机器学习——可视化库Seaborn
seaborn是在matplotlib上的更高一级,它其实只是对matplotlib的一个补充,不能说它能够替代matplotlib,最显著的就是它可以美化图像。
为了让matplotlib更美观,seaborn提供了一些控制图表外表的方法。seaborn中可有5种主题供我们选择:
1、darkgrid(灰色网格)
2、whitegrid(白色网格)
3、dark(白色主题)
4、ticks(十字叉)
5、white(黑色主题)
首先需要导入import seaborn as sns这句话,前提是已经通过pip或者Anaconda安装好了seaborn库,下面就来学习一下:
这里需要注意一点的是,取文件名的时候千万不要跟包名一样,否则一定会报错说找不到“moudle”。
颜色绘图
调用seaborn的默认模板
我们可以使用sns.set()取seaborn的默认值,也就是默认主题。
# sns.set() #seaborn的默认取值
x=np.linspace(0,14,100) #x的取值为(0,14),共有100个点
for i in range(0,6):
plt.plot(x,np.sin(x+i*0.5)*(6-i))
plt.show()
在没有加入sns.set()这句话之前,图表的显示结果为:
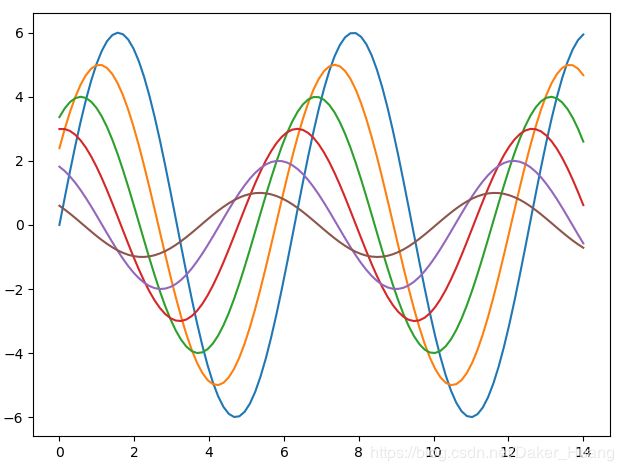
背景是一片白。加入sns.set()这句话之后:
sns.set()#seaborn的默认取值
x=np.linspace(0,14,100) #x的取值为(0,14),共有100个点
for i in range(0,6):
plt.plot(x,np.sin(x+i*0.5)*(6-i))
plt.show()
图表的显示结果为:

这样看数据的时候感觉就比较好。
seaborn的其它风格
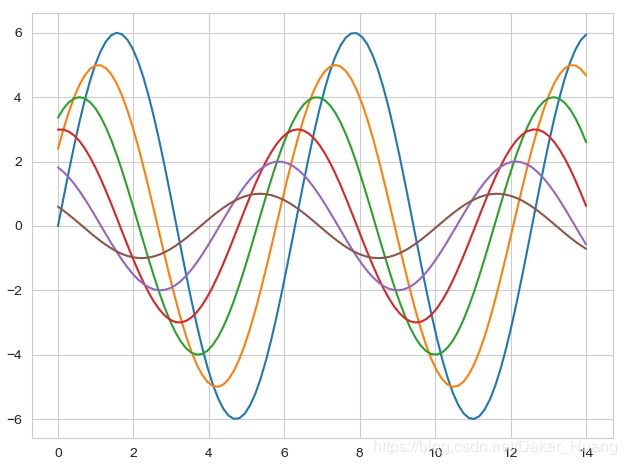
1、这里使用“whitegrid”这种主题试试看:
sns.set_style("whitegrid")#seaborn的whitegrid风格
x=np.linspace(0,14,100) #x的取值为(0,14),共有100个点
for i in range(0,6):
plt.plot(x,np.sin(x+i*0.5)*(6-i))
plt.show()
运行结果:
2、这里使用“ticks”这种主题试试看:

这里的区别就是x轴和y轴有刻度标识。
距离轴线的距离
对于图表,我们想让它距离x轴和y轴远一点,可以使用seaborn.despine(offset=?)这个方法。
sns.set_style("ticks")#seaborn的whitegrid风格
x=np.linspace(0,14,100) #x的取值为(0,14),共有100个点
for i in range(0,6):
plt.plot(x,np.sin(x+i*0.5)*(6-i))
sns.despine(offset=100)
plt.show()
运行结果:

轴线的显示与隐藏
在坐标轴中我们也可以使用seaborn.despine()来显示和隐藏坐标轴,只留下刻度数字。效果图如下(隐藏左边y轴的线):

上图中,可以看到y轴的线被隐藏了,我们也可以显示上面和右面的线,效果图如下:
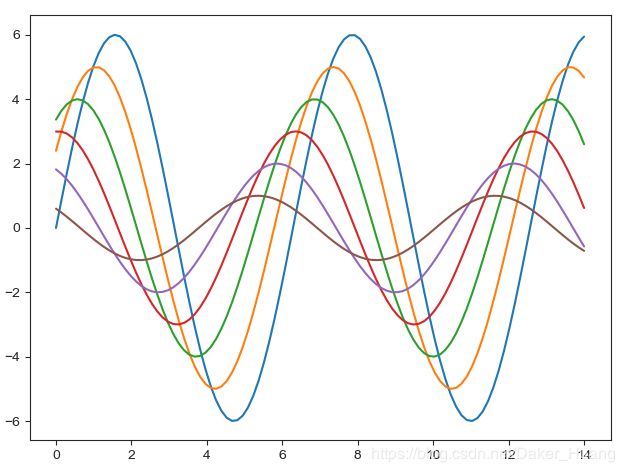
所有操作,都可以在seaborn.despine()中来实现。代码如下:
sns.set_style("ticks")#seaborn的whitegrid风格
x=np.linspace(0,14,100) #x的取值为(0,14),共有100个点
for i in range(0,6):
plt.plot(x,np.sin(x+i*0.5)*(6-i))
# True表示隐藏,False表示显示,默认为False
#sns.despine(top=False,right=False) #显示上面和右边的线
sns.despine(left=True) #隐藏左边的线
plt.show()
注意,这些语句要写在plt.show()的前面,不然不会有任何改变。
不同主题的子图
在一张大图上,我们也可以画不同主题的子图,具体子图的画法详见上篇机器学习——数据可视化库Matplotlib,这里可以使用with sns.axes_style(“ticks”)来划分一个域。
"""可以使用with sns.axes_style("ticks"):域将子图进行分隔设置"""
def y_sinx(flip=1):
x = np.linspace(0, 14, 100) # x的取值为(0,14),共有100个点
for i in range(0, 6):
plt.plot(x, np.sin(x + i * 0.5) * (6 - i)*flip)
# 第一张子图的风格
with sns.axes_style("ticks"):
plt.subplot(2, 1, 1)
y_sinx(1)
#第二张子图的风格
with sns.axes_style("dark"):
plt.subplot(2, 1, 2)
y_sinx(-1)
plt.show()
运行结果:
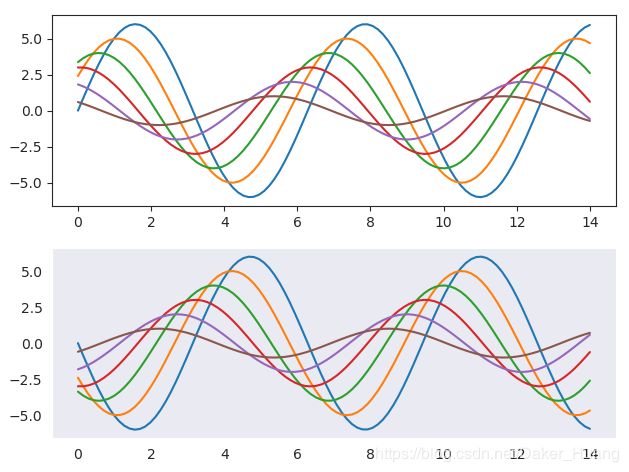
线,图的另外形式风格
这里有一个seaborn.set_context()函数,这里可以设置一些图表的风格。
sns.set() #使用默认风格
def y_sinx(flip=1):
x = np.linspace(0, 14, 100) # x的取值为(0,14),共有100个点
for i in range(0, 6):
plt.plot(x, np.sin(x + i * 0.5) * (6 - i)*flip)
sns.set_context(context="paper")
y_sinx(1)
plt.show()
1、当sns.set_context(context="paper")中为“paper”时,结果如下:
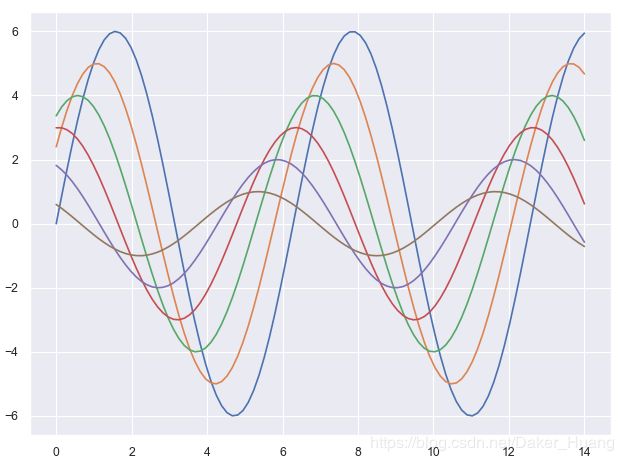
2、当sns.set_context(context="talk")中为“talk”时,结果如下:
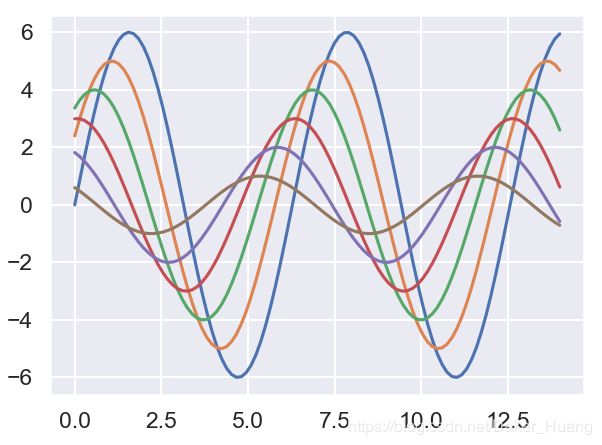
可以看到,线宽,字体都变得有些大了。
3、当sns.set_context(context="poster")中为“poster”时,结果如下:
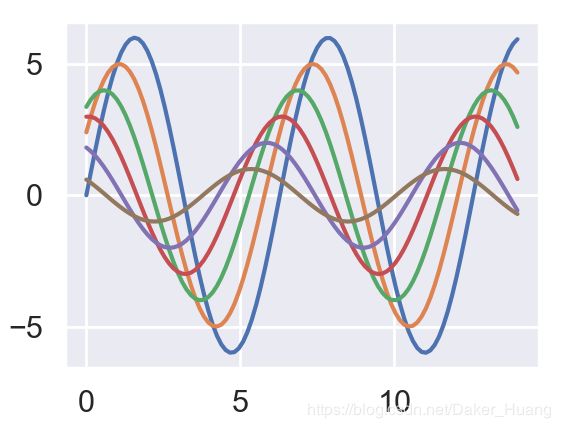
可以看到,线宽,字体变得更大了。
当我在sns.set_context(context="paper")的基础上增加两个参数值时:sns.set_context(context="paper",font_scale=2,rc={"lines.linewidth":1.5}),第二个参数表示字体大小,第三个参数表示线的粗细。显示结果如下:

可以看到,跟sns.set_context(context="paper")的结果比较,字体,线的粗细都有明显变化。
调色板
seaborn中还支持多种颜色:
1、color_palette()能传入任何matplotlib所支持的颜色
2、color_palette()不写参数则默认颜色
3、set_palette()设置所有图的颜色
sns.set(rc={"figure.figsize":(6,6)}) #定义画板的大小为(6,6)
current_palette=sns.color_palette() #默认颜色
sns.palplot(current_palette)
plt.show()
运行结果:

可以看到,seaborn中的默认颜色为以上10种颜色,几乎以深色颜色为主。
当我有10种以上颜色时要怎么办?这里最常用的是“hls”颜色空间,里面传入这样的参数就可以了:sns.color_palette("hls",12)
实例:
sns.set(rc={"figure.figsize":(6,6)}) #定义画板的大小为(6,6)
#current_palette=sns.color_palette() #默认颜色
current_palette=sns.color_palette("hls",12) #12种颜色
sns.palplot(current_palette)
plt.show()
运行结果:

上图中就出现了总共12种颜色的调色板。
饱和度和亮度
我们还可以调整饱和度和亮度,这里使用.hls_palette()方法。
"""
1、l->亮度(lightness)
2、s->饱和度(saturation)
"""
sns.set(rc={"figure.figsize":(6,6)}) #定义画板的大小为(6,6)
# current_palette=sns.color_palette("hls",12) #12种颜色
sns.palplot(sns.hls_palette(12,l=0.8,s=0.9))
plt.show()
运行结果:

调色板传颜色
data=np.random.normal(size=(20,8))+np.arange(8)/2
sns.boxplot(data=data,palette=sns.color_palette("hls",8))
plt.show()
运行结果:
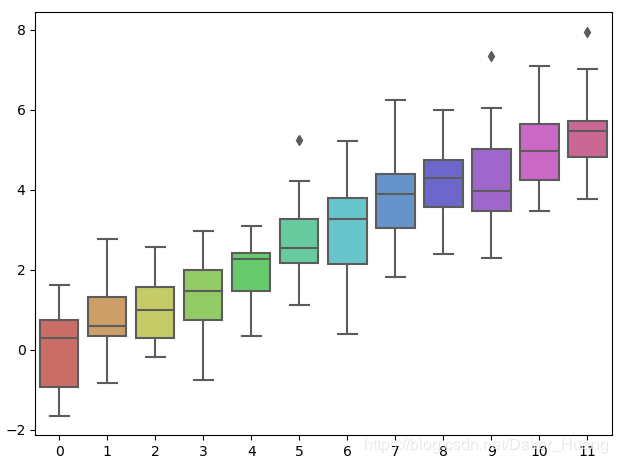
这里就把12种颜色一一绘制出来了,并且没有任何重叠。
成对出现相近颜色
使用color_palette()还可以成对的出现相近的颜色
sns.set(rc={"figure.figsize":(6,6)}) #定义画板的大小为(6,6)
# current_palette=sns.color_palette("hls",12) #12种颜色
sns.palplot(sns.color_palette("Paired",8))
plt.show()
运行结果:

使用xkcd颜色来命名颜色
xkcd使用了一套众包努力的针对随机RGB色的命名。产生了954个可以随机通过xkcd_rgb字典中调用的命名颜色。
plt.plot([0,1],[0,1],sns.xkcd_rgb["pale red"],lw=3) #分别为x轴取值,y轴取值,颜色,线宽
plt.plot([0,1],[0,2],sns.xkcd_rgb["medium green"],lw=3) #分别为x轴取值,y轴取值,颜色,线宽
plt.plot([0,1],[0,3],sns.xkcd_rgb["denim blue"],lw=3) #分别为x轴取值,y轴取值,颜色,线宽
plt.show()
运行结果:

这里只绘制三种颜色,其余的可在官网去查。
上面讲的都是离散型的画板,下面讲连续型画板。色彩会随数据变化,比如数据越来越重要,颜色则会越来越深。
连续画板(颜色深浅变化)
sns.palplot(sns.color_palette("Blues")) #绘制一个蓝色,从浅到深
plt.show()
运行结果:

可以看到,颜色是越来越深的,如果想要从深到浅,则需要添加一个“_r”后缀。如:
sns.palplot(sns.color_palette("Blues_r")) #绘制一个蓝色,从深到浅
plt.show()
运行结果:

连续画板(调用函数实现颜色深浅变化)
1、light_palette() 从浅到深
2、dark_palette() 从深到浅
从浅到深:
sns.palplot(sns.light_palette("green",8)) #从浅到深
plt.show()
运行结果:

从深到浅:
sns.palplot(sns.dark_palette("green",8)) #从深到浅
plt.show()
运行结果:

当然也可以直接使用light_palette()或dark_palette() 而不替换,现在进行下面操作进行颜色反转:
sns.palplot(sns.light_palette("green",reverse=True,n_colors=8)) #从浅到深,反转,变成从深到浅
# sns.palplot(sns.dark_palette("green",reverse=True,n_colors=8)) #从深到浅,反转,变成从浅到深
plt.show()
运行结果:

# sns.palplot(sns.light_palette("green",reverse=True,n_colors=8)) #从浅到深,反转,变成从深到浅
sns.palplot(sns.dark_palette("green",reverse=True,n_colors=8)) #从深到浅,反转,变成从浅到深
plt.show()
运行结果:

连续画板(调用函数实现颜色深浅变化-实例)
x,y=np.random.multivariate_normal([0,0],[[1,-0.5],[-0.5,1]],size=300).T
pal=sns.dark_palette("green",as_cmap=True)
sns.kdeplot(x,y,cmap=pal) #核密度估计图
plt.show()
运行结果:

这个可以很容易看出来,绿色从外向里逐渐变浅。
线性变换
在color_palette()中,里面可以填写“cubehelix”,可以让当前的亮度和饱和度做线性变换。
sns.palplot(sns.color_palette("cubehelix",8))
plt.show()
运行结果:

也可以指定一个区间:
sns.palplot(sns.cubehelix_palette(8,start=0.2,rot=0.95)) #8个颜色,0.2-0.95的区间
plt.show()
运行结果:

数据分析绘图
直方图数据绘制
sns.set() #设置默认主题
x=np.random.normal(size=100) #产生制定分布的数值,正太分布
sns.distplot(x,kde=False) #绘制直方图
plt.show()
运行结果:

上图中默认把数据切分成10块,即bins=10,我现在要把数据切分成更多。只需要改变bins的值就行了。
sns.set() #设置默认主题
x=np.random.normal(size=100) #产生制定分布的数值,正态分布
# sns.distplot(x,kde=False) #绘制直方图
sns.distplot(x,bins=20,kde=False)
plt.show()
运行结果:

根据均值和协方差生成数据
上面的直方图都是只针对一个特征进行的,那么特征与特征之间就不适用于直方图了,这里最好使用散点图绘制。
生成一些均值和协方差的数据:
mean,cov=[0,1],[(0.5,1),(1,1.5)]
data=np.random.multivariate_normal(mean,cov,200)#根据实际情况生成一个多元正态分布矩阵
df=pd.DataFrame(data,columns=["x","y"])
print(df)
运行结果:

绘制散点图:
在seaborn中可以使用seaborn.jointplot()方法来绘制散点图,同时它还会把每一个维度(这里表示x和y两个变量)的直方图绘制出来。
sns.set()
sns.jointplot(x="x",y="y",data=df)
plt.show()
运行结果:

散点图虽然比较明显,但是当数据比较多的时候,就不知道哪些地方的点比较密集,在seaborn.jointplot()中的参数中有这么一句话“kind=“hex””,这样可以把散点图变成如下模样:

通过判别颜色的方法来判断哪个地方颜色比较深。颜色越深的地方密集的点越多。
代码:
mean,cov=[0,1],[(0.5,1),(1,1.5)]
sns.jointplot(x="x",y="y",data=df)
with sns.axes_style("white"):
x,y=np.random.multivariate_normal(mean,cov,500).T
sns.jointplot(x=x,y=y,kind="hex")
plt.show()
数据分析绘图
“鸢尾花”数据集我们应该都不陌生,里面有4个特征,分别是花瓣的长度宽度、花萼的长度宽度。如果有csv或excel文件,可以用pandas读进来,但其实seaborn这个库已经内置了“鸢尾花”的数据集,现在我们想要比较两两特征之间的关系,可以使用sns.pairplot(iris)绘制。
使用如下代码:
iris=sns.load_dataset("iris") #读取鸢尾花数据集
sns.pairplot(iris) #绘图(直方图、散点图)
plt.show()
显示结果:
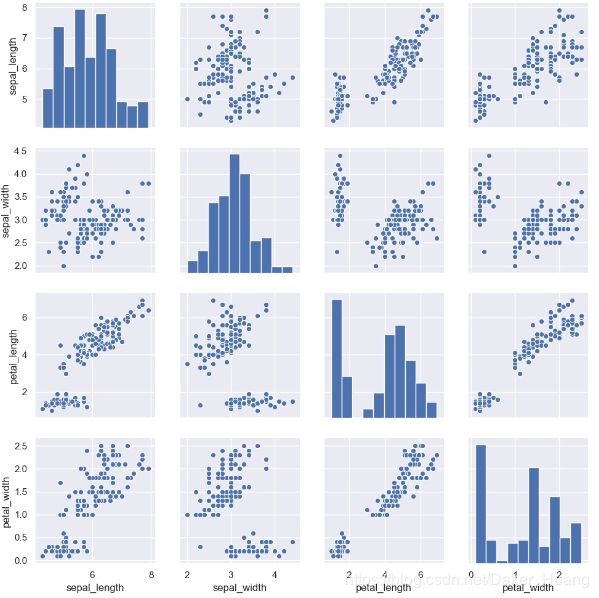
上图中,我们可以看到,斜对角线上全是直方图,其余的都是散点图。这是因为对角线上是单变量的对应情况,散点图是双变量的对应情况。
指定某两列绘制scatter图

我现在选择上面两列(已标注)的数值进行绘图,写下sns.pairplot(data=iris,vars=["sepal_length","petal_length"],hue="species")代码就可以,重点在于vars=["",""]。
sns.set()
iris=sns.load_dataset("iris") #读取内置数据集iris
print(iris.head())
g=sns.pairplot(data=iris,vars=["sepal_length","petal_length"],hue="species")
g.map(plt.scatter)
plt.show()
运行结果:
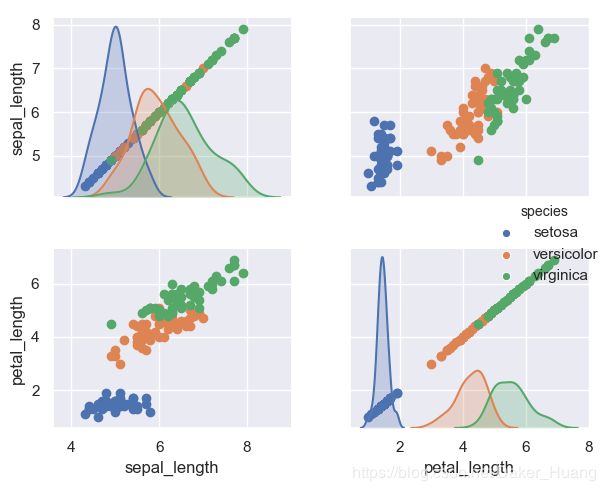
回归模型绘制
seaborn中内置了许多数据集,这里以“tips”为例
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head()) #打印前5项数据看看
我们来看看打印出来的数据集:

上图中,该数据集分别表示:
total_bill:某饭店消费付款金额;
tip:顾客给的小费;
sex:顾客性别
smoker:顾客是否吸烟;
day:星期几;
time:早中晚;
size:当前店内的顾客人数。
在seaborn中,我们可以使用regplot()和implot()来绘制线性关系,初学时推荐使用regplot(),下面就来绘制线性关系。
sns.regplot(x="total_bill",y="tip",data=tips) #绘制线性关系
plt.show()
代码中的x=“total_bill”,y="tip"分别是该数据集中的某两列,data=tips表示该数据集。
运行结果:

当我把上面代码中的sns.regplot(x="total_bill",y="tip",data=tips)变成sns.regplot(x="size",y="total_bill",data=tips),只是换了两列而已,输出的结果是这样的:

因为x轴的数都是整数,不是一个连续的值,所以它不太适合用来做回归分析,当数据不太满足分析的要求时,我们也可以对数据做一个很小很小的抖动,我在sns.regplot(x="size",y="total_bill",data=tips)这句代码中多写一个参数,变成sns.regplot(x="size",y="total_bill",data=tips,x_jitter=0.05),让x轴的数值增加或减少0.05,使其在原始点上上下浮动,输出的结果如图所示:

通过小范围的变化数值,使它能够不太能构成一些离散值,这样建立的回归模型会比原来相对准确一些。
数值偏移重叠
有这么一个事,当数据有重叠时,会影响我们进行数据的分析,所以我们要将它进行适当的偏移。
比如,原图是这样:

数据来源还是来源于seaborn的内置数据集“tips”,现在我们使用sns.stripplot()这个方法,让上图中的点进行适当的偏移,但是又不稍那么大的改变数值表示的含义。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
sns.stripplot(x="day",y="total_bill",data=tips,jitter=True) #jitter=True本来就是默认的,也可以不写
plt.show()
当然,上面sns.stripplot(x="day",y="total_bill",data=tips,jitter=True)中,jitter=True本来就是默认的,也可以不写。
运行结果:

除了上面的以外,seaborn中还有sns.swarmplot(),它的效果不像sns.stripplot()那样数值来回晃,它更像一颗圣诞树,如下图所示:
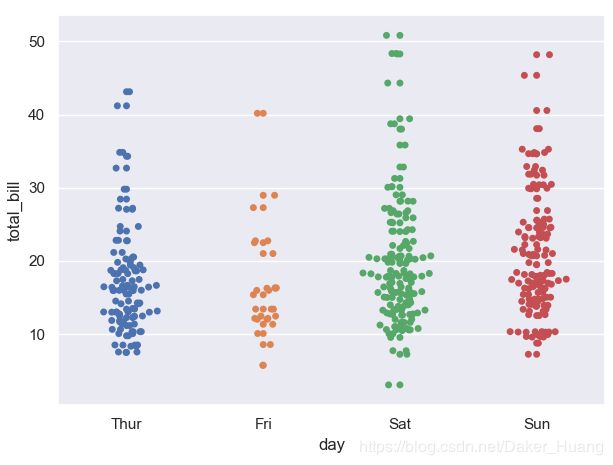
具体代码:
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
# sns.stripplot(x="day",y="total_bill",data=tips,jitter=True) #jitter=True本来就是默认的,也可以不写
sns.swarmplot(x="day",y="total_bill",data=tips)
plt.show()
当然,我们还可以给sns.swarmplot(x="day",y="total_bill",data=tips)添加“hue”属性,其实,在许多画图方法当中都可以添加“hue”属性,这里我们添加hue属性,看看效果如何(这里hue=“sex”,表示按照数据集中的“sex”列进行划分):
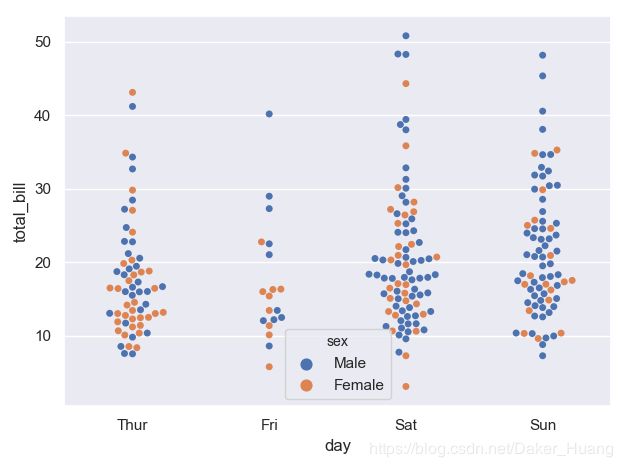
上面的这图有点像一棵棵树,我们暂且把它叫做“树形图”,这样给人的感觉就有点高大上了…
具体代码:
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
#sns.stripplot(x="day",y="total_bill",data=tips,jitter=True) #jitter=True本来就是默认的,也可以不写
#sns.swarmplot(x="day",y="total_bill",data=tips)
sns.swarmplot(x="day",y="total_bill",data=tips,hue="sex")
plt.show()
seaborn盒图
下面先说说这样一个概念,有一份数据,统计了一个学校所有男生的身高,普遍在1.5-1.8之间,但是,突然有几个数据达到了2.2或1.1,那么这几个数据就有可能是统计错误的,我们把它们称作离群点,这时盒图的作用就体现出来了,它可以很直观的看到离群点的分布状况。
此时我们引入IQR的概念,即四分位距:第1/4位与3/4位的距离(如果数据点为100,则该位置在25-75之间),N=1.5*IQR,如果一个值X>第3/4位+N,或X<1/4位-N,则点X位离群点。
代码:
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
sns.boxplot(x="day",y="total_bill",data=tips,hue="time") #盒图
plt.show()
运行结果:
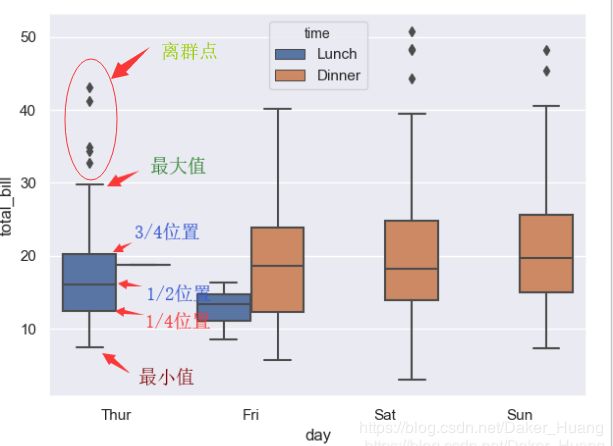
seaborn盒图水平画
在sns.boxplot()中国指定属性“orient=“h””就可以让盒图水平翻转
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
sns.boxplot(data=tips,orient="h") #盒图
plt.show()
运行结果:

seaborn小提琴图
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
sns.violinplot(x="day",y="total_bill",data=tips,hue="sex") #小提琴图
plt.show()
小提琴的“胖瘦”反映了数据的密集度,,如下图所示:

上面的图这样看着很不舒服,我们这样写:
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
# sns.violinplot(x="day",y="total_bill",data=tips,hue="sex") #小提琴图
sns.violinplot(x="day",y="total_bill",data=tips,hue="sex",split=True) #小提琴图,合并
plt.show()
运行结果:

我们把同一天的男女比例合并起来,就能很明显比较了。
绘图合并
当然我们也可以把两种类型的图片合在一起,使用1个plt.show()就可以了。这里把树形图和小提琴图合在一起。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
sns.swarmplot(x="day",y="total_bill",data=tips,hue="sex") #树形图
sns.violinplot(x="day",y="total_bill",data=tips,hue="sex",split=True) #小提琴图,合并
plt.show()
运行结果:

条形图
显示值的集中趋势可以用条形图。这里使用seaborn的内置数据集“titanic”,“泰坦尼克人员存活数据集”。
具体的数据如下:

sns.set()
titanic=sns.load_dataset("titanic") #titanic
print(titanic.head())
sns.barplot(x="sex",y="survived",hue="class",data=titanic) #条形图,泰坦尼克人员男女在不同舱位之间的存货率分析
plt.show()
运行结果:

上图表示了不同舱位(一、二、三等)的男女幸存几率。
点图
点图可以更好地描述变化差异。
sns.set()
titanic=sns.load_dataset("titanic") #titanic
print(titanic.head())
sns.pointplot(x="sex",y="survived",hue="class",data=titanic) #点图,泰坦尼克人员男女在不同舱位之间的存货率分析
plt.show()
运行结果:

上图中,男性和女性之间的存活率的值都用比较大的圆点标了出来。
多层面板分类图
有这么一个函数seaborn.factorplot(),通过输入不同的参数,它几乎封装了所有图,如条形图,折线图,盒图…
当它是默认,也就是不输入任何参数,它默认输出折线图
sns.set()
titanic=sns.load_dataset("titanic") #titanic
print(titanic.head())
sns.factorplot(x="sex",y="survived",hue="class",data=titanic) #默认折线图
plt.show()
运行结果:

这与上图中的点图就是一样的。
当我想要更换其它图时,这个函数就需要填写参数,即kind=“xxx”,比如条形图:kind=“bar”
sns.set()
titanic=sns.load_dataset("titanic") #titanic
print(titanic.head())
#sns.factorplot(x="sex",y="survived",hue="class",data=titanic) #默认折线图
sns.factorplot(x="sex",y="survived",hue="class",data=titanic,kind="bar") #条形图
plt.show()
运行结果:

也可以添加维度:
输入col="",就可以同时显示几列。
sns.set()
titanic=sns.load_dataset("titanic") #titanic
print(titanic.head())
#sns.factorplot(x="sex",y="survived",hue="class",data=titanic) #默认折线图
#sns.factorplot(x="sex",y="survived",hue="class",data=titanic,kind="bar") #条形图
sns.factorplot(x="sex",y="survived",hue="class",col="pclass",data=titanic,kind="bar")
plt.show()
运行结果:

seaborn.factorplot()可能会用到的一些参数:

每个变量的翻译解释:

Facetgrid使用方法
当我们想把数据集当中的许多子集进行展示的时候,我们就可以用这个函数了。
Facetgrid创建空白子图
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
g=sns.FacetGrid(data=tips,col="time") #以time为基准,创建col个子图,这里time只有lunch和dinner
plt.show()
运行结果:

Facetgrid绘制子图-单变量
接下来我们就来绘制子图中的内容。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
g=sns.FacetGrid(data=tips,col="time") #以time为基准,创建col个子图,这里time只有lunch和dinner
g.map(plt.hist,"tip") #单变量,绘制子图中的内容
plt.show()
运行结果:

Facetgrid绘制子图-多变量
直方图适合于单变量,多变量可以使用散点图。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
g=sns.FacetGrid(data=tips,col="time",hue="smoker") #以time为基准,创建col个子图,这里time只有lunch和dinner
g.map(plt.scatter,"total_bill","tip") #多变量,散点图,绘制子图中的内容
g.add_legend() #添加图注
plt.show()
运行结果:

Facetgrid绘制子图-设置大小布局
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
g=sns.FacetGrid(data=tips,col="time",hue="smoker",size=5) #在点的大小不变的情况下把图变大
g.map(plt.scatter,"total_bill","tip") #多变量,散点图,绘制子图中的内容
g.add_legend() #添加图注
plt.show()
运行结果:

当然,我们也可以加上这个属性:hue_kws={"marker":["","v"]},把图中的小点变成三角形。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
# g=sns.FacetGrid(data=tips,col="time",hue="smoker",size=5) #在点的大小不变的情况下把图变大
g=sns.FacetGrid(data=tips,col="time",hue="smoker",size=5,hue_kws={"marker":["","v"]}) #在点的大小不变的情况下把图变大
g.map(plt.scatter,"total_bill","tip") #多变量,散点图,绘制子图中的内容
g.add_legend() #添加图注
plt.show()
运行结果:
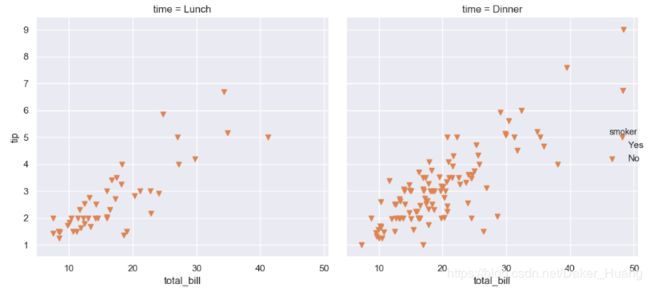
Facetgrid绘制子图-自定义显示x轴和y轴数值
这里可以使用.set()方法进行设置。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
g=sns.FacetGrid(data=tips,col="time",hue="smoker",size=5) #在点的大小不变的情况下把图变大
g.map(plt.scatter,"total_bill","tip") #多变量,散点图,绘制子图中的内容
g.add_legend() #添加图注
g.set(xticks=[10,30,50],yticks=[2,4,6,8]) #只显示x轴的10,30,50的点,只显示y轴的2,4,6,8的点
plt.show()
运行结果:

Facetgrid绘制子图-改变显示顺序
原来的图如果是这样:
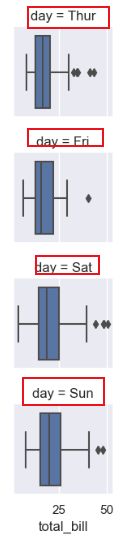
它是按照Thur->Fri->Sat->Sun的顺序显示的,我现在想要它按照Fri->Thur->Sun->Sat顺序显示,可以使用pandas中的“Categorical”函数进行index的调换。
seaborn.FacetGrid()默认读取DataFrame的格式数据,而pandas的数据格式就是DataFrame,所以最好使用pandas进行处理。
sns.set()
tips=sns.load_dataset("tips") #读取内置数据集tips
print(tips.head())
orderd_days=pd.Categorical(['Fri','Thur','Sun','Sat'])
g=sns.FacetGrid(data=tips,row="day",size=1.7,row_order=orderd_days) #在点的大小不变的情况下把图变大
g.map(sns.boxplot,"total_bill")
plt.show()
运行结果:
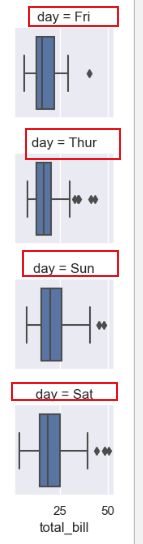
这样就实现了数据位置的替换。
热度图绘制
什么是热度图?比如说现在我们有一群离散点,它里面有的值比较大,有的值比较小,我们可以用颜色的深浅来表示,如果值越大,则颜色越深,这样看起来就十分显眼。
绘制热度图使用seaborn.heatmap()这个函数,现在随机定义一组数据,绘制一张热度图。
sns.set()
uniform_data=np.random.rand(3,3) #随机定义一个3*3的矩阵
print(uniform_data)
sns.heatmap(uniform_data)
plt.show()
运行结果:
随机输出的数据:

图像结果:

上图中,右侧有条形的调色板,在打印输出的矩阵中,可以看到值只要越接近0.2,颜色越黑。
注意:上图中由此调色板的最底部及最顶部的值就是数据集中的最小值与最大值。
也可以在该函数中添加最大最小值,当矩阵中的值小于最小值,则它等于最小值,当矩阵中的值大于最大值,则等于最大值,比如:
sns.set()
uniform_data=np.random.rand(3,3) #随机定义一个3*3的矩阵
print(uniform_data)
# sns.heatmap(uniform_data)
sns.heatmap(uniform_data,vmin=0.2,vmax=0.6) #最小值0.2,最大值0.6
plt.show()
运行结果:
随机输出的数据:

图片结果:

可以看到,坐标为(1,1)和(2,2)的色块都是黑色,因为它们大于0.5,所以被截断成0.5,故都为黑色。
热度图绘制_中间值
如果有一批正负数的数据,那么最好以0为中心来区分开颜色。
sns.set()
uniform_data=np.random.randn(3,3) #随机定义一个3*3的矩阵,有正有负
print(uniform_data)
# sns.heatmap(uniform_data)
sns.heatmap(uniform_data,center=0) #中心值为0
plt.show()
打印输出的矩阵:

图片结果:
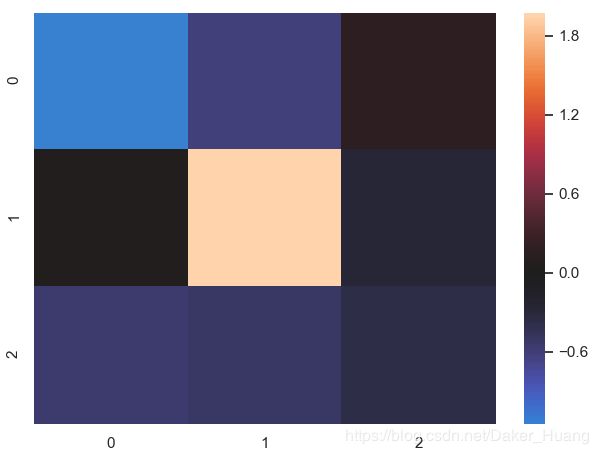
上图中,右侧调色板有0.0这个值,如果是正数,则是别的颜色,如果是负数,则是另外的颜色,色差也比较大。
热度图绘制_航班信息绘制
seaborn中内置了"flights"这样一个简单的数据集,它的具体内容如下:
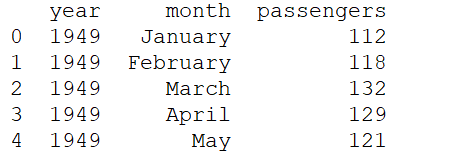
分别表示年,月,以及当月乘坐航班的总人数。现在就用热度图来绘制一下航班信息。
sns.set()
flights=sns.load_dataset("flights") #读取内置的航班数据集
print(flights.head())
flights=flights.pivot("month","year","passengers") #把它转化成一个二维数据,横轴是year,纵轴是month,值是passengers
sns.heatmap(flights)
plt.show()
运行结果:

当然,如果颜色很接近,也没法看,这时可以把原来的数值放进去。
sns.set()
flights=sns.load_dataset("flights") #读取内置的航班数据集
print(flights.head())
flights=flights.pivot("month","year","passengers") #把它转化成一个二维数据,横轴是year,纵轴是month,值是passengers
# sns.heatmap(flights)
sns.heatmap(flights,annot=True,fmt="d") #annot=True表示把值显示在图中,fmt="d"表示数字的一种字体
plt.show()
显示结果:

注意:代码sns.heatmap(flights,annot=True,fmt="d") #annot=True表示把值显示在图中,fmt="d"表示数字的一种字体中的"fmt=“d”"千万不要省略,否则图中的值会是一些科学计数值:

这样的值显然是我们不需要的,所以,"fmt=“d”"千万要加上。
上面的图虽然有数值,但是看着也不顺眼,我们再来美化一下:
sns.set()
flights=sns.load_dataset("flights") #读取内置的航班数据集
print(flights.head())
flights=flights.pivot("month","year","passengers") #把它转化成一个二维数据,横轴是year,纵轴是month,值是passengers
# sns.heatmap(flights)
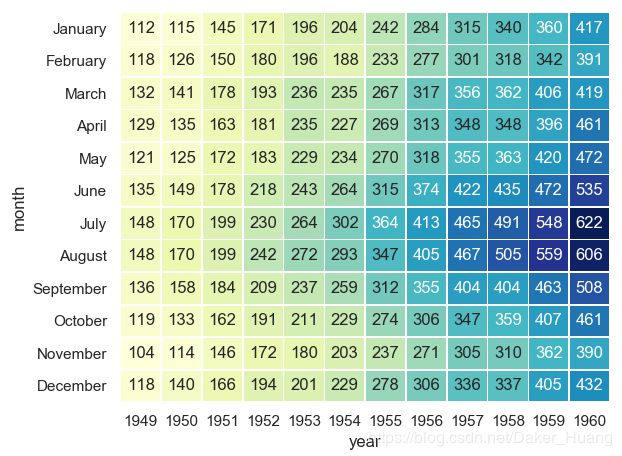
sns.heatmap(flights,annot=True,fmt="d",linewidths=0.5) #annot=True表示把值显示在图中,fmt="d"表示数字的一种字体
plt.show()
我们在sns.heatmap()中加上"linwidths"这个属性,它表示色块与色块之间的间距。
运行结果:

上图是不是就看着舒服了一些呢?
热度图绘制_自定义颜色
sns.set()
flights=sns.load_dataset("flights") #读取内置的航班数据集
print(flights.head())
flights=flights.pivot("month","year","passengers") #把它转化成一个二维数据,横轴是year,纵轴是month,值是passengers
sns.heatmap(flights,annot=True,fmt="d",linewidths=0.5,cmap="YlGnBu") #annot=True表示把值显示在图中,fmt="d"表示数字的一种字体
plt.show()
运行结果:

具体的其它颜色可以去查询参考手册。
热度图绘制_调色板隐藏
如果不想要上图中的调色板,我们也可以进行隐藏:
sns.set()
flights=sns.load_dataset("flights") #读取内置的航班数据集
print(flights.head())
flights=flights.pivot("month","year","passengers") #把它转化成一个二维数据,横轴是year,纵轴是month,值是passengers
sns.heatmap(flights,annot=True,fmt="d",linewidths=0.5,cmap="YlGnBu",cbar=False) #annot=True表示把值显示在图中,fmt="d"表示数字的一种字体
plt.show()
运行结果:
可以看到,调色板被隐藏了,但是不建议这么做。