Content-Based Information Retrieval 基于内容的信息检索
Content-Based Information Retrieval
Information Era- The Internet and the WWW
- Milestones of the Information Era
- Keyword / Text - based Search
- Content-based Search
Information Era
The second half of the 20th century and the beginning of the third millenium can be described as the information era of the mankind's development because of the enormous impact of information on the human lifestyle and way of thinking. Permanent and intensive exposure to information broaden people's views and deepen knowledge and awareness about the environment and the world in general. This process globalises society and creates new living and educational standards (Hanjalic e.a., 2000).
The information era is a consequence of digital revolution, which started in the nineteen forties - fifties and has continuously built up. Representation of information in the digital form allows for a lossless data compression or lossy compression with a low quality loss, which in turn results in a large reduction of the time and channel capacity for data transmission and of the space required for data storage. Possibilities to combine and transmit or process different types of information such as audio, visual or textual data without quality loss and permanently increasing performance-to-price ratio of digital transmission, storage, and processing resulted in the advent and continuous advance of multimediasystems and applications. Today's digital telecommunication networks such as the Internet provide extremely high-speed information transfer, called frequently "information superhighway".
In a broad sense, multimedia is a general framework for interaction with information avaliable from different sources, and the more that is known about the content means the better can be its representation, processing, analysis, and so forth, in terms of efficiency and allowed functionalities (Rao e. a., 2002). Digital imagery is the most important part of multimedia data types. If video and audio data are in the predominant use of entertainment and news applications, images are actively exploited in almost all human activities (Castelli & Bergman, 2002). Large collections of images are maintained in many application domains, for example, medical, astronomical, geologic image databases, digital libraries and museums accessible via the Internet, collections of space and aerial remetely sensed images of the Earth's surface, and so on. Although digital imagery have been used, starting from the nineteen sixties - seventies, the Internet and the World Wide Web browsers brought a new world, the virtual cyberspace, that stimulates the era of information explosion (Shih, 2002).
The Internet and the WWW
The terms Internet and the World Wide Web are not synonymous although describe two related things. The Internet is a massive networking infrastructure linking millons of computers together globally. In this network any computer can communicate with any other computer as long as they are both connected to the Internet. More than 100 countries are linked into exchanges of data, news and opinions. Unlike online services, which are centrally controlled, the Internet is decentralised by design. Each Internet computer, called a host, is independent. Its operator chooses which Internet services to use and which local services to make available to other computers. "Remarkably, this anarchy by design works exceedingly well" (Webopedia, 2002).
Information travels over the Internet via a variety of languages known as protocols. A protocol consists of a set of conventions or rules, which govern communications by allowing networks to interconnect and ensuring compatibility between devices of different manufacturers. Examples of the protocols are:
| TCP | Transmission Control Protocol | converts messages into streams of packets at the source and then reassembles them back into messages at the destination |
| IP | Internet Protocol | handles addressing and routing of packets across multiple nodes and even multiple networks with multiple standards |
| TCP/IP | combined TCP and IP | |
| FTP | File Transfer Protocol | transfers files from one computer to another; based on TCP/IP protocol |
| HTTP | Hypertext Transfer Protocol | transfers compound documents with links; based on TCP/IP protocol |
| IPP | Internet Printing Protocol | |
| IIP | Internet Imaging Protocol | transports high-quality images and metadata across the Internet, using the Flashpix format; integrated with TCP/IP and HTTP |
| SMTP | Simple Mail Transfer Protocol | |
The protocols deal with Internet media types, which identify type/subtype and encoding of transmitted data. The media types are used by Multipurpose Internet Mail Extensions (MIME) and others. Basic standard media types registered with Internet Assigned Numbers Authority (IANA) are text, application (e.g. document), audio, image, and video (Buckley & Beretta, 2000).
The World Wide Web, or simply Web, is a way of accessing information over the medium of the Internet. It is an information-sharing model built on the top of the Internet. The Web is based on three specifications: URL (Uniform Resource Locator) to locate information, HTML (Hypertext Markup Language) to write simple documents, and HTTP. The Web uses the HTTP protocol, only one of the languages spoken over the Internet, to transmit data. Web services, which use the HTTP to allow applications to communicate, use the Web to share information. The Web utilises browsers to access Web documents (called Web pages) that are linked to each other via hyperlinks. Web documents also contain text, graphics, sounds, and video.

The Web is just one of the ways that information can be disseminated over the Internet. The Internet, not the Web, is also used for e-mail, which relies on the SMTP, instant messaging, Usenet news groups, and FTP. Thus the Web is only a large portion of the Internet as well as the Web is the basic way to publish and access information on networks within companies (Intranet). Although it is nominally based on the HTML standard, a steady stream of innovations in the domains of multimedia and interactivity has greatly expanded Web capabilities (Blumberg & Hughes, 1997).
In addition to Internet standards, Multimedia communication is governed by own standards that provide a compromise between what is theoretically possible and what is stechnically feasible as well as guarantee well balanced cost / performance ratio (Rao e. a.):
| MPEG-1 | ISO/IEC IS 11172 | Coding of moving pictures and associated audio |
multimedia CD-ROM applications at a bit rate up to about 1.5 Mb/s; the standard format for distribution of video material across the Web |
| MPEG-2 | ISO/IEC IS 13818 | Generic coding of moving pictures and associated audio |
high-quality coding for all digital multi-media transmissions at data rates of 2 to 50 Mb/s; digital TV and HDTV in home entertainment, business, and scientific aplications) |
| MPEG-4 | ISO/IEC IS 14496 | Coding of audiovisual objects | coding and flexible representation of both natural and synthetic, real time and non-real time audio and video data; digital TV, interactive graphics applications, interactive multimedia (distribution of and access to content on the Web) |
| MPEG-4 VTC | ISO/IEC IS 14496-2 Pt.2 Visual |
Visual Texture Coding | the MPEG-4 algorithm for compressing the texture information in photo-realistic 3D models; it can be used for compression still images |
| JPEG2000 | Still-image compression for multimedia communication |
an emerging standard intended to provide rate distortion and subject image quality performance superior to existing standards |
|
| MPEG-7 | ISO/IEC IS 15938 | Multimedia Content Description Interface |
to describe multimedia content so that users can search, browse, and retrieve the content more efficiently and effectively than with existing mainly text-based search engines |
| MPEG21 | ISO/IEC IS 18034 | Multimedia framework | to enable transparent and augmented use of mulimedia resources across a wide range of networks and devices |
Milestones of the Information Era
For last two decades, an average information consumer permanently was raising his expectations regarding the amount, variety and technical quality of the received multimedia information, as well as of the systems for information receiving, processing, storage, and replay or display. The Internet and the Web created a virtual world linking us together, having unique multimedia capabilities, and yielding a new concept of E-Utopia. The new concept realises new activities such as e-conferencing, e-entertainment, e-commerce, e-learning, telemedicine, and so forth. All these activities involve distributed multimedia databases and techniques for multimedia communication and content-based information search and retrieval (Hanjalic e.a., 2000; Rao e.a., 2002; Shih, 2002).
The advent of virtual reality environments (e.g., Apple Computer's Quick Time VR) and the virtual reality markup language (VRML) for rendering 3D objects and scenes added much to the Web unique multimedia capabilities. But the Web continues to grow as both an interactive and a publishing environment and offers new types of interactions and ways to distribute, utilise, and visualise information. Some experts anticipate that today's interaction with a database via the Web will necessarily evolve to become the interaction with a variety of knowledge bases and will result in the more intelligent Web.
In addition to the present e-activities over the Web, one can expect the advent of smart houses, which can communicate with owners, repair services, shops, police, and others over the Web in order to suggest appropriate decisions using current measurements together with specific knowledge bases. For instance, an appliance may connect through the Web to a central facility and inform the vendor about the status of all of its subsystems for deriving the most cost-effective time schedule for service and routing of service.
In near future most of households are expected to be equipped with receivers for Digital Video Broadcasting (DVB) and Audio Broadcasting (DAB), providing together hundreds of high-quality audiovisual channels, combined with a high-speed Internet connection to access countless archives of invormation all over the world. Today we witness a fast development of home digital multimedia archives and digital libraries for a large-scale collection of multimedia information, e.g. digital museum archives or professional digital multimedia archives at service providers such as TV and radio broadcasters, Internet providers, etc. Digital medical images are widely used in telemedicine based on the Web, mainly, for continuing medical education and diagnostic purposes (Della Mea e.a., 2001).
At present, more than a hundred million digital images and videos are already embedded in Web pages, and these collections are rapidly expanding because "a picture is worth a thousand words". Gigabytes of new images, audio and video clips are stored everyday in various repositories accessed through the Web (Shih, 2002). In some cases, such as space and aerial imagery of the Earth's surface, amounts of the stored data exceed thousands of Terabytes. Thus, among other new challenges of the information era, mechanisms for content-based information retrieval, especially, for efficient retrieval of image and video information stored in the Web-based multimedia databases, become the most important and difficult issue.
Multimedia Information Retrieval
| "Anyone who has surfed the Web has explained at one point or another that there is so much information available, so much to search and so much to keep up with". (Smeulders & Jain, 1997) |
Multimedia information differs from conventional text or numerical data in that multimedia objects require a large amount of memory and special processing operations. A multimedia database management system should be able to handle various data types (image, video, audio, text) and a large number of such objects, provide a high-performance and cost-effective storage of the objects, and support such functions as insert, delete, update, and search (Shih, 2002). A typical multimedia document or presentation contains a number of objects of different types, such as picture, music, and text. Thus content-based multimedia information retrieval has become a very important new research issue. Unlike a traditional searching scheme based on text and numerical data comparison, it is hard to model the searching and matching criteria of multimedia information.
Image and video retrieval is based on how contents of an image or a chain of images can be represented. Conventional techniques of text data retrieval can be applied only if every image and video record is accompanied with a textual content description (image metadata). But image or video content is much more versatile compared to text, and in the most cases the query topics are not reflected in the textual metadata available. Images, by their very nature, contain "non-textual", unstructured information, which hardly can be captured automatically. Computational techniques that pursue the goals of indexing the unstructured visual information are called content-based video information retrieval (CBVIR), or more frequently content-based image retrieval (CBIR). Thus both the content-based video information retrieval and the general-purpose content-based information retrieval share the same abbreviation (CBIR).
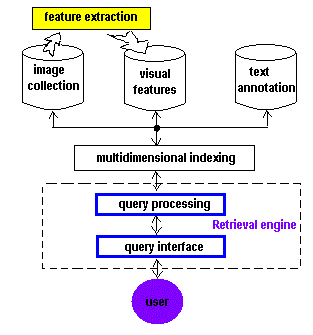
Architecture of a CBIR system
In CBIR, the user should describe the desired content in terms of visual features, images should be ranked with respect to similarity to the description, and the top-rank (or most similar) images should be retrieved. At the lowest, or initial level of description, an image is considered as a collection of pixels. Although a pixel-level content might be of interest for some specific applications (say, in remote sensing of the Earth's surface), today's CBIR is based on more elaborated descriptors showing specific local and global photometric and geometric features of visual objects and semantic relationships between the features.
Features can be divided into general-purpose and domain-specific. In the most cases general features are colour, texture, geometric shape, sketch, and spatial relationships. Domain-specific features are used in special applications such as surveying and mapping of the Earth's surface using remotely sensed imagery or biometrics based on human face or fingerprint recognition. But extraction of adequate descriptors and especially inference of semantic content are extremely difficult problems having no universal solution. Higher levels of image content description involve objects and abstract relationships. Such a description is more or less easily formed by human vision, but it is often difficult to detect and recognise objects of interest in one or more images (Castelli & Bergman, 2002).
The most difficult issue of multimedia information retrieval is how to make a query describing the needs of the user. For example, it is a hard task to conduct a query like "Find me a picture with a house and a car" and it is even harder to match a specification against the large amount of picture files in a multimedia database. Generally, human and automated content-based information retrieval differ much. Human retrieval tasks (queries) are stated at cognitive level and exploit human knowledge, analysis, and understanding of the information context in terms of objects, persons, sceneries, meaning of speech fragments or the context of a story in general. Therefore, the queries by content can be formulated in different ways, e.g.
- "Find the most recent image of Australian Prime Minister John Howard"
- "Find all images of an American bald eagle"
- "Find the movie scene where Titanic hits the iceberg"
- "Classify all the images according to the place where they are taken"
- "Select recent aerial images of Rangitoto"
- "Find images depicting similar tornadoes in Alabama"
- "Select most impressive sunset images" and so on.
The notion of content is hardly formalised at present. Among a host of possible definitions, content is defined on the Web as:
- meaning or message contained and communicated by a work of art, including its emotional, intellectual, symbolic, thematic, and narrative connotations (see www.ackland.org/tours/classes/glossary.html)
- the subject matter of a work of art and its values apart from the artist's ability; form and content are the two elements that comprise a work (see www.worldimages.com/art_glossary.php)
- that which conveys information, eg text, data, symbols, numerals, images, sound and vision (see www.naa.gov.au/recordkeeping/er/guidelines/14-glossary.html)
- the "meat" of a document, as opposed to its format, or appearance (see www.microsoft.com/technet/prodtechnol/visio/visio2002/plan/glossary.mspx)
- media to communicate information or knowledge in information retrieval (see www.cordis.lu/ist/ka1/administrations/publications/glossary.htm)
Current computer vision does not allow to easily and automatically extract semantic information. An ultimate image encoding should capture an image semantic content in a way that corresponds to human interpretation. But the initially sensed image encoding consists of the raw pixel values - grey values or colours. Image analysis addresses a spectrum of intermediate possibilities between these two extremes but mostly focusses on low-level features being functions of the pixel values (Cox e.a.,2000). Although some features like colour relate to image semantics in some cases, but typically do not reflect true meaning of the image, and a much higher level of image description is necessary to effectively and practically represent the content.
So far the content is described in terms of general-purpose and domain-specific quantitative features. The general-purpose features include colour, texture, geometric shape, sketch, and spatial relationships of regions in an image or a video sequence. The domain-specific features appear in some special applications e.g. face detection and recognition or remote sensing of the Earth. Description of semantics (meaning) is a very hard problem with no universal solution because typically each meaningful description (interpretation) of video data easily formed by human vision turns to be extremely difficult for computation and vice versa.
Let us look, for instance, to a small database of natural images below:
 |
 |
 |
 |
 |
 |
 |
 |
 |
These 3D scenes contain various objects such as horses, foals, cows, grass fields, bushes, water, hills, and many others, and their content is manifold because the interpretation of scenes, objects, and relations between objects in each such image depend on an observer, time, goal, and other subjective and objective factors...
The most difficult problem is how to describe what content the user needs and has in mind when makes a query. The simplest but still difficult example is to explicitly outline semantic elements to be searched for: "Find a picture with a brown foal near a bush". Even a harder task is to match such or more general specification against the large multimedia database. Human queries for a data search are always on a cognitive level exploiting human knowledge of the context in terms of objects, persons, sceneries, scenarios, etc. These queries may be formulated in different ways using natural language(s) and visual examples. But a query to a CBIR system has to account for much more constrained abilities of automatic data description and search.
The content-based video information retrieval has first to cope with a "sensory gap" (Smeulders e.a., 2000) caused by distinctions between the properties of an object in the world and the properties of its computational description derived from an image or a series of images. The sensory gap makes the content description problem ill-posed and notably limits capabilities of formal representation of the image content. Secondly, there is a semantic gap, or "a discrepancy between the query a user ideally would and one which the user actually could submit to an information retrieval system" (Castelli & Bergman, 2002). Semantics ("significant" in Greek) describes relationships between words and their meanings in linguistics and between signs and what they mean in logic. In relation to images, semantics is concerned with meaning of depicted objects and their features.
The semantic gap results in considerable distinctions between a description extracted from visual data and human interpretation of the same data in each particular case. The main restriction of the content-based retrieval is that the user searches for semantic, i.e. meaningful similarity, whereas the CBIR system provides only similarity of quantitative features obtained with data processing. Semantic relationships encode human interpretations of images which are relevant to each particular application, but these interpretations constitute only a small subset of all the possible meaningful interpretations. This is why automatic description of a "true" image contents is an unsolvable problem due to an intrinsically subjective human perception of images and video sequences.
Contents is so far described with digital signatures combining recognised objects, shapes, features, and relationships, and images are ranked by their quantitative similarity to a query description in terms of these objects, shapes, features, and their relationships. The top-rank, i.e. most similar images are retrieved and output. Informally, content of a still image includes, in increasing level of complexity, perceptual, oralgorithmic properties of visual information, semantic properties, e.g. abstract primitives such as objects, roles, and scenes, and subjectiveattributes such as impressions, emotions and meaning associated to the perceptual properties (Shih, 2002). Content-based retrieval of video records involves not only the objects shown but also the timing and spatial patterns of object movements.
But tools for content description by computational image / video understanding, object tracing, and semantic analysis are still and will be for a very long future time under development. First of all, the content of an image is a very subjective notion, and there are no "objective" ways to annotate the content at a semantic level to reflect all or even most of subjective interpretations of this image. Secondly, the gaps between "formal" and "human" (user) semantics should be bridged from both sides, by extending the image descriptions and adapting the user queries to how a CBIR system operates.
As mentioned by Cox e.a., 2000, to codify image semantics one needs a language to express them. Because it has to be used for human queries and human interpretation of a database image's description, the language must be natural for expressing search goals and give accurate and consistent description of each database image. Thus, it is very difficult to design such a consistent formal language. Today's CBIR systems exploit a more practical way of using hidden languages for semantic encoding and probabilistic learning and classification frameworks for linking image features and semantic classes. In particular, specific random field models of features and their spatial distributions are involved to account for wide variations of features within the same �semantic� class, and "semantic" representations of an image are built with modern feature clustering and classification techniques such as Support Vector Machines (SVM) or Bayesian networks. The resulting feature-based labelling of blocks (regions) of an image is used for interpreting its semantic content.
The users of a CBIR system have a diversity of goals, in particular, search by association, search for a specific image, or category search(Smeulders e.a., 2000). Search by association has first no partricular aim and implies highly interactive iterative refinement of the search using sketches or example images. Search for a precise copy of the image in mind (e.g., in an art catalogue) or for another image of the same object assumes that the targer can be interactively specified as similar to a group of given examples. Category search retrieves an arbitrary image representative of a certain class either specified also by an example or derived from labels or other database information.
At present, the only feasible analysis of a video, or an image, or a musical piece, or a speech fragment, or a text can be performed only atalgorithmic level. Such analyses involve computable features of audio and video signals, e.g. colour, texture, shape, frequency components, temporal characteristics of signals, as well as algorithms operating on these features.
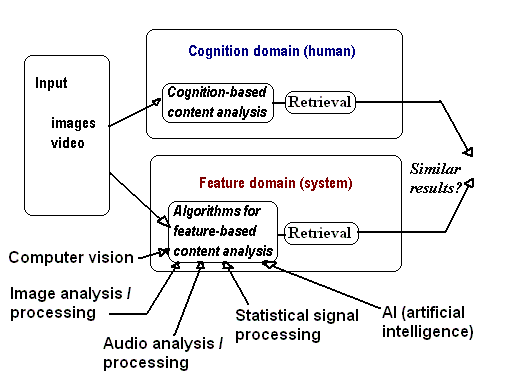
In image and video retrieval, various algorithms of image segmentation into homogeneous regions, detection of moving objects in successive frames, extraction of particular (e.g., spatially invariant) types of textures and geometric shapes, determination of relations among different objects, and analysis of 2D frequency spectrum are used for getting features. But in contrast to most of computer vision applications, image and video retrieval combines automatic image recognition with active user participation in the retrieval process (Castelli & Bergman, 2002). Also, retrieval relates inherently to image ranking by similarity to a query example, rather than to image classification by matching to a model. In CBIR systems the user evaluates system responses, refines the query, and determines whether the receieved answers are relevant to that query.
Of course, there is almost no parallelism in results of the cognition-based and feature-based retrieval even in the simple tasks like "an image containing a bird". As underlined in Chang e.a., "the multimedia information is highly distributed, minimally indexed, and lacks appropriate schemas. The critical question in multimedia search is how to design a scalable, visual information retrieval system? Such audio and visual information systems require large resources for transmission, storage and processing, factors which make indexing, retrieving, and managing visual information an immense challenge".
Keyword / Text - based Search
An image can hardly be described by text annotations or keywords, although these latter are to some extent associated with semantics. In principle, by extensive investigation of an image database one may obtain a set of specific keywords covering a broad range of semantic attributes ( Cox e.a., 2000 ). The set implies an additional set of keywords defining general categories , e.g. the specific attribute "horse" yields the category attribute "animal" to be present.At present, most popular multimedia search engines, including all first generation visual information, or image retrieval (IR) systems, are still textual, even though the Web is now a multimedia-based repository with a variety of audio, video, image, and text formats. Some popular formats for different media types are as follows (Chang e.a., 2001):
| Media type | Media format | File extension |
|---|---|---|
| text | plain | txt |
| HTML | html, htm | |
| document | PDF Portable Document Format | |
| TEX DVI Device Independent Data | dvi | |
| Postscript | ai, eps, ps, | |
| image | PNG (Portable Network Graphics) image | png |
| Windows Bitmap | bmp | |
| X Bitmap | xbm | |
| TIFF (Tag Image File Format) image | tif | |
| JPEG (Joint Photographic Experts Group) image | jpg | |
| GIF (Graphics Interchange Format) image | gif | |
| audio | Midi | midi |
| MP3 | mp3 | |
| RealAudio | ra, ram | |
| WAV Audio | wav | |
| video | MPEG (Moving Picture Experts Group) Video | mpeg, mpg, mpe, mpv, mpegv |
| QuickTime | qt, mov, moov | |
| RealMedia | ra, ram | |
| MPEG Audio | mp2, mpa, abs, mpega | |
| AVI | avi |
In the case of text or keyword - based search, users specify keywords, and multimedia relevant to these keywords should be retrieved. Such retrieval relies strongly on metadata represented by text strings, keywords, or full scripts (Shih, 2002). Several recently developed and deployed efficient commercial multimedia search engines, such as Google Image Search, AltaVista Photo Finder, Lycos Pictures and Sounds, Yahoo! Image Surfer, and Lycos Fast MP3 Search, exploit text or keyword-based retrieval. It requires an inverted file index that describes the multimedia content and allows for obtaining fast query response. Building an index is the core part of the keyword-based multimedia information search.
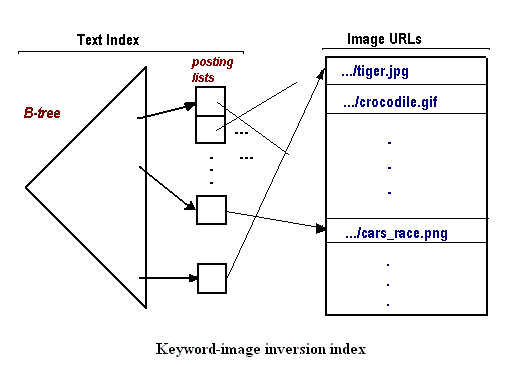
Another indexing techniques are partitioning multimedia content into categories, which the user can browse through for images of interest that match category keywords and using the text embedded around multimedia content as a way to identify its content. But the keywords and texts relate only implicitly to image / video / audio content, and be it possible to examine directly such a content, the search results could be notably refined.
Content - based Search
In content or semantics-based search, retrieval criteria and queries are specified in terms of computable data features related to semantic content of a multimedia object (audio, image, or video). Most content-based video information retrieval (CBIR) systems allow for searching the visual database contents in several different ways, either alone or combined ( Chang e.a., 2001 ; Shih, 2002 , Smeulders e.a., 2000 ): .- General interactive browsing by a user with no specific idea about the desired images or video clips.
- category (subject) search to retrieve an arbitrary image that represents a specific class (in this case clustering of visually similar images into groups can reduce the number of retrieved undesired images and navigation through a subject hierarchy allows to get to the target subject and then browse or search only that limited subset of images);
- search by association having no specific aim and iteratively refined on the basis of the user's relevance feedback.
- Search to illustrate a story or document or for arbitrary pictures of expected aesthetical value.
- Search for a specific image, or Query-by-X where "X" can be:
- an image example or a group of examples (Query-by-Example, or QBE) specified by a user virtually anywhere in the Internet; the images that are most similar to the query image(s) are presented in descending order of the similarity score;
- a visual sketch of the desired image or video clip drawn by a user with graphics tools provided by the system;
- direct specification of visual features (e.g., colour, texture, shape, and motion properties), which appeals to more technical users; or
- a keyword or complete text entered by the user to search for visual information that has been previously annotated with that set of keywords.