清华华为发布“万词王”反向词典系统,入选AAAI 2020
本文部分内容源自清华大学计算机系在读博士岂凡超在AI科技评论发布的:话到嘴边却忘了?这个模型能帮你 | AAAI 2020。会议之眼参考论文对模型框架、背景知识以及数据来源、评测部分进行了补充。

岂凡超
论文简介和摘要
《Multi-channelReverse Dictionary Model》是由清华大学、华为诺亚方舟合作的论文。该论文已经被AAAI 2020录用。

该文关注反向词典问题——即给定对某个词语的描述,希望得到符合给定描述的词语。该文提出了一种受到人的描述→词的推断过程启发的多通道模型,在中英两种语言的数据集上都实现了当前最佳性能(state-of-the-art),甚至超过了最流行的商业反向词典系统。此外,基于该文提出的模型,论文作者还开发了在线反向词典系统,包含首次实现的中文、中英跨语言反向查词功能。
论文地址:https://arxiv.org/abs/1912.08441 代码和数据地址:https://github.com/thunlp/MultiRD web端万词王地址:https://wantwords.thunlp.org/
网站简介
基于论文所提模型的在线反向词典系统——万词王(WantWords):https://wantwords.thunlp.org/。该系统不仅支持英文、中文反向查词,还支持英汉、汉英跨语言反向查词,能够显示候选词的词性、定义等基本信息,且支持按照词性、单词长度、词形等对候选词进行筛选,助你更快找到你想要的词。
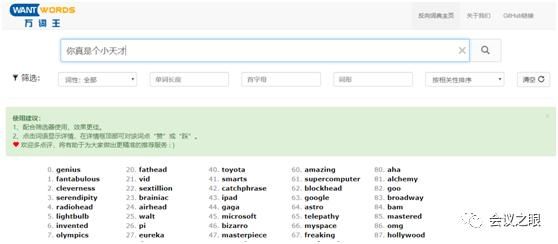
图1 万词王示例
研究背景
反向词典顾名思义,以对目标词语义的描述为输入,输出目标词以及其他符合描述的词语。
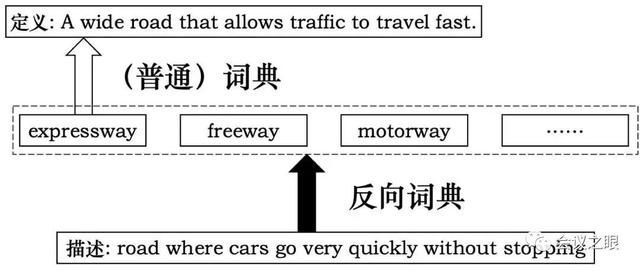
图2 反向词典示例
反向词典有重要的实用价值,其最大的用处在于解决舌尖现象(Tip of the tongue),即话到嘴边说不出来的问题——频繁写作的人,如作家、研究人员、学生等经常会遇到这种问题。
此外,反向词典也可以为掌握词汇不多的新语言学习者提供帮助,让他们学习、巩固尚不十分了解的词语。
最后,反向词典还可以帮助选词性命名不能(wordselection anomia)的患者——他们知道想说的词语的意思但无法主动说出来。
反向词典同样具有自然语言处理研究价值,比如可以用于评测句子表示学习模型,辅助解决问答、信息检索等包含文本到实体映射的任务。
相关工作进展
现在已经有一些投入使用的商业化反向词典系统,其中最著名、最流行的是OneLook(https://www.onelook.com/thesaurus/),但其背后的实现原理尚不得知。
在学术研究领域,目前有两类反向词典实现方法:
第一类为基于句子匹配的方法,该方法在数据库中存储足够多的词语及其定义,当进行反向词典查询时,在数据库中检索与输入描述最相似的定义并返回所对应的词语。然而反向词典的输入描述非常多变,往往与已存储的词典定义有巨大差别,这种方法很难解决这一问题。
另一类基于神经语言模型的方法由Bengio等人提出,该方法使用神经语言模型作为编码器将输入描述编码到词向量空间,返回与之最近的词向量对应的词语。近年来有很多反向词典研究基于这种方法,尽管这种方法避免了第一类方法面临的输入描述多变导致的性能较差的问题,然而该方法对低频词的处理效果不甚理想。
模型搭建
作者首先搭建了模型的基本框架,其实质上类似于由句子编码器和分类器组成的句子分类模型。作者选择了1997年发布的双向 LSTM(BiLSTM)作为句子编码器,该编码器将输入语句编码为向量。而由于句子中的不同单词对句子而言代表的重要性不同,例如,在定义语句中,属词比修饰语更重要, 因此,作者将注意力机制(Bahdanau,Cho和Bengio 2015)也整合到了基本框架中。这仅仅是刚开始。
人的描述到词的推断过程如图3所示,当人看到“road where cars go very quickly without stopping”这条描述时,除了直接猜目标词以外,还可以推断出目标词应具有的一些特征,比如词性应为名词,词的类型应为实体,以及大概率具有“way”这个词素。
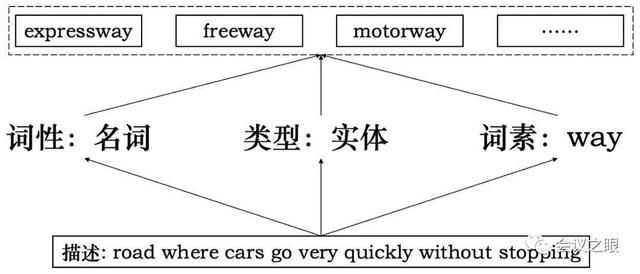
图3 人的描述→词的推断过程
受此启发,该文的模型在对描述编码后直接进行词预测的基础上,额外增加了四个特征预测器。该文将每个特征视作一个信息通道,四个通道可分为两类:
1)内部通道,该类通道预测词本身的特征,包括词性(part-of-speech)和词素(morpheme);
2)外部通道,该类通道预测外部知识库提供的词的特征,包括词类(word category)和义原(sememe)。其中词类信息可由WordNet或同义词词林提供,义原由知网(HowNet)提供。
四个特征汇总
词性:(part-of-speech,Pos)
词素:(morpheme,Mor)
词类:(word category,Cat)
义原:(sememe,Sem)
三个数据库汇总
wordnet:WordNet是由Princeton大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。
同义词词林:是梅家驹等人于1983年编纂而成,年代较为久远,对于目前的使用不太适合,哈工大实验室基于该词林进行扩展,完成了词林扩展版。下载地址:
https://www.ltp-cloud.com/download/
HowNet:是董振东先生、董强先生父子毕数十年之功标注的大型语言知识库,主要面向中文(也包括英文)的词汇与概念。HowNet 秉承还原论思想,认为词汇/词义可以用更小的语义单位来描述。这种语义单位被称为「义原」(Sememe),顾名思义就是原子语义,即最基本的、不宜再分割的最小语义单位。在不断标注的过程中,HowNet 逐渐构建出了一套精细的义原体系(约 2000 个义原)。HowNet 基于该义原体系累计标注了数十万词汇/词义的语义信息。在 NLP 领域知识库资源一直扮演着重要角色,在英语世界中最具知名度的是 WordNet,采用同义词集(synset)的形式标注词汇/词义的语义知识。HowNet 采取了不同于 WordNet 的标注思路,可以说是我国学者为 NLP 做出的最独具特色的杰出贡献。HowNet 在 2000 年前后引起了国内 NLP 学术界极大的研究热情,在词汇相似度计算、文本分类、信息检索等方面探索了 HowNet 的重要应用价值,与当时国际上对 WordNet 的应用探索相映成趣。
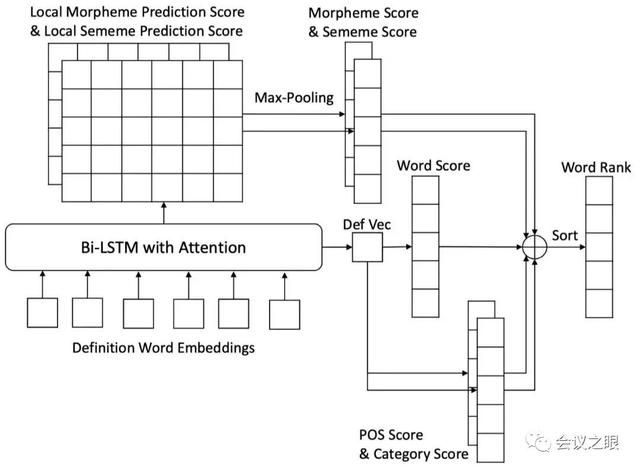
图4 文中的多通道反向词典模型图
图4为该文所提模型的图示。该模型以基于注意力机制的双向LSTM对输入定义或描述进行编码得到句子表示,除了用该句子表示直接预测目标词之外,还对目标词的词性(POS)和词类(category)进行预测。而对于另外两个特征词素(morpheme)和义原(sememe)的预测,则采用了不同的方法。
考虑到词的词素或义原和词的描述/定义中的词存在一种局部语义对应关系—如图3中的例子中“expressway”的“express-”与“quickly”、“-way”与“road”分别对应,且义原也有类似的对应关系——因此对于这两个特征的预测,该文用每个词的隐状态(hidden state)分别预测,然后对预测分数做max-pooling来得到预测分数。这些特征的预测分数会按一定比例加到符合该特征的词语的预测分数上,得到最终的词语预测分数。
评测部分
1.评测数据集
该文在英文、中文多个数据集上进行了实验。对于英文实验,该文使用了前人工作都使用的来自多个英文词典的定义数据集作为训练集,测试集则有3个:
1)见过的词典定义(Seen Definition),由一部分训练集中出现的词典定义构成,这一数据集主要测试模型对以往信息的回忆能力;
2)没见过的词典定义(Unseen Definition),由未在训练集中出现的词典定义构成;
3)人工构造的描述(Description)数据集,该数据集包括人根据给定的词语写出的描述,是最贴合反向词典应用实际的数据集。
2.用于比较的模型1)OneLook,最流行的商业反向词典系统,使用2.0版本;
2)3)具有等级损失的BOW和RNN(Hill等人,2016),都是基于NLM的,而前者使用的是词袋模型,而后者使用LSTM;
4)RDWECI(Morinaga和Yamaguchi 2018),其中包含类别推断,是BOW的改进版本;
5)SuperSense(Pilehvar 2019),BOW的改进版本,使用预训练的有义嵌入来替代目标词嵌入;
6)MS-LSTM(Kartsaklis,Pilehvar和Collier 2018),RNN的改进版本,它使用基于图的WordNet同义词集嵌入和多义LSTM来根据描述和声明来预测同义词集产生最优性能;
7)BiLSTM,作者的多通道模型的基本框架。
3.评测参数1)目标词的中位等级(median rank,越低越好);
2)目标词出现在顶部的准确性1/10/100(acc @ 1/10/100,越高越好);
3)目标词的排名标准差(rank variance,越低越好)。
4.评测结果1列表1展示了三个测试集对模型的预测效果,其中“ Mor”,“ Cat”和“ Sem”分别表示词素,词类和语素预测词。(OneLook的性能在Unseen Definition上没有意义,因为作者不能从其定义的库中排除数据,因此作者没有列出相应的结果。)
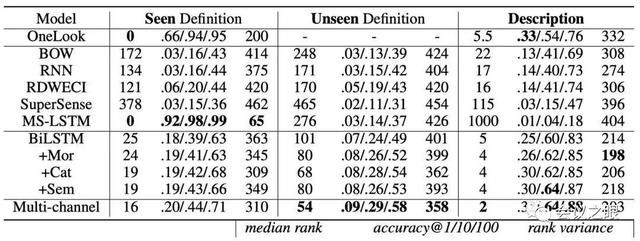
表1 反向词典性能评估比较
除OneLook,作者的多通道模式在Unseen Definition和Description数据集上有更好的性能。 在以下情况下,OneLook明显优于作者的模型:测试集是SeenDefinition, 由于输入词典定义已经存在,因此可以预先得到此结果存并储在OneLook数据库中,简单的文本匹配就可以轻松处理这种情况。但是,反向词典的输入查询实际上不能是确切的词典定义。 在Description测试集上,多通道模型可实现更好的整体性能。尽管OneLook的效果在acc @ 1上更好,但在实际应用中价值有限,因为人们往往从整个列表中选择合适的词语,而不是只选择列表中的第一个词语,更不用说OneLook的acc @ 1只有0.33。 MS-LSTM在Seen Definition和Description测试集的表现效果天壤之别,表示它的泛化能力和实用效果很差。 不论增强什么通道变量时,作者的多通道模型效果都要比最初的多通道模型效果要好,这证明了特征融合的潜力。 2016年,Hill等人发现BOW性能优于RNN, 而与RNN同样基于LSTM的多通道模型效果又远远超过了RNN和BOW,证明了RNN模型中双向编码的重要性,并且显示了RNN模型的潜力。
5.评测结果2在反向词典的实际应用中,除描述外,可能还会有关于目标词的额外信息。例如,作者可能会记得作者忘记的单词的首字母,或者在填字游戏中已知目标单词的长度。在本小节中,作者使用目标词的先验知识(包括POS标签,首字母和字长。更具体地说,作者从模型的前1,000个结果中提取满足给定先验知识的单词,然后重新评估性能。结果示于表2)。
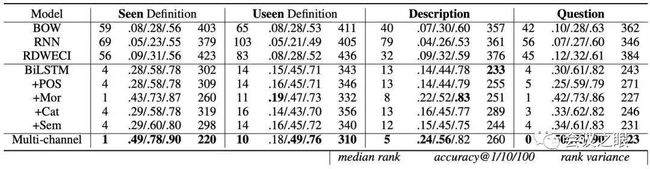
表1 基于先验知识的反向词典性能评估比较
作者可以发现,任何先验知识都会或多或少地改善作者模型的性能,这是预期的结果。但是,首字母和单词长度信息带来的性能提升比POS标签信息带来的性能提升要大得多。可能的原因如下。对于POS标签,已经在作者的多通道模型中进行了预测,因此带来的改进是有限的,这也表明作者的模型在POS标签预测中可以做得很好。对于首字母和单词长度,很难根据定义或描述来预测它们,因此在作者的模型中没有考虑。因此,它们可以过滤掉许多候选对象并显着提高性能。 给出了英文数据集上的实验结果,可以发现每个特征预测器的增加都会提高模型的效果,而包含所有特征的多通道模型得到了最好的性能,不但超过了此前最佳模型(state-of-the-art) MS-LSTM,而且在真实数据集Description上甚至超过了最流行的反向词典系统OneLook。
6.评测结果3图5显示了所有在acc@10的评测标准上,具有不同数量语义的单词上建立模型。很显然所有模型的性能都会随着sense数量增加而递减,这意味着这表明多义词是反向词典任务中的一个难点。但是作者的模型表现出了出色的鲁棒性,即使是在最多义的单词上,性能依旧棒棒的。
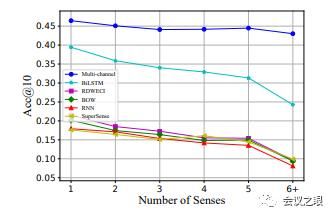
图6显示了所有模型在单词频率排名的变化模型表现的效果。作者发现对于所有反向词典模型,最频繁和最不频繁的单词都难以预测。最不常用的词通常具有较差的嵌入,这可能会损害基于NLM的模型的性能。另一方面,对于最常用的单词,尽管它们的嵌入效果更好,但它们通常是多义词。作者分别计算所有排名的平均语义数目。排名第一的单词的平均语义数要大得多,这说明了它的性能不佳。而且,作者的该模型还展示了出色的鲁棒性。
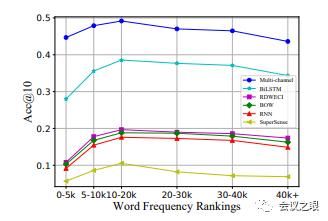
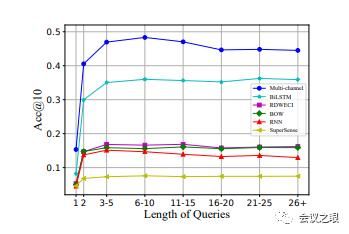
图7显示了查询长度对反向词典性能的影响。当输入查询只有一个单词时,模型性能非常差,尤其是作者的多通道模型。这很容易解释,因为从输入查询中提取的信息太有限了。在这种情况下,输出查询词的同义词可能是更好的选择。
总结和讨论
本文中,作者提出了一种多通道反向词典模型,该模型结合了多个预测变量,可以根据给定的输入查询预测目标词的特征。实验结果和分析表明,作者的模型达到了最先进的性能,并且还具有出色的鲁棒性。
将来,作者将尝试将作者的模型与文本匹配方法结合起来,以更好地处理极端情况,例如,单字输入查询。另外,作者正在考虑将模型扩展到跨语言反向词典任务。此外,作者将探讨将模型转移到相关任务(如问题回答)的可行性。