- 1 进程描述符struct task_struct
- 1.1 进程状态
- 1.1.1 5个互斥状态
- 1.1.2 2个终止状态
- 1.1.3 睡眠状态
- 1.1.3.1 内核将进程置为睡眠状态的方法
- 1.1.4 状态切换
- 1.2 进程标识符(PID)
- 1.3 进程内核栈与thread_info结构
- 1.3.1 为什么需要内核栈
- 1.3.2 为什么需要thread_info
- 1.3.3 内核栈和线程描述符
- 1.3.4 内核栈数据结构描述thread_info和thread_union
- 1.3.5 获取当前在CPU上正在运行进程的thread_info
- 1.3.6 分配和销毁thread_info
- 1.4 进程标记
- 1.5 表示进程亲属关系的成员
- 1.6 ptrace系统调用
- 1.7 Performance Event
- 1.8 进程调度
- 1.8.1 优先级
- 1.8.2 调度策略相关字段
- 1.9 进程地址空间
- 1.10 判断标志
- 1.11 时间
- 1.12 信号处理
- 1.13 其他
- 1.1 进程状态
- 2 命名空间
- 2.1 Linux内核命名空间描述
- 2.2 命名空间的创建
- 2.3 PID Namespace
- 3 进程ID类型
- 4 PID命名空间
- 4.1 pid命名空间概述
- 4.2 局部ID和全局ID
- 4.2.1 全局ID
- 4.2.2 局部ID
- 4.3 PID命名空间数据结构pid_namespace
- 5 pid结构描述
- 5.1 pid与upid
- 5.1.1 特定命名空间信息struct upid
- 5.1.2 局部ID类struct pid
- 5.2 用于分配pid的位图struct pidmap
- 5.3 pid的哈希表存储结构struct pid_link
- 5.4 task_struct中的进程ID相关描述符信息
- 5.5 进程ID管理函数
- 5.5.1 进程pid号找到struct pid实体
- 5.5.2 获取局部ID
- 5.5.3 根据PID查找进程task_struct
- 5.5.4 生成唯一的PID
- 5.1 pid与upid
- 6 Liux进程类别
- 6.1 内核线程
- 7 linux进程的创建流程
- 7.1 进程的复制fork和加载execve
- 7.2 写时复制技术
- 7.3 内核线程创建接口
- 7.3.1 kernel_thread
- 7.3.2 kthread_create
- 7.3.3 kthread_run
- 7.4 内核线程的退出接口
- 8 Linux中3个特殊的进程
- 8.1 0号idle进程
- 8.1.1 0号进程上下文信息--init_task描述符
- 8.1.2 进程堆栈init_thread_union
- 8.1.3 进程内存空间
- 8.1.4 0号进程的演化
- 8.1.4.1 rest_init创建init进程(PID=1)和kthread进程(PID=2)
- 8.1.4.1.1 创建kernel_init
- 8.1.4.1.2 创建kthreadd
- 8.1.4.2 0号进程演变为idle
- 8.1.4.1 rest_init创建init进程(PID=1)和kthread进程(PID=2)
- 8.1.5 idle的运行与调度
- 8.1.5.1 idle的workload--cpu_idle_loop
- 8.1.5.2 idle的运行时机
- 8.2 1号init进程
- 8.2.1 执行函数kernel_init()
- 8.2.2 关于init程序
- 8.3 2号kthreadd进程
- 8.3.1 执行函数kthreadd()
- 8.3.1.1 create_kthread(struct kthread_create_info)完成内核线程创建
- 8.3.2 新创建的内核线程执行函数kthread()
- 8.3.3 小结
- 8.3.1 执行函数kthreadd()
- 8.1 0号idle进程
- 9 用户空间创建进程/线程的三种方法
- 9.1 系统调用的参数传递
- 9.2 sys_fork的实现
- 9.3 sys_vfork的实现
- 9.4 sys_clone的实现
- 10 创建子进程流程
- 10.1 _do_fork的流程
- 10.2 copy_process流程
- 10.2.1 dup_task_struct()产生新的task_struct
- 10.2.2 sched_fork()流程
- 10.2.3 copy_thread和copy_thread_tls流程
- 11 用户程序结束进程
- 12 进程状态变化过程
- 13 内核线程
- 13.1 概述
- 13.2 内核线程的创建
- 13.2.1 创建内核线程接口
- 13.2.2 2号进程kthreadd
- 13.2.3 kernel_thread()创建内核线程
- 14 可执行程序的加载和运行
- 14.1 exec()函数族
- 14.2 可执行程序相关数据结构
- 14.2.1 struct linux_binprm结构描述一个可执行程序的信息
- 14.2.2 struct linux_binfmt可执行格式的结构
- 14.3 execve加载可执行程序的过程
- 14.4 execve的入口函数sys_execve
- 14.5 do_execve函数
- 14.6 exec_binprm()识别并加载二进程程序
- 14.7 search_binary_handler()识别二进程程序
- 15 对象文件格式
- 15.1 对象文件
- 15.1.1 可重定位的对象文件(Relocatable file)
- 15.1.2 可执行的对象文件(Executable file)
- 15.1.3 可被共享的对象文件(Shared object file)
- 15.2 文件格式
- 15.3 ELF对象文件格式
- 15.4 示例
- 15.4.1 add.c
- 15.4.2 sub.c
- 15.4.3 testelf.c
- 15.4.4 Makefile
- 15.1 对象文件
- 16 ELF可执行与链接文件格式详解
- 16.1 布局和结构
- 16.1.1 链接视图
- 16.1.2 执行视图
- 16.2 ELF基本数据类型定义
- 16.3 ELF头部elfxx_hdr
- 16.3.1 ELF魔数e_ident
- 16.3.2 目标文件类型e_type
- 16.3.3 目标体系结构类型e_machine
- 16.3.4 ELF版本e_version
- 16.3.5 readelf -h查看elf头部
- 16.3.5.1 可重定位的对象文件(Relocatable file)
- 16.3.5.2 可执行的对象文件(Executable file)
- 16.3.5.3 可被共享的对象文件(Shared object file)
- 16.4 程序头部elf32_phdr
- 16.4.1 段类型p_type
- 16.4.2 readelf -l查看程序头表
- 16.4.2.1 可重定位的对象文件(Relocatable file)
- 16.4.2.2 可被共享的对象文件(Shared object file)
- 16.4.2.3 可执行的对象文件(Executable file)
- 16.5 节区(Sections)
- 16.5.1 节区头部表格
- 16.5.2 特殊节区
- 16.5.3 readelf -S查看节区头表
- 16.5.3.1 可重定位的对象文件(Relocatable file)
- 16.5.3.2 可执行的对象文件(Executable file)
- 16.5.3.3 可被共享的对象文件(Shared object file)
- 16.6 字符串表
- 16.7 符号表(Symbol Table)
- 16.7.1 数据结构elfxx_sym
- 17 加载和动态链接
- 16.1 布局和结构
- 18 elf文件格式的注册
- 19 内核空间的加载过程load_elf_binary
- 19.1 填充并且检查目标程序ELF头部
- 19.2 load_elf_phdrs加载目标程序的程序头表
- 19.3 如果需要动态链接, 则寻找和处理解释器段, 得到解释器映像的elf头部
- 19.4 检查并读取解释器的程序表头
- 19.5 装入目标程序的段segment
- 19.6 填写程序的入口地址
- 19.7 create_elf_tables()填写目标文件的参数环境变量等必要信息
- 19.8 start_thread宏准备进入新的程序入口
- 19.9 小结
- 20 ELF文件中符号的动态解析过程
- 20.1 内核的工作
- 20.2 动态链接器的工作
- 21 Linux进程退出
- 21.1 linux下进程退出的方式
- 21.1.1 正常退出
- 21.1.2 异常退出
- 21.2 _exit, exit和_Exit的区别和联系
- 21.3 进程退出的系统调用
- 21.3.1 _exit和exit_group系统调用
- 21.3.2 系统调用声明
- 21.3.3 系统调用号
- 21.3.4 系统调用实现
- 21.4 do_group_exist流程
- 21.5 do_exit()流程
- 22 调度器和调度策略
- 22.1 进程饥饿
- 23 Linux进程的分类
- 23.1 进程的分类
- 23.2 实时进程与普通进程
- 21.1 linux下进程退出的方式
- 24 linux调度器的演变
- 24.1 O(n)的始调度算法
- 24.2 O(1)调度器
- 24.3 CFS调度器Completely Fair Scheduler
- 24.3.1 楼梯调度算法staircase scheduler(SD)
- 24.3.2 RSDL(Rotating Staircase Deadline Scheduler)
- 24.3.3 完全公平的调度器CFS
- 25 Linux调度器的组成
- 25.1 2个调度器
- 25.2 6种调度策略
- 25.3 5个调度器类
- 25.4 3个调度实体
- 25.5 调度器类的就绪队列
- 25.6 调度器整体框架
- 25.7 5种调度器类为什么只有3种调度实体?
- 26 进程调度的数据结构
- 26.1 task_struct中调度相关的成员
- 26.1.1 优先级
- 26.1.2 调度策略
- 26.1.3 调度策略相关字段
- 26.2 调度类
- 26.3 就绪队列
- 26.3.1 CPU就绪队列struct rq
- 26.3.2 CFS公平调度器的就绪队列cfs_rq
- 26.3.3 实时进程就绪队列rt_rq
- 26.3.4 deadline就绪队列dl_rq
- 26.4 调度实体
- 26.4.1 普通进程调度实体sched_entity
- 26.4.2 实时进程调度实体sched_rt_entity
- 26.4.3 EDF调度实体sched_dl_entity
- 26.5 组调度(struct task_group)
- 26.1 task_struct中调度相关的成员
- 27 进程调度小结
- 28 周期性调度器scheduler_tick
- 28.1 周期性调度器主流程
- 28.2 更新统计量
- 28.3 激活进程所属调度类的周期性调度器
- 29 周期性调度器的激活
- 29.1 定时器周期性的激活调度器
- 29.2 定时器中断实现
- 30 主调度器schedule()
- 30.1 调度函数的__sched前缀
- 30.2 schedule()函数
- 30.2.1 schedule主框架
- 30.2.2 sched_submit_work()避免死锁
- 30.2.3 preempt_disable和sched_preempt_enable_no_resched开关内核抢占
- 30.3 __schedule()开始进程调度
- 30.3.1 __schedule()函数主框架
- 30.3.2 pick_next_task选择抢占的进程
- 30.3.3 context_switch进程上下文切换
- 30.3.3.1 进程上下文切换
- 30.3.3.2 context_switch()流程
- 30.3.3.3 switch_mm切换进程虚拟地址空间
- 30.3.3.4 switch_to切换进程堆栈和寄存器
- 30.3.4 need_resched()判断是否用户抢占
- 31 用户抢占和内核抢占
- 31.1 Linux用户抢占
- 31.1.1 need_resched标识TIF_NEED_RESCHED
- 31.1.2 用户抢占的发生时机(什么时候需要重新调度need_resched)
- 31.2 Linux内核抢占
- 31.2.1 内核抢占的发生时机
- 31.2.2 内核抢占的实现
- 31.2.2.1 内核如何跟踪它能否被抢占?
- 31.2.2.2 内核如何知道是否需要抢占?
- 31.2.2.2.1 重新启用内核抢占时使用preempt_schedule()检查抢占
- 31.2.2.2.2 中断之后返回内核态时通过preempt_schedule_irq()触发
- 31.2.2.2.3 PREEMPT_ACTIVE标识位和PREEMPT_DISABLE_OFFSET
- 31.3 小结
- 31.3.1 用户抢占
- 31.3.2 内核抢占
- 31.1 Linux用户抢占
- 32 Linux优先级
- 32.1 内核的优先级表示
- 32.2 DEF最早截至时间优先实时调度算法的优先级描述
- 32.3 进程优先级的计算
- 32.3.1 normal_prio()设置普通优先级normal_prio
- 32.3.1.1 辅助函数task_has_dl_policy和task_has_rt_policy
- 32.3.1.2 关于rt_priority数值越大, 实时进程优先级越高的问题
- 32.3.1.3 为什么需要__normal_prio函数
- 32.3.2 effective_prio()设置动态优先级prio
- 32.3.2.1 使用优先级数值检测实时进程rt_prio()
- 32.3.3 设置prio的时机
- 32.3.3.1 nice系统调用的实现
- 32.3.3.2 fork时优先级的继承
- 32.3.1 normal_prio()设置普通优先级normal_prio
- 33 Linux睡眠唤醒抢占
- 33.1 Linux进程的睡眠
- 33.2 Linux进程的唤醒
- 33.2.1 wake_up_process()
- 33.2.2 try_to_wake_up()
- 33.2.3 wake_up_new_task()
- 33.2.3.1 check_preempt_curr
- 33.3 无效唤醒
- 33.3.1 无效唤醒的原因
- 33.3.2 避免无效抢占
- 34 stop_sched_class调度器类与stop_machine机制
- 35 dl_sched_class调度器类
- 36 rt_sched_class调度器类
- 37 fair_sched_clas调度器类
- 37.1 CFS调度器类fair_sched_class
- 37.2 cfs的就绪队列
- 37.3 进程优先级
- 37.4 负荷权重
- 37.4.1 调度实体的负荷权重结构struct load_weight
- 37.4.2 进程的负荷权重
- 37.5 优先级和权重的转换
- 37.5.1 优先级->权重转换表
- 37.5.2 set_load_weight()依据静态优先级设置进程的负荷权重
- 37.6 就绪队列的负荷权重
- 37.6.1 就绪队列的负荷权重计算
- 37.7 虚拟运行时间
- 37.7.1 虚拟时钟相关的数据结构
- 37.7.1.1 调度实体的虚拟时钟信息
- 37.7.1.2 就绪队列上的虚拟时钟信息
- 37.7.2 update_curr()函数计算进程虚拟时间
- 37.7.2.1 计算时间差
- 37.7.2.2 模拟虚拟时钟
- 37.7.2.3 重新设置cfs_rq->min_vruntime
- 37.7.1 虚拟时钟相关的数据结构
- 37.8 红黑树的键值entity_key和entity_before
- 37.x 进程调度相关的初始化sched_fork()
- 38 idle_sched_class调度器类
1 进程描述符struct task_struct
1.1 进程状态
struct task_struct{
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
}可能取值是
[include/linux/sched.h]
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128 /** wake on signals that are deadly **/
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_STATE_MAX 2048
/* Convenience macros for the sake of set_task_state */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)1.1.1 5个互斥状态
| 状态 | 描述 |
|---|---|
| TASK_RUNNING | 表示进程要么正在执行,要么正要准备执行(已经就绪),正在等待cpu时间片的调度 |
| TASK_INTERRUPTIBLE | 阻塞态.进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号……,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING |
| TASK_UNINTERRUPTIBLE | 意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外,对于处于TASK_UNINTERRUPIBLE状态的进程,哪怕我们传递一个信号或者有一个外部中断都不能唤醒他们。只有它所等待的资源可用的时候,他才会被唤醒。这个标志很少用,但是并不代表没有任何用处,其实他的作用非常大,特别是对于驱动刺探相关的硬件过程很重要,这个刺探过程不能被一些其他的东西给中断,否则就会让进城进入不可预测的状态 |
| TASK_STOPPED | 进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态 |
| TASK_TRACED | 表示进程被debugger等进程监视,进程执行被调试程序所停止,当一个进程被另外的进程所监视,每一个信号都会让进城进入该状态 |
1.1.2 2个终止状态
有两个附加的进程状态既可以被添加到state域中,又可以被添加到exit_state域中.
只有当进程终止的时候,才会达到这两种状态.
struct task_struct{
int exit_state;
int exit_code, exit_signal;
}| 状态 | 描述 |
|---|---|
| EXIT_ZOMBIE | 进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程 |
| EXIT_DEAD | 进程的最终状态 |
1.1.3 睡眠状态
1.1.3.1 内核将进程置为睡眠状态的方法
两种方法.
普通方法是将进程状态置为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE, 然后调用调度程序的schedule()函数。这样会将进程从CPU运行队列中移除。
- TASK_INTERRUPTIBLE: 可中断模式的睡眠状态, 可通过显式的唤醒呼叫(wakeup_process())或者需要处理的信号来唤醒
- TASK_UNINTERRUPTIBLE: 不可中断模式的睡眠状态, 只能通过显式的唤醒呼叫, 一般不建议设置
新方法是使用新的进程睡眠状态TASK_KILLABLE
TASK_KILLABLE: 可以终止的新睡眠状态, 原理类似于TASK_UNINTERRUPTIBLE,只不过可以响应致命信号
1.1.4 状态切换
进程状态的切换过程和原因大致如下图
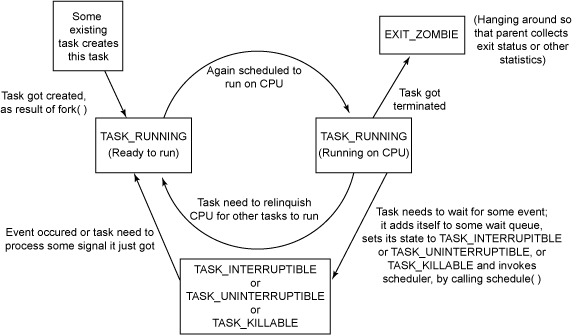
1.2 进程标识符(PID)
typedef int __kernel_pid_t;
typedef __kernel_pid_t pid_t;
struct task_struct{
pid_t pid;
pid_t tgid;
}pid来标识进程,一个线程组所有线程与领头线程具有相同的pid,存入tgid字段,只有线程组的领头线程的pid成员才会被设置为与tgid相同的值。
注意, getpid()返回当前进程的tgid值而不是pid的值(!!!)。
在CONFIG_BASE_SMALL配置为0的情况下,PID的取值范围是0到32767,即系统中的进程数最大为32768个。
#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000) 1.3 进程内核栈与thread_info结构
1.3.1 为什么需要内核栈
struct task_struct{
// 指向内核栈的指针
void *stack;
}进程在内核态运行时需要自己的堆栈信息,因此linux内核为每个进程(!!!每一个!!!)都提供了一个内核栈kernel stack(这里的stack就是这个进程在内核态的堆栈信息!!!)
内核态的进程访问处于内核数据段的栈,这个栈不同于用户态的进程所用的栈。
用户态进程所用的栈,是在进程线性地址空间中;
而内核栈是当进程从用户空间进入内核空间时,特权级发生变化,需要切换堆栈,那么内核空间中使用的就是这个内核栈。因为内核控制路径使用很少的栈空间,所以只需要几千个字节的内核态堆栈。
需要注意的是,内核态堆栈仅用于内核例程,Linux内核另外为中断提供了单独的硬中断栈和软中断栈
1.3.2 为什么需要thread_info
内核还需要存储每个进程的PCB信息,linux内核是支持不同体系的,但是不同的体系结构可能进程需要存储的信息不尽相同,这就需要我们实现一种通用的方式,我们将体系结构相关的部分和无关的部分进行分离
用一种通用的方式来描述进程, 这就是struct task_struct, 而thread_info就保存了特定体系结构的汇编代码段需要访问的那部分进程的数据, 我们在thread_info中嵌入指向task_struct的指针, 则我们可以很方便的通过thread_info来查找task_struct
1.3.3 内核栈和线程描述符
对每个进程,Linux内核都把两个不同的数据结构紧凑的存放在一个单独为进程分配的内存区域中
-
一个是内核态的进程堆栈,
-
另一个是紧挨着进程描述符的小数据结构thread_info,叫做线程描述符。
Linux将这两个存放在一块, 这块区域通常是8192 Byte(两个页框), 其地址必须是8192的整数倍.
[arch/x86/include/asm/page_32_types.h]
#define THREAD_SIZE_ORDER 1
// 2个页大小
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)[arch/x86/include/asm/page_64_types.h]
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
// 4个页或8个页大小
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)下图中显示了在物理内存中存放两种数据结构的方式。线程描述符驻留与这个内存区的开始,而栈顶末端向下增长。

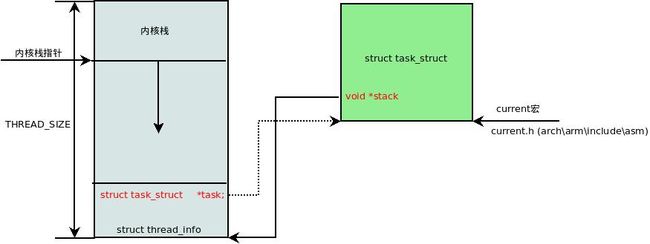
sp寄存器是CPU栈指针,用来存放栈顶单元的地址。在80x86系统中,栈起始于顶端,并朝着这个内存区开始的方向增长。从用户态刚切换到内核态以后,进程的内核栈总是空的。因此,esp寄存器指向这个栈的顶端。一旦数据写入堆栈,esp的值就递减。
进程描述符task_struct结构中没有直接指向thread_info结构的指针,而是用一个void指针类型的成员表示,然后通过类型转换来访问thread_info结构。
#define task_thread_info(task) ((struct thread_info *)(task)->stack)1.3.4 内核栈数据结构描述thread_info和thread_union
thread_info是体系结构相关的,结构的定义在thread_info.h, 不同体系结构不同文件.
[arch/x86/include/asm/thread_info.h]
struct thread_info {
struct task_struct *task; /* main task structure */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};Linux内核中使用一个联合体来表示一个进程的线程描述符和内核栈:
[include/linux/sched.h]
union thread_union
{
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};1.3.5 获取当前在CPU上正在运行进程的thread_info
static inline unsigned long current_top_of_stack(void)
{
#ifdef CONFIG_X86_64
// 内核栈(0)栈顶寄存器SP0
return this_cpu_read_stable(cpu_tss.x86_tss.sp0);
#else
/* sp0 on x86_32 is special in and around vm86 mode. */
return this_cpu_read_stable(cpu_current_top_of_stack);
#endif
}
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_top_of_stack() - THREAD_SIZE);
}为了获取当前CPU上运行进程的task_struct结构,内核提供了current宏,由于task_struct *task在thread_info的起始位置,该宏本质上等价于current_thread_info()->task
[include/asm-generic/current.h]
#define get_current() (current_thread_info()->task)
#define current get_current()1.3.6 分配和销毁thread_info
进程通过alloc_thread_info_node()函数分配它的内核栈,通过free_thread_info()函数释放所分配的内核栈。
1.4 进程标记
struct task_struct{
unsigned int flags;
}反应进程状态的信息,但不是运行状态,用于内核识别进程当前的状态
取值以PF(ProcessFlag)开头的宏, 定义在include/linux/sched.h
1.5 表示进程亲属关系的成员
struct task_struct{
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
}| 字段 | 描述 |
|---|---|
| real_parent | 指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程 |
| parent | 指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与real_parent相同 |
| children | 表示链表的头部,链表中的所有元素都是它的子进程 |
| sibling | 用于把当前进程插入到兄弟链表中 |
| group_leader | 指向其所在进程组的领头进程 |
1.6 ptrace系统调用
ptrace提供了一种父进程可以控制子进程运行,并可以检查和改变它的核心image。
主要用于实现断点调试。一个被跟踪的进程运行中,直到发生一个信号,则进程被中止,并且通知其父进程。在进程中止的状态下,进程的内存空间可以被读写。父进程还可以使子进程继续执行,并选择是否是否忽略引起中止的信号。
struct task_struct{
unsigned int ptrace;
struct list_head ptraced;
struct list_head ptrace_entry;
unsigned long ptrace_message;
siginfo_t *last_siginfo;
}成员ptrace被设置为0时表示不需要被跟踪, 取值定义在文件include/linux/ptrace.h, 以PT开头
1.7 Performance Event
性能诊断工具.分析进程的性能问题.
struct task_struct{
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
}1.8 进程调度
1.8.1 优先级
struct task_struct{
int prio, static_prio, normal_prio;
unsigned int rt_priority;| 字段 | 描述 |
|---|---|
| static_prio | 用于保存静态优先级,可以通过nice系统调用来进行修改 |
| rt_priority | 用于保存实时优先级 |
| normal_prio | 值取决于静态优先级和调度策略 |
| prio | 用于保存动态优先级 |
实时优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(即100到139)。值越大静态优先级越低。
1.8.2 调度策略相关字段
struct task_struct{
unsigned int policy;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
cpumask_t cpus_allowed;
}| 字段 | 描述 |
|---|---|
| policy | 调度策略 |
| sched_class | 调度类 |
| se | 普通进程的调度实体,每个进程都有其中之一的实体 |
| rt | 实时进程的调度实体,每个进程都有其中之一的实体 |
| cpus_allowed | 用于控制进程可以在哪些处理器上运行 |
1.9 进程地址空间
struct task_struct{
struct mm_struct *mm, *active_mm;
/* per-thread vma caching */
u32 vmacache_seqnum;
struct vm_area_struct *vmacache[VMACACHE_SIZE];
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
}| 字段 | 描述 |
|---|---|
| mm | 进程所拥有的用户空间内存描述符(拥有的!!!),内核线程无,mm为NULL |
| active_mm | active_mm指向进程运行时所使用的内存描述符(使用的!!!内核线程不拥有用户空间内存,但是必须有使用的空间),对于普通进程而言,这两个指针变量的值相同。但是内核线程kernel thread是没有进程地址空间的,所以内核线程的tsk->mm域是空(NULL)。但是内核必须知道用户空间包含了什么,因此它的active_mm成员被初始化为前一个运行进程的mm值。 |
| brk_randomized | 用来确定对随机堆内存的探测。参见LKML上的介绍 |
| rss_stat | 用来记录缓冲信息 |
如果当前内核线程被调度之前运行的也是另外一个内核线程时候,那么其mm和avtive_mm都是NULL
对Linux来说,用户进程和内核线程(kernel thread)都是task_struct的实例,唯一的区别是kernel thread是没有进程地址空间的,内核线程也没有mm描述符的,所以内核线程的tsk->mm域是空(NULL)。
内核scheduler在进程context switching的时候,会根据tsk->mm判断即将调度的进程是用户进程还是内核线程。
但是虽然thread thread不用访问用户进程地址空间,但是仍然需要page table来访问kernel自己的空间。但是幸运的是,对于任何用户进程来说,他们的内核空间都是100%相同的,所以内核可以’borrow'上一个被调用的用户进程的mm中的页表来访问内核地址,这个mm就记录在active_mm。
简而言之就是,对于kernel thread,tsk->mm == NULL表示自己内核线程的身份,而tsk->active_mm是借用上一个用户进程的mm,用mm的page table来访问内核空间。对于用户进程,tsk->mm == tsk->active_mm。
1.10 判断标志
struct task_struct{
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
unsigned long jobctl; /* JOBCTL_*, siglock protected */
/* Used for emulating ABI behavior of previous Linux versions */
unsigned int personality;
/* scheduler bits, serialized by scheduler locks */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
unsigned sched_migrated:1;
unsigned :0; /* force alignment to the next boundary */
/* unserialized, strictly 'current' */
unsigned in_execve:1; /* bit to tell LSMs we're in execve */
unsigned in_iowait:1;
}| 字段 | 描述 |
|---|---|
| exit_code | 用于设置进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数(正常终止),要么是由内核提供的一个错误代号(异常终止)。 |
| exit_signal | 被置为-1时表示是某个线程组中的一员。只有当线程组的最后一个成员终止时,才会产生一个信号,以通知线程组的领头进程的父进程。 |
| pdeath_signal | 用于判断父进程终止时发送信号。 |
| personality | 用于处理不同的ABI |
| in_execve | 用于通知LSM是否被do_execve()函数所调用 |
| in_iowait | 用于判断是否进行iowait计数 |
| sched_reset_on_fork | 用于判断是否恢复默认的优先级或调度策略 |
1.11 时间
| 字段 | 描述 |
|---|---|
| utime/stime | 用于记录进程在用户态/内核态下所经过的节拍数(定时器) |
| prev_utime/prev_stime | 先前的运行时间 |
| utimescaled/stimescaled | 用于记录进程在用户态/内核态的运行时间,但它们以处理器的频率为刻度 |
| gtime | 以节拍计数的虚拟机运行时间(guest time) |
| nvcsw/nivcsw | 是自愿(voluntary)/非自愿(involuntary)上下文切换计数 |
| last_switch_count | nvcsw和nivcsw的总和 |
| start_time/real_start_time | 进程创建时间,real_start_time还包含了进程睡眠时间,常用于/proc/pid/stat |
| cputime_expires | 用来统计进程或进程组被跟踪的处理器时间,其中的三个成员对应着cpu_timers[3]的三个链表 |
1.12 信号处理
struct task_struct{
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
}| 字段 | 描述 |
|---|---|
| signal | 指向进程的信号描述符 |
| sighand | 指向进程的信号处理程序描述符 |
| blocked | 表示被阻塞信号的掩码,real_blocked表示临时掩码 |
| pending | 存放私有挂起信号的数据结构 |
| sas_ss_sp | 是信号处理程序备用堆栈的地址,sas_ss_size表示堆栈的大小 |
1.13 其他
2 命名空间
Linux Namespaces机制提供一种资源隔离方案。
命名空间是为操作系统层面的虚拟化机制提供支撑,目前实现的有六种不同的命名空间,分别为mount命名空间、UTS命名空间、IPC命名空间、用户命名空间、PID命名空间、网络命名空间。命名空间简单来说提供的是对全局资源的一种抽象,将资源放到不同的容器中(不同的命名空间),各容器彼此隔离。
命名空间有的还有层次关系,如PID命名空间
要创建新的Namespace,只需要在调用clone时指定相应的flag。
LXC(Linux containers)就是利用这一特性实现了资源的隔离。
虽然子容器不了解系统中的其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有进程。子容器的进程映射到父容器中,PID为4到9。尽管系统上有9个进程,但却需要15个PID来表示,因为一个进程可以关联到多个PID。
2.1 Linux内核命名空间描述
在Linux内核中提供了多个namespace!!!,一个进程可以属于多个namesapce.
在task_struct 结构中有一个指向namespace结构体的指针nsproxy。
struct task_struct
{
/* namespaces */
struct nsproxy *nsproxy;
}
struct nsproxy
{
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
};struct nsproxy定义了5个指向各个类型namespace的指针, 由于多个进程可以使用同一个namespace,所以nsproxy可以共享使用,count字段是该结构的引用计数。
-
UTS命名空间包含了运行内核的名称、版本、底层体系结构类型等信息。UTS是UNIX Timesharing System的简称。
-
保存在struct ipc_namespace中的所有与进程间通信(IPC)有关的信息。
-
已经装载的文件系统的视图,在struct mnt_namespace中给出。
-
有关进程ID的信息,由struct pid_namespace提供。
-
struct net包含所有网络相关的命名空间参数。
系统中有一个默认的nsproxy,init_nsproxy,该结构在task初始化是也会被初始化,定义在include/linux/init_task.h
#define INIT_TASK(tsk) \
{
.nsproxy = &init_nsproxy,
}其中init_nsproxy的定义为:
struct nsproxy init_nsproxy = {
.count = ATOMIC_INIT(1),
.uts_ns = &init_uts_ns,
#if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC)
.ipc_ns = &init_ipc_ns,
#endif
.mnt_ns = NULL,
.pid_ns_for_children = &init_pid_ns,
#ifdef CONFIG_NET
.net_ns = &init_net,
#endif
};
对于.mnt_ns没有进行初始化,其余的namespace都进行了系统默认初始化
2.2 命名空间的创建
新的命名空间可以用下面两种方法创建。
-
在用fork或clone系统调用创建新进程时,有特定的选项可以控制是与父进程共享命名空间,还是建立新的命名空间。
-
unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间。
命名空间的实现需要两个部分:
-
每个子系统的命名空间结构,将此前所有的全局组件包装到命名空间中;
-
将给定进程关联到所属各个命名空间的机制。
使用fork或clone系统调用创建新进程可使用的选项:
-
CLONE_NEWPID 进程命名空间。空间内的PID是独立分配的,意思就是命名空间内的虚拟PID可能会与命名空间外的PID相冲突,于是命名空间内的PID映射到命名空间外时会使用另外一个PID。比如说,命名空间内第一个PID为1,而在命名空间外就是该PID已被init进程所使用。
-
CLONE_NEWIPC 进程间通信(IPC)的命名空间,可以将SystemV的IPC和POSIX的消息队列独立出来。
-
CLONE_NEWNET 网络命名空间,用于隔离网络资源(/proc/net、IP地址、网卡、路由等)。后台进程可以运行在不同命名空间内的相同端口上,用户还可以虚拟出一块网卡。
-
CLONE_NEWNS 挂载命名空间,进程运行时可以将挂载点与系统分离,使用这个功能时,我们可以达到 chroot 的功能,而在安全性方面比 chroot 更高。
-
CLONE_NEWUTS UTS命名空间,主要目的是独立出主机名和网络信息服务(NIS)。
-
CLONE_NEWUSER 用户命名空间,同进程ID一样,用户ID和组ID在命名空间内外是不一样的,并且在不同命名空间内可以存在相同的ID。
2.3 PID Namespace
CLONE_NEWPID, 会创建一个新的PID Namespace,clone出来的新进程将成为Namespace里的第一个进程,PID Namespace内的PID将从1开始, 类似于独立系统中的init进程, 该Namespace内的孤儿进程都将以该进程为父进程,当该进程被结束时,该Namespace内所有的进程都会被结束。
PID Namespace是层次性,新创建的Namespace将会是创建该Namespace的进程属于的Namespace的子Namespace。子Namespace中的进程对于父Namespace是可见的,一个进程将拥有不止一个PID,而是在所在的Namespace以及所有直系祖先Namespace中都将有一个PID(直系祖先!!!)。
系统启动时,内核将创建一个默认的PID Namespace,该Namespace是所有以后创建的Namespace的祖先,因此系统所有的进程在该Namespace都是可见的。
3 进程ID类型
[include/linux/pid.h]
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};- PID, 其命名空间中唯一标识进程
- TGID, 线程组(轻量级进程组)的ID标识
在一个进程中,如果以CLONE_THREAD标志来调用clone建立的进程就是该进程的一个线程(即轻量级进程,Linux其实没有严格的线程概念),它们处于一个线程组, 所有进程都有相同的TGID, pid不同.
线程组组长(也叫主线程)的TGID与其PID相同;一个进程没有使用线程,则其TGID与PID也相同。
该枚举没有包括线程组ID, 因为task_struct已经线程组ID
struct task_struct
{
pid_t pid;
pid_t tgid;
}- PGID, 进程组的ID标识
独立的进程可以组成进程组(使用setpgrp系统调用),进程组可以简化向所有组内进程发送信号的操作
- SID, 会话组的ID标识
几个进程组可以合并成一个会话组(使用setsid系统调用), SID保存在task_struct的session成员中
4 PID命名空间
4.1 pid命名空间概述
PID命名空间有层次关系
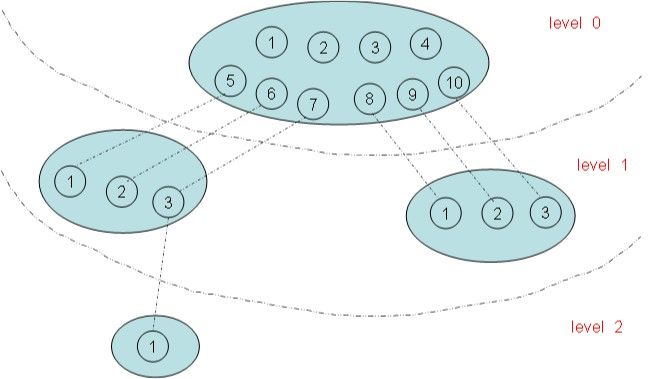
上图有四个命名空间,一个父命名空间衍生了两个子命名空间,其中的一个子命名空间又衍生了一个子命名空间。以PID命名空间为例,由于各个命名空间彼此隔离,所以每个命名空间都可以有 PID 号为 1 的进程;但又由于命名空间的层次性,父命名空间是知道子命名空间的存在,因此子命名空间要映射到父命名空间中去,因此上图中 level 1 中两个子命名空间的六个进程分别映射到其父命名空间的PID号5~10。
level 2的PID是1的进程在level 1和level 0都有映射
4.2 局部ID和全局ID
全局ID: 在内核本身和初始命名空间中唯一的ID(初始命名空间中!!!), 系统启动期间开始的init进程即属于该初始命名空间。
局部ID: 属于某个特定的命名空间
4.2.1 全局ID
- 全局PID和全局TGID直接保存在task_struct中,分别是task_struct的pid和tgid成员:
struct task_struct
{
pid_t pid;
pid_t tgid;
} 两项都是pid_t类型,该类型定义为__kernel_pid_t,后者由各个体系结构分别定义。通常定义为int,即可以同时使用232个不同的ID。
-
task_struct->signal->__session表示全局SID, set_task_session用于修改
-
全局PGID则保存在task_struct->signal->__pgrp, set_task_pgrp用于修改
4.2.2 局部ID
4.3 PID命名空间数据结构pid_namespace
struct pid_namespace
{
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES];
int last_pid;
struct task_struct *child_reaper;
struct kmem_cache *pid_cachep;
unsigned int level;
struct pid_namespace *parent;
}; | 字段 | 描述 |
|---|---|
| kref | 表示指向pid_namespace的个数 |
| pidmap | pidmap结构体表示分配pid的位图。当需要分配一个新的pid时只需查找位图,找到bit为0的位置并置1,然后更新统计数据域(nr_free) |
| last_pid | 用于pidmap的分配。指向最后一个分配的pid的位置。 |
| child_reaper | 指向的是当前命名空间的init进程,每个命名空间都有一个作用相当于全局init进程的进程 |
| pid_cachep | 域指向分配pid的slab的地址。 |
| level | 代表当前命名空间的等级,初始命名空间的level为0,它的子命名空间level为1,依次递增,而且子命名空间对父命名空间是可见的。从给定的level设置,内核即可推断进程会关联到多少个ID。 |
| parent | 指向父命名空间的指针 |
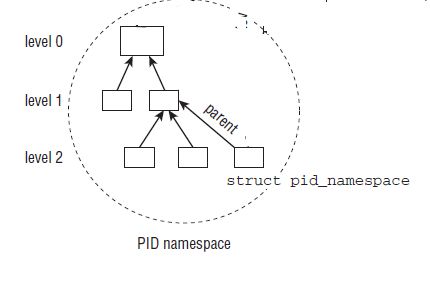
PID分配器也需要依靠该结构的某些部分来连续生成唯一ID
每个PID命名空间都具有一个进程,其发挥的作用相当于全局的init进程。init的一个目的是对孤儿进程调用wait4,命名空间局部的init变体也必须完成该工作。
5 pid结构描述
5.1 pid与upid
PID的管理围绕两个数据结构展开:
-
struct pid是内核对PID的内部表示
-
struct upid则表示特定的命名空间中可见的信息
5.1.1 特定命名空间信息struct upid
[include/linux/pid.h]
struct upid
{
int nr;
struct pid_namespace *ns;
struct hlist_node pid_chain;
}; struct upid是一个特定namespace里面的进程的信息,包含该namespace里面进程具体ID号,namespace指针,哈希列表指针.
| 字段 | 描述 |
|---|---|
| nr | 表示在该命名空间所分配的进程ID具体的值 |
| ns | 指向命名空间的指针 |
| pid_chain | 指向PID哈希列表的指针,用于关联对应的PID |
所有的upid实例都保存在一个散列表中
5.1.2 局部ID类struct pid
[include/linux/pid.h]
struct pid
{
atomic_t count;
/* 使用该pid的进程的列表 */
struct hlist_head tasks[PIDTYPE_MAX];
int level;
struct upid numbers[1];
};srtuct pid是局部ID类,对应一个
| 字段 | 描述 |
|---|---|
| count | 是指使用该PID的task的数目; |
| level | 表示可以看到该PID的命名空间的数目,也就是包含该进程的命名空间的深度 |
| tasks[PIDTYPE_MAX] | 是一个数组,每个数组项都是一个散列表头,分别对应以下三种类型 |
| numbers[1] | 一个upid的实例数组,每个数组项代表一个命名空间,用来表示一个PID可以属于不同的命名空间,该元素放在末尾,可以向数组添加附加的项。 |
tasks是一个数组,每个数组项都是一个散列表头,对应于一个ID类型, PIDTYPE_PID,PIDTYPE_PGID,PIDTYPE_SID(PIDTYPE_MAX表示ID类型的数目)这样做是必要的,因为一个ID可能用于几个进程(task_struct)!!!。所有共享同一ID的task_struct实例,都通过该列表连接起来(这个列表就是使用这个pid的进程
5.2 用于分配pid的位图struct pidmap
需要分配一个新的pid时查找可使用pid的位图
struct pidmap
{
atomic_t nr_free;
void *page;
};| 字段 | 描述 |
|---|---|
| nr_free | 表示还能分配的pid的数量 |
| page | 指向的是存放pid的物理页 |
pidmap[PIDMAP_ENTRIES]域表示该pid_namespace下pid已分配情况
5.3 pid的哈希表存储结构struct pid_link
pid_link是pid的哈希表存储结构
task_struct中的struct pid_link pids[PIDTYPE_MAX]指向了和该task_struct相关的pid结构体。
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};5.4 task_struct中的进程ID相关描述符信息
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
struct task_struct
{
pid_t pid;
pid_t tgid;
struct task_struct *group_leader;
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct list_head thread_node;
struct nsproxy *nsproxy;
};
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};
struct pid
{
unsigned int level;
/* 使用该pid的进程的列表, lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX];
struct upid numbers[1];
};
struct upid
{
int nr;
struct pid_namespace *ns;
struct hlist_node pid_chain;
};task_struct结构信息
| 字段 | 描述 |
|---|---|
| pid | 指该进程的进程描述符。在fork函数中对其进行赋值的 |
| tgid | 指该进程的线程描述符。在linux内核中对线程并没有做特殊的处理,还是由task_struct来管理。所以从内核的角度看, 用户态的线程本质上还是一个进程。对于同一个进程(用户态角度)中不同的线程其tgid是相同的,但是pid各不相同。 主线程即group_leader(主线程会创建其他所有的子线程)。如果是单线程进程(用户态角度),它的pid等于tgid。 |
| group_leader | 除了在多线程的模式下指向主线程!!!,还有一个用处,当一些进程组成一个群组时(PIDTYPE_PGID), 该域指向该进程群组!!!的leader |
| pids | pids[0]是PIDTYPE_PID类型的,指向自己的PID结构, 其余指向了相应群组的leader的PID结构,也就是组长的PID结构 |
| nsproxy | 指针指向namespace相关的域,通过nsproxy域可以知道该task_struct属于哪个pid_namespace |
对于用户态程序来说,调用getpid()函数其实返回的是tgid,因此线程组中的进程id应该是是一致的,但是他们pid不一致,这也是内核区分他们的标识
-
多个task_struct可以共用一个PID
-
一个PID可以属于不同的命名空间
-
当需要分配一个新的pid时候,只需要查找pidmap位图即可
那么最终,linux下进程命名空间和进程的关系结构如下:
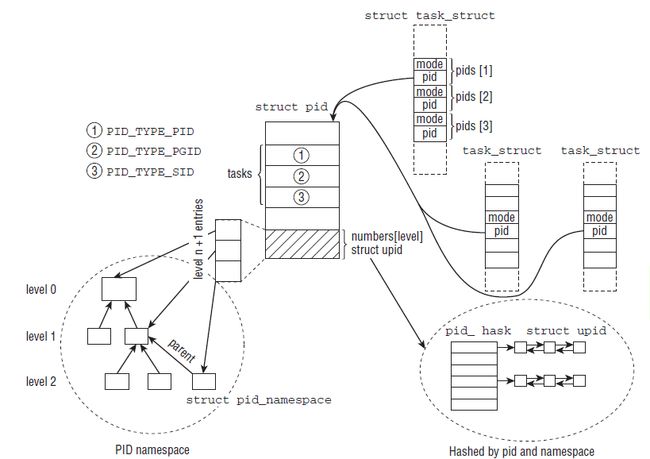
可以看到,多个task_struct指向一个PID,同时PID的hash数组里安装不同的类型对task进行散列,并且一个PID会属于多个命名空间。
-
进程的结构体是task_struct, 一个进程对应一个task_struct结构体(一对一). 一个进程会有PIDTYPE_MAX个(3个)pid_link结构体(一对多), 这三个结构体中的pid分别指向 ①该进程对应的进程本身(PIDTYPE_PID)的真实的pid结构体; ②该进程的进程组(PIDTYPE_PGID)的组长本身的pid结构体; ③该进程的会话组(PIDTYPE_SID)的组长本身的pid结构体. 所以一个真实的进程只会有一个自身真实的pid结构体; thread_group指向的是该线程所在线程组的链表头; thread_node是线程组中的结点.
-
这三个pid_link结构体里面有个哈希节点node, 因为进程组、会话组等的存在, 这个node用来链接同一个组的进程task_struct, 指向的是task_struct中的pid_link的node
-
pid结构体(不是一个ID号)代表一个真实的进程(某个组的组长的pid也是这个结构体, 因为组长也是真实的进程, 也就有相应的真实的pid结构体, 而组长身份是通过task_struct引的), 所以里面会有 ①该进程真实所处命名空间的level; ②PIDTYPE_MAX个(3个)散列表头, tasks[PIDTYPE_PID]指向自身进程(因为PIDTYPE_PID是PID类型), 如果该进程是进程组组长, 那么tasks[PIDTYPE_PGID]就是这个散列表的表头, 指向下一个进程的相应组变量pids[PIDTYPE_PGID]的node, 如果该进程是会话组组长, 那么tasks[PIDTYPE_SID]就是这个散列表的表头, 指向下一个进程的相应组变量pids[PIDTYPE_SID]的node; ③由于一个进程可能会呈现在多个pid命名空间, 所以有该进程在其他命名空间中的信息结构体upid的数组, 每个数组项代表一个
-
结构体upid的数组number[1], 数组项个数取决于该进程pid的level值, 每个数组项代表一个命名空间, 这个就是用来一个PID可以属于不同的命名空间, nr值表示该进程在该命名空间的pid值, ns指向该信息所在的命名空间, pid_chain属于哈希表的节点. 系统有一个pid_hash[], 通过pid在某个命名空间的nr值哈希到某个表项, 如果多个nr值哈希到同一个表项, 将其加入链表, 这个节点就是upid的pid_chain
遍历线程所在线程组的所有线程函数while_each_thread(p, t)使用了:
static inline struct task_struct *next_thread(const struct task_struct *p)
{
return list_entry_rcu(p->thread_group.next,
struct task_struct, thread_group);
}
#define while_each_thread(g, t) \
while ((t = next_thread(t)) != g)扫描同一个进程组的可以, 扫描与current->pids[PIDTYPE_PGID](这是进程组组长pid结构体)对应的PIDTYPE_PGID类型的散列表(因为是进程组组长,所以其真实的pid结构体中tasks[PIDTYPE_PGID]是这个散列表的表头)中的每个PID链表
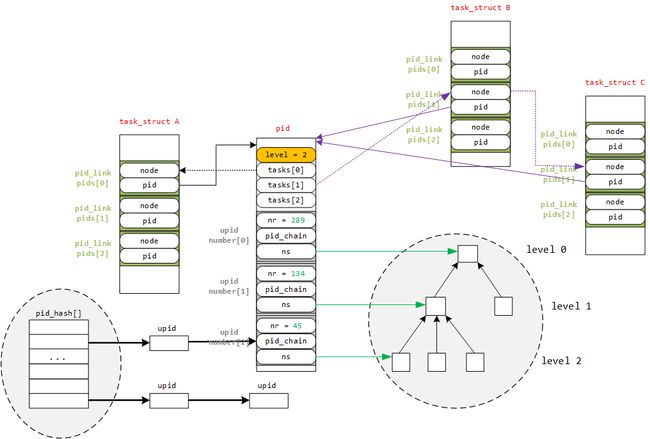
图中关于如何分配唯一的PID没有画出
5.5 进程ID管理函数
5.5.1 进程pid号找到struct pid实体
首先就需要通过进程的pid找到进程的struct pid,然后再通过struct pid找到进程的task_struct
实现函数有三个
//通过pid值找到进程的struct pid实体
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
struct pid *find_vpid(int nr)
struct pid *find_get_pid(pid_t nr)find_pid_ns获得pid实体的实现原理,主要使用哈希查找。
内核使用哈希表组织struct pid,每创建一个新进程,给进程的struct pid都会插入到哈希表中,这时候就需要使用进程的进程pid和pid命名空间ns在哈希表中将相对应的struct pid索引出来
根据局部PID以及命名空间计算在pid_hash数组中的索引,然后遍历散列表找到所要的upid,再根据内核的 container_of 机制找到 pid 实例。
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
{
struct hlist_node *elem;
struct upid *pnr;
//遍历散列表
hlist_for_each_entry_rcu(pnr, elem,
&pid_hash[pid_hashfn(nr, ns)], pid_chain) //pid_hashfn() 获得hash的索引
// 比较 nr 与 ns 是否都相同
if (pnr->nr == nr && pnr->ns == ns)
//根据container_of机制取得pid 实体
return container_of(pnr, struct pid, numbers[ns->level]);
return NULL;
}
EXPORT_SYMBOL_GPL(find_pid_ns);5.5.2 获取局部ID
根据进程的 task_struct、ID类型、命名空间,可以很容易获得其在命名空间内的局部ID
5.5.3 根据PID查找进程task_struct
-
根据PID号(nr值)取得task_struct 结构体
-
根据PID以及其类型(即为局部ID和命名空间)获取task_struct结构体
如果根据的是进程的ID号,我们可以先通过ID号(nr值)获取到进程struct pid实体(局部ID),然后根据局部ID、以及命名空间,获得进程的task_struct结构体
5.5.4 生成唯一的PID
内核中使用下面两个函数来实现分配和回收PID的:
static int alloc_pidmap(struct pid_namespace *pid_ns);
static void free_pidmap(struct upid *upid);struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
tmp = ns;
pid->level = ns->level;
// 初始化 pid->numbers[] 结构体
for (i = ns->level; i >= 0; i--)
{
nr = alloc_pidmap(tmp); //分配一个局部ID
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
// 初始化 pid->task[] 结构体
for (type = 0; type < PIDTYPE_MAX; ++type)
INIT_HLIST_HEAD(&pid->tasks[type]);
// 将每个命名空间经过哈希之后加入到散列表中
upid = pid->numbers + ns->level;
for ( ; upid >= pid->numbers; --upid)
{
hlist_add_head_rcu(&upid->pid_chain, &pid_hash[pid_hashfn(upid->nr, upid->ns)]);
upid->ns->nr_hashed++;
}
return pid;
}6 Liux进程类别
Linux下只有一种类型的进程,那就是task_struct,当然我也想说linux其实也没有线程的概念, 只是将那些与其他进程共享资源的进程称之为线程。
通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。通常把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。
线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文(!!!这些是线程独享的!!!)。
-
一个进程由于其运行空间的不同, 从而有内核线程和用户进程的区分, 内核线程运行在内核空间, 之所以称之为线程是因为它没有虚拟地址空间(唯一使用的资源是内核栈和上下文切换时保持寄存器的空间), 只能访问内核的代码和数据, 而用户进程则运行在用户空间, 但是可以通过中断,系统调用等方式从用户态陷入内核态。
-
用户进程运行在用户空间上,而一些通过共享资源实现的一组进程我们称之为线程组, Linux下内核其实本质上没有线程的概念,Linux下线程其实上是与其他进程共享某些资源的进程而已。但是我们习惯上还是称他们为线程或者轻量级进程
因此, Linux上进程分3种,内核线程(或者叫内核进程)、用户进程、用户线程(!!!因为内核里面的进程没有虚拟地址空间!!!), 当然如果更严谨的,你也可以认为用户进程和用户线程都是用户进程。
-
内核线程拥有进程描述符、PID、进程正文段、内核堆栈
-
用户进程拥有进程描述符、PID、进程正文段、内核堆栈、用户空间的数据段和堆栈
-
用户线程拥有进程描述符、PID、进程正文段、内核堆栈,同父进程共享用户空间的数据段和堆栈
用户线程也可以通过exec函数族拥有自己的用户空间的数据段和堆栈,成为用户进程。
进程task_struct中pid存储的是内核对该进程的唯一标示, 即对进程则标示进程号, 对线程来说就是其线程号, 那么对于线程来说一个线程组所有线程与领头线程具有相同的进程号,存入tgid字段
每个线程除了共享进程的资源外还拥有各自的私有资源:一个寄存器组(或者说是线程上下文);一个专属的堆栈;一个专属的消息队列;一个专属的Thread Local Storage(TLS);一个专属的结构化异常处理串链。
6.1 内核线程
只运行在内核态,不受用户态上下文的拖累。
从内核的角度来说, Linux并没有线程这个概念。Linux把所有的线程都当做进程来实现。
跟普通进程一样,内核线程也有优先级和被调度。当和用户进程拥有相同的static_prio时,内核线程有机会得到更多的cpu资源
内核线程没有自己的地址空间,所以它们的"current->mm"都是空的, 唯一使用的资源就是内核栈和上下文切换时保存寄存器的空间。
内核线程还有核心堆栈,没有mm怎么访问它的核心堆栈呢?这个核心堆栈跟task_struct的thread_info共享8k的空间,所以不用mm描述。
但是内核线程总要访问内核空间的其他内核啊,没有mm域毕竟是不行的。所以内核线程被调用时,内核会将其task_strcut的active_mm指向前一个被调度出的进程的mm域,在需要的时候,内核线程可以使用前一个进程的内存描述符。
因为内核线程不访问用户空间,只操作内核空间内存,而所有进程的内核空间都是一样的。这样就省下了一个mm域的内存。
7 linux进程的创建流程
7.1 进程的复制fork和加载execve
Linux下进行进行编程,往往都是通过fork出来一个新的程序.
一个进程,包括代码、数据和分配给进程的资源,它其实是从现有的进程(父进程)复制出的一个副本(子进程),fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,然后如果我们通过execve为子进程加载新的应用程序后,那么新的进程将开始执行新的应用
- fork生成当前进程的的一个相同副本,该副本成为子进程
原进程(父进程)的所有资源都以适当的方法复制给新的进程(子进程)。因此该系统调用之后,原来的进程就有了两个独立的实例,这两个实例的联系包括:同一组打开文件,同样的工作目录,进程虚拟空间(内存)中同样的数据(当然两个进程各有一份副本,也就是说他们的虚拟地址相同,但是所对应的物理地址不同)等等。
- execve从一个可执行的二进制程序镜像加载应用程序, 来代替当前运行的进程
换句话说, 加载了一个新的应用程序。因此execv并不是创建新进程
所以我们在linux要创建一个进程的时候,其实执行的操作就是
-
首先使用fork复制一个旧的进程
-
然后调用execve在为新的进程加载一个新的应用程序
7.2 写时复制技术
大批量的复制会导致执行效率过低。
现在的Linux内核采用一种更为有效的方法,称之为写时复制(Copy On Write,COW)。这种思想相当简单:父进程和子进程共享页帧而不是复制页帧。然而,只要页帧被共享,它们就不能被修改,即页帧被保护。无论父进程还是子进程何时试图写一个共享的页帧,就产生一个异常,这时内核就把这个页复制到一个新的页帧中并标记为可写(标志位设置只是对用户特权级即3特权级有效)。原来的页帧仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页帧的唯一属主,如果是,就把这个页帧标记为对这个进程是可写的。
当父进程A或子进程B任何一方对这些已共享的物理页面执行写操作时,都会产生页面出错异常(page_fault int14)中断,此时CPU会执行系统提供的异常处理函数do_wp_page()来解决这个异常.
do_wp_page()会对这块导致写入异常中断的物理页面进行取消共享操作,为写进程复制一新的物理页面,使父进程A和子进程B各自拥有一块内容相同的物理页面.最后,从异常处理函数中返回时,CPU就会重新执行刚才导致异常的写入操作指令,使进程继续执行下去.
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值(比如PID)不同。相当于克隆了一个自己。
7.3 内核线程创建接口
在内核中,有两种方法可以生成内核线程,一种是使用kernel_thread()接口,另一种是用kthread_create()接口
7.3.1 kernel_thread
先说kernel_thread接口,使用该接口创建的线程,必须在该线程中调用daemonize()函数,这是因为只有当线程的父进程指向"Kthreadd"时,该线程才算是内核线程(!!!),而恰好daemonize()函数主要工作便是将该线程的父进程改成“kthreadd"内核线程;
默认情况下,调用deamonize()后,会阻塞所有信号,如果想操作某个信号可以调用allow_signal()函数。
// fn为线程函数,arg为线程函数参数,flags为标记
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
// name为内核线程的名称
void daemonize(const char * name,...); 7.3.2 kthread_create
而kthread_create接口,则是标准的内核线程创建接口,只须调用该接口便可创建内核线程;
默认创建的线程是存于不可运行的状态,所以需要在父进程中通过调用wake_up_process()函数来启动该线程。
//threadfn为线程函数;data为线程函数参数;namefmt为线程名称,可被格式化的, 类似printk一样传入某种格式的线程名
struct task_struct *kthread_create(int (*threadfn)(void *data),void *data,
const char namefmt[], ...);
线程创建后,不会马上运行,而是需要将kthread_create()返回的task_struct指针传给wake_up_process(),然后通过此函数运行线程。
7.3.3 kthread_run
当然,还有一个创建并启动线程的函数:kthread_run
struct task_struct *kthread_run(int (*threadfn)(void *data),
void *data,
const char *namefmt, ...);线程一旦启动起来后,会一直运行,除非该线程主动调用do_exit函数,或者其他的进程调用kthread_stop函数,结束线程的运行。
int kthread_stop(struct task_struct *thread);kthread_stop() 通过发送信号给线程。
如果线程函数正在处理一个非常重要的任务,它不会被中断的。当然如果线程函数永远不返回并且不检查信号,它将永远都不会停止。
//唤醒线程
int wake_up_process(struct task_struct *p);
//是以上两个函数的功能的总和
struct task_struct *kthread_run(int (*threadfn)(void *data),void *data,
const char namefmt[], ...);因为线程也是进程,所以其结构体也是使用进程的结构体"struct task_struct"。
7.4 内核线程的退出接口
当内核线程执行到函数末尾时会自动调用内核中do_exit()函数来退出或其他线程调用kthread_stop()来指定线程退出。
怎么调用do_exit()可以看kthreadd线程
int kthread_stop(struct task_struct *thread);kthread_stop()通过发送信号给线程。
如果线程函数正在处理一个非常重要的任务,它不会被中断的。当然如果线程函数永远不返回并且不检查信号,它将永远都不会停止。
在执行kthread_stop的时候,目标线程必须没有退出,否则会Oops。原因很容易理解,当目标线程退出的时候,其对应的task结构也变得无效,kthread_stop引用该无效task结构就会出错。
为了避免这种情况,需要确保线程没有退出,其方法如代码中所示:
thread_func()
{
// do your work here
// wait to exit
while(!thread_could_stop())
{
wait();
}
}
exit_code()
{
kthread_stop(_task); //发信号给task,通知其可以退出了
}这种退出机制很温和,一切尽在thread_func()的掌控之中,线程在退出时可以从容地释放资源,而不是莫名其妙地被人“暗杀”。
8 Linux中3个特殊的进程
Linux下有3个特殊的进程,idle进程($PID = 0$), init进程($PID = 1$)和kthreadd($PID = 2$)
- idle进程由系统自动创建, 运行在内核态
idle进程其pid=0,其前身是系统创建的第一个进程,也是唯一一个没有通过fork或者kernel_thread产生的进程。完成加载系统后,演变为进程调度、交换
- init进程由idle通过kernel_thread创建,在内核空间(!!!)完成初始化后, 最终执行/sbin/init进程,变为所有用户态程序的根进程(pstree命令显示),即用户空间的init进程
由0进程创建,完成系统的初始化.是系统中所有其它用户进程(!!!用户进程!!!)的祖先进程.Linux中的所有进程都是有init进程创建并运行的。首先Linux内核启动,然后在用户空间中启动init进程,再启动其他系统程。在系统启动完成后,init将变为守护进程监视系统其他进程
- kthreadd进程由idle通过kernel_thread创建,并始终运行在内核空间,负责所有内核线程(内核线程!!!)的调度和管理, 变为所有内核态其他守护线程的父线程。
它的任务就是管理和调度其他内核线程kernel_thread,会循环执行一个kthread的函数,该函数的作用就是运行kthread_create_list全局链表中维护kthread, 当我们调用kernel_thread创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程
8.1 0号idle进程
在smp系统中,每个处理器单元有独立的一个运行队列,而每个运行队列上又有一个idle进程,即有多少处理器单元,就有多少idle进程。
系统的空闲时间,其实就是指idle进程的"运行时间"。
8.1.1 0号进程上下文信息--init_task描述符
在内核初始化过程中,通过静态定义构造出了一个task_struct接口,取名为init_task变量,然后在内核初始化的后期,通过rest_init()函数新建了内核init线程,kthreadd内核线程
所以init_task决定了系统所有进程、线程的基因, 它完成初始化后, 最终演变为0号进程idle, 并且运行在内核态
在init_task进程执行后期,它会调用kernel_thread()函数创建第一个核心进程kernel_init,同时init_task进程继续对Linux系统初始化。在完成初始化后,init_task会退化为cpu_idle进程,当Core 0的就绪队列中没有其它进程时,该进程将会获得CPU运行。新创建的1号进程kernel_init将会逐个启动次CPU,并最终创建用户进程!
备注:core 0上的idle进程由init_task进程退化而来,而AP的idle进程则是BSP在后面调用fork()函数逐个创建的
内核在初始化过程中,当创建完init和kthreadd内核线程后,内核会发生调度执行,此时内核将使用该init_task作为其task_struct结构体描述符,当系统无事可做时,会调度其执行,此时该内核会变为idle进程,让出CPU,自己进入睡眠,不停的循环,查看init_task结构体,其comm字段为swapper,作为idle进程的描述符。
init_task描述符在init/init_task.c中定义
[init/init_task.c]
struct task_struct init_task = INIT_TASK(init_task);
EXPORT_SYMBOL(init_task);8.1.2 进程堆栈init_thread_union
init_task进程使用init_thread_union数据结构描述的内存区域作为该进程的堆栈空间,并且和自身的thread_info参数共用这一内存空间空间
#define INIT_TASK(tsk) \
{ \
.stack = &init_thread_info,
}init_thread_info则是一段体系结构相关的定义
[arch/x86/include/asm/thread_info.h]
#define init_thread_info (init_thread_union.thread_info)
#define init_stack (init_thread_union.stack)其中init_thread_union被定义在init/init_task.c
union thread_union init_thread_union __init_task_data =
{ INIT_THREAD_INFO(init_task) };init_task是用INIT_THREAD_INFO宏进行初始化的, 这个才是我们真正体系结构相关的部分
[arch/x86/include/asm/thread_info.h]
#define INIT_THREAD_INFO(tsk) \
{ \
.task = &tsk, \
.flags = 0, \
.cpu = 0, \
.addr_limit = KERNEL_DS, \
}init_thread_info定义中的__init_task_data表明该内核栈所在的区域位于内核映像的init data区,我们可以通过编译完内核后所产生的System.map来看到该变量及其对应的逻辑地址
8.1.3 进程内存空间
由于init_task是一个运行在内核空间的内核线程,因此其虚地址段mm为NULL,但是必要时他还是需要使用虚拟地址的,因此avtive_mm被设置为init_mm
.mm = NULL, \
.active_mm = &init_mm, \[mm/init-mm.c]
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
INIT_MM_CONTEXT(init_mm)
};8.1.4 0号进程的演化
8.1.4.1 rest_init创建init进程(PID=1)和kthread进程(PID=2)
在vmlinux的入口startup_32(head.S)中为pid号为0的原始进程设置了执行环境,然后原始进程开始执行start_kernel()完成Linux内核的初始化工作。包括初始化页表,初始化中断向量表,初始化系统时间等。
从rest_init开始,Linux开始产生进程,因为init_task是静态制造出来的,pid=0,它试图将从最早的汇编代码一直到start_kernel的执行都纳入到init_task进程上下文中。
这个函数其实是由0号进程执行的, 就是在这个函数中, 创建了init进程和kthreadd进程
start_kernel最后一个函数调用rest_init
[init/main.c]
static noinline void __init_refok rest_init(void)
{
int pid;
rcu_scheduler_starting();
smpboot_thread_init();
kernel_thread(kernel_init, NULL, CLONE_FS);
numa_default_policy();
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
complete(&kthreadd_done);
init_idle_bootup_task(current);
schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */
cpu_startup_entry(CPUHP_ONLINE);
}-
调用kernel_thread()创建1号内核线程, 该线程随后转向用户空间, 演变为init进程
-
调用kernel_thread()创建kthreadd内核线程, pid=2。
-
init_idle_bootup_task():当前0号进程init_task最终会退化成idle进程,所以这里调用init_idle_bootup_task()函数,让init_task进程隶属到idle调度类中。即选择idle的调度相关函数。
-
调用schedule()函数切换当前进程,在调用该函数之前,Linux系统中只有两个进程,即0号进程init_task和1号进程kernel_init,其中kernel_init进程也是刚刚被创建的。调用该函数后,1号进程kernel_init将会运行!!!, 后续初始化都是使用该进程
-
调用cpu_idle(),0号线程进入idle函数的循环,在该循环中会周期性地检查。
8.1.4.1.1 创建kernel_init
产生第一个真正的进程(pid=1)
kernel_thread(kernel_init, NULL, CLONE_FS);8.1.4.1.2 创建kthreadd
在rest_init函数中,内核将通过下面的代码产生第一个kthreadd(pid=2)
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);8.1.4.2 0号进程演变为idle
init_idle_bootup_task(current);
schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */
cpu_startup_entry(CPUHP_ONLINE);因此我们回过头来看pid=0的进程,在创建了init进程后,pid=0的进程调用cpu_idle()演变成了idle进程。
0号进程首先执行init_idle_bootup_task, 让init_task进程隶属到idle调度类中。即选择idle的调度相关函数。
void init_idle_bootup_task(struct task_struct *idle)
{
idle->sched_class = &idle_sched_class;
}接着通过schedule_preempt_disabled来执行调用schedule()函数切换当前进程,在调用该函数之前,Linux系统中只有两个进程,即0号进程init_task和1号进程kernel_init,其中kernel_init进程也是刚刚被创建的。调用该函数后,1号进程kernel_init将会运行
void __sched schedule_preempt_disabled(void)
{
sched_preempt_enable_no_resched();
schedule();
preempt_disable();
}最后cpu_startup_entry调用cpu_idle_loop(),0号线程进入idle函数的循环,在该循环中会周期性地检查
void cpu_startup_entry(enum cpuhp_state state)
{
#ifdef CONFIG_X86
boot_init_stack_canary();
#endif
arch_cpu_idle_prepare();
cpu_idle_loop();
}其中cpu_idle_loop就是idle进程的事件循环,定义在kernel/sched/idle.c
整个过程简单的说就是,原始进程(pid=0)创建init进程(pid=1),然后演化成idle进程(pid=0)。init进程为每个从处理器(运行队列)创建出一个idle进程(pid=0),然后演化成/sbin/init。
8.1.5 idle的运行与调度
8.1.5.1 idle的workload--cpu_idle_loop
idle在系统没有其他就绪的进程可执行的时候才会被调度。不管是主处理器,还是从处理器,最后都是执行的cpu_idle_loop()函数
idle进程中并不执行什么有意义的任务,所以通常考虑的是两点
-
节能
-
低退出延迟。
[kernel/sched/idle.c]
static void cpu_idle_loop(void)
{
while (1) {
__current_set_polling();
quiet_vmstat();
tick_nohz_idle_enter();
while (!need_resched()) {
check_pgt_cache();
rmb();
if (cpu_is_offline(smp_processor_id())) {
rcu_cpu_notify(NULL, CPU_DYING_IDLE,
(void *)(long)smp_processor_id());
smp_mb(); /* all activity before dead. */
this_cpu_write(cpu_dead_idle, true);
arch_cpu_idle_dead();
}
local_irq_disable();
arch_cpu_idle_enter();
if (cpu_idle_force_poll || tick_check_broadcast_expired())
cpu_idle_poll();
else
cpuidle_idle_call();
arch_cpu_idle_exit();
}
preempt_set_need_resched();
tick_nohz_idle_exit();
__current_clr_polling();
smp_mb__after_atomic();
sched_ttwu_pending();
schedule_preempt_disabled();
}
}循环判断need_resched以降低退出延迟,用idle()来节能。
默认的idle实现是hlt指令,hlt指令使CPU处于暂停状态,等待硬件中断发生的时候恢复,从而达到节能的目的。即从处理器C0态变到C1态(见ACPI标准)。这也是早些年windows平台上各种"处理器降温"工具的主要手段。当然idle也可以是在别的ACPI或者APM模块中定义的,甚至是自定义的一个idle(比如说nop)。
-
idle是一个进程,其pid为0。
-
主处理器上的idle由原始进程(pid=0)演变而来。从处理器上的idle由init进程fork得到,但是它们的pid都为0。
-
idle进程为最低优先级,且不参与调度,只是在运行队列为空的时候才被调度。
-
idle循环等待need_resched置位。默认使用hlt节能。
8.1.5.2 idle的运行时机
idle进程优先级为MAX_PRIO - 20。早先版本中,idle是参与调度的,所以将其优先级设低点,当没有其他进程可以运行时,才会调度执行idle。而目前的版本中idle并不在运行队列中参与调度,而是在运行队列结构中含idle指针,指向idle进程,在调度器发现运行队列为空的时候运行,调入运行
inux进程的调度顺序是按照rt实时进程(rt调度器),normal普通进程(cfs调度器),和idle的顺序来调度的
那么可以试想如果rt和cfs都没有可以运行的任务,那么idle才可以被调度,那么他是通过怎样的方式实现的呢?
在normal的调度类,cfs公平调度器sched_fair.c中
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,也就是说,如果系统中没有普通进程,那么会选择下个调度类优先级的进程,即使用idle_sched_class调度类进行调度的进程
当系统空闲的时候,最后就是调用idle的pick_next_task函数,被定义在/kernel/sched/idle_task.c中
static struct task_struct *pick_next_task_idle(struct rq *rq)
{
schedstat_inc(rq, sched_goidle);
calc_load_account_idle(rq);
return rq->idle; //可以看到就是返回rq中idle进程。
}这idle进程在启动start_kernel函数的时候调用init_idle函数的时候,把当前进程(0号进程)置为每个rq运行队列的的idle上。
rq->curr = rq->idle = idle;
这里idle就是调用start_kernel函数的进程,就是0号进程。
8.2 1号init进程
8.2.1 执行函数kernel_init()
0号进程创建1号进程的方式如下
kernel_thread(kernel_init, NULL, CLONE_FS);1号进程的执行函数就是kernel_init, kernel_init函数将完成设备驱动程序的初始化, 并调用init_post函数启动用户空间的init进程。
[init/main.c]
static int __ref kernel_init(void *unused)
{
int ret;
// 完成初始化工作,准备文件系统,准备模块信息
kernel_init_freeable();
/* need to finish all async __init code before freeing the memory */
// 用以同步所有非同步函式呼叫的执行, 加速Linux Kernel开机的效率
async_synchronize_full();
free_initmem();
mark_rodata_ro();
// 设置运行状态SYSTEM_RUNNING
system_state = SYSTEM_RUNNING;
numa_default_policy();
flush_delayed_fput();
rcu_end_inkernel_boot();
if (ramdisk_execute_command) {
ret = run_init_process(ramdisk_execute_command);
if (!ret)
return 0;
pr_err("Failed to execute %s (error %d)\n",
ramdisk_execute_command, ret);
}
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/init.txt for guidance.");
}| 执行流程 | 说明 |
|---|---|
| kernel_init_freeable | 调用kernel_init_freeable完成初始化工作,准备文件系统,准备模块信息 |
| async_synchronize_full | 用以同步所有非同步函式呼叫的执行, 主要设计用来加速Linux Kernel开机的效率,避免在开机流程中等待硬体反应延迟,影响到开机完成的时间 |
| free_initmem | 释放Linux Kernel介于__init_begin到 __init_end属于init Section的函数的所有内存.并会把Page个数加到变量totalram_pages中 |
| system_state | 设置运行状态SYSTEM_RUNNING |
| 加载init进程,进入用户空间 | a,如果ramdisk_execute_command不为0,就执行该命令成为init User Process. b,如果execute_command不为0,就执行该命令成为init User Process. c,如果上述都不成立,就依序执行如下指令 run_init_process(“/sbin/init”); run_init_process(“/etc/init”); run_init_process(“/bin/init”); run_init_process(“/bin/sh”); 也就是说会按照顺序从/sbin/init, /etc/init, /bin/init 与 /bin/sh依序执行第一个 init User Process. 如果都找不到可以执行的 init Process,就会进入Kernel Panic.如下所示panic(“No init found. Try passing init= option to kernel. ”“See Linux Documentation/init.txt for guidance.”); |
由0号进程创建1号进程(内核态),1号内核线程负责执行内核的部分初始化工作及进行系统配置(包括启动AP),并创建若干个用于高速缓存和虚拟主存管理的内核线程。
随后,内核1号进程就会在/sbin, /etc, /bin寻找init程序, 调用do_execve()运行可执行程序init,并演变成用户态1号进程,即init进程。这个过程并没有使用调用do_fork(),因此两个进程都是1号进程。
该init程序会替换kernel_init进程(注意:并不是创建一个新的进程来运行init程序,而是一次变身,使用sys_execve函数改变核心进程的正文段,将核心进程kernel_init转换成用户进程init),此时处于内核态的1号kernel_init进程将会转换为用户空间内的1号进程init。
init进程是linux内核启动的第一个用户级进程。init有许多很重要的任务,比如像启动getty(用于用户登录)、实现运行级别、以及处理孤立进程。
它按照配置文件/etc/initab的要求,完成系统启动工作,创建编号为1号、2号...的若干终端注册进程getty。
每个getty进程设置其进程组标识号,并监视配置到系统终端的接口线路。当检测到来自终端的连接信号时,getty进程将通过函数do_execve()执行注册程序login,此时用户就可输入注册名和密码进入登录过程,如果成功,由login程序再通过函数execv()执行/bin/shell,该shell进程接收getty进程的pid,取代原来的getty进程。再由shell直接或间接地产生其他进程。
用户进程init将根据/etc/inittab中提供的信息完成应用程序的初始化调用。然后init进程会执行/bin/sh产生shell界面提供给用户来与Linux系统进行交互。
上述过程可描述为:0号进程->1号内核进程->1号用户进程(init进程)->getty进程->shell进程
在系统完全起来之后,init为每个用户已退出的终端重启getty(这样下一个用户就可以登录)。init同样也收集孤立的进程:当一个进程启动了一个子进程并且在子进程之前终止了,这个子进程立刻成为init的子进程。
8.2.2 关于init程序
init的最适当的位置(在Linux系统上)是/sbin/init。如果内核没有找到init,它就会试着运行/bin/sh,如果还是失败了,那么系统的启动就宣告失败了。
通过rpm -qf查看系统程序所在的包, 目前系统的包是systemd.
8.3 2号kthreadd进程
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);所有其它的内核线程的ppid都是2,也就是说它们都是由kthreadd thread创建的
所有的内核线程在大部分时间里都处于阻塞状态(TASK_INTERRUPTIBLE)只有在系统满足进程需要的某种资源的情况下才会运行
它的任务就是管理和调度其他内核线程kernel_thread,会循环执行一个kthread的函数,该函数的作用就是运行kthread_create_list全局链表中维护的kthread,当我们调用kernel_thread创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程
8.3.1 执行函数kthreadd()
[kernel/kthread.c]
int kthreadd(void *unused)
{
struct task_struct *tsk = current;
/* Setup a clean context for our children to inherit. */
set_task_comm(tsk, "kthreadd");
ignore_signals(tsk);
// 允许kthreadd在任意CPU上运行
set_cpus_allowed_ptr(tsk, cpu_all_mask);
set_mems_allowed(node_states[N_MEMORY]);
current->flags |= PF_NOFREEZE;
for (;;) {
// 首先将线程状态设置为TASK_INTERRUPTIBLE,
// 如果当前没有要创建的线程则主动放弃CPU完成调度.此进程变为阻塞态
set_current_state(TASK_INTERRUPTIBLE);
// 没有需要创建的内核线程
if (list_empty(&kthread_create_list))
// 什么也不做, 执行一次调度, 让出CPU
schedule();
// 运行到此表示kthreadd线程被唤醒(就是我们当前)
// 设置进程运行状态为 TASK_RUNNING
__set_current_state(TASK_RUNNING);
// 加锁,
spin_lock(&kthread_create_lock);
while (!list_empty(&kthread_create_list)) {
struct kthread_create_info *create;
// 从链表中取得 kthread_create_info
// 结构的地址,在上文中已经完成插入操作(将
// kthread_create_info 结构中的 list
// 成员加到链表中,此时根据成员 list 的偏移获得 create)
create = list_entry(kthread_create_list.next,
struct kthread_create_info, list);
/* 完成穿件后将其从链表中删除 */
list_del_init(&create->list);
/* 完成真正线程的创建 */
spin_unlock(&kthread_create_lock);
create_kthread(create);
spin_lock(&kthread_create_lock);
}
spin_unlock(&kthread_create_lock);
}
return 0;
}kthreadd的核心是for和while循环体。
在for循环中,如果发现kthread_create_list是一空链表(!!!),则调用schedule调度函数,因为此前已经将该进程的状态设置为TASK_INTERRUPTIBLE,所以schedule的调用将会使当前进程进入睡眠(会将进程从CPU运行队列中移除,可以通过显式的唤醒呼叫wakeup_process()或需要处理的信号来唤醒它)。
如果kthread_create_list不为空,则进入while循环,在该循环体中会遍历该kthread_create_list列表,对于该列表上的每一个entry,都会得到对应的类型为struct kthread_create_info的节点的指针create.
然后函数在kthread_create_list中删除create对应的列表entry,接下来以create指针为参数调用create_kthread(create).
完成了进程的创建后继续循环,检查kthread_create_list链表,如果为空,则 kthreadd 内核线程昏睡过去
我们在内核中通过kernel_create或者其他方式创建一个内核线程, 然后kthreadd内核线程被唤醒, 来执行内核线程创建的真正工作, 于是这里有三个线程
-
kthreadd进程已经光荣完成使命(接手执行真正的创建工作),睡眠
-
唤醒kthreadd的线程(!!!不是kthreadd线程本身!!!)由于新创建的线程还没有创建完毕而继续睡眠(在kthread_create函数中)
-
新创建的线程已经正在运行kthread()函数,但是由于还有其它工作没有做所以还没有最终创建完成.
8.3.1.1 create_kthread(struct kthread_create_info)完成内核线程创建
[kernel/kthread.c]
static void create_kthread(struct kthread_create_info *create)
{
int pid;
#ifdef CONFIG_NUMA
current->pref_node_fork = create->node;
#endif
/* We want our own signal handler (we take no signals by default). */
// 其实就是调用首先构造一个假的上下文执行环境,
// 最后调用do_fork()返回进程 id, 创建后的线程执行 kthread 函数
pid = kernel_thread(kthread, create, CLONE_FS | CLONE_FILES | SIGCHLD);
if (pid < 0) {
/* If user was SIGKILLed, I release the structure. */
struct completion *done = xchg(&create->done, NULL);
if (!done) {
kfree(create);
return;
}
create->result = ERR_PTR(pid);
complete(done);
}
}里面会调用kernel_thread来生成一个新的进程,该进程的内核函数为kthread,调用参数为
pid = kernel_thread(kthread, create, CLONE_FS | CLONE_FILES | SIGCHLD);
创建的内核线程执行的函数是kthread()
8.3.2 新创建的内核线程执行函数kthread()
static int kthread(void *_create)
{
/* Copy data: it's on kthread's stack
create 指向 kthread_create_info 中的 kthread_create_info */
struct kthread_create_info *create = _create;
/* 新的线程创建完毕后执行的函数 */
int (*threadfn)(void *data) = create->threadfn;
/* 新的线程执行的参数 */
void *data = create->data;
struct completion *done;
struct kthread self;
int ret;
self.flags = 0;
self.data = data;
init_completion(&self.exited);
init_completion(&self.parked);
current->vfork_done = &self.exited;
/* If user was SIGKILLed, I release the structure. */
done = xchg(&create->done, NULL);
if (!done) {
kfree(create);
do_exit(-EINTR);
}
/* OK, tell user we're spawned, wait for stop or wakeup
设置运行状态为 TASK_UNINTERRUPTIBLE */
__set_current_state(TASK_UNINTERRUPTIBLE);
/* current 表示当前新创建的 thread 的 task_struct 结构 */
create->result = current;
complete(done);
/* 至此线程创建完毕, 执行任务切换,让出 CPU */
schedule();
ret = -EINTR;
if (!test_bit(KTHREAD_SHOULD_STOP, &self.flags)) {
__kthread_parkme(&self);
ret = threadfn(data);
}
/* we can't just return, we must preserve "self" on stack */
do_exit(ret);
}线程创建完毕:
-
创建新thread的进程(原进程)恢复运行kthread_create()并且返回新创建线程的任务描述符
-
新创建的线程由于执行了schedule()调度,此时并没有执行(!!!).
直到我们手动使用wake_up_process(p)唤醒新创建的线程
-
线程被唤醒后, 会接着执行threadfn(data)
-
得到执行结果, 将结果(整型类型)作为参数调用do_exit()函数
8.3.3 小结
-
任何一个内核线程入口都是kthread()
-
通过kthread_create()创建的内核线程不会立刻运行.需要手工wake up
-
通过kthread_create()创建的内核线程有可能不会执行相应线程函数threadfn而直接退出(!!!)
9 用户空间创建进程/线程的三种方法
| 系统调用 | 描述 |
|---|---|
| fork | fork创造的子进程是父进程的完整副本,复制了父亲进程的资源,包括内存的task_struct内容 |
| vfork | vfork创建的子进程与父进程共享数据段(数据段!!!),而且由vfork()创建的子进程将先于父进程运行 |
| clone | Linux上创建线程一般使用的是pthread库.实际上linux也给我们提供了创建线程的系统调用,就是clone |
fork, vfork和clone的系统调用的入口地址分别是sys_fork(),sys_vfork()和sys_clone(), 而他们的定义是依赖于体系结构的, 因为在用户空间和内核空间之间传递参数的方法因体系结构而异
9.1 系统调用的参数传递
由于系统调用是通过中断进程从用户态到内核态的一种特殊的函数调用,没有用户态或者内核态的堆栈(!!!)可以被用来在调用函数和被调函数之间进行参数传递。
系统调用通过CPU的寄存器来进行参数传递。在进行系统调用之前,系统调用的参数被写入CPU的寄存器,而在实际调用系统服务例程之前,内核将CPU寄存器的内容拷贝到内核堆栈中,实现参数的传递。
上面函数的任务就是从处理器的寄存器中提取用户空间提供的信息,并调用体系结构无关的_do_fork(或者早期的do_fork)函数,负责进程的复制
Linux有一个TLS(Thread Local Storage)机制,clone的标识CLONE_SETTLS接受一个参数来设置线程的本地存储区。
sys_clone也因此增加了一个int参数来传入相应的tls_val。sys_clone通过do_fork来调用copy_process完成进程的复制,它调用特定的copy_thread和copy_thread把相应的系统调用参数从pt_regs寄存器列表中提取出来,这个参数仍然是体系结构相关的.
所以Linux引入一个新的CONFIG_HAVE_COPY_THREAD_TLS,和一个新的COPY_THREAD_TLS接受TLS参数为额外的长整型(系统调用参数大小)的争论。改变sys_clone的TLS参数unsigned long,并传递到copy_thread_tls。
[include/linux/sched.h]
extern long _do_fork(unsigned long, unsigned long, unsigned long, int __user *, int __user *, unsigned long);
extern long do_fork(unsigned long, unsigned long, unsigned long, int __user *, int __user *);
#ifndef CONFIG_HAVE_COPY_THREAD_TLS
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
return _do_fork(clone_flags, stack_start, stack_size,
parent_tidptr, child_tidptr, 0);
}
#endif新版本的系统中clone的TLS设置标识会通过TLS参数传递,因此_do_fork替代了老版本的do_fork。
老版本的do_fork只有在如下情况才会定义
-
只有当系统不支持通过TLS参数传递而是使用pt_regs寄存器列表传递时
-
未定义CONFIG_HAVE_COPY_THREAD_TLS宏
| 参数 | 描述 |
|---|---|
| clone_flags | 与clone()参数flags相同,用来控制进程复制过的一些属性信息,描述你需要从父进程继承哪些资源。该标志位的4个字节分为两部分。最低的一个字节为子进程结束时发送给父进程的信号代码,通常为SIGCHLD;剩余的三个字节则是各种clone标志的组合(本文所涉及的标志含义详见下表),也就是若干个标志之间的或运算。通过clone标志可以有选择的对父进程的资源进行复制; |
| stack_start | 与clone()参数stack_start相同, 子进程用户态(!!!)堆栈的地址 |
| regs | 是一个指向了寄存器集合的指针,其中以原始形式,保存了调用的参数,该参数使用的数据类型是特定体系结构的struct pt_regs,其中按照系统调用执行时寄存器在内核栈上的存储顺序,保存了所有的寄存器,即指向内核态堆栈通用寄存器值的指针,通用寄存器的值是在从用户态切换到内核态时被保存到内核态堆栈中的(指向pt_regs结构体的指针。当系统发生系统调用,即用户进程从用户态切换到内核态时,该结构体保存通用寄存器中的值,并被存放于内核态的堆栈中) |
| stack_size | 用户状态下栈的大小, 该参数通常是不必要的, 总被设置为0 |
| parent_tidptr | 与clone的ptid参数相同,父进程在用户态下pid的地址,该参数在CLONE_PARENT_SETTID标志被设定时有意义 |
| child_tidptr | 与clone的ctid参数相同,子进程在用户态下pid的地址,该参数在CLONE_CHILD_SETTID标志被设定时有意义 |
clone_flags如下表所示
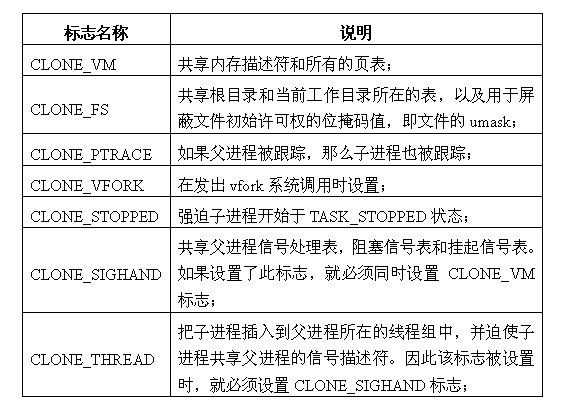
9.2 sys_fork的实现
早期实现
asmlinkage long sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.rsp, ®s, 0);
}
新版本实现
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
#else
return -EINVAL;
#endif
}
#endif-
唯一使用的标志是SIGCHLD。这意味着在子进程终止后将发送信号SIGCHLD信号通知父进程
-
写时复制(COW)技术, 最初父子进程的栈地址相同, 但是如果操作栈地址并写入数据, 则COW机制会为每个进程分别创建一个新的栈副本
-
如果do_fork成功, 则新建进程的pid作为系统调用的结果返回, 否则返回错误码
9.3 sys_vfork的实现
早期实现
asmlinkage long sys_vfork(struct pt_regs regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs.rsp, ®s, 0);
}
新实现
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
return _do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL, 0);
}
#endif相较于sys_vfork, 多使用了额外的标志CLONE_VFORK | CLONE_VM
9.4 sys_clone的实现
早期实现
casmlinkage int sys_clone(struct pt_regs regs)
{
/* 注释中是i385下增加的代码, 其他体系结构无此定义
unsigned long clone_flags;
unsigned long newsp;
clone_flags = regs.ebx;
newsp = regs.ecx;*/
if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags, newsp, ®s, 0);
}
新版本
#ifdef __ARCH_WANT_SYS_CLONE
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
unsigned long, tls,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#endif
{
return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls);
}
#endifsys_clone的标识不再是硬编码的,而是通过各个寄存器参数传递到系统调用, clone也不再复制进程的栈,而是可以指定新的栈地址,在生成线程时,可能需要这样做,线程可能与父进程共享地址空间,但是线程自身的栈可能在另外一个地址空间
另外还指令了用户空间的两个指针(parent_tidptr和child_tidptr), 用于与线程库通信
10 创建子进程流程
_do_fork和do_fork在进程的复制的时候并没有太大的区别,他们就只是在进程tls复制的过程中实现有细微差别
10.1 _do_fork的流程
所有进程复制(创建)的fork机制最终都调用了kernel/fork.c中的_do_fork(一个体系结构无关的函数)
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
/* 复制进程描述符,copy_process()的返回值是一个 task_struct 指针 */
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
/* 得到新创建的进程的pid信息 */
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
/* 如果调用的 vfork()方法,初始化 vfork 完成处理信息 */
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
/* 将子进程加入到调度器中,为其分配 CPU,准备执行 */
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
/* 如果设置了 CLONE_VFORK 则将父进程插入等待队列,
并挂起父进程直到子进程释放自己的内存空间
*/
/* 如果是 vfork,将父进程加入至等待队列,等待子进程完成 */
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}-
调用copy_process为子进程复制出一份进程信息
-
如果是vfork(设置了CLONE_VFORK和ptrace标志)初始化完成处理信息
-
调用wake_up_new_task()将子进程加入调度器,为之分配CPU. 计算此进程的优先级和其他调度参数,将新的进程加入到进程调度队列并设此进程为可被调度的,以后这个进程可以被进程调度模块调度执行。
-
如果是vfork,父进程等待子进程完成exec替换自己的地址空间
10.2 copy_process流程
fork的大部分事情,它主要完成讲父进程的运行环境复制到新的子进程,比如信号处理、文件描述符和进程的代码数据等。
-
dup_task_struct()复制当前的task_struct, 并为其分配了新的堆栈.分配一个新的进程控制块,包括新进程在kernel中的堆栈。新的进程控制块会复制父进程的进程控制块,但是因为每个进程都有一个kernel堆栈,新进程的堆栈将被设置成新分配的堆栈
-
检查进程数是否超过限制,两个因素:操作系统和内存大小
-
初始化自旋锁、挂起信号、CPU定时器等
-
调用sched_fork()初始化进程数据结构,并把进程状态设置为TASK_RUNNING. 设置子进程调度相关的参数,即子进程的运行CPU、初始时间片长度和静态优先级等
-
copy_semundo()复制父进程的semaphore undo_list到子进程
-
copy_files()、copy_fs()复制父进程文件系统相关的环境到子进程
-
copy_sighand()、copy_signal()复制父进程信号处理相关的环境到子进程
-
copy_mm()复制父进程内存管理相关的环境到子进程,包括页表、地址空间和代码数据
-
copy_thread_tls()中将父进程的寄存器上下文复制给子进程,保证了父子进程的堆栈信息是一致的. 设置子进程的执行环境,如子进程运行时各CPU寄存器的值、子进程的kernel栈的起始地址
-
将ret_from_fork的地址设置为eip寄存器的值
-
为新进程分配并设置新的pid
-
将子进程加入到全局的进程队列中
-
设置子进程的进程组ID和对话期ID等
-
最终子进程从**ret_from_fork!!!**开始执行
简单的说,copy_process()就是将父进程的运行环境复制到子进程并对某些子进程特定的环境做相应的调整。
10.2.1 dup_task_struct()产生新的task_struct
-
调用alloc_task_struct_node分配一个task_struct节点
-
调用alloc_thread_info_node分配一个thread_info节点,其实是分配了一个thread_union联合体,将栈底返回给ti
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};-
最后将栈底的值ti赋值给新节点的栈
-
最终执行完dup_task_struct之后,子进程除了tsk->stack指针不同之外,全部都一样!
10.2.2 sched_fork()流程
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
int cpu = get_cpu();
__sched_fork(clone_flags, p);
// 将子进程状态设置为 TASK_RUNNING
p->state = TASK_RUNNING;
p->prio = current->normal_prio;
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = __normal_prio(p);
set_load_weight(p);
p->sched_reset_on_fork = 0;
}
if (dl_prio(p->prio)) {
put_cpu();
return -EAGAIN;
} else if (rt_prio(p->prio)) {
p->sched_class = &rt_sched_class;
} else {
p->sched_class = &fair_sched_class;
}
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
// 为子进程分配 CPU
set_task_cpu(p, cpu);
put_cpu();
return 0;
}我们可以看到sched_fork大致完成了两项重要工作,后续会详细说明
-
一是将子进程状态设置为TASK_RUNNING, 并设置调度相关字段
-
二是为其分配CPU
10.2.3 copy_thread和copy_thread_tls流程
如果未定义CONFIG_HAVE_COPY_THREAD_TLS宏默认则使用copy_thread同时将定义copy_thread_tls为copy_thread
单独这个函数是因为这个复制操作与其他操作都不相同,这是一个特定于体系结构的函数,用于复制进程中特定于线程(thread-special)的数据,重要的就是填充task_struct->thread的各个成员,这是一个thread_struct类型的结构, 其定义是依赖于体系结构的。它包含了所有寄存器(和其他信息!!!所有寄存器信息在thread里面!!!),内核在进程之间切换时需要保存和恢复的进程的信息。
该函数用于设置子进程的执行环境,如子进程运行时各CPU寄存器的值、子进程的内核栈的起始地址(指向内核栈的指针通常也是保存在一个特别保留的寄存器中)
32位架构的copy_thread_tls函数
[arch/x86/kernel/process_32.c]
int copy_thread_tls(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p, unsigned long tls)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
/* 获取寄存器的信息 */
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread 内核线程的设置 */
memset(childregs, 0, sizeof(struct pt_regs));
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
/* 将当前寄存器信息复制给子进程 */
*childregs = *current_pt_regs();
/* 子进程 eax 置 0,因此fork 在子进程返回0 */
childregs->ax = 0;
if (sp)
childregs->sp = sp;
/* 子进程ip设置为ret_from_fork,因此子进程从ret_from_fork开始执行 */
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
p->thread.io_bitmap_ptr = NULL;
tsk = current;
err = -ENOMEM;
if (unlikely(test_tsk_thread_flag(tsk, TIF_IO_BITMAP))) {
p->thread.io_bitmap_ptr = kmemdup(tsk->thread.io_bitmap_ptr,
IO_BITMAP_BYTES, GFP_KERNEL);
if (!p->thread.io_bitmap_ptr) {
p->thread.io_bitmap_max = 0;
return -ENOMEM;
}
set_tsk_thread_flag(p, TIF_IO_BITMAP);
}
err = 0;
/* 为进程设置一个新的TLS */
if (clone_flags & CLONE_SETTLS)
err = do_set_thread_area(p, -1,
(struct user_desc __user *)tls, 0);
if (err && p->thread.io_bitmap_ptr) {
kfree(p->thread.io_bitmap_ptr);
p->thread.io_bitmap_max = 0;
}
return err;
}这里解释了两个相当重要的问题!
一是,为什么fork在子进程中返回0!!!,原因是childregs->ax = 0;这段代码将子进程的 eax 赋值为0!!!
二是,p->thread.ip = (unsigned long) ret_from_fork;将子进程的 ip 设置为 ret_form_fork 的首地址,因此子进程是从ret_from_fork 开始执行的!!!
11 用户程序结束进程
应用程序使用系统调用exit()来结束一个进程,此系统调用接受一个退出原因代码,父进程可以使用wait()系统调用来获取此退出代码,从而知道子进程退出的原因。
对应到kernel,此系统调用sys_exit_group(),它的基本流程如下:
-
将信号SIGKILL加入到其他线程的信号队列中,并唤醒这些线程。
-
此线程执行do_exit()来退出。
do_exit()完成线程退出的任务,其主要功能是将线程占用的系统资源释放,do_exit()的基本流程如下:
-
将进程内存管理相关的资源释放
-
将进程ICP semaphore相关资源释放
-
__exit_files()、__exit_fs()将进程文件管理相关的资源释放。
-
exit_thread()只要目的是释放平台相关的一些资源。
-
exit_notify()在Linux中进程退出时要将其退出的原因告诉父进程,父进程调用wait()系统调用后会在一个等待队列上睡眠。
-
schedule()调用进程调度器,因为此进程已经退出,切换到其他进程。
12 进程状态变化过程
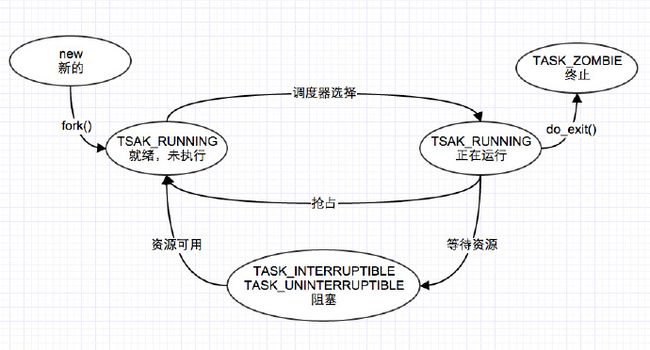
进程的创建到执行过程如下图所示
13 内核线程
内核线程就是内核的分身,一个分身可以处理一件特定事情。内核线程的调度由内核负责,一个内核线程处于阻塞状态时不影响其他的内核线程,因为其是调度的基本单位。
内核线程只运行在内核态
因此,它只能使用大于PAGE_OFFSET(传统的x86_32上是3G)的地址空间(!!!)。
13.1 概述
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,它与内核中的其他进程"并行"执行。内核线程经常被称之为内核守护进程。
他们执行下列任务
-
周期性地将修改的内存页与页来源块设备同步
-
如果内存页很少使用,则写入交换区
-
管理延时动作, 如2号进程接手内核进程的创建
-
实现文件系统的事务日志
内核线程主要有两种类型
-
线程启动后一直等待,直至内核请求线程执行某一特定操作。
-
线程启动后按周期性间隔运行,检测特定资源的使用,在用量超出或低于预置的限制时采取行动。
内核线程由内核自身生成,其特点在于
-
它们在CPU的管态执行,而不是用户态。
-
它们只可以访问虚拟地址空间的内核部分(高于TASK_SIZE的所有地址),但不能访问用户空间
内核线程和普通的进程间的区别在于内核线程没有独立的地址空间,mm指针被设置为NULL;它只在内核空间运行,从来不切换到用户空间去;并且和普通进程一样,可以被调度,也可以被抢占。
13.2 内核线程的创建
13.2.1 创建内核线程接口
内核线程可以通过两种方式实现:
- kernel_thread和daemonize
将一个函数传递给kernel_thread创建并初始化一个task,该函数接下来负责帮助内核调用daemonize已转换为内核守护进程
- kthead_create和kthread_run
创建内核更常用的方法是辅助函数kthread_create,该函数创建一个新的内核线程。最初线程是停止的,需要使用wake_up_process启动它。
使用kthread_run,与kthread_create不同的是,其创建新线程后立即唤醒它,其本质就是先用kthread_create创建一个内核线程,然后通过wake_up_process唤醒它
13.2.2 2号进程kthreadd
见前面2号进程的创建.
参见kthreadd函数, 它会循环的是查询工作链表static LIST_HEAD(kthread_create_list)中是否有需要被创建的内核线程
我们的通过kthread_create执行的操作, 只是在内核线程任务队列kthread_create_list中增加了一个create任务, 然后会唤醒kthreadd进程来执行真正的创建操作
内核线程会出现在系统进程列表中,但是在ps的输出中进程名command由方括号包围, 以便与普通进程区分。
如下图所示, 我们可以看到系统中,所有内核线程都用[]标识,而且这些进程父进程id均是2, 而2号进程kthreadd的父进程是0号进程

13.2.3 kernel_thread()创建内核线程
kernel_thread()的实现经历过很多变革
早期的kernel_thread()执行更底层的操作, 直接创建了task_struct并进行初始化,
引入了kthread_create和kthreadd 2号进程后, kernel_thread()的实现也由统一的_do_fork(或者早期的do_fork)托管实现
14 可执行程序的加载和运行
fork, vfork等复制出来的进程是父进程的一个副本, 那么如何我们想加载新的程序, 可以通过execve系统调用来加载和启动新的程序。
在Linux中提供了一系列的函数,这些函数能用可执行文件所描述的新上下文代替进程的上下文。这样的函数名以前缀exec开始。所有的exec函数都是调用了execve()系统调用。
14.1 exec()函数族
exec函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)都是调用execve的库函数。
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg,
..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);14.2 可执行程序相关数据结构
Linux下标准的可执行文件格式是ELF. ELF(Executable and Linking Format)是一种对象文件的格式, 作为缺省的二进制文件格式来使用.
linux也支持其他不同的可执行程序格式, 各个可执行程序的执行方式不尽相同, 因此linux内核每种被注册的可执行程序格式都用linux_bin_fmt来存储, 其中记录了可执行程序的加载和执行函数
同时我们需要一种方法来保存可执行程序的信息,比如可执行文件的路径,运行的参数和环境变量等信息,即linux_binprm结构
14.2.1 struct linux_binprm结构描述一个可执行程序的信息
struct linux_binprm保存要执行的文件相关的信息, 包括可执行程序的路径, 参数和环境变量的信息
[include/linux/binfmts.h]
struct linux_binprm {
char buf[BINPRM_BUF_SIZE]; // 保存可执行文件的头128字节
#ifdef CONFIG_MMU
struct vm_area_struct *vma;
unsigned long vma_pages;
#else
# define MAX_ARG_PAGES 32
struct page *page[MAX_ARG_PAGES];
#endif
struct mm_struct *mm;
/* current top of mem , 当前内存页最高地址*/
unsigned long p;
unsigned int
cred_prepared:1,
cap_effective:1;
#ifdef __alpha__
unsigned int taso:1;
#endif
unsigned int recursion_depth;
/* 要执行的文件 */
struct file * file;
struct cred *cred; /* new credentials */
int unsafe;
unsigned int per_clear;
/* 命令行参数和环境变量数目 */
int argc, envc;
// 要执行的文件的名称
const char * filename;
// 要执行的文件的真实名称,通常和filename相同
const char * interp;
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
};14.2.2 struct linux_binfmt可执行格式的结构
linux内核对所支持的每种可执行的程序类型(!!!)都有个struct linux_binfmt的数据结构,定义如下
[include/linux/binfmts.h]
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
};其提供了3种方法来加载和执行可执行程序
- load_binary
通过读存放在可执行文件中的信息为当前进程建立一个新的执行环境
- load_shlib
用于动态的把一个共享库捆绑到一个已经在运行的进程, 这是由uselib()系统调用激活的
- core_dump
在名为core的文件中, 存放当前进程的执行上下文.这个文件通常是在进程接收到一个缺省操作为"dump"的信号时被创建的, 其格式取决于被执行程序的可执行类型
所有的linux_binfmt对象都处于一个链表中,第一个元素的地址存放在formats变量!!!中,可以通过调用register_binfmt()和unregister_binfmt()函数在链表中插入和删除元素,在系统启动期间,为每个编译进内核的可执行格式都执行registre_fmt()函数.当实现了一个新的可执行格式的模块正被装载时,也执行这个函数,当模块被卸载时, 执行unregister_binfmt()函数.
当我们执行一个可执行程序的时候,内核会list_for_each_entry遍历所有注册的linux_binfmt对象,对其调用load_binrary方法来尝试加载, 直到加载成功为止.
14.3 execve加载可执行程序的过程
内核中实际执行execv()或execve()系统调用的程序是do_execve()
这个函数先打开目标映像文件,
并从目标文件的头部(第一个字节开始)读入若干(当前Linux内核中是128)字节(实际上就是填充ELF文件头,下面的分析可以看到),
然后调用另一个函数search_binary_handler(),在此函数里面,它会搜索我们上面提到的Linux支持的可执行文件类型队列,让各种可执行程序的处理程序前来认领和处理。
在每种可执行文件类型中, 调用load_binary函数指针所指向的处理函数来处理目标映像文件。在ELF文件格式中,处理函数是load_elf_binary函数:
sys_execve() > do_execve() > do_execveat_common() > search_binary_handler() > load_elf_binary()
14.4 execve的入口函数sys_execve
| 描述 | 定义 | 链接 |
|---|---|---|
| 系统调用号(体系结构相关) | 类似与如下的形式 #define __NR_execve 117 __SYSCALL(117, sys_execve, 3) |
arch/对应体系结构/include/uapi/asm/unistd.h |
| 入口函数声明 | asmlinkage long sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp); | include/linux/syscalls.h |
| 系统调用实现 | SYSCALL_DEFINE3(execve, const char __user *, filename, const char __user *const __user *, argv, const char __user *const __user *, envp){ return do_execve(getname(filename), argv, envp); } |
fs/exec.c |
execve系统调用的的入口点是体系结构相关的sys_execve,该函数很快将工作委托给系统无关的do_execve()函数
[fs/exec.c]
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}| 参数 | 描述 |
|---|---|
| filename | 可执行程序的名称 |
| argv | 程序的参数字符串 |
| envp | 环境变量字符串 |
指向程序参数argv和环境变量envp两个数组的指针以及数组中所有的指针都位于虚拟地址空间的用户空间部分。因此内核在访问用户空间内存时,需要多加小心,而__user注释则允许自动化工具来检测时候所有相关事宜都处理得当
14.5 do_execve函数
-
早期linux-2.4中直接由do_execve实现程序的加载和运行
-
linux-3.18do_execve调用do_execve_common来完成程序的加载和运行
-
linux-3.19~至今引入execveat之后do_execve调用do_execveat_common来完成程序的加载和运行
在Linux中提供了一系列的函数,这些函数能用可执行文件所描述的新上下文代替进程的上下文。这样的函数名以前缀exec开始。所有的exec函数都是调用了execve()系统调用。
sys_execve是调用do_execve实现的。do_execve()则是调用do_execveat_common()实现的,在文件[fs/exec.c]中
依次执行以下操作:
-
调用unshare_files()为进程复制一份文件表
-
调用kzalloc()在堆上分配一份struct linux_binprm结构体
-
调用open_exec()查找并打开二进制文件
-
调用sched_exec()找到最小负载的CPU,用来执行该二进制文件
-
根据获取的信息,填充struct linux_binprm结构体中的file、filename、interp成员
-
调用bprm_mm_init()创建进程的内存地址空间,为新程序初始化内存管理.并调用init_new_context()检查当前进程是否使用自定义的局部描述符表;如果是,那么分配和准备一个新的LDT(!!!)
-
填充struct linux_binprm结构体中的argc、envc成员
-
调用prepare_binprm()检查该二进制文件的可执行权限;最后,kernel_read()读取二进制文件的头128字节(这些字节用于识别二进制文件的格式及其他信息,后续会使用到)
-
调用copy_strings_kernel()从内核空间获取二进制文件的路径名称
-
调用copy_string()从用户空间拷贝环境变量和命令行参数
-
至此,二进制文件已经被打开,struct linux_binprm结构体中也记录了重要信息
-
内核开始调用exec_binprm()识别该二进制文件的格式并执行可执行程序, 得到执行的返回结果retval
-
释放linux_binprm数据结构,返回从该文件可执行格式的load_binary中获得的代码
-
将执行结果retval返回
14.6 exec_binprm()识别并加载二进程程序
每种格式的二进制文件对应一个struct linux_binprm结构体,每种可执行的程序类型都对应一个数据结构struct linux_binfmt, 其中的load_binary成员负责识别该二进制文件的格式;
内核使用链表组织这些struct linux_binfmt结构体,链表头是formats。
接着do_execveat_common()中的exec_binprm()继续往下看:
[fs/exec.c]
static int exec_binprm(struct linux_binprm *bprm)
{
pid_t old_pid, old_vpid;
int ret;
/* Need to fetch pid before load_binary changes it */
old_pid = current->pid;
rcu_read_lock();
old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
ret = search_binary_handler(bprm);
if (ret >= 0) {
audit_bprm(bprm);
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
proc_exec_connector(current);
}
return ret;
}调用search_binary_handler()函数对linux_binprm的formats链表进行扫描,并尝试每个load_binary()函数,如果成功加载了文件的执行格式,对formats的扫描终止。
14.7 search_binary_handler()识别二进程程序
[include/linux/platform_data/simplefb.h]
#define SIMPLEFB_FORMATS \
{ \
{ "r5g6b5", 16, {11, 5}, {5, 6}, {0, 5}, {0, 0}, DRM_FORMAT_RGB565 }, \
{ "x1r5g5b5", 16, {10, 5}, {5, 5}, {0, 5}, {0, 0}, DRM_FORMAT_XRGB1555 }, \
{ "a1r5g5b5", 16, {10, 5}, {5, 5}, {0, 5}, {15, 1}, DRM_FORMAT_ARGB1555 }, \
{ "r8g8b8", 24, {16, 8}, {8, 8}, {0, 8}, {0, 0}, DRM_FORMAT_RGB888 }, \
{ "x8r8g8b8", 32, {16, 8}, {8, 8}, {0, 8}, {0, 0}, DRM_FORMAT_XRGB8888 }, \
{ "a8r8g8b8", 32, {16, 8}, {8, 8}, {0, 8}, {24, 8}, DRM_FORMAT_ARGB8888 }, \
{ "a8b8g8r8", 32, {0, 8}, {8, 8}, {16, 8}, {24, 8}, DRM_FORMAT_ABGR8888 }, \
{ "x2r10g10b10", 32, {20, 10}, {10, 10}, {0, 10}, {0, 0}, DRM_FORMAT_XRGB2101010 }, \
{ "a2r10g10b10", 32, {20, 10}, {10, 10}, {0, 10}, {30, 2}, DRM_FORMAT_ARGB2101010 }, \
}
[arch/x86/kernel/sysfb_simplefb.c]
static const struct simplefb_format formats[] = SIMPLEFB_FORMATS;
[fs/exec.c]
int search_binary_handler(struct linux_binprm *bprm)
{
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
/* This allows 4 levels of binfmt rewrites before failing hard. */
if (bprm->recursion_depth > 5)
return -ELOOP;
retval = security_bprm_check(bprm);
if (retval)
return retval;
retval = -ENOENT;
retry:
read_lock(&binfmt_lock);
// 遍历formats链表
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
// 每个尝试load_binary()函数
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
bprm->recursion_depth--;
if (retval < 0 && !bprm->mm) {
/* we got to flush_old_exec() and failed after it */
read_unlock(&binfmt_lock);
force_sigsegv(SIGSEGV, current);
return retval;
}
if (retval != -ENOEXEC || !bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (need_retry) {
if (printable(bprm->buf[0]) && printable(bprm->buf[1]) &&
printable(bprm->buf[2]) && printable(bprm->buf[3]))
return retval;
if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
return retval;
need_retry = false;
goto retry;
}
return retval;
}linux内核支持多种可执行程序格式, 每种格式都被注册为一个linux_binfmt结构, 其中存储了对应可执行程序格式加载函数等
15 对象文件格式
15.1 对象文件
对象文件(Object files)有三个种类:
15.1.1 可重定位的对象文件(Relocatable file)
适于链接的可重定位文件(relocatable file),包含二进制代码和数据,能与其他可重定位对象文件在编译时合并创建出一个可执行文件。
这是由汇编器汇编生成的 .o 文件。后面的链接器(link editor)拿一个或一些可重定位的对象文件(Relocatable object files)作为输入,经链接处理后,生成一个可执行的对象文件 (Executable file)或者一个可被共享(!!!)的对象文件(Shared object file)。
可以使用 ar 工具将众多的 .o Relocatable object files 归档(archive)成 .a 静态库文件。
内核可加载模块 .ko 文件也是 Relocatable object file。
15.1.2 可执行的对象文件(Executable file)
适于执行的可执行文件(executable file),包含可以直接拷贝进行内存执行的二进制代码和数据。用于提供程序的进程映像,加载的内存执行。
各种软件都是Executable object file。
Linux系统里面,存在两种可执行的东西(!!!)。
一个是Executable object file,
另外一种就是可执行的脚本(如shell脚本)。注意这些脚本不是 Executable object file,它们只是文本文件,但是执行这些脚本所用的解释器就是 Executable object file,比如 bash shell 程序。
15.1.3 可被共享的对象文件(Shared object file)
共享目标文件(shared object file),一种特殊的可重定位对象文件!!!,能在加载时或运行时,装载进内存进行动态链接。
链接器可将它与其它可重定位文件和共享目标文件连接成其它的目标文件,动态连接器又可将它与可执行文件和其它共享目标文件结合起来创建一个进程映像。
这些就是所谓的动态库文件,也即 .so 文件。如果拿前面的静态库来生成可执行程序,那每个生成的可执行程序中都会有一份库代码的拷贝。如果在磁盘中存储这些可执行程序,那就会占用额外的磁盘空间;另外如果拿它们放到Linux系统上一起运行,也会浪费掉宝贵的物理内存。如果将静态库换成动态库,那么这些问题都不会出现。
动态库在发挥作用的过程中,必须经过两个步骤:
-
链接编辑器(link editor)拿它和其他可重定位的对象文件Relocatable object file以及其他可被共享的对象文件shared object file作为输入,经链接处理后,生成另外的 可被共享的对象文件shared object file 或者 可执行的对象文件executable file。
-
在运行时,动态链接器(dynamic linker)拿它和一个可执行的对象文件Executable file以及另外一些 可被共享的对象文件Shared object file 来一起处理,在Linux系统里面创建一个进程映像。
15.2 文件格式
本质上,对象文件只是保存在磁盘文件中的一串字节,每个系统的文件格式都不尽相同:
-
Bell实验室的第一个Unix系统使用 a.out格式。
-
System V Unix的早期版本使用 Common Object File Format(COFF)。
-
Windows NT使用COFF的变种,叫做 Portable Executable(PE)。
-
现代Unix系统,包括Linux、新版System V、BSD变种、Solaris都使用 Executable and Linkable Format(ELF)。
15.3 ELF对象文件格式
ELF代表Executable and Linkable Format。它是一种对可执行文件、目标文件和库使用的文件格式。
ELF一个特别的优点在于, 同一文件格式可以用于内核支持的几乎所有体系结构上
但是文件格式相同并不意味着不同系统上的程序之间存在二进制兼容性, 例如,FreeBSD和Linux都使用ELF作为二进制格式。尽管两种系统在文件中组织数据的方式相同。但在系统调用机制以及系统调用的语义方面, 仍然有差别. 所以在没有中间仿真层的情况下, FreeBSD程序不能在linux下运行的原因(反过来同样是如此)。
二进制程序不能在不同体系结构交换, 因为底层的体系结构是完全不同的。但是由于ELF的存在, 对所有体系结构而言, 程序本身的相关信息以及程序的各个部分(!!!)在二进制文件中编码的方式都是相同的。
Linux不仅将ELF用于用户空间程序和库, 还用于构建模块。内核本身也是ELF格式。
1995年, 发布了ELF 1.2标准, 然后委员会解散了. 所以ELF文件格式标准最新版本是1.2.
文件类型 e_type成员表示ELF文件类型,即前面提到过的3种ELF文件类型,每个文件类型对应一个常量。系统通过这个常量来判断ELF的真正文件类型,而不是通过文件的扩展名。相关常量以“ET_”开头.
15.4 示例
15.4.1 add.c
#include
#include
// 不指定寄存器实现两个整数相加
int Add(int a, int b)
{
__asm__ __volatile__
(
//"lock;\n"
"addl %1,%0;\n"
: "=m"(a)
: "r"(b), "m"(a)
// :
);
return a;
} 15.4.2 sub.c
#include
#include
// 不指定寄存器实现两个参数相减
int Sub(int a, int b)
{
__asm__ __volatile__
(
"subl %1, %0;"
: "=m"(a)
: "r"(b), "m"(a)
// :
);
return a;
} 15.4.3 testelf.c
#include
#include
int main(void)
{
int a = 3, b = 5;
printf("%d + %d = %d\n", a, b, Add(a, b));
printf("%d - %d = %d\n", a, b, Sub(a, b));
return EXIT_SUCCESS;
} 15.4.4 Makefile
target=testelf_normal testelf_dynamic testelf_static
MAIN_OBJS=testelf.o
SUBS_OBJS=add.o sub.o
DYNA_FILE=libtestelf.so
STAT_FILE=libtestelf.a
all:$(target)
%.o : %.c
$(CC) -c $^ -o $@
clean :
rm -rf $(MAIN_OBJS) $(SUBS_OBJS)
rm -rf $(DYNA_FILE) $(STAT_FILE)
rm -rf $(target)
# Complie the execute
testelf_normal:$(MAIN_OBJS) $(SUBS_OBJS)
gcc $^ -o $@
testelf_dynamic:$(MAIN_OBJS) $(DYNA_FILE)
gcc $^ -o $@ -L./ -ltestelf
testelf_static:$(MAIN_OBJS) $(STAT_FILE)
gcc testelf.o -o $@ -static -L./ -ltestelf
# Complie the Dynamic Link Library libtestelf.so
libtestelf.so:$(SUBS_OBJS)
gcc -fPCI -shared $^ -o $@
# Complie the Static Link Library libtestelf.so
libtestelf.a:$(SUBS_OBJS)
ar -r $@ $^我们编写了两个库函数分别实现add和sub的功能, 然后编写了一个测试代码testelf.c调用了Add和Sub.
然后我们的Makefile为测试程序编写了3分程序
-
普通的程序testelf_normal, 由add.o sub.o 和testelf.o直接链接生成
-
动态链接程序testelf_dynamic, 将add.o和sub.o先链接成动态链接库libtestelf.so, 然后再动态链接生成testelf_dynamic
-
静态链接程序testelf_static, 将add.o和sub.o先静态链接成静态库libtestelf.a, 然后再静态链接生成可执行程序testelf_staticke
我们在源代码目录执行make后会完成编译, 编译完成后
-
add.o, sub.o和testelf.o是可重定位的对象文件(Relocatable file)
-
libtestelf.so是可被共享的对象文件(Shared object file)
-
testelf_normal, testelf_dynamic和testelf_static是可执行的对象文件(Executable file)
如下图所示
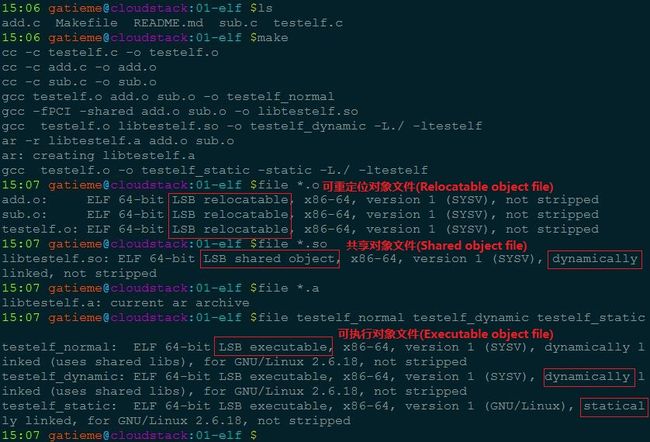
16 ELF可执行与链接文件格式详解
16.1 布局和结构
ELF文件内容有两个平行的视角: 一个是程序连接角度,另一个是程序运行角度

16.1.1 链接视图
首先图的左边部分,它是以链接视图来看待elf文件的, 从左边可以看出,包含了一个ELF头部,它描绘了整个文件的组织结构。
它还包括很多节区(p)。这些节有的是系统定义好的,有些是用户在文件在通过.p命令自定义的,链接器会将多个输入目标文件中的相同的节合并。节区部分包含链接视图的大量信息:指令、数据、符号表、重定位信息等等。
除此之外,还包含程序头部表(可选)和节区头部表.
程序头部表,告诉系统如何创建进程映像。用来构造进程映像的目标文件!!!必须具有程序头部表,**可重定位文件!!!**不需要这个表。
而节区头部表(Section Header Table)包含了描述文件节区的信息,每个节区在表中都有一项(!!!),每一项给出诸如节区名称、节区大小这类信息。用于链接的目标文件必须包含节区头部表,其他目标文件可以有,也可以没有这个表。
需要注意地是:尽管图中显示的各个组成部分是有顺序的,实际上除了ELF头部表以外,其他节区和段都没有规定的顺序。
16.1.2 执行视图
右半图是以程序执行视图来看待的,与左边对应,多了一个段(segment)的概念
编译器在生成目标文件时,通常使用从零开始的相对地址,而在链接过程中,链接器从一个指定的地址开始,根据输入目标文件的顺序,以段(segment)为单位将它们拼装起来。其中每个段可以包括很多个节(p)。
- elf头部
除了用于标识ELF文件的几个字节外,ELF头还包含了有关文件类型和大小的有关信息,以及文件加载后程序执行的入口点信息
- 程序头表(program header table)
程序头表向系统提供了可执行文件的数据在进程虚拟地址空间中组织文件的相关信息。他还表示了文件可能包含的段数据、段的位置和用途
- 段segment
各个段保存了与文件相关的各种形式的数据,例如,符号表、实际的二进制码、固定值(如字符串)或程序使用的数值常数
- 节头表p
包含了与各段相关的附加信息。
16.2 ELF基本数据类型定义
ELF数据编码顺序与机器相关,为了使数据结构更加通用, linux内核自定义了几种通用的数据, 使得数据的表示与具体体系结构分离
但是由于32位程序和64位程序所使用的数据宽度不同, 同时64位机必须兼容的执行32位程序, 因此我们所有的数据都被定义为32bit和64bit两个不同类型的数据
[include/uapi/linux/elf.h]
/* 32-bit ELF base types. */
typedef __u32 Elf32_Addr;
typedef __u16 Elf32_Half;
typedef __u32 Elf32_Off;
typedef __s32 Elf32_Sword;
typedef __u32 Elf32_Word;
/* 64-bit ELF base types. */
typedef __u64 Elf64_Addr; // 无符号程序地址
typedef __u16 Elf64_Half; // 无符号小整数
typedef __s16 Elf64_SHalf; // 无符号小整数
typedef __u64 Elf64_Off; // 无符号文件偏移
typedef __s32 Elf64_Sword; // 有符号中等整数
typedef __u32 Elf64_Word; // 无符号中等整数
typedef __u64 Elf64_Xword; // 无符号大整数
typedef __s64 Elf64_Sxword; // 有符号大整数
16.3 ELF头部elfxx_hdr
elf头部用elfxx_hdr结构(被定义在linux/uapi/linux/elf.h)来表示, elf32_hdr(32bit)和elf64_hdr(64bit)
| 成员 | 类型 | 描述 |
|---|---|---|
| e_ident[EI_NIDENT] | unsigned char | 目标文件标识信息, EI_NIDENT=16, 因此共占用128位 |
| e_type | Elf32_Half/Elf64_Half | 目标文件类型 |
| e_machine | Elf32_Half/Elf64_Half | 目标体系结构类型 |
| e_version | Elf32_Word/Elf64_Word | 目标文件版本 |
| e_entry | Elf32_Addr/Elf64_Addr | 程序入口的虚拟地址,若没有,可为0 |
| e_phoff | Elf32_Off/Elf64_Off | 程序头部表格(Program Header Table)的偏移量(按字节计算),若没有,可为0 |
| e_shoff | Elf32_Off/Elf64_Off | 节区头部表格(Section Header Table)的偏移量(按字节计算),若没有,可为0 |
| e_flags | Elf32_Word/Elf64_Word | 保存与文件相关的,特定于处理器的标志。标志名称采用 EF_machine_flag的格式 |
| e_ehsize | Elf32_Half/Elf64_Half | ELF 头部的大小(以字节计算) |
| e_phentsize | Elf32_Half/Elf64_Half | 程序头部表格的表项大小(按字节计算) |
| e_phnum | Elf32_Half/Elf64_Half | 程序头部表格的表项数目。可以为 0 |
| e_shentsize | Elf32_Half/Elf64_Half | 节区头部表格的表项大小(按字节计算) |
| e_shnum | Elf32_Half/Elf64_Half | 节区头部表格的表项数目。可以为 0 |
| e_shstrndx | Elf32_Half/Elf64_Half | 节区头部表格中与节区名称字符串表相关的表项的索引。如果文件没有节区名称字符串表,此参数可以为 SHN_UNDEF |
16.3.1 ELF魔数e_ident
很多类型的文件,其起始的几个字节的内容是固定的(固定不变!!!)。根据这几个字节的内容就可以确定文件类型,因此这几个字节的内容被称为魔数 (magic number)。
a.out格式的魔数为0x01、0x07
PE/COFF文件最开始两个字节为0x4d、0x5a,即ASCII字符MZ。
ELF文件最前面的"Magic"的16个字节刚好对应“Elf32_Ehdr”的e_ident这个成员。这16个字节被ELF标准规定用来标识ELF文件的平台属性
最开始的4个字节是所有ELF文件都必须相同的标识码,分别为0x7F、0x45、0x4c、0x46, 这四个被称为魔数
-
第1个字节对应ASCII字符里面的DEL控制符,
-
后面第2到第4的3个字节刚好是ELF这3个字母的ASCII码。这4个字节又被称为ELF文件的魔数
-
第5个字节是用来标识ELF的文件类的,0x01表示是32位的,0x02表示是64位的;
-
第6个字节是字节序,规定该ELF文件是大端的还是小端的。
-
第7个字节规定ELF文件的主版本号,一般是1,因为ELF标准自1.2版以后就再也没有更新了。
-
后面第8到第16的9个字节ELF标准没有定义,一般填0,有些平台会使用这9个字节作为扩展标志。
e_ident是一个16字节的数组,这个数组按位置从左到右都是有特定含义,每个数组元素的下标在标准中还存在别称,如byte0的下标0别名为EI_MAG0
16.3.2 目标文件类型e_type
每个文件类型对应一个常量。系统通过这个常量来判断ELF的真正文件类型,而不是通过文件的扩展名。相关常量以“ET_”开头
如下定义:
| 名称 | 取值 | 含义 |
|---|---|---|
| ET_NONE | 0 | 未知目标文件格式 |
| ET_REL | 1 | 可重定位文件 |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 共享目标文件 |
| ET_CORE | 4 | Core 文件(转储格式) |
| ET_LOPROC | 0xff00 | 特定处理器文件 |
| ET_HIPROC | 0xffff | 特定处理器文件 |
| ET_LOPROC~ET_HIPROC | 0xff00~0xffff | 特定处理器文件 |
16.3.3 目标体系结构类型e_machine
e_machine表示目标体系结构类型
| 名称 | 取值 | 含义 |
|---|---|---|
| EM_NONE | 0 | 未指定 |
| EM_M32 | 1 | AT&T WE 32100 |
| EM_SPARC | 2 | SPARC |
| EM_386 | 3 | Intel 80386 |
| EM_68K | 4 | Motorola 68000 |
| EM_88K | 5 | Motorola 88000 |
| EM_860 | 7 | Intel 80860 |
| EM_MIPS | 8 | MIPS RS3000 |
| others | 9~ | 预留 |
16.3.4 ELF版本e_version
ELF最新版本就是1(1.2),仍然是最新版,因此目前不需要这个特性
16.3.5 readelf -h查看elf头部
16.3.5.1 可重定位的对象文件(Relocatable file)
readelf -h add.o
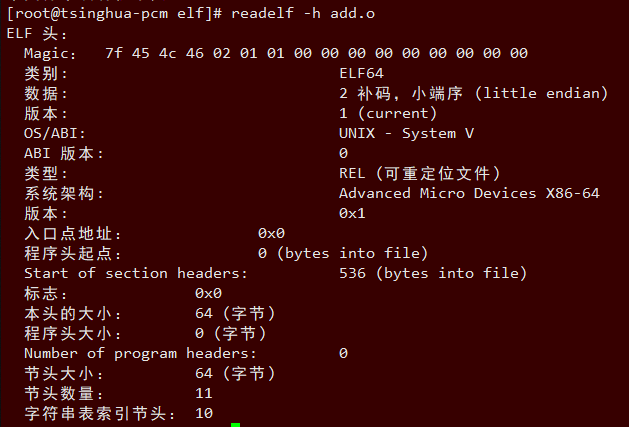
文件类型是REL, 说明是可重定位文件, 其代码可以移动至任何位置.
该文件没有程序头表, 对需要进行链接的对象而言, 程序头表是不必要的, 为此所有长度都设置为0
16.3.5.2 可执行的对象文件(Executable file)
readelf -h testelf_dynamic

16.3.5.3 可被共享的对象文件(Shared object file)
readelf -h libtestelf.so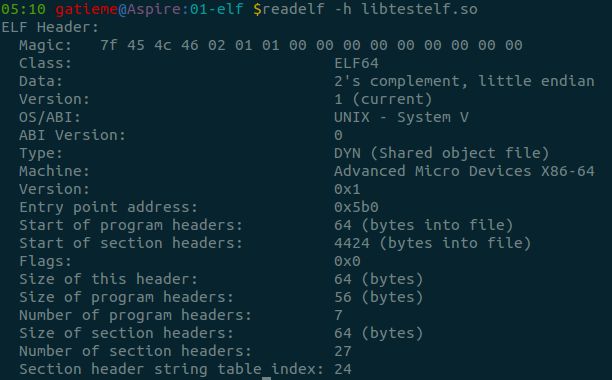
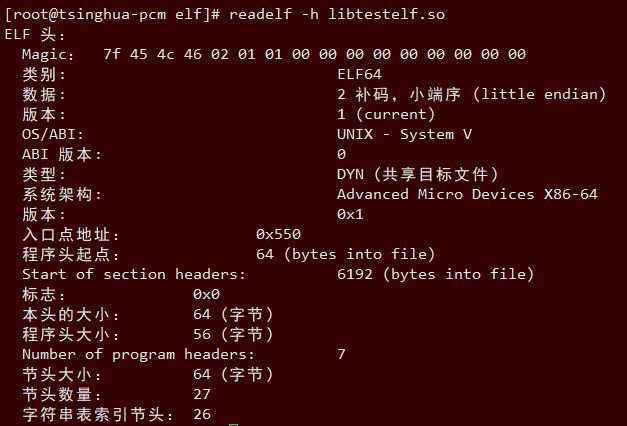
16.4 程序头部elf32_phdr
以程序运行的角度看ELF文件,就需要程序头表,即要运行这个elf文件,需要将哪些东西载入到内存镜像(!!!)。
而节区头部表是以elf资源的角度来看待elf文件的,即这个elf文件到底存在哪些资源,以及这些资源之间的关联关系
程序头部是一个表!!!,它的起始地址在elf头部结构中的e_phoff成员指定,数量由e_phnum表示,每个程序头部表项的大小由e_phentsize指出。因此可知,这个程序头部表格为一段连续的空间!!!,每一项元素为一结构体
可执行文件或者共享目标文件的程序头部是一个结构数组,每个结构描述了一个段或者系统准备程序执行所必需的其它信息。目标文件的"段"包含一个或者多个"节区(!!!)",也就是"段内容(Segment Contents)"。
程序头部仅对于可执行文件和共享目标文件有意义。
elf头部用elfxx_phdr结构(被定义在linux/uapi/linux/elf.h来表示, elf32_phdr(32bit)和elf64_phdr(64bit)
下面来看程序头号部表项(表项!!!)的数据结构
| 成员 | 类型 | 描述 |
|---|---|---|
| p_type | Elf32_Word/Elf64_Word | 段类型 |
| p_offset | Elf32_Off/Elf64_Off | 段在文件映像中的偏移位置 |
| p_vaddr | Elf32_Addr/Elf64_Addr | 给出段的第一个字节将被放到内存中的虚拟地址 |
| p_paddr | Elf32_Addr/Elf64_Addr | 仅用于与物理地址相关的系统中 |
| p_filesz | Elf32_Word/Elf64_Word | 给出段在文件映像中所占的字节数 |
| p_memsz | Elf32_Word/Elf64_Word | 给出段在内存映像中占用的字节数 |
| p_flags | Elf32_Word/Elf64_Word | 与段相关的标志 |
| p_align | Elf32_Word/Elf64_Word | 对齐 |
16.4.1 段类型p_type
| 名称 | 取值 | 说明 |
|---|---|---|
| PT_NULL | 0 | 此数组元素未用。结构中其他成员都是未定义的 |
| PT_LOAD | 1 | 表示一个需要从二进制文件映射到虚拟地址的段.其中保存了常量数据(如字符串),程序的目标代码等 |
| PT_DYNAMIC | 2 | 数组元素给出动态链接信息 |
| PT_INTERP | 3 | 数组元素给出一个NULL结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对与可执行文件有意义(尽管也可能在共享目标文件上发生)。在一个文件中不能出现一次以上(!!!)。如果存在这种类型的段,它必须在所有可加载段项目的前面 |
| PT_NOTE | 4 | 此数组元素给出附加信息的位置和大小 |
| PT_SHLIB | 5 | 此段类型被保留,不过语义未指定。包含这种类型的段的程序与ABI不符 |
| PT_PHDR | 6 | 此类型的数组元素如果存在,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中不能出现一次以上。并且只有程序头部表是程序的内存映像的一部分时才起作用。如果存在此类型段,则必须在所有可加载段项目的前面 |
| PT_LOPROC~PT_HIPROC | 0x70000000~0x7fffffff | 此范围的类型保留给处理器专用语义 |
16.4.2 readelf -l查看程序头表
16.4.2.1 可重定位的对象文件(Relocatable file)
readelf -l add.o
可重定向文件,是一个需要链接的对象,程序头表对其而言不是必要的, 因此这类文件一般没有程序头表
16.4.2.2 可被共享的对象文件(Shared object file)
readelf -l libtestelf.so
16.4.2.3 可执行的对象文件(Executable file)
readelf -l testelf_dynamic
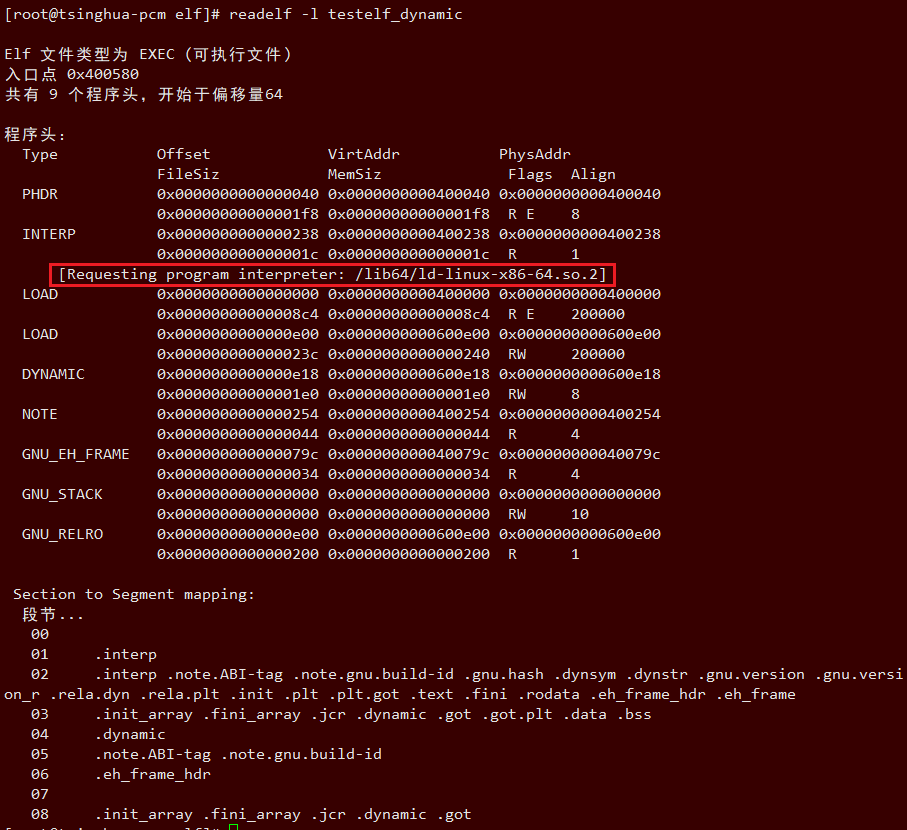
虚拟地址空间中的各个段,填充了来自ELF文件中特定的段的数据.因而readelf输出的第二部分(Section to Segment mapping!!!)指定了哪些节载入到哪些段(节段映射).
物理地址信息将被忽略,因为该信息是由内核根据物理页帧到虚拟地址空间中相应位置的映射情况动态分配的.只有在没有MMU(因而没有虚拟内存)的系统上该信息才是有意义的
在程序头表之后, 列出了6个段, 这些组成了最终在内存中执行的程序(!!!)
其还提供了各段在虚拟地址空间和物理空间的大小,位置,标志,访问权限和对齐方面的信息.还指定了多个类型来更精确的描述段.
| 段 | 描述 |
|---|---|
| PHDR | 保存了程序头表 |
| INTERP | 指定在程序已经从可执行文件映射到内存之后,必须调用的解释器.在这里解释器并不意味着二进制文件的内容必须解释执行(比如Java的字节码需要Java虚拟机解释).它指的是这样一个程序:通过链接其他库, 来满足未解决的引用. 通常/lib/ld-linux.so.2,/lib/ld-linux-ia-64.so.2等库, 用于在虚拟地址空间中插入程序运行所需的动态库.对几乎所有的程序来说,可能C标准库都是必须映射的.还需要添加的各种库, 如GTK, QT, 数学库math, 线程库pthread等等 |
| LOAD | 表示一个需要从二进制文件映射到虚拟地址的段.其中保存了常量数据(如字符串),程序的目标代码等 |
| DYNAMIC | 该段保存了由动态链接器(即, INTERP中指定的解释器)使用的信息 |
| NOTE | 保存了专有信息 |
16.5 节区(Sections)
节区中包含目标文件中的所有信息
除了:ELF 头部、程序头部表格、节区头部表格。
节区满足以下条件:
-
目标文件中的每个节区都有对应的节区头部描述它,反过来,有节区头部不意味着有节区。
-
每个节区占用文件中一个连续字节区域(这个区域可能长度为 0)。
-
文件中的节区不能重叠,不允许一个字节存在于两个节区中的情况发生。
-
目标文件中可能包含非活动空间(INACTIVE SPACE)。这些区域不属于任何头部和节区,其内容未指定。
16.5.1 节区头部表格
ELF文件在描述各段的内容(程序头!!!)时,是指定了哪些节的数据映射到段(!!!段的指定是通过base和size确定的!!!)中. 因此需要一个结构来管理各个节的内容, 即节头表
节区头部表是以elf资源的角度来看待elf文件的,即这个elf文件到底存在哪些资源,以及这些资源之间的关联关系,而前面提到的程序头部表,则以程序运行来看elf文件的,即要运行这个elf文件,需要将哪些东西载入到内存镜像。
ELF头部中,
e_shoff 成员给出从文件头到节区头部表格的偏移字节数;
e_shnum给出表格中条目数目;
e_shentsize 给出每个项目的字节数。
从这些信息中可以确切地定位节区的具体位置、长度。
每一项节区在节区头部表格中都存在着一项元素与它对应,因此可知,这个节区头部表格为一段连续的空间,每一项元素为一结构体
这个节区头部表项由elfxx_shdr(定义在[include/uapi/linux/elf.h]),32位elf32_shdr,64位elf64_shdr
| 成员 | 类型 | 描述 |
|---|---|---|
| sh_name | Elf32_Word/Elf64_Word | 节区名,是节区头部字符串表节区(Section Header String Table Section)的索引。名字是一个NULL结尾的字符串 |
| sh_type | Elf32_Word/Elf64_Word | 节区类型 |
| sh_flags | Elf32_Word/Elf64_Word | 节区标志 |
| sh_addr | Elf32_Addr/Elf64_Addr | 如果节区将出现在进程的内存映像中,此成员给出节区的第一个字节应处的位置。否则,此字段为 0 |
| sh_offset | Elf32_Off/Elf64_Off | 此成员的取值给出节区的第一个字节与文件头之间的偏移 |
| sh_size | Elf32_Word/Elf64_Word | 此成员给出节区的长度(字节数) |
| sh_link | Elf32_Word/Elf64_Word | 此成员给出节区头部表索引链接。其具体的解释依赖于节区类型 |
| sh_info | Elf32_Word/Elf64_Word | 此成员给出附加信息,其解释依赖于节区类型 |
| sh_addralign | Elf32_Word/Elf64_Word | 某些节区带有地址对齐约束 |
| sh_entsize | Elf32_Word/Elf64_Word | 某些节区中包含固定大小的项目,如符号表。对于这类节区,此成员给出每个表项的长度字节数 |
16.5.2 特殊节区
有些节区是系统预订的,一般以点开头号
| 名称 | 类型 | 属性 | 含义 |
|---|---|---|---|
| .bss | SHT_NOBITS | SHF_ALLOC +SHF_WRITE | 包含将出现在程序的内存映像中的为初始化数据。根据定义,当程序开始执行,系统将把这些数据初始化为 0。此节区不占用文件空间 |
| .comment | SHT_PROGBITS | (无) | 包含版本控制信息 |
| .data | SHT_PROGBITS | SHF_ALLOC + SHF_WRITE | 这些节区包含初始化了的数据,将出现在程序的内存映像中 |
| .data1 | SHT_PROGBITS | SHF_ALLOC + SHF_WRITE | 这些节区包含初始化了的数据,将出现在程序的内存映像中 |
| .debug | SHT_PROGBITS | (无) | 此节区包含用于符号调试的信息 |
| .dynamic | SHT_DYNAMIC | 此节区包含动态链接信息。节区的属性将包含 SHF_ALLOC 位。是否 SHF_WRITE 位被设置取决于处理器 | |
| .dynstr | SHT_STRTAB | SHF_ALLOC | 此节区包含用于动态链接的字符串,大多数情况下这些字符串代表了与符号表项相关的名称 |
| .dynsym | SHT_DYNSYM | SHF_ALLOC | 此节区包含了动态链接符号表 |
| .fini | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR | 此节区包含了可执行的指令,是进程终止代码的一部分。程序正常退出时,系统将安排执行这里的代码 |
| .got | SHT_PROGBITS | 此节区包含全局偏移表 | |
| .hash | SHT_HASH | SHF_ALLOC | 此节区包含了一个符号哈希表 |
| .init | SHT_PROGBITS | SHF_ALLOC +SHF_EXECINSTR | 此节区包含了可执行指令,是进程初始化代码的一部分。当程序开始执行时,系统要在开始调用主程序入口之前(通常指 C 语言的 main 函数)执行这些代码 |
| .interp | SHT_PROGBITS | 此节区包含程序解释器的路径名。如果程序包含一个可加载的段,段中包含此节区,那么节区的属性将包含 SHF_ALLOC 位,否则该位为 0 | |
| .line | SHT_PROGBITS | (无) | 此节区包含符号调试的行号信息,其中描述了源程序与机器指令之间的对应关系。其内容是未定义的 |
| .note | SHT_NOTE | (无) | 此节区中包含注释信息,有独立的格式。 |
| .plt | SHT_PROGBITS | 此节区包含过程链接表(procedure linkage table) | |
| .relname .relaname |
SHT_REL SHT_RELA |
这些节区中包含了重定位信息。如果文件中包含可加载的段,段中有重定位内容,节区的属性将包含 SHF_ALLOC 位,否则该位置 0。传统上 name 根据重定位所适用的节区给定。例如 .text 节区的重定位节区名字将是:.rel.text 或者 .rela.text | |
| .rodata .rodata1 |
SHT_PROGBITS | SHF_ALLOC | 这些节区包含只读数据,这些数据通常参与进程映像的不可写段 |
| .shstrtab | SHT_STRTAB | 此节区包含节区名称 | |
| .strtab | SHT_STRTAB | 此节区包含字符串,通常是代表与符号表项相关的名称。如果文件拥有一个可加载的段,段中包含符号串表,节区的属性将包含SHF_ALLOC 位,否则该位为 0 | |
| .symtab | SHT_SYMTAB | 此节区包含一个符号表。如果文件中包含一个可加载的段,并且该段中包含符号表,那么节区的属性中包含SHF_ALLOC 位,否则该位置为 0 | |
| .text | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR | 此节区包含程序的可执行指令 |
16.5.3 readelf -S查看节区头表
16.5.3.1 可重定位的对象文件(Relocatable file)
readelf -S add.o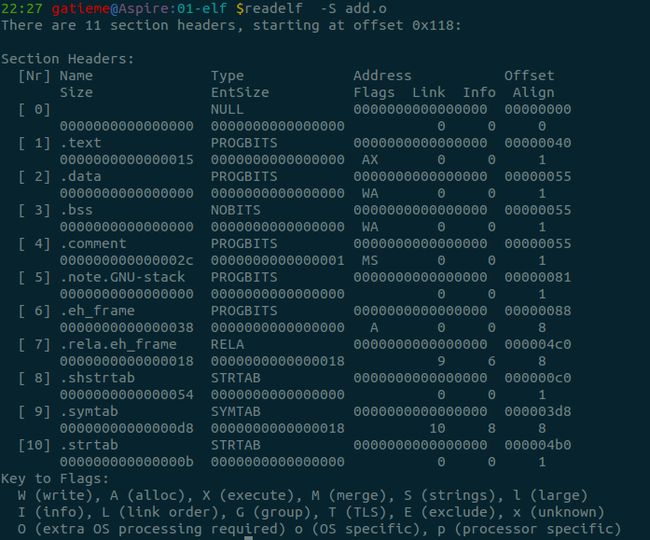
可重定向文件, 是一个需要链接的对象, 程序头表对其而言不是必要的, 因此这类文件一般没有程序头表
16.5.3.2 可执行的对象文件(Executable file)
readelf -S testelf_dynamic
16.5.3.3 可被共享的对象文件(Shared object file)
readelf -S libtestelf.so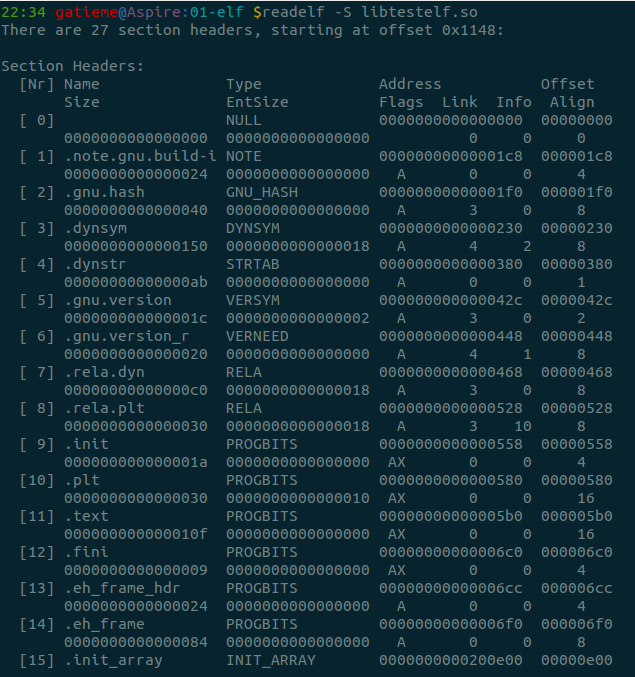
16.6 字符串表
首先要知道,字符串表它本身就是一个节区,每一个节区都存在一个节区头部表项与之对应,所以字符串表这个节区也存在一个节区头部表项对应,而在elf文件头部结构中存在一个成员e_shstrndx给出这个节区头部表项的索引位置。因此可以通过
shstrab = (rt_uint8_t *)module_ptr +shdr[elf_module->e_shstrndx].sh_offset;来得到字符串表的起始位置。
字符串表节区包含以NULL(ASCII码0)结尾的字符序列,通常称为字符串。ELF目标文件通常使用字符串来表示符号和节区名称。对字符串的引用通常以字符串在字符串表中的下标给出。
一般,第一个字节(索引为0)定义为一个空字符串。类似的,字符串表的最后一个字节也定义为NULL,以确保所有的字符串都以NULL结尾。索引为0的字符串在不同的上下文中可以表示无名或者名字为NULL的字符串。
允许存在空的字符串表节区,其节区头部的sh_size成员应该为0。对空的字符串表而言,非0的索引值是非法的。
例如:对于各个节区而言,节区头部的sh_name成员包含其对应的节区头部字符串表节区的索引,此节区由ELF头的e_shstrndx成员给出。下图给出了包含25个字节的一个字符串表,以及与不同索引相关的字符串。

那么上面字符串表包含以下字符串:
| 索引 | 字符串 |
|---|---|
| 0 | (无) |
| 1 | "name." |
| 7 | "Variable" |
| 11 | "able" |
| 16 | "able" |
| 24 | (空字符串) |
16.7 符号表(Symbol Table)
符号表同样本身是一节区,也存在一对应节区头部表项。
目标文件的符号表中包含用来定位、重定位程序中符号定义和引用的信息。
符号表索引是对此数组的索引。索引0表示表中的第一表项,同时也作为未定义符号的索引。
16.7.1 数据结构elfxx_sym
符号表是由一个个符号元素组成,用elfxx_sym来结构来表示,定义在[include/uapi/linux/elf.h], 同样32位为elf32_sym, 64位对应elf64_sym
每个元素的数据结构如下定义:
| 成员 | 类型 | 描述 |
|---|---|---|
| st_name | Elf32_Word/Elf64_Word | 名称,索引到字符串表 |
| st_value | Elf32_AddrElf64_Addr | 给出相关联的符号的取值。依赖于具体的上下文 |
| st_size | Elf32_Word/Elf64_Word | 相关的尺寸大小 |
| st_info | unsigned char | 给出符号的类型和绑定属性 |
| st_other | unsigned char | 该成员当前包含 0,其含义没有定义 |
| st_shndx | Elf32_Half/Elf64_Half | 给出相关的节区头部表索引。某些索引具有特殊含义 |
17 加载和动态链接
从编译/链接和运行的角度看,应用程序和库程序的连接有两种方式。
-
一种是固定的、静态的连接,就是把需要用到的库函数的目标代码(二进制)代码从程序库中抽取出来,链接进应用软件的目标映像中;
-
另一种是动态链接,是指库函数的代码并不进入应用软件的目标映像,应用软件在编译/链接阶段(!!!)并不完成跟库函数的链接,而是把函数库的映像也交给用户,到启动应用软件目标映像运行时才把程序库的映像也装入用户空间(并加以定位),再完成应用软件与库函数的连接。
这样,就有了两种不同的ELF格式映像。
-
一种是静态链接的,在装入/启动其运行时无需装入函数库映像、也无需进行动态连接。
-
另一种是动态连接,需要在装入/启动其运行时同时装入函数库映像并进行动态链接。
Linux内核既支持静态链接的ELF映像,也支持动态链接的ELF映像,而且装入/启动ELF映像必须由内核完成(内核部分!!!),而动态连接的实现则既可以在内核中完成,也可在用户空间完成。
因此,GNU!!!把对于动态链接ELF映像的支持作了分工:
-
把ELF映像的装入/启动入在Linux内核中;
-
而把动态链接的实现放在用户空间(glibc),并为此提供一个称为"解释器"(ld-linux.so.2)的工具软件,而解释器的装入/启动也由内核负责,这在后面我们分析ELF文件的加载时就可以看到
这部分主要说明ELF文件在内核空间的加载过程,下一部分对用户空间符号的动态解析过程进行说明。
18 elf文件格式的注册
ELF文件格式的linux_binfmt结构对象elf_format, 定义如下, 在[fs/binfmt.c]
[fs/binfmt.c]
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
.hasvdso = 1
};要支持ELF文件的运行,则必须向内核登记注册elf_format这个linux_binfmt类型的数据结构,加入到内核支持的可执行程序的队列中。内核提供两个函数来完成这个功能,一个注册,一个注销,即:
int register_binfmt(struct linux_binfmt * fmt)
int unregister_binfmt(struct linux_binfmt * fmt)当需要运行一个程序时,则扫描这个队列,依次调用各个数据结构所提供的load处理程序来进行加载工作,ELF中加载程序即为load_elf_binary,内核中已经注册的可运行文件结构linux_binfmt会让其所属的加载程序load_binary逐一前来认领需要运行的程序binary,如果某个格式的处理程序发现相符后,便执行该格式映像的装入和启动
19 内核空间的加载过程load_elf_binary
在ELF文件格式中,load_binary对应的处理函数是load_elf_binary
其流程如下
-
填充并且检查目标程序ELF头部
-
load_elf_phdrs加载目标程序的程序头表
-
如果需要动态链接, 则寻找和处理解释器段
-
检查并读取解释器的程序表头
-
装入目标程序的段segment
-
填写程序的入口地址
-
create_elf_tables填写目标文件的参数环境变量等必要信息
-
start_kernel宏准备进入新的程序入口
19.1 填充并且检查目标程序ELF头部
struct pt_regs *regs = current_pt_regs();
struct {
// 可执行文件的elf头部
struct elfhdr elf_ex;
// 解释器的elf头部
struct elfhdr interp_elf_ex;
} *loc;
struct arch_elf_state arch_state = INIT_ARCH_ELF_STATE;
loc = kmalloc(sizeof(*loc), GFP_KERNEL);
if (!loc) {
retval = -ENOMEM;
goto out_ret;
}
/* Get the exec-header
使用映像文件的前128个字节对bprm->buf进行了填充 */
loc->elf_ex = *((struct elfhdr *)bprm->buf);
retval = -ENOEXEC;
/* 比较文件头的前四个字节
。*/
if (memcmp(loc->elf_ex.e_ident, ELFMAG, SELFMAG) != 0)
goto out;
/* 还要看映像的类型是否ET_EXEC和ET_DYN之一;前者表示可执行映像,后者表示共享库 */
if (loc->elf_ex.e_type != ET_EXEC && loc->elf_ex.e_type != ET_DYN)
goto out;在load_elf_binary之前,内核已经使用映像文件的前128个字节对bprm->buf进行了填充,563行就是使用这此信息填充映像的文件头(具体数据结构定义见第一部分,ELF文件头节),然后567行就是比较文件头的前四个字节,查看是否是ELF文件类型定义的“\177ELF”。除这4个字符以外,还要看映像的类型是否ET_EXEC和ET_DYN之一;前者表示可执行映像,后者表示共享库。
19.2 load_elf_phdrs加载目标程序的程序头表
elf_phdata = load_elf_phdrs(&loc->elf_ex, bprm->file);
if (!elf_phdata)
goto out;而这个load_elf_phdrs函数就是通过kernel_read读入整个program header table。从函数代码中可以看到,一个可执行程序必须至少有一个段(segment),而所有段的大小之和不能超过64K(65536u)
19.3 如果需要动态链接, 则寻找和处理解释器段, 得到解释器映像的elf头部
这个for循环的目的在于寻找和处理目标映像的"解释器"段。
"解释器"段的类型为PT_INTERP,找到后就根据其位置的p_offset和大小p_filesz把整个"解释器"段的内容读入缓冲区。
"解释器"段实际上只是一个字符串(!!!),即解释器的文件名,如"/lib/ld-linux.so.2", 或者64位机器上对应的叫做"/lib64/ld-linux-x86-64.so.2"
有了解释器的文件名以后,就通过open_exec()打开这个文件,再通过kernel_read()读入其开头128个字节,即解释器映像的头部。*
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
/* 3.1 检查是否有需要加载的解释器 */
if (elf_ppnt->p_type == PT_INTERP) {
elf_interpreter = kmalloc(elf_ppnt->p_filesz,
GFP_KERNEL);
if (!elf_interpreter)
goto out_free_ph;
/* 3.2 根据其位置的p_offset和大小p_filesz把整个"解释器"段的内容读入缓冲区 */
retval = kernel_read(bprm->file, elf_ppnt->p_offset,
elf_interpreter,
elf_ppnt->p_filesz);
if (elf_interpreter[elf_ppnt->p_filesz - 1] != '\0')
goto out_free_interp;
/* 3.3 通过open_exec()打开解释器文件 */
interpreter = open_exec(elf_interpreter);
/* 3.4 通过kernel_read()读入解释器的前128个字节,即解释器映像的头部。*/
retval = kernel_read(interpreter, 0,
(void *)&loc->interp_elf_ex,
sizeof(loc->interp_elf_ex));
break;
}
elf_ppnt++;
}可以使用readelf -l查看program headers,其中的INTERP段标识了我们程序所需要的解释器
readelf -l testelf_normal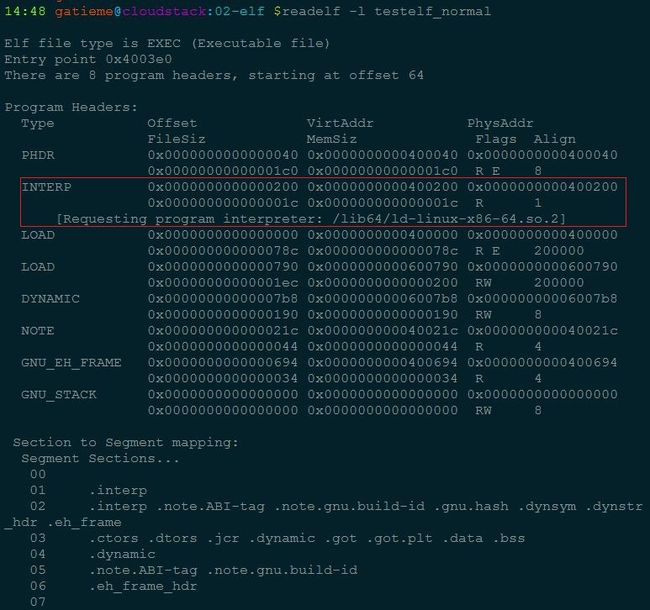
readelf -l testelf_dynamic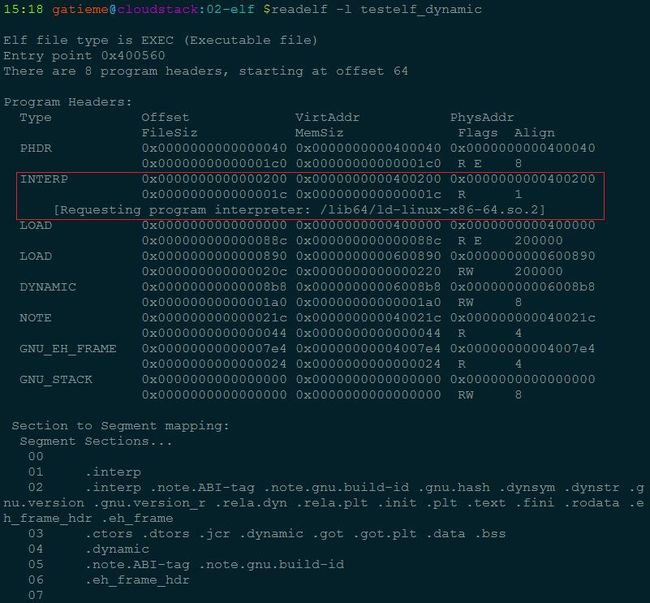
readelf -l test_static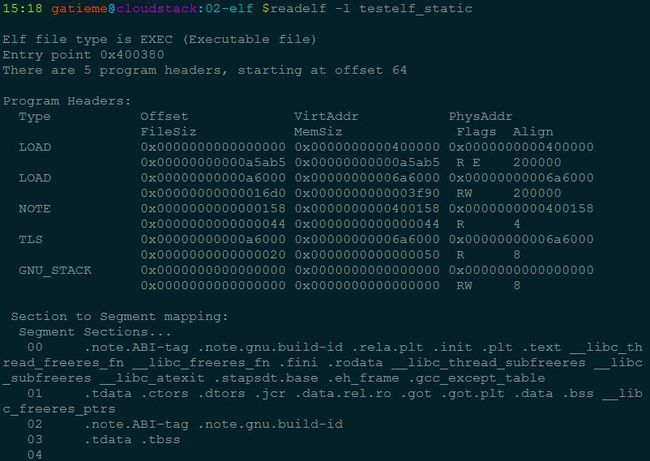
我们可以看到testelf_normal和testelf_dynamic都是动态链接的, 需要解释器
而testelf_static则是静态链接的, 不需要解释器
19.4 检查并读取解释器的程序表头
如果需要加载解释器,前面经过一趟for循环已经找到了需要的解释器信息elf_interpreter,他也是当作一个ELF文件,因此跟目标可执行程序一样, 我们需要load_elf_phdrs加载解释器!!!的程序头表program header table
/* 4. 检查并读取解释器的程序表头 */
/* 4.1 检查解释器头的信息 */
if (elf_interpreter) {
retval = -ELIBBAD;
/* Not an ELF interpreter */
/* 4.2 读入解释器的程序头 */
interp_elf_phdata = load_elf_phdrs(&loc->interp_elf_ex,
interpreter);
if (!interp_elf_phdata)
goto out_free_dentry;至此我们已经把目标执行程序和其所需要的解释器都加载初始化,并且完成检查工作, 也加载了程序头表program header table, 下面开始加载程序的段信息
19.5 装入目标程序的段segment
从目标映像的程序头中搜索类型为PT_LOAD的段(Segment)。
在二进制映像中,只有类型为PT_LOAD的段才是需要装入的。当然在装入之前,需要确定装入的地址,只要考虑的就是页面对齐,还有该段的p_vaddr域的值(上面省略这部分内容)。
确定了装入地址后,就通过elf_map()建立用户空间虚拟地址空间与目标映像文件中某个连续区间之间的映射,其返回值就是实际映射的起始地址。
for(i = 0, elf_ppnt = elf_phdata;
i < loc->elf_ex.e_phnum; i++, elf_ppnt++) {
/* 5.1 搜索PT_LOAD的段, 这个是需要装入的 */
if (elf_ppnt->p_type != PT_LOAD)
continue;
/* 5.2 检查地址和页面的信息 */
/* 5.3 虚拟地址空间与目标映像文件的映射
确定了装入地址后,
就通过elf_map()建立用户空间虚拟地址空间
与目标映像文件中某个连续区间之间的映射,
其返回值就是实际映射的起始地址 */
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
}19.6 填写程序的入口地址
完成了目标程序和解释器的加载, 同时目标程序的各个段也已经加载到内存了, 我们的目标程序已经准备好了要执行了, 但是还缺少一样东西, 就是我们程序的入口地址, 没有入口地址, 操作系统就不知道从哪里开始执行内存中加载好的可执行映像
-
如果需要装入解释器,就通过load_elf_interp装入其映像(!!!这是动态链接, 所以是现在运行时候加载解释器的映像!!!), 并把将来进入用户空间的入口地址设置成load_elf_interp()的返回值,即解释器映像的入口地址。
-
而若不装入解释器,那么这个入口地址就是目标映像本身的入口地址。
if (elf_interpreter) {
unsigned long interp_map_addr = 0;
/* 入口地址是解释器映像的入口地址 */
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
} else {
/* 入口地址是目标程序的入口地址 */
elf_entry = loc->elf_ex.e_entry;
}
}19.7 create_elf_tables()填写目标文件的参数环境变量等必要信息
在完成装入,启动用户空间的映像运行之前,还需要为目标映像和解释器准备好一些有关的信息,这些信息包括常规的argc、envc等等,还有一些“辅助向量(Auxiliary Vector)”。
这些信息需要复制到用户空间,使它们在CPU进入解释器或目标映像的程序入口时出现在用户空间堆栈上。这里的create_elf_tables()就起着这个作用。
install_exec_creds(bprm);
retval = create_elf_tables(bprm, &loc->elf_ex,
load_addr, interp_load_addr);
if (retval < 0)
goto out;
/* N.B. passed_fileno might not be initialized? */
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;19.8 start_thread宏准备进入新的程序入口
start_thread(regs, elf_entry, bprm->p);最后,start_thread()这个宏操作会将eip和esp改成新的地址,就使得CPU在返回用户空间时就进入新的程序入口。如果存在解释器映像,那么这就是解释器映像的程序入口,否则就是目标映像的程序入口。
那么什么情况下有解释器映像存在,什么情况下没有呢?如果目标映像与各种库的链接是静态链接,因而无需依靠共享库、即动态链接库,那就不需要解释器映像;否则就一定要有解释器映像存在。
start_thread宏是一个体系结构相关的
19.9 小结
简单来说可以分成这几步
-
读取并检查目标可执行程序的头信息,检查完成后加载目标程序的程序头表
-
如果需要解释器则读取并检查解释器的头信息,检查完成后加载解释器的程序头表
-
装入目标程序的段segment,这些才是目标程序二进制代码中的真正可执行映像
-
填写程序的入口地址(如果有解释器则填入解释器的入口地址,否则直接填入可执行程序的入口地址)
-
create_elf_tables填写目标文件的参数环境变量等必要信息
-
start_kernel宏准备进入新的程序入口
gcc在编译时,除非显示的使用static标签,否则所有程序的链接都是动态链接的,也就是说需要解释器。
由此可见,我们的程序在被内核加载到内存,内核跳到用户空间后并不是执行目标程序的,而是先把控制权交到用户空间的解释器,由解释器加载运行用户程序所需要的动态库!!!(比如libc等等),然后控制权才会转移到用户程序。
20 ELF文件中符号的动态解析过程
前面我们提到了内核空间中ELF文件的加载工作
20.1 内核的工作
-
内核首先读取ELF文件头部,再读入各种数据结构,从这些数据结构中可知各段或节的地址及标识,然后调用mmap()把找到的可加载段的内容加载到内存中。同时读取段标记,以标识该段在内存中是否可读、可写、可执行。其中,文本段是程序代码,只读且可执行,而数据段是可读且可写。
-
从PT_INTERP的段中找到所对应的动态链接器名称,并加载动态链接器。通常是/lib/ld-linux.so.2.
-
内核把新进程的堆栈中设置一些标记对,以指示动态链接器的相关操作。
-
内核把控制权传递给动态链接器。
动态链接器的工作并不是在内核空间完成的,而是在用户空间完成!!!的,比如C语言程序则交给C运行时库来完成,这个并不是我们今天内核学习的重点,而是由glic完成的,但是其一般过程如下
20.2 动态链接器的工作
-
动态链接器检查程序对共享库的依赖性(前面已经读取了解释器和当前程序的程序头, 程序头有一个类型是PT_DYNAMIC,提供了动态链接信息!!!),并在需要时对其进行加载。
-
动态链接器对程序的外部引用进行重定位,并告诉程序其引用的外部变量/函数的地址,此地址位于共享库被加载在内存的区间内。动态链接还有一个延迟定位的特性,即只有在“真正”需要引用符号时才重定位,这对提高程序运行效率有极大帮助。
-
动态链接器执行在ELF文件中标记为.init的节的代码,进行程序运行的初始化。动态链接器把控制传递给程序,从ELF文件头部中定义的程序进入点开始执行。在a.out格式和ELF格式中,程序进入点的值是显式存在的,而在COFF格式中则是由规范隐含定义。
-
程序开始执行
21 Linux进程退出
21.1 linux下进程退出的方式
21.1.1 正常退出
-
从main函数返回return
-
调用exit
-
调用_exit
21.1.2 异常退出
-
调用abort
-
由信号终止
21.2 _exit, exit和_Exit的区别和联系
_exit是linux系统调用,关闭所有文件描述符,然后退出进程。
exit是c语言的库函数,他最终调用_exit。在此之前,先清洗标准输出的缓存,调用atexit注册的函数等,在c语言的main函数中调用return就等价于调用exit。
_Exit是c语言的库函数,自c99后加入,等价于_exit,即可以认为它直接调用_exit。
基本来说,_Exit(或_exit,建议使用大写版本)是为fork之后的子进程准备的特殊API。
由fork()函数创建的子进程分支里,正常情况下使用函数exit()是不正确的,这是因为使用它会导致标准输入输出的缓冲区被清空两次,而且临时文件可能被意外删除。
因为在fork之后,exec之前,很多资源还是共享的(如某些文件描述符),如果使用exit会关闭这些资源,导致某些非预期的副作用(如删除临时文件等)。
「刷新」是对应flush,意思是把内容从内存缓存写出到文件里,而不仅仅是清空(所以常见的对stdin调用flush的方法是耍流氓而已)。如果在fork的时候父进程内存有缓冲内容,则这个缓冲会带到子进程,并且两个进程会分别 flush (写出)一次,造成数据重复。
21.3 进程退出的系统调用
21.3.1 _exit和exit_group系统调用
_exit系统调用
进程退出由_exit系统调用来完成,这使得内核有机会将该进程所使用的资源释放回系统中
进程终止时,一般是调用exit库函数(无论是程序员显式调用还是编译器自动地把exit库函数插入到main函数的最后一条语句之后!!!)来释放进程所拥有的资源。
_exit系统调用的入口点是sys_exit()函数,需要一个错误码作为参数,以便退出进程。
其定义是体系结构无关的, 见kernel/exit.c
exit_group系统调用
不管是多线程, 还是进程组起本质都是多个进程组成的一个集合, 那么我们的应用程序在退出的时候, 自然希望一次性的退出组内所有的进程。
exit_group函数会杀死属于当前进程所在线程组的所有进程。它接受进程终止代号作为参数,进程终止代号可能是系统调用exit_group(正常结束)指定的一个值,也可能是内核提供的一个错误码(异常结束)。
因此C语言的库函数exit使用系统调用exit_group来终止整个线程组,库函数pthread_exit使用系统调用_exit来终止某一个线程
_exit和exit_group这两个系统调用在Linux内核中的入口点函数分别为sys_exit和sys_exit_group。
21.3.2 系统调用声明
[include/linux/syscalls.h]
asmlinkage long sys_exit(int error_code);
asmlinkage long sys_exit_group(int error_code);
asmlinkage long sys_wait4(pid_t pid, int __user *stat_addr,
int options, struct rusage __user *ru);
asmlinkage long sys_waitid(int which, pid_t pid,
struct siginfo __user *infop,
int options, struct rusage __user *ru);
asmlinkage long sys_waitpid(pid_t pid, int __user *stat_addr, int options);21.3.3 系统调用号
其系统调用号是一个体系结构相关的定义, 但是多数体系结构的定义如下,
[include/uapi/asm-generic/unistd.h]
/* kernel/exit.c */
#define __NR_exit 93
__SYSCALL(__NR_exit, sys_exit)
#define __NR_exit_group 94
__SYSCALL(__NR_exit_group, sys_exit_group)
#define __NR_waitid 95
__SC_COMP(__NR_waitid, sys_waitid, compat_sys_waitid)只有少数体系结构, 重新定义了系统调用号
21.3.4 系统调用实现
[kernel/exit.c]
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
SYSCALL_DEFINE1(exit_group, int, error_code)
{
do_group_exit((error_code & 0xff) << 8);
/* NOTREACHED */
return 0;
}21.4 do_group_exist流程
do_group_exit()函数杀死属于current线程组的所有进程。它接受进程终止代码作为参数,进程终止代号可能是系统调用exit_group()指定的一个值,也可能是内核提供的一个错误代号。
[kernel/exit.c]
void do_group_exit(int exit_code)
{
struct signal_struct *sig = current->signal;
BUG_ON(exit_code & 0x80); /* core dumps don't get here */
/*
检查current->sig->flags的SIGNAL_GROUP_EXIT标志是否置位
或者current->sig->group_exit_task是否不为NULL
*/
if (signal_group_exit(sig))
/* 说明已经开始执行线程组的退出 */
/* group_exit_code存放的是线程组终止代码 */
exit_code = sig->group_exit_code;
/* 检查线程组链表是否不为空 */
else if (!thread_group_empty(current)) {
struct sighand_struct *const sighand = current->sighand;
spin_lock_irq(&sighand->siglock);
if (signal_group_exit(sig))
/* Another thread got here before we took the lock. */
exit_code = sig->group_exit_code;
else {
sig->group_exit_code = exit_code;
sig->flags = SIGNAL_GROUP_EXIT;
/* 遍历整个线程组链表,并杀死其中的每个线程 */
zap_other_threads(current);
}
spin_unlock_irq(&sighand->siglock);
}
do_exit(exit_code);
/* NOTREACHED */
}该函数执行下述操作
-
检查退出进程的SIGNAL_GROUP_EXIT标志是否不为0,如果不为0,说明内核已经开始线程组执行退出的过程。在这种情况下,就把存放在current->signal->group_exit_code的值当作退出码,然后跳转到第4步。
-
否则,设置进程的SIGNAL_GROUP_EXIT标志并把终止代号放到current->signal->group_exit_code字段。
-
调用zap_other_threads()函数杀死current线程组中的其它进程。为了完成这个步骤,函数扫描当前线程所在线程组的链表,向表中所有不同于current的进程发送SIGKILL信号,结果,所有这样的进程都将执行do_exit()函数,从而被杀死。
遍历线程所在线程组的所有线程函数while_each_thread(p, t)使用了:
static inline struct task_struct *next_thread(const struct task_struct *p)
{
return list_entry_rcu(p->thread_group.next,
struct task_struct, thread_group);
}
#define while_each_thread(g, t) \
while ((t = next_thread(t)) != g)- 调用do_exit()函数,把进程的终止代码传递给它。正如我们将在下面看到的,do_exit()杀死进程而且不再返回。
21.5 do_exit()流程
[kernel/exit.c]
void __noreturn do_exit(long code)
{
......
}
EXPORT_SYMBOL_GPL(do_exit);- 触发task_exit_nb通知链实例的处理函数
- 保证task_struct中的plug字段是空的,或者plug字段指向的队列是空的。plug字段的意义是stack plugging
- 中断上下文不能执行do_exit函数, 也不能终止PID为0的进程。
- 设定进程可以使用的虚拟地址的上限(用户空间)
- 首先是检查PF_EXITING标识, 此标识表示进程正在退出. 如果此标识已被设置,则进一步设置PF_EXITPIDONE标识,并将进程的状态设置为不可中断状态TASK_UNINTERRUPTIBLE, 并进行一次进程调度schedule(); 如果此标识未被设置, 设置PF_EXITING标志
- 内存屏障,用于确保在它之后的操作开始执行之前,它之前的操作已经完成
- 同步进程的mm的rss_stat
- 清除定时器, 收集进程会计信息, 审计
- 释放进程占用的资源: 释放线性区描述符和页表, 释放用户空间的“信号量”, 释放锁, 释放文件对象相关资源, 释放struct fs_struct结构体, 脱离控制终端, 释放命名空间, 释放task_struct中的thread_struct结构, Performance Event功能相关资源的释放, 注销断点, 更新所有子进程的父进程等
- 调度其它进程schedule(), 在设置了进程状态为TASK_DEAD后,进程进入僵死状态,进程已经无法被再次调度, 因为对应用程序或者用户空间来说此进程已经死了,但是尽管进程已经不能再被调度,但系统还是保留了它的进程描述符,这样做是为了让系统有办法在进程终止后仍能获得它的信息。在父进程获得已终止子进程的信息后,子进程的task_struct结构体才被释放(包括此进程的内核栈)。
22 调度器和调度策略
调度器, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换.
调度器的一般原理是, 按所需分配的计算能力,向系统中每个进程提供最大的公正性,或者从另外一个角度上说, 他试图确保没有进程被亏待.
调度策略(scheduling policy)的任务就是决定什么时候以怎么样的方式选择一个新进程占用CPU运行.
传统操作系统的调度基于分时(time sharing)技术: 多个进程以"时间多路复用"方式运行,因为CPU的时间被分成"片(slice)",给每个可运行进程分配一片CPU时间片,当然单处理器在任何给定的时刻只能运行一个进程.
如果当前可运行进程的时限(quantum)到期时(即时间片用尽), 而该进程还没有运行完毕, 进程切换就可以发生.
分时依赖于定时中断, 因此对进程是透明的, 不需要在承租中插入额外的代码来保证CPU分时.
调度策略也是根据进程的优先级对他们进行分类.有时用复杂的算法求出进程当前的优先级,但最后的结果是相同的: 每个进程都与一个值(优先级)相关联, 这个值表示把进程如何适当地分配给CPU.
在linux中, 进程的优先级是动态的.调度程序跟踪进程正在做什么,并周期性的调整他们的优先级. 在这种方式下, 在较长的时间间隔内没有任何使用CPU的进程, 通过动态地增加他们的优先级来提升他们. 相应地, 对于已经在CPU上运行了较长时间的进程, 通过减少他们的优先级来处罚他们.
22.1 进程饥饿
进程饥饿,即为Starvation,指当等待时间给进程推进和响应带来明显影响称为进程饥饿。当饥饿到一定程度的进程在等待到即使完成也无实际意义的时候称为饥饿死亡。
产生饥饿的主要原因是
在一个动态系统中,对于每类系统资源,操作系统需要确定一个分配策略,当多个进程同时申请某类资源时,由分配策略确定资源分配给进程的次序。
有时资源分配策略可能是不公平的,即不能保证等待时间上界的存在。在这种情况下,即使系统没有发生死锁,某些进程也可能会长时间等待.当等待时间给进程推进和响应带来明显影响时,称发生了进程饥饿,当饥饿到一定程度的进程所赋予的任务即使完成也不再具有实际意义时称该进程被饿死。
23 Linux进程的分类
23.1 进程的分类
当涉及有关调度的问题时, 传统上把进程分类为"I/O受限(I/O-dound)"或"CPU受限(CPU-bound)".
| 类型 | 别称 | 描述 | 示例 |
|---|---|---|---|
| I/O受限型 | I/O密集型 | 频繁的使用I/O设备, 并花费很多时间等待I/O操作的完成 | 数据库服务器, 文本编辑器 |
| CPU受限型 | 计算密集型 | 花费大量CPU时间进行数值计算 | 图形绘制程序 |
另外一种分类法把进程区分为三类:
| 类型 | 描述 | 示例 |
|---|---|---|
| 交互式进程(interactive process) | 此类进程经常与用户进行交互,因此需要花费很多时间等待键盘和鼠标操作. 当接受了用户的输入后, 进程必须很快被唤醒, 否则用户会感觉系统反应迟钝 | shell, 文本编辑程序和图形应用程序 |
| 批处理进程(batch process) | 此类进程不必与用户交互, 因此经常在后台运行. 因为这样的进程不必很快响应, 因此常受到调度程序的怠慢 | 程序语言的编译程序, 数据库搜索引擎以及科学计算 |
| 实时进程(real-time process) | 这些进程有很强的调度需要,这样的进程绝不会被低优先级的进程阻塞.并且他们的响应时间要尽可能的短 | 视频音频应用程序,机器人控制程序以及从物理传感器上收集数据的程序 |
一个批处理进程很有可能是I/O受限的(如数据库服务器),也可能是CPU受限的(比如图形绘制程序)
23.2 实时进程与普通进程
在linux中, 调度算法可以明确的确认所有实时进程的身份,但是没办法区分交互式程序和批处理程序(统称为普通进程)
对于实时进程,采用FIFO或者Round Robin的调度策略.
对于普通进程,则需要区分交互式和批处理式的不同。传统Linux调度器提高交互式应用的优先级,使得它们能更快地被调度。而CFS和RSDL等新的调度器的核心思想是"完全公平"。
注意Linux通过将进程和线程调度视为一个,进程调度也包含了线程调度的功能.
linux进程的调度算法其实经过了很多次的演变,但是其演变主要是针对与普通进程的. 实时进程和普通进程采用了不同的调度策略,更一般的普通进程还需要启发式的识别批处理进程和交互式进程.
目前实时进程的调度策略比较简单,因为实时进程只要求尽可能快的被响应, 基于优先级, 每个进程根据它重要程度的不同被赋予不同的优先级,调度器在每次调度时, 总选择优先级最高的进程开始执行.低优先级不可能抢占高优先级, 因此FIFO或者Round Robin的调度策略即可满足实时进程调度的需求.
但是普通进程的调度策略就比较麻烦了,因为普通进程不能简单的只看优先级,必须公平的占有CPU,否则很容易出现进程饥饿.
此外系统中进程如果存在实时进程, 则实时进程总是在普通进程之前被调度
24 linux调度器的演变
| 字段 | 版本 |
|---|---|
| O(n)的始调度算法 | linux-0.11~2.4 |
| O(1)调度器 | linux-2.5 |
| CFS调度器 | linux-2.6~至今 |
24.1 O(n)的始调度算法
一开始的调度器是复杂度为O(n)的始调度算法(实际上每次会遍历所有任务,所以复杂度为O(n)), 活动的任务越多, 调度任务所花费的时间越长. 在任务负载非常重时, 处理器会因调度消耗掉大量的时间, 用于任务本身的时间就非常少了。因此,这个算法缺乏可伸缩性
调度器采用基于优先级的设计. 该调度器的pick next算法非常简单:对runqueue中所有进程的优先级进行依次进行比较,选择最高优先级的进程作为下一个被调度的进程。(Runqueue是Linux 内核中保存所有就绪进程的队列). pick next用来指从所有候选进程中挑选下一个要被调度的进程的过程。
在每次进程切换时,内核扫描可运行进程的链表,计算优先级,然后选择"最佳"进程来运行.
每个进程被创建时都被赋予一个时间片。时钟中断递减当前运行进程的时间片,当进程的时间片被用完时,它必须等待重新赋予时间片才能有机会运行。Linux2.4调度器保证只有当所有RUNNING进程的时间片都被用完之后,才对所有进程重新分配时间片。这段时间被称为一个epoch。这种设计保证了每个进程都有机会得到执行。每个epoch中,每个进程允许执行到其时间切片用完。如果某个进程没有使用其所有的时间切片,那么剩余时间切片的一半将被添加到新时间切片使其在下个epoch中可以执行更长时间。调度器只是迭代进程,应用goodness函数(指标)决定下面执行哪个进程。当然,各种进程对调度的需求并不相同,Linux 2.4调度器主要依靠改变进程的优先级,来满足不同进程的调度需求。事实上,所有后来的调度器都主要依赖修改进程优先级来满足不同的调度需求。
实时进程:实时进程的优先级是静态设定的,而且始终大于普通进程的优先级。因此只有当runqueue中没有实时进程的情况下,普通进程才能够获得调度。
实时进程采用两种调度策略,SCHED_FIFO 和 SCHED_RR
FIFO 采用先进先出的策略,对于所有相同优先级的进程,最先进入 runqueue 的进程总能优先获得调度;Round Robin采用更加公平的轮转策略,使得相同优先级的实时进程能够轮流获得调度。
普通进程:对于普通进程,调度器倾向于提高交互式进程的优先级,因为它们需要快速的用户响应。普通进程的优先级主要由进程描述符中的Counter字段决定 (还要加上 nice 设定的静态优先级) 。进程被创建时子进程的 counter值为父进程counter值的一半,这样保证了任何进程不能依靠不断地 fork() 子进程从而获得更多的执行机会。
Linux2.4内核是非抢占的,当进程处于内核态时不会发生抢占,这对于真正的实时应用是不能接受的。
24.2 O(1)调度器
linux2.5开始引入赫赫有名的O(1)调度器
进程优先级的最大值为139,因此MAX_PRIO的最大值取140(具体的是,普通进程使用100到139的优先级,实时进程使用0到99的优先级).
因此,该调度算法为每个优先级都设置一个可运行队列,即包含140个可运行状态的进程链表。
除此之外, 还包括一个优先级位图bitmap。该位图使用一个位(bit)来代表一个优先级,而140个优先级最少需要5个32位来表示,因此只需要一个int[5]就可以表示位图,该位图中的所有位都被置0,当某个优先级的进程处于可运行状态时,该优先级所对应的位就被置1。
如果确定了优先级,那么选取下一个进程就简单了,只需在queue数组中对应的链表上选取一个进程即可。
24.3 CFS调度器Completely Fair Scheduler
24.3.1 楼梯调度算法staircase scheduler(SD)
楼梯算法(SD)在思路上和O(1)算法有很大不同,它抛弃了动态优先级的概念。而采用了一种完全公平的思路。前任算法的主要复杂性来自动态优先级的计算,调度器根据平均睡眠时间和一些很难理解的经验公式来修正进程的优先级以及区分交互式进程。这样的代码很难阅读和维护。楼梯算法思路简单,但是实验证明它对应交互式进程的响应比其前任更好,而且极大地简化了代码。
和O(1)算法一样,楼梯算法也同样为每一个优先级维护一个进程列表,并将这些列表组织在active数组中。当选取下一个被调度进程时,SD算法也同样从active数组中直接读取。
与O(1)算法不同在于,当进程用完了自己的时间片后,并不是被移到expire数组中。而是被加入active数组的低一优先级列表中,即将其降低一个级别。不过请注意这里只是将该任务插入低一级优先级任务列表中,任务本身的优先级并没有改变(!!!)。当时间片再次用完,任务被再次放入更低一级优先级任务队列中。就象一部楼梯,任务每次用完了自己的时间片之后就下一级楼梯。任务下到最低一级楼梯时,如果时间片再次用完,它会回到初始优先级的下一级任务队列!!!中。比如某进程的优先级为1,当它到达最后一级台阶140后,再次用完时间片时将回到优先级为2的任务队列中,即第二级台阶。不过此时分配给该任务的time_slice将变成原来的2倍!!!。比如原来该任务的时间片time_slice为10ms,则现在变成了20ms。
基本的原则是,当任务下到楼梯底部时,再次用完时间片就回到上次下楼梯的起点的下一级台阶。并给予该任务相同于其最初分配的时间片。
总结如下:设任务本身优先级为P,当它从第N级台阶开始下楼梯并到达底部后,将回到第N+1级台阶。并且赋予该任务N+1倍的时间片。
以上描述的是普通进程的调度算法,实时进程还是采用原来的调度策略,即FIFO或者Round Robin。
楼梯算法能避免进程饥饿现象,高优先级的进程会最终和低优先级的进程竞争,使得低优先级进程最终获得执行机会。对于交互式应用,当进入睡眠状态时,与它同等优先级的其他进程将一步一步地走下楼梯,进入低优先级进程队列。当该交互式进程再次唤醒后,它还留在高处的楼梯台阶上,从而能更快地被调度器选中,加速了响应时间。
楼梯算法的优点:从实现角度看,SD基本上还是沿用了O(1)的整体框架,只是删除了O(1)调度器中动态修改优先级的复杂代码;还淘汰了expire数组,从而简化了代码。它最重要的意义在于证明了完全公平这个思想的可行性。
24.3.2 RSDL(Rotating Staircase Deadline Scheduler)
RSDL也是由Con Kolivas开发的,它是对SD算法的改进。核心的思想还是"完全公平"。没有复杂的动态优先级调整策略。
RSDL重新引入了expire数组。它为每一个优先级都分配了一个“组时间配额”,记为Tg(整个一个组的!!!);同一优先级的每个进程都拥有同样的"优先级时间配额(!!!)",用Tp表示。当进程用完了自身的Tp时,就下降到下一优先级进程组中。这个过程和SD相同,在RSDL中这个过程叫做minor rotation(次轮询)。请注意Tp不等于进程的时间片,而是小于进程的时间片。
下图表示了minor rotation。进程从priority1的队列中一步一步下到priority140之后回到priority2的队列中,这个过程如下图左边所示,然后从priority 2开始再次一步一步下楼,到底后再次反弹到priority3队列(!!!)中,如下图所示。
在SD算法中,处于楼梯底部的低优先级进程必须等待所有的高优先级进程执行完才能获得CPU。因此低优先级进程的等待时间无法确定。
在RSDL中,当高优先级进程组用完了它们的Tg(即组时间配额)时,无论该组中是否还有进程Tp尚未用完,所有属于该组的进程(!!!)都被强制降低到下一优先级进程组中。这样低优先级任务就可以在一个可以预计的未来得到调度。从而改善了调度的公平性。这就是RSDL中Deadline代表的含义。
进程用完了自己的时间片time_slice时(下图中T2),将放入expire数组指向的对应初始优先级队列中(priority 1)。
当active数组为空,或者所有的进程都降低到最低优先级时就会触发主轮询major rotation。Major rotation交换active数组和expire数组,所有进程都恢复到初始状态,再一次重新开始minor rotation的过程。
RSDL对交互式进程的支持:和SD同样的道理,交互式进程在睡眠时间时,它所有的竞争者都因为minor rotation而降到了低优先级进程队列中。当它重新进入RUNNING状态时,就获得了相对较高的优先级,从而能被迅速响应。
24.3.3 完全公平的调度器CFS
CFS是最终被内核采纳的调度器。它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间(!!!),也不再企图区分交互式进程(!!!)。它将所有的进程都统一对待,这就是公平的含义。
CFS百分之八十的工作可以用一句话概括:CFS在真实的硬件上模拟了完全理想的多任务处理器(!!!)。
在真实的硬件上,同一时刻我们只能运行单个进程,因此当一个进程占用CPU时,其它进程就必须等待,这就产生了不公平。但是在“完全理想的多任务处理器“下,每个进程都能同时!!!获得CPU的执行时间,即并行地每个进程占1/nr_running的时间。例如当系统中有两个进程时,CPU的计算时间被分成两份,每个进程获得50%。假设runqueue中有n个进程,当前进程运行了10ms。在“完全理想的多任务处理器”中,10ms应该平分给n个进程(不考虑各个进程的nice值),因此当前进程应得的时间是(10/n)ms,但是它却运行了10ms。所以CFS将惩罚当前进程,使其它进程能够在下次调度时尽可能取代当前进程。最终实现所有进程的公平调度。
CFS没有将任务维护在链表式的运行队列中,它抛弃了active/expire数组,而是对每个CPU维护一个以时间为顺序的红黑树。
该树方法能够良好运行的原因在于:
-
红黑树可以始终保持平衡,这意味着树上没有路径比任何其他路径长两倍以上。
-
由于红黑树是二叉树,查找操作的时间复杂度为O(logn)。但是除了最左侧查找以外,很难执行其他查找,并且最左侧的节点指针始终被缓存。
-
对于大多数操作(插入、删除、查找等),红黑树的执行时间为O(logn),而以前的调度程序通过具有固定优先级的优先级数组使用O(1)。O(logn)行为具有可测量的延迟,但是对于较大的任务数无关紧要.
-
红黑树可通过内部存储实现,即不需要使用外部分配即可对数据结构进行维护。
要实现平衡,CFS使用"虚拟运行时间"表示某个任务的时间量。任务的虚拟运行时越小,意味着任务被允许访问服务器的时间越短,其对处理器的需求越高。CFS还包含睡眠公平概念以便确保那些目前没有运行的任务(例如,等待 I/O)在其最终需要时获得相当份额的处理器。
25 Linux调度器的组成
25.1 2个调度器
可以用两种方法来激活调度
-
一种是直接的, 比如进程打算睡眠或出于其他原因放弃CPU
-
另一种是通过周期性的机制, 以固定的频率运行, 不时的检测是否有必要
因此当前linux的调度程序由两个调度器组成:
-
主调度器
-
周期性调度器
两者又统称为通用调度器(generic scheduler)或核心调度器(core scheduler)
并且每个调度器包括两个内容:调度框架(其实质就是两个函数框架)及调度器类
25.2 6种调度策略
linux内核目前实现了6种调度策略(即调度算法),用于对不同类型的进程进行调度,或者支持某些特殊的功能
比如SCHED_NORMAL和SCHED_BATCH调度普通的非实时进程,SCHED_FIFO和SCHED_RR和SCHED_DEADLINE则采用不同的调度策略调度实时进程,SCHED_IDLE则在系统空闲时调用idle进程.
idle的运行时机
idle 进程优先级为MAX_PRIO,即最低优先级。
早先版本中,idle是参与调度的,所以将其优先级设为最低,当没有其他进程可以运行时,才会调度执行idle
而目前的版本中idle并不在运行队列中参与调度,而是在cpu全局运行队列rq中含idle指针,指向idle进程, 在调度器发现运行队列为空的时候运行, 调入运行
| 字段 | 描述 | 所在调度器类 |
|---|---|---|
| SCHED_NORMAL | (也叫SCHED_OTHER)用于普通进程,通过CFS调度器实现。SCHED_BATCH用于非交互的处理器消耗型进程。SCHED_IDLE是在系统负载很低时使用 | CFS |
| SCHED_BATCH | SCHED_NORMAL普通进程策略的分化版本。采用分时策略,根据动态优先级(可用nice()API设置),分配CPU运算资源。注意:这类进程比上述两类实时进程优先级低,换言之,在有实时进程存在时,实时进程优先调度。但针对吞吐量优化,除了不能抢占外与常规任务一样,允许任务运行更长时间,更好地使用高速缓存,适合于成批处理的工作 | CFS |
| SCHED_IDLE | 优先级最低,在系统空闲时才跑这类进程(如利用闲散计算机资源跑地外文明搜索,蛋白质结构分析等任务,是此调度策略的适用者) | CFS-IDLE |
| SCHED_FIFO | 先入先出调度算法(实时调度策略),相同优先级的任务先到先服务,高优先级的任务可以抢占低优先级的任务 | RT |
| SCHED_RR | 轮流调度算法(实时调度策略),后者提供 Round-Robin 语义,采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,同样,高优先级的任务可以抢占低优先级的任务。不同要求的实时任务可以根据需要用sched_setscheduler() API设置策略 | RT |
| SCHED_DEADLINE | 新支持的实时进程调度策略,针对突发型计算,且对延迟和完成时间高度敏感的任务适用。基于Earliest Deadline First (EDF) 调度算法 | DL |
SCHED_BATCH用于非交互的处理器消耗型进程
SCHED_IDLE是在系统负载很低时使用CFS
SCHED_BATCH用于非交互, CPU使用密集型的批处理进程. 调度决策对此类进程给予"冷处理": 他们绝不会抢占CFS调度器处理的另一个进程, 因此不会干扰交互式进程. 如果打算使用nice值降低进程的静态优先级, 同时又不希望该进程影响系统的交互性, 此时最适合使用该调度类.
而SCHED_LDLE进程的重要性则会进一步降低, 因此其权重总是最小的
注意
尽管名称是SCHED_IDLE但是SCHED_IDLE不负责调度空闲进程. 空闲进程由内核提供单独的机制来处理
SCHED_RR和SCHED_FIFO用于实现软实时进程. SCHED_RR实现了轮流调度算法, 一种循环时间片的方法, 而SCHED_FIFO实现了先进先出的机制, 这些并不是由完全贡品调度器类CFS处理的, 而是由实时调度类处理.
linux内核实现的6种调度策略,前面三种策略使用的是cfs调度器类,后面两种使用rt调度器类,最后一个使用DL调度器类
25.3 5个调度器类
而依据其调度策略的不同实现了5个调度器类,一个调度器类可以用一种或者多种调度策略调度某一类进程, 也可以用于特殊情况或者调度特殊功能的进程.
| 调度器类 | 描述 | 对应调度策略 |
|---|---|---|
| stop_sched_class | 优先级最高的线程,会中断所有其他线程,且不会被其他任务打断 作用: 1.发生在cpu_stop_cpu_callback 进行cpu之间任务migration 2.HOTPLUG_CPU的情况下关闭任务 |
无, 不需要调度普通进程 |
| dl_sched_class | 采用EDF最早截至时间优先算法调度实时进程 | SCHED_DEADLINE |
| rt_sched_class | 采用提供Roound-Robin算法或者FIFO算法调度实时进程 具体调度策略由进程的task_struct->policy指定 |
SCHED_FIFO, SCHED_RR |
| fair_sched_clas | 采用CFS算法调度普通的非实时进程 | SCHED_NORMAL, SCHED_BATCH |
| idle_sched_class | 采用CFS算法调度idle进程,每个cup的第一个pid=0线程:swapper,是一个静态线程。调度类属于:idel_sched_class,所以在ps里面是看不到的。一般运行在开机过程和cpu异常的时候做dump | SCHED_IDLE |
这5种调度类通过next指针串联在一起, 其所属进程的优先级顺序为
stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class25.4 3个调度实体
调度器不限于调度进程,还可以调度更大的实体,比如实现组调度:可用的CPU时间首先在一半的进程组(比如, 所有进程按照所有者分组)之间分配, 接下来分配的时间再在组内进行二次分配.
这种一般性要求调度器不直接操作进程,而是处理可调度实体,因此需要一个通用的数据结构描述这个调度实体,即seched_entity结构,其实际上就代表了一个调度对象,可以为一个进程,也可以为一个进程组.
linux中针对当前可调度的实时和非实时进程, 定义了类型为seched_entity的3个调度实体
| 调度实体 | 名称 | 描述 | 对应调度器类 |
|---|---|---|---|
| sched_dl_entity | DEADLINE调度实体 | 采用EDF算法调度的实时调度实体 | dl_sched_class |
| sched_rt_entity | RT调度实体 | 采用Roound-Robin或者FIFO算法调度的实时调度实体 | rt_sched_class |
| sched_entity | CFS调度实体 | 采用CFS算法调度的普通非实时进程的调度实体 | fair_sched_class |
内核中调度器相关数据结构的关系如图所示,看起来很复杂,其实它们是有关联的。
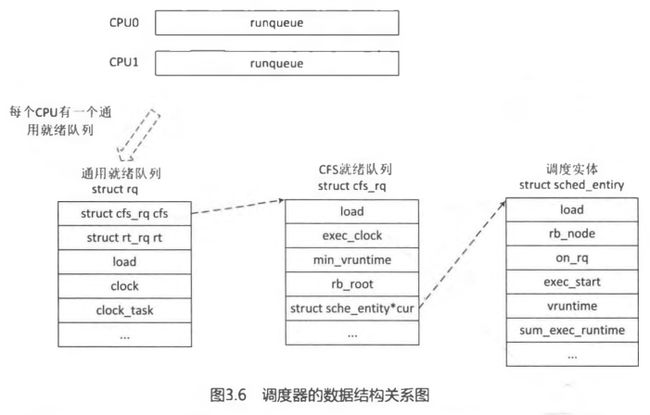
25.5 调度器类的就绪队列
另外,对于调度框架及调度器类,它们都有自己管理的运行队列,调度框架只识别rq(其实它也不能算是运行队列),而对于cfs调度器类它的运行队列则是cfs_rq(内部使用红黑树组织调度实体),实时rt的运行队列则为rt_rq(内部使用优先级bitmap+双向链表组织调度实体), 此外内核对新增的dl实时调度策略也提供了运行队列dl_rq
25.6 调度器整体框架
本质上, 通用调度器(核心调度器)是一个分配器,与其他两个组件交互.
- 调度器用于判断接下来运行哪个进程.
内核支持不同的调度策略(完全公平调度,实时调度,在无事可做的时候调度空闲进程<即0号进程也叫swapper进程>,idle进程), 调度类使得能够以模块化的方法实现这些策略,即一个类的代码不需要与其他类的代码交互
当调度器被调用时, 他会查询调度器类, 得知接下来运行哪个进程
- 在选中将要运行的进程之后, 必须执行底层的任务切换.
每个进程都属于某个调度器类(由字段task_struct->sched_class标识), 由调度器类采用进程对应的调度策略调度(由task_struct->policy)进行调度, task_struct也存储了其对应的调度实体标识
linux实现了6种调度策略, 依据其调度策略的不同实现了5个调度器类, 一个调度器类可以用一种或者多种调度策略调度某一类进程, 也可以用于特殊情况或者调度特殊功能的进程.
| 调度器类 | 调度策略 | 调度策略对应的调度算法 | 调度实体 | 调度实体对应的调度对象 |
|---|---|---|---|---|
| stop_sched_class | 无 | 无 | 无 | 特殊情况,发生在cpu_stop_cpu_callback进行cpu之间任务迁移migration或者HOTPLUG_CPU的情况下关闭任务 |
| dl_sched_class | SCHED_DEADLINE | Earliest-Deadline-First最早截至时间有限算法 | sched_dl_entity | 采用DEF最早截至时间有限算法调度实时进程 |
| rt_sched_class | SCHED_RR SCHED_FIFO |
Roound-Robin时间片轮转算法 FIFO先进先出算法 |
sched_rt_entity | 采用Roound-Robin或者FIFO算法调度的实时调度实体 |
| fair_sched_class | SCHED_NORMAL SCHED_BATCH |
CFS完全公平懂调度算法 | sched_entity | 采用CFS算法普通非实时进程 |
| idle_sched_class | SCHED_IDLE | 无 | 无 | 特殊进程, 用于cpu空闲时调度空闲进程idle |
调度器组成的关系如下图
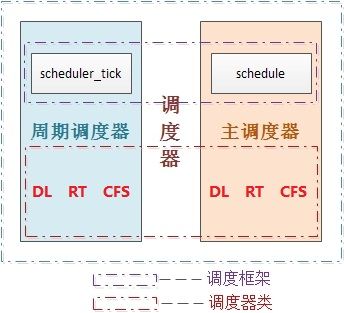
25.7 5种调度器类为什么只有3种调度实体?
正常来说一个调度器类应该对应一类调度实体, 但是5种调度器类却只有了3种调度实体?
这是因为调度实体本质是一个可以被调度的对象, 要么是一个进程(linux中线程本质上也是进程), 要么是一个进程组, 只有dl_sched_class,rt_sched_class调度的实时进程(组)以及fair_sched_class调度的非实时进程(组)是可以被调度的实体对象,而stop_sched_class和idle_sched_class没有调度实体
为什么采用EDF实时调度需要单独的调度器类, 调度策略和调度实体
linux针对实时进程实现了Roound-Robin, FIFO和Earliest-Deadline-First(EDF)算法, 但是为什么SCHED_RR和SCHED_FIFO两种调度算法都用rt_sched_class调度类和sched_rt_entity调度实体描述, 而EDF算法却需要单独用rt_sched_class调度类和sched_dl_entity调度实体描述
为什么采用EDF实时调度不用rt_sched_class调度类调度, 而是单独实现调度类和调度实体?
26 进程调度的数据结构
26.1 task_struct中调度相关的成员
struct task_struct
{
/* 表示是否在运行队列 */
int on_rq;
/* 进程优先级
* prio: 动态优先级,范围为100~139,与静态优先级和补偿(bonus)有关
* static_prio: 静态优先级,static_prio = 100 + nice + 20 (nice值为-20~19,所以static_prio值为100~139)
* normal_prio: 没有受优先级继承影响的常规优先级,具体见normal_prio函数,跟属于什么类型的进程有关
*/
int prio, static_prio, normal_prio;
/* 实时进程优先级 */
unsigned int rt_priority;
/* 调度类,调度处理函数类 */
const struct sched_class *sched_class;
/* 调度实体(红黑树的一个结点) */
struct sched_entity se;
/* 调度实体(实时调度使用) */
struct sched_rt_entity rt;
struct sched_dl_entity dl;
#ifdef CONFIG_CGROUP_SCHED
/* 指向其所在进程组 */
struct task_group *sched_task_group;
#endif
}26.1.1 优先级
int prio, static_prio, normal_prio;
unsigned int rt_priority;动态优先级 静态优先级 实时优先级
其中task_struct采用了三个成员表示进程的优先级: prio和normal_prio表示动态优先级, static_prio表示进程的静态优先级.
为什么表示动态优先级需要两个值prio和normal_prio
调度器会考虑的优先级则保存在prio. 由于在某些情况下内核需要暂时提高进程的优先级, 因此需要用prio表示. 由于这些改变不是持久的, 因此静态优先级static_prio和普通优先级normal_prio不受影响.
此外还用了一个字段rt_priority保存了实时进程的优先级
| 字段 | 描述 |
|---|---|
| static_prio | 用于保存静态优先级, 是进程启动时分配的优先级, ,可以通过nice和sched_setscheduler系统调用来进行修改, 否则在进程运行期间会一直保持恒定 |
| prio | 保存进程的动态优先级 |
| normal_prio | 表示基于进程的静态优先级static_prio和调度策略计算出的优先级. 因此即使普通进程和实时进程具有相同的静态优先级, 其普通优先级也是不同的, 进程分叉(fork)时, 子进程会继承父进程的普通优先级 |
| rt_priority | 用于保存实时优先级, 实时进程的优先级用实时优先级rt_priority来表示 |
linux2.6内核将任务优先级进行了一个划分,实时进程优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(即100到139)。
[include/linux/sched/prio.h]
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
[include/linux/sched/prio.h]
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20)| 优先级范围 | 描述 |
|---|---|
| 0 - 99 | 实时进程 |
| 100 - 139 | 非实时进程 |
- prio: 动态优先级,范围为100~139,与静态优先级和补偿(bonus)有关
- static_prio: 静态优先级,static_prio = 100 + nice + 20 (nice值为-20~19, 所以static_prio值为100~139)
- normal_prio: 没有受优先级继承影响的常规优先级,具体见normal_prio函数,跟属于什么类型的进程有关
26.1.2 调度策略
unsigned int policy;policy保存了进程的调度策略,目前主要有以下五种:
[include/uapi/linux/sched.h]
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 626.1.3 调度策略相关字段
[include/linux/sched.h]
unsigned int policy;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
cpumask_t cpus_allowed;| 字段 | 描述 |
|---|---|
| sched_class | 调度类, 调度类,调度处理函数类 |
| se | 普通进程的调用实体, 每个进程都有其中之一的实体 |
| rt | 实时进程的调用实体, 每个进程都有其中之一的实体 |
| dl | deadline的调度实体 |
| cpus_allowed | 用于控制进程可以在哪里处理器上运行 |
调度器不限于调度进程, 还可以调度更大的实体, 比如实现组调度: 可用的CPU时间首先在一半的进程组(比如, 所有进程按照所有者分组)之间分配, 接下来分配的时间再在组内进行二次分配
cpus_allows是一个位域, 在多处理器系统上使用, 用来限制进程可以在哪些CPU上运行
26.2 调度类
sched_class结构体表示调度类, 类提供了通用调度器和各个调度器之间的关联, 调度器类和特定数据结构中汇集地几个函数指针表示, 全局调度器请求的各个操作都可以用一个指针表示, 这使得无需了解调度器类的内部工作原理即可创建通用调度器, 定义在[kernel/sched/sched.h]
对于各个调度器类, 都必须提供struct sched_class的一个实例, 目前内核中有实现以下五种:
[kernel/sched/sched.h]
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;开发者可以根据己的设计需求,來把所属的Task配置到不同的Scheduling Class中.
用户层应用程序无法直接与调度类交互(!!!),他们只知道上下文定义的常量SCHED_XXX(用task_struct->policy表示), 这些常量提供了调度类之间的映射。
26.3 就绪队列
就绪队列是核心调度器用于管理活动进程的主要数据结构。
各个CPU都有自身的就绪队列,各个活动进程只出现在一个就绪队列中,在多个CPU上同时运行一个进程是不可能(!!!)的.
早期的内核中就绪队列是全局的,即有全局唯一的rq,但是在Linux-2.6内核时代,为了更好的支持多核,Linux调度器普遍采用了per-cpu的run queue,从而克服了多CPU系统中,全局唯一的run queue由于资源的竞争而成为了系统瓶颈的问题,因为在同一时刻,一个CPU访问run queue时,其他的CPU即使空闲也必须等待,大大降低了整体的CPU利用率和系统性能。当使用per-CPU的run queue之后,每个CPU不再使用大内核锁,从而大大提高了并行处理的调度能力。
就绪队列是全局调度器许多操作的起点, 但是进程并不是由就绪队列直接管理的, 调度管理是各个调度器的职责, 因此在各个就绪队列中嵌入了特定调度类的子就绪队列(cfs的就绪队列struct cfs_rq, 实时调度类的就绪队列struct rt_rq和deadline调度类的就绪队列struct dl_rq
每个CPU(!!!)都有自己的struct rq结构,其用于描述在此CPU上所运行的所有进程,其包括一个实时进程队列!!!和一个根CFS运行队列!!!,在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去CFS运行队列找是否有进行需要运行,这就是为什么常说的实时进程优先级比普通进程高,不仅仅体现在prio优先级上,还体现在调度器的设计上,至于dl运行队列,我暂时还不知道有什么用处,其优先级比实时进程还高,但是创建进程时如果创建的是dl进程创建会错误(具体见sys_fork)。
26.3.1 CPU就绪队列struct rq
就绪队列用struct rq来表示, 每个处理器都会配置一个rq, 其定义在[kernel/sched/sched.h]
| 字段 | 描述 |
|---|---|
| nr_running | 队列上可运行进程的数目, 不考虑优先级和调度类 |
| load | 提供了就绪队列当前负荷的度量, 队列的负荷本质上与队列上当前活动进程的数目成正比, 其中的各个进程又有优先级作为权重. 每个就绪队列的虚拟时钟的速度等于该信息 |
| cpu_load | 用于跟踪此前的负荷状态 |
| cfs,rt 和dl | 嵌入的子就绪队列, 分别用于完全公平调度器, 实时调度器和deadline调度器 |
| curr | 当前运行的进程的task_struct实例 |
| idle | 指向空闲进程的task_struct实例 |
| clock | 就绪队列自身的时钟 |
系统中所有的就绪队列都在runqueues数组(!!!)中,该数组的每个元素分别对应于系统中的一个CPU,如果是单处理器系统只有一个就绪队列, 则数组就只有一个元素
内核中也提供了一些宏, 用来获取cpu上的就绪队列的信息
[kernel/sched/sched.h]
DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
#define this_rq() this_cpu_ptr(&runqueues)
#define task_rq(p) cpu_rq(task_cpu(p))
#define cpu_curr(cpu) (cpu_rq(cpu)->curr)
#define raw_rq() raw_cpu_ptr(&runqueues)
26.3.2 CFS公平调度器的就绪队列cfs_rq
在系统中至少有一个CFS运行队列,其就是根CFS运行队列,而其他的进程组和进程都包含在此运行队列中(!!!),不同的是进程组又有它自己的CFS运行队列,其运行队列中包含的是此进程组中的所有进程。当调度器从根CFS运行队列中选择了一个进程组进行调度时,进程组会从自己的CFS运行队列中选择一个调度实体进行调度(这个调度实体可能为进程,也可能又是一个子进程组!!!),就这样一直深入,直到最后选出一个进程进行运行为止
struct cfs_rq其代表着一个CFS运行队列,并且包含有一个红黑树进行选择调度进程即可。其定义在[kernel/sched/sched.h]
每个CPU的rq会包含一个cfs_rq,而每个组调度的sched_entity也会有自己的一个cfs_rq队列
/* CFS-related fields in a runqueue */
/* CFS调度的运行队列,每个CPU的rq会包含一个cfs_rq,而每个组调度的sched_entity也会有自己的一个cfs_rq队列 */
struct cfs_rq {
/* CFS运行队列中所有进程的总负载 */
struct load_weight load;
/*
* nr_running: cfs_rq中调度实体数量
* h_nr_running: 只对进程组有效,其下所有进程组中cfs_rq的nr_running之和
*/
unsigned int nr_running, h_nr_running;
u64 exec_clock;
/*
* 当前CFS队列上最小运行时间,单调递增
* 两种情况下更新该值:
* 1、更新当前运行任务的累计运行时间时
* 2、当任务从队列删除去,如任务睡眠或退出,这时候会查看剩下的任务的vruntime是否大于min_vruntime,如果是则更新该值。
*/
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
/* 该红黑树的root */
struct rb_root tasks_timeline;
/* 下一个调度结点(红黑树最左边结点,最左边结点就是下个调度实体) */
struct rb_node *rb_leftmost;
/*
* curr: 当前正在运行的sched_entity(对于组虽然它不会在cpu上运行,但是当它的下层有一个task在cpu上运行,那么它所在的cfs_rq就把它当做是该cfs_rq上当前正在运行的sched_entity)
* next: 表示有些进程急需运行,即使不遵从CFS调度也必须运行它,调度时会检查是否next需要调度,有就调度next
*
* skip: 略过进程(不会选择skip指定的进程调度)
*/
struct sched_entity *curr, *next, *last, *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg;
u64 runnable_load_sum;
unsigned long runnable_load_avg;
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
#endif
atomic_long_t removed_load_avg, removed_util_avg;
#ifndef CONFIG_64BIT
u64 load_last_update_time_copy;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
/* 所属于的CPU rq */
struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */
int on_list;
struct list_head leaf_cfs_rq_list;
/* 拥有该CFS运行队列的进程组 */
struct task_group *tg; /* group that "owns" this runqueue */
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock, throttled_clock_task;
u64 throttled_clock_task_time;
int throttled, throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};| 成员 | 描述 |
|---|---|
| nr_running | 队列上可运行进程的数目 |
| load | 就绪队列上可运行进程的累计负荷权重 |
| min_vruntime | 跟踪记录队列上所有进程的最小虚拟运行时间. 这个值是实现与就绪队列相关的虚拟时钟的基础 |
| tasks_timeline | 用于在按时间排序的红黑树中管理所有进程 |
| rb_leftmost | 总是设置为指向红黑树最左边的节点, 即需要被调度的进程. 该值其实可以可以通过病例红黑树获得, 但是将这个值存储下来可以减少搜索红黑树花费的平均时间 |
| curr | 当前正在运行的sched_entity(对于组虽然它不会在cpu上运行,但是当它的下层有一个task在cpu上运行,那么它所在的cfs_rq就把它当做是该cfs_rq上当前正在运行的sched_entity |
| next | 表示有些进程急需运行,即使不遵从CFS调度也必须运行它,调度时会检查是否next需要调度,有就调度next |
| skip | 略过进程(不会选择skip指定的进程调度) |
26.3.3 实时进程就绪队列rt_rq
其定义在[kernel/sched/sched.h]
26.3.4 deadline就绪队列dl_rq
其定义在[kernel/sched/sched.h]
26.4 调度实体
调度器不限于调度进程, 还可以调度更大的实体, 比如实现组调度: 可用的CPU时间首先在一半的进程组(比如,所有进程按照所有者分组)之间分配, 接下来分配的时间再在组内进行二次分配.
这种一般性要求调度器不直接操作进程!!!, 而是处理可调度实体!!!, 因此需要一个通用的数据结构描述这个调度实体,即seched_entity结构, 其实际上就代表了一个调度对象,可以为一个进程,也可以为一个进程组。对于根的红黑树而言,一个进程组就相当于一个调度实体,一个进程也相当于一个调度实体。
26.4.1 普通进程调度实体sched_entity
定义在[include/linux/sched.h]
在struct sched_entity结构中,值得我们注意的成员是
| 字段 | 描述 |
|---|---|
| load | 指定了权重, 决定了各个实体占队列总负荷的比重, 计算负荷权重是调度器的一项重任, 因为CFS所需的虚拟时钟的速度最终依赖于负荷, 权重通过优先级转换而成,是vruntime计算的关键 |
| run_node | 调度实体在红黑树对应的结点信息, 使得调度实体可以在红黑树上排序 |
| sum_exec_runtime | 记录程序运行所消耗的CPU时间, 以用于完全公平调度器CFS |
| on_rq | 调度实体是否在就绪队列上接受检查,表明是否处于CFS红黑树运行队列中,需要明确一个观点就是,CFS运行队列里面包含有一个红黑树,但这个红黑树并不是CFS运行队列的全部,因为红黑树仅仅是用于选择出下一个调度程序的算法。很简单的一个例子,普通程序运行时,其并不在红黑树中!!!,但是还是处于CFS运行队列中,其on_rq为真。只有准备退出、即将睡眠等待和转为实时进程的进程其CFS运行队列的on_rq为假 |
| vruntime | 虚拟运行时间,调度的关键,其计算公式:一次调度间隔的虚拟运行时间 = 实际运行时间 * (NICE_0_LOAD / 权重)。可以看出跟实际运行时间和权重有关,红黑树就是以此作为排序的标准,优先级越高的进程在运行时其vruntime增长的越慢,其可运行时间相对就长,而且也越有可能处于红黑树的最左结点,调度器每次都选择最左边的结点为下一个调度进程。注意其值为单调递增,在每个调度器的时钟中断时当前进程的虚拟运行时间都会累加。单纯的说就是进程们都在比谁的vruntime最小,最小的将被调度 |
| cfs_rq | 此调度实体所处于的CFS运行队列 |
| my_q | 如果此调度实体代表的是一个进程组,那么此调度实体就包含有一个自己的CFS运行队列,其CFS运行队列中存放的是此进程组中的进程,这些进程就不会在其他CFS运行队列的红黑树中被包含(包括顶层红黑树也不会包含他们,他们只属于这个进程组的红黑树) |
-
在进程运行时,我们需要记录消耗的CPU时间,以用于完全公平调度器.sum_exec_runtime就用于该目的.
-
跟踪运行时间是由update_curr不断累积完成的.内核中许多地方都会调用该函数,例如,新进程加入就绪队列时,或者周期性调度器中.每次调用时,会计算当前时间和exec_start之间的差值,exec_start则更新到当前时间.差值则被加到sum_exec_runtime.
-
在进程执行期间虚拟时钟上流逝的时间数量由vruntime统计
-
在进程被撤销时,其当前sum_exec_runtime值保存到prev_sum_exec_runtime, 此后,进程抢占的时候需要用到该数据,但是注意,在prev_sum_exec_runtime中保存了sum_exec_runtime的值,而sum_exec_runtime并不会被重置,而是持续单调增长
每个进程的task_struct中都嵌入了sched_entity对象,所以进程是可调度的实体,但是请注意,其逆命一般是不正确的,即可调度的实体不一定是进程.
对于怎么理解一个进程组有它自己的CFS运行队列,其实很好理解,比如在根CFS运行队列的红黑树上有一个进程A一个进程组B,各占50%的CPU,对于根的红黑树而言,他们就是两个调度实体。调度器调度的不是进程A就是进程组B,而如果调度到进程组B,进程组B自己选择一个程序交给CPU运行就可以了,而进程组B怎么选择一个程序给CPU,就是通过自己的CFS运行队列的红黑树选择,如果进程组B还有个子进程组C,原理都一样,就是一个层次结构。
26.4.2 实时进程调度实体sched_rt_entity
26.4.3 EDF调度实体sched_dl_entity
26.5 组调度(struct task_group)
我们知道,linux是一个多用户系统,如果有两个进程分别属于两个用户,而进程的优先级不同,会导致两个用户所占用的CPU时间不同,这样显然是不公平!!!的(如果优先级差距很大,低优先级进程所属用户使用CPU的时间就很小),所以内核引入组调度。如果基于用户分组,即使进程优先级不同,这两个用户使用的CPU时间都为50%。
如果task_group中的运行时间还没有使用完,而当前进程运行时间使用完后,会调度task_group中的下一个被调度进程;相反,如果task_group的运行时间使用结束,则调用上一层的下一个被调度进程。需要注意的是,一个组调度中可能会有一部分是实时进程,一部分是普通进程,这也导致这种组要能够满足即能在实时调度中进行调度,又可以在CFS调度中进行调度。
linux可以以以下两种方式进行进程的分组:
-
用户ID:按照进程的USER ID进行分组,在对应的/sys/kernel/uid/目录下会生成一个cpu.share的文件,可以通过配置该文件来配置用户所占CPU时间比例。
-
cgourp(control group):生成组用于限制其所有进程,比如我生成一个组(生成后此组为空,里面没有进程),设置其CPU使用率为10%,并把一个进程丢进这个组中,那么这个进程最多只能使用CPU的10%,如果我们将多个进程丢进这个组,这个组的所有进程平分这个10%。
注意的是,这里的进程组概念和fork调用所产生的父子进程组概念不一样,文章所使用的进程组概念全为组调度中进程组的概念。为了管理组调度,内核引进了struct task_group结构
其定义在[kernel/sched/sched.h]
在struct task_group结构中,最重要的成员为 struct sched_entity ** se 和 struct cfs_rq ** cfs_rq。
在多核多CPU的情况下,同一进程组的进程有可能在不同CPU上同时运行,所以每个进程组都必须对每个CPU分配它的调度实体(struct sched_entity 和 struct sched_rt_entity)和运行队列(struct cfs_rq 和 struct rt_rq)。
27 进程调度小结
进程调度器的框架如下图所示

从图中可以看出来,每个CPU对应包含一个运行队列结构(struct rq),而每个运行队列又包含有其自己的实时进程运行队列(struct rt_rq)、普通进程运行队列(struct cfs_rq)、和deadline实时调度的运行队列(struct dl_rq),也就是说每个CPU都有他们自己的实时进程运行队列及普通进程运行队列
为了方便,我们在图中只描述普通进程的组织结构(最复杂的也是普通进程的组织结构),而红色se则为当前CPU上正在执行的程序,蓝色为下个将要执行的程序,其实图中并不规范,实际上当进程运行时,会从红黑树中剥离出来!!!,然后设定下一个调度进程,当进程运行时间结束时,再重新放入红黑树!!!中。而为什么CPU0上有两个蓝色将被调度进程,将在组调度中解释。而为什么红黑树中又有一个子红黑树,我们将在调度实体中解释。
通过的调度策略对象--调度类
linux下每个进程都有自身所属的调度类进行管理,sched_class结构体表示调度类, 调度类提供了通用调度器和各个调度器之间的关联,调度器类和特定数据结构中汇集地几个函数指针表示,全局调度器请求的各个操作都可以用一个指针表示, 这使得无需了解调度器类的内部工作原理即可创建通用调度器, 定义在kernel/sched/sched.h
开发者可以根据己的设计需求, 来把所属的Task配置到不同的Scheduling Class中.
用户层应用程序无法直接与调度类交互,他们只知道上下文定义的常量SCHED_XXX(用task_struct->policy表示), 这些常量提供了调度类之间的映射。
目前系統中,Scheduling Class的优先级顺序为
stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class被调度的实体--进程或者进程组
linux下被调度的不只是进程,还可以是进程组.因此需要一种更加通用的形式组织被调度数据结构, 即调度实体, 同样不同的进程用不同的调度实体表示
| 普通进程 | 实时进程 |
|---|---|
| sched_entity | rt_entity, sched_dl_entity |
用就绪队列保存和组织调度进程
所有的就绪进程(TASK_RUNNING)都被组织在就绪队列(!!!),也叫运行队列中,每个CPU对应包含一个运行队列结构(struct rq)(!!!),而每个运行队列又嵌入了有其自己的实时进程运行队列(struct rt_rq)、普通进程运行队列(struct cfs_rq)、和EDF实时调度的运行队列(struct dl_rq),也就是说每个CPU都有他们自己的实时进程运行队列及普通进程运行队列
| 全局 | 普通进程 | 实时进程 |
|---|---|---|
| rq | cfs_rq | rt_rq, dl_rq |
28 周期性调度器scheduler_tick
周期性调度器在scheduler_tick()中实现. 如果系统正在活动中,内核会按照频率HZ自动调用该函数. 如果没有进程在等待调度, 那么在计算机电力供应不足的情况下, 内核将关闭该调度器以减少能耗(!!!). 这对于我们的嵌入式设备或者手机终端设备的电源管理是很重要的.
28.1 周期性调度器主流程
scheduler_tick()函数定义在[kernel/sched/core.c]
它有两个主要任务
- 更新相关统计量
管理内核中的与整个系统和各个进程的调度相关的统计量. 其间执行的主要操作是对各种计数器+1
- 激活负责当前进程调度类!!!的周期性调度方法!!!
检查进程执行的时间是否超过了它对应的ideal_runtime,如果超过了,则告诉系统,需要启动主调度器(schedule)进行进程切换。(注意thread_info:preempt_count、thread_info:flags (TIF_NEED_RESCHED))
[kernel/sched/core.c]
void scheduler_tick(void)
{
/* 1. 获取当前cpu上的全局就绪队列rq和当前运行的进程curr */
/* 1.1 在于SMP的情况下,获得当前CPU的ID。如果不是SMP,那么就返回0 */
int cpu = smp_processor_id();
/* 1.2 获取cpu的全局就绪队列rq, 每个CPU都有一个就绪队列rq */
struct rq *rq = cpu_rq(cpu);
/* 1.3 获取就绪队列上正在运行的进程curr */
struct task_struct *curr = rq->curr;
sched_clock_tick();
/* 2 更新rq上的统计信息, 并执行进程对应调度类的周期性的调度 */
/* 加锁 */
raw_spin_lock(&rq->lock);
/* 2.1 更新rq的当前时间戳.即使rq->clock变为当前时间戳 */
update_rq_clock(rq);
/* 2.2 执行当前运行进程所在调度类的task_tick函数进行周期性调度 */
curr->sched_class->task_tick(rq, curr, 0);
/* 2.3 更新rq的负载信息, 即就绪队列的cpu_load[]数据
* 本质是讲数组中先前存储的负荷值向后移动一个位置,
* 将当前负荷记入数组的第一个位置 */
update_cpu_load_active(rq);
/* 2.4 更新cpu的active count活动计数
* 主要是更新全局cpu就绪队列的calc_load_update */
calc_global_load_tick(rq);
/* 解锁 */
raw_spin_unlock(&rq->lock);
/* 与perf计数事件相关 */
perf_event_task_tick();
#ifdef CONFIG_SMP
/* 当前CPU是否空闲 */
rq->idle_balance = idle_cpu(cpu);
/* 如果到是时候进行周期性负载平衡则触发SCHED_SOFTIRQ */
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}28.2 更新统计量
| 函数 | 描述 | 定义 |
|---|---|---|
| update_rq_clock | 处理就绪队列时钟的更新, 本质上就是增加struct rq当前实例的时钟时间戳 | sched/core.c, L98 |
| update_cpu_load_active | 负责更新就绪队列的cpu_load数组,其本质上相当于将数组中先前存储的负荷值向后移动一个位置,将当前就绪队列的负荷记入数组的第一个位置. 另外该函数还引入一些取平均值的技巧, 以确保符合数组的内容不会呈现太多的不联系跳读. | kernel/sched/fair.c, L4641 |
| calc_global_load_tick | 更新cpu的活动计数, 主要是更新全局cpu就绪队列的calc_load_update | kernel/sched/loadavg.c, L382 |
28.3 激活进程所属调度类的周期性调度器
由于调度器的模块化结构, 主体工程其实很简单, 在更新统计信息的同时, 内核将真正的调度工作委托给了特定的调度类方法
内核先找到了就绪队列上当前运行的进程curr, 然后调用curr所属调度类sched_class的周期性调度方法task_tick
即
curr->sched_class->task_tick(rq, curr, 0);task_tick()的实现方法取决于底层的调度器类, 例如完全公平调度器会在该方法中检测是否进程已经运行了太长的时间, 以避免过长的延迟, 注意此处的做法与之前就的基于时间片的调度方法有本质区别, 旧的方法我们称之为到期的时间片, 而完全公平调度器CFS中则不存在所谓的时间片概念.
内核中有5个调度器类
针对当前内核中实现的调度器类分别列出其周期性调度函数task_tick()
| 调度器类 | task_tick操作 | task_tick函数定义 |
|---|---|---|
| stop_sched_class | kernel/sched/stop_task.c, line 77, task_tick_stop | |
| dl_sched_class | kernel/sched/deadline.c, line 1192, task_tick_dl | |
| rt_sched_class | /kernel/sched/rt.c, line 2227, task_tick_rt | |
| fail_sched_class | kernel/sched/fair.c, line 8116, task_tick_fail | |
| idle_sched_class | kernel/sched/idle_task.c, line 53, task_tick_idle |
- 如果当前进程是完全公平队列中的进程, 则首先根据当前就绪队列中的进程数算出一个延迟时间间隔,大概每个进程分配2ms时间,然后按照该进程在队列中的总权重中占的比例,算出它该执行的时间X,如果该进程执行物理时间超过了X,则激发延迟调度;如果没有超过X,但是红黑树就绪队列中下一个进程优先级更高,即curr->vruntime - leftmost->vruntime > X, 也将延迟调度
延迟调度的真正调度过程在:schedule()中实现,会按照调度类顺序和优先级挑选出一个最高优先级的进程执行
- 如果当前进程是实时调度类中的进程:则如果该进程是SCHED_RR,则递减时间片为[HZ/10],到期,插入到队列尾部,并激发延迟调度,如果是SCHED_FIFO,则什么也不做,直到该进程执行完成
如果当前进程希望被重新调度,那么调度类方法会在task_struct中设置TIF_NEED_RESCHED标志,以表示该请求, 而内核将会在接下来的适当实际完成此请求.
29 周期性调度器的激活
29.1 定时器周期性的激活调度器
定时器是Linux提供的一种定时服务的机制. 它在某个特定的时间唤醒某个进程,来做一些工作.
在低分辨率定时器的每次时钟中断完成全局统计量更新后, 每个cpu(!!!)在软中断中执行以下操作
- 更新该cpu上当前进程内核态、用户态使用时间xtime_update
- 调用该cpu上的定时器函数
- 启动周期性定时器(scheduler_tick())完成该cpu上任务的周期性调度工作;
在支持动态定时器(!!!)的系统中,可以关闭该调度器(没有进程在等待调度时候!!!),从而进入深度睡眠过程;scheduler_tick()查看当前进程是否运行太长时间,如果是,将进程的TIF_NEED_RESCHED置位,然后在中断返回时,调用schedule(),进行进程切换操作
[arch/arm/kernel/time.c]
void timer_tick(void)
{
profile_tick(CPU_PROFILING);
xtime_update(1);
#ifndef CONFIG_SMP
update_process_times(user_mode(get_irq_regs()));
#endif
}
[kernel/time/timer.c]
void update_process_times(int user_tick)
{
struct task_struct *p = current;
/* Note: this timer irq context must be accounted for as well. */
account_process_tick(p, user_tick);
run_local_timers();
rcu_check_callbacks(user_tick);
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_tick();
#endif
// 周期性调度器
scheduler_tick();
run_posix_cpu_timers(p);
}29.2 定时器中断实现
在内核2.6版本以后,定时器中断处理采用了软中断机制而不是下半部机制。
时钟中断处理函数仍然为timer_interrupt()-> do_timer_interrupt()-> do_timer_interrupt_hook()-> do_timer()。
不过do_timer()函数的实现有所不同
void do_timer(struct pt_regs *regs)
{
jiffies_64++;
update_process_times(user_mode(regs));
update_times();
}30 主调度器schedule()
在内核中的许多地方, 如果要将CPU分配给与当前活动进程不同的另一个进程,都会直接调用主调度器函数schedule();
从系统调用返回后, 内核也会检查当前进程是否设置了重调度标志TLF_NEDD_RESCHED
例如, 前述的周期性调度器的scheduler_tick()就会设置该标志,如果是这样则内核会调用schedule(), 该函数假定当前活动进程一定会被另一个进程取代.
30.1 调度函数的__sched前缀
该前缀用于可能调用schedule()的函数,包括schedule()本身.
__sched前缀的声明, 在[include/linux/sched.h]
#define __sched __attribute__((__p__(".sched.text")))__attribute__((__p_("...")))是一个gcc的编译属性,其目的在于将相关的函数的代码编译之后, 放到目标文件的特定的段内,即.sched.text中.该信息使得内核在显示栈转储活类似信息时, 忽略所有与调度相关的调用. 由于调度函数调用不是普通代码流程的一部分, 因此在这种情况下是没有意义的.
用它修饰函数的方式如下
void __sched some_function(args, ...)
{
......
schedule();
......
}30.2 schedule()函数
30.2.1 schedule主框架
schedule()就是主调度器的函数, 在内核中的许多地方,如果要将CPU分配给与当前活动进程不同的另一个进程, 都会直接调用主调度器函数schedule().
该函数完成如下工作
-
确定当前就绪队列, 并在保存一个指向当前(仍然)活动进程的task_struct指针
-
检查死锁, 关闭内核抢占后调用__schedule完成内核调度
-
恢复内核抢占, 然后检查当前进程是否设置了重调度标志TLF_NEDD_RESCHED, 如果该进程被其他进程设置了TIF_NEED_RESCHED标志, 则函数重新执行进行调度
该函数定义在[kernel/sched/core.c], 如下所示
asmlinkage __visible void __sched schedule(void)
{
/* 获取当前的进程 */
struct task_struct *tsk = current;
/* 避免死锁 */
sched_submit_work(tsk);
do {
/* 关闭内核抢占 */
preempt_disable();
/* 完成调度 */
__schedule(false);
/* 开启内核抢占 */
sched_preempt_enable_no_resched();
/* 如果该进程被其他进程设置了TIF_NEED_RESCHED标志,则函数重新执行进行调度 */
} while (need_resched());
}
EXPORT_SYMBOL(schedule);30.2.2 sched_submit_work()避免死锁
该函数定义在[kernel/sched/core.c]
30.2.3 preempt_disable和sched_preempt_enable_no_resched开关内核抢占
如果进程正执行内核函数时,即它在内核态运行时,允许发生内核切换(被替换的进程是正执行内核函数的进程),这个内核就是抢占的。
抢占内核的主要特点是:一个在内核态运行的进程,当且仅当在执行内核函数期间被另外一个进程取代。
这与用户态的抢占有本质区别.
定义在[include/linux/preempt.h]
#define preempt_disable() \
do { \
preempt_count_inc(); \
barrier(); \
} while (0)
#define sched_preempt_enable_no_resched() \
do { \
barrier(); \
preempt_count_dec(); \
} while (0)30.3 __schedule()开始进程调度
__schedule()完成了真正的调度工作, 其定义在[kernel/sched/core.c]
30.3.1 __schedule()函数主框架
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
/* ==1==
找到当前cpu上的就绪队列rq
并将正在运行的进程curr保存到prev中 */
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
if (unlikely(prev->state == TASK_DEAD))
preempt_enable_no_resched_notrace();
/* 如果禁止内核抢占,而又调用了cond_resched就会出错
* 这里就是用来捕获该错误的 */
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/* 关闭本地中断 */
local_irq_disable();
/* 更新全局状态,
* 标识当前CPU发生上下文的切换 */
rcu_note_context_switch();
smp_mb__before_spinlock();
/* 锁住该队列 */
raw_spin_lock(&rq->lock);
lockdep_pin_lock(&rq->lock);
rq->clock_skip_update <<= 1; /* promote REQ to ACT */
/* 切换次数记录, 默认认为非主动调度计数(抢占) */
switch_count = &prev->nivcsw;
/*
* scheduler检查prev的状态state和内核抢占表示
* 如果prev是不可运行的, 并且在内核态没有被抢占
*
* 此时当前进程不是处于运行态, 并且不是被抢占
* 此时不能只检查抢占计数
* 因为可能某个进程(如网卡轮询)直接调用了schedule
* 如果不判断prev->stat就可能误认为task进程为RUNNING状态
* 到达这里,有两种可能,一种是主动schedule, 另外一种是被抢占
* 被抢占有两种情况, 一种是时间片到点, 一种是时间片没到点
* 时间片到点后, 主要是置当前进程的need_resched标志
* 接下来在时钟中断结束后, 会preempt_schedule_irq抢占调度
*
* 那么我们正常应该做的是应该将进程prev从就绪队列rq中删除,
* 但是如果当前进程prev有非阻塞等待信号,
* 并且它的状态是TASK_INTERRUPTIBLE
* 我们就不应该从就绪队列总删除它
* 而是配置其状态为TASK_RUNNING, 并且把他留在rq中
/* 如果内核态没有被抢占, 并且内核抢占有效
即是否同时满足以下条件:
1 该进程处于停止状态
2 该进程没有在内核态被抢占 */
if (!preempt && prev->state)
{
/* 如果当前进程有非阻塞等待信号,并且它的状态是TASK_INTERRUPTIBLE */
if (unlikely(signal_pending_state(prev->state, prev)))
{
/* 将当前进程的状态设为:TASK_RUNNING */
prev->state = TASK_RUNNING;
}
else /* 否则需要将prev进程从就绪队列中删除*/
{
/* 将当前进程从runqueue(运行队列)中删除 */
deactivate_task(rq, prev, DEQUEUE_SLEEP);
/* 标识当前进程不在runqueue中 */
prev->on_rq = 0;
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
/* 如果不是被抢占的,就累加主动切换次数 */
switch_count = &prev->nvcsw;
}
/* 如果prev进程仍然在就绪队列上没有被删除 */
if (task_on_rq_queued(prev))
update_rq_clock(rq); /* 跟新就绪队列的时钟 */
/* 挑选一个优先级最高的任务将其排进队列 */
next = pick_next_task(rq, prev);
/* 清除pre的TIF_NEED_RESCHED标志 */
clear_tsk_need_resched(prev);
/* 清楚内核抢占标识 */
clear_preempt_need_resched();
rq->clock_skip_update = 0;
/* 如果prev和next非同一个进程 */
if (likely(prev != next))
{
rq->nr_switches++; /* 队列切换次数更新 */
rq->curr = next; /* 将next标记为队列的curr进程 */
++*switch_count; /* 进程切换次数更新 */
trace_sched_switch(preempt, prev, next);
/* 进程之间上下文切换 */
rq = context_switch(rq, prev, next); /* unlocks the rq */
}
else /* 如果prev和next为同一进程,则不进行进程切换 */
{
lockdep_unpin_lock(&rq->lock);
raw_spin_unlock_irq(&rq->lock);
}
balance_callback(rq);
}
STACK_FRAME_NON_STANDARD(__schedule); /* switch_to() */30.3.2 pick_next_task选择抢占的进程
内核从cpu的就绪队列中选择一个最合适的进程来抢占CPU
next = pick_next_task(rq);全局的pick_next_task函数会从按照优先级遍历所有调度器类的pick_next_task函数,去查找最优的那个进程, 当然因为大多数情况下,系统中全是CFS调度的非实时进程,因而linux内核也有一些优化的策略
其执行流程如下
-
如果当前cpu上所有的进程都是cfs调度的普通非实时进程,则直接用cfs调度,如果无程序可调度则调度idle进程
-
否则从优先级最高的调度器类sched_class_highest(目前是stop_sched_class)开始依次遍历所有调度器类的pick_next_task函数, 选择最优的那个进程执行
其定义在[kernel/sched/core.c]
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev)
{
const struct sched_class *class = &fair_sched_class;
struct task_struct *p;
/*
* 如果待被调度的进程prev是隶属于CFS的普通非实时进程
* 而当前cpu的全局就绪队列rq中的进程数与cfs_rq的进程数相等
* 则说明当前cpu上的所有进程都是由cfs调度的普通非实时进程
*
* 那么我们选择最优进程的时候
* 就只需要调用cfs调度器类fair_sched_class的选择函数pick_next_task
* 就可以找到最优的那个进程p
*/
/* 如果当前所有的进程都被cfs调度, 没有实时进程 */
if (likely(prev->sched_class == class &&
rq->nr_running == rq->cfs.h_nr_running))
{
/* 调用cfs的选择函数pick_next_task找到最优的那个进程p*/
p = fair_sched_class.pick_next_task(rq, prev);
/* #define RETRY_TASK ((void *)-1UL)有被其他调度气找到合适的进程 */
if (unlikely(p == RETRY_TASK))
goto again; /* 则遍历所有的调度器类找到最优的进程 */
/* assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p)) /* 如果没有进程可被调度 */
p = idle_sched_class.pick_next_task(rq, prev); /* 则调度idle进程 */
return p;
}
/* 进程中所有的调度器类, 是通过next域链接域链接在一起的
* 调度的顺序为stop -> dl -> rt -> fair -> idle
* again出的循环代码会遍历他们找到一个最优的进程 */
again:
for_each_class(class)
{
p = class->pick_next_task(rq, prev);
if (p)
{
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
BUG(); /* the idle class will always have a runnable task */
}进程中所有的调度器类, 是通过next域链接域链接在一起的, 调度的顺序为
stop -> dl -> rt -> fair -> idle其中for_each_class遍历所有的调度器类,依次执行pick_next_task操作选择最优的进程
它会从优先级最高的sched_class_highest(目前是stop_sched_class)查起,依次按照调度器类的优先级从高到低的顺序调用调度器类对应的pick_next_task_fair函数直到查找到一个能够被调度的进程
for_each_class定义在[kernel/sched/sched.h]
#define sched_class_highest (&stop_sched_class)
#define for_each_class(class) \
for (class = sched_class_highest; class; class = class->next)
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;除了全局的pick_next_task函数,每个调度器类都提供了pick_next_task函数用以查找对应调度器下的最优进程
对于FIFO和RR的区别,在scheduler_tick中通过curr->sched_class->task_tick进入到task_tick_rt的处理, 如果是非RR的进程则直接返回,否则递减时间片,如果时间片耗完,则需要将当前进程放到运行队列的末尾, 这个时候才操作运行队列(FIFO和RR进程,是否位于同一个plist队列?),时间片到点,会重新移动当前进程requeue_task_rt,进程会被加到队列尾,接下来set_tsk_need_resched触发调度,进程被抢占进入schedule()
30.3.3 context_switch进程上下文切换
30.3.3.1 进程上下文切换
上下文切换(有时也称做进程切换或任务切换)是指CPU从一个进程或线程切换到另一个进程或线程
上下文切换可以认为是内核(操作系统的核心)在 CPU 上对于进程(包括线程)进行以下的活动:
-
挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于内存中的某处,
-
在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复
-
跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程
因此上下文是指某一时间点CPU寄存器和程序计数器的内容,广义上还包括内存中进程的虚拟地址映射信息.
上下文切换只能发生在内核态(!!!)中, 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的CPU时间,事实上,可能是操作系统中时间消耗最大的操作。
30.3.3.2 context_switch()流程
context_switch()函数完成了进程上下文的切换, 其定义在[kernel/sched/core.c]
context_switch()函数建立next进程的地址空间。进程描述符的active_mm字段指向进程所使用的内存描述符,而mm字段指向进程所拥有的用户空间内存描述符。对于一般的进程,这两个字段有相同的地址,但是,内核线程没有它自己的地址空间而且它的mm字段总是被设置为 NULL;active_mm成员被初始化为前一个运行进程的active_mm值,如果当前内核线程被调度之前运行的也是另外一个内核线程时候,那么其mm和avtive_mm都是NULL.
context_switch()函数保证:如果next是一个内核线程, 它使用prev所使用的地址空间(!!!)
它主要执行如下操作
-
调用switch_mm(), 把虚拟内存从一个进程映射切换到新进程中
-
调用switch_to(), 从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存、恢复栈信息和寄存器信息
由于不同架构下地址映射的机制有所区别,而寄存器等信息弊病也是依赖于架构的,因此switch_mm和switch_to两个函数均是体系结构相关的
30.3.3.3 switch_mm切换进程虚拟地址空间
switch_mm主要完成了进程prev到next虚拟地址空间的映射, 由于内核虚拟地址空间是不许切换!!!的, 因此切换的主要是用户态的虚拟地址空间
switch_mm更换通过task_struct->mm描述的内存管理上下文,该工作的细节取决于处理器,要包括加载页表, 刷出地址转换后备缓冲器(部分或者全部), 向内存管理单元(MMU)提供新的信息
这个是一个体系结构相关的函数,其实现在对应体系结构下的[arch/对应体系结构/include/asm/mmu_context.h]
其主要工作就是切换了进程的CR3
控制寄存器(CR0~CR3)用于控制和确定处理器的操作模式以及当前执行任务的特性
CR0中含有控制处理器操作模式和状态的系统控制标志;
CR1保留不用;
CR2含有导致页错误的线性地址;
CR3中含有页目录表物理内存基地址,因此该寄存器也被称为页目录基地址寄存器PDBR(Page-Directory Base address Register)。
30.3.3.4 switch_to切换进程堆栈和寄存器
执行环境的切换是在switch_to()中完成的,switch_to完成最终的进程切换,它保存原进程的所有寄存器信息,恢复新进程的所有寄存器信息,这包括保存、恢复栈信息和寄存器信息, 并执行新的进程
switch_to切换处理器寄存器的内容和内核栈(虚拟地址空间的用户部分已经通过switch_mm变更, 其中也包括了用户状态下的栈, 因此switch_to不需要变更用户栈, 只需变更内核栈), 此段代码严重依赖于体系结构, 且代码通常都是用汇编语言编写.
调度过程可能选择了一个新的进程, 而清理工作则是针对此前的活动进程, 请注意, 这不是发起上下文切换的那个进程(!!!), 而是系统中随机的某个其他进程, 内核必须想办法使得进程能够与context_switch例程(!!!)通信, 这就可以通过switch_to宏实现. 因此switch_to函数通过3个参数提供2个变量,
我们考虑这个样一个例子,假定多个进程A,B,C...在系统上运行,在某个时间点,内核决定从进程A切换到进程B, 此时prev = A, next = B,即执行了switch_to(A, B),而后当被抢占的进程A再次被选择执行的时候,系统可能进行了多次进程切换/抢占(!!!)(至少会经历一次即再次从B到A),假设A再次被选择执行时时当前活动进程是C, 即此时prev = C. next = A.
在每个switch_to被调用的时候,prev和next指针位于各个进程的内核栈中, prev指向了当前运行的进程, 而next指向了将要运行的下一个进程, 那么为了执行从prev到next的切换, switcth_to使用前两个参数prev和next就够了.
在进程A被选中再次执行的时候,会出现一个问题, 此时控制权即将回到A, switch_to函数返回,内核开始执行switch_to之后的点(!!!),此时内核栈准确的恢复到切换之前的状态,即进程A上次被切换出去时的状态, prev = A, next = B. 此时,内核无法知道实际上在进程A之前运行的是进程C(!!!).
因此, 在新进程被选中执行时, 内核恢复到进程被切换出去的点继续执行, 此时内核只知道谁之前将新进程抢占了(上面例子就是知道了B抢占的是A), 但是却不知道新进程再次执行是抢占了谁(A的再次执行是抢占了C,但是因为是状态恢复到原有的点,所以不会知道A这里抢占的是C),因此底层的进程切换机制必须将此前执行的进程(即新进程抢占的那个进程!!!)提供给context_switch. 由于控制流会回到函数的该中间, 因此无法通过普通函数的返回值来完成. 因此使用了一个3个参数,但是逻辑效果是相同的,仿佛是switch_to是带有两个参数的函数, 而且返回了一个指向此前运行的进程的指针.
switch_to(prev, next, last);
即
prev = last = switch_to(prev, next);其中返回的prev值并不是做参数的prev值,而是prev被再次调度的时候抢占掉的那个进程last(进程C!!!).
在上个例子中, 进程A提供给switch_to的参数是prev = A, next = B, 然后控制权从A交给了B, 但是恢复执行的时候是通过prev = C, next = A完成了再次调度, 而后内核恢复了进程A被切换之前的内核栈信息, 即prev = A, next = B. 内核为了通知调度机制A抢占了C的处理器, 就通过last参数传递回来, prev = last = C.
内核在switch_to中执行如下操作
-
进程切换, 即esp的切换, 由于从esp可以找到进程的描述符
-
硬件上下文切换, 设置ip寄存器的值, 并jmp到__switch_to函数
-
堆栈的切换, 即ebp的切换, ebp是栈底指针, 它确定了当前用户空间属于哪个进程
30.3.4 need_resched()判断是否用户抢占
| 抢占类型 | 描述 | 抢占发生时机 |
|---|---|---|
| 用户抢占 | 内核在即将返回用户空间时检查进程是否设置了TIF_NEED_RESCHED标志,如果设置了,就会发生用户抢占. | 从系统调用或中断处理程序返回用户空间的时候 |
| 内核抢占 | 在不支持内核抢占的内核中,内核进程如果自己不主动停止,就会一直的运行下去。无法响应实时进程. 抢占内核虽然牺牲了上下文切换的开销, 但获得 了更大的吞吐量和响应时间 2.6的内核添加了内核抢占,同时为了某些地方不被抢占,又添加了自旋锁. 在进程的thread_info结构中添加了preempt_count该数值为0,当进程使用一个自旋锁时就加1,释放一个自旋锁时就减1. 为0时表示内核可以抢占. |
1. 从中断处理程序返回内核空间时,内核会检查preempt_count和TIF_NEED_RESCHED标志,如果进程设置了TIF_NEED_RESCHED标志, 并且preempt_count为0,发生内核抢占 2. 当内核再次用于可抢占性的时候,当进程所有的自旋锁都释 放了,释放程序会检查TIF_NEED_RESCHED标志,如果设置了就会调用schedule() 3. 显示调用schedule()时 4. 内核中的进程被堵塞的时候 |
31 用户抢占和内核抢占
非抢占式内核是由任务主动放弃CPU的使用权
抢占式内核可以保证系统响应时间.
根据抢占发生的时机分为用户抢占和内核抢占。
-
用户抢占发生在内核即将返回到用户空间的时候。
-
内核抢占发生在返回内核空间的时候。
31.1 Linux用户抢占
内核在即将返回用户空间时检查进程是否设置了TIF_NEED_RESCHED标志,如果设置了,就会发生用户抢占.
31.1.1 need_resched标识TIF_NEED_RESCHED
抢占时伴随着schedule()的执行
内核在即将返回用户空间时检查进程是否需要重新调度,如果设置了,就会发生调度(需要主动调用schedule()!!!), 这被称为用户抢占, 因此内核在thread_info的flag中设置了一个标识来标志进程是否需要重新调度, 即重新调度need_resched标识TIF_NEED_RESCHED
- set_tsk_need_resched(struct task_struct): 设置指定进程中的need_resched标志
- clear_tsk_need_resched(): 清除指定进程中的need_resched标志
- test_tsk_need_resched(): 检查指定进程need_resched标志
[include/linux/sched.h]
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
static inline void clear_tsk_need_resched(struct task_struct *tsk)
{
clear_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
static inline int test_tsk_need_resched(struct task_struct *tsk)
{
return unlikely(test_tsk_thread_flag(tsk,TIF_NEED_RESCHED));
}内核中调度时常用的need_resched()函数检查进程是否需要被重新调度其实就是通过test_tsk_need_resched实现的
[include/linux/sched.h]
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
}
[include/linux/thread_info.h]
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)31.1.2 用户抢占的发生时机(什么时候需要重新调度need_resched)
一般来说,用户抢占发生几下情况:
-
从系统调用返回用户空间;
-
从中断(异常)处理程序返回用户空间
当kernel(系统调用或者中断都在kernel中!!!)返回用户态时,系统可以安全的执行当前的任务,或者切换到另外一个任务.
当中断处理例程或者系统调用完成后, kernel返回用户态时, need_resched标志的值会被检查, 假如它为1, 调度器会选择一个新的任务并执行. 中断和系统调用的返回路径(return path)的实现在entry.S中(entry.S不仅包括kernel entry code,也包括kernel exit code)。
从这里我们可以看到, 用户抢占是发生在用户空间的抢占现象.
更详细的触发条件如下所示, 其实不外乎就是前面所说的两种情况: 从系统调用或者中断返回用户空间
-
时钟中断处理例程检查当前任务的时间片,当任务的时间片消耗完时,scheduler_tick()函数就会设置need_resched标志;
-
信号量、等待队列、completion等机制唤醒时都是基于waitqueue的,而waitqueue的唤醒函数为default_wake_function,其调用try_to_wake_up将被唤醒的任务更改为就绪状态并设置need_resched标志。
-
设置用户进程的nice值时,可能会使高优先级的任务进入就绪状态;
-
改变任务的优先级时,可能会使高优先级的任务进入就绪状态;
-
新建一个任务时,可能会使高优先级的任务进入就绪状态;
-
对CPU(SMP)进行负载均衡时,当前任务可能需要放到另外一个CPU上运行
31.2 Linux内核抢占
对比用户抢占, 顾名思义, 内核抢占就是指一个在内核态运行的进程, 可能在执行内核函数期间被另一个进程取代.
内核抢占主要是从实时系统中引入的
31.2.1 内核抢占的发生时机
要满足什么条件,kernel才可以抢占一个任务的内核态呢?
-
没持有锁。锁是用于保护临界区的,不能被抢占。
-
Kernel code可重入(reentrant)。因为kernel是SMP-safe的,所以满足可重入性。
内核抢占发生的时机,一般发生在:
-
当从中断处理程序正在执行,且返回内核空间之前。当一个中断处理例程退出,在返回到内核态时(kernel-space)。这是隐式的调用schedule()函数,当前任务没有主动放弃CPU使用权,而是被剥夺了CPU使用权。
-
当内核代码再一次具有可抢占性的时候,如解锁(spin_unlock_bh)及使能软中断(local_bh_enable)等, 此时当kernel code从不可抢占状态变为可抢占状态时(preemptible again)。也就是preempt_count从正整数变为0时。这也是隐式的调用schedule()函数
-
如果内核中的任务显式的调用schedule(), 任务主动放弃CPU使用权
-
如果内核中的任务阻塞(这同样也会导致调用schedule()),导致需要调用schedule()函数。任务主动放弃CPU使用权
内核抢占,并不是在任何一个地方都可以发生,以下情况不能发生
-
内核正进行中断处理。在Linux内核中进程不能抢占中断(中断只能被其他中断中止、抢占,进程不能中止、抢占中断!!!),在中断例程中不允许进行进程调度。进程调度函数schedule()会对此作出判断,如果是在中断中调用,会打印出错信息。
-
内核正在进行中断上下文的Bottom Half(中断下半部,即软中断)处理。硬件中断返回前会执行软中断(!!!),此时仍然处于中断上下文中。如果此时正在执行其它软中断,则不再执行该软中断。
-
内核的代码段正持有spinlock自旋锁、writelock/readlock读写锁等锁,处干这些锁的保护状态中。内核中的这些锁是为了在SMP系统中短时间内保证不同CPU上运行的进程并发执行的正确性。当持有这些锁时,内核不应该被抢占。
-
内核正在执行调度程序Scheduler。抢占的原因就是为了进行新的调度,没有理由将调度程序抢占掉再运行调度程序。
-
内核正在对每个CPU“私有”的数据结构操作(Per-CPU date structures)。在SMP中,对于per-CPU数据结构未用spinlocks保护,因为这些数据结构隐含地被保护了(不同的CPU有不一样的per-CPU数据,其他CPU上运行的进程不会用到另一个CPU的per-CPU数据)。但是如果允许抢占,但一个进程被抢占后重新调度,有可能调度到其他的CPU上去(!!!),这时定义的Per-CPU变量就会有问题,这时应禁抢占。
31.2.2 内核抢占的实现
31.2.2.1 内核如何跟踪它能否被抢占?
前面用户抢占, 系统中每个进程都有一个特定于体系结构的struct thread_info结构, 用户层程序被调度的时候会检查struct thread_info中的need_resched标识TLF_NEED_RESCHED标识来检查自己是否需要被重新调度.
内核抢占也可以应用同样的方法被实现, linux内核在thread_info结构中添加了一个自旋锁标识preempt_count, 称为抢占计数器(preemption counter).
struct thread_info
{
int preempt_count; /* 0 => preemptable, <0 => BUG */
}| preempt_count值 | 描述 |
|---|---|
| 大于0 | 禁止内核抢占, 其值标记了使用preempt_count的临界区的数目 |
| 0 | 开启内核抢占 |
| 小于0 | 锁为负值, 内核出现错误 |
内核提供了一些函数或者宏, 用来开启, 关闭以及检测抢占计数器preempt_count的值, 这些通用的函数定义在[include/asm-generic/preempt.h]
而某些架构也定义了自己的接口, 比如x86架构[/arch/x86/include/asm/preempt.h]
31.2.2.2 内核如何知道是否需要抢占?
首先必须设置了TLF_NEED_RESCHED标识来通知内核有进程在等待得到CPU时间, 然后会判断抢占计数器preempt_count是否为0, 这个工作往往通过preempt_check_resched或者其相关来实现
31.2.2.2.1 重新启用内核抢占时使用preempt_schedule()检查抢占
在内核停用抢占后重新启用时, 检测是否有进程打算抢占当前执行的内核代码, 是一个比较好的时机, 如果是这样, 应该尽快完成, 则无需等待下一次对调度器的例行调用.
抢占机制中主要的函数是preempt_schedule(), 设置了TIF_NEED_RESCHED标志并不能保证可以抢占内核, 内核可能处于临界区, 不能被干扰
[kernel/sched/core.c]
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/* !preemptible() => preempt_count() != 0 || irqs_disabled()
* 如果抢占计数器大于0, 那么抢占被停用, 该函数立即返回
* 如果
*/
if (likely(!preemptible()))
return;
preempt_schedule_common();
}
NOKPROBE_SYMBOL(preempt\_schedule);
EXPORT_SYMBOL(preempt\_schedule);
[include/linux/preempt.h]
#define preemptible() (preempt_count() == 0 && !irqs_disabled())!preemptible() => preempt_count() != 0 || irqs_disabled()表明
-
如果抢占计数器大于0, 那么抢占仍然是被停用的, 因此内核不能被打断, 该函数立即结束.
-
如果在某些重要的点上内核停用了硬件中断,以保证一次性完成相关的处理,那么抢占也是不可能的.irqs_disabled会检测是否停用了中断. 如果已经停用, 则内核不能被抢占
接着如果可以被抢占, 则执行如下步骤
static void __sched notrace preempt_schedule_common(void)
{
do {
/* 等待于__preempt_count_inc();增加抢占计数器 */
preempt_disable_notrace();
/* 完成一次调度 */
__schedule(true);
/* 等价于__preempt_count_dec;减少抢占计数器 */
preempt_enable_no_resched_notrace();
/*
* 再次检查, 以免在__scheudle和当前点之间错过了抢占的时机
*/
} while (need_resched());
}我们可以看到, 内核在增加了抢占计数器的计数后, 用__schedule进行了一次调度, 参数传入preempt = true, 表明调度不是以普通的方式引发的, 而是由于内核抢占. 在内核重调度之后, 代码流程回到当前进程, 那么就将抢占计数器减少1.
31.2.2.2.2 中断之后返回内核态时通过preempt_schedule_irq()触发
上面preempt_schedule()只是触发内核抢占的一种方法, 另一种激活抢占的方式是在处理了一个硬件中断请求之后. 如果处理器在处理中断请求后返回内核态(返回用户态则没有影响), 特定体系结构的汇编例程会检查抢占计数器是否为0, 即是否允许抢占, 以及是否设置了重调度标识, 类似于preempt_schedule()的处理. 如果两个条件都满足(!!!)则通过preempt_schedule_irq调用调度器,此时表明抢占请求发自中断上下文
该函数与preempt_schedule的本质区别在于: preempt_schedule_irq调用时停用了中断,防止终端造成的递归调用, 其定义在[kernel/sched/core.c]
[kernel/sched/core.c]
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}31.2.2.2.3 PREEMPT_ACTIVE标识位和PREEMPT_DISABLE_OFFSET
之前的内核版本中, 抢占计数器中于一个标识位PREEMPT_ACTIVE, 这个位设置后即标识了可以进行内核抢占, 使得preempt_count有一个很大的值, 这样就不受普通的抢占计数器加1操作的影响了
但是在linux-4.4版本之后移除了这个标志, 取而代之的是在linux-4.2时引入的PREEMPT_DISABLE_OFFSET
31.3 小结
一般来说,CPU在任何时刻都处于以下三种情况之一(!!!):
-
运行于用户空间,执行用户进程
-
运行于内核空间,处于进程上下文
-
运行于内核空间,处于中断上下文
31.3.1 用户抢占
一般来说, 当进程从系统调用或者从中断(异常)处理程序返回用户空间时会触发主调度器进行用户抢占
-
从系统调用返回用户空间
-
从中断(异常)处理程序返回用户空间
为了对一个进程需要被调度进行标记,内核在thread_info的flag中设置了一个标识来标志进程是否需要重新调度, 即重新调度need_resched标识TIF_NEED_RESCHED, 内核在即将返回用户空间时会检查标识TIF_NEED_RESCHED标志进程是否需要重新调度,如果设置了,就会发生调度, 这被称为用户抢占
31.3.2 内核抢占
linux内核通过在thread_info结构中添加了一个自旋锁标识preempt_count,称为抢占计数器(preemption counter)来作为内核抢占的标记,
内核抢占的触发大致也是两类, 内核抢占关闭后重新开启时, 中断返回内核态时
-
内核重新开启内核抢占时使用preempt_schedule检查内核抢占
-
中断之后返回内核态时通过preempt_schedule_irq触发内核抢占
而内核抢占时, 通过调用__schedule(true)传入的preempt=true来通知内核, 这是一个内核抢占
32 Linux优先级
在用户空间通过nice命令设置进程的静态优先级,这在内部会调用nice系统调用,进程的nice值在-20~+19之间(用户空间!!!。).值越低优先级越高.
setpriority系统调用也可以用来设置进程的优先级.它不仅能够修改单个线程的优先级, 还能修改进程组中所有进程的优先级,或者通过制定UID来修改特定用户的所有进程的优先级(特定用户!!!)
内核使用一些简单的数值范围0~139表示内部优先级(内核里面使用!!!), 数值越低, 优先级越高。
-
0~99的范围专供实时进程使用
-
nice的值[-20,19]则映射到范围100~139, 用于普通进程!!!
linux2.6内核将任务优先级进行了一个划分, 实时进程优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(即100到139).
内核里面priority的范围:
| 优先级范围 | 内核宏 | 描述 |
|---|---|---|
| 0 —— 99 | 0 —— (MAX_RT_PRIO - 1) | 实时进程 |
| 100 —— 139 | MAX_RT_PRIO —— (MAX_PRIO - 1) | 非实时进程 |

32.1 内核的优先级表示
内核表示优先级的所有信息基本都放在[include/linux/sched/prio.h], 其中定义了一些表示优先级的宏和函数.
优先级数值通过宏来定义, 如下所示,
其中MAX_NICE和MIN_NICE定义了nice的最大最小值
而MAX_RT_PRIO指定了实时进程的最大优先级, 而MAX_PRIO则是普通进程的最大优先级数值
[include/linux/sched/prio.h]
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
[include/linux/sched/prio.h]
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20)| 宏 | 值 | 描述 |
|---|---|---|
| MIN_NICE | -20 | 对应于优先级100,可以使用NICE_TO_PRIO和PRIO_TO_NICE转换 |
| MAX_NICE | 19 | 对应于优先级139,可以使用NICE_TO_PRIO和PRIO_TO_NICE转换 |
| NICE_WIDTH | 40 | nice值得范围宽度, 即[-20, 19]共40个数字的宽度 |
| MAX_RT_PRIO, MAX_USER_RT_PRIO | 100 | 实时进程的最大优先级 |
| MAX_PRIO | 140 | 普通进程的最大优先级 |
| DEFAULT_PRIO | 120 | 进程的默认优先级, 对应于nice=0 |
| MAX_DL_PRIO | 0 | 使用EDF最早截止时间优先调度算法的实时进程最大的优先级 |
而内核提供了一组宏将优先级在各种不同的表示形之间转移
[include/linux/sched/prio.h]
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
#define USER_PRIO(p) ((p)-MAX_RT_PRIO)
#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)
#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))还有一些nice值和rlimit值之间相互转换的函数nice_to_rlimit和rlimit_to_nice, 这在nice系统调用进行检查的时候很有用
static inline long nice_to_rlimit(long nice)
{
return (MAX_NICE - nice + 1);
}
static inline long rlimit_to_nice(long prio)
{
return (MAX_NICE - prio + 1);
}32.2 DEF最早截至时间优先实时调度算法的优先级描述
EDF实时调度算法, 它的优先级比RT进程和NORMAL/BATCH进程的优先级都要高, 关于EDF的优先级的设置信息都在内核头文件[include/linux/sched/deadline.h]
因此内核将MAX_DL_PRIO设置为0
#define MAX_DL_PRIO 032.3 进程优先级的计算
前面说了task_struct中的几个优先级的字段
| 静态优先级 | 普通优先级 | 动态优先级 | 实时优先级 |
|---|---|---|---|
| static_prio | normal_prio | prio | rt_priority |
但是这些优先级是如何关联的呢, 动态优先级prio又是如何计算的呢?
32.3.1 normal_prio()设置普通优先级normal_prio
静态优先级static_prio(普通进程)和实时优先级rt_priority(实时进程)是计算的起点(!!!)
因此他们也是进程创建的时候设定好的, 我们通过nice修改的就是普通进程的静态优先级static_prio(!!!。)
首先通过静态优先级static_prio计算出普通优先级normal_prio, 该工作可以由normal_prio()来完成, 该函数定义在 [kernel/sched/core.c]
/*
* 普通进程(非实时进程)的普通优先级normal_prio就是静态优先级static_prio
*/
static inline int __normal_prio(struct task_struct *p)
{
return p->static_prio;
}
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p)) /* EDF调度的实时进程 */
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p)) /* 普通实时进程的优先级 */
prio = MAX_RT_PRIO-1 - p->rt_priority;
else /* 普通进程的优先级 */
prio = __normal_prio(p);
return prio;
}| 进程类型 | 调度器 | 普通优先级normal_prio |
|---|---|---|
| EDF实时进程 | EDF | MAX_DL_PRIO - 1 = -1 |
| 实时进程 | RT | MAX_RT_PRIO - 1 - p->rt_priority = 99 - rt_priority |
| 普通进程 | CFS | __normal_prio(p) = static_prio |
32.3.1.1 辅助函数task_has_dl_policy和task_has_rt_policy
其本质其实就是传入task->policy调度策略字段看其值等于SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE, SCHED_FIFO, SCHED_RR, SCHED_DEADLINE中的哪个, 从而确定其所属的调度类, 进一步就确定了其进程类型
[kernel/sched/sched.h]
static inline int idle_policy(int policy)
{
return policy == SCHED_IDLE;
}
static inline int fair_policy(int policy)
{
return policy == SCHED_NORMAL || policy == SCHED_BATCH;
}
static inline int rt_policy(int policy)
{
return policy == SCHED_FIFO || policy == SCHED_RR;
}
static inline int dl_policy(int policy)
{
return policy == SCHED_DEADLINE;
}
static inline bool valid_policy(int policy)
{
return idle_policy(policy) || fair_policy(policy) ||
rt_policy(policy) || dl_policy(policy);
}
static inline int task_has_rt_policy(struct task_struct *p)
{
return rt_policy(p->policy);
}
static inline int task_has_dl_policy(struct task_struct *p)
{
return dl_policy(p->policy);
}32.3.1.2 关于rt_priority数值越大, 实时进程优先级越高的问题
前面提到了数值越小,优先级越高, 但是此处我们会发现rt_priority的值越大,其普通优先级越小,从而优先级越高.
对于一个实时进程(!!!),他有两个参数来表明优先级(!!!)——prio 和 rt_priority,
prio才是调度所用的最终优先级数值(!!!),这个值越小,优先级越高;
而rt_priority被称作实时进程优先级,prio要经过转化——prio=MAX_RT_PRIO - 1 - p->rt_priority = 99 - p->rt_priority;
MAX_RT_PRIO = 100;这样意味着rt_priority值越大,优先级越高;
而内核提供的修改优先级的函数,是修改rt_priority的值,所以越大,优先级越高。
所以用户在使用实时进程或线程,在修改优先级时,就会有“优先级值越大,优先级越高的说法”,也是对的。
32.3.1.3 为什么需要__normal_prio函数
历史原因
32.3.2 effective_prio()设置动态优先级prio
可以通过函数effective_prio()用静态优先级static_prio计算动态优先级prio, 即·
p->prio = effective_prio(p);[kernel/sched/core.c]
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}-
设置进程的普通优先级(实时进程99 - rt_priority, 普通进程为static_priority)
-
计算进程的动态优先级(实时进程则维持动态优先级的prio不变, 普通进程的动态优先级即为其普通优先级)
| 进程类型 | 实时优先级rt_priority | 静态优先级static_prio | 普通优先级normal_prio | 动态优先级prio |
|---|---|---|---|---|
| EDF调度的实时进程 | rt_priority | 不使用 | MAX_DL_PRIO-1 | 维持原prio不变 |
| RT算法调度的实时进程 | rt_priority | 不使用 | MAX_RT_PRIO-1-rt_priority | 维持原prio不变 |
| 普通进程 | 不使用 | static_prio | static_prio | static_prio |
| 优先级提高的普通进程 | 不使用 | static_prio(改变) | static_prio | 维持原prio不变 |
32.3.2.1 使用优先级数值检测实时进程rt_prio()
rt_prio()会检测普通优先级是否在实时范围内,即是否小于MAX_RT_PRIO.
static inline int rt_prio(int prio)
{
if (unlikely(prio < MAX_RT_PRIO))
return 1;
return 0;
}32.3.3 设置prio的时机
- 在新进程用wake_up_new_task唤醒时, 或者使用nice系统调用改变其静态优先级时, 则会通过effective_prio的方法设置p->prio
wake_up_new_task(),计算此进程的优先级和其他调度参数,将新的进程加入到进程调度队列并设此进程为可被调度的,以后这个进程可以被进程调度模块调度执行。
- 进程创建时copy_process()通过调用sched_fork()来初始化和设置调度器的过程中会设置子进程的优先级
32.3.3.1 nice系统调用的实现
nice系统调用是的内核实现是sys_nice(), 通过一系列检测后, 通过set_user_nice()函数
32.3.3.2 fork时优先级的继承
在进程分叉处子进程时, 子进程的静态优先级继承自父进程.
子进程的动态优先级p->prio则被设置为父进程的普通优先级(!!!), 这确保了实时互斥量(RT-Mutex)引起的优先级提高不会传递到子进程.
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
/* ...... */
/*
* Make sure we do not leak PI boosting priority to the child.
* 子进程的动态优先级被设置为父进程普通优先级
*/
p->prio = current->normal_prio;
/*
* sched_reset_on_fork标识用于判断是否恢复默认的优先级或调度策略
*/
if (unlikely(p->sched_reset_on_fork)) /* 如果要恢复默认的调度策略, 即SCHED_NORMAL */
{
/* 首先是设置静态优先级static_prio
* 由于要恢复默认的调度策略
* 对于父进程是实时进程的情况, 静态优先级就设置为DEFAULT_PRIO
*
* 对于父进程是非实时进程的情况, 要保证子进程优先级不小于DEFAULT_PRIO
* 父进程nice < 0即static_prio < 的重新设置为DEFAULT_PRIO的重新设置为DEFAULT_PRIO
* 父进程nice > 0的时候, 则什么也没做
* */
if (task_has_dl_policy(p) || task_has_rt_policy(p))
{
p->policy = SCHED_NORMAL; /* 普通进程调度策略 */
p->static_prio = NICE_TO_PRIO(0); /* 静态优先级为nice = 0 即DEFAULT_PRIO*/
p->rt_priority = 0; /* 实时优先级为0 */
}
else if (PRIO_TO_NICE(p->static_prio) < 0) /* */
p->static_prio = NICE_TO_PRIO(0); /* */
/* 接着就通过__normal_prio设置其普通优先级和动态优先级
* 这里做了一个优化, 因为用sched_reset_on_fork标识设置恢复默认调度策略后
* 创建的子进程是是SCHED_NORMAL的非实时进程
* 因此就不需要绕一大圈用effective_prio设置normal_prio和prio了
* 直接用__normal_prio设置就可 */
p->prio = p->normal_prio = __normal_prio(p); /* 设置*/
/* 设置负荷权重 */
set_load_weight(p);
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
/* ...... */
}33 Linux睡眠唤醒抢占
每个调度器类都应该实现一个check_preempt_curr函数, 在全局check_preempt_curr中会调用进程其所属调度器类check_preempt_curr进行抢占检查, 对于完全公平调度器CFS处理的进程,则对应由check_preempt_wakeup函数执行该策略.
新唤醒的进程不必一定由完全公平调度器处理, 如果新进程是一个实时进程, 则会立即请求调度, 因为实时进程优先极高,实时进程总会抢占CFS进程.
33.1 Linux进程的睡眠
在Linux中,仅等待CPU时间的进程称为就绪进程,它们被放置在一个运行队列中,一个就绪进程的状态标志位为TASK_RUNNING.一旦一个运行中的进程时间片用完,Linux内核的调度器会剥夺这个进程对CPU的控制权,并且从运行队列中选择一个合适的进程投入运行.
当然,一个进程也可以主动释放CPU的控制权.函数schedule()是一个调度函数, 它可以被一个进程主动调用,从而调度其它进程占用CPU.一旦这个主动放弃CPU的进程被重新调度占用CPU,那么它将从上次停止执行的位置开始执行,也就是说它将从调用schedule()的下一行代码处开始执行(!!!).
在现代的Linux操作系统中,进程一般都是用调用schedule()的方法进入睡眠状态的, 下面的代码演示了如何让正在运行的进程进入睡眠状态。
sleeping_task = current;
set_current_state(TASK_INTERRUPTIBLE);
schedule();
func1();在第一个语句中, 程序存储了一份进程结构指针sleeping_task, current 是一个宏,它指向正在执行的进程结构。set_current_state()将该进程的状态从执行状态TASK_RUNNING变成睡眠状态TASK_INTERRUPTIBLE.
-
如果schedule是被一个状态为TASK_RUNNING的进程调度,那么schedule将调度另外一个进程占用CPU;
-
如果schedule是被一个状态为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE的进程调度,那么还有一个附加的步骤(!!!)将被执行:当前执行的进程在另外一个进程被调度之前会被从运行队列中移出(!!!),这将导致正在运行的那个进程进入睡眠,因为它已经不在运行队列中了.
33.2 Linux进程的唤醒
当在try_to_wake_up/wake_up_process和wake_up_new_task中唤醒进程时, 内核使用全局check_preempt_curr看看是否进程可以抢占当前进程可以抢占当前运行的进程. 请注意该过程不涉及核心调度器(!!!).
33.2.1 wake_up_process()
使用wake_up_process将刚才那个进入睡眠的进程唤醒,该函数定义在[kernel/sched/core.c]
int wake_up_process(struct task_struct *p)
{
return try_to_wake_up(p, TASK_NORMAL, 0);
}在调用了wake_up_process以后, 这个睡眠进程的状态会被设置为TASK_RUNNING,而且调度器会把它加入到运行队列中去. 当然,这个进程只有在下次被调度器调度(!!!)到的时候才能真正地投入运行.
33.2.2 try_to_wake_up()
try_to_wake_up函数通过把进程状态设置为TASK_RUNNING,并把该进程插入**本地CPU运行队列rq!!!**来达到唤醒睡眠和停止的进程的目的.
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)该函数接受的参数有:被唤醒进程的描述符指针(p),可以被唤醒的进程状态掩码(state),一个标志wake_flags,用来禁止被唤醒的进程抢占本地CPU上正在运行的进程.
33.2.3 wake_up_new_task()
[kernel/sched/core.c]
void wake_up_new_task(struct task_struct *p)之前进入睡眠状态的可以通过try_to_wake_up和wake_up_process完成唤醒
而我们fork新创建的进程在完成自己的创建工作后, 可以通过wake_up_new_task完成唤醒并添加到就绪队列中等待调度, 详情见上面
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
/* Initialize new task's runnable average */
init_entity_runnable_average(&p->se);
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
#ifdef CONFIG_SMP
set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endif
rq = __task_rq_lock(p, &rf);
post_init_entity_util_avg(&p->se);
activate_task(rq, p, 0);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
lockdep_unpin_lock(&rq->lock, rf.cookie);
p->sched_class->task_woken(rq, p);
lockdep_repin_lock(&rq->lock, rf.cookie);
}
#endif
task_rq_unlock(rq, p, &rf);
}33.2.3.1 check_preempt_curr
wake_up_new_task中唤醒进程时,内核使用全局check_preempt_curr看看是否进程可以抢占当前运行的进程.
[kernel/sched/core.c]
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
const struct sched_class *class;
if (p->sched_class == rq->curr->sched_class)
{
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
}
else
{
for_each_class(class) {
if (class == rq->curr->sched_class)
break;
if (class == p->sched_class) {
resched_curr(rq);
break;
}
}
}
if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr))
rq_clock_skip_update(rq, true);
}33.3 无效唤醒
几乎在所有的情况下,进程都会在检查了某些条件之后,发现条件不满足才进入睡眠. 可是有的时候进程却会在判定条件为真后开始睡眠,如果这样的话进程就会无限期地休眠下去, 这就是所谓的无效唤醒问题.
当多个进程都企图对共享数据进行某种处理,而最后的结果又取决于进程运行的顺序时,就会发生竞争条件,这是操作系统中一个典型的问题,无效唤醒恰恰就是由于竞争条件导致的.
设想有两个进程A和B,A进程正在处理一个链表,它需要检查这个链表是否为空,如果不空就对链表里面的数据进行一些操作,同时B进程也在往这个链表添加节点.当这个链表是空的时候,由于无数据可操作,这时A进程就进入睡眠,当B进程向链表里面添加了节点之后它就唤醒A进程
A进程:
spin_lock(&list_lock);
if(list_empty(&list_head))
{
spin_unlock(&list_lock);
set_current_state(TASK_INTERRUPTIBLE);
schedule();
spin_lock(&list_lock);
}
/* Rest of the code ... */
spin_unlock(&list_lock);
}B进程:
spin_lock(&list_lock);
list_add_tail(&list_head, new_node);
spin_unlock(&list_lock);
wake_up_process(A);这里会出现一个问题,假如当A进程执行到第4行后(spin_unlock(&list_lock);)第5行前(set_current_state(TASK_INTERRUPTIBLE);)的时候,B进程被另外一个处理器调度投入运行.在这个时间片内,B进程执行完了它所有的指令,因此它试图唤醒A进程,而此时的A进程还没有进入睡眠, 所以唤醒操作无效.
在这之后, A进程继续执行, 它会错误地认为这个时候链表仍然是空的,于是将自己的状态设置为TASK_INTERRUPTIBLE然后调用schedule()进入睡眠. 由于错过了B进程唤醒, 它将会无限期的睡眠下去, 这就是无效唤醒问题, 因为即使链表中有数据需要处理, A进程也还是睡眠了.
33.3.1 无效唤醒的原因
无效唤醒主要发生在检查条件之后(链表为空)和进程状态被设置为睡眠状态之前,本来B进程的wake_up_process提供了一次将A进程状态置为TASK_RUNNING的机会,可惜这个时候A进程的状态仍然是TASK_RUNNING,所以wake_up_process将A进程状态从睡眠状态转变为运行状态的努力没有起到预期的作用.
33.3.2 避免无效抢占
Linux中避免进程的无效唤醒的关键是
-
在进程检查条件之前就将进程的状态置为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE
-
并且如果检查的条件满足的话就应该将其状态重新设置为TASK_RUNNING.
这样无论进程等待的条件是否满足,进程都不会因为被移出就绪队列而错误地进入睡眠状态,从而避免了无效唤醒问题.
以上面为例, 必须使用一种保障机制使得判断链表为空和设置进程状态为睡眠状态成为一个不可分割的步骤才行, 也就是必须消除竞争条件产生的根源, 这样在这之后出现的wake_up_process就可以起到唤醒状态是睡眠状态的进程的作用了.
A进程
set_current_state(TASK_INTERRUPTIBLE);
spin_lock(&list_lock);
if(list_empty(&list_head))
{
spin_unlock(&list_lock);
schedule();
spin_lock(&list_lock);
}
set_current_state(TASK_RUNNING);
/* Rest of the code ... */
spin_unlock(&list_lock);可以看到,这段代码在测试条件之前(链表为空)就将当前执行进程状态转设置成TASK_INTERRUPTIBLE了,并且在链表不为空的情况下又将自己置为TASK_RUNNING状态.
34 stop_sched_class调度器类与stop_machine机制
所属调度器类为stop_sched_class的进程是系统中优先级最高的进程, 其次才是dl_shced_class和rt_sched_class
stop_sched_class用于停止CPU, 一般在SMP系统上使用,用以实现负载平衡和CPU热插拔.这个类有最高的调度优先级, 如果你的系统没有定义CONFIG_SMP. 你可以试着将此类移除.
stop_machine是一个通信信号: 在SMP的情况下相当于暂时停止其他的CPU的运行, 它让一个CPU继续运行,而让所有其他CPU空闲. 在单CPU的情况下这个东西就相当于关中断
我的理解是如果Mulit CPU共享的东西需要修改, 且无法借助OS的lock, 关中断等策略来实现这一功能, 则需要stop_machine
35 dl_sched_class调度器类
对于实时进程,采用FIFO, Round Robin或者Earliest Deadline First (EDF)最早截止期限优先调度算法的调度策略.
36 rt_sched_class调度器类
对于实时进程,采用FIFO, Round Robin或者Earliest Deadline First (EDF)最早截止期限优先调度算法的调度策略.
实时进程与普通进程有一个根本的不同之处: 如果系统中有一个实时进程且可运行, 那么调度器总是会选中它运行, 除非有另外一个优先级更高的实时进程.
现有的两种实时调度策略, 不同之处如下所示:
| 名称 | 调度策略 | 描述 |
|---|---|---|
| 循环进程 | SCHED_RR | 有时间片, 其值在进程运行时会减少, 就像是普通进程. 在所有的时间段到期后, 则该值重置为初始值, 而进程则置与队列的末尾, 这保证了在有几个优先级相同的SCHED_RR进程的情况下, 他们总是依次执行 |
| 先进先出进程 | SCHED_FIFO | 没有时间片, 在被调度器选择执行后, 可以运行任意长时间. |
很明显, 如果实时进程编写的比较差, 系统可能长时间无法使用. 最简单的例子, 只要写一个无限循环, 循环体内不进入休眠即可. 因而我们在编写实时应用程序时, 应该格外小心.
37 fair_sched_clas调度器类
简单说一下CFS调度算法的思想:理想状态下每个进程都能获得相同的时间片,并且同时运行在CPU上,但实际上一个CPU同一时刻运行的进程只能有一个。 也就是说,当一个进程占用CPU时,其他进程就必须等待。
37.1 CFS调度器类fair_sched_class
[kernel/sched/sched.h]
struct sched_class {
/* 系统中多个调度类, 按照其调度的优先级排成一个链表
下一优先级的调度类
* 调度类优先级顺序: stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class
*/
const struct sched_class *next;
/* 将进程加入到运行队列中,即将调度实体(进程)放入红黑树中,并对 nr_running 变量加1 */
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
/* 从运行队列中删除进程,并对 nr_running 变量中减1 */
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
/* 放弃CPU,在 compat_yield sysctl 关闭的情况下,该函数实际上执行先出队后入队;在这种情况下,它将调度实体放在红黑树的最右端 */
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
/* 检查当前进程是否可被新进程抢占 */
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
/* 选择下一个应该要运行的进程运行 */
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev);
/* 将进程放回运行队列 */
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
/* 为进程选择一个合适的CPU */
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
/* 迁移任务到另一个CPU */
void (*migrate_task_rq)(struct task_struct *p);
/* 用于进程唤醒 */
void (*task_waking) (struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
/* 修改进程的CPU亲和力(affinity) */
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
/* 启动运行队列 */
void (*rq_online)(struct rq *rq);
/* 禁止运行队列 */
void (*rq_offline)(struct rq *rq);
#endif
/* 当进程改变它的调度类或进程组时被调用 */
void (*set_curr_task) (struct rq *rq);
/* 该函数通常调用自 time tick 函数;它可能引起进程切换。这将驱动运行时(running)抢占 */
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
/* 在进程创建时调用,不同调度策略的进程初始化不一样 */
void (*task_fork) (struct task_struct *p);
/* 在进程退出时会使用 */
void (*task_dead) (struct task_struct *p);
/* 用于进程切换 */
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
/* 改变优先级 */
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p);
#endif
};| 成员 | 描述 |
|---|---|
| enqueue_task | 向就绪队列中添加一个进程,某个任务进入可运行状态时,该函数将得到调用。它将调度实体(进程)放入红黑树中,并对nr_running变量加 1 |
| dequeue_task | 将一个进程从就就绪队列中删除,当某个任务退出可运行状态时调用该函数,它将从红黑树中去掉对应的调度实体,并从 nr_running 变量中减 1 |
| yield_task | 在进程想要资源放弃对处理器的控制权的时, 可使用在sched_yield系统调用, 会调用内核API yield_task完成此工作. compat_yield sysctl关闭的情况下,该函数实际上执行先出队后入队;在这种情况下,它将调度实体放在红黑树的最右端 |
| check_preempt_curr | 该函数将检查当前运行的任务是否被抢占。在实际抢占正在运行的任务之前,CFS 调度程序模块将执行公平性测试。这将驱动唤醒式(wakeup)抢占 |
| pick_next_task | 该函数选择接下来要运行的最合适的进程 |
| put_prev_task | 用另一个进程代替当前运行的进程 |
| set_curr_task | 当任务修改其调度类或修改其任务组时,将调用这个函数 |
| task_tick | 在每次激活周期调度器时, 由周期性调度器调用, 该函数通常调用自 time tick 函数;它可能引起进程切换。这将驱动运行时(running)抢占 |
| task_new | 内核调度程序为调度模块提供了管理新任务启动的机会,用于建立fork系统调用和调度器之间的关联, 每次新进程建立后,则用new_task通知调度器,CFS调度模块使用它进行组调度,而用于实时任务的调度模块则不会使用这个函数 |
37.2 cfs的就绪队列
就绪队列是全局调度器许多操作的起点, 但是进程并不是由就绪队列直接管理的, 调度管理是各个调度器的职责, 因此在各个就绪队列中嵌入了特定调度类的子就绪队列(cfs的顶级调度就队列 struct cfs_rq, 实时调度类的就绪队列struct rt_rq和deadline调度类的就绪队列struct dl_rq
见上面
37.3 进程优先级
struct task_struct
{
/* 进程优先级
* prio: 动态优先级,范围为100~139,与静态优先级和补偿(bonus)有关
* static_prio: 静态优先级,static_prio = 100 + nice + 20 (nice值为-20~19,所以static_prio值为100~139)
* normal_prio: 没有受优先级继承影响的常规优先级,具体见normal_prio函数,跟属于什么类型的进程有关
*/
int prio, static_prio, normal_prio;
/* 实时进程优先级 */
unsigned int rt_priority;
}37.4 负荷权重
37.4.1 调度实体的负荷权重结构struct load_weight
调度实体的数据结构中己经内嵌了struct load_weight结构体,用于描述当前调度实体的权重
[include/linux/sched.h]
struct sched_entity {
struct load_weight load; /* for load-balancing */
}
struct load_weight {
unsigned long weight; /* 存储了权重的信息 */
u32 inv_weight; /* 存储了权重值用于重除的结果 weight * inv_weight = 2^32 */
};inv_weight是inverse weight的缩写
37.4.2 进程的负荷权重
而进程可以被作为一个调度的实体时, 其内部通过存储struct sched_entity se而间接存储了其load_weight信息
struct task_struct
{
/* ...... */
struct sched_entity se;
/* ...... */
}因此代码中经常通过p->se.load来获取进程p的权重信息, 而set_load_weight()负责根据进程类型及其静态优先级计算负荷权重.
37.5 优先级和权重的转换
37.5.1 优先级->权重转换表
nice值的范围是从-20〜19(nice值转priority是120, 也可见nice值对应的是普通进程的, 不是实时进程或deadline进程或idle进程!!!), 进程默认的nice值为0。这些值含义类似级别,可以理解成有40个等级,nice值越高,则优先级越低(优先级数值越大,nice值和优先级值线性关系)
一般这个概念是这样的, 进程每降低一个nice值(优先级提升), 则多获得10%的CPU时间, 没升高一个nice值(优先级降低), 则放弃10%的CPU时间.
为执行该策略, 内核需要将优先级转换为权重值, 内核约定nice值为0的权重值为1024, 并提供了一张优先级->权重转换表sched_prio_to_weight, 表下标对应nice值[-20〜19]。
[kernel/sched/sched.h]
extern const int sched_prio_to_weight[40];
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};10%的影响是相对及累加的
举个例子,进程A和进程B的nice值都为0,那么权重值都是1024,它们获得CPU的时间都是50%, 计算公式为1024/(1024+1024)=50%。
假设进程A增加一个nice值,即nice=1, 进程B的nice值不变,那么进程B应该获得55%的CPU时间,进程A应该是45%。我们利用prio_to_weight[]表来计算,进程A=820/(1024+820)=45%,而进程B=1024/(1024+820)=55%, 注意是近似等于。
内核不仅维护了负荷权重自身, 还保存另外一个数值, 用于负荷重除的结果, 即sched_prio_to_wmult数组, 这两个数组中的数据是一一对应的.
[kernel/sched/sched.h]
extern const u32 sched_prio_to_wmult[40];
static const u32 prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};prio_to_wmult[]表的计算公式如下:
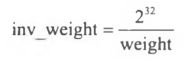
其中,inv_weight是inverse weight的缩写,指权重被倒转了,作用是为后面计算方便。
nice [-20, 19] -=> 下标 [0, 39]
37.5.2 set_load_weight()依据静态优先级设置进程的负荷权重
定义了两个宏WEIGHT_IDLEPRIO和WMULT_IDLEPRIO这两个宏对应的就是SCHED_IDLE调度的进程的负荷权重信息, 因为要保证SCHED_IDLE进程的最低优先级和最低的负荷权重.
内核提供一个函数来查询这两个表,然后把值存放在p->se.load数据结构中,即struct load_weight结构中。
#define WEIGHT_IDLEPRIO 3
#define WMULT_IDLEPRIO 1431655765
[kernel/sched/core.c]
static void set_load_weight(struct task_struct *p)
{
/*
* 由于数组中的下标是0~39, 普通进程的优先级是[100~139]
* 因此通过static_prio - MAX_RT_PRIO将静态优先级转换成为数组下标
*/
int prio = p->static_prio - MAX_RT_PRIO;
/* 取得指向进程task负荷权重的指针load,
* 下面修改load就是修改进程的负荷权重
*/
struct load_weight *load = &p->se.load;
/*
* 必须保证SCHED_IDLE进程的负荷权重最小
* 其权重weight就是WEIGHT_IDLEPRIO
* 而权重的重除结果就是WMULT_IDLEPRIO
*/
if (p->policy == SCHED_IDLE) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
/* 设置进程的负荷权重weight和权重的重除值inv_weight */
load->weight = scale_load(prio_to_weight[prio]);
load->inv_weight = prio_to_wmult[prio];
}37.6 就绪队列的负荷权重
不仅进程, 就绪队列也关联到一个负荷权重.
这样不仅确保就绪队列能够跟踪记录有多少进程在运行, 而且还能将进程的权重添加到就绪队列中.
[kernel/sched/sched.h]
struct rq
{
struct load_weight load;
};
struct cfs_rq
{
struct load_weight load;
unsigned int nr_running, h_nr_running;
/* ...... */
};
struct rt_rq中不需要负荷权重
struct dl_rq中不需要负荷权重由于负荷权重仅用于调度普通进程(非实时进程!!!), 因此只在cpu的就绪队列队列rq和cfs调度器的就绪队列cfs_rq上需要保存其就绪队列的信息, 而实时进程的就绪队列rt_rq和dl_rq是不需要保存负荷权重的.
37.6.1 就绪队列的负荷权重计算
就绪队列的负荷权重存储的其实就是队列上所有进程的负荷权重的总和, 因此每次进程被加到就绪队列的时候, 就需要在就绪队列的负荷权重中加上进程的负荷权重, 同时由于就绪队列不是一个单独被调度的实体, 也就不需要优先级到负荷权重的转换, 因而其不需要负荷权重的重除字段, 即inv_weight = 0;
//struct load_weight {
/* 就绪队列的负荷权重 +/- 入队/出队进程的负荷权重 */
unsigned long weight +/- task_struct->se->load->weight;
/* 就绪队列负荷权重的重除字段无用途,所以始终置0 */
u32 inv_weight = 0;
//};因此进程从就绪队列上入队或者出队的时候, 就绪队列的负荷权重就加上或者减去进程的负荷权重, 内核为我们提供了增加/减少/重置就绪队列负荷权重的的函数, 分别是update_load_add, update_load_sub, update_load_set
[kernel/sched/fair.c]
/* 使得lw指向的负荷权重的值增加inc, 用于进程进入就绪队列时调用
* 进程入队account_entity_enqueue
*/
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
{
lw->weight += inc;
lw->inv_weight = 0;
}
/* 使得lw指向的负荷权重的值减少inc, 用于进程调出就绪队列时调用
* 进程出队account_entity_dequeue
*/
static inline void update_load_sub(struct load_weight *lw, unsigned long dec)
{
lw->weight -= dec;
lw->inv_weight = 0;
}
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}| 函数 | 描述 | 调用时机 | 定义位置 | 调用位置 |
|---|---|---|---|---|
| update_load_add | 使得lw指向的负荷权重的值增加inc | 用于进程进入就绪队列时调用 | [kernel/sched/fair.c] | [account_entity_enqueue两处], [sched_slice] |
| update_load_sub | 使得lw指向的负荷权重的值减少inc | 用于进程调出就绪队列时调用 | [update_load_sub] | [account_entity_dequeue两处] |
| update_load_set |
其中sched_slice()函数计算当前进程在调度延迟内期望的运行时间, 它根据cfs就绪队列中进程数确定一个最长时间间隔,然后看在该时间间隔内当前进程按照权重比例执行
37.7 虚拟运行时间
CFS调度算法的思想:理想状态下每个进程都能获得相同的时间片,并且同时运行在CPU上,但实际上一个CPU同一时刻运行的进程只能有一个。 也就是说,当一个进程占用CPU时,其他进程就必须等待。
假设现在系统有A,B,C三个进程,A.weight=1, B.weight=2, C.weight=3.那么我们可以计算出整个公平调度队列的总权重是cfs_rq.weight = 6,很自然的想法就是,公平就是你在重量中占的比重的多少来排你的重要性,那么,A的重要性就是1/6,同理,B和C的重要性分别是2/6,3/6. 很显然C最重要就应改被先调度,而且占用的资源也应该最多,即假设A,B,C运行一遍的总时间假设是6个时间单位的话,A占1个单位,B占2个单位,C占三个单位。这就是CFS的公平策略.
CFS为了实现公平,必须惩罚当前正在运行的进程,以使那些正在等待的进程下次被调度。
具体实现时,CFS通过每个进程的虚拟运行时间(vruntime)来衡量哪个进程最值得被调度。
CFS中的就绪队列是一棵以vruntime为键值的红黑树,虚拟时间越小的进程越靠近整个红黑树的最左端。因此,调度器每次选择位于红黑树最左端的那个进程,该进程的vruntime最小
虚拟运行时间是通过进程的实际运行时间和进程的权重(weight)计算出来的。
在CFS调度器中,将进程优先级这个概念弱化,而是强调进程的权重。一个进程的权重越大,则说明这个进程更需要运行,因此它的虚拟运行时间就越小,这样被调度的机会就越大。
那么,在用户态进程的优先级nice值与CFS调度器中的权重又有什么关系?在内核中通过prio_to_weight数组进行nice值和权重的转换。
37.7.1 虚拟时钟相关的数据结构
37.7.1.1 调度实体的虚拟时钟信息
这个虚拟时钟为什叫虚拟的,是因为这个时钟与具体的时钟晶振没有关系, 它与进程的权重有关, 权重越高,说明进程的优先级比较高,进而该进程虚拟时钟增长的就慢
既然虚拟时钟是调度实体(一个或者多个进程)的一种时间度量, 因此必须在调度实体中存储其虚拟时钟的信息
struct sched_entity
{
/* 负荷权重,这个决定了进程在CPU上的运行时间和被调度次数 */
struct load_weight load;
struct rb_node run_node;
/* 是否在就绪队列上 */
unsigned int on_rq;
/* 上次启动的时间 */
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
};sum_exec_runtime是用于记录该进程的CPU消耗时间,这个是真实的CPU消耗时间。在进程撤销时会将sum_exec_runtime保存到prev_sum_exec_runtime中
vruntime是本进程生命周期中在CPU上运行的虚拟时钟。那么何时应该更新这些时间呢? 这是通过调用update_curr实现的, 该函数在多处调用.
37.7.1.2 就绪队列上的虚拟时钟信息
完全公平调度器类sched_fair_class主要负责管理普通进程, 在全局的CPU就绪队列上存储了在CFS的就绪队列struct cfs_rq
进程的就绪队列中就存储了CFS相关的虚拟运行时钟的信息, struct cfs_rq定义如下:
struct cfs_rq
{
struct load_weight load; /*所有进程的累计负荷值*/
unsigned long nr_running; /*当前就绪队列的进程数*/
u64 min_vruntime; // 队列的虚拟时钟,
struct rb_root tasks_timeline; /*红黑树的头结点*/
struct rb_node *rb_leftmost; /*红黑树的最左面节点*/
struct sched_entity *curr; /*当前执行进程的可调度实体*/
...
};37.7.2 update_curr()函数计算进程虚拟时间
所有与虚拟时钟有关的计算都在update_curr()中执行, 该函数在系统中各个不同地方调用, 包括周期性调度器在内.
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
// 获取当前CPU的通用就绪队列保存的clock_task值,
// 该变量在每次时钟滴答(tick)到来时更新。
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
// 上一次调用update_curr()函数到现在的时间差,即实际运行的时间.
// 权重大的
// 权重值大的后期该值会变大
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
// 开始执行时间设为现在
curr->exec_start = now;
/* 将时间差加到先前统计的时间即可 */
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
// 虚拟运行时间不断增加
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}update_curr的流程如下
- 首先计算进程当前时间与上次启动时间的差值
- 通过负荷权重和当前时间模拟出进程的虚拟运行时钟
- 重新设置cfs的min_vruntime保持其单调性
37.7.2.1 计算时间差
/* 确定就绪队列的当前执行进程curr */
struct sched_entity *curr = cfs_rq->curr;首先, 该函数确定就绪队列的当前执行进程, 并获取主调度器就绪队列的实际时钟值, 该值在每个调度周期都会更新
/* rq_of -=> return cfs_rq->rq 返回cfs队列所在的全局就绪队列
* rq_clock_task返回了rq的clock_task */
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;辅助函数rq_of()用于确定与CFS就绪队列相关的struct rq实例, cfs_rq就绪队列中存储了指向就绪队列的实例, 而rq_of就返回了这个指向rq的指针, 即CPU就绪队列struct rq
rq_clock_task()函数获取当前就绪队列(每个CPU对应的通用就绪队列)保存的clock_task值,该变量在每次时钟滴答(tick)到来时更新。
/* 如果就队列上没有进程在执行, 则显然无事可做 */
if (unlikely(!curr))
return;
/* 内核计算当前和上一次更新负荷权重时两次的时间的差值 */
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;如果就绪队列上没有进程在执行, 则显然无事可做, 否则内核计算当前和上一次更新负荷权重时两次的时间的差值
delta_exec计算该进程从上次调用update_curr()函数到现在的时间差(实际运行的时间!!!)。
/* 重新更新启动时间exec_start为now */
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
/* 将时间差加到先前统计的时间即可 */
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);然后重新更新更新启动时间exec_start为now, 以备下次计算时使用
最后将计算出的时间差delta_exec, 加到了先前的统计时间上
37.7.2.2 模拟虚拟时钟
如何使用给出的信息来模拟不存在的虚拟时钟.
对于运行在nice级别0!!!的进程来说, 根据定义虚拟时钟和物理时间相等!!!.
在使用不同的优先级时, 必须根据进程的负荷权重重新衡定时间
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);其中calc_delta_fair函数是计算的关键
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}calc_delta_fair()使用delta_exec时间差来计算该进程的虚拟时间vruntime。
calc_delta_fair函数所做的就是根据下列公式计算:
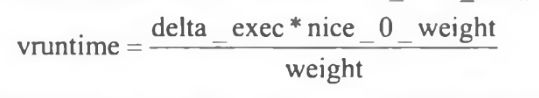
调度实体struct sched_entity数据结构中有一个成员weight, 用于记录该进程的权重。
calc_delta_fair()首先判断该调度实体的权重是否为NICE_0_LOAD,如果是,则直接使用该delta时间。
NICE_0_LOAD类似参考权重,__calc_delta()利用参考权重来计算虚拟时间。把nice值为0的进程作为一个参考进程,系统上所有的进程都以此为参照物,根据参考进程权重和权重的比值作为速率向前奔跑。
nice值范围是-20〜19,nice值越大,优先级越低。优先级越低的进程,其权重也越低。
因此按照vruntime的计算公式,进程权重小,那么vruntime值反而越大;反之,进程优先级高,权重也大,vruntime值反而越小。
每一个进程拥有一个vruntime, 每次需要调度的时候就选运行队列中拥有最小vruntime的那个进程来运行, vruntime在时钟中断里面被维护, 每次时钟中断都要更新当前进程的vruntime, 即vruntime以如下公式逐渐增长
那么curr->vruntime += calc_delta_fair(delta_exec, curr);即相当于如下操作
| 条件 | 公式 |
|---|---|
| curr.nice != NICE_0_LOAD | $curr->vruntime += delta_exec \times \dfrac{NICE_0_LOAD}{curr->se->load.weight}$ |
| curr.nice == NICE_0_LOAD | $ curr->vruntime += delta $ |
根据公式可知, nice = 0的进程(优先级120), 则虚拟时间和物理时间是相等的, 即current->se->load.weight等于NICE_0_LAD的情况.
CFS总是在红黑树中选择vruntime最小的进程进行调度,优先级高的进程总会被优先选择,随着vruntime增长(权限级高的后期vruntime值会变大),优先级低的进程也会有机会运行。
37.7.2.3 重新设置cfs_rq->min_vruntime
接着内核需要重新设置min_vruntime. 必须小心保证该值是单调递增的, 通过update_min_vruntime()函数来设置
我们通过分析update_min_vruntime函数设置cfs_rq->min_vruntime的流程如下
- 首先检测cfs就绪队列上是否有活动进程curr, 以此设置vruntime的值
如果cfs就绪队列上没有活动进程curr, 就设置vruntime为curr->vruntime; 否则又活动进程就设置为vruntime为cfs_rq的原min_vruntime;
-
接着检测cfs的红黑树上是否有最左节点, 即等待被调度的节点, 重新设置vruntime的值为curr进程和最左进程rb_leftmost的vruntime较小者的值
-
为了保证min_vruntime单调不减, 只有在vruntime超出的cfs_rq->min_vruntime的时候才更新
37.8 红黑树的键值entity_key和entity_before
37.x 进程调度相关的初始化sched_fork()
__sched_fork()函数会把新创建进程的调度实体se相关成员初始化为0, 因为这些值不能复用父进程,子进程将来要加入调度器中参与调度,和父进程“分道扬镳”。
[do_fork()->sched_fork()->_sched_fork()]
[kernel/sched/core.c]
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
#ifdef CONFIG_SMP
p->se.avg.decay_count = 0;
#endif
INIT_LIST_HEAD(&p->se.group_node);
}继续看sched_fork()函数,设置子进程运行状态为TASK_RUNNING,这里不是真正开始运行,因为还没添加到调度器里。
[do_fork() ->sched_fork()]
[kernel/sched/core.c]
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
int cpu = get_cpu();
__sched_fork(clone_flags, p);
p->state = TASK_RUNNING;
p->prio = current->normal_prio;
if (dl_prio(p->prio)) {
put_cpu();
return -EAGAIN;
} else if (rt_prio(p->prio)) {
p->sched_class = &rt_sched_class;
} else {
p->sched_class = &fair_sched_class;
}
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
set_task_cpu(p, cpu);
put_cpu();
return 0;
}根据新进程的优先级确定相应的调度类.每个调度类都定义了一套操作方法集,调用CFS调度器的task_fork()方法做一些fork相关的初始化。
CFS调度器调度类定义的操作方法是task_fork_fair()
task_fork方法实现在kernel/fair.c文件中。
[do_fork()->sched_fork()->task_fork_fair()]
[kernel/sched/fair.c]
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
int this_cpu = smp_processor_id();
struct rq *rq = this_rq();
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
rcu_read_lock();
// 重点
__set_task_cpu(p, this_cpu);
rcu_read_unlock();
// 重点
update_curr(cfs_rq);
if (curr)
se->vruntime = curr->vruntime;
place_entity(cfs_rq, se, 1);
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
se->vruntime -= cfs_rq->min_vruntime;
raw_spin_unlock_irqrestore(&rq->lock, flags);
}se表示新进程的调度实体,由current变量(当前进程task_struct数据结构!!!)通过函数task_cfs_rp()取得当前进程对应的CFS调度器就绪队列的数据结构(cfs_rq )。调度器代码中经常有类似的转换,例如取出当前CPU的通用就绪队列struct rq 数据结构,取出当前进程对应的通用就绪队列,取出当前进程对应的CFS调度器就绪队列等。
task_cfs_rq()函数可以取出当前进程对应的CFS就绪队列:
#define task_thread_info(task) ((struct thread_info *)(task)->stack)
static inline unsigned int task_cpu(const struct task_struct *p)
{
return task_thread_info(p)->cpu;
}
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
#define task_rq(p) cpu_rq(task_cpu(p))
static inline struct cfs_rq *task_cfs_rq(struct task_struct *p)
{
return &task_rq(p)->cfs;
}task_fork_fair()函数中__set_task_cpu()把当前CPU绑定到该进程中(struct task_struct中的stack
[kernel/sched/sched.h]
static inline void __set_task_cpu(struct task_struct *p, unsigned int cpu)
{
set_task_rq(p, cpu);
#ifdef CONFIG_SMP
smp_wmb();
// 当前CPU绑定到该进程中
task_thread_info(p)->cpu = cpu;
p->wake_cpu = cpu;
#endif
}