基于RPC Call延时返回的HDFS异步editlog原理
文章目录
- 前言
- 现有HDFS的RPC正常请求处理
- 基于RPC Call延时返回的异步editlog机制
- 相关链接
前言
前面文章笔者介绍过Hadoop社区为了增加内部RPC的throughput,通过延时返回response的调整来提早释放Server端的Handler资源,以此尽可能的把Handler的处理能力用在真正的RPC请求上。HDFS目前所使用的异步editlog机制正是使用了这个优化改进。这里所说的HDFS异步editlog写出并不是大家所简单的认为NameNode完全异步化写出editlog到其JournalNode服务中,然后直接返回结果给client。那么但异步写出editlog失败的时候,client怎么能知道后面发生的结果呢?它只能接受之前收到的“预期”结果进行后续的操作了。因此我们说延时返回在这个场景就能发挥其强大的作用了。本文笔者来详细聊聊这个延时返回机制如何在HDFS的异步editlog中发挥作用的。
现有HDFS的RPC正常请求处理
在讲述HDFS异步editlog机制之前,我们先来看看正常HDFS RPC请求处理的过程:
- 1)Client端发起请求操作。
- 2)NameNode收到请求,然后执行对应RPC call请求方法的处理,以及操作处理成功情况下,需要额外写出对应操作的editlog信息。
- 3)NameNode请求执行结束,在方法末尾操作执行logSync操作,写出此操作对应的editlog到JournalNode中,至此一个完整的RPC调用操作结束。
- 4)NameNode返回结果回复给Client。
简单图示过程如下:

以下是一个NameNode里面的样例RPC call请求处理方法:
boolean setReplication(final String src, final short replication)
throws IOException {
final String operationName = "setReplication";
boolean success = false;
checkOperation(OperationCategory.WRITE);
final FSPermissionChecker pc = getPermissionChecker();
FSPermissionChecker.setOperationType(operationName);
try {
writeLock();
// 1)执行设置副本具体操作
try {
checkOperation(OperationCategory.WRITE);
checkNameNodeSafeMode("Cannot set replication for " + src);
success = FSDirAttrOp.setReplication(dir, pc, blockManager, src,
replication);
} finally {
writeUnlock(operationName, getLockReportInfoSupplier(src));
}
} catch (AccessControlException e) {
logAuditEvent(false, operationName, src);
throw e;
}
if (success) {
// 3)如果执行成功,执行logSync操作,写出editlog到JN中
getEditLog().logSync();
logAuditEvent(true, operationName, src);
}
return success;
}
上面的内部setReplication方法:
static boolean setReplication(
FSDirectory fsd, FSPermissionChecker pc, BlockManager bm, String src,
final short replication) throws IOException {
bm.verifyReplication(src, replication, null);
final boolean isFile;
fsd.writeLock();
try {
final INodesInPath iip = fsd.resolvePath(pc, src, DirOp.WRITE);
if (fsd.isPermissionEnabled()) {
fsd.checkPathAccess(pc, iip, FsAction.WRITE);
}
final BlockInfo[] blocks = unprotectedSetReplication(fsd, iip,
replication);
isFile = blocks != null;
if (isFile) {
// 2)执行到此处,setReplication操作成功,写出setReplication对应的editlog信息
fsd.getEditLog().logSetReplication(iip.getPath(), replication);
}
} finally {
fsd.writeUnlock();
}
return isFile;
}
基于RPC Call延时返回的异步editlog机制
了解完上述同步方式写editlog的RPC Call调用后,下面我们再来看看异步editlog它是怎么做的呢?
首先异步editlog要保证一个大的原则前提
Client收到的请求处理结果必须还是可靠的。
这里要解决的真正难题在于我们既想让editlog能够被异步写出,另外一方面Client调用线程的返回结果又得依赖于editlog的写出完成,后者其实是依赖于前面的执行结果的。所以这里我们的editlog的异步写出并不是完全意义上的异步化。
异步editlog的核心改进在于它把logSync这种editlog同步写出的比较重的操作从RPC Call处理方法中挪出去了,由另外一个线程做editlog的写出操作了。取而代之的是,logSync就做一个简单的editlog的进queue操作。这样的话,NameNode server端的Handler马上能take over处理别的请求了。随后等待消费editlog的真正被写出好后,同步editlog的线程再触发返回client response的操作,这个时候client才会收到请求处理的结果了。在这个过程中,我们还是保证了只要editlog写出成功才返回这样一个大的前提的。
简单来说,对于server端内部来说,它的editlog写出是异步执行,但对于client side而言,它的结果还是需要等待editlog的完成的。
这个过程的简单图示如下所示:
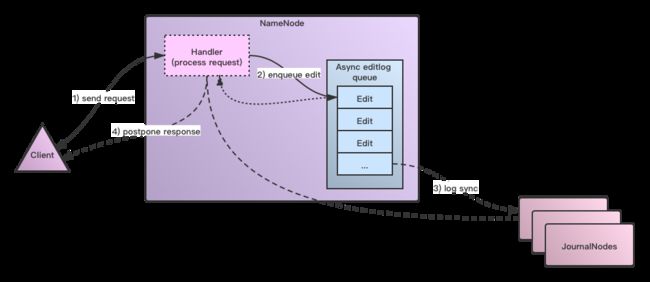
上图显示了2段虚线,第一段小的虚线指的是Handler线程处理执行logSync方法后,将待写出的editlog加入pending editlog queue后,Handler就算处理请求完成了,随后它可以继续处理别的请求。第二段大虚线指当editlog写出线程真正执行完logSync后,才触发response的返回。
因此从这里我们可以看到,RPC Call的延时返回策略起到的作用方式主要如下:
- 拆分原RPC Call操作中潜在的比较固定的而且可能比较重的操作到另外一个线程中处理,以此确保Handler线程能够快速地执行完主要操作方法,以此增大Server的请求throughput。
- 对于异步线程执行前面拆分出来的操作,通过延时返回结果的方式让client等待对于请求操作的执行完成,以此确保数据处理的准确性。
关于延时返回的改动,感兴趣的同学参考社区JIRA:HADOOP-10300:Allowed deferred sending of call responses。当然本文所阐述的异步editlog只是使用延时回复机制的一个使用的场景case,我们还可以有其它类似的适用场景。
相关链接
[1].https://issues.apache.org/jira/browse/HADOOP-10300
[2].https://blog.csdn.net/Androidlushangderen/article/details/106316751