【Elasticsearch学习笔记-基础篇2】Elasticsearch倒排索引、分析及打分
前言
【Elasticsearch学习笔记-基础篇1】Elasticsearch介绍及设计概念
在之前的一篇文章中,简单介绍了 es 的设计和相关概念,这一篇来介绍一下 es 中实操方面相关概念的引申——在索引和搜索文档的时候,es 是怎么做的。
倒排索引
概念介绍
倒排索引是 es 能快速搜索的原因之一。但是在了解倒排索引之前,我们需要先了解什么是正排索引。
正排索引,是指文档ID为key,表中记录每个关键词出现的次数,查找时扫描表中的每个文档中字的信息,直到找到所有包含查询关键字的文档。
结构如图:(转自博客https://www.cnblogs.com/softidea/p/9852048.html)
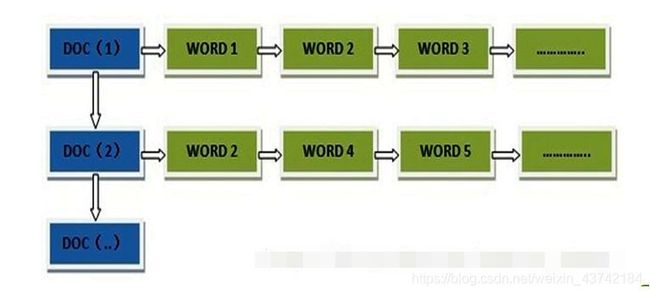
倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
再来看看倒排索引的结构:
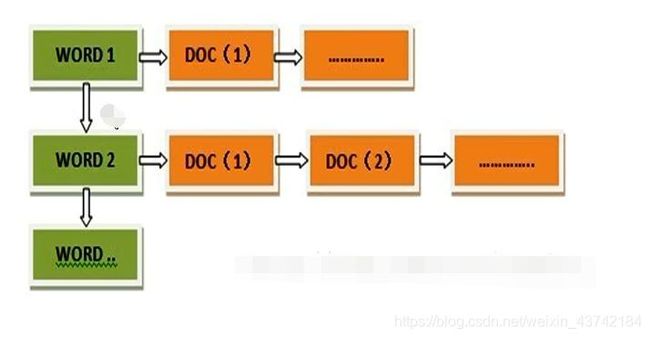
以常理分析,
如果是索引速度方面,一定是正排索引结构更占优势,因为只需要分词后,将文档的ID指向前一个文档的ID就可以了,而倒排索引需要将文档的ID指向其包含的关键词序列的前一个拥有相同关键词的文档。
如果是查询速度方面,那显然是倒排索引更占据优势,搜索词条可以直接得到包含词条的文档,而正排索引需要遍历关键词最后聚合文档。
单词词典
单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。
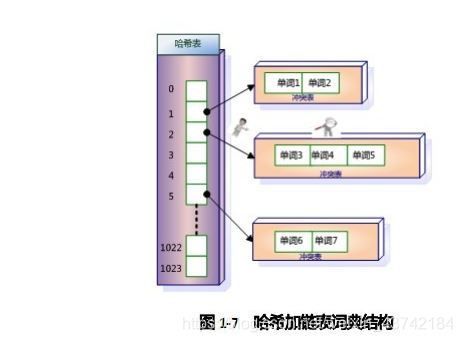
与此同时,当搜索一个关键词时,一定不是遍历所有的关键词,那样太耗时了,所以也需要有一个高效的数据结构来快速的映射关键词。一般能到想到的就是哈希链表和B+树。
哈希链表:(转自博客https://blog.csdn.net/hguisu/article/details/7962350)
B+树:(转自博客https://blog.csdn.net/hguisu/article/details/7962350)

具体数据结构的知识,可以自行查阅学习,在这里不过多赘述。
分析
分析是什么?实际上,就是每次你输入语句时对于语句的分词过程。这个分析过程在索引数据、搜索文档中体现。
首先,简单介绍一下 es 的分析语句步骤(也有可能是普遍的处理办法):
- 字符过滤
简单来说,就是将 & 、¥ 字符去掉,或转换成文字。比如 & -> 和 - 文本切分
这一步,就是我们日常普遍理解的分词,就是将文本通过文本切割算法(一般是正向匹配)切分。 - 分词过滤
我个人理解,这一步可能拼音语系应用的比较多,主要有区别大小写规整,剔除限制长度外单词等功能。
对于中文来说, es 的分词效果很差,所以我们自己配置 ik 分词器来作为 es 的分词器。具体配置方法可以自行学习。
关于 ik-smart 分词器的分词器效果评测可以参考我的 github:
https://github.com/amber0515/ik_smart-Evaluation.git
注意: 分词器可以在字段级别做设置,但是只能在索引(index)为空的时候做设置,类似于设置字段类型。
打分,相关性
es 作为一个搜索引擎,所以自然要在搜索结果的相关性上多下下功夫,这部分也正是搜索引擎区别于其他 nosql 数据库的主要方面之一。
首先,我们要学习的是一个大名鼎鼎的统计方法:
TF-IDF(term frequency-inverse document frequency)词频-逆文档频率
在这里解析两个概念:词频、逆文档频率
词频
词频顾名思义,就是词条在一个文档中出现的频率。简单计数就是数个数。例如:
对于关键词条“酒”,对于这个文档,词频记为2:
小明去买酒,小红也去买酒
逆文档频率
这里实际上把名词进行拆分会更好理解——“逆”、“文档频率”,在计算时,我们也是先计算文档频率,之后再取倒数。
文档频率也是顾名思义,即是词条出现的频率。对于这样一组数据,以及“酒”这个关键词,文档频率记为2,逆文档频率记为 1/2:
小明去买酒,小红也去买酒
小明去买酒
小红去买烟
在这里关注的是:词条是否在文档中出现,而不是出现多少次。
从这个计算方式也可以得知,如果一个词在不同文档中出现的越多,逆文档频率的数值就越小。
Lucene 评分公式
Lucene 的评分公式是TF-IDF的一个具体数学实现。这里我们大概了解一下,体会一下评分方式,具体不做深入。
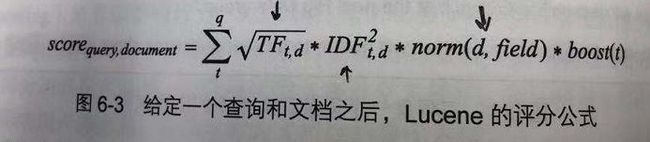
对于词频来讲,平方根可以有效地防止长文档的得分过高(因为x^1/2,k随着x增大而较小)。
对于逆文档频率来讲,因为这里最大取值就是1,所以文档频率越大,也就是逆文档频率的数值越小,得分越低。而平方则是加大了这里的权重。
norm是做归一化处理的子公式,目前尚不清楚用途。
boost是用来在搜索或索引时,手动调整权重的参数,会影响最终得分的计算。
ES精细评分和评分优化
在很多时候,我们需要自己控制更精细化的评分规则,来满足业务需求。
在 es 中,自定义和精细化评分是非常消耗性能的。如果我们需要在数百万的文档中召回相关文档,我们该使用怎样的机制来提升搜索性能呢?
简单评分后,对于小范围文档再评分就好了。对于再评分,es 有两种实现方式:
- rescore
对于一些评分计算消耗比较大的内置函数,可以使用rescore方式,对规定范围的找回文档进行精细化评分。下面这个例子就是rescore的用法:

- function_score
这个功能可就酷了,在这个字段下,使用者可以自定义多函数来评分,但同样,这个操作也是非常吃性能的,所以 function_score 也是一个再评分机制。目前我接触到的,有两种 function_score 的使用方法。- function 内置函数评分
这里包含了 weight、合并、随机等操作,例如:

- function 内置函数评分
其他操作可以大家另行查找学习。
* Groovy 脚本评分
这里实际上是使用 Groovy 脚本做一些自定义的简单评分操作,评分精细化的极致哈哈哈。

问题1:为什么能快速的、方便的搜索?
现在我们可以从稍微深一点的层面来回答这个问题了。
- 快速体现在:
- 分布式节点、分片物理存储结构的优势。
- 倒排索引的特性。
- 方便体现在:
- 自定义分词器,可以提供不同语种的精准分词。
- 详细的打分机制,帮助开发人员实现定制化的业务需求。