AMS (2): AMS 如何进程管理?
这里看3个问题:
1. AMS 如何创建新进程?
2. AMS如何更新LRU?
3. AMS如何更新OOM_ADJ?
AMS对于进程的管理主要体现在两个方面:
第一是动态调整进程再mLruProcess中的位置,
第二就是调整进程的oom_adj的值,
这两项都和系统的内存自动回收有关系,当系统的内存不足时,
系统主要根据oom_adj的值来选择杀死一些进程以释放内存,这个值越大表示进程越容易被杀死。
AMS如何启动一个进程?
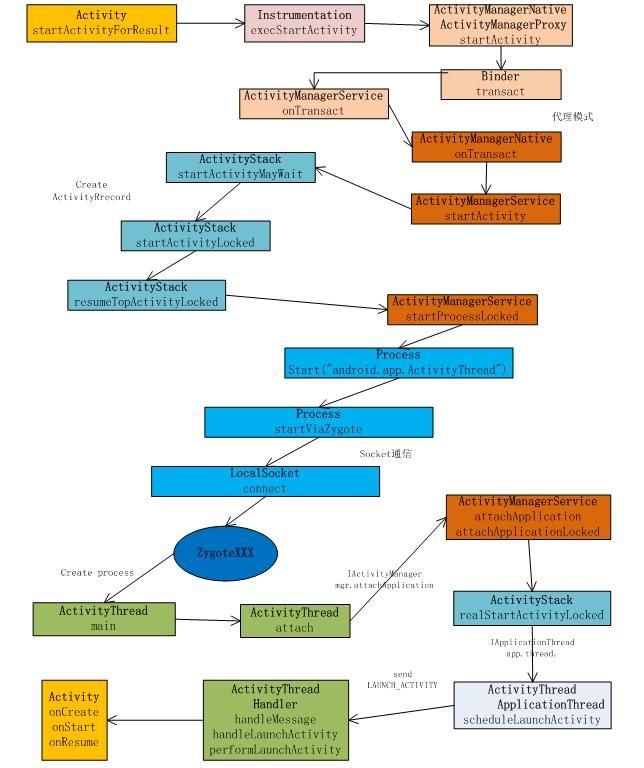
AMS是调用addAppLocked方法来启动一个进程的,这个方法实现如下:
final ProcessRecord addAppLocked(ApplicationInfo info, boolean isolated,
String abiOverride) {
ProcessRecord app;
//isolated 表示当前需要启动的App, 是不是一个独立的进程?
if (!isolated) { //如果不是独立进程,就从正在运行的进程列表中找
app = getProcessRecordLocked(info.processName, info.uid, true);
} else { //如果是独立进程,则重现创建一个ProcessRecord
app = null;
}
//这是一个独立的进程,或者在 正在运行的进程列表中没有找到记录
if (app == null) {
//创建一个新的ProcessReocrd对象
app = newProcessRecordLocked(info, null, isolated, 0);
//更新LRU列表和oom_adj值,后面具体分析
updateLruProcessLocked(app, false, null);
updateOomAdjLocked();
}
// This package really, really can not be stopped.
// 将这个App的包设置为启动状态,这样这个App就可以接受隐式Intent了
try {
AppGlobals.getPackageManager().setPackageStoppedState(
info.packageName, false, UserHandle.getUserId(app.uid));
} catch (RemoteException e) {
} catch (IllegalArgumentException e) {
Slog.w(TAG, "Failed trying to unstop package "
+ info.packageName + ": " + e);
}
//如果这个app带有PERSISTENT的话,将相应App打上标记
if ((info.flags & PERSISTENT_MASK) == PERSISTENT_MASK) {
app.persistent = true;
app.maxAdj = ProcessList.PERSISTENT_PROC_ADJ;
}
//如果App的主线程为空的话,
if (app.thread == null && mPersistentStartingProcesses.indexOf(app) < 0) {
mPersistentStartingProcesses.add(app);
//启动实际App
startProcessLocked(app, "added application", app.processName, abiOverride,
null /* entryPoint */, null /* entryPointArgs */);
}
return app;
}addAppLocked方法会根据参数isolated来决定这个进程是不是一个独立的进程,如果是那就创建一个新的ProcessRecord对象,如果不是的话,那就调用getProcessRecordLocked方法在当前运行的进程列表中查找进程,我们看下这个方法的定义:
final ProcessRecord getProcessRecordLocked(String processName, int uid, boolean keepIfLarge) {
//如果是一个系统级别的UID,也就是说这个App是由system用户启动的
if (uid == Process.SYSTEM_UID) {
// The system gets to run in any process. If there are multiple
// processes with the same uid, just pick the first (this
// should never happen).
// 如果是系统uid,就直接取第一个
SparseArray procs = mProcessNames.getMap().get(processName);
if (procs == null) return null;
final int procCount = procs.size();
for (int i = 0; i < procCount; i++) {
final int procUid = procs.keyAt(i);
if (UserHandle.isApp(procUid) || !UserHandle.isSameUser(procUid, uid)) {
// Don't use an app process or different user process for system component.
continue;
}
return procs.valueAt(i);
}
}
//如果不是系统UID的话,首先从mProcessNames中查找正在运行的进程记录
ProcessRecord proc = mProcessNames.get(processName, uid);
if (false && proc != null && !keepIfLarge //这个分支走不到,测试分支
&& proc.setProcState >= ActivityManager.PROCESS_STATE_CACHED_EMPTY
&& proc.lastCachedPss >= 4000) {
// Turn this condition on to cause killing to happen regularly, for testing.
if (proc.baseProcessTracker != null) {
proc.baseProcessTracker.reportCachedKill(proc.pkgList, proc.lastCachedPss);
}
proc.kill(Long.toString(proc.lastCachedPss) + "k from cached", true);
} else if (proc != null && !keepIfLarge //走这个分支,如果传递过来的KeepIfLarge是true, 也不会走这个分支
&& mLastMemoryLevel > ProcessStats.ADJ_MEM_FACTOR_NORMAL
&& proc.setProcState >= ActivityManager.PROCESS_STATE_CACHED_EMPTY) {
if (DEBUG_PSS) Slog.d(TAG_PSS, "May not keep " + proc + ": pss=" + proc.lastCachedPss);
if (proc.lastCachedPss >= mProcessList.getCachedRestoreThresholdKb()) {
if (proc.baseProcessTracker != null) {
proc.baseProcessTracker.reportCachedKill(proc.pkgList, proc.lastCachedPss);
}
proc.kill(Long.toString(proc.lastCachedPss) + "k from cached", true);
}
}
//直接返回
return proc;
} frameworks\base\core\java\android\os\userhandle.java:
public static boolean isApp(int uid) {
if (uid > 0) {
final int appId = getAppId(uid);
return appId >= Process.FIRST_APPLICATION_UID && appId <= Process.LAST_APPLICATION_UID;
} else {
return false;
}
}现在我们回到addAppLocked方法,我们刚才分析了如果不是独立进程的情况的逻辑,总结来说就是通过getProcessRecordLocked查找当前系统中正在运行的进程记录,并且把这个记录保存下来。现在我们看一下如果请求的是一个独立的进程的话(这也是最常见的情形),处理的方式是什么样的.
新建了一个ProcessRecord对象之后的操作就是最重要的操作了:
updateLruProcessLocked(app, false, null);
updateOomAdjLocked();我们稍后详细分析,我们先接下来的逻辑,接下来的逻辑中最重要的就是调用startProcessLocked方法实际启动一个进程:
mPersistentStartingProcesses.add(app);
startProcessLocked(app, "added application", app.processName, abiOverride,
null /* entryPoint */, null /* entryPointArgs */); private final void startProcessLocked(ProcessRecord app, String hostingType,
String hostingNameStr, String abiOverride, String entryPoint, String[] entryPointArgs) {
long startTime = SystemClock.elapsedRealtime(); //首先需要记录一下app的启动时间
if (app.pid > 0 && app.pid != MY_PID) {
checkTime(startTime, "startProcess: removing from pids map"); //这个startTime是给checkTime方法使用的
synchronized (mPidsSelfLocked) {
mPidsSelfLocked.remove(app.pid);
mHandler.removeMessages(PROC_START_TIMEOUT_MSG, app);
}
checkTime(startTime, "startProcess: done removing from pids map");
app.setPid(0);
}
[email protected]
private void checkTime(long startTime, String where) {
long now = SystemClock.uptimeMillis();
if ((now-startTime) > 50) {
// If we are taking more than 50ms, log about it.
Slog.w(TAG, "Slow operation: " + (now-startTime) + "ms so far, now at " + where);
}
}我们继续startProcessLocked的分析:
if (app.pid > 0 && app.pid != MY_PID) {
checkTime(startTime, "startProcess: removing from pids map");
synchronized (mPidsSelfLocked) {
mPidsSelfLocked.remove(app.pid);
mHandler.removeMessages(PROC_START_TIMEOUT_MSG, app);
}
checkTime(startTime, "startProcess: done removing from pids map");
app.setPid(0);
}然后就是移除PROC_START_TIMEOUT_MSG消息,这个消息是AMS用来控制app启动时间的,如果启动超时了就发出效果消息,下面我们会设置这个消息,现在需要取消之前设置的消息,防止干扰。
接下来的逻辑:
mProcessesOnHold.remove(app);这里是将app进程从mProcessesOnHold列表中清除,这个列表是什么呢?这个列表是系统中在AMS没有启动之前请求启动的app,这些app当时没有启动,被hold了,当AMS启动完成的时候需要将他们启动;现在如果我们启动的app就在这个列表中的, 那么自然需要将它移除,防止重复启动。我们可以从mProcessesOnHold的定义的地方看到这一点:
/**
* List of records for processes that someone had tried to start before the
* system was ready. We don't start them at that point, but ensure they
* are started by the time booting is complete.
*/
final ArrayList mProcessesOnHold = new ArrayList(); 接下来就要更新cpu使用统计信息:
checkTime(startTime, "startProcess: starting to update cpu stats");
updateCpuStats();
checkTime(startTime, "startProcess: done updating cpu stats"); void updateCpuStats() {
final long now = SystemClock.uptimeMillis();
if (mLastCpuTime.get() >= now - MONITOR_CPU_MIN_TIME) { //5s采样一次
return;
}
if (mProcessCpuMutexFree.compareAndSet(true, false)) {
synchronized (mProcessCpuThread) {
mProcessCpuThread.notify();
}
}
}工作的方式就是唤醒mProcessCpuThread去采集cpu的信息。这个线程的实现我们这里先不分析,这块和我们的进程管理相关不是很密切,我后面的文章会详细分析这块的内容。
在startProcessLocked的接下来的逻辑中,主要就是app启动的一些参数设置,条件检查等操作,这里我们直接略过,我们直接看实际进程启动的部分:
// Start the process. It will either succeed and return a result containing
// the PID of the new process, or else throw a RuntimeException.
boolean isActivityProcess = (entryPoint == null);
if (entryPoint == null) entryPoint = "android.app.ActivityThread";
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "Start proc: " +
app.processName);
checkTime(startTime, "startProcess: asking zygote to start proc");
Process.ProcessStartResult startResult = Process.start(entryPoint, //实际启动进程
app.processName, uid, uid, gids, debugFlags, mountExternal,
app.info.targetSdkVersion, app.info.seinfo, requiredAbi, instructionSet,
app.info.dataDir, entryPointArgs);
checkTime(startTime, "startProcess: returned from zygote!");
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);frameworks\base\core\java\android\os\process.java
public static final ProcessStartResult start(final String processClass,
final String niceName,
int uid, int gid, int[] gids,
int debugFlags, int mountExternal,
int targetSdkVersion,
String seInfo,
String abi,
String instructionSet,
String appDataDir,
String[] zygoteArgs) {
try {
return startViaZygote(processClass, niceName, uid, gid, gids,
debugFlags, mountExternal, targetSdkVersion, seInfo,
abi, instructionSet, appDataDir, zygoteArgs);
} catch (ZygoteStartFailedEx ex) {
Log.e(LOG_TAG,
"Starting VM process through Zygote failed");
throw new RuntimeException(
"Starting VM process through Zygote failed", ex);
}
}Step:
我们再次回到startProcessLocked方法中分析剩下的逻辑,刚才我们上面的请求zygote的部分是一个异步请求,会立即返回,当时实际进程启动需要多长的时间是不确定的,但是我们不能无限制等待,需要有一个启动超时机制,在startProcessLocked接下来的逻辑中就启动了一个延迟消息:
checkTime(startTime, "startProcess: starting to update pids map");
synchronized (mPidsSelfLocked) {
ProcessRecord oldApp;
// If there is already an app occupying that pid that hasn't been cleaned up
if ((oldApp = mPidsSelfLocked.get(startResult.pid)) != null && !app.isolated) {
// Clean up anything relating to this pid first
Slog.w(TAG, "Reusing pid " + startResult.pid
+ " while app is still mapped to it");
cleanUpApplicationRecordLocked(oldApp, false, false, -1,
true /*replacingPid*/);
}
this.mPidsSelfLocked.put(startResult.pid, app);
if (isActivityProcess) {
Message msg = mHandler.obtainMessage(PROC_START_TIMEOUT_MSG);
msg.obj = app;
mHandler.sendMessageDelayed(msg, startResult.usingWrapper
? PROC_START_TIMEOUT_WITH_WRAPPER : PROC_START_TIMEOUT);
}
}
checkTime(startTime, "startProcess: done updating pids map");为了弄清楚假如发生了启动超时,系统怎么处理,我们还需要看一下mHandler对这个消息的处理:
case PROC_START_TIMEOUT_MSG: {
if (mDidDexOpt) { //如果处于dex优化过程中
mDidDexOpt = false;
Message nmsg = mHandler.obtainMessage(PROC_START_TIMEOUT_MSG); //再等10秒
nmsg.obj = msg.obj;
mHandler.sendMessageDelayed(nmsg, PROC_START_TIMEOUT);
return;
}
ProcessRecord app = (ProcessRecord)msg.obj;
synchronized (ActivityManagerService.this) {
processStartTimedOutLocked(app); //处理启动超时的数据和资源回收的操作
}
} break;我们看下mDidDexOpt的定义就知道了:
/**
* This is set if we had to do a delayed dexopt of an app before launching
* it, to increase the ANR timeouts in that case.
*/
boolean mDidDexOpt;到现在位置我们弄明白了android是怎么启动一个app进程的了,主要就是通过addAppLocked方法实现,这个方法会调用startProcessLocked方法实现,而这个方法很长,主要就是一些app进程启动数据和参数检查和设置,最后就是调用Process类的静态方法start方法和zygote建立链接fork进程。

了解了AMS怎么启动一个进程之后,我们接下来分析一下AMS怎么管理进程的。
AMS的进程管理之LRU管理
前面我们在分析app进程的启动流程的时候,我们看到系统调用updateLruProcessLocked和updateOomAdjLocked来调控设置进程,其实在AMS中有很多地方都会调用到他们。
我们首先来看下updateLruProcessLocked方法,这个方法用来调整某个进程在mLruProcesses列表中的位置,mLruProcesses是最近使用进程列表的意思。
每当进程中的activity或者service等组件发生变化的时候,就意味着相应的进程发生了活动,因此调用这个方法将该进程调整到尽可能高的位置,同时还要更新关联进程的位置。在mLruProcesses这个列表中,最近运行的进程是从前往后排列的,也就是说越是处于前端的这个进程就越是最近使用的,同时需要注意的是拥有activity的进程的位置总是高于只有service的进程,因为activity可以和用户发生实际的交互,而后台的service是不可以的。
还要需要说明的是,在分析LRU管理机制之前,我们需要关注以下两个变量:
/**
* Where in mLruProcesses that the processes hosting activities start.
*/
int mLruProcessActivityStart = 0;
/**
* Where in mLruProcesses that the processes hosting services start.
* This is after (lower index) than mLruProcessesActivityStart.
*/
int mLruProcessServiceStart = 0;第一个变量总是指向列表中位置最高的带有activity进程和没有activity只有service的进程,
并且mLruProcessServiceStart总是在mLruProcessActivityStart的后面。还需要注意的是mLruProcesses的定义:
/**
* List of running applications, sorted by recent usage.
* The first entry in the list is the least recently used.
*/
final ArrayList mLruProcesses = new ArrayList(); 我们看到mLruProcesses只是一个ArrayList,在mLruProcesses中,某个成员的index越大,就表示这个app越是最近使用的,这一点在后面的分析中很重要。
接下来我们看一下updateLruProcessLocked的实现,这个方法比较长,我们分段来分析这个方法的实现:
final void updateLruProcessLocked(ProcessRecord app, boolean activityChange,
ProcessRecord client) {
final boolean hasActivity = app.activities.size() > 0 || app.hasClientActivities
|| app.treatLikeActivity;
final boolean hasService = false; // not impl yet. app.services.size() > 0;
1. app本身确实包含activity组件;
2. app本身有service,并且有另外一个含有activity的app链接到此app的service上;
3. 该app启动serivce的时候带有标记BIND_TREAT_LIKE_ACTIVITY。
if (!activityChange && hasActivity) {
// The process has activities, so we are only allowing activity-based adjustments
// to move it. It should be kept in the front of the list with other
// processes that have activities, and we don't want those to change their
// order except due to activity operations.
return; //这种情况下,没有必要更新LRU
}这里的代码中注释写的很清楚,这里的意思就是,如果当前app中有activity组件,并且不是activity发生了改变(启动或者销毁等),那就直接返回,因为这个时候没有必要更新LRU。
我们继续看下面的代码:
mLruSeq++; //计数器,记录该函数被调用了多少次,也就是LRU被更新了多少次。
//记录更新时间
final long now = SystemClock.uptimeMillis();
app.lastActivityTime = now;
// First a quick reject: if the app is already at the position we will
// put it, then there is nothing to do.
if (hasActivity) {
final int N = mLruProcesses.size();
if (N > 0 && mLruProcesses.get(N-1) == app) { //如果要插入的app已经在mLruProcesses顶端了,就不用插入了
if (DEBUG_LRU) Slog.d(TAG_LRU, "Not moving, already top activity: " + app);
return;
}
} else {
if (mLruProcessServiceStart > 0
&& mLruProcesses.get(mLruProcessServiceStart-1) == app) {
if (DEBUG_LRU) Slog.d(TAG_LRU, "Not moving, already top other: " + app);
return;
}
} int lrui = mLruProcesses.lastIndexOf(app);
if (app.persistent && lrui >= 0) {
// We don't care about the position of persistent processes, as long as
// they are in the list.
if (DEBUG_LRU) Slog.d(TAG_LRU, "Not moving, persistent: " + app);
return;
}继续看代码:
if (lrui >= 0) {
if (lrui < mLruProcessActivityStart) {
mLruProcessActivityStart--;
}
if (lrui < mLruProcessServiceStart) {
mLruProcessServiceStart--;
}1. 如果小于mLruProcessActivityStart,那么mLruProcessActivityStart需要减1,
2. 同理如果小于mLruProcessServiceStart,那么mLruProcessServiceStart也需要减1,这两个变量的含义上面已经解释,
这里操作因为我们下面即将remove掉这个app进程记录(我们要把它放到合适的地方去),所以这里都要减1.
接下来的代码就是主要操作代码了,分为3种情况操作:有activity的,有service的(没有实现,我们略过),其他的(暂时可以理解为有service的)。
case 1: 我们首先看一下有activity的情况:
int nextIndex;
if (hasActivity) {
final int N = mLruProcesses.size();
//这个分支:该App没有Activity, 但是链接到它的service的App有Activity,
//就把该App添加到mLruProcessActivityStart的第二位,因为第一位必须是包含实际Activity的App
if (app.activities.size() == 0 && mLruProcessActivityStart < (N - 1)) {
// Process doesn't have activities, but has clients with
// activities... move it up, but one below the top (the top
// should always have a real activity).
if (DEBUG_LRU) Slog.d(TAG_LRU,
"Adding to second-top of LRU activity list: " + app);
mLruProcesses.add(N - 1, app);
// To keep it from spamming the LRU list (by making a bunch of clients),
// we will push down any other entries owned by the app.
// 为了防止某个app中的service绑定了一群client从而导致LRU中顶部大部分都是这些client
//,这里需要将这些client往下移动,以防止某些app通过和某个app的service绑定从而提升自己在LRU中位置。
final int uid = app.info.uid;
for (int i = N - 2; i > mLruProcessActivityStart; i--) {
ProcessRecord subProc = mLruProcesses.get(i);
if (subProc.info.uid == uid) {
// We want to push this one down the list. If the process after
// it is for the same uid, however, don't do so, because we don't
// want them internally to be re-ordered.
if (mLruProcesses.get(i - 1).info.uid != uid) {
if (DEBUG_LRU) Slog.d(TAG_LRU,
"Pushing uid " + uid + " swapping at " + i + ": "
+ mLruProcesses.get(i) + " : " + mLruProcesses.get(i - 1));
ProcessRecord tmp = mLruProcesses.get(i);
mLruProcesses.set(i, mLruProcesses.get(i - 1));
mLruProcesses.set(i - 1, tmp);
i--;
}
} else {
// A gap, we can stop here.
break;
}
}else { //如果进程有Activity, 就把它放到mLruProcesses的顶端 (一般情况下走这个流程)
// Process has activities, put it at the very tipsy-top.
if (DEBUG_LRU) Slog.d(TAG_LRU, "Adding to top of LRU activity list: " + app);
mLruProcesses.add(app);
}
nextIndex = mLruProcessServiceStart;
} 我们继续看接下来的代码:
else if (hasService) { //不走这个分支,hasService 总是false
// Process has services, put it at the top of the service list.
if (DEBUG_LRU) Slog.d(TAG_LRU, "Adding to top of LRU service list: " + app);
mLruProcesses.add(mLruProcessActivityStart, app);
nextIndex = mLruProcessServiceStart;
mLruProcessActivityStart++;
} else { //一般走这里,可以理解为hasService的情况
// Process not otherwise of interest, it goes to the top of the non-service area.
// 我们直接定义index为mLruProcessServiceStart的位置,因为此时的位置最高只能是mLruProcessServiceStart这个位置
int index = mLruProcessServiceStart;
if (client != null) { //一般情况下client == null, 这个分支不走
// If there is a client, don't allow the process to be moved up higher
// in the list than that client.
int clientIndex = mLruProcesses.lastIndexOf(client);
if (DEBUG_LRU && clientIndex < 0) Slog.d(TAG_LRU, "Unknown client " + client
+ " when updating " + app);
if (clientIndex <= lrui) {
// Don't allow the client index restriction to push it down farther in the
// list than it already is.
clientIndex = lrui;
}
if (clientIndex >= 0 && index > clientIndex) {
index = clientIndex;
}
}
if (DEBUG_LRU) Slog.d(TAG_LRU, "Adding at " + index + " of LRU list: " + app);
//将App进程对象插入到index的位置
mLruProcesses.add(index, app);
nextIndex = index-1;
mLruProcessActivityStart++;
mLruProcessServiceStart++;
} // If the app is currently using a content provider or service,
// bump those processes as well.
for (int j=app.connections.size()-1; j>=0; j--) {
ConnectionRecord cr = app.connections.valueAt(j);
if (cr.binding != null && !cr.serviceDead && cr.binding.service != null
&& cr.binding.service.app != null
&& cr.binding.service.app.lruSeq != mLruSeq
&& !cr.binding.service.app.persistent) {
nextIndex = updateLruProcessInternalLocked(cr.binding.service.app, now, nextIndex,
"service connection", cr, app);
}
}
for (int j=app.conProviders.size()-1; j>=0; j--) {
ContentProviderRecord cpr = app.conProviders.get(j).provider;
if (cpr.proc != null && cpr.proc.lruSeq != mLruSeq && !cpr.proc.persistent) {
nextIndex = updateLruProcessInternalLocked(cpr.proc, now, nextIndex,
"provider reference", cpr, app);
}
}[email protected]
private int updateLruProcessInternalLocked(ProcessRecord app, long now, int index,
String what, Object obj, ProcessRecord srcApp) {
app.lastActivityTime = now;
//如果有Activity,不做调整
if (app.activities.size() > 0) {
// Don't want to touch dependent processes that are hosting activities.
return index;
}
//如果进程不在mLruProcess中,就返回
int lrui = mLruProcesses.lastIndexOf(app);
if (lrui < 0) {
Slog.wtf(TAG, "Adding dependent process " + app + " not on LRU list: "
+ what + " " + obj + " from " + srcApp);
return index;
}
//如果进程的位置高于需要调整的位置,不做调整
if (lrui >= index) {
// Don't want to cause this to move dependent processes *back* in the
// list as if they were less frequently used.
return index;
}
//如果目前进程的位置比mLruProcessActivityStart还要高,不调整
if (lrui >= mLruProcessActivityStart) {
// Don't want to touch dependent processes that are hosting activities.
return index;
}
//把App调整到index-1的位置
mLruProcesses.remove(lrui);
if (index > 0) {
index--;
}
if (DEBUG_LRU) Slog.d(TAG_LRU, "Moving dep from " + lrui + " to " + index
+ " in LRU list: " + app);
mLruProcesses.add(index, app);
return index;
}
到这里我们就基本分析完了LRU的更新过程,现在我们总结一下它的流程:updateLruProcessLocked方法中调整进程很重要的一个依据就是进程有没有活动的activity,除了进程本身存在activity对象外,如果和进程中运行的serivice相关联的客户进程中有activity也算是本进程拥有activity。如果一个进程拥有activity的话,那么把这个进程放到列表的最高位置,否则只会把它放到没有activity的前面。调整某个进程的位置之后,还有调整和该进程的关联进程的位置,进程的关联进程有两种类型:绑定本进程servrice的进程和链接了本进程的ContentProvider的进程。同时,如果这些进程本身是有activity的话,那么就不调整,需要调整的是那些没有activity的进程,在updateLruProcessInternalLocked方法中会做这种调整。
AMS的进程管理之oom_adj管理
在介绍AMS的进程oom_adj管理之前,我们先了解一下什么是oom_adj。我们知道android运行的设备一般都是内存资源比较有限的嵌入式移动设备,在这些设备上的内存资源是十分宝贵的,因此我们需要妥善的使用和管理,总的来说就是:在合适的时候,将必要的内存资源释放出来。传统的Linux的做法就是将不需要的进程直接杀死,为重要的进程运行腾出“空”来。但是问题来了,你根据什么来决定是否杀死一个进程呢?或者说你怎么知道某个进程是可以杀死的?仿照linux的做法,我们可以给每一个进程标记一个优先级,但是android中的进程和linux中的进程又不太一样了,进程之间可以通过binder绑定,如果杀死绑定的一端,另一端也可能会出问题。那么android是怎么做的呢,android引入了oom_adj这个东西,所谓的oom_adj就是out of memory adjustment中文叫做内存溢出调节器,这么翻译有点生硬,说的简单点这个东西就是一个用来标记某个app进程的重要性,这个值越小说明它越重要,越大就越有可能在必要的时候被“干掉”。

其中红色部分代表比较容易被杀死的 Android 进程(OOM_ADJ>=4),绿色部分表示不容易被杀死的 Android 进程,其他表示非 Android 进程(纯 Linux 进程)。在 Lowmemorykiller 回收内存时会根据进程的级别优先杀死 OOM_ADJ 比较大的进程,对于优先级相同的进程则进一步受到进程所占内存和进程存活时间的影响。
Android 手机中进程被杀死可能有如下情况:
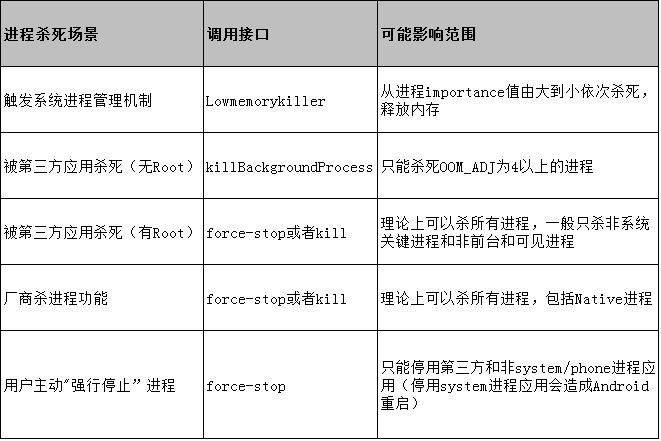
综上,可以得出减少进程被杀死概率无非就是想办法提高进程优先级,减少进程在内存不足等情况下被杀死的概率。
下面我们先看一下android中都定义了那些oom_adj的值,这些值定义在/frameworks/base/services/core/java/com/android/server/am/ProcessList.java中:
6.0以后,oom_adj定义的初始值,已经变了:
final class ProcessList {
private static final String TAG = TAG_WITH_CLASS_NAME ? "ProcessList" : TAG_AM;
// The minimum time we allow between crashes, for us to consider this
// application to be bad and stop and its services and reject broadcasts.
static final int MIN_CRASH_INTERVAL = 60*1000;
// OOM adjustments for processes in various states:
// Uninitialized value for any major or minor adj fields
static final int INVALID_ADJ = -10000;
// Adjustment used in certain places where we don't know it yet.
// (Generally this is something that is going to be cached, but we
// don't know the exact value in the cached range to assign yet.)
static final int UNKNOWN_ADJ = 1001;
// This is a process only hosting activities that are not visible,
// so it can be killed without any disruption.
static final int CACHED_APP_MAX_ADJ = 906;
static final int CACHED_APP_MIN_ADJ = 900;
// The B list of SERVICE_ADJ -- these are the old and decrepit
// services that aren't as shiny and interesting as the ones in the A list.
static final int SERVICE_B_ADJ = 800;
// This is the process of the previous application that the user was in.
// This process is kept above other things, because it is very common to
// switch back to the previous app. This is important both for recent
// task switch (toggling between the two top recent apps) as well as normal
// UI flow such as clicking on a URI in the e-mail app to view in the browser,
// and then pressing back to return to e-mail.
static final int PREVIOUS_APP_ADJ = 700;
// This is a process holding the home application -- we want to try
// avoiding killing it, even if it would normally be in the background,
// because the user interacts with it so much.
static final int HOME_APP_ADJ = 600;
// This is a process holding an application service -- killing it will not
// have much of an impact as far as the user is concerned.
static final int SERVICE_ADJ = 500;
// This is a process with a heavy-weight application. It is in the
// background, but we want to try to avoid killing it. Value set in
// system/rootdir/init.rc on startup.
static final int HEAVY_WEIGHT_APP_ADJ = 400;
// This is a process currently hosting a backup operation. Killing it
// is not entirely fatal but is generally a bad idea.
static final int BACKUP_APP_ADJ = 300;
// This is a process only hosting components that are perceptible to the
// user, and we really want to avoid killing them, but they are not
// immediately visible. An example is background music playback.
static final int PERCEPTIBLE_APP_ADJ = 200;
// This is a process only hosting activities that are visible to the
// user, so we'd prefer they don't disappear.
static final int VISIBLE_APP_ADJ = 100;
static final int VISIBLE_APP_LAYER_MAX = PERCEPTIBLE_APP_ADJ - VISIBLE_APP_ADJ - 1;
// This is the process running the current foreground app. We'd really
// rather not kill it!
static final int FOREGROUND_APP_ADJ = 0;
// This is a process that the system or a persistent process has bound to,
// and indicated it is important.
static final int PERSISTENT_SERVICE_ADJ = -700;
// This is a system persistent process, such as telephony. Definitely
// don't want to kill it, but doing so is not completely fatal.
static final int PERSISTENT_PROC_ADJ = -800;
// The system process runs at the default adjustment.
static final int SYSTEM_ADJ = -900;
// Special code for native processes that are not being managed by the system (so
// don't have an oom adj assigned by the system).
static final int NATIVE_ADJ = -1000;
FOREGROUND_APP_ADJ:这表示进程有一个正在和用户交互的界面,这个千万不能杀死,除非万不得已。
VISIBLE_APP_ADJ:这个表示进程中的某个UI组件是可以被用户看见的,但是并没有和用户发生交互,比如一个被dialog挡住部分的activity,这个进程也是尽量不能杀死的,因为用户是可以看见它的,杀死的话会影响用户的体验。
PERCEPTIBLE_APP_ADJ:正如注释里面说的那样,这个adj表示进程中的某个组件可以被用户感知到,比如说一个正在播放音乐的进程。
BACKUP_APP_ADJ:当前进程正在执行一个备份的操作,这个操作最好不要打断,否则会出现不可修复的数据错误。
CACHED_APP_MIN_ADJ:这是cache进程的最小的adj的值
CACHED_APP_MAX_ADJ:cache进程的最大adj的值
当Background process中的后台activity被destroy的时候他就变成了空进程。空进程是所有进程中优先级最低的,是最可能被杀死的进程。
回到我们刚才说的cache进程,所谓的cache进程就是上面说的Background process。当我们的进程没有任何后台的时候,如果它退出了前台,android系统是不会立即将它杀死的。因为,用户很可能还会在不就的将来再次回到这个应用中,这个时候如果我们把它cache起来了,下次用户再次启动这个进程的时候速度就快了,这对于用户体验是很重要的;另外,这些cache进程确实占用了内存,如果我们需要内存的时候,就首先杀死这些cache进程。
举个形象点的例子,android中的所有的进程就像监狱中的犯人,而cache进程就是那些被判死刑,但是缓期执行的犯人。
理解了什么是cache进程之后,我们开始分析AMS是怎么管理oom_adj的。所谓的oom_adj的管理就是为每一个进程设置一个合理的oom_adj值。在AMS中,oom_adj值的设置是通过updateOomAdjLocked方法完成,这个方法比较长,我们分段来分析:
final void updateOomAdjLocked() {
final ActivityRecord TOP_ACT = resumedAppLocked();
final ProcessRecord TOP_APP = TOP_ACT != null ? TOP_ACT.app : null;
final long now = SystemClock.uptimeMillis();
final long nowElapsed = SystemClock.elapsedRealtime();
final long oldTime = now - ProcessList.MAX_EMPTY_TIME;
final int N = mLruProcesses.size();这里还要注意的是oldTime,oldTime是用当前时间减去MAX_EMPTY_TIME获得的,MAX_EMPTY_TIME的定义如下:
// We allow empty processes to stick around for at most 30 minutes.
static final long MAX_EMPTY_TIME = 30*60*1000;我们继续updateOomAdjLocked的分析:
// Reset state in all uid records.
for (int i=mActiveUids.size()-1; i>=0; i--) {
final UidRecord uidRec = mActiveUids.valueAt(i);
if (false && DEBUG_UID_OBSERVERS) Slog.i(TAG_UID_OBSERVERS,
"Starting update of " + uidRec);
uidRec.reset();
} public void reset() {
curProcState = ActivityManager.PROCESS_STATE_CACHED_EMPTY;
}
/**
* Track all uids that have actively running processes.
*/
final SparseArray mActiveUids = new SparseArray<>(); PID:为Process Identifier, PID就是各进程的身份标识,程序一运行系统就会自动分配给进程一个独一无二的PID。进程中止后PID被系统回收,可能会被继续分配给新运行的程序,但是在android系统中一般不会把已经kill掉的进程ID重新分配给新的进程,新产生进程的进程号,一般比产生之前所有的进程号都要大。
UID:一般理解为User Identifier,UID在linux中就是用户的ID,表明时哪个用户运行了这个程序,主要用于权限的管理。而在android 中又有所不同,因为android为单用户系统,这时UID 便被赋予了新的使命,数据共享,为了实现数据共享,android为每个应用几乎都分配了不同的UID,不像传统的linux,每个用户相同就为之分配相同的UID。(当然这也就表明了一个问题,android只能时单用户系统,在设计之初就被他们的工程师给阉割了多用户),使之成了数据共享的工具。
因此在android中PID,和UID都是用来识别应用程序的身份的,但UID是为了不同的程序来使用共享的数据。
这里的注释说的很清楚了。返回到updateOomAdjLocked中,我们把mActiveUids每一个UidRecord的当前进程状态reset为PROCESS_STATE_CACHED_EMPTY,是因为我们下面需要给他一个合适的值。
继续:我们继续查看updateOomAdjLocked接下来的代码:
mStackSupervisor.rankTaskLayersIfNeeded();
mAdjSeq++;
mNewNumServiceProcs = 0;
mNewNumAServiceProcs = 0;接下来,就是获得系统后台进程限制的情况了:
final int emptyProcessLimit; //表示后台可以运行的空进程的数量
final int cachedProcessLimit; //表示后台可以运行的缓存进程的数量
if (mProcessLimit <= 0) { //mProcessList表示后台进程的数量 (Cache + empty)
emptyProcessLimit = cachedProcessLimit = 0;
} else if (mProcessLimit == 1) {
emptyProcessLimit = 1;
cachedProcessLimit = 0;
} else {
emptyProcessLimit = ProcessList.computeEmptyProcessLimit(mProcessLimit);
cachedProcessLimit = mProcessLimit - emptyProcessLimit;
}
int mProcessLimit = ProcessList.MAX_CACHED_APPS; //初始值32MAX_CACHED_APPS定义如下:
// The maximum number of cached processes we will keep around before killing them.
// NOTE: this constant is *only* a control to not let us go too crazy with
// keeping around processes on devices with large amounts of RAM. For devices that
// are tighter on RAM, the out of memory killer is responsible for killing background
// processes as RAM is needed, and we should *never* be relying on this limit to
// kill them. Also note that this limit only applies to cached background processes;
// we have no limit on the number of service, visible, foreground, or other such
// processes and the number of those processes does not count against the cached
// process limit.
static final int MAX_CACHED_APPS = 32;我们看到了,初始值系统中的所有后台进程,也就是空进程和cache进程的总和不能超过32个。但是,用户可以设置这个值,在settings的开发者选项中可以设置。
不过一般情况下,这个值都是32.
现在我们就以32为值来分析一下代码,我们看到上面的代码中最终会走到最后一个分支,这个分支中针对emptyProcessLimit和cachedProcessLimit分别赋值,emptyProcessLimit的值是通过ProcessList的computeEmptyProcessLimit获取的:
[email protected]
public static int computeEmptyProcessLimit(int totalProcessLimit) {
return totalProcessLimit/2;
}
继续看代码:
// Let's determine how many processes we have running vs.
// how many slots we have for background processes; we may want
// to put multiple processes in a slot of there are enough of
// them.
int numSlots = (ProcessList.CACHED_APP_MAX_ADJ
- ProcessList.CACHED_APP_MIN_ADJ + 1) / 2;
int numEmptyProcs = N - mNumNonCachedProcs - mNumCachedHiddenProcs;
if (numEmptyProcs > cachedProcessLimit) {
// If there are more empty processes than our limit on cached
// processes, then use the cached process limit for the factor.
// This ensures that the really old empty processes get pushed
// down to the bottom, so if we are running low on memory we will
// have a better chance at keeping around more cached processes
// instead of a gazillion empty processes.
numEmptyProcs = cachedProcessLimit;
}
int emptyFactor = numEmptyProcs/numSlots;
if (emptyFactor < 1) emptyFactor = 1;
int cachedFactor = (mNumCachedHiddenProcs > 0 ? mNumCachedHiddenProcs : 1)/numSlots;
if (cachedFactor < 1) cachedFactor = 1;
int stepCached = 0;
int stepEmpty = 0;
int numCached = 0;
int numEmpty = 0;
int numTrimming = 0;
mNumNonCachedProcs = 0;
mNumCachedHiddenProcs = 0;然后是计算了空进程的数目,直接用mLruProcesses总数目减去mNumNonCachedProcs(非cache进程,正常进程)和mNumCachedHiddenProcs(cache进程)得到。然后就是emptyFactor(每个slot的empty的进程数)和cachedFactor(每个slot的cache进程数)的计算,方法是对应的总数目除以slot数目。这些变量有什么意义呢?下面的代码给了我们答案:
// First update the OOM adjustment for each of the
// application processes based on their current state.
int curCachedAdj = ProcessList.CACHED_APP_MIN_ADJ;
int nextCachedAdj = curCachedAdj+1;
int curEmptyAdj = ProcessList.CACHED_APP_MIN_ADJ;
int nextEmptyAdj = curEmptyAdj+2;
for (int i=N-1; i>=0; i--) { //从mLruProcess的顶部,循环操作
ProcessRecord app = mLruProcesses.get(i);
//如果App没有被AMS杀死,并且主线程不为空的话(正在运行),则
if (!app.killedByAm && app.thread != null) {
app.procStateChanged = false;
//通过computeOomAdjLocked()计算该App的 oom_adj值,非常重要!后面详细分析
computeOomAdjLocked(app, ProcessList.UNKNOWN_ADJ, TOP_APP, true, now);
// If we haven't yet assigned the final cached adj
// to the process, do that now.
// 如果当前ADJ值还是比UNKNOWN_ADJ 大,说明该进程是空进程或者cache进程
if (app.curAdj >= ProcessList.UNKNOWN_ADJ) {
switch (app.curProcState) {
case ActivityManager.PROCESS_STATE_CACHED_ACTIVITY: //这两个case是cache进程
case ActivityManager.PROCESS_STATE_CACHED_ACTIVITY_CLIENT:
// This process is a cached process holding activities...
// assign it the next cached value for that type, and then
// step that cached level.
app.curRawAdj = curCachedAdj;
app.curAdj = app.modifyRawOomAdj(curCachedAdj); //通过modifyRawOomAdj调整当前app进程的oom_adj的值
if (DEBUG_LRU && false) Slog.d(TAG_LRU, "Assigning activity LRU #" + i
+ " adj: " + app.curAdj + " (curCachedAdj=" + curCachedAdj
+ ")");
//没有达到最大值CACHED_APP_MAX_ADJ
if (curCachedAdj != nextCachedAdj) {
stepCached++;
// 如果当前slot中的cache进程数大于前面算出的cachedFactor的话就要进入下一个slot,
// 这么做的目的就是使得从CACHED_APP_MIN_ADJ到CACHED_APP_MAX_ADJ之间的cache进程数目分配均匀,
// 否则就会出现很多优先级相差很多的cache进程拥有相近的oom_adj的值,这样的结果是不合理的。
if (stepCached >= cachedFactor) {
stepCached = 0;
curCachedAdj = nextCachedAdj;
nextCachedAdj += 2;
if (nextCachedAdj > ProcessList.CACHED_APP_MAX_ADJ) {
nextCachedAdj = ProcessList.CACHED_APP_MAX_ADJ;
}
}
}
break;
//这个case就是empty进程了,处理的逻辑和上面的cache进程是一样的
default:
// For everything else, assign next empty cached process
// level and bump that up. Note that this means that
// long-running services that have dropped down to the
// cached level will be treated as empty (since their process
// state is still as a service), which is what we want.
app.curRawAdj = curEmptyAdj;
app.curAdj = app.modifyRawOomAdj(curEmptyAdj);
if (DEBUG_LRU && false) Slog.d(TAG_LRU, "Assigning empty LRU #" + i
+ " adj: " + app.curAdj + " (curEmptyAdj=" + curEmptyAdj
+ ")");
if (curEmptyAdj != nextEmptyAdj) {
stepEmpty++;
if (stepEmpty >= emptyFactor) {
stepEmpty = 0;
curEmptyAdj = nextEmptyAdj;
nextEmptyAdj += 2;
if (nextEmptyAdj > ProcessList.CACHED_APP_MAX_ADJ) {
nextEmptyAdj = ProcessList.CACHED_APP_MAX_ADJ;
}
}
}
break;
}
}
// 应用更新oom_adj后的数据,主要就是更新进程的各种oom_adj的值
applyOomAdjLocked(app, true, now, nowElapsed);
// 统计各种类型进程的数目 // Count the number of process types. switch (app.curProcState) { case ActivityManager.PROCESS_STATE_CACHED_ACTIVITY: //cache进程 case ActivityManager.PROCESS_STATE_CACHED_ACTIVITY_CLIENT: mNumCachedHiddenProcs++; numCached++; if (numCached > cachedProcessLimit) { app.kill("cached #" + numCached, true); } break; case ActivityManager.PROCESS_STATE_CACHED_EMPTY: //空进程 if (numEmpty > ProcessList.TRIM_EMPTY_APPS && app.lastActivityTime < oldTime) { app.kill("empty for " + ((oldTime + ProcessList.MAX_EMPTY_TIME - app.lastActivityTime) / 1000) + "s", true); } else { numEmpty++; if (numEmpty > emptyProcessLimit) { app.kill("empty #" + numEmpty, true); } } break; default: //正常的进程 mNumNonCachedProcs++; break; }
// 下面的注释写的很清楚,意思就是如果这个app进程是独立的,
// 并且这个app中没有任何的service,那么这个进程就没有存在的必要的,直接杀死。
if (app.isolated && app.services.size() <= 0) { // If this is an isolated process, and there are no // services running in it, then the process is no longer // needed. We agressively kill these because we can by // definition not re-use the same process again, and it is // good to avoid having whatever code was running in them // left sitting around after no longer needed. app.kill("isolated not needed", true); } else { // Keeping this process, update its uid.
// 否则就保留这个进程
final UidRecord uidRec = app.uidRecord; if (uidRec != null && uidRec.curProcState > app.curProcState) { uidRec.curProcState = app.curProcState; } }
// 如果这个app进程的重要级别比home的级别低的话,那么就增加trim计数,这个计数在后面清除多余app进程时会用到。 if (app.curProcState >= ActivityManager.PROCESS_STATE_HOME && !app.killedByAm) { numTrimming++; //作用? } } } 上面代码中我的注释将这段程序的基本逻辑描述了,这里就不再赘述。这里需要额外说明一下,我们上面通过调用modifyRawOomAdj方法调整对应app进程的oom_adj值,我们下面看一下是怎么调整的:
int modifyRawOomAdj(int adj) {
if (hasAboveClient) {
// If this process has bound to any services with BIND_ABOVE_CLIENT,
// then we need to drop its adjustment to be lower than the service's
// in order to honor the request. We want to drop it by one adjustment
// level... but there is special meaning applied to various levels so
// we will skip some of them.
if (adj < ProcessList.FOREGROUND_APP_ADJ) {
// System process will not get dropped, ever
} else if (adj < ProcessList.VISIBLE_APP_ADJ) {
adj = ProcessList.VISIBLE_APP_ADJ;
} else if (adj < ProcessList.PERCEPTIBLE_APP_ADJ) {
adj = ProcessList.PERCEPTIBLE_APP_ADJ;
} else if (adj < ProcessList.CACHED_APP_MIN_ADJ) {
adj = ProcessList.CACHED_APP_MIN_ADJ;
} else if (adj < ProcessList.CACHED_APP_MAX_ADJ) {
adj++;
}
}
return adj;
} /**
* Flag for {@link #bindService}: indicates that the client application
* binding to this service considers the service to be more important than
* the app itself. When set, the platform will try to have the out of
* memory killer kill the app before it kills the service it is bound to, though
* this is not guaranteed to be the case.
*/
public static final int BIND_ABOVE_CLIENT = 0x0008;google的解释很清楚了,这里的意思就是说client使用BIND_ABOVE_CLIENT绑定service的话,那么client的优先级是比service要低的,虽然android系统并不会保证一定是这样。正是因为这个,上面我们的代码才将adj的值增加处理。现在我们再总结一下上面代码的逻辑,主要就是从mLruProcesses中的最顶端(index最大的)开始挨个计算oom_adj的值,然后针对计算后的值进行一定的调整,就这样。
// memory trimming: (内存整理)
// blabla
// blabla上面我们分析updateOomAdjLocked的时候,我们发现updateOomAdjLocked是通过调用computeOomAdjLocked方法来计算oom_adj的,那么computeOomAdjLocked究竟是怎么计算的呢?下面我们来分析一下,由于这个方法非常长(其实google应该缩短这个方法,将其拆分成几个独立的方法,这样代码的可读性更好),这里我就针对重点代码片段分析一下,大家主要理解其主要意图即可:
1). 如果是当前进程的话(TOP_APP),即包含了当前显示的activity的进程,则将他们的oom_adj设置为FOREGROUND_APP_ADJ:
if (app == TOP_APP) {
// The last app on the list is the foreground app.
adj = ProcessList.FOREGROUND_APP_ADJ;
schedGroup = ProcessList.SCHED_GROUP_TOP_APP;
app.adjType = "top-activity";
foregroundActivities = true;
procState = PROCESS_STATE_CUR_TOP;
}2). 如果进程有instrumentation实例,说明这个app正在测试当中,这个时候它的adj应该是一个前台adj,保证尽量不被杀死:
} else if (app.instrumentationClass != null) {
// Don't want to kill running instrumentation.
adj = ProcessList.FOREGROUND_APP_ADJ;
schedGroup = ProcessList.SCHED_GROUP_DEFAULT;
app.adjType = "instrumentation";
procState = ActivityManager.PROCESS_STATE_FOREGROUND_SERVICE;
} if ((queue = isReceivingBroadcast(app)) != null) {
// An app that is currently receiving a broadcast also
// counts as being in the foreground for OOM killer purposes.
// It's placed in a sched group based on the nature of the
// broadcast as reflected by which queue it's active in.
adj = ProcessList.FOREGROUND_APP_ADJ;
schedGroup = (queue == mFgBroadcastQueue)
? ProcessList.SCHED_GROUP_DEFAULT : ProcessList.SCHED_GROUP_BACKGROUND;
app.adjType = "broadcast";
procState = ActivityManager.PROCESS_STATE_RECEIVER;
}if (app.executingServices.size() > 0) {
// An app that is currently executing a service callback also
// counts as being in the foreground.
adj = ProcessList.FOREGROUND_APP_ADJ;
schedGroup = app.execServicesFg ?
ProcessList.SCHED_GROUP_DEFAULT : ProcessList.SCHED_GROUP_BACKGROUND;
app.adjType = "exec-service";
procState = ActivityManager.PROCESS_STATE_SERVICE;
//Slog.i(TAG, "EXEC " + (app.execServicesFg ? "FG" : "BG") + ": " + app);
} else {
// As far as we know the process is empty. We may change our mind later.
schedGroup = ProcessList.SCHED_GROUP_BACKGROUND;
// At this point we don't actually know the adjustment. Use the cached adj
// value that the caller wants us to.
adj = cachedAdj;
procState = ActivityManager.PROCESS_STATE_CACHED_EMPTY;
app.cached = true;
app.empty = true;
app.adjType = "cch-empty";
}上面的几个步骤只是计算了进程了oom_adj的一个初始值,接下来的代码还有针对这个值继续调整,但是调整的原则就是向下调整,只有判断出进程的oom_adj的值可以更低的时候才会去改变它。
6). 如果进程有可见的activity的话,那么将它的adj设置为VISIBLE_APP_ADJ:
if (r.visible) {
// App has a visible activity; only upgrade adjustment.
if (adj > ProcessList.VISIBLE_APP_ADJ) {
adj = ProcessList.VISIBLE_APP_ADJ;
app.adjType = "visible";
}
if (procState > PROCESS_STATE_CUR_TOP) {
procState = PROCESS_STATE_CUR_TOP;
}
schedGroup = ProcessList.SCHED_GROUP_DEFAULT;
app.cached = false;
app.empty = false;
foregroundActivities = true;
if (r.task != null && minLayer > 0) {
final int layer = r.task.mLayerRank;
if (layer >= 0 && minLayer > layer) {
minLayer = layer;
}
}
break;
}
else if (r.state == ActivityState.PAUSING || r.state == ActivityState.PAUSED) {
if (adj > ProcessList.PERCEPTIBLE_APP_ADJ) {
adj = ProcessList.PERCEPTIBLE_APP_ADJ;
app.adjType = "pausing";
}
if (procState > PROCESS_STATE_CUR_TOP) {
procState = PROCESS_STATE_CUR_TOP;
}
schedGroup = ProcessList.SCHED_GROUP_DEFAULT;
app.cached = false;
app.empty = false;
foregroundActivities = true;
}else if (r.state == ActivityState.STOPPING) {
if (adj > ProcessList.PERCEPTIBLE_APP_ADJ) {
adj = ProcessList.PERCEPTIBLE_APP_ADJ;
app.adjType = "stopping";
}
// For the process state, we will at this point consider the
// process to be cached. It will be cached either as an activity
// or empty depending on whether the activity is finishing. We do
// this so that we can treat the process as cached for purposes of
// memory trimming (determing current memory level, trim command to
// send to process) since there can be an arbitrary number of stopping
// processes and they should soon all go into the cached state.
if (!r.finishing) {
if (procState > ActivityManager.PROCESS_STATE_LAST_ACTIVITY) {
procState = ActivityManager.PROCESS_STATE_LAST_ACTIVITY;
}
}
app.cached = false;
app.empty = false;
foregroundActivities = true;
} if (adj > ProcessList.PERCEPTIBLE_APP_ADJ
|| procState > ActivityManager.PROCESS_STATE_FOREGROUND_SERVICE) {
if (app.foregroundServices) {
// The user is aware of this app, so make it visible.
adj = ProcessList.PERCEPTIBLE_APP_ADJ;
procState = ActivityManager.PROCESS_STATE_FOREGROUND_SERVICE;
app.cached = false;
app.adjType = "fg-service";
schedGroup = ProcessList.SCHED_GROUP_DEFAULT;
} else if (app.forcingToForeground != null) {
// The user is aware of this app, so make it visible.
adj = ProcessList.PERCEPTIBLE_APP_ADJ;
procState = ActivityManager.PROCESS_STATE_IMPORTANT_FOREGROUND;
app.cached = false;
app.adjType = "force-fg";
app.adjSource = app.forcingToForeground;
schedGroup = ProcessList.SCHED_GROUP_DEFAULT;
}
} if (app == mHeavyWeightProcess) {
if (adj > ProcessList.HEAVY_WEIGHT_APP_ADJ) {
// We don't want to kill the current heavy-weight process.
adj = ProcessList.HEAVY_WEIGHT_APP_ADJ;
schedGroup = ProcessList.SCHED_GROUP_BACKGROUND;
app.cached = false;
app.adjType = "heavy";
}
if (procState > ActivityManager.PROCESS_STATE_HEAVY_WEIGHT) {
procState = ActivityManager.PROCESS_STATE_HEAVY_WEIGHT;
}
}http://www.wideskills.com/android/application-components/android-threads-and-processes/p/0/1
11). 如果当前app进程是home进程,那么我们将它的adj设置为HOME_APP_ADJ
if (app == mHomeProcess) {
if (adj > ProcessList.HOME_APP_ADJ) {
// This process is hosting what we currently consider to be the
// home app, so we don't want to let it go into the background.
adj = ProcessList.HOME_APP_ADJ;
schedGroup = ProcessList.SCHED_GROUP_BACKGROUND;
app.cached = false;
app.adjType = "home";
}
if (procState > ActivityManager.PROCESS_STATE_HOME) {
procState = ActivityManager.PROCESS_STATE_HOME;
}
}
12). 如果这个进程是Previous进程,并且它有activity的话,那么我们将它的adj设置为PREVIOUS_APP_ADJ:
if (app == mPreviousProcess && app.activities.size() > 0) {
if (adj > ProcessList.PREVIOUS_APP_ADJ) {
// This was the previous process that showed UI to the user.
// We want to try to keep it around more aggressively, to give
// a good experience around switching between two apps.
adj = ProcessList.PREVIOUS_APP_ADJ;
schedGroup = ProcessList.SCHED_GROUP_BACKGROUND;
app.cached = false;
app.adjType = "previous";
}
if (procState > ActivityManager.PROCESS_STATE_LAST_ACTIVITY) {
procState = ActivityManager.PROCESS_STATE_LAST_ACTIVITY;
}
}
13). 如果进程正在备份的话,那么将它的adj设置为BACKUP_APP_ADJ:
if (mBackupTarget != null && app == mBackupTarget.app) {
// If possible we want to avoid killing apps while they're being backed up
if (adj > ProcessList.BACKUP_APP_ADJ) {
if (DEBUG_BACKUP) Slog.v(TAG_BACKUP, "oom BACKUP_APP_ADJ for " + app);
adj = ProcessList.BACKUP_APP_ADJ;
if (procState > ActivityManager.PROCESS_STATE_IMPORTANT_BACKGROUND) {
procState = ActivityManager.PROCESS_STATE_IMPORTANT_BACKGROUND;
}
app.adjType = "backup";
app.cached = false;
}
if (procState > ActivityManager.PROCESS_STATE_BACKUP) {
procState = ActivityManager.PROCESS_STATE_BACKUP;
}
}14). 接下来开始处理进程中含有service组件的情况,针对每个service,分两种情况处理:
a. 如果进程的service是显式启动的(service对象的startRequested为true),而且进程还拥有activity,则将它的adj值设置为SERVICE_ADJ
b. 重新计算和service链接的其他的进程的adj值,如果service的链接标记中包含了BIND_ABOVE_CLIENT的话,那么将当前进程的adj设置为客户端的adj值;如果标记中包含了BIND_NOT_VISIBLE则将进程的adj设置为PERCEPTIBLE_APP_ADJ;否则就设置为VISIBLE_APP_ADJ
for (int is = app.services.size()-1;
is >= 0 && (adj > ProcessList.FOREGROUND_APP_ADJ
|| schedGroup == ProcessList.SCHED_GROUP_BACKGROUND
|| procState > ActivityManager.PROCESS_STATE_TOP);
is--) {
ServiceRecord s = app.services.valueAt(is);
// blabla ....15). 接下来考虑进程中包含ContentProvider的情况,对该进程中的每个provider对象,进行如下处理:
a. 首先计算和ContentProvider链接的client进程的oom_adj值,如果当前的oom_adj值大于client的值,那么就将当前进程的adj设置为和client一样的值。这表示当前进程的重要性至少和client一样的。
b. 如果ContentProvider对象有一个应用进程和它链接,将当前进程的oom_adj调整为FOREGROUND_APP_ADJ
15). 如果当前进程的adj大于了这个进程可以拥有的最大的adj(maxAdj)的话,那么就调整为maxAdj
for (int provi = app.pubProviders.size()-1;
provi >= 0 && (adj > ProcessList.FOREGROUND_APP_ADJ
|| schedGroup == ProcessList.SCHED_GROUP_BACKGROUND
|| procState > ActivityManager.PROCESS_STATE_TOP);
provi--) {
ContentProviderRecord cpr = app.pubProviders.valueAt(provi);
// blabla....总结
这里我们大概梳理一下AMS中的进程和oom_adj的管理流程,这是AMS所有的工作中比较重要的,这个是下面理解AMS的activity管理流程基础,希望本文可以帮助大家更好地理解AMS。