验证码识别多账号微博自动模拟登录
多账号微博自动模拟登录cookie写入数据库
- 多账号自动登录
- 注意点
- 文件目录
- 简单的运行
- 实现
- selelogin登录模块
- login登录脚本
- 思考
代码已经存放于github点击前往
多账号自动登录
由于需要方便登录weibo.com拿到多账号的cookie,由nghuyong/
WeiboSpider项目的登录部分获得启发,写了登录脚本。本脚本能够:自动登录多个账号获得cookie写入mongodb,自动识别验证码,设置计划任务便能自动维护cookie池。
注意点
这是我第一次写博客,如果写的不好请见谅。主要是搜集网上资料时发现相关资料较少,大多代码陈旧且无法运行,并且大多从cn端进入而最新的更新则加大了难度。
- 学习目的 ,本篇博客旨在互相交流学习,请不要用于非正常用途;
- 因为脚本中间遇到了屏幕截取,我已经设置了固定的分辨率,但是在不同的电脑上貌似验证码的截取还会错位,这个可以自行修改截取位置参数;
文件目录

| 文件 | 作用 |
|---|---|
| account.txt | 账号池记录 |
| login | 读取、运行、写入cookie |
| selelogin | 登录脚本 |
简单的运行
1.打开account输入如下格式账号密码
[email protected]
18cohucas92----xijoun
13iugiagsuigcsia5----mscahoih
2.运行login
3.完成登录
查看数据库
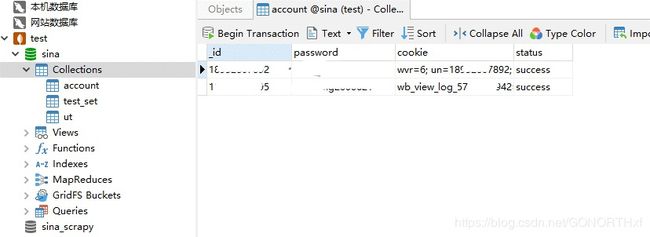
实现
selelogin登录模块
使用前请import本模块并传入必要参数,chromedriver和图像识别需要的appcode(可在此申请)
aliyun有免费次数但是数据接口不同,将请求头改为如下形式调用免费接口
headers = {'Authorization':'APPCODE ' + self.appcode,"Content-Type":"application/x-www-form-urlencoded; charset=utf-8"}
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
from selenium.webdriver.support import expected_conditions as EC
import time,requests,base64,json
from PIL import Image
from json.decoder import JSONDecodeError
class WeiboLogin():
def __init__(self,weibo_username,weibo_password,ali_appcode,chrome_driver_path):
## super().__init__()(self):
'''
weibo_username,weibo_password,ali_appcode,chrome_driver_path
微博用户名,密码,识别应用号,chrome_driver路径
识别号申请地址:https://www.3023data.com/ocr/captcha/
'''
# 配置chrome驱动
self.chrome_driver = chrome_driver_path
self.driver = webdriver.Chrome(executable_path=self.chrome_driver)
self.driver.implicitly_wait(5)
self.verificationErrors = []
self.accept_next_alert = True
##微博用户名密码
self.username = weibo_username
self.password = weibo_password
##阿里云识别号
# 识别号申请地址:https://market.aliyun.com/products/57124001/cmapi027426.html?spm=5176.2020520132.101.2.75ef7218vDrZVw#sku=yuncode2142600000
self.appcode = ali_appcode
##百度云识别AIP
# 识别率较低弃用
# self.APP_ID = '***'
# self.API_KEY = '***'
# self.SECRET_KEY = '***'
def login(self):
'''
登录
'''
driver = self.driver
wait=WebDriverWait(driver,30)
driver.set_window_size(1489,880)
driver.get("https://www.weibo.com/")
time.sleep(2)
if 'home' in driver.current_url:
print('该账号已经登录成功')
cookies = driver.get_cookies()
print('-------------------------------------------------success-------------------------------------------------')
## 存到cookies中
cookie = [item["name"] + "=" + item["value"] for item in cookies]
cookie_str = '; '.join(item for item in cookie)
driver.quit()
return cookie_str
wait.until(EC.presence_of_element_located((By.XPATH,"//*[@id='loginname']")))
time.sleep(0.5)
## 输入用户名密码
print('正在输入输入用户名密码')
driver.find_element_by_xpath(u"//*[@id='loginname']").click()
driver.find_element_by_xpath("//*[@id='loginname']").clear()
driver.find_element_by_xpath("//*[@id='loginname']").send_keys(self.username)
driver.find_element_by_xpath(u"//*[@id='pl_login_form']/div/div[3]/div[2]/div/input").click()
driver.find_element_by_xpath("//*[@id='pl_login_form']/div/div[3]/div[2]/div/input").clear()
driver.find_element_by_xpath("//*[@id='pl_login_form']/div/div[3]/div[2]/div/input").send_keys(self.password)
driver.find_element_by_xpath(u"//*[@id='pl_login_form']/div/div[3]/div[6]/a").click()
time.sleep(1.5)
## 验证码识别阶段
while 'home' not in driver.current_url:
print('检测到有验证码,正在调用人工智能识别')
# 截取图像
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#pl_login_form > div > div:nth-child(3) > div.info_list.verify.clearfix > a > img')))
driver.save_screenshot('printscreen.png')
# 定位截取验证码
imgelement = driver.find_element_by_css_selector('#pl_login_form > div > div:nth-child(3) > div.info_list.verify.clearfix > a > img')
location = imgelement.location
size = imgelement.size
rangle = (int(location['x']), int(location['y']), int(location['x'] + size['width']),int(location['y'] + size['height']))
i = Image.open("printscreen.png") # 打开截图
frame4 = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域
frame4=frame4.convert('RGB')
frame4.save('save.jpg')
# 储存验证码图像
with open('save.jpg','rb') as f:
imgbytes = f.read()
## 调用阿里云API
# 转换base64编码
imgbase64 = base64.b64encode(imgbytes)
# 上传
url = 'http://api.3023data.com/ocr/captcha'
headers = {'key':self.appcode}
content = {
'image':imgbase64,
'length':'5',
'type':'1001'
}
rep = requests.post(url, data=content,headers=headers)
# 返回checkcode
try:
checkcode = str(json.loads(rep.content).get('data').get('captcha'))
except JSONDecodeError:
print('请检查余额是否充足或CODE是否正确')
checkcode = str('401')
# 填入checkcode
driver.find_element_by_name("verifycode").send_keys(checkcode)
## 登录
driver.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[3]/div[6]/a').click()
time.sleep(4)
## 登陆成功后拿到cookies
cookies = driver.get_cookies()
print('-------------------------------------------------success-------------------------------------------------')
## 存到cookies中
cookie = [item["name"] + "=" + item["value"] for item in cookies]
cookie_str = '; '.join(item for item in cookie)
driver.quit()
return cookie_str
def login(weibo_username,weibo_password,ali_appcode='***输入你的appcode',chrome_driver_path=r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'):
print('正在调用一键登录功能,祝您登录愉快!from go north')
return WeiboLogin(weibo_username,weibo_password,ali_appcode,chrome_driver_path).login()
login登录脚本
注意前更改数据库地址和认证信息
import pymongo
from pymongo.errors import DuplicateKeyError
from selelogin import login
LOCAL_MONGO_HOST = '192.168.160.166'
LOCAL_MONGO_PORT = 27017
DB_NAME = 'sina'
if __name__ == '__main__':
# 在目录中新建一个account.txt文件,输入账号和密码
file_path = 'account.txt'
with open(file_path, 'r') as f:
lines = f.readlines()
mongo_client = pymongo.MongoClient(LOCAL_MONGO_HOST, LOCAL_MONGO_PORT)
mongo_client[DB_NAME].authenticate('root','123456')
collection = mongo_client[DB_NAME]["account"]
for line in lines:
line = line.strip()
username = line.split('----')[0]
password = line.split('----')[1]
print('=' * 10 + username + '=' * 10)
try:
cookie_str = login(username, password)
except Exception as e:
print(e)
continue
print('获取cookie成功')
print('Cookie:', cookie_str)
try:
collection.insert_one(
{"_id": username, "password": password, "cookie": cookie_str, "status": "success"})
except DuplicateKeyError as e:
collection.find_one_and_update({'_id': username}, {'$set': {'cookie': cookie_str, "status": "success"}})
思考
1.效率较低
2.屏幕裁取参数较难配置
3.成本问题
某警校学生,正在努力学习各种技术栈,欢迎留言。