MySQL 数据库相关知识汇总以及常用SQL语句
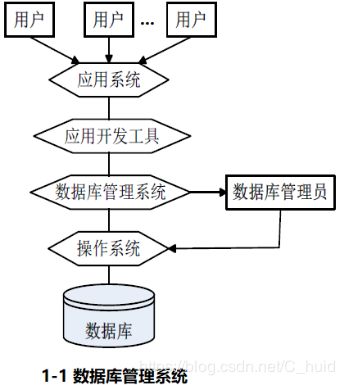
数据库系统(DBS:DataBase System)
数据库系统是由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员(DBA:DataBase Administrator)组成的存储、管理、处理和维护数据的系统
图1-1表示一个数据库管理系统,其中数据库提供数据的存储功能,数据库管理系统提供数据的组织、存取、管理和维护等基础功能,数据库应用系统根据应用需求使用数据库,数据库管理员负责全面管理数据库系统。
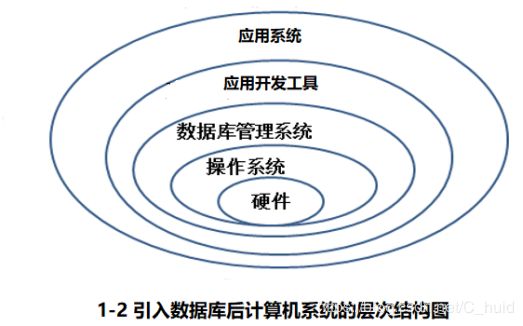
在不会引起混淆的情况下,我们经常把数据库系统简称为数据库。
下面将介绍与数据库技术紧密相关的数据、数据库、数据库管理系统和数据库系统4个基本概念。
1. 什么是数据(data)
我们可以这样来定义数据:描述客观事物的符号记录成为数据。数据是数据库中存储的基本对象,数据不仅仅是狭义上的数字表现形式,如整数、实数、浮点数等,它在广义上还包含了文本文字(text)、图形(graph)、图像(image)、音频(audio)、视频(video)等非数字的表现形式,因为他们通过数字化处理之后就可以存入计算机内。
当然,这些数据无论是数字形式的还是非数字形式的,都没办法真正的表达出数据的真实含义,要想完整地表达出数据的含义,我们需要对数据进行解释才行。数据的解释实质就是指对数据含义的说明,即对数据的语义进行说明,数据和数据的语义是不可分的。
例如,178既可以指一个人的身高是178cm,也可以指这个人的体重是178斤,甚至还可以认为是某个社团协会的总人数,我们如果不知道数据的语义,就没办法说明数据的含义。
记录是计算机内表示和存储数据的一种格式或方法。例如,我们把某个学生的姓名、性别、出生日期,所在院系、入学时间等组织在一起,就构成了一个记录。
2. 数据库(DB:DataBase)
数据库,指的是按一定格式将数据存储在计算机存储设备上的数据仓库。如果要严格地定义数据库,那么,数据库是长期存储在计算机内、有组织的、可共享的大量数据的集合。数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度(redundancy)、较高的数据独立性(data independency)和易扩展性(scalability),并可为各种用户共享。更概括地说,数据库具有永久存储、有组织和可共享三个基本特点。
3. 数据库管理系统(DBMS:DataBase Mangement System)
数据库管理系统是用于管理数据库的系统软件,有数据库和用于访问管理数据库的程序组成,DBMS可以组织和存储数据,获取、检索、管理和维护数据库中的数据,是数据库系统的核心组成部分。
数据库管理系统是位于用户和操作系统之间的数据管理软件,它和操作系统一样属于系统软件,主要包括以下功能:
(1)数据定义功能
数据库管理系统提供数据定义语言(DDL:Data Definition Language),用户可以通过它方便地对数据库中的数据对象的组成和结构进行定义。
(2)数据组织、存储和管理功能
数据库管理系统要分类组织、存储和管理各种数据,包括数据字典、用户数据、数据的存取路径等。要确定以何种文件结构和存取方式在存储级别上组织这些数据,如何实现数据之间的联系。数据组织和存储的基本目标是提高存储空间的利用率和方便存取,并提供多种存取方法(如索引查找、哈希查找、二分查找等)来提高存取效率。
(3)数据操纵功能
数据库管理系统还提供了数据操纵语言(DML:Data Manipulation Language),用户可以使用它操纵数据,实现对数据库的基本操作,如插入、删除、修改和查询等。
(4)事务管理和运行管理功能
数据库在建立、运行和维护时有数据库管理系统进行统一管理和控制,以保证事务的正确运行,保证数据的安全性、完整性、多用户对数据的并发使用以及故障发生后的系统恢复。
(5)数据库建立和维护功能
数据库的建立和维护功能包括数据库初始数据的输入、转换功能,数据库的转储、恢复功能,数据库的重组织功能和性能监视、分析功能等。这些功能通常由一些实用程序或者管理工具来完成。
(6)其它功能
其它功能包括数据库管理系统与网络中其他软件系统的通信功能,一个数据库管理系统与另一个数据库管理系统或文件系统的数据转换功能,异构数据库之间的互访和互操作功能等。
SQL语句:
--查询数据
select <目标列表达式> from <表>
--添加数据
insert
into <表> [(<列名> [,<列名>]...)]
values(<属性值> [,<属性值>]...)
--修改数据
update <表>
set <修改表达式>
[where <条件表达式>]
--删除数据
delete
from <表>
[where <条件表达式>]
语法格式:
DROP VIEW <视图名>
语法格式:
CREATE CLUSTERED INDEX <索引名>
ON <视图或数据表>(属性列)
语法格式:
CREATE [NONCLUSTERED] INDEX <索引名>
ON <视图或数据表>(属性列)
语法格式:
ALTER INDEX <索引名>
ON <数据表或视图> REBUILD
语法格式:
ALTER INDEX <索引名>
ON <数据表或视图> DISABLE
语法格式:
--查看数据表或视图中的索引
SP_HELPINDEX <数据表或视图>
语法格式:
DROP INDEX <索引名>
ON <数据表或视图>
语法格式:
CREATE PROC <过程名> --创建存储过程
AS
<过程化SQL块> --使用存储过程
EXEC <过程名>
语法格式:
CREATE PROC <过程名>(<入参1> [,<入参2>]...) --创建存储过程
AS
<过程化SQL块> --使用存储过程
EXEC <过程名> <入参值> [,<入参值>]...
语法格式:
--查看存储过程属性信息、参数与数据类型
sp_help <存储过程名>
语法格式:
DROP PROC <存储过程名> --删除存储过程
语法格式:
INSERT
INTO <表名> [(<属性列1>[,<属性列2>]...)]
VALUES(<常量1>[,<常量2>]...)
语法格式:
INSERT
INTO <表名> [(<属性列1>[,<属性列2>]...)]
VALUES(<常量1>[,<常量2>]...),
(<常量1>[,<常量2>]...),
(<常量1>[,<常量2>]...)
语法格式:
DELETE
FROM <表名>
[WHERE <条件>]
(如果省略WHERE子句,则表示删除表中的全部元组,但表的定义仍在字典中)
语法格式:
INSERT
INTO <表名> [(<属性列1>[,<属性列2>]...)]
子查询
语法格式:
UPDATE <表名>
SET <列名>=<表达式>[,<列名>=<表达式>]...
[WHERE <条件>]
语法格式:
SELECT [all | DISTINCT] <目标列表达式> [别名] [,<目标列表达式> [别名]]...
FROM <表名或视图名> [别名] [,<表名或视图名> [别名]]... | (
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2> [AES|DESC]]
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> WHERE <比较条件表达式>
比较条件有:
= 等于 > 大于 < 小于
>= 大于等于 <= 小于等于
!> 不大于 !< 不小于
!=或<> 不等于
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> WHERE <范围条件表达式>
范围条件有: BETWEEN AND 在指定范围内,包括指定范围的上限和下限
NOT BETWEEN AND 不在指定范围内,不包括指定范围的上限和下限
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> WHERE <集合条件表达式>
集合条件有:
IN 在指定集合内
NOT IN 不在指定集合内
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> WHERE <空值·条件表达式>
空值条件有:
IS NULL 是空值
IS NOT NULL 不是空值
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> WHERE <逻辑条件表达式>
逻辑条件有:
AND 与逻辑,两个或多个条件同时满足时返回查询结果
OR 或逻辑,任何一个条件满足时返回查询结果
NOT 非逻辑,不满足条件时返回查询结果
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> WHERE <模糊条件表达式>
--模糊条件使用LIKE或NOT LIKE进行查找
语法格式:
SELECT <含有统计函数的目标列表达式> FROM <表名或视图名> WHERE <查询条件表达式>
语法格式:
SELECT <目标列表达式> FROM <表名或视图名> [WHERE <查询条件表达式>]
GROUP BY <进行分组的列名>
[HAVING <条件表达式>]
--WHERE子句是在分组前过滤数据
--HAVING子句是在分组后过滤数据,通常与GROUP BY子句一起用来筛选结果集内的组
语法格式:
SELECT [all | DISTINCT] <目标列表达式> [别名] [,<目标列表达式> [别名]]...
FROM <表名或视图名> [别名] [,<表名或视图名> [别名]]... | (
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2> [AES|DESC]]
简要说明:
交叉连接是连接查询里最简单的连接方式,原理是对两个表进行连接查询操作时,生成两者的笛卡尔积。 例如:一个s行的数据表与一个n行的数据表进行交叉连接,则会生成一个s*n的结果集。交叉连接查询由于会生成大量不符合业务的数据,因此基本没有实际应用。
语法格式
语法一: SELECT <目标列表达式> FROM <表名或视图名> CROSS JOIN <表名或视图名>
语法二: SELECT <目标列表达式> FROM <表名或视图名> , <表名或视图名>
语法格式:
CREATE VIEW <视图名> [(<列名>[,<列名>]...)]
AS <子查询>
[WITH CHECK OPTION]
语法格式:
ALTER VIEW <视图名> [(<列名>[,<列名>]...)]
[WITH ENCRIPTION] --加密
AS <子查询>
[WITH CHECK OPTION]
语法格式:
CREATE TRIGGER <触发器名>
ON <数据表|视图|DATABASE>
AS
<触发动作体>
--AFTER与FOR均为后置触发器,版本兼容原因存在两种方式,本质无区别
语法格式:
--重命名触发器
exec sp_rename <原触发器名>,<新触发器名>
--修改触发器内容
ALTER TRIGGER <触发器名>
ON <数据表|视图|DATABASE>
AS
<触发动作体>
语法格式:
--禁用DML触发器
DISABLE TRIGGER <触发器名> ON <表|视图>
--禁用DDL触发器trig_schoolDB_denyalterdrop
DISABLE TRIGGERtrig_schoolDB_denyalterdrop ON DATABASE
--启用DML触发器
ENABLE TRIGGER <触发器名> ON <表|视图>
--启用DDL触发器trig_schoolDB_denyalterdrop
ENABLE TRIGGER trig_schoolDB_denyalterdrop ON DATABASE
语法格式:
DROP TRIGGER <触发器名>
语法格式:
CREATE LOGIN <[计算机名\用户名]>
FROM WINDOWS
WITH DEFAULT_DATABASE=<默认数据库>
语法格式:
CREATE LOGIN <[SQL Server登录名>
WITH PASSWORD=<密码>,
WITH DEFAULT_DATABASE=<默认数据库>
语法格式:
CREATE USER 用户名
FROM LOGIN 登录名
语法格式:
--授予权限
GRANT <权限列表> ON <视图或数据表> TO <用户名>
--拒绝权限
DENY <权限列表> ON <视图或数据表> TO <用户名>
--撤销权限
REVOKE <权限列表> ON <视图或数据表> FROM <用户名>
语法格式:
EXEC sp_addumpdevice <存储类型> ,<备份设备逻辑名>, <物理文件路径>
语法格式:
--备份数据库
USE master
GO
BACKUP DATABASE <数据库> TO <备份设备>
--还原数据库
USE master
GO
RESTORE DATABASE <数据库> FROM <备份设备>
语法格式:
--数据库差异备份
USE master
GO
BACKUP DATABASE <数据库> TO <备份设备>
WITH DIFFERENTIAL
--数据库还原
--备份集编号可在对应的备份设备右击选择属性,查看备份介质即可找到备份集的编号
USE master
GO
RESTORE DATABASE <数据库> FROM <备份设备>
WITH FILE=<备份集标号>,NORECOVERY --NORECOVERY 表示还原未恢复
GO
...
GO
RESTORE DATABASE <数据库> FROM <备份设备>
WITH FILE=<备份集标号>,RECOVERY --RECOVERY 表示还原已恢复
语法格式:
--备份事务日志
USE master
GO
BACKUP LOG <数据库> TO <备份设备>
--恢复数据库备份
--备份集编号可在对应的备份设备右击选择属性,查看备份介质即可找到备份集的编号
USE master
GO
RESTORE DATABASE <数据库> FROM <备份设备>
WITH REPLACE,FILE=<备份集编号>,NORECOVERY --NORECOVERY 表示还原未恢复
GO
...
GO
RESTORE LOG <数据库> FROM <备份设备>
WITH FILE=<备份集编号>,RECOVERY --RECOVERY 表示还原已恢复