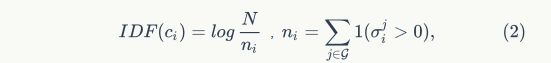
式中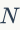 是图形数目,
是图形数目,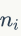 表示视觉词汇
表示视觉词汇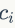 出现的图像编号。视觉词汇出现在图像中的TF-IDF值为:
出现的图像编号。视觉词汇出现在图像中的TF-IDF值为:
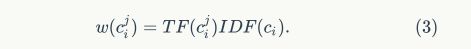
改进方案。与视觉单词加权相关的一个主要问题是突变性。它指的是图像中出现重复结构的现象。这个问题往往在图像相似度中占主要位置。Jégou等人提出了几个TF的变种来解决突变问题。一个有效的策略是在TF上进行平方运算。Revaud等人提出了检测在不相关图像中频繁出现的关键点组来降低评分函数的计算值,而不是用相同的单词索引来分组特征。尽管上述两种方法都提出在量化后检测突变组,Shi等人提出在描述符阶段检测它们。检测到的突变描述符经过平均池化并且送往BoW结构中。在改进IDF方面,Zheng等人提出了 IDF方法来处理突变情况,同时Murata等人设计了后来被并入到BM25公式的指数IDF。在大多数方案都以抑制突变性为目的时,Torii等人将这个问题视为体系结构的一个显着特征,并在突发性检测后设计新的相似性度量方法。
IDF方法来处理突变情况,同时Murata等人设计了后来被并入到BM25公式的指数IDF。在大多数方案都以抑制突变性为目的时,Torii等人将这个问题视为体系结构的一个显着特征,并在突发性检测后设计新的相似性度量方法。
另一个特征加权策略是数据库端的特征增强,《Better matching with fewer features: The selection of useful features in large database recognition problems》和《Three things everyone should know to improve object retrieval》在这方面进行了研究。两篇文献中的方法都离线构建图像的图结构,通过边缘指示两个图像是否共享同一对象。对第一种方案来说,只有通过几何验证的特征才会被被保留,这降低了存储成本。然后,利用其连接图像的所有视觉字来增强基础图像的特征。第二种方案进一步进行对其进行改进,通过只添加那些被认为在增强图像中可见的视觉词汇,从而干扰性的视觉词被排除。
倒排
倒排是一种提高存储和检索效率的算法,它常被用于大/中等规模的编码本中,结构如图4所示。

倒排是一种单一尺寸的结构,其中每一个条目对应编码本中低的一个视觉词汇。每一个视觉词汇都包含一个倒排表,每个倒排表中的索引被称为索引特征或者记录。倒排索引很好地发挥了大规模编码本词汇直方图稀疏性的特点。新的文献提出新的检索方法来适应倒排算法。在基准方案中,图像ID和TF值都被存储在一条记录中。但其他的信息被整合进来时,它们的尺寸应该足够小。例如,在《Contextual weighting for vocabulary tree based image retrieval》中,原始数据在一条记录中被描述符上下文,描述符密度,平均关联日志规模和平均方向差异等属性量化。相似地,方向等空间信息也会被量化。在联合检索的方法中,当倒排索引随着全局一直近邻增长是,单独分割的图片将会被删除以减少内存消耗。在《The inverted multi-index》中提出,原始的单一尺寸倒排索引可以拓展为二维结构来进行替代了SITF特征向量的ANN检索。后来,这种方法被《Packing and padding: Coupled multi-index for accurate image retrieval》改进,融合局部颜色和SIFT描述符进行实例检索。
使用中等规模编码本进行检索
中等规模编码本一般含有10——200k个视觉词汇。视觉词汇展现了中等区分能力,同时检索时也使用了倒排索引。
编码本的生成与量化
考虑到中等规模编码本和大规模编码本相比,计算成本较低,扁平k-means可以在中等规模编码本的生成中使用。同样也有文献指出使用AKM算法可以在聚类中取得很好的效果。
在量化过程中,最近邻检索用来搜索最近的视觉词汇。实践表明使用高精度的ANN算法可以得到更好的检索效果。和大规模编码本下量化算法的研究热度比起来,中等规模编码本的研究明显低了很多。
汉明嵌入算法及其改进
在中等规模编码本下视觉词汇的区分度介于小规模编码本和大规模编码本之间。因此,对量化过程中带来的信息损失需要进行补偿。最终,汉明嵌入(HE)这个里程碑式的工作成为实践中的主流算法。
HE算法由Jégou等人在论文《Hamming embedding and weak geometric consistency for large scale image search》中提出,它提升了中等规模编码本下视觉词汇的区分能力,也是首次将一个SIFT描述符 从
从 维空间映射到
维空间映射到 维空间:
维空间:

式中,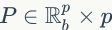 是一二个投影矩阵,
是一二个投影矩阵,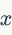 是一个低维向量。通过创建一个高斯随机矩阵同时对它使用
是一个低维向量。通过创建一个高斯随机矩阵同时对它使用 分解,矩阵
分解,矩阵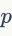 作为最后正交阵的前行,对于二值化,Jegou等人提出在每个Voronoi单元
作为最后正交阵的前行,对于二值化,Jegou等人提出在每个Voronoi单元 中使用描述符下降法来计算低维向量的中值向量
中使用描述符下降法来计算低维向量的中值向量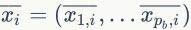 。给定描述符
。给定描述符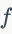 和它的投影向量,HE计算它的视觉词汇
和它的投影向量,HE计算它的视觉词汇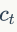 ,HE二值向量计算公式如下:
,HE二值向量计算公式如下:
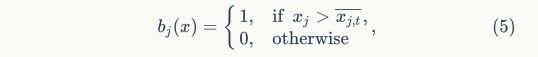
其中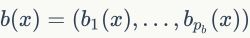 是第维的HE向量计算结果。二值特征
是第维的HE向量计算结果。二值特征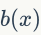 作为特征匹配的第二重校验。当满足以下两个标准时,一对局部特征可以认为是匹配的:1) 它们是同一个视觉词汇;2) 它们的HE哈希值距离很小。HE的扩展方法通过指数函数估计特征
作为特征匹配的第二重校验。当满足以下两个标准时,一对局部特征可以认为是匹配的:1) 它们是同一个视觉词汇;2) 它们的HE哈希值距离很小。HE的扩展方法通过指数函数估计特征 和
和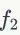 与Hamming距离的匹配强度:
与Hamming距离的匹配强度:

其中, 和分别代表特征和的二值向量,
和分别代表特征和的二值向量,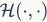 计算两个二值向量的汉明距离,
计算两个二值向量的汉明距离,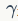 是权重参数。如图6所示,HE及其加权版本在2008和2010年准确率大大提高。
是权重参数。如图6所示,HE及其加权版本在2008和2010年准确率大大提高。
HE应用于视频拷贝检测、图像分类和重排序等场合。例如,在图像分类中,例如,在图像分类中,将HE集成到基于线性核的SVM中,有效地提高了了图像块匹配相似度的速度。在图像重排序任务中,Tolias等人使用更低的HE阈值来找到类似于RANSAC得到的(图像局部特征)严格对应关系,并且得到的图像子集更可能包含真正应查得的图像。
有很多工作都对HE提升,特别是从匹配核的角度对HE进行改进。为了减少查询上的信息损失,Jain等人提出一种矢量二值距离比较法。它利用向量到超平面距离,同时保持倒排索引的效率。更进一步地,Qin等人在概率框架内设计一个高阶匹配核函数,并通过假匹配的距离分布自适应地标准化局部特征距离。该方法的思想类似于《Accurate image search using the contextual dissimilarity measure》,其中,根据每个视觉词汇的邻域分布,将字-字距离而不是特征-特征距离归一化。虽然在《Accurate image search using the contextual dissimilarity measure》中,一个词与它的邻居之间的平均距离被规范为几乎为恒定值,但后来在《Triangulation embedding and democratic aggregation for image search》中采用了将单个嵌入向量的贡献民主化的想法。在《To aggregate or not to aggregate: Selective match kernels for image search》中,Tolias等人表明VLAD和HE向量具有相似的性质,并提出了一种新的匹配核函数,它在局部特征聚合和特征到特征匹配之间进行折衷,使用和《Query adaptive similarity for large scale object retrieval》相似的匹配函数。他们还证明了在HE中使用更多比特位(例如128bit)优于原始64比特方案,代价是效率的降低。在《Scalar quantization for large scale image search》中使用了更多的比特位(256),但是这种方法可能使得结果的召回率相对较低。
其他重要问题
特征融合
局部-局部特征融合。 SIFT特征的一个问题就是它只提供了局部梯度描述,在图像中编码的其他判别信息仍然没有被利用。在图5(B)中,由于一对错误匹配在SIFT空间中的相似性,因此这对匹配没有被HE编码拒绝,但是其他局部(或区域)特征的融合可以纠正这个问题。
将SIFT与颜色描述符耦合是局部-局部特征融合的一个好选择。颜色-SIFT描述符融合特征的使用可以部分地解决不变性和辨别能力之间的权衡问题。在几个基准识别测试集上已经对几个诸如HSV-SIFT,HueSIFT和OpponentSIFT几个融合特征进行了评估。HSV-SIFT和HueSIFT特征都属于尺度,平移不变性特征。OpponentSIFT使用SIFT描述符描述对立的颜色空间中的所有通道,并且对光照颜色变化大的图像具有很强的鲁棒性。在《Evaluating color descriptors for object and scene recognition》中认为OpponentSIFT是当有关数据没有先验知识时的优先选择。在最近的工作中,二进制颜色签名都存储在倒排索引中。尽管现有的图像检索方法在一些数据集上取得了很好的检索精度,但一个潜在不容忽视:照明的密集变化可能会有损颜色特征检索的有效性。
局部-全局特征融合。 局部特征和全局特征从不同的角度来描述图像并互为补充。在图5(C)中,但局部(以及区域)信息不足以判断出一个错误的匹配对时,进一步整合更广的上下文尺度视觉信息是有效的。前期和后期融合是两种可能的方式。在前期融合中,图像邻域关系由如AlexNet中的FC8这样的全局特征挖掘出,并融合在基于SIFT的倒排索引中。在后期融合中,Zhang等人为每种类型的特征创建一个离线图,随后在在线查询期间进行特征融合。在对《Query specific fusion for image retrieval》中的方法进行改进时,Deng等人在《Visual reranking through weakly supervised multi-graph learning》提出增加弱监督锚(weakly supervised anchors)来协助图融合。两个工作都是在排序方面进行研究。对于分数级别的融合,将自动学习的类别的特定属性与预训练的类级别信息相结合。Zheng等人在《Query-adaptive late fusion for image search and person re-identification》中提出通过提取一些特征(局部或全局特征,好的或坏的特征)进行后期特征融合的自适应查询,并且以自适应查询的方式赋给特征相应的权重
几何学上的匹配问题
BoW模型的一个常见问题是缺乏局部特征间的几何约束。几何验证可以用作各种场景的关键预处理步骤,例如拓展查询,特征选择,数据库端的特征增强,大规模咯物体挖掘等。著名的全局空间验证方法是RANSAC。RANSAC它重复计算每个对应的仿射变换,并通过适合变换的内点数来验证。RANSAC算法有效地重新排列排名最高的图像的子集,但存在效率问题。最终,如何在SIFT为基础的框架下有效、准确地结合空间信息被广泛地研究。
一个好的方法是研究局部特征间的空间上下文。例如,视觉短语在独立的视觉词汇中产生以提供更加精准的匹配规范。估计和聚合整个图像中的视觉词汇共现是一种研究思路,同时也有研究员研究视觉词汇在局部邻域中的聚类。视觉短语也可以通过临近图像块,随机空间分割和局部稳定区域(如MSER)的方式来组成。
另一种策略使用投票机制来检查几何一致性。在投票空间中,具有较大值的容器更可能代表真正的转换。其中一项重要的工作就是弱几何一致性(WGC),这种方法关注匹配特征在尺度和方向上的差异,不同空间则被量化到容器中。Hough投票方法被用来定位在规模或方向上相似或相异的子集。许多后来的研究工作可以看作是WGC的扩展。例如,Zhang等人的工作《Image retrieval with geometrypreserving visual phrases》可以被视为使用x,y偏移量而不是比例和方向的WGC方法。该方法具有目标平移不变性,但由于采用了刚体坐标量化,因此对尺度和旋转变化敏感。为了重新获得目标的尺度和旋转的不变性,Shen等人在《Object retrieval and localization with spatially-constrained similarity measure and k-nn re-ranking》中提出在应用多个变换后,量化查询区域的角度和尺度。Shen等人的这个方法的一个缺点就是,查询时间和存储效率的降低。实现高效的投票方法并减轻量化损失,论文《Hough pyramid matching: Speeded-up geometry re-ranking for large scale image retrieval》提出了霍夫金字塔匹配(HPM)方法,通过分层划分变换空间来分配匹配结果。HPM在灵活性和准确性之间取得了平衡,非常高效。还可以通过允许单个通信对多个容器进行投票来减少量化损失。HPM和这种方法都在速度上快于RANSAC算法,同时也可以被看作是对和HE一起提出的WGC在旋转和尺度不变性上的拓展。在《Pairwise geometric matching for large-scale object retrieval》中提出了一种基于投票的全局方向和尺度的粗略估计方法,以此来检验通过匹配特征得到的变形参数。《A vote-and-verify strategy for fast spatial verification in image retrieval》结合了基于假设的方法(如RANSAC)和基于投票的方法的优点,通过投票和后续的验证、精确微调来确定可能的假设。该方法保有了投票方法的效率,同时因为它的输出是显式变换和一组内值,因此还支持了查询扩展。
拓展查询
作为后处理步骤,拓展查询(QE)对提高检索的准确度很有帮助。简单地说,QE就是采用来自原始排名列表的多个排在前列的图像来发布新的查询,新的查询用于获得新的排名列表。QE可以增加额外的有区分度的特征到原始查询中,因此提高了召回率。
在实例检索任务中,Chum等人是第一个提出研究这项工作的。他们提出了平均拓展查询(AQE)方法,用排名靠前的图像的平均特征来发出新的查询。通常,空间验证用于重排序以及局部特征通过平均池化获得感兴趣区域。AQE被后来许多工作作为标准工具来使用。递归AQE和尺度-带递归QE是对AQE有效的改进,但它们的计算成本更大。四年后,Chum等从学习背景的混淆、扩展查询区域和增加空间验证的角度来改进QE。在《Three things everyone should know to improve object retrieval》中分别使用最靠前和最靠后图片作为训练正负样本。在线训练了一个线性支持向量机。学习到的权重向量用于计算平均查询。其他重要的QE算法的扩展包括基于互惠邻居思想的“hello neighbor”算法,基于排序的权重QE算法,汉明QE算法等。
小目标检索
检索图像中的一小部分对象是一项具有挑战性的任务由于1) 检测到的局部特征数量少,2) 背景噪声过大。TRECVID活动中的实例检索任务和logo检索任务都是小目标检索任务中的重要竞赛/应用。
一般来数,TRECVID任务和logo检索都可以用相似的流程来处理。对于基于关键点的检索方法,局部特征之间的空间上下文对区分目标是至关重要的,特别是对要求苛刻的小目标检索任务来说。其他有效的方法包括突发性处理,考虑查询对象和目标对象之间不同的比率。在第二种方法中,有效的可能区域或多尺度图像块可用作候选对象区域。在《Efficient diffusion on region manifolds: Recovering small objects with compact cnn representations》中,提出了一种基于邻域图的区域扩散机制,以进一步提高小对象的查全率,达到了当时最高水平。
基于CNN的图像检索系统
基于CNN的图像检索方法近年来不断被提出,并且在逐渐取代基于手工检测器和描述符的方法。在这篇综述中,基于CNN的方法被分为三类:使用预训练的CNN模型,使用微调的CNN模型以及使用混合模型。前两类方法使用单向传递网络来提取全局特征,混合模型方法可能需要多个网络传递。
使用预训练CNN模型的图像检索系统
由于预训练CNN模型是single-pass mode,因此这种方法在特征计算中非常高效。考虑到传输特性,它的成功在于特征提取和编码步骤。我们将首先描述一些常用的数据集和网络进行预训练,然后进行特征计算。
预训练的CNN模型

流行的CNN网络结构。 AlexNet,VGGNet,GoogleNet以及ResNet这几个CNN网络适用于特征提取,详见表2.简单来说,CNN网络可以视为一系列非线性函数的集合,它由如卷积,池化,非线性等多个层组成。CNN是一个分层次的结构。自网络的底层到顶层,图像经过滤波器的卷积,同时这些图像滤波器的感受野随增长而增加。同一层的滤波器尺寸相同但是参数不同。AlxNet是这些网络中最早被提出的的,它有五个卷积层和三个全连接(FC)层。它的第一层大小96个11×11×3的滤波器,在第五层中有256个大小为3×3×192的滤波器。Zeiler等人观察到滤波器对某些视觉模式十分敏感,这些模式从底层的低级的图像纹理演变到顶层的高级的图像目标。对于低层次和简单的视觉刺激,CNN滤波器类似局部手工制作的特征中的检测器,但是对于高层次和复杂的刺激,CNN滤波器具有不同于SIFT类检测器的特质。AlxNET已被证明被新的的如具有最大数量参数的VGGNet超越。ResNet和GoogleNet分别赢得了ILSVRC 2014和2015的挑战,表明CNN网络的效果和网络层数成正比。如果要调研全部这些网络超出了本文的范围,我们建议读者参阅《Imagenet classification with deep convolutional neural networks》,《Return of the devil in the details: Delving deep into convolutional nets》和《Very deep convolutional networks for large-scale image recognition》中的细节。
用于预训练模型的数据集。 一些大规模的识别数据集被用于CNN网络的预训练。在其中,ImageNet数据集常被研究员拿来使用。它包含1000个语义类的120万个图像,并且通常被认为是具有普适性的。用于预训练模型的另一个数据集是PASES-205,它的数据规模是ImageNet的两倍但图像种类却要比ImageNet少五倍。它是一个以场景为主的数据集,描绘了各种室内场景和室外场景。在《Learning deep features for scene recognition using places database》中,混合了ImageNet和PASES-205的数据集也同样会被拿来用于模型的预训练。HybridNet在《Going deeper with convolutions》,《Deep residual learning for image recognition》,《Factors of transferability for a generic convnet representation》和《A practical guide to cnns and fisher vectors for image instance retrieval》中被用于实例检索任务的评估。
迁移问题。 最近的一些工作综合评估了各种CNN网络在实例检索任务中的表现,模型迁移是大家都比较关心的一个问题。在《Factors of transferability for a generic convnet representation》中将实例检索任务认为是距离原始数据集最远的(计算机视觉)目标。首先,在模型迁移过程中,从不同层提取的特征表现出不同的检索性能。实验表明高层网络的泛化能力要低于较低层的网络。例如,在ImageNet上预训练的网络AlexNet表明,FC6、FC7和FC8在检索精度上呈递减顺序。《Particular object retrieval with integral max-pooling of cnn activations》和《Good practice in cnn feature transfer》也指出,当使用适当的编码技术时,AlexNet和VGGNet的pool5层特征甚至优于FC6层特征。其次,当原始的训练集不同时,模型的准确率也会受到影响。例如,Azizpour等人指出HybridNet在Holidays数据集上展现出的性能要劣于PCA。他们同样发现在ImageNet上预训练的AlexNet模型在包含常见物体而非建筑场景图像的Ukbench数据集上的表现要好于PlacesNet和HybridNet(译者注:AlexNet,PlacesNet和HybridNet预训练模型使用的训练集不同)。因此,当使用预训练的CNN模型时,源和目标的相似度在实例检索中起着至关重要的作用。
特征提取
FC描述符。 最直接的想法就是网络的全连接层(FC layer)提取描述符,在AlexNet中就是FC6或FC7中的描述符。FC描述符是在与输入图像卷积的层之后生成的,具有全局表示性,因此可以被视为全局特征。它在欧几里德距离下产生较好的检索精度,并且可以使用指数归一化来提高检索精度。
中间局部特征。 许多最新的检索方法专注于研究中间层的描述符。在这种方法中,低层网络的卷积核用于检测局部视觉模式。作为局部检测器,这些滤波器具有较小的感受野并密集地应用于整张图像。与全局FC特征相比,局部检测器对于诸如截断和遮挡的图像变换更鲁棒,其方式类似于局部不变量检测器。
局部描述符与这些中间局部检测器紧密耦合,换而言之,它们是输入图像对这些卷积运算的响应。另一方面,在卷积运算后等到的激活图层可以看做是特征的集成,在这篇综述中将其称为“列特征”。例如,在AlexNet中第一层有 个检测器(卷积滤波器)。这些滤波器产生了张大小为
个检测器(卷积滤波器)。这些滤波器产生了张大小为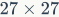 的热力图(在最大池化后)。热力图中的每个像素点具有大小为
的热力图(在最大池化后)。热力图中的每个像素点具有大小为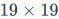 的感受野,同时记录了图像对滤波器的响应。因此列特征的大小是
的感受野,同时记录了图像对滤波器的响应。因此列特征的大小是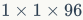 ,它可以看作是对原始图像中某个图像块的描述。该描述符的每个维度表示相应检测器的激活程度,并且在某种程度上类似于SIFT描述符。列特征最早出现在《Visual instance retrieval with deep convolutional networks》中,Razavian等人首先在分好块的特征图上进行最大池化,然后将它们连接在所有过滤器上,最终生成列特征。在《Hypercolumns for object segmentation and fine-grained localization》中,来自多层的列特征被连接形成“超列”(hypercolumn)特征。
,它可以看作是对原始图像中某个图像块的描述。该描述符的每个维度表示相应检测器的激活程度,并且在某种程度上类似于SIFT描述符。列特征最早出现在《Visual instance retrieval with deep convolutional networks》中,Razavian等人首先在分好块的特征图上进行最大池化,然后将它们连接在所有过滤器上,最终生成列特征。在《Hypercolumns for object segmentation and fine-grained localization》中,来自多层的列特征被连接形成“超列”(hypercolumn)特征。
特征编码与池化
当提取列特征时,图像由一组描述符表示。为了将这些描述符聚合为全局表示,目前采用了两种策略:编码和直接池化合并(如图2所示)。
编码。 一组列特征类似于一组SIFT特征,因此可以直接使用标准编码方案。常用的方法就是VLAD和FV算法,两个算法的简要介绍可以参加本文3.3.2节。一个里程碑式的工作发布于《Exploiting local features from deep networks for image retrieval》,文中后首次将列特征用VLAD算法编码。这个想法后来扩展为CNN的微调。BoW编码同样也可以使用,具体工作可以参见《Hybrid multi-layer deep cnn/aggregator feature for image classification》。每个层内的列特征被聚集成一个BoW向量,然后跨层连接。《Bags of local convolutional features for scalable instance search》是固定长度表示的一个例外,这篇文章将列特征用大小为25K的码本量化,还采用了倒排索引结构来提升效率。
池化。 CNN特征与SIFT的主要区别在于前者在每个维度上都有明确的含义,也就是对输入图像的特定区域的滤波器响应。因此,除了上面提到的编码方案之外,直接池化技术也可以产生具有区分度的特征。
这方面的一项里程碑工作包括Tolias等人提出的最大卷积激活(MAC)。在没有扭曲或裁剪图像的情况下,MAC用单个前向传递来计算全局描述符。特别地,MAC计算每个中间特征映射的最大值,并将所有这些值串联在一个卷积层内。在其多区域版本中,使用积分图算法和最似最大算子进行快速计算。随后局部的MAC描述符随着一系列归一化和PCA白化操作被一起合并。我们在本次调研中也注意到了其他一些工作同样也采用了相似的思想,在中间特征映射上采用最大或平均池化,其中Razavian等人的《Visual instance retrieval with deep convolutional networks》是打开先河的工作。同时大家也发现最后一层卷积层(如VGGNet的pool5)在池化后达到的准确率要高于FC描述符以及其他卷积层。
除了直接特征池化,在池化之前给每个层内的特征图分配一些特定的权重也是有益的。在《Aggregating local deep features for image retrieval》中,Babenko等人提出“目标对象往往出现在图像中心”这样一个先验知识,并在总池化前对特征图施加一个2-D高斯掩膜。Xie等人在《Interactive: Inter-layer activeness propagation》中改进了MAC表示法,他们将高层语义和空间上下文传播到底层神经元,以提高这些底层激活神经元的描述能力。Kalantidis等人使用了一个更常规的加权策略,他们同时执行特征映射和信道加权以突出高激活的空间响应,同时减少异常突发情况的影响。
使用微调CNN模型的图像检索系统
虽然预先训练的CNN模型已经取得了令人惊叹的检索性能,但在指定训练集上对CNN模型进行微调也是一个热门话题。当采用微调的CNN模型时,图像级的描述符通常以端到端的方式生成,那么网络将产生最终的视觉表示,而不需要额外的显式编码或合并步骤。
用于微调网络的数据集
微调网络时使用的数据集对学习高区分度的CNN特征具有至关重要的作用。ImageNet仅提供了图像的类别标签,因此预训练的CNN模型可以对图像的类别进行分类,但却难以区分同一类的图像。因此要面向任务数据集进行CNN模型微调。
近年来用于微调网络方法数据集统计在表3中。数据集主要集中于建筑物和普通物体中。微调网络方向一个里程碑式的工作是《Neural codes for image retrieva》。这篇文章通过一个半自动化的方法收集地标数据集:在Yandex搜索引擎中自动地爬取流行的地标,然后手动估计排名靠前的相关图像的比例。该数据集包含672类不同的地标建筑,微调网络在相关的地标数据集,如Oxford5k和假日数据集上表现优异,但是在Ukbench数据集(包含有普通物体)上性能降低了。Babenko等人也在含有300个多角度拍摄的日常物品图像的多视图RGB-D数据集上对CNN模型进行了精细调整,以提高在Ukbench数据集上的性能。地标数据集后来被Gordo等人使用,他们使用基于SIFT匹配的自动清洗方法后再微调网络。在《Cnn image retrieval learns from bow: Unsupervised fine-tuning with hard examples》中,Radenovi等人利用检索和运动结构的方法来构建三维地标模型,以便将描述相同建筑的图像进行分组。使用这个标记的数据集,线性判别投影方法(在表5中表示为 )优于先前的白化方法。另一个名为 Tokyo Time Machine的数据集使用谷歌街景时间机器工具来收集图像,谷歌提供的这个工具可以提供同一地点不同时间的图像。上述的大部分数据集主要关注了地标图像,而Bell等人则建立了一个由家具组成的产品数据集,通过开发众包流程来绘制现场的目标和相应产品之间的连接。对所得到的查询集进行微调也是可行的,但是这种方法可能不适合于新的查询类型。
)优于先前的白化方法。另一个名为 Tokyo Time Machine的数据集使用谷歌街景时间机器工具来收集图像,谷歌提供的这个工具可以提供同一地点不同时间的图像。上述的大部分数据集主要关注了地标图像,而Bell等人则建立了一个由家具组成的产品数据集,通过开发众包流程来绘制现场的目标和相应产品之间的连接。对所得到的查询集进行微调也是可行的,但是这种方法可能不适合于新的查询类型。
微调的网络
用于微调的CNN结构主要分为两类:基于分类的网络和基于验证的网络。基于分类的网络被训练以将建筑分类为预定义的类别。由于训练集和查询图像之间通常不存在类重叠,因此在AlexNet中如FC6或FC7的学习到的嵌入特征用于基于欧氏距离的检索。该训练/测试策略采用在方框中,其中最后的FC层被修改为具有对应于地标数据集中类的数目的672个节点。在《Neural codes for image retrieval》中采用训练/测试策略,其网络最后的FC层被修改为672个节点,对应于地标数据集中类别数目。
验证网络可以使用孪生网络(siamese network)结合成对损失函数(pairwise loss)或三元损失函数(triplet loss),这种方法已经被更广泛地用于微调网络任务中。在《Learning visual similarity for product design with convolutional neural networks》中采用了基于AlexNet的孪生网络和对比损失函数。在《Cnn image retrieval learns from bow: Unsupervised fine-tuning with hard examples》中Radenovi´c等人提出用MAC成代替全连接层。更进一步地,可以通过建立的3维建筑模型挖掘训练对。基于共同观测的3D点云(匹配的SIFT特征)的数目来选择正例图像对,而CNN描述符中距离较小的那些图像对被认为是负例样本。这些图像输入到孪生网络中,并且用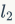 正则后的MAC层输出计算对比损失函数。与《Cnn image retrieval learns from bow: Unsupervised fine-tuning with hard examples》同时进行的一项工作是《Deep image retrieval: Learning global representations for image search》,Gordo等人在Landmark数据库上对三元损失网络和区域提取网络进行微调。《Deep image retrieval: Learning global representations for image search》这项工作的的优越性在于物体其定位能力,它很好地在特征学习和提取步骤中排除了图像背景。在这两项工作中,微调模型在landmark,OxFoD5K、PARIS6K和Holidays数据集上表现出了最先进的精度,以及在UKBayes数据集上表现出良好的泛化能力(将表5)。在《Netvlad: Cnn architecture for weakly supervised place recognition》中,在最后一个卷积层中插入一个类似VLAD编码层,通过反向传播进行训练。与此同时,设计了一个新的三元损失函数来利用弱监督的Google Street View Time Machine数据。
正则后的MAC层输出计算对比损失函数。与《Cnn image retrieval learns from bow: Unsupervised fine-tuning with hard examples》同时进行的一项工作是《Deep image retrieval: Learning global representations for image search》,Gordo等人在Landmark数据库上对三元损失网络和区域提取网络进行微调。《Deep image retrieval: Learning global representations for image search》这项工作的的优越性在于物体其定位能力,它很好地在特征学习和提取步骤中排除了图像背景。在这两项工作中,微调模型在landmark,OxFoD5K、PARIS6K和Holidays数据集上表现出了最先进的精度,以及在UKBayes数据集上表现出良好的泛化能力(将表5)。在《Netvlad: Cnn architecture for weakly supervised place recognition》中,在最后一个卷积层中插入一个类似VLAD编码层,通过反向传播进行训练。与此同时,设计了一个新的三元损失函数来利用弱监督的Google Street View Time Machine数据。
基于CNN模型的混合式方法
混合式方法中使用多网络传递方式。许多图像块从输入图像中获得并被输入网络中进行特征提取,随后进行编码/池化。由于“检测器+描述符”的方式和基于SIFT的方法很相似,因此我们称其为“混合式”方法。这种方法的效率通常比单通传递要低。
特征提取
在混合方法中,特征提取过程包括图像块检测和描述符生成。对第一步而言,主要有三种区域检测器。第一种检测器是网格化图像块。例如,在《Multi-scale orderless pooling of deep convolutional activation features》中使用了两个尺寸滑动窗口的策略来生成图像块。在《Cnn features off-the-shelf: an astounding baseline for recognition》中首先对数据集进行裁剪和旋转,然后将其划分为不同尺度的图像块。第二类是具有不变性的关键点/区域检测器。例如高斯差分特征点在《Learning to compare image patches via convolutional neural networks》中使用。MSER区域检测器在《Descriptor matching with convolutional neural networks: a comparison to sift》中被使用。第三种是区域建议方法,它也同样提供了潜在对象可能的位置信息。Mopuri等人使用选择性搜索策略来提取图像块,而边缘区域方法在《Fisher encoded convolutional bag-of-windows for efficient image retrieval and social image tagging》中使用。在《Faster r-cnn features for instance search》中使用区域建议网络(RPN)来对目标进行定位。
《Descriptor matching with convolutional neural networks: a comparison to sift》证实了CNN一类的区域描述是有效的,并且在出模糊图像之外的图像匹配任务繁重要优于SIFT描述符。对于给定的图像块,混合CNN方法通常使用全连接层或池化的方法来整合CNN特征,相关文献对此均有研究。这些研究从多尺度的图像区域中提取4096维FC特征或目标建议区域。另一方面,Razavian等人还在最大池化后采用中间描述符来作为区域描述符。
上述方法采用预训练模型进行图像块特征提取。以手工检测器为基础,图像块描述符也可以通过有监督或无监督方式进行CNN训练学习,这相对于之前关于SIFT描述符学习的工作有所改进。Yi等人进一步提出了一种在单个流程中集成了区域检测器、方向估计和特征描述符结果的端到端学习方法。
特征编码与索引
混合方法的编码/索引过程类似于基于SIFT的检索,如同在小码本下的VLAD / FV编码或大码本下的倒排索引。
VLAD/FV编码过程紧随SIFT特征提取后,在上文已经详细描述过这样的流程,不再赘述。另一方面,有一些工作研究探索了图像块的CNN特征的倒排索引。同样,在SIFT方法流程中诸如HE之类的编码方法也被使用。除了上述提到的编码策略,我们注意到《Cnn features off-the-shelf: an astounding baseline for recognition》,《Visual instance retrieval with deep convolutional networks》,《Image classification and retrieval are one》这些工作提取每个图像的多个区域描述符进行多对多匹配,这种方法称为称为“空间搜索”。该方法提高了检索系统对平移和尺度变化的鲁棒性,但可能会遇到效率问题。另一种使用CNN最高层特征编码的策略是在基于SIFT编码(如FV)的最后面建立一个CNN结构(主要由全连接层组成)。通过在自然图像上训练一个分类模型,中间的全连接层可以被用来进行检索任务。
讨论
基于SIFT和CNN的方法间的关系
在本篇综述中,我们将现有的文献分为六个精细的类,表1和表5总结了六个类别的差异和代表性作品。我们的观察结果如下。
第一,混合方法可被视为从SIFT-到基于CNN的方法的过渡方法,除了将CNN特征提取为局部描述符之外,它在所有方面都类似于基于SIFT的方法。由于在图像块特征提取期间需要多次访问网络,因此特征提取步骤的效率可能会受到影响。
第二,单向CNN方法倾向于将SIFT和混合方法中的各个步骤结合起来。在表5中,“预训练单向网络”一类方法整合了特征检测和描述步骤;在“微调单向网络”中,图像级描述符通常是在端到端模式下提取的,因此不需要单独的编码过程。在《Deep image retrieval: Learning global representations for image search》中,集成了类似“PCA”层以减少区分维数,进一步完善了端到端的特征学习。
第三,出于效率上的考虑,特征编码的固定长度表示方法越来越流行。它可以通过聚集局部描述符(SIFT或CNN)、直接汇或端到端特征计算的方法来获得。通常,诸如PCA的降维方法可以在固定长度的特征表达中使用,ANN搜索方法(如PQ或哈希)可用于快速检索。
哈希与实例检索
哈希方法是最似最近邻问题的主流解决方案。它可以被分类类为局部敏感哈希(LSH)算法和哈希学习方法。LSH是数据无关的且常通过学习哈希来获得更优异的性能。对于学习哈希方法,最近的一项调研《A survey on learning to hash》将其归类为量化和成对相似性保留这两类。我们在3.3.2节已经详细讨论过量化方法热,不再赘述。成对相似性保留方法包括一些常用的手工设计哈希方法,如谱哈希,LDA哈希等。
近年来随着深度网络的发展,哈希方法也从手工设计的方式转变到受监督的训练方式。这些方法将原始图像作为输入,并在二值化之前生成学习的特征。然而,这些方法大多集中于图像分类式的检索任务,与本次调研所中讨论的实例图像检索不同。实例检索任务中,当可以收集到足够的训练数据时(例如建筑和行人和数据)时,深度散列方法可能是至关重要的。
5 实验比较
5.1 图像检索数据集
在本次调研中使用了五个流行的实例检索数据集,这些数据集的统计数据如表4所示。
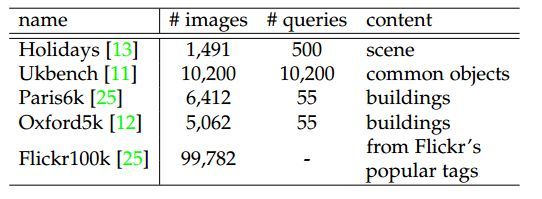
表4:流行的实例检索数据集统计
Holidays数据集由Jégou等人从个人假日相册中收集,因此图像包含各种各样的场景。该数据库由500组1,491幅相似图像组成,每组图像有一条查询记录,共计500条。除了《Efficient representation of local geometry for large scale object retrieval》和《Learning a fine vocabulary》,大多数基于SIFT的方法手动地将图像旋转成直立方向。最近许多基于CNN的方法也使用了旋转版的Holidays数据集。在表5中这两个版本数据集上的结果用”/“间隔,旋转图像可以带来2%-3%的mAP值。
Ukbench数据集包括10,200种不同内容的图像,如物体、场景和CD封面。所有图像被分为2,550组,每个组有四个图像描述相同的物体/场景,在不同的角度,照明,形变,等情况下的表现。该数据集中的每个图像依次作为查询记录,因此有10,200条查询记录。
Oxford5k数据集用牛津11个地标名从Flickr网站爬取共计5062幅图像组建数据集。该数据集通过手绘边界框为每个地标的定义五个查询记录,从而总共存在55个感兴趣区域(ROI)查询记录。每个数据库图像被分配了好的,还可以的,垃圾的,或坏的四个标签之一。前两个标签表示与查询的感兴趣区域是匹配的,而“坏”表示不匹配。在糟糕的图像中,只有不到25%的对象是可见的,或者它们遭受严重的遮挡或变形,因此这些图像对检索精度影响不大。
Flickr100k数据集包括99,782张来Flickr网站145个最流行标签的高清图像。在文献中,通常将该数据集添加到Oxford5k中,以测试检索算法的可扩展性。
Paros6k数据集从11指定的巴黎建筑查询中爬出6,412中图像。每个地标有五个查询记录,因此这个数据集同样有55个带有边界框的查询记录。数据库图像使用和Oxford5k一样的四种类型的标签作为Oxford5k数据集标签。针对Oxford5k和Paris6k数据集有两个评估准则。对于基于SIFT的方法,被裁剪的区域通常用于查询。对于基于CNN的方法,有些工作采用的是全尺寸图像,有些工作采用的是将裁剪的ROI传入CNN或者用CNN提取全图特征后再裁剪得到ROI。使用完整的图像的方法可以提高mAP指标。详细的指标可以参见表5。

表5:一些有代表性的图像检索方法在六个数据集上的表现
5.2 评价指标
精准度-召回率。召回指的是返回的正确匹配数占数据库中总数或正确匹配数的比率,而精准度是指返回结果中真实匹配的那部分图像。给定一个集合含有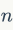 张返回的图像,假设其中有
张返回的图像,假设其中有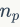 张正确匹配的图像,而整个数据集中有
张正确匹配的图像,而整个数据集中有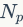 张正确匹配的图像,那么召回率
张正确匹配的图像,那么召回率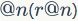 和精准度
和精准度 分别计算为
分别计算为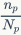 和
和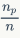 。在图像检索中,给定一张待查询图像和返回列表,可以根据
。在图像检索中,给定一张待查询图像和返回列表,可以根据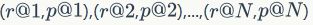 这些点绘制精准度-召回率曲线,其中是数据库中的图像数目。
这些点绘制精准度-召回率曲线,其中是数据库中的图像数目。
平均准确率和平均精度。 为了更加清晰地记录图像检索系统的性能,我们使用平均准确率(average precision)对其进行衡量,它相当于精准度-召回率曲线下的面积。通常,较大的AP值意味着更高的精准度-召回率曲线,亦即更好的检索性能。由于图像检索数据集通常具有多个查询图像,所以对它们各自的AP值进行平均,以产生最终的性能评价,即平均精度(mean average precision, mAP)。传统地,我们使用mAP来评估检索系统在Oxford5k、Paris6k和Holidays数据集上的准确度。
N-S得分。 N-S得分专用于Ukbench数据集,它是以David Nistér 和Henrik Stewénius的名字来命名的。N-S得分其实等价于精准度或者召回率,因为在Ukbench数据集中的每个查询在数据库中都有四个正确的匹配项。N-S得分用总排名列表中前四中的真实匹配的平均数量来计算。

图6:多年来在Holidays(a), Ukbench(b), Oxford5k(c)数据集上的最优表现
5.3 比较与分析
5.3.1 多年来性能的改进
我们在图6中展示了过去十年图像检索精度的改善以及在表5中展示了一些有代表性的方法。实验结果通过在独立的数据集上建立的编码本来计算。我们可以清楚地看到,实例检索的领域一直在不断改进。10多年前提出的基线方法(HKM)在Holidays, Ukbench, Oxford5k, Oxford5k+Flickr100k以及Paris6k数据集上的准确率分别仅为59.7%, 2.85, 44.3%, 26.6%以及46.5%。从基线方法开始,通过引入高区分度编码本、空间约束和互补描述符,大规模编码本方法开始稳定地提升。对于中型编码本方法来说,随着Hamming嵌入及其改进的方法,在2008年至2010年间它见证了最显著的精度提升。从那时起,主要的改进来自特征融合的强度,特别是使用在Holiday和Ukbench数据集上提取的的颜色和CNN特征。
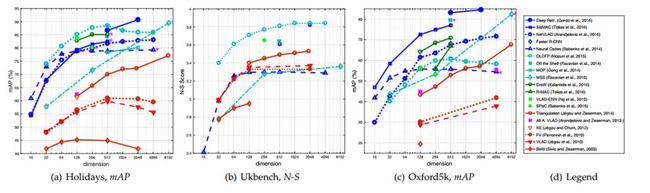
图7:特征维度对图像检索系统准确率的影响
 表6:不同类别方法间的效率和准确度的比较
表6:不同类别方法间的效率和准确度的比较
另一方面,基于CNN的检索模型在图像例检索中迅速显示出其优势。在2012年AlexNet刚提出时,当时的FC特征的性能与SIFT模型相比仍然远不能令人满意。例如,在ImageNet上预训练的AlexNet,其FC描述符在Holidays,Ukbench和Oxford5k数据集上的AP,N-S得分和mAP上的得分分别为 64.2%,3.42,43.3%。这些指标是要比《Contextual weighting for vocabulary tree based image retrieval》在Holidays和Ukbench数据集上的成绩低13.85%和0.14,比《Object retrieval and localization with spatially-constrained similarity measure and k-nn re-ranking》在Oxford5k上的成绩低31.9%。然而,然而,CNN网络结构和微调策略的进步,基于CNN的方法的性能迅速提高,在Holidays和Ukbench数据集上极具竞争力,并且在Oxford5k数据集上的指标略低,但它具的内存消耗更小。
5.3.2 准确率比较
不同数据集上不同类别的检索精度可以在图6,表5和表6中查看。从这些结果中,我们有三个发现。
第一,在基于SIFT的方法中,中等规模编码本对的表现要优于小规模编码本。一方面,由于大的沃罗诺伊方格,中等规模编码本的视觉词汇可以使相关匹配的召回率变高。HE方法的进一步集成在很大程度上提高了模型区分度,实现了匹配图像召回率和精度之间较好的平衡。另一方面,虽然小规模编码本中的视觉词具有最高的匹配召回率,但由于聚合过程和维度小,它们的图像区分能力没有显著提高。因此它的表现可以认为是不佳的。
第二,在基于CNN的方法中,微调的模型在特定任务(如地标/场景检索)中的表现要有很大优势,这些任务的数据一般和训练集数据分布相似。虽然这一观察是在预期之内,有趣的是我们发现在《Deep image retrieval: Learning global representations for image search》中提出的微调模型在通用检索(例如Ukbench数据集)上的表现极具竞争力,而它与训练集的数据分布并不同。事实上,Babenko等人在《Neural codes for image retrieval》中表明,在Landmarks数据集上进行微调的CNN特征会降低在Ukbench上的的准确率。《Deep image retrieval: Learning global representations for image search》这项工作的泛化能力可以归因于对区域提取网络的有效训练。相比之下,使用预先训练模型可以在Ukbench上表现出较高的精度,但在landmarks数据集上的表现中等。相似地,混合方法在所有的任务中的表现都相当,但它仍然可能遇到效率问题时。
第三,比较这六中方法,“CNN微调模型”和“SIFT中等编码本”方法具有最好的总体准确度,而“SIFT小编码本”类别具有相对较低的准确度。
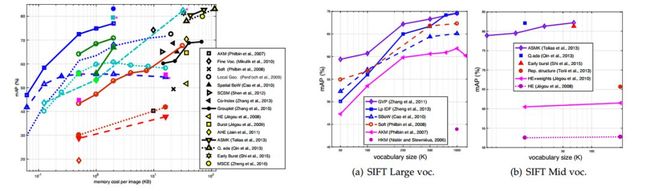
图8:在 Oxford5k数据集上的存储代价和检索准确率
5.3.3 效率比较
特征计算时间。 在基于SIFT的方法中,主要的步骤就是局部特征的提取。通常情况下,根据图像的复杂度(纹理),CPU提取640×480大小图像的基于Hessian仿射区域的SIFT描述符需要1-2s。对于基于CNN的方法,在TitanX卡上通过VGG16网络对一个224×224和1024×768的图像进行单向传递分别需要0.082s和0.34 7s。据报道,四幅图像(最大边724像素)可以在1s内处理。预训练列特征的编码(VLAD或FV)的时间非常快。对于CNN混合方法,提取几十个区域的CNN特征可能需要几秒钟。总体而言,CNN预训练模型和微调模型在用GPU进行特征计算时的效率高。同样应该注意的是,当使用GPU进行SIFT提取时,也可以实现高效率。
检索时间。 最似最近邻搜索算法用于“SIFT大编码本”,“SIFT小编码本”,“CNN预训练模型”和“CNN微调模型”时都是相当高效的,这是因为倒排列表对于适当训练的大码本来说是简短的,并且因为后者三有一个紧凑的表示,用像PQ这样的ANN搜索方法来加速是可行的。中等规模编码本的效率较低,因为它的倒排索引与大码本相比包含更多的条目,并且汉明嵌入方法的过滤效果只能在一定程度上修正这个问题。如4.3节所述,混合方法的检索复杂度会因为多对多匹配策略的影响而变得低效率。
训练时间。 用AKM或HKM训练大型或中型编码本通常需要几个小时,使用小型编码本可以缩短训练时间。对于微调模型,Gordo等人在一块K40 GPU上花费了5天训练三元损失模型。可能在孪生网络或者分类模型上这会花费更少的时间,但是要比生成SIFT编码本的时间长得多。因此,在训练方面,使用直接池或小码本的效率更高。
存储代价。 表5和图8表明具有大码本的SIFT方法和紧凑方法在存储成本上都是高效的。还可以使用PQ或其他有效的量化/散列方法将紧凑表示压缩成紧凑编码,从而可以进一步减少它们的存储消耗。相比之下,使用中等码本的方法是最消耗内存的,因为二进制签名应该存储在倒排索引中。混合方法总要有混合存储成本,因为多对多策略需要存储每个图像的多个区域描述符,而其他一些方法则采用高效的编码方法。
空间验证与查询拓展。 空间验证通常和QE算法一起使用,可以使得检索结果排列表更加精准。RANSAC验证在《Object retrieval with large vocabularies and fast spatial matching》中提出,它的复杂度为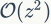 ,其中
,其中 是匹配的特征数目,可以看出算法的复杂度较高。ADV方法的复杂度相对较小,为
是匹配的特征数目,可以看出算法的复杂度较高。ADV方法的复杂度相对较小,为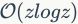 ,因为它能够避免不相关的Hough选票。《Hough pyramid matching: Speeded-up geometry re-ranking for large scale image retrieval》和《A vote-and-verify strategy for fast spatial verification in image retrieval》提出的方法最有效,复杂度仅为
,因为它能够避免不相关的Hough选票。《Hough pyramid matching: Speeded-up geometry re-ranking for large scale image retrieval》和《A vote-and-verify strategy for fast spatial verification in image retrieval》提出的方法最有效,复杂度仅为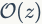 ,同时后一项工作进一步地输出QE的变换和内值。
,同时后一项工作进一步地输出QE的变换和内值。
从查询扩展的角度来看,由于提出了新的查询,搜索效率会受到影响。例如,由于新查询,AQE的搜索时间几乎增加了一倍。对于递归AQE和带尺度递归QE方法,搜索时间更加长了,因为要执行好几个新的搜索。其他QE变体所提出的改进只比执行另一搜索增加了边际成本,因此它们的复杂性类似于QE方法。
5.3.4 重要的参数
我们总结编码本大小对使用SIFT特征的大/中型码本的影响,以及维数对包括SIFT小编码本和基于CNN方法的紧凑表示的影响。
编码本规模。 图8展示了模型在Oxford5k上的mAP结果,对大规模编码本和中规模编码本的方法进行对比。有两点值得注意。第一,mAP值通常随着编码本增大而增加,但当码本足够大时aMP值可能达到饱和。这是因为更大的码本提高了匹配精度,但是如果它太大,匹配的召回率变低,导致性能饱和甚至损害性能。第二,当编码本规模变化时,使用中等规模编码本的方法表现更稳定。这可以归因于HE方法,它对更小的码本贡献更多,弥补了较低的基线方法的性能。
维数。 维数对紧凑向量的影响在图7中给出。我们的发现检索精度通常在较大的尺寸下较为稳定,而当维数低于256或128时精度迅速下降。我们第二个发现是关于区域提取的。这些方法在各种特征长度下都表现出非常出色的性能,这可能是由于它们在目标定位方面的优越能力。
5.3.5 讨论
我们简要地讨论何时使用CNN或SIFT以及其他相关方法。上文对两者特征进行了详细的比较。
一方面,表示向量长度固定的CNN方法几乎在所有的基准数据集上的性能都占有优势。具体而言,在两种情况下基于CNN的方法可以考虑优先使用。第一种是对于特定对象的检索(例如建筑物、行人),当提供的训练数据足够时,可以充分利用CNN网络嵌入学习的能力。第二种,对于常见的对象检索或类检索,预训练的CNN模型是有竞争力的。
另一方面,尽管基于CNN方法的通常是具有优势的,我们仍认为SIFT特征在某些情况下仍然具有优势。例如,当查询或一些目标图像是灰度图像时,CNN可能不如SIFT有效,因为SIFT是在灰度图像上计算而不诉诸于颜色信息。当物体颜色变化非常剧烈时也同样如此。另外,在小对象检索中或当查询对象被严重遮挡时,使用诸如SIFT之类的局部特征是更好的选择。在书籍/CD封面检索等应用中,由于丰富的纹理,我们也可以期待SIFT的良好性能。
6 未来的研究方向
6.1 面向通用任务的实例检索
图像检索一个非常重要的方向就是使用搜索引擎实现通用检索。为了实现这个目标需要解决两个重要问题。
第一,需要引入大规模图像数据集。虽然如表3所示展示了多个图像数据集,但这些数据集通常包含特定类型的实例,例如地标或室内物品。虽然Gordo等人在《Deep image retrieval: Learning global representations for image search》中使用的RPN结构除了在构建数据集之外,还在在Ukbench数据集上表现得富有竞争力,但如果在更通用的数据集上训练CNN能否带来进一步的改进,则仍然是未知数。因此,社区迫切需要大规模的图像数据集或一种可以以监督或非监督的方式生成这样一个数据集的有效方法。
第二,设计新的CNN网络和学习策略对于充分利用训练数据具有重要意义。先前有工作采用标准分类模型,成对损失或三重损失模型对CNN网络进行微调。Faster R-CNN在实例检索中的引入对更精确的对象定位来说是一个良好的开始。此外,在另一个检索任务中采用微调模型时,迁移学习方法也是非常重要。
6.2 面向专用任务的实例检索
另一方面,在专用实例检索中的研究也越来越多。例如地点检索,行人检索,车辆检索,标志检索等。在这些任务中的图像具有特定的先验知识。例如在行人检索任务中,循环神经网络(RNN)可以连接身体部分的描述符,在车辆检索任务中,在特征学习期间可以推断视图信息,同时牌照图像也可以提供关键信息。
同时,训练数据的收集过程可以进一步研究。例如,可以通过谷歌街景收集不同地点的训练图像。车辆图像可以通过监视视频或互联网图像来获取。在这些特定的数据集上探索新的学习策略以及研究迁移学习的效果将是有趣的。最后,紧凑向量编码或短编码也将在现实的检索任务设置中变得重要。
7 结语
本篇综述回顾了基于SIFT和CNN特征的实例检索方法。根据编码本的规模,我们将基于SIFT的方法分为三类:使用大,中,小规模的编码本。基于CNN的方法也被分为了三类:使用预训练模型,微调模型和混合模型的方法。在每个类别下都对先前的方法进行了全面的调研。从各种方法的演变可以看出,混合方法处于SIFT和CNN方法的过渡位置,紧凑编码方法越来越流行,并且实例检索正朝着端到端的特征学习和提取的方向发展。
通过在几个基准数据集上收集的实验结果,对六种方法进行了比较。我们发现CNN微调模型策略在不同的检索任务上都得到了较高准确率,并且在效率上也具有优势。未来的研究可能集中于学习更通用的特征表示或更特定场景的检索任务。