进程的概述与创建—Linux
文章目录
- 1.进程概述
- 1.1 概念
- 1.2 进程属性
- 1.3 进程的状态及转换
- 1.4 进程间的亲属关系
- 1.5 PCB块所存放的位置
- 1.6 进程的组织方法
- 1.7 进程与容器
- 2.进程创建
- 2.1 问题引入
- 2.2 进程的API实现
- 2.3 fork的实现:
- 2.4 vfork的实现
- 2.5 clone的实现
- 2.6 内核线程的创建
- 2.7 copy_process()
- 2.8 进程的生命周期
- 3.小结
1.进程概述
Linux是一个操作系统,类似于之前我们所接触的Window系列(XP、7、8)和Mac OS。Linux主要是系统调用与内核,连接了应用程序与硬件。而我们又都知道OS一般包含一些在其上运行的应用程序,比如文本编辑器、浏览器和电子邮件等。进程就是处于执行期的程序。
在系统中一个程序通过编译器将其编译为汇编程序,通过汇编器将其汇编成目标代码,通过链接器形成可执行文件a.out或者elf格式,最后交给操作系统来执行。在这个过程中,当一个程序一旦开始执行,它的身份就会变为进程,而在操作系统看来每个进程是没有多大差异性的,都被封装在这样的可执行文件格式中。在用户态下可根据top命令感知系统中各个进程以及动态变化。
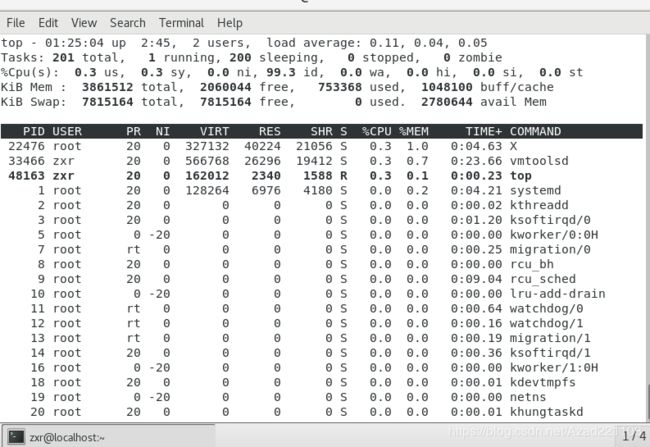
1.1 概念
API: API(Application Programming Interface,应用程序接口)是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。 目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问原码,或理解内部工作机制的细节。
例程: 例程的作用类似于函数,但含义更为丰富一些。例程是某个系统对外提供的功能接口或服务的集合。比如操作系统的API、服务等就是例程;Delphi或C++Builder提供的标准函数和库函数等也是例程。我们编写一个DLL的时候,里面的输出函数就是这个DLL的例程。
进程: 进程(Process)是处于执行期的程序以及相关的资源的总称,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。进程是正在执行的程序代码的实时结果,是一个具有生命周期的动态实体。从内核观点看到的进程就是任务。
线程: 执行线程,简称线程(thread),是在进程中活动的对象。每个线程都拥有一个独立的程序计数器、进程栈和一组进程寄存器。线程是内核调度的对象。
PID: 是一个数,表示为pid_t隐含类型(数据类型的物理表示是未知的或不相关的),实际上是一个int类型。PID的最大值默认设置为32768。内核把每个进程的PID都存放在它们各自的进程描述符中。
写时拷贝: (copy-on-write)写时拷贝技术是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父进程和子进程共享同一个拷贝。
1.2 进程属性
Linux内核中把对进程的描述数据结构叫做task_struct结构,即进程控制块PCB,在内核代码中具体定义在sched.h文件中。
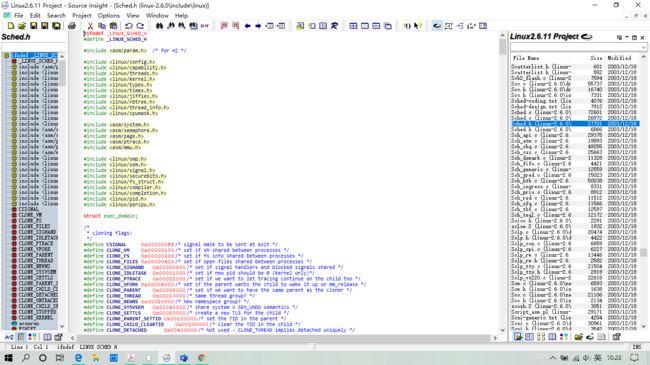
这里列出进程控制块的各种信息分类:
状态信息一描述进程动态的变化。
链接信息一描述进程的父子关系。
各种标识符一用简单数字对进程进行标识。
进程间通信信息一描述多个进程在同任务上协作工作,
时间和定时器信息一描述进程在生存周期内使用CPU时间的统计、计费等信息。
调度信息一描述进程优先级、 调度策略等信息。
文件系统信息一对进程使用文件情况进行记录。
虚拟内存信息一描述每个进程拥有的地址空间。
处理器环境信息一描述进程的执行环境(处理器的寄存器及堆栈等)
进程控制块中的信息多达几百个字段,具体可通过查看源代码认识。
1.3 进程的状态及转换
进程中的五种状态标志:
- TASK_RUNNING(运行)——程序是可执行的;
- TASK_INTERRUPTIBLE(可中断)——程序正在睡眠(即阻塞),等待某些条件的达成;
- TASK_UNINTERRUPTINLE(不可中断)——与可中断类似除了收到信号仍未唤醒或准备投入运行;
- _TASK_TRACED ——被其他进程跟踪的进程
- _TASK_STOPPED(停止)——进程停止执行。
状态是用来描述进程动态变化的,最基本的状态有三种,分别为就绪态、睡眠态和运行态。在具体的操作系统中可能实例化出多个状态,将就绪与运行态合并为就绪态,调度程序从就绪队列中选择一个程序投入运行,睡眠态分为浅度睡眠与深度睡眠两种,此外还存在暂停状态与僵死状态(即进程死亡却并未释放PCB块)。
1.4 进程间的亲属关系
系统在创建进程时具有父子关系,因一个进程可创建几个子进程,而子进程之间存在兄弟关系,在PCB中引入几个域来表示相关的关系。
子进程与父进程的区别:
子进程与父进程的区别仅仅在于PID(每个进程唯一)、PPID(父进程的进程号,子进程将其设置为被拷贝进程的PID)和某些资源和统计量。
进程1(init)是所有进程的祖先,系统中的进程形成一颗进程树。在进程的PCB中引入几个域用来描述进程之间的父子及兄弟关系。假设p表示一个进程,首先有一个域来描述它的父亲(parent),其次有一个域描述p的子进程。由于子进程不止一个,因此让这些域指向年龄最小的子进程(child),最后p可能有兄弟,所以用一个域来表示p的长兄进程(old sibling),一个域描述p的弟进程(younger sibling)。
以下是在源码中截取的部分代码片段:
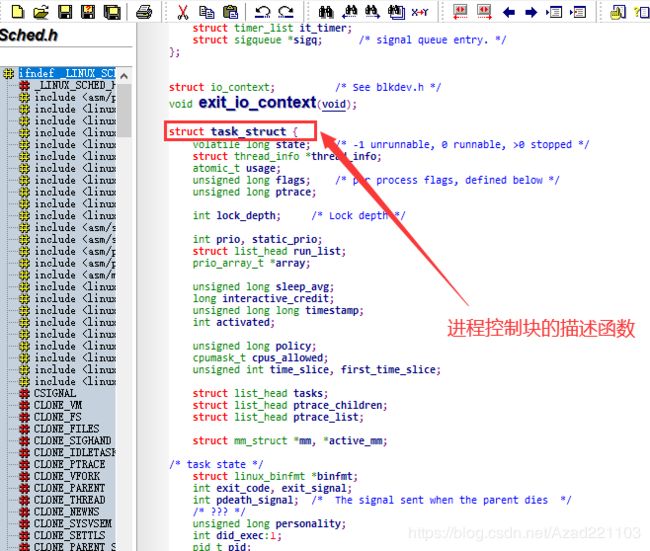
从以上可看出进程完全模拟人类的生存状态。且Linux中进程的状态及其转换与之前在OS中学习的差别不大,所以可回顾学习。
1.5 PCB块所存放的位置
内核把进程的列表存放在叫做任务队列的双向循环链表中,链表中的每一项都是类型为task_struct、称为进程描述符(process descriptor)的结构。
Linux内核为节省空间,把内核栈和一个紧挨着PCB的小数据结构thread_info放在一起,占用8KB的内存区。在内核代码中以混合结构的形式体现。thread_info表示和硬件关系更密切的数据,第一个字段就是task_struct结构。
随着Linux版本的变化,PCB中的内容越来越多,所需的空间也随之增大,这样便使得留给内核的堆栈空间变小了,所以把部分PCB中的内容移出这个空间,只保留访问频繁的thread_info。
把PCB与内核栈放在一起的好处是:
1.内核可方便快速地找到PCB,即只要知道栈指针便可以找到PCB的起始地址;
2.可避免在创建进程时动态分配额外的内存。
在Linux中为了表示当前正在运行的进程,定义了一个current宏,可以将其看作全局变量来应用,如current->pid,则返回正在执行的进程的标识符。
1.6 进程的组织方法
内核中组织进程的方法之一有链表组织方法,链表的头尾都为init_task。(可进入源代码查看具体各个字段的值) 0号这个进程永远不会被撤销,它的PCB被静态地分配在内核的数据段中,即init_task的PCB是预先由编译器分配的,在运行的过程中保持不变,而其他PCB是在进程的运行过程中,由系统根据当前的内存状态随机分配的,撤销时再还给系统。也可自己编写一个可以打印所有进程的PID和进程名的内核模块。
1.7 进程与容器
目前云技术的核心技术为容器,进程的静态表现为程序,平时安静待于磁盘之上,一旦运行起来就变成了计算机中的数据和状态的总和,也就是它的动态表现;而容器技术的核心是:通过约束和修改进程的动态表现,从而为其创造出一个“边界”。对于Docker等大多数Linux容器而言Cgroups技术是用来制造约束的主要手段,而Namespace技术则是用来修改进程视图的主要方法。
2.进程创建
2.1 问题引入
在系统中,进程与线程几乎共享所有的信息,包括代码、数据、进程的空间和打开的文件等等。线程只拥有自己的寄存器与栈。我们都知道,在操作系统中,进程是系统资源分配的基本单位,线程是独立运行的基本单位。但此说法终究过于笼统仍然存在一些需要我们思考的问题,比如进程的资源有哪些,如何体现,而线程又为何是轻量级的运行单位,如何体现?
这是因为进程不仅仅局限于一段可执行程序代码,还包含其他资源,类似于:打开的资源、挂起的信号、内核内部数据、处理器状态、一个或多个具有内存映射的内存地址空间及一个或多个执行线程,还有用来存放全局变量的数据段等等;线程的轻量级体现在其耗费资源少,运行迅速。
系统中进程的生生死死随时发生,因此操作系统对于进程的描述模仿人类的活动,一个进程不会平白无故的诞生,它也有自己的父母。在linux中通过调用fork系统调用来创建一个新的进程,新创建的进程同样也可执行fork,所以可形成一颗完整的进程树。
如图是Linux系统启动以后形成的一颗进程树:
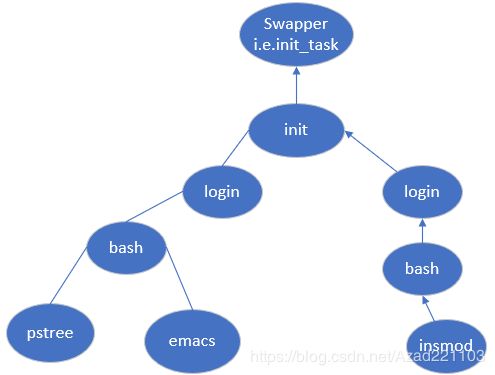
可通过ps(process struct)命令查看自己机子上的进程树。
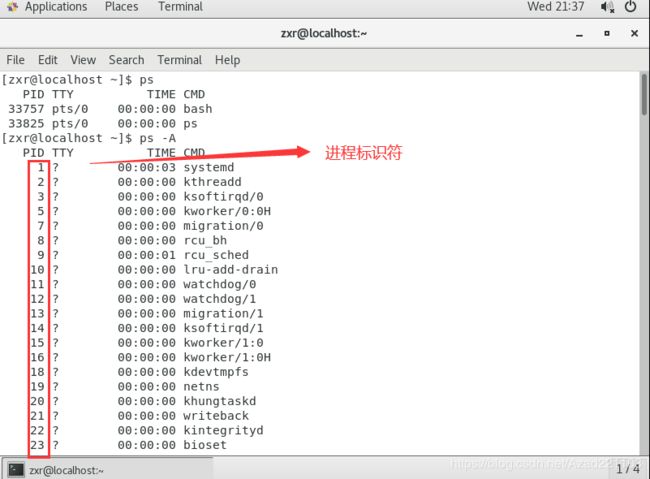
task_struct结构具有统一性和多样性。linux内核以“一视同仁”为原则对待进程、线程与内核线程,即内核使用唯一的数据结构task_struct结构来分别表示前三者,使用相同的调度算法对此三者进行调度。在内核中统一由 do_fork() 分别创建,此种处理方法对内核而言简单方便,在统一的基础上又保持了各自的特性。
2.2 进程的API实现
这当中的细节是这样的:
首先,在用户态函数中创造进程与创造线程调用了不同的函数,创建进程的函数为fork,创建线程的函数为pthread_create,而对应的系统调用分别为fork和clone,vfork与fork虽然较为类似却仍有不同,在后面会加以阐述。所有的系统调用进入内核只有一个入口,即 system_call() ,在进入后分道扬镳各自有了自己的服务历程暂时分开,最终在do_fork处汇合。
2.3 fork的实现:
fork()的实际开销就是复制父进程的页表以及给子进程创建唯一的进程描述符。
Linux通过clone()系统调用实现fork()。
do_fork在内核中的原型为:
long do_ fork(unsignedlong clone flags,unsigned long stack_ start,unsigned long stack_ size,int user * parent_ tidptir,int user *child_ tidptr)
在用户态调用fork时无需传递参数给它,而进入内核后之所以变得麻烦是因为:
首先fork调用do_fork,除了SLGCHLD参数外有三个参数空手而来,有两个参数无明确目标,但其作为子进程完全由自己的个性不想与父进程共享任何的资源,而是让父进程把它所有的资源给自己复制一份,父进程假装给子进程复制一下(即用一个指针指过去),当真正需要之时比如当写一个页面时,写时复制技术便登场了。只有父子进程中不管谁想写一个页面的时候这个页面才被复制一份。
2.4 vfork的实现
vfork狡猾过于fork,直接传递两个标志过去,第一个标志CLONE_VFORK表示儿子优先老爸等待,于是父进程去睡觉,等子进程结束后才能醒来;第二个标志CLONE_VE,儿子与父进程直接呆在一个进程的地址空间中,即父子进程共享内存的地址空间,但父进程的页表除外。vfork看起来聪明实则做了无用功,因写时复制技术的招数更高效,因此vfork失去了生存空间直接被取代了。
2.5 clone的实现
clone的意思为克隆,线程便是通过克隆技术诞生的,子进程传递一堆参数告诉父进程,我要共享你的这里和那里,于是老爸把地址空间、文件系统、打开的文件、信号处理函数等等都被子进程一句话说过去了,看起来实际上是四个参数的或。
fork()、vfork()和_clone()库函数都根据各自需要的参数标志去调用clone(),然后由clone()去调用do_fork()。
2.6 内核线程的创建
内核线程与普通进程的区别在于内核线程无独立的地址空间(指向地址空间的mm指针被设置为NULL),只在内核空间运行,从不切换到用户空间去。
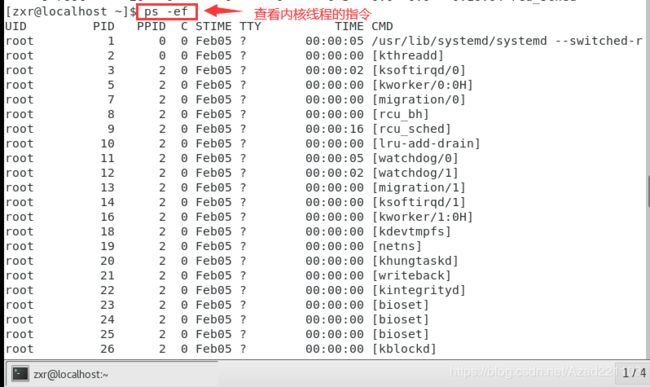
如果你是一个内核线程(kernel thread),则你的出生便很有优势,因为用户空间对于内核线程而言根本毫无意义,甚至不知其的存在,早期内核中内核线程的创建是通过kernel_thread()创建的,目前是在内核中调用kthread_create创建的,其本质也是向do_fork提供特定的标志而创建。task_struct结构会带来统一性,为thread的诞生带来方便,归根结底是因为两者站在了同一个战壕中,即task_struct结构。由此我们的生命历程便有了诸多相似,无论是被调度到CPU上去运行还是分配各种资源到最终的诞生都是调用了相同的函数do_fork。
以下为do_fork的代码流程:
1.首先调用了copy_process复制父进程的进程控制块
2.然后获得子进程的PID
3.若设置了暂停标志CLONE_STOPPED,则子进程的状态被设置为暂停;否则通过唤醒函数wake_up_new_task()将子进程的状态设置为就绪,并将子进程加入就绪队列
4.若使用了vfork创建进程,则阻塞父进程。
内核线程启动后就一直运行直到调用do_exit()退出,或者内核的其他部分调用Kthread_stop()退出,传递给Kthread_stop()的参数为Kthread_create()函数返回的task_struct结构的地址。
2.7 copy_process()
copy_process主要用于创建进程控制块以及子进程执行时所需要的其他数据结构,该函数的参数与do_fork的参数大致相同,并添加了子进程的PID。copy_process所做的处理必须考虑到各种可能的情况,这些特殊的情况通过clone_flags来具体体现。
下面忽略特殊情况给出一般的copy_process代码执行过程的流程图:
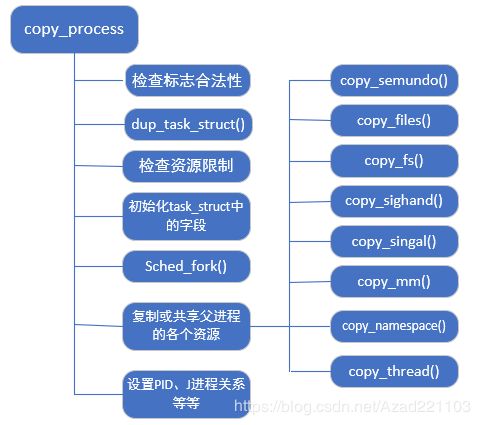
copy_process函数主要是为子进程创建父进程PCB的副本,然后对子进程PCB中各个字段进行初始化同时子进程对父进程中的各种资源进行复制或共享,具体取决于clone_flags所设置的标志。
每一种资源的复制或者共享都通过copy_xyz函数完成,子进程通过copy_xyz获得自己的PID,父进程通过copy_xyz函数共享各种资源,比如打开的文件、所在的文件系统、进程的地址空间、信号、命名空间等等,若进入此些函数去阅读,几乎延伸到内核的各个子系统,所以可先简单的阅读,在了解了内核的各个子系统后再回头阅读会发现一个进程的创建牵一发而动全局,将相关的零散知识通过do_fork聚集在一起。
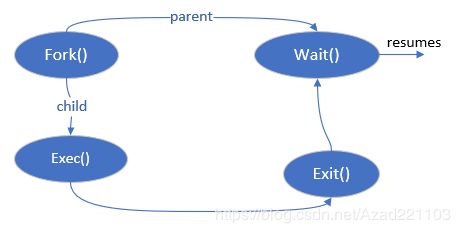
2.8 进程的生命周期
前面我们详细的介绍了fork的创建过程,与此相应的还有三个系统调用分别为exec、wait、exit三个系统调用。
一个新进程由fork产生,这时只是老进程的一个克隆,随着exec系统调用,新进程开始独立工作的职业生涯,即创建新的地址空间并把新的程序载入其中。进程可以自然死亡即运行到主函数的最后一个大括号后从容离开,也可以是中途退场,退场有两种方式,一种是调用exit函数,一种是在主函数(main)中使用return,无论哪种方式,进程都可以留下留言放在返回值里保留下来;甚至还有可能被谋杀,被其他进程通过另外一种方式结束它的生命,进程死掉后会留下一个空壳,wait站好最后一班岗打扫战场,使进程最终归于无形,这便是进程完整的一生。
3.小结
Linux使用task_struct()和thread_info()来存放和表示进程;
通过fork(),实际最终是clone()创建进程;
通过exec()系统调用族把新的执行映像装入到地址空间;
通过wait()系统调用族父进程收集其后代的信息,表示进程的层次关系;
最终进程强制或自愿地调用exit()走向消亡。
关于进程在Linux系统中的详细内容可结合Linux2.6版本的内核源码进行相关的学习与探究。
为自由开路者,不可使其困顿于荆棘。