精选36道MySQL练习题解析 from(原50道SQL练习题)
目录
- 一、MySQL基础知识点总结
- 二、学生成绩管理系统数据库设计
- 1.项目背景及需求分析
- 2.概念结构设计
- 3.逻辑结构设计
- 4.物理设计和实施
- 4.1 SQL练习数据库及表创建
- MySQL版本:8.0.20
- 4.2 SQL练习表数据
- 4.3 精选36道SQL查询练习题解析
- 4.3.1. 连接查询 - 4题
- 4.3.2. 子查询、连接查询 - 4题
- 4.3.3. 聚合分组、连接查询 - 8题
- 4.3.4. if 或 case 语句 - 2题
- 4.3.5. 时间函数 - 6题
- 4.3.6.综合应用 - 12题
- 待补充:创建视图、创建函数、创建存储过程、创建触发器
- 更新时间:2020.6.20
一、MySQL基础知识点总结
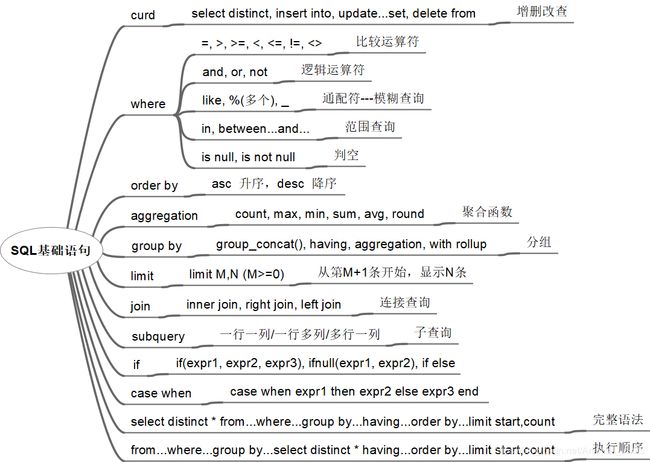
对网络上流传的50道SQL练习题做了筛选,去掉了一些重复的题,剩下36道,总结分为6大类,几乎囊括了SQL查询绝大部分知识点,并给出了不同方法及解析,掌握这36道题,SQL查询语句基本上没啥大问题了,上图:
二、学生成绩管理系统数据库设计
1.项目背景及需求分析
1.1 项目背景
1.2 需求分析
2.概念结构设计
2.1 抽象出系统实体
2.2 全局E-R图
3.逻辑结构设计
3.1 关系模式
3.2 函数依赖识别
3.3 范式
4.物理设计和实施
4.1 SQL练习数据库及表创建
MySQL版本:8.0.20
-- 如果已有该数据库,则删除
DROP DATABASE IF EXISTS StudentScore;
-- 创建数据库
CREATE DATABASE StudentScore CHARSET=UTF8;
-- 使用数据库
USE StudentScore;
-- 创建数据表
-- table 1: students
DROP TABLE IF EXISTS students;
CREATE TABLE students(
sid INT(20) UNSIGNED PRIMARY KEY AUTO_INCREMENT NOT NULL,
sname VARCHAR(20),
sclass INT(10),
sgender VARCHAR(10),
smajor VARCHAR(20),
sbirthday DATE
);
-- table 2: teachers
DROP TABLE IF EXISTS teachers;
CREATE TABLE teachers(
tid INT(10) UNSIGNED PRIMARY KEY AUTO_INCREMENT NOT NULL,
tname VARCHAR(20),
tschool VARCHAR(20)
);
-- table 3: courses
DROP TABLE IF EXISTS courses;
CREATE TABLE courses(
cid INT(10) UNSIGNED PRIMARY KEY AUTO_INCREMENT NOT NULL,
cname VARCHAR(20),
tid INT(10) UNSIGNED NOT NULL,
FOREIGN KEY(tid) REFERENCES teachers(tid)
);
-- table 4: scores
DROP TABLE IF EXISTS scores;
CREATE TABLE scores(
sid INT(10) UNSIGNED NOT NULL,
cid INT(10) UNSIGNED NOT NULL,
score DECIMAL(5, 2),
FOREIGN KEY(sid) REFERENCES students(sid),
FOREIGN KEY(cid) REFERENCES courses(cid)
);
4.2 SQL练习表数据
-- 插入数据
INSERT INTO students VALUES
(0, '赵雷', 1, '男', '计算机', '1990-01-01'),
(0, '钱电', 2, '男', '计算机', '1990-12-21'),
(0, '孙风', 3, '男', '计算机', '1990-12-20'),
(0, '李云', 1, '男', '计算机', '1990-12-06'),
(0, '周梅', 2, '女', '物理', '1991-12-01'),
(0, '吴兰', 3, '女', '物理', '1992-01-01'),
(0, '郑竹', 1, '女', '物理', '1989-01-01'),
(0, '张三', 2, '女', '物理', '2017-12-20'),
(0, '李四', 3, '女', '数学', '2017-12-25'),
(0, '李四', 1, '女', '数学', '2012-06-06'),
(0, '赵六', 2, '女', '数学', '2013-06-13'),
(0, '孙七', 3, '女', '数学', '2014-06-01');
INSERT INTO teachers VALUES
(0, '张若尘', '时空学院'),
(0, '孙悟空', '魔法学院'),
(0, '纪梵心', '本源学院'),
(0, '萧炎', '斗气学院'),
(0, '鲁班', '机械学院');
INSERT INTO courses VALUES
(0, '变形', 2),
(0, '时空穿梭', 1),
(0, '分解术', 3),
(0, '炼器', 5),
(0, '炼丹', 4),
(0, '飞行', 2);
INSERT INTO scores VALUES
(1, 1, 80),
(1, 2, 90),
(1, 3, 99),
(2, 1, 70),
(2, 2, 60),
(2, 3, 80),
(3, 1, 80),
(3, 2, 80),
(3, 3, 80),
(4, 1, 50),
(4, 2, 30),
(4, 3, 20),
(5, 1, 76),
(5, 2, 87),
(6, 1, 31),
(6, 3, 34),
(7, 2, 89),
(8, 1, 88),
(8, 2, 82),
(8, 4, 81),
(9, 6, 95),
(10, 5, 86);
4.3 精选36道SQL查询练习题解析
4.3.1. 连接查询 - 4题
-- 1.1 查询同时选修了课程 1 和 课程 2 的学生的信息
select distinct s1.* from students s1 join
scores s2 on s1.sid = s2.sid join
scores s3 on s2.sid = s3.sid and s2.cid=1 and s3.cid;
-- 1.2 查询课程 1 比 课程 2 成绩高的学生的信息及课程分数
select * from students s1 join
(select t1.sid, t1.score as course1, t2.score as course2
from scores t1, scores t2
where t1.cid=1 and t2.cid=2 and t1.sid=t2.sid and t1.score > t2.score) as t3
on s1.sid = t3.sid;
-- 1.3 查询课程 1 分数小于 60 的学生信息和课程分数,按分数降序排列
select s1.*, s2.score from students s1 join
scores s2 on s1.sid = s2.sid and s2.cid = 1 and s2.score < 60
order by s2.score desc;
-- 1.4 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select distinct s1.* from scores s1 join
scores s2 on s1.sid =s2.sid and s1.cid !=s2.cid and s1.score =s2.score;
4.3.2. 子查询、连接查询 - 4题
-- 2.1 查询有成绩的学生信息
-- 连接查询
select distinct s1.* from students s1, scores s2 where s1.sid = s2.sid;
select distinct s1.* from students s1 join scores s2 on s1.sid = s2.sid;
-- 子查询
select * from students where sid in (select distinct sid from scores);
select * from students where exists (select sid from scores where scores.sid = students.sid);
-- 2.2 查询学过 孙悟空 老师所授课程的学生信息
-- 连接查询
select s1.* from students s1 join
scores s2 on s1.sid = s2.sid join
courses c on c.cid = s2.cid join
teachers t on t.tid = c.tid and t.tname = '孙悟空';
-- 多级子查询嵌套
select * from students where sid in
(select sid from scores where cid in
(select cid from courses where tid in
(select tid from teachers where tname='孙悟空')));
-- 2.3 查询至少有一门课与学号为 1 的同学所学相同的学生信息
-- 多级子查询嵌套
select * from students where sid in
(select sid from scores where cid in
(select cid from scores where sid = 1));
-- 2.4 查询选修了课程 2 但是没有选修课程 1 的学生信息
select s1.* from students s1 join
scores s2 on s1.sid = s2.sid and s2.cid = 2 and
s1.sid not in (select sid from scores where cid = 1);
4.3.3. 聚合分组、连接查询 - 8题
-- 3.1 查询同名学生名单,并统计同名人数
select sname, count(*) as num from students group by sname having count(*) > 1;
-- 3.2 查询选修了 3 门课程的学生信息
select * from students
where sid in (select sid from scores group by sid having count(cid) = 3);
-- 3.3 查询平均成绩大于等于 85 的所有学生的学号、姓名、平均成绩(保留2位小数)
select s2.sid, s1.sname, avg(s2.score) as avgscore from students s1 join
scores s2 on s1.sid = s2.sid
group by s2.sid, s1.sname
having avg(s2.score) >= 85;
-- 3.4 查询平均成绩大于等于 60 分的学生学号、姓名、平均成绩(保留2位小数)
select s1.sid, s1.sname, s2.avgscore from students s1 join
(select sid, round(avg(score), 2) as avgscore from scores group by sid having avgscore >= 60) as s2
on s1.sid = s2.sid;
-- 3.5 查询两门及以上课程分数小于60分的学生学号、姓名及平均成绩(保留2位小数)
select s1.sid, s1.sname, s2.avgscore from students s1 join
(select sid, round(avg(score), 2) as avgscore from scores where score < 60 group by sid having count(*)>1) s2
on s1.sid = s2.sid;
-- 3.6 查询姓 赵 的同学的学生信息、总分,若没选课则总分显示为 0
select s1.*, ifnull(s2.total, 0) as total_score from students s1 left join
(select sid, sum(score) as total from scores group by sid) s2
on s1.sid = s2.sid where s1.sname like '赵%';
-- 3.7 查询所有同学的学号、姓名、选课总数、总成绩,没选课的学生要求显示选课总数和总成绩为 0
select s1.sid, s1.sname,
ifnull(s2.num, 0) as course_num,
ifnull(s2.total, 0) as total_score
from students s1 left join
(select sid, count(cid) as num, sum(score) as total from scores group by sid) as s2
on s1.sid=s2.sid;
-- 3.8 查询所有学生学号、姓名、选课名称、总成绩,按总成绩降序排序,没选课的学生显示总成绩为 0
select s1.sid, s1.sname, s3.cname,
ifnull(s3.total, 0) as total_score
from students s1 left join
(select s2.sid, group_concat(c.cname) as cname, sum(s2.score) as total from scores s2
join courses c on s2.cid = c.cid group by s2.sid) as s3
on s1.sid=s3.sid
order by total_score desc;
4.3.4. if 或 case 语句 - 2题
-- 4.1 若学号sid为学生座位编号,现开始对座位号调整,奇数号和偶数号对调,如1和2对调、3和4对调...等,
-- 如果最后一位为奇数,则不调换座位,查询调换后的学生座位号(sid)、姓名,按sid排序
-- 思路:考察对 if 和 case when 的运用,需要关注最后一位是否为奇数,对此进行判断
-- if
select if(
sid < (select count(*) from students),
if(sid mod 2 = 0, sid-1, sid+1),
if(sid mod 2 = 0, sid-1, sid)
) as sid, sname from students
order by sid asc;
-- case when
select (
case when sid < (select count(*) from students) and sid % 2 != 0 then sid+1
when sid = (select count(*) from students) and sid % 2 != 0 then sid
else sid-1 end
) as sid, sname from students
order by sid asc;
-- 4.2 查询各科成绩最高分、最低分和平均分:
-- 以如下形式显示:课程id、课程名、选修人数、最高分、最低分、平均分、及格率、中等率、优良率、优秀率
-- 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
-- 要求查询结果按人数降序排列,若人数相同,按课程号升序排列,平均分、及格率等保留2位小数
-- case when
select s.cid,
c.cname,
count(score) as '选修人数',
max(score) as '最高分',
min(score) as '最低分',
round(avg(score), 2) as '平均分',
round(sum(case when score>=60 then 1 else 0 end)/count(score), 2) as '及格率',
round(sum(case when score>=70 and score<80 then 1 else 0 end)/count(score), 2) as '中等率',
round(sum(case when score>=80 and score<90 then 1 else 0 end)/count(score), 2) as '优良率',
round(sum(case when score>=90 then 1 else 0 end)/count(score), 2) as '优秀率'
from scores s, courses c
where s.cid=c.cid
group by s.cid, c.cname
order by count(score) desc, cid asc;
-- if
select s.cid, c.cname,
count(score) as '选修人数',
max(score) as '最高分',
min(score) as '最低分',
round(avg(score), 2) as '平均分',
round( count( if(score >= 60, true, null))/count(score), 2) as '及格率',
round( count( if(score >= 70 and score < 80, true, null))/count(score), 2) as '中等率',
round( count( if(score >= 80 and score < 90, true, null))/count(score), 2) as '优良率',
round( count( if(score >= 90, true, null))/count(score), 2) as '优秀率'
from scores s, courses c
where s.cid=c.cid
group by s.cid, c.cname
order by count(score) desc, s.cid asc;
4.3.5. 时间函数 - 6题
-- 5.1 查询 1990 年出生的学生信息
-- 时间函数:year()
select * from students where year(sbirthday)=1990;
-- 5.2 查询各学生的年龄,分别按年份和按出生日期来算
-- 按年份算
select sid, sname, (year(curdate()) - year(sbirthday)) as age from students;
-- 按出生日期算
select sid, sname, timestampdiff(year, sbirthday, curdate()) as age from students;
-- 5.3 查询本周或下周过生日的学生
-- 本周
select * from students where week(sbirthday) = week(now());
-- 下周
select * from students where week(sbirthday) = week(now()) + 1;
-- 5.4 查询本月或下月过生日的学生
-- 本月
select * from students where month(sbirthday) = month(now());
-- 下月
select * from students where month(sbirthday) = month(now()) + 1;
-- 5.5 查询学生信息,要求:学号和年龄同时至少比一位学生的学号和年龄大
-- to_days()
select distinct s1.* from students s1, students s2
where s1.sid > s2.sid and to_days(s1.sbirthday) < to_days(s2.sbirthday)
order by s1.sid;
-- datediff()
select distinct s1.* from students s1
inner join students s2
on datediff(s1.sbirthday, s2.sbirthday) < 0 and s1.sid > s2.sid
order by s1.sid;
-- 5.6 查询连续相邻3年出生的学生中,学生性别相同的学生信息
-- 相邻年份即时间差为1年,通过3表自交对比得出连续3年出生且性别相同的学生,
-- 注意:select 后跟的是那个表数据,那哪个表的 sbirthday 就要分别作为连续3年中最小、中间、最大那一年出现
select distinct s1.* from students s1 join
students s2 on s1.sgender = s2.sgender join
students s3 on s1.sgender = s3.sgender
where (year(s1.sbirthday) - year(s2.sbirthday) = 1 and year(s2.sbirthday) - year(s3.sbirthday) = 1)
or (year(s2.sbirthday) - year(s1.sbirthday) = 1 and year(s1.sbirthday) - year(s3.sbirthday) = 1)
or (year(s2.sbirthday) - year(s3.sbirthday) = 1 and year(s3.sbirthday) - year(s1.sbirthday) = 1)
order by s1.sid;
4.3.6.综合应用 - 12题
-- 6.1 查询和学号为 1 的同学学习的课程完全相同的其他同学的信息
-- 思路:
-- 用 case when 对把其余学生选的课与 1 号学生选的每一门课进行对比,
-- 相同就计数 1 ,最后 sum 求和得出其他学生与 1 号学生相同选课数 number,
-- 如果 number 与 1 号学生选课数相等,则表示该学生与 1 号同学学习的课程完全相同
select * from students
where sid in (
select sid from (
select s1.sid,
sum(case when s2.sid = 1 and s1.cid = s2.cid then 1 else 0 end) as number
from scores s1, scores s2
group by sid having s1.sid != 1) s3
where s3.number = (select count(cid) from scores group by sid having sid = 1));
-- 6.2 查询每科均及格的人的平均成绩:学号、姓名、平均成绩(保留2位小数)
-- 思路:可以先筛选出有不及格科目的学生学号,然后在把这些学生排除掉
select s1.sid, s1.sname, s2.avgscore
from students s1,
(select sid, round(avg(score), 2) as avgscore
from scores group by sid) s2
where s1.sid = s2.sid
and s1.sid not in (select distinct sid from scores where score < 60);
-- 6.3 查询选修 张若尘 老师所授课程的学生中,该门课成绩最高的学生信息及成绩(成绩可能重复)
-- 思路:
-- 先找出符合条件的课程和分数列表,然后通过分组聚合、聚合函数得到课程编号和最高成绩
select s1.*, s2.score from students s1, scores s2
where s1.sid = s2.sid
and (s2.cid, s2.score) = (
select cid, max(score) from (select s.cid, s.score from scores s, courses c, teachers t
where s.cid = c.cid and c.tid = t.tid and t.tname ='张若尘') t
group by cid);
-- 6.4 查询各科成绩,按各科成绩进行排序,并显示排名
-- 分数重复时保留名次空缺,即名次不连续
-- 思路:
-- 1.排名一类的查询一般通过自交(连接)进行对比,通过计算“比当前分数高的分数有几个”来确定排名
-- 2.或者用rank()函数,高版本的MySQL会有这个功能
-- 这一道题只能左交-left join不能用where联合
-- 因为分数重复时保留名次空缺意味着不对score去重,不去重分数对比排名时使用where,
-- 如果带等号,即使用>=或者<=去比较,当重复分数在第1名时,得出排名结果不准确,
-- 如果不带等号,即使用<或>去比较判断,则会漏掉第一名;
-- 而使用left join 则不会漏掉;
--left join
select s1.*, count(s2.score)+1 as '排名'
from scores s1 left join scores s2
on s1.score<s2.score and s1.cid=s2.cid
group by s1.cid, s1.sid, s1.score
order by s1.cid, s1.score desc;
-- rank()
select *, rank() over (partition by cid order by score desc) as '排名' from scores;
-- 6.5 查询各科成绩,按各科成绩进行排序,并显示排名
-- 分数重复时不保留名次空缺,即名次连续
-- 思路:
-- 1.通过distinct 去重score,保证排名名次连续;
-- 2.通过与自己比较,计数得出每一名所在的排名;
-- 3.这一题既可以用where也可以用left join,
-- 4.但是where只能和<=或者>=搭配,而left join即可以和>, <搭配,也可以和=>, <=搭配;
-- 5.或者采用 dense_rank()
-- left join
select s1.*, count(distinct s2.score)+1 as '排名' from scores s1
left join scores s2
on s1.cid=s2.cid and s1.score < s2.score
group by s1.sid, s1.cid, s1.score
order by s1.cid asc, s1.score desc;
-- 同上:
select s1.*, count(distinct s2.score) as '排名' from scores s1
left join scores s2
on s1.cid=s2.cid and s1.score <= s2.score
group by s1.sid, s1.cid, s1.score
order by s1.cid asc, s1.score desc;
-- where
select s1.*, count(distinct s2.score) as '排名' from scores s1, scores s2
where s1.cid=s2.cid and s1.score <= s2.score
group by s1.sid, s1.cid, s1.score
order by s1.cid asc, s1.score desc;
-- dense_rank()
select *, dense_rank() over (partition by cid order by score desc) as '排名' from scores;
-- 6.6 查询学生 赵雷 的 变形 课程成绩的排名:学生信息,分数,排名
-- 分数重复时不保留名次空缺,即名次连续
-- 注意:需要对分数进行去重
select s1.*, s2.score,
(select count(distinct score) from scores s3
where s2.cid=s3.cid and s2.score <= s3.score) as '排名'
from students s1, scores s2, courses c
where s1.sname='赵雷'
and c.cname='变形'
and c.cid=s2.cid
and s2.sid=s1.sid;
-- 6.7 查询课程 时空穿梭 成绩在第2-4名的学生,要求显示字段:学号、姓名、课程名、成绩
-- 分数重复时不保留名次空缺,即名次连续
select s1.sid, s1.sname, c.cname, s2.score
from students s1, scores s2, courses c
where s1.sid=s2.sid and s2.cid=c.cid and c.cname='时空穿梭'
and (select count(distinct score) from scores s3
where s2.cid=s3.cid and s2.score>=s3.score) between 2 and 4
order by score desc;
-- 6.8 查询学生的总成绩,并进行排名,总分重复时不保留名次空缺,即名次连续
-- 思路:
-- 先分组得出总分,然后通过自交对总分进行比较得出名次,
-- 需要注意题目要求总分重复时不保留名次空缺,即需要对自关联的一边去重
-- 通过对比
select t1.sid, t1.total, count(t1.total) as '排名' from
(select sid, sum(score) as total from scores group by sid) t1,
(select distinct sum(score) as total from scores group by sid) t2
where t1.total <= t2.total
group by t1.sid
order by t1.total desc;
-- dense_rank()
select *, dense_rank() over (order by total desc) '排名'
from(select sid, sum(score) total from scores group by sid) t;
-- 6.9 查询学生的总成绩,并进行排名,总分重复时保留名次空缺,及名次不连续
-- 排名名次不连续,不需要去重
-- 通过对比
select t1.sid, t1.total, count(t1.total) as '排名' from
(select sid, sum(score) as total from scores group by sid) t1,
(select sum(score) as total from scores group by sid) t2
where t1.total <= t2.total
group by t1.sid
order by t1.total desc;
-- rank()
select *, rank() over (order by total desc) '排名'
from(select sid, sum(score) total from scores group by sid) t;
-- 6.10 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 分别所占百分比
-- 结果:保留2位小数
-- 核心思路:分组聚合,用case when, sum, cancat,left join结合使用
select c.cname, t.* from courses c
left join (select cid,
concat(round(sum(case when score>=85 and score<=100 then 1 else 0 end)/count(*)*100, 2), '%') as '[100-85]',
concat(round(sum(case when score>=70 and score<85 then 1 else 0 end)/count(*)*100, 2), '%') as '[85-70]',
concat(round(sum(case when score>=60 and score<70 then 1 else 0 end)/count(*)*100, 2), '%') as '[70-60]',
concat(round(sum(case when score<60 then 1 else 0 end)/count(*)*100, 2), '%') as '[60-0]'
from scores group by cid) as t on c.cid = t.cid;
-- 6.11 查询各科成绩前三名的记录,按照课程编号和分数排序
-- 分数重复时,重复分数按照一名算,即不保留名次空缺,及名次连续
-- 查询结果如下:
-- +-----+-----+-------+
-- | sid | cid | score |
-- +-----+-----+-------+
-- | 8 | 1 | 88.00 |
-- | 1 | 1 | 80.00 |
-- | 3 | 1 | 80.00 |
-- | 5 | 1 | 76.00 |
-- | 1 | 2 | 90.00 |
-- | 7 | 2 | 89.00 |
-- | 5 | 2 | 87.00 |
-- | 1 | 3 | 99.00 |
-- | 2 | 3 | 80.00 |
-- | 3 | 3 | 80.00 |
-- | 6 | 3 | 34.00 |
-- | 8 | 4 | 81.00 |
-- | 9 | 6 | 95.00 |
-- +-----+-----+-------+
-- 思路:
-- 这一题逻辑比较简单,但是坑比较多。
-- 核心逻辑是表内分数相互比较得出前3名,需要将单个表定义成2个虚表来实现对比,
-- 关键在于要把重复分数的情况考虑进来,不然容易漏掉
-- 成绩前N名表示比前N名更大的数不会超过N名(去掉重复情况)
-- <=
select s1.sid, s1.cid, s1.score
from scores s1, scores s2
where s1.score<=s2.score and s1.cid=s2.cid
group by s1.cid, s1.sid, s1.score
having count(distinct s2.score) <= 3
order by s1.cid asc, s1.score desc;
-- <
select * from scores s1
where (
select count(distinct score) from scores s2
where s1.cid = s2.cid and s1.score < s2.score) < 3
order by cid asc, score desc;
-- 解析:
-- 当 where (select count(distinct score) from scores s2
-- where s1.cid = s2.cid and s1.score < s2.score) < 3 在计数时,
-- 会把count(distinct score)为 0 的数算进来,所以此时select count(distinct)
-- 的结果是[0, 1, 2],即选出s1.score中比s2.score大0个(没有比第1名大的所以为0)、
-- 1个(第1名比第2名大所以为1)、2个(第1,2名比第3名大所以为3)的score;
-- 图解,以cid=01为例:
-- cid s1.score s2.score s2比s1中score大的数有N个(重复不算)
-- 01 80 80 0
-- 01 80 80 0
-- 01 76 76 1
-- 01 70 70 2
-- 当N=0, 1, 2时,对应s1.score中(80, 80, 76, 70)
-- <= 对比时同时取了等号,此时select count(distinct)的结果是[1, 2, 3]
select * from scores s1
where (
select count(distinct score) from scores s2
where s1.cid = s2.cid and s1.score <= s2.score) <= 3
order by cid asc, score desc;
-- dense_rank()
select * from(select *, dense_rank() over (partition by cid order by score desc) score_rank from scores) t
where t.score_rank <= 3;
-- 6.12 查询各科成绩的前两名,列出学生信息、课程名、分数,按照课程名、分数排序
-- 分数重复时,重复分数按照一名算,即不保留名次空缺,及名次连续
select s1.*, c.cname, s2.score
from students s1, scores s2, courses c
where
(select count(distinct score) from scores s3
where s3.cid=s2.cid and s3.score > s2.score) < 2
and s1.sid=s2.sid and s2.cid=c.cid
order by c.cname, s2.score desc;
题目总结终于完成啦!