技术笔记外传二——用elasticsearch搭建自己的搜索框架(一)
在上一个系列的外传中,我们实现了用whoosh搭建的搜索框架。Whoosh作为纯python的搜索库,其使用方便简单,适合作为搜索方面的入门库。然而,elasticsearch由于其强大的分布式设计,以及易于扩容的特性,被更广泛地应用在各个商业场景中。在这个系列中,我们将使用elasticsearch来搭建我们的搜索框架,主要会涉及到以下方面:elasticsearch的安装及运行;建立elasticsearch索引;使用elasticsearch的Query DSL进行搜索等功能。
一 elasticsearch的安装及运行
elasticsearch提供了各种风格的安装包,包括deb,zip/tar.gz,rpm,msi以及docker。由于在我这里选择deb安装一直不成功,因此我选择了tar.gz进行安装。需要注意的一点是,elasticsearch需要java环境才能运行,因此在安装elasticsearch之前请确保安装了jdk1.8.0(官方推荐此版本)。
我们可以到如下网址下载elasticsearch的安装包:https://www.elastic.co/downloads/elasticsearch,在此选择自己喜欢的安装风格,这里以linux为例。当安装包下载好后,找到一个地方将其解压,然后进入elasticsearch下的bin目录,如下所示:

其中第一个文件就是elasticsearch的server端,输入./elasticsearch启动之,若看到以下画面说明启动成功:
elasticsearch默认使用的端口为9200,我们也可以在浏览器中输入127.0.0.1:9200来查看elasticsearch是否启动:
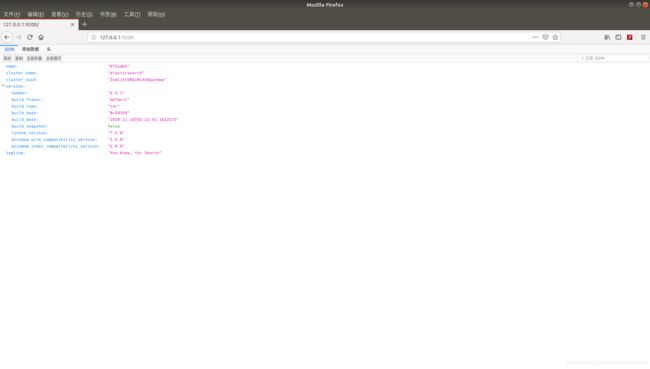
如果我们看到了以上画面,就说明elasticsearch启动了。
在成功启动后,我们可以自行根据elasticsearch的官方文档来了解一下elasticsearch的基本概念,以及通过cURL来建立一些索引,感受一下使用elasticsearch的搜索风格,以便我们在django中使用elasticsearch搜索。
二 开始搭建esengine框架——索引的建立及更新
首先我们需要在python环境下安装elasticsearch,输入以下命令完成安装:
pip3 install elasticsearch安装完成后,我们在django工程中建立一个新的app,命名为esengine,并将其加入到myblog/settings.py中的INSTALLED_APPS列表中:
# myblog/settings.py
# ...
INSTALLED_APPS = [
# ...
'esengine.apps.EsengineConfig',
]
# ...然后我们建立一个名为esenginecore.py的文件,顾名思义,此文件为esengine的核心,索引的建立以及更新都会在这个文件中实现。我们先来看建立索引的部分:
# esengine/esenginecore.py
class esengine:
def __init__(self):
self.es = Elasticsearch()
def __parsefieldname(self,fieldname):
return fieldname.__str__().split('.')[-1]
def __getforeignvalue(self,dedicatedmodel,obj):
modelschema = {}
modelfields = dedicatedmodel._meta.get_fields()
for field in modelfields:
if type(field) == CharField:
modelschema[dedicatedmodel.__name__ + '_' + self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == IntegerField:
modelschema[dedicatedmodel.__name__ + '_' + self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == FloatField:
modelschema[dedicatedmodel.__name__ + '_' + self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == DateField or type(field) == DateTimeField:
modelschema[dedicatedmodel.__name__ + '_' + self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == RichTextUploadingField:
modelschema[dedicatedmodel.__name__ + '_' + self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == ForeignKey:
subschema = self.__getforeignvalue(field.related_model)
modelschema.update(**subschema)
return modelschema
def createIndex(self,indexname,doctype,model):
if not self.es.indices.exists(indexname):
modelfields = model._meta.get_fields()
objectlist = model.objects.all()
docId = 0
for obj in objectlist:
singledoc = {}
for field in modelfields:
if type(field) == CharField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == RichTextUploadingField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == FloatField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == IntegerField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == DateField or type(field) == DateTimeField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == AutoField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == ForeignKey:
foreignobj = getattr(obj,self.__parsefieldname(field))
subvalue = self.__getforeignvalue(field.related_model,foreignobj)
singledoc.update(**subvalue)
print(singledoc)
docId = docId + 1
self.es.index(indexname,doctype,singledoc,docId)在构造函数中,我们建立一个Elasticsearch对象用于今后的索引、查询操作;然后是两个helper函数__parsefieldname和__getforeignvalue,这两个函数和在whoosh篇中的函数类似,这里不再赘述;接下来是对指定model的所有对象建立索引的函数createIndex,该函数接受三个参数:indexname,doctype以及model。indexname为索引名,可以理解为sql概念下的数据库名;doctype为文档类型,我们在此可以理解为sql概念下的表名(值得一提的是,doctype在elasticsearch6中被取消了,但是这里不妨碍我们继续使用它);而model就是指我们要对哪个model建立索引。
可以看到,我们建立索引的代码和之前用Whoosh建立索引的代码比较相似,然而又有些不同:相同的点是均会利用一个递归函数__getforeignvalue去获取对应的外键;不同的点是,elasticsearch没有whoosh那种schema的概念,而是直接将数据以json的形式组成文档存入,因此我们在建立索引时就要获取到model中每个对象的所有字段值,直接为每篇博客建立文档并将其存入elasticsearch。
在elasticsearch中,每篇文档都需要一个内部的id作为标志,因此我们这里设置个自增变量docId作为博客的内部id。我们使用index方法在指定的indexname中建立索引,这样我们就将model下的每个对象都存入了elasticsearch中。
接下来让我们看看更新索引的部分,同样和whoosh篇很相似:
# esengine/esenginecore.py
class esengine:
# ...
def __addOneDoc(self,indexname,doctype,model,objId):
obj = model.objects.get(id=objId)
modelfields = model._meta.get_fields()
singledoc = {}
for field in modelfields:
if type(field) == CharField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == RichTextUploadingField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == FloatField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == IntegerField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == DateField or type(field) == DateTimeField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == AutoField:
singledoc[self.__parsefieldname(field)] = getattr(obj, self.__parsefieldname(field))
elif type(field) == ForeignKey:
foreignobj = getattr(obj, self.__parsefieldname(field))
subvalue = self.__getforeignvalue(field.related_model, foreignobj)
singledoc.update(**subvalue)
print(singledoc)
docId = self.es.count(indexname,doctype)['count'] + 1
self.es.index(indexname, doctype, singledoc, docId)
def __getvalue(self, indexname, doctype, id, fieldname):
return self.es.get(indexname,id,doctype)['_source'][fieldname]
def updateIndex(self,indexname, doctype, model, updatefield):
index_id = set()
to_index_id = set()
print(updatefield)
#print(self.es.count(indexname,doctype))
indexfield = model._meta.get_fields()
objlist = model.objects.all()
for indexDocId in range(1,self.es.count(indexname,doctype)['count']+1):
#print(self.es.get(indexname,indexDocId,doctype))
docId = self.__getvalue(indexname,doctype,indexDocId,'id')
index_id.add(docId)
if not model.objects.get(id=docId):
# 数据库未找到此篇,则可能已被删除,故从index中删除此篇
print('delete')
self.es.delete(indexname, doctype, indexDocId)
else:
print('update')
# 根据updatefield的值进行更新
for field in indexfield:
# 根据updatefield进行更新
if self.__parsefieldname(field) == updatefield:
print(docId)
objfromdb = model.objects.get(id=docId)
contentofobj = getattr(objfromdb, updatefield)
contentofindex = self.__getvalue(indexname,doctype,indexDocId,updatefield)
if contentofobj != contentofindex:
print('content in index is %s,content in db is %s' % (contentofindex, contentofobj))
to_index_id.add(docId)
self.es.delete(indexname, doctype, indexDocId)
for obj in objlist:
if obj.id not in index_id or obj.id in to_index_id:
self.__addOneDoc(indexname,doctype,model,obj.id)
# ...这里同样是根据updatefield的值的变化来作为是否更新索引的依据。其实,我们这里写的updateIndex方法相当于重新实现了elasticsearch提供的update方法。根据官方文档,elasticsearch的update方法也是对已有的文档进行先删除后添加的方式进行update操作。这里不直接使用modify或update方法的原因在于,我们以updatefield的值是否变化来作为更新的依据,但并不表示每当更新updatefield值时没有其他字段跟着一块更新,而update或modify方法需要指定修改或更新的字段,我们在这里显然无法预判到底有哪些字段会一并修改,因此最好的方法便是将整篇文档删除后重新添加。
这篇文章为使用elasticsearch搭建搜索框架开了个头,实现了基于elasticsearch的索引建立以及更新操作。在后续的博客中,我将继续带来基于elasticsearch搜索的相关内容,希望大家继续关注~