BEGAN
《BEGAN: Boundary Equilibrium Generative Adversarial Networks》
github

背景
在传统的GAN中,虽然提供了一种新的方法来学习数据分布,也取得了相比以前的方法不错的效果,但是它仍存在以下的几个问题:
- 即便使用很多的训练技巧,GAN仍然很难训练
- 模型的超参数的选择对于模型最终的效果十分重要
- 难以控制生成图像的质量和多样性
- 难以平衡判别器和生成器之间的收敛
- GAN易出现梯度消失和模式坍缩问题
针对于这些问题,作者提出了一种基于均衡思想的GAN的变体BEGAN,它相对于其他的GANs的贡献或是优势在于:
- 一个简单且鲁棒性更好的 GAN 架构,使用标准的训练步骤实现了快速、稳定的收敛,生成的图像质量更高
- 提出了一种均衡的概念,使得判别器和生成器在训练过程中保持平衡
- 一种控制在图像多样性与视觉质量之间权衡的新方法
- 提出了用于衡量收敛的方法
- 提出了一个由Wasseratein loss衍生而来的配套的loss
损失函数
在BEGAN出现之前,DCGAN使用了卷积结构来提高生成图像的质量;EBGAN提高收敛的稳定性和模型的鲁棒性;WGAN提高了稳定性和更好的模式覆盖,但是收敛速度慢。
上述的这些GAN的变体以及其他的GAN相关的模型,都是基于训练数据实现的一种直接匹配,希望生成模型的数据分布 p G p_{G} pG尽可能的接近真实数据分布 p d a t a p_{data} pdata。而BEGAN中提出了另一种思路,它使用了自动编码器(auto-encoder)做为判别器 D D D ,它所做的是尽可能地匹配误差的分布而不是直接匹配样本的分布,如果误差的分布之间足够的接近,那么真实的样本之间的分布也会足够的接近,生成的结果质量同样也不差。
下面先介绍一下训练一个pixel-wise的自编码器的损失如下所示:
L ( v ) = ∣ v − D ( v ) ∣ η where { D : R N x ↦ R N x is the autoencoder function. η ∈ { 1 , 2 } is the target norm. v ∈ R N x is a sample of dimension N x \mathcal{L}(v)=|v-D(v)|^{\eta} \text { where } \left\{\begin{array}{l}{D : \mathbb{R}^{N_{x}} \mapsto \mathbb{R}^{N_{x}}} & {\text { is the autoencoder function. }} \\ {\eta \in\{1,2\}} & {\text { is the target norm. }} \\ {v \in \mathbb{R}^{N_{x}}} & {\text { is a sample of dimension } N_{x}}\end{array}\right. L(v)=∣v−D(v)∣η where ⎩⎨⎧D:RNx↦RNxη∈{1,2}v∈RNx is the autoencoder function. is the target norm. is a sample of dimension Nx
- μ 1 、 μ 2 \mu_{1}、\mu_{2} μ1、μ2 :表示自动编码器loss的两个分布,即真实样本损失的分布和生成样本损失的分布
- Γ ( μ 1 , μ 2 ) \Gamma(\mu_{1},\mu_{2}) Γ(μ1,μ2):表示 μ 1 \mu_{1} μ1和 μ 2 \mu_{2} μ2的所有组合的集合
- m 1 、 m 2 m_{1}、m_{2} m1、m2:表示各自的均值
有了上述的的规定后,Wasserstein distance可以定义为:
W 1 ( μ 1 , μ 2 ) = inf γ ∈ Γ ( μ 1 , μ 2 ) E ( x 1 , x 2 ) ∼ γ [ ∣ x 1 − x 2 ∣ ] W_{1}\left(\mu_{1}, \mu_{2}\right)=\inf _{\gamma \in \Gamma\left(\mu_{1}, \mu_{2}\right)} \mathbb{E}_{\left(x_{1}, x_{2}\right) \sim \gamma}\left[\left|x_{1}-x_{2}\right|\right] W1(μ1,μ2)=γ∈Γ(μ1,μ2)infE(x1,x2)∼γ[∣x1−x2∣]
那么它的下界为:
inf E [ ∣ x 1 − x 2 ∣ ] ⩾ inf ∣ E [ x 1 − x 2 ] ∣ = ∣ m 1 − m 2 ∣ \inf \mathbb{E}\left[\left|x_{1}-x_{2}\right|\right] \geqslant \inf \left|\mathbb{E}\left[x_{1}-x_{2}\right]\right|=\left|m_{1}-m_{2}\right| infE[∣x1−x2∣]⩾inf∣E[x1−x2]∣=∣m1−m2∣
BEGAN中 G G G和 D D D对应的损失函数为:
{ L D = L ( x ; θ D ) − L ( G ( z D ; θ G ) ; θ D ) for θ D L G = − L D for θ G \left\{\begin{array}{ll}{\mathcal{L}_{D}=\mathcal{L}\left(x ; \theta_{D}\right)-\mathcal{L}\left(G\left(z_{D} ; \theta_{G}\right) ; \theta_{D}\right)} & {\text { for } \theta_{D}} \\ {\mathcal{L}_{G}=-\mathcal{L}_{D}} & {\text { for } \theta_{G}}\end{array}\right. {LD=L(x;θD)−L(G(zD;θG);θD)LG=−LD for θD for θG
均衡
当 D D D无法判别样本的来源时,真实样本和生成样本错误的分布就应该是一样的,即它们的期望误差应该相等
E [ L ( x ) ] = E [ L ( G ( z ) ) ] \mathbb{E}[\mathcal{L}(x)]=\mathbb{E}[\mathcal{L}(G(z))] E[L(x)]=E[L(G(z))]
为了方便处理,引入超参数 γ \gamma γ来放松限制, γ \gamma γ 的定义如下:
γ = E [ L ( G ( z ) ) ] E [ L ( x ) ] \gamma=\frac{\mathbb{E}[\mathcal{L}(G(z))]}{\mathbb{E}[\mathcal{L}(x)]} γ=E[L(x)]E[L(G(z))]
在EBGAN中,我们希望 D D D既可以对真实图像自动编码,又可以正确的判别输入的样本。 γ \gamma γ 的引入就是平衡这两种要求的,例如当 γ \gamma γ很小时,说明分母部分值很大,那么此时模型专注于识别的正确率,导致 G G G只生成已经可以欺骗 D D D的图像,这时就会出现模式坍缩问题。因此, γ \gamma γ 也可以称为多样性比率(diversity ratio)。
边界均衡思想
BEGAN的目标为:
{ L D = L ( x ) − k t ⋅ L ( G ( z D ) ) for θ D L G = L ( G ( z G ) ) for θ G k t + 1 = k t + λ k ( γ L ( x ) − L ( G ( z G ) ) ) for each training step t \left\{\begin{array}{ll}{\mathcal{L}_{D}=\mathcal{L}(x)-k_{t} \cdot \mathcal{L}\left(G\left(z_{D}\right)\right)} & {\text { for } \theta_{D}} \\ {\mathcal{L}_{G}=\mathcal{L}\left(G\left(z_{G}\right)\right)} & {\text { for } \theta_{G}} \\ {k_{t+1}=k_{t}+\lambda_{k}\left(\gamma \mathcal{L}(x)-\mathcal{L}\left(G\left(z_{G}\right)\right)\right)} & {\text { for each training step } t}\end{array}\right. ⎩⎨⎧LD=L(x)−kt⋅L(G(zD))LG=L(G(zG))kt+1=kt+λk(γL(x)−L(G(zG))) for θD for θG for each training step t
其中 k t k_{t} kt控制在梯度下降过程中对 D D D判别能力的重视程度, λ k \lambda_{k} λk表示学习率。
然后使用Adam优化器独立的更新 G G G和 D D D。
此外,作者还提出了一种新的对于GAN收敛性的测度。在传统的GAN中,只能通过迭代次数或是直观的看生成图像的效果来判断收敛。这里作者提出了一种全局收敛测度方式,同时也是使用了均衡的思想,我们可以构建收敛过程,先找到比例控制算法 ( ∣ γ L ( x ) − L ( G ( z G ) ) ∣ ) (|\gamma\mathcal{L}(x)-\mathcal{L}(G(z_G))|) (∣γL(x)−L(G(zG))∣)的瞬时过程误差,然后找到该误差的最低绝对值的最接近重建 ( L ( x ) ) (\mathcal{L}(x)) (L(x))。该测度可以形式化为两项的和:
M g l o b a l = L ( x ) + ∣ γ L ( x ) − L ( G ( z G ) ) ∣ \mathcal{M}_{g l o b a l}=\mathcal{L}(x)+\left|\gamma \mathcal{L}(x)-\mathcal{L}\left(G\left(z_{G}\right)\right)\right| Mglobal=L(x)+∣γL(x)−L(G(zG))∣
通过 M g l o b a l \mathcal{M}_{g l o b a l} Mglobal的值就可以判断模型是否收敛了。
模型架构
BEGAN 的架构十分简单,几乎所有都是 3×3 卷积,sub-sampling 或者 upsampling,没有 dropout、批量归一化或者随机变分近似,如下所示
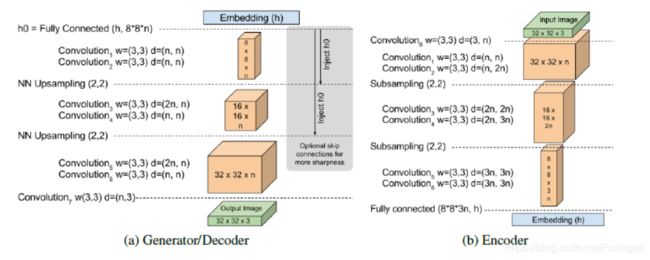
实验
针对于图像的多样性和生成图形的质量所做的实验的结果如下所示,从中可以看出EBGAN的效果远优于BEGAN

当我们改变 γ \gamma γ 的值时,模型生成结果的多样性和质量对比效果如下所示,从中可以看出,值越小,生成的图像越清晰,但是也更接近;值越大,多样性提高了,但是图像的质量同样也下降了

在生成图像的空间连续性方面,BEGAN的效果也要远优于其他的GANs

同时随着模型的逐渐收敛,我们可以看出,生成的图像的质量在不断地提升
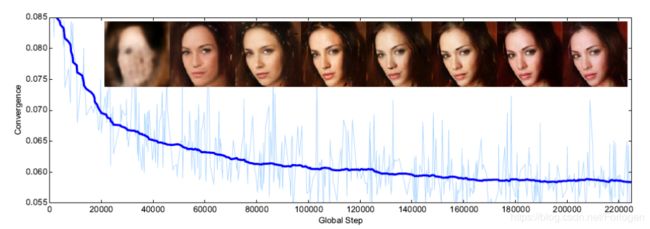
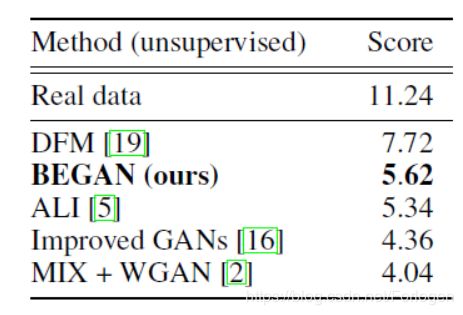
最后在数值实验中也显示了BEGAN的inception score更小
因此我们可以看出,BEGAN针对 GAN 训练难、控制生成样本多样性难、平衡鉴别器和生成器收敛难等问题,做出了很大的改善。
参考
http://www.dataguru.cn/article-11048-1.html
https://blog.csdn.net/linmingan/article/details/79912988
https://blog.csdn.net/qq_25737169/article/details/77575617
https://www.cnblogs.com/shouhuxianjian/p/10405147.html
https://blog.csdn.net/m0_37561765/article/details/77512692
https://blog.csdn.net/StreamRock/article/details/81023212