Matlab k-means
K-means 聚类算法
- Syntax
- Description
- Input Arguments
- Examples
- Train a k-Means Clustering Algorithm
- Partition Data into Two Clusters
- Cluster Data Using Parallel Computing
全文翻译自Matlab官方文档 kmeans
Syntax
idx = kmeans(X,k)
idx = kmeans(X,k,Name,Value)
[idx,C] = kmeans(___)
[idx,C,sumd] = kmeans(___)
[idx,C,sumd,D] = kmeans(___)
Description
idx = kmeans(X,k)执行k-均值聚类,将size为(n,p)数据矩阵 X X X的划分为k个簇,并返回包含每个簇索引的n*1向量idx。 x x x的行为点,列为变量。默认情况下,k-means度量为平方欧氏距离和k-means++算法来初始化类中心。
idx=kmeans(X,k,Name,Value)返回具有由一个或多个(Name,Value)参数对指定的附加选项的聚类索引。例如,指定余弦距离、使用新初始值重复聚类的次数或使用并行计算。
[idx,C]=kmeans(____):C为k*p的矩阵,为k个簇的质心位置。
[idx,C,sumd]=kmeans(____):sumd为k*1向量,簇内的点到质心距离的和。
[idx,C,sumd,D]=kmeans(____):D为n*k矩阵,为每个点到每个质心的距离。
Input Arguments
- X — Data
Examples
Train a k-Means Clustering Algorithm
采用k均值聚类数据,然后绘制聚类区域。
加载Fisher虹膜数据集,使用花瓣的长度和宽度作为预测值:
load fisheriris
X = meas(:,3:4);
figure;
plot(X(:,1),X(:,2),'k*','MarkerSize',5);
title 'Fisher''s Iris Data';
xlabel 'Petal Lengths (cm)';
ylabel 'Petal Widths (cm)';
如下图:
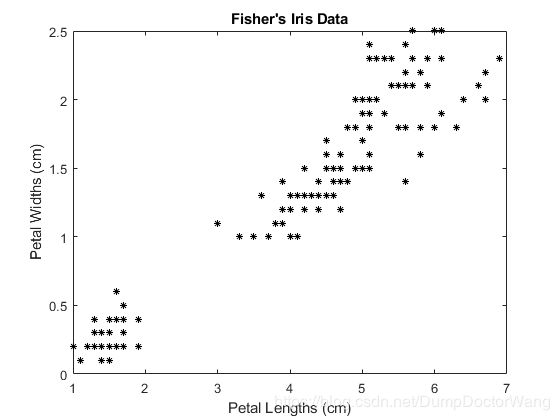
更大的簇似乎被分成一个低方差区域和一个高方差区域。这可能表明较大的簇是两个重叠的簇,故可分为3个簇。
对数据进行聚类,指定k=3个簇:
rng(1); % 固定随机数,保证结果可复现,自己写的可去掉这行
[idx,C] = kmeans(X,3);
k means使用k-means++算法初始化质心,默认情况下使用平方欧氏距离。通过设置’Replicates’的名称-值对参数对来搜索较低的局部最小值。
idx是与 x x x中的观测值相对应的预测聚类索引的向量。C是包含最终质心位置的3*2矩阵。
为可视,迭代一次k-means算法:
% 定义一个网格数据
x1 = min(X(:,1)):0.01:max(X(:,1));
x2 = min(X(:,2)):0.01:max(X(:,2));
[x1G,x2G] = meshgrid(x1,x2);
XGrid = [x1G(:),x2G(:)]; % Defines a fine grid on the plot
% 聚类迭代一次
idx2Region = kmeans(XGrid,3,'MaxIter',1,'Start',C);
输出:
Warning: Failed to converge in 1 iterations.
kmeans显示一个警告,指出算法没有收敛,因为k-means只进行了一次迭代。
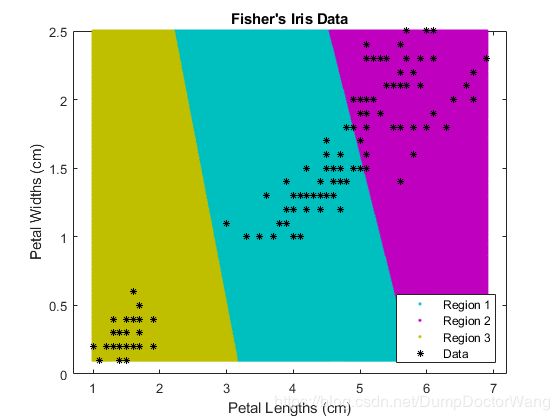
画图:
figure;
gscatter(XGrid(:,1),XGrid(:,2),idx2Region,...
[0,0.75,0.75;0.75,0,0.75;0.75,0.75,0],'..');
hold on;
plot(X(:,1),X(:,2),'k*','MarkerSize',5);
title 'Fisher''s Iris Data';
xlabel 'Petal Lengths (cm)';
ylabel 'Petal Widths (cm)';
legend('Region 1','Region 2','Region 3','Data','Location','SouthEast');
hold off;
得到如下结果:
Partition Data into Two Clusters
随机生成样本数据:
rng default; % For reproducibility
X = [randn(100,2)*0.75+ones(100,2);
randn(100,2)*0.5-ones(100,2)];
figure;
plot(X(:,1),X(:,2),'.');
title 'Randomly Generated Data';
得到:
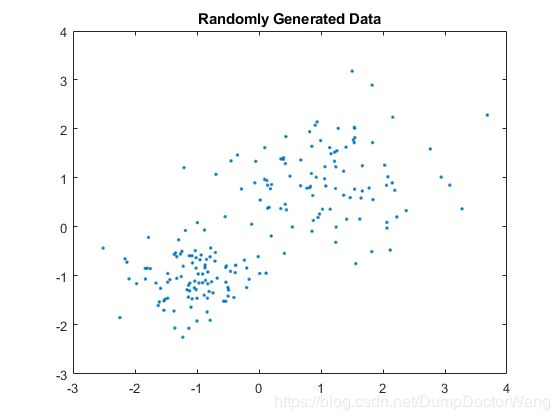
图片中的数据好像是两个簇。因此将数据划分为两个簇,然后从五个不同初始化中选择最佳的结果:
opts = statset('Display','final');
[idx,C] = kmeans(X,2,'Distance','cityblock',...
'Replicates',5,'Options',opts);
输出:
Replicate 1, 3 iterations, total sum of distances = 201.533.
Replicate 2, 5 iterations, total sum of distances = 201.533.
Replicate 3, 3 iterations, total sum of distances = 201.533.
Replicate 4, 3 iterations, total sum of distances = 201.533.
Replicate 5, 2 iterations, total sum of distances = 201.533.
Best total sum of distances = 201.533
默认情况下,k-means使用k-means++分别初始化初始中心。
绘制聚类和聚类质心:
figure;
plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12)
hold on
plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12)
plot(C(:,1),C(:,2),'kx',...
'MarkerSize',15,'LineWidth',3)
legend('Cluster 1','Cluster 2','Centroids',...
'Location','NW')
title 'Cluster Assignments and Centroids'
hold off
输出:
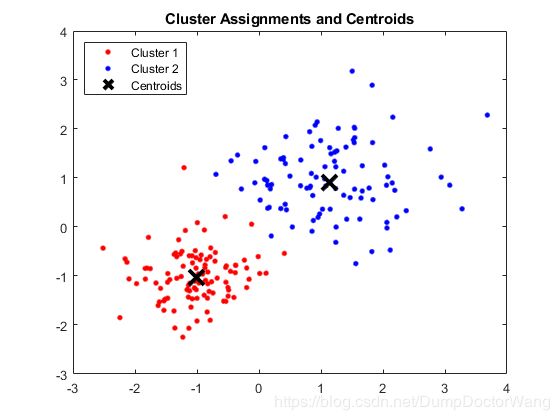
通过将idx作为 silhouette的参数,可以确定簇之间的分离程度。
Cluster Data Using Parallel Computing
聚类大型数据集可能需要时间。如果你有一个并行计算工具箱™license并设置并行计算的选项,然后kmeans并行运行每个集群任务(或复制)。而且,如果Replicates>1,那么并行计算减少了收敛时间。
从高斯混合模型随机生成大数据集:
Mu = bsxfun(@times,ones(20,30),(1:20)'); % Gaussian mixture mean
rn30 = randn(30,30);
Sigma = rn30'*rn30; % Symmetric and positive-definite covariance
Mdl = gmdistribution(Mu,Sigma); % Define the Gaussian mixture distribution
rng(1); % For reproducibility
X = random(Mdl,10000);
Mdl是一个包含20个分量的30维gm分布模型。X是由Mdl生成的10000乘30的数据矩阵。
指定并行计算的选项:
stream = RandStream('mlfg6331_64'); % Random number stream
options = statset('UseParallel',1,'UseSubstreams',1,...
'Streams',stream);
RandStream的输入参数mlfg6331_64指定使用乘法滞后Fibonacci生成器算法。options是一个结构数组,具有指定用于控制估计的选项的字段。
使用k-means聚类对数据进行聚类。指定数据中有k=20个集群,并增加迭代次数。通常,目标函数包含局部极小值。指定10个副本以帮助查找较低的本地最小值。
tic; % Start stopwatch timer
[idx,C,sumd,D] = kmeans(X,20,'Options',options,'MaxIter',10000,...
'Display','final','Replicates',10);
Starting parallel pool (parpool) using the ‘local’ profile …
connected to 6 workers.
Replicate 5, 72 iterations, total sum of distances = 7.73161e+06.
Replicate 1, 64 iterations, total sum of distances = 7.72988e+06.
Replicate 3, 68 iterations, total sum of distances = 7.72576e+06.
Replicate 4, 84 iterations, total sum of distances = 7.72696e+06.
Replicate 6, 82 iterations, total sum of distances = 7.73006e+06.
Replicate 7, 40 iterations, total sum of distances = 7.73451e+06.
Replicate 2, 194 iterations, total sum of distances = 7.72953e+06.
Replicate 9, 105 iterations, total sum of distances = 7.72064e+06.
Replicate 10, 125 iterations, total sum of distances = 7.72816e+06.
Replicate 8, 70 iterations, total sum of distances = 7.73188e+06.
Best total sum of distances = 7.72064e+06
toc % Terminate stopwatch timer
Elapsed time is 61.915955 seconds.
命令窗口指示有六个线程可用。系统上的线程数量可能会有所不同。命令窗口显示每次复制的迭代次数和终端目标函数值。输出参数包含replicate 9的结果,因为它的总距离之和最低。