支持向量机 Support vecor machine,SVM)本身是一个二元分类算法,是对感知器算法模型的一种扩展,现在的SVM算法支持线性分类和非线性分类的分类应用,并且也能够直接将SVM应用于回归应用中,同时通过OvR或者OVO的方式我们也可以将SWM应用在多元分类领域中。在不考虑集成学习算法,不考虑特定的数据集的时候,在分类算法中SVM可以说是特别优秀的。
算法思想
在感知器模型中,算法是在数据中找出一个划分超平面,让尽可能多的数据分布在这个平面的两侧,从而达到分类的效果,但是在实际数据中这个符合我们要求的超平面是可能存在多个的。如下图所示:

在感知器模型中,我们可以找到多个可以分类的超平面讲数据分开,并且优化时希望所有的点都离超平面尽可能的远,但是实际上离超平面足够远的点基本上都是被正确分类的,所以这个是没有意义的;反而比较关心那些离超平面很近的点,这些点比较容易分错。所以说我们只要让离超平面比较近的点尽可能的远离这个超平面,那么我们的模型分类效果应该就会比较不错喽。SⅥM其实就是这个思想。
举个例子简单介绍一下svm算法的几个基本概念,参考知乎作者简之的回答。他通过简单明了的故事讲述了各个概念的生动比喻,这里就不在这里累述了,有兴趣的可以参照网址:https://www.zhihu.com/question/21094489。
线性可分(Linearly Separable):在数据集中,如果可以找出一个超平面,将两组数据分开,那么这个数据集叫做线性可分数据。
线性不可分( Linear Inseparable):在数据集中,没法找出一个超平面,能够将两组数据分开,那么这个数据集就叫做线性不可分数据。
分割超平面( Separating Hyperplane):将数据集分割开来的直线/平面叫做分割超平面。
间隔( Margin):数据点到分割超平面的距离称为间隔。
支持向量( Support Vector):离分割超平面最近的那些点叫做支持向量。如下如:分别用红蓝标记的点就为支持向量点。

线性可分svm
SVM的解决问题的思路是找到离超平面的最近点,通过其约束条件求出最优解。如下图所示:

支持向量满足函数:
支持向量点到超平面的距离:
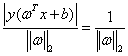
我们解题的思路是:让所有分类的点各自在支持向量的两边,同时要求尽量使得支持向量远离超平面,优化问题可以用数学公式可以表示如下:
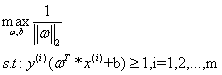
以上优化问题可以转化为:

可以转化为求损失函数J(w)的最小值,如下表示:

以上问题可以用前面讲的KKT条件求解:
求解过程如下:
引入拉格朗日乘子之后,优化目标变成了:
根据朗格朗日对偶特性,将该优化目标转化为等价的对偶问题来解决,从而优化目标变成了:
对于优化目标而言,可以先求w和b的最小值,然后再求解拉格朗日乘额最大值。求极小值,我们以前学过,可以通过求各自的偏导让其各自为零,可以求得参数。
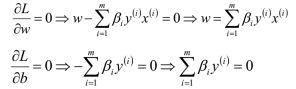
将求得的参数带入优化函数L(W,b,β)中,得到只关于β的函数L(β):
求解过程如下:
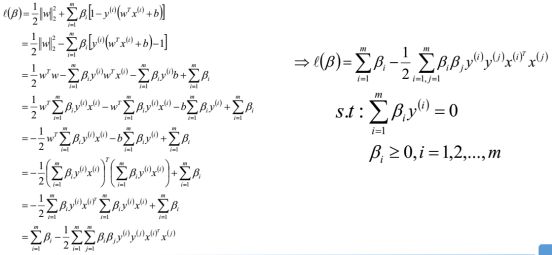
通过对W、b极小化后,我们最终得到的优化函数只和β有关,所以此时我们可以直接极大化我们的优化函数,得到β的值,从而可以最终得到w和b的值。

以上β的求解可以用后面学的SMO算法进行求解,
设存在最优解β;根据W、b和β的关系,可以分别计算出对应的W值和b值般使用所有支持向量的计算均值来作为实际的b值,求得解为:
最终可以求得svm的分类器模型。
svm算法流程
输入线性可分的m个样本数据{(x1y1)、(x2y2)…,(xmym)},其中x为n维的特征向量,y为二元输出,取值为+1或者-1;svm模型输出为参数w、b以及分类决策函数。步骤如下:
(1) 构造约束优化问题;

(2) 使用SMO算法求出上式优化中对应的最优解β*;
(3) 找出所有的支持向量集合S
(4) 更新参数W、b的值;
(5)构造最终分类器:
小结
(1)要求数据必须是线性可分的;
(2)纯线性可分的SVM模型对于异常数据的预测可能会不太准
(3)对于线性可分的数据,SVM分类器的效果毛非常不错