python开发之算法&数据结构(一)
python开发之算法&数据结构(一)
- 一、算法基础
- 1. 时间复杂度
- 2. 空间复杂度
- 3. 递归
- 二、列表查找
- 1. 顺序查找
- 1.1 代码实现
- 1.2 时间复杂度(O(n))
- 2. 二分查找
- 2.1 查找过程
- 2.2 代码实现
- 2.3 时间复杂度(O(logn))
- 三、排序lowB三人组
- 1. 冒泡排序
- 1.1 排序过程
- 1.2 代码实现
- 1.3 时间复杂度(O(n²))
- 1.4 空间复杂度(O(1))
- 2. 选择排序
- 2.1 排序过程
- 2.2 代码实现
- 2.3 时间复杂度(O(n²))
- 2.4 空间复杂度(O(1))
- 3. 插入排序
- 3.1 排序过程
- 3.2 代码实现
- 3.3 时间复杂度(O(n²))
- 3.4 空间复杂度(O(1))
一、算法基础
1. 时间复杂度
在计算机科学中,时间复杂性,又称时间复杂度(Time Complexity ),算法的时间复杂度是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。
- Python的效率大概1秒能计算107个基本运算。
例1. 时间复杂度为:O(1)
print("hello world")
例2. 时间复杂度为:O(n)
for i in range(n):
print("hello world")
例3. 时间复杂度为:O(n²)
for i in range(n):
for j in range(n):
print("hello world")
例4. 时间复杂度为:O(n³)
for i in range(n):
for j in range(n):
for k in range(n):
print("hello world")
例5. 时间复杂度为:O(n²)
for i in range(n):
for j in range(i):
print("hello world")
例5分析:当i=0时,第二层循环执行0次;当i=1时,第二层循环执行1次;当i=2时,第二层循环执行2次;以此类推…当i=n-1时,第二层循环执行n-1次;整个程序执行了0+1+2+3+…+(n-1)次,利用等差数列求和公式,求得整个程序执行了 n²/2-n/2 次。但是时间复杂度考虑的是规模趋于无穷大的情况,不包括低阶项和首项系数,故例5的时间复杂度为:O(n²) 。
例6. 时间复杂度为:O(logn)
while n > 1:
print(n)
n = n // 2
例6分析:假设n=64,发现打印的n分别是64,32,16,8,4,2,一共打印了6次,由2^6=64 => 6 = log264,所以时间复杂度为:O(log2n);又因为计算机处理的是二进制数据,多数情况都是以2为底的情况,所以时间复杂度可以写为:O(logn) 。
常见时间复杂度效率排序:
O(1) < O(logn) < O(n) < O(nlogn) < O(n²) < O(n²logn) < O(n³)
一眼法判断时间复杂度:
- 先看是否有循环减半的过程,如果有—> O(logn);
- 几层循环就是n的几次方的复杂度(循环要是关于n的)。
2. 空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间(内存)大小的量度。
空间换时间:
- 在实际公司应用中,更注重的是时间复杂度尽可能的小,毕竟空间可以通过加内存条解决,所以会有“空间换时间”的思想。
3. 递归
递归的两个特点:
- 调用自身
- 结束条件
对比以下两个递归函数:
def func1(x):
if x > 0:
print(x)
func1(x-1)
def func2(x):
if x > 0:
func2(x-1)
print(x)
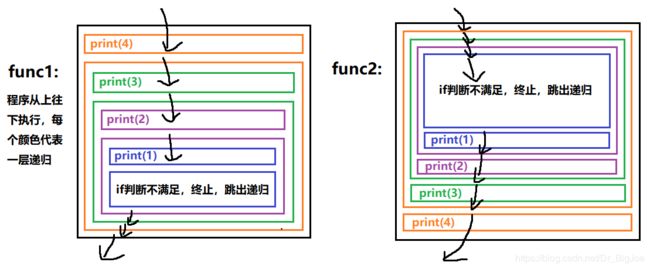
分析:假设x = 4,func1打印输出:4,3,2,1;而func2打印输出:1,2,3,4。原因是func1是先打印再调用递归,func2是先调用递归再打印,当x = 4时执行到 func2(x-1),就会跳回代码开头执行 func2(x),第一层递归此时x = 3,执行到 func2(x-1)时,又跳回代码开头执行 func2(x),第二层递归此时x = 2,执行到 func2(x-1)时,又跳回代码开头执行 func2(x),第三层递归此时x =1,执行到 func2(x-1)时,又跳回代码开头执行 func2(x),第四层递归此时x = 0不满足if判断(结束条件),代码就逐层跳出递归,依次打印:1,2,3,4。func1是在往里跳的时候打印,func2是在往外跳的时候打印。
递归经典例子——汉诺塔,可参考这篇:《从汉诺塔到Python递归,一波带走》
原文链接:https://blog.csdn.net/Dr_BigJoe/article/details/105255910
二、列表查找
1. 顺序查找
从列表第一个元素开始,顺序进行搜索,找到返回元素下标(索引),未找到返回None。
1.1 代码实现
# 顺序查找:
def linear_search(li,n):
for i in range(len(li)):
if li[i] == n:
return i
return None
1.2 时间复杂度(O(n))
顺序查找的时间复杂度为:O(n)
2. 二分查找
- 二分查找重要前提:必须是 有序 列表!
- 从有序列表的候选区 data[0:n] 开始,把待查找的值与候选区中间的值进行比较,每次比较可使候选区减半。
2.1 查找过程
假设一个长度为9的升序列表,要查找的目标数是:4
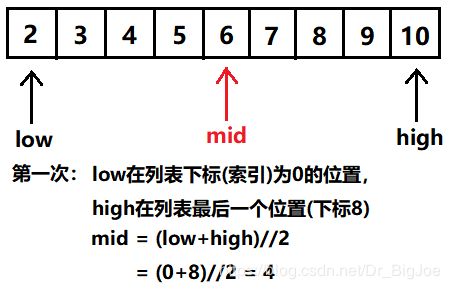
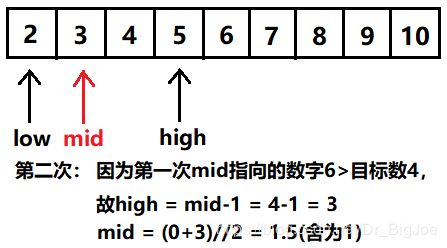

注意:这里的low, mid, high进行的加减操作均是下标(索引)的加减。
2.2 代码实现
二分查找代码关键点:候选区
# 二分查找:
def binary_search(li,n):
low = 0
high = len(li) - 1
while low <= high:
mid = (low + high) // 2 # //表示是整除,取做除法后比浮点数小的最近整数,5//2=2,-5//2=-3
if li[mid] > n: # 若mid指向的数>目标数,则把high移到mid左边一格
high = mid - 1
elif li[mid] < n: # 若mid指向的数<目标数,则把low移到mid右边一格
low = mid + 1
else:
return mid
return None
# 递归版本的二分查找:
def bin_search(li,n,low,high):
if low <= high:
mid = (low + high) // 2
if li[mid] == n:
return mid
elif li[mid] > n:
return bin_search(li,n,low,mid-1) # 尾递归
else:
return bin_search(li,n,mid+1,high)
else:
return
尾递归:一个函数只有最后一句是递归调用就是尾递归。尾递归的效率和循环差不多,因为尾递归会被编译器优化成循环。
2.3 时间复杂度(O(logn))
设列表有n个元素,则查找次数与剩余待查元素数量有如下对应关系:
查找次数 剩余待查元素数量
第1次 n/2
第2次 n/(2^2)
第3次 n/(2^3)
. .
. .
. .
第k次 n/(2^k)
由于右边一列表示的是剩余待查元素的数量,所以剩余数量始终应该大于等于1。而时间复杂度是计算查找最坏(找最多次)的情况,就是查到剩余最后一个数了才查到目标数,即:n/(2^k) = 1 => k = log2n ,所以时间复杂度为:O(log2n);又因为计算机处理的是二进制数据,多数情况都是以2为底的情况,所以时间复杂度可以写为:O(logn) 。
三、排序lowB三人组
1. 冒泡排序
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
1.1 排序过程
假设一个长度为9的列表,扫描趟数是从0开始。
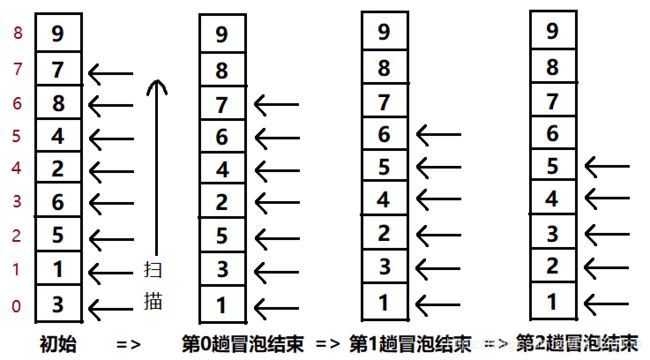
从上图可以看到在第2趟冒泡结束时排序就完成了,对于普通冒泡排序其实还会继续扫描,只是不交换元素的位置,这样会浪费时间;于是还给出了一种优化版的冒泡排序,见下代码。
1.2 代码实现
冒泡排序代码关键点:有序区、无序区、趟、扫描指针
代码思路:外层一个循环控制扫描趟数,内层一个循环控制扫描指针。
# 普通冒泡排序:
def bubble_sort(li):
for i in range(len(li)-1): # i表示趟数
for j in range(len(li)-i-1): # j表示每次扫描的指针
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
# 优化版:如果冒泡执行一趟而没有发生交换,说明已经是排好序的,直接结束算法
def bubble_sort1(li):
for i in range(len(li)-1): # i表示趟数
change = False
for j in range(len(li)-i-1): # j表示每次扫描的指针
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
change = True
if not change:
return
1.3 时间复杂度(O(n²))
设列表有n个元素,考虑最坏的情况是扫描到最后一趟的最后一个元素才排序完成,则扫描的总次数为:(n-1) + (n-2) + (n-3) + … + 2 + 1,根据等差数列求和公式,得扫描的总次数为:n²/2 - n/2,故时间复杂度为:O(n²)
1.4 空间复杂度(O(1))
冒泡排序的空间复杂度为:O(1)
2. 选择排序
第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
2.1 排序过程
假设一个长度为9的列表,扫描趟数是从0开始,下图蓝色箭头是每趟扫描找出的最小元素,红色表示有序区,黑色表示无序区。
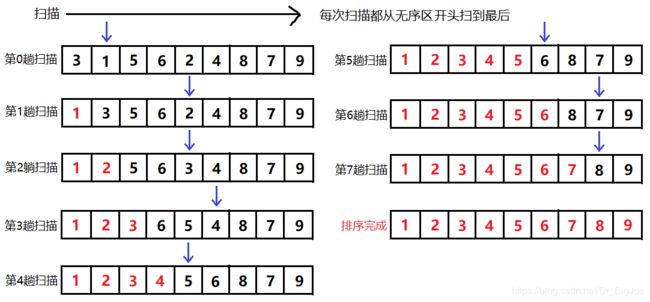
2.2 代码实现
选择排序关键点:无序区、最小元素的位置
代码思路:外层一个循环控制趟数,内层一个循环控制指针。每趟是从无序区第一个元素开始扫描,要记录每趟扫描选出的最小元素的位置与无序区第一个元素位置交换,而无序区第一个元素位置是递增的。
# 选择排序:
def sel_sort(li):
for i in range(len(li)-1):
# 第i趟开始,无序区为从i到最后
# 找到无序区的最小值,保存最小值的位置
min_pos = i
for j in range(i+1,len(li)):
if li[j] < li[min_pos]:
min_pos = j
li[min_pos], li[i] = li[i], li[min_pos]
2.3 时间复杂度(O(n²))
设列表有n个元素,考虑最坏的情况是扫描到最后一趟的最后一个元素才排序完成,则扫描的总次数为:(n-1) + (n-2) + (n-3) + … + 2 + 1,根据等差数列求和公式,得扫描的总次数为:n²/2 - n/2,故时间复杂度为:O(n²)
2.4 空间复杂度(O(1))
选择排序的空间复杂度为:O(1)
3. 插入排序
- 插入排序是指在待排序的元素中,假设前面n-1(其中n>=2)个数已经是排好顺序的,现将第n个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。按照此法对所有元素进行插入,直到整个序列排为有序的过程,称为插入排序。
- 插入排序类似打扑克,一张一张的摸牌并排序,默认一开始手里有一张牌,所以摸牌的下标(索引)是从1开始。每摸一张牌都与手里的牌从最后往前依次比较,将摸到的牌插入正确的位置。
3.1 排序过程
假设一个长度为9的列表,下图红色表示有序区,黑色表示无序区。
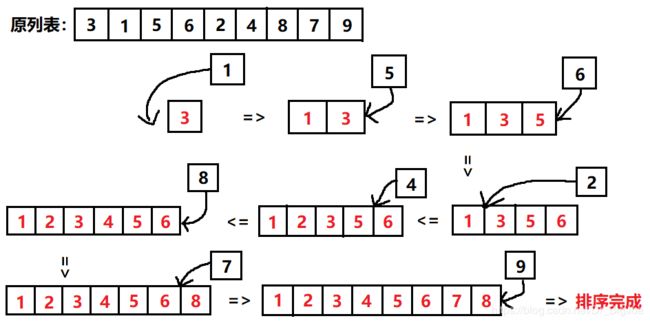
3.2 代码实现
插入排序关键点:有序区(手里的牌)、无序区(待摸的牌)
代码思路:外层循环控制每次摸牌,内层循环控制每次比较。插入牌前该位置后的牌都要后移,所以要把摸到的牌存起来,不然后移会覆盖掉摸得牌的值。注意退出循环条件有两个:1. 指针<0,说明摸到的牌比手里的牌都小;2. li[i]>li[j],说明摸到的牌比手里j位置的牌大,此时该插入牌。
# 插入排序:
def insert_sort(li):
for i in range(1,len(li)): # i是摸到牌的下标
temp = li[i]
j = i - 1 # j是手里最后一张牌的下标
# 两个终止条件顺序不能乱,因为布尔运算有短路功能
while j >= 0 and li[j] > temp: # j小于0表示temp是最小的
li[j+1] = li[j]
j -= 1
li[j+1] = temp
# 插入排序的另一种写法:
def insert_sort1(li):
for i in range(1,len(li)): # i是摸到牌的下标
temp = li[i]
for j in range(i-1,-2,-1):
if li[j] > temp:
li[j+1] = li[j]
else:
break
li[j+1] = temp
布尔运算短路功能:
1>2 and 3<4
实际上式在1>2为False时该式就不再往下判断直接返回False了,因为and是一否则否;
2>1 or 3<4
同理上式在2>1为True时该式就不再往下判断直接返回True了,因为or是一True则True。
不用if写判断语句:
def func():
print("Hello")
a = -2
a > 0 and func()
3.3 时间复杂度(O(n²))
设列表有n个元素,考虑最坏的情况是每次摸到牌都要插入手里牌的最前面位置,也就是摸到的牌要与手里的牌全部比较一遍,手里的牌也全要往后挪一格,则比较总次数为:1 + 2 +3 + … + (n-3) + (n-2) + (n-1) ;移动总次数为:1 + 2 +3 + … + (n-3) + (n-2) + (n-1) ,根据等差数列求和公式,得总次数为:n² - n,故时间复杂度为:O(n²)
3.4 空间复杂度(O(1))
插入排序的空间复杂度为:O(1)
================================================================
本篇涉及代码见week17