【Hadoop】(三)资源管理器 YARN 和分布式计算框架 MapReduce
文章目录
- 前言
- 一 、MapReduce 介绍
- 1. 基本介绍
- 2. MR 数据流程方向
- 3. MR 核心思想
- 4. MR运行原理
- 5. 块 、切片 、 map 、reduce 、组 、分区 、输出文件之间的关系
- 6. 计算框架
- 二、Hadoop 2.x-MapReduce
- 1. Hadoop YARN
- 2 .Hadoop2 MR在Yarn上运行流程
- 3. YARN
- 三、MapReduce 原理分析
前言
Hadoop MapReduce / MR 是一个软件计算框架,可以轻松地编写应用程序,以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多达TB数据集) 。
一 、MapReduce 介绍
1. 基本介绍
MapReduce框架由一个主资源管理器,一个集群节点一个工作器NodeManager和每个应用程序MRAppMaster组成(请参阅YARN体系结构指南)。应用程序通过适当的接口和/或抽象类的实现来指定输入/输出位置和供应图,并减少功能。这些以及其他作业参数构成作业配置。然后,Hadoop 作业客户端将作业(jar /可执行文件等)和配置提交给ResourceManager,然后由ResourceManager负责将软件/配置分发给工作人员,安排任务并对其进行监视,为工作提供状态和诊断信息,客户。
计算节点和存储节点是相同的,也就是说,MapReduce框架和Hadoop分布式文件系统(HDFS)在同一组节点上运行。此配置使框架可以在已经存在数据的节点上有效地调度任务,从而在整个群集中产生很高的聚合带宽。
尽管Hadoop框架是用Java实现的,但MapReduce应用程序不必用Java编写。
Hadoop Streaming是一个实用程序,它允许用户使用任何可执行程序(例如Shell实用程序)作为映射器和/或reducer创建和运行作业。
2. MR 数据流程方向
输入(格式化k,v)数据集 -> map映射成一个中间数据集(k,v) -> reduce
3. MR 核心思想
相同的key为一组,调用一次reduce方法,方法内迭代这一组数据, 进行计算(sum count max min)
4. MR运行原理
宏观角度
InputSplit(输入分片)

MapReduce 作业通常将输入数据集拆分为独立的块,这些任务由Map Task以完全并行的方式进行处理。框架对map的输出进行排序,然后将其输入到reduce任务。通常,作业的输入和输出都存储在文件系统中。该框架负责安排任务,监视任务并重新执行失败的任务。
注意 :
一个切片对应一个Map
切片以一条记录为单位调用一次Map
map数量由切片决定的 , reduce 数据由人来决定的
左边矩形 Map Task( 块/block ) , 小矩形 map方法
右边矩形 Reduce Task( 分区/partition ) , 小矩形 Reduce 方法
微观角度
Shuffle阶段 数据从Map输出到Reduce输入的过程

- Shuffler<洗牌>:框架内部实现机制(数据分发)
补充: 面试问如何理解shuffle?(在MapReduce环境下)
1.shuffle就是在reduce启动后 ,在map中拉回属于自己的数据的过程(动作角度)
2.如果面试官说不对,就说是从map输出完数据之后, 算出属于的分区号 /reduce开始 ,一直到拉取并计算数据这一整个过程(逻辑角度)
shuffle :动作 :拷贝 ; 逻辑: 数据规划,整理,拉取 - 分布式计算节点数据流转:连接MapTask与 ReduceTask
- Reduce分组和排序强依赖 Map输出的结果: .Reduce没有排序的能力, 只是对map的结果做归并
理解运行原理角色模型:
- Map:
读懂数据
映射为KV模型
并行分布式
计算向数据移动: / 移动计算 - Reduce:
数据全量/分量加工
Reduce中可以包含不同的key
相同的Key汇聚到一个Reduce中
相同的Key调用一次reduce方法
排序实现key的汇聚 - K,V使用自定义数据类型
作为参数传递,节省开发成本,提高程序自由度
Writable序列化:使能分布式程序数据交互
Comparable比较器:实现具体排序(字典序,数值序等)
5. 块 、切片 、 map 、reduce 、组 、分区 、输出文件之间的关系

6. 计算框架
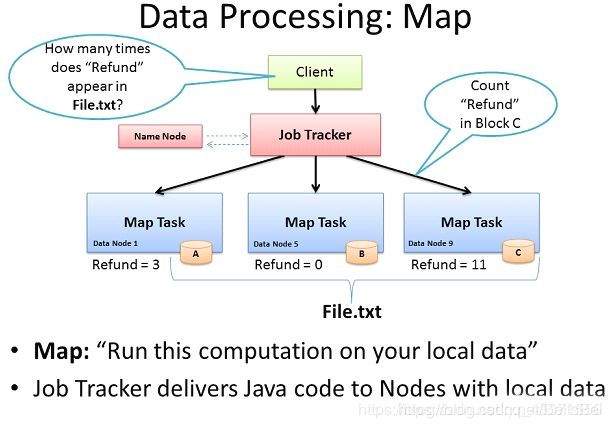
计算框架 Map
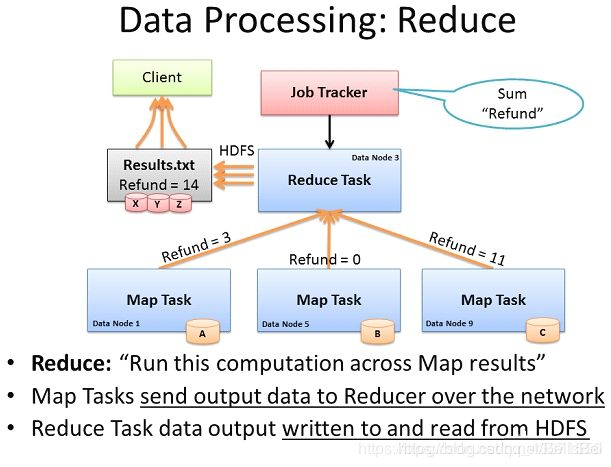
计算框架Reduce
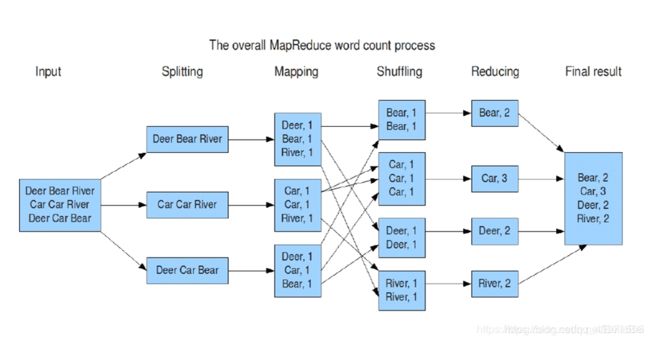
计算框架MR图例演示
二、Hadoop 2.x-MapReduce
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
1. Hadoop YARN

2 .Hadoop2 MR在Yarn上运行流程

1、YARN:解耦资源与计算
- ResourceManager /RM
主,核心
集群节点资源管理 - NodeManager /NM
向RM汇报资源
管理Container生命周期
计算框架中的角色都以Container表示 - Container:【节点NM,CPU,MEM,I/O大小,启动命令】
默认NodeManager启动线程监控Container大小,超出申请资源额度,kill
支持Linux内核的Cgroup
2、MR :
- MR-ApplicationMaster-Container
作业为单位,避免单点故障,负载到不同的节点
创建Task需要和RM申请资源(Container) - Task-Container
3.、Client:
- RM-Client:请求资源创建AM
- AM-Client:与AM交互
3. YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的。
核心思想:
将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现
ResourceManager:
负责整个集群的资源管理和调度
ApplicationMaster:
负责应用程序相关的事务,比如任务调度、任务监控和容错等
YARN的引入,使得多个计算框架可运行在一个集群中 ,每个应用程序对应一个ApplicationMaster
目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、Storm等
三、MapReduce 原理分析
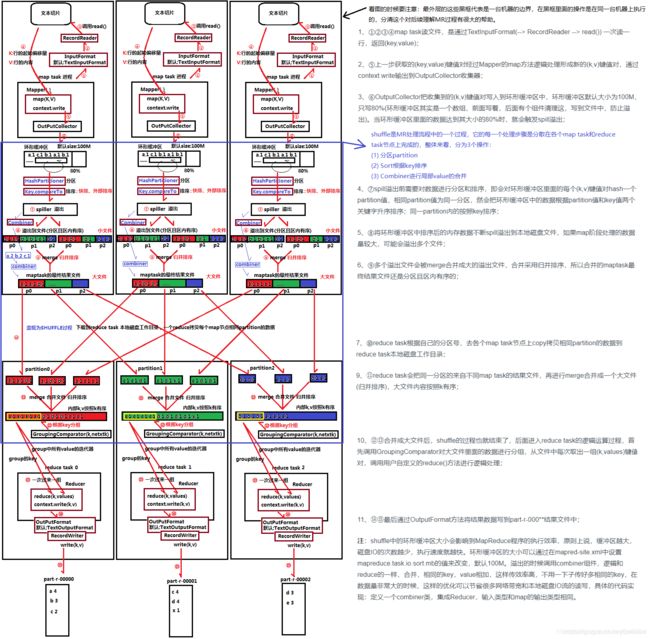
在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
流程简介:
通过map task读文件,使用TextInputFormat()方法一次读入整行文件,输入文件会被切分成多个块,每一块都有一个map task。
补充面试问题:
* block块大小的设置:
* HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在Hadoop2.x版本中是128M,老版本中是64M。
*
* 为什么是128MB:
* block块的大小主要取决于磁盘传输速率.
* 一般hdfs的寻址时间为10ms左右.
* 当寻址时间为传输时间的1%时为最佳状态,因此传输时间大概在1s左右.
* 机械硬盘文件顺序读写的速度为100MB/s,普通固态为500MB/s,pcie固态的速度可以达到2000MB/s,因此块的大小可以分别设为128MB,512MB,2048MB.
*
* block块的大小主要取决于磁盘传输速率.
*
*
* 先将所有的块读出来 判断能否按照计算机生成的块分割(存在部分块的尾端文件没读完就结束) 通过InputSplit的指针 在最后的位置判断有没有读完
* 生成逻辑代码块(可能少于或者大于等于128M)
/**
* extends MyMapper<>
* 参数:
* LongWritable 第几行的行号
* Text 每一行读出的数据 因为 string不能改变大小 拼接序列化比较麻烦(比如拼接int) 所以新写入的一个类,底层是StringBuffer
* Text 最后输出的每一个 key
* IntWritable 输出的每一个key的个数
* /
public class WCMapper extends Mapper {
private Text out = new Text();
// 每个单词都传输个数为1
private IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 对参数的几个数据的处理与返回方法
* value 拿到的每一行的数据 先转成string进行分割
*/
String[] splits = value.toString().split(" ");
for (String word : splits) {
// 将分割好的 每个string 再转成 text
out.set(word);
// 存储 每一个 key 和 个数
context.write(out,one);
}
}
}
OutPutCollector 将收集到的(k,v)写入到环形缓冲区,然后由缓冲区写到磁盘上。默认的缓冲区大小是100M,溢出的百分比是0.8,也就是说当缓冲区中达到80M的时候就会往磁盘上写。如果map计算完成后的中间结果没有达到80M,最终也是要写到磁盘上的,因为它最终还是要形成文件。
在spill溢出前,会对数据进行分区和排序,即在缓冲区对每个(k,v)键值对hash一个partition值,值相同则在同一个区,同一分区根据key来排序。不同分区在缓冲区根据partition和key值进行排序。
多个溢出的文件再通过merge合并,采用归并排序,合并成一个大的分区且区内有序的溢出文件。
reduce task 根据自己的分区号,到各自的map task节点拷贝相同的partition的数据到reduce task磁盘工作目录,再通过merge归并排序成一个有序的大文件。
public class WCReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* 参数:
* Text :传输过来的key
* IntWritable : 传输过来的个数
* Text : 统计的每一个key
* IntWritable : 统计好的个数
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
/**
* Iterable values 可以理解成按key分好组的数组
*/
int sum = 0;
for (IntWritable num : values) {
sum+=num.get();
}
context.write(key,new IntWritable(sum));
}
}
测试:
public class Mydemo {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
// jar 包的入口
job.setJarByClass(Mydemo.class);
// jar 包的名字
job.setJobName("wc");
// 读取文件并用inputSpilt的getSplit方法对文件进行分割生成逻辑区 根据逻辑区的大小开启对应数量的Map Task
FileInputFormat.addInputPath(job,new Path("hdfs://192.168.56.122:9000/data/data.txt"));
// 结果写入的文件夹路径 这个文件夹要没有的自动生成
FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.56.122:9000/my1"));
//设置对应的Mapper类
job.setMapperClass(WCMapper.class);
//设置Mapper类的输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置对应的 Reduce类
job.setReducerClass(WCReduce.class);
//设置对应的Reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//启动job任务
job.waitForCompletion(true);
}
}
总结:
流程说明如下:
1、输入文件分片,每一片都由一个MapTask来处理
2、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
3、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
4、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。
5、以上只是一个map的输出,接下来进入reduce阶段
6、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
7、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
8、reduce输出