Elasticsearch第一篇:基本介绍(入门必看系列)
文章目录
- es系列导航
- 一、简介
- 二、特点
- 三、为什么使用ES
- 四、基本概念
- 1.2.1.Near Realtime(NRT)
- 1.2.2.Index:索引库
- 1.2.3.Type:类型
- 1.2.4.Document&field
- 结构概念图
- 1.2.5.Cluster:集群
- 1.2.6.Node:节点
- 1.2.7.shard(分片)
- 1.2.8.replica(复制品)
- 集群概念图
- 五、面向文档
- 六、ES中HTTP请求详解
最近开发需要使用到es,我就将自己在es中一些学习和使用情况记录下来,方便以后复习和他人学习使用。如果文档中有错误请麻烦给我指出一下,感谢!
es系列导航
Elasticsearch第一篇:基本介绍
Elasticsearch第二篇:es版本比较
一、简介
Elasticsearch是基于Lucene的不足,而推出的分布式的全文搜索引擎,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能
目的:是通过简单的 RESTful API来隐Lucene的复杂性,从而让全文搜索变得简单!!!。
二、特点
- 操作简单,上手快
- 支持分布式,能在分布式/集群中使用
- 支持RESTful的风格来进行通信
- 基于Lucene来进行分布式的全文检索
- 处理PB级结构化与非结构化数据
- 支持各种语言客户端
三、为什么使用ES
这里我贴一段网上对ES的理解和为什么会使用ES
Elasticsearch所涉及到的每一项技术都不是创新或者革命性的,全文搜索,分析系统以及分布式数据库这些早就已经存在了。它的革命性在于将这些独立且有用的技术整合成一个一体化的、实时的应用。它对新用户的门槛很低,当然它也会跟上你技能和需求增长的步伐。
如果你打算看这本书,说明你已经有数据了,但光有数据是不够的,除非你能对这些数据做些什么事情。
很不幸,现在大部分数据库在提取可用知识方面显得异常无能。的确,它们能够通过时间戳或者精确匹配做过滤,但是它们能够进行全文搜索,处理同义词和根据相关性给文档打分吗?它们能根据同一份数据生成分析和聚合的结果吗?最重要的是,它们在没有大量工作进程(线程)的情况下能做到对数据的实时处理吗?
这就是Elasticsearch存在的理由:Elasticsearch鼓励你浏览并利用你的数据,而不是让它烂在数据库里,因为在数据库里实在太难查询了。
四、基本概念
1.2.1.Near Realtime(NRT)
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
1.2.2.Index:索引库
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
倒排索引 传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。到时候需要的话会专门开一篇文章来讲解倒排索引
1.2.3.Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
1.2.4.Document&field
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
结构概念图

这也是一个简单的对比
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
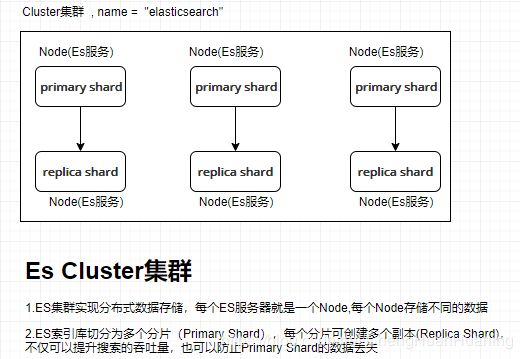
1.2.5.Cluster:集群
包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
1.2.6.Node:节点
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为"elasticsearch"的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
1.2.7.shard(分片)
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
1.2.8.replica(复制品)
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
集群概念图
五、面向文档
在以前我们使用数据库,我们总是将其中复杂的内容拆分为简单的数据结构,然后将这些简单的数据内容存入数据库中。我们需要的时候从数据库中读取出来再进行重铸。
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会**索引(index)**每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
六、ES中HTTP请求详解
curl -X<VERB> '://:/?' -d ''
- VERB HTTP方法:GET, POST, PUT, HEAD, DELETE
- PROTOCOL http或者https协议(只有在Elasticsearch前面有https代理的时候可用)
- HOST Elasticsearch集群中的任何一个节点的主机名,如果是在本地的节点,那么就叫localhost
- PORT Elasticsearch HTTP服务所在的端口,默认为9200
- PATH API路径(例如_count将返回集群中文档的数量),PATH可以包含多个组件,例如_cluster/stats或者_nodes/stats/jvm
- QUERY_STRING 一些可选的查询请求参数,例如?pretty参数将使请求返回更加美观易读的JSON数据
- BODY 一个JSON格式的请求主体(如果请求需要的话)
为了计算集群中的文档数量,我们可以这样做:
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
Elasticsearch返回一个类似200 OK的HTTP状态码和JSON格式的响应主体(除了HEAD请求)。上面的请求会得到如下的JSON格式的响应主体:
{
"count" : 0,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
}
}