Java - File类 / 输入输出流 / IO流(FileReader、FileWriter、FileInputStream、FileOnputStream、缓冲流、转换流)
目录
- File类
- File类的常用构造器
- File类的常用方法
- File类的使用
- IO流原理及流的分类
- FileReader读入数据的操作
- FileWriter写出数据的操作
- FileInputStream和FileOnputStream复制文件操作
- BufferedInputStream和BufferedOutputStream复制文件操作
- BufferedReader和BufferedWriter复制文本文件操作
- 获取文本上字符出现的次数
- 转换流InputStreamReader和OutputStreamWriter
- 标准输入输出流
- 打印流PrintStream和PrintWriter
- 对象流ObjectInputStream和ObjectOutputStream
- 多线程搜索文件的关键字
File类
java.io.File 类能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容,则需要使用输入流/输出流。
想要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对象,但是Java程序中的一个File对象,可能没有一个真实存在的文件或目录。
File类的常用构造器
若硬盘中有一个真实存在的文件或目录,创建File对象时,各个属性会显式赋值。当硬盘中没有真实的文件或目录对应时,那么创建File对象时,除了指定的目录和路径之外,其他的属性都是取成员变量的默认值。
//以pathname为路径创建File对象,可以是绝对路径或相对路径
public File(String pathname)
//以parent为父路径,child为子路径创建File对象
public File(String parent, String child)
//关于一个父File对象,child为子路径创建File对象
public File(File parent, String child)
//以URI对象创建File对象
public File(URI uri)
路径中的每级目录之间用一个路径分割符隔开。在Windows下默认使用 “ \ ”,在UNIX和Linux下默认使用 “ / ”。Java提供一个常量File.separator,根据操作系统动态提供分隔符。
File file1 = new File("D:\\Java\\File");
File file2 = new File("D:"+File.separator+"Java"+File.separator+"File");
File file3 = new File("D:/Java/File");
此时的file1对象是在内存层面的,在硬盘中不一定存在。
File类的常用方法
|——public String getAbsolutePath():获取绝对路径
|——public String getPath():获取路径
|——public String getName():获取名称
|——public String getParent():获取上层文件目录路径,若无返回null
|——public long length():获取文件字节数,不能获取目录的字节数
|——public long lastModified():获取最后一次修改时间(毫秒值)
|——public String[] list():获取指定目录下的所有文件或文件目录的名称数组
|——public File[] listFiles():获取指定目录下的所有文件或文件目录的File数组
|——public boolean renameTo(File dest):文件重命名(源文件在硬盘必须存在,目标文件不能在硬盘存在)
File——|——public boolean isDirectory():判断是否是文件目录
|——public boolean isFile():判断是否是文件
|——public boolean exists():判断是否是存在
|——public boolean canRead():判断是否可读
|——public boolean canWrite():判断是否可写
|——public boolean isHidden():判断是否隐藏
|——public boolean createNewFile():创建文件。若文件存在,则不创建,返回false
|——public boolean mkdir():创建文件目录。若此文件目录存在,则不创建。若其上层目录不存在,也不创建
|——public boolean mkdir():创建文件目录。若此文件目录存在,则不创建。若其上层目录不存在,一并创建
|——public boolean delete():删除文件或文件夹(如果文件夹内有文件则删除失败)
File类的使用
1. 将指定目录下的 .jpg 文件重命名:
File[] files =new File("D:\\Java\\eclipse-workspace\\study").listFiles();
StringBuilder builder = new StringBuilder("图片1.jpg");
int i = 1;
for(File file : files) { //遍历目录下的文件
if(file.isFile()) {
if(file.getName().endsWith(".jpg")) {
file.renameTo(new File(builder.toString())); //重命名
builder.delete(2, builder.length());
builder.append(++i+".jpg");
}
}
}
2. 遍历指定目录下的所有文件和文件夹,并输出文件数、文件夹数、总大小:
import java.io.File;
public class FileTest {
private static int fileNum = 0; // 文件数
private static int folderNum = 0; // 文件夹数
private static int total = 0; // 总大小
public static void search(File[] folder) {
for (File file : folder) {
if (file.isFile()) { //文件
fileNum++;
total += file.length();
} else { //文件夹
folderNum++;
search(file.listFiles()); //深度遍历
}
}
}
public static void main(String[] args) {
search(new File("C:\\Users\\HP\\Desktop").listFiles());
System.out.println("文件数:" + fileNum);
System.out.println("文件夹数:" + folderNum);
System.out.println("总大小:" + total + " kb");
}
}
运行结果:
文件数:1346
文件夹数:142
总大小:1525166593 byte
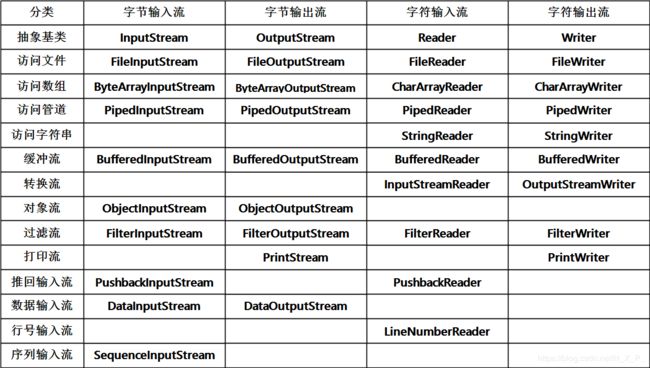
IO流原理及流的分类
I/O的Input/Output的缩写,在Java程序中,对于数据的输入/输出操作以“流”(stream)的方式进行。
输入Input:读取外部数据(磁盘等存储设备)的数据到程序(内存)。
输出Output:将程序(内存)数据输出到硬盘等存储设备中。
流的分类:
按操作数据单位不同分为:字节流(8 bit),字符流(16 bit)
按数据流的流向不同分为:输入流,输出流
按流的角色的不同分为:节点流,处理流

Java的IO共涉及多个类,实际上都是从上面4个抽象基类派生,由这4个类派生出来的子类名称都是以其父类名作为子类名的后缀,如FileInputStream,BufferedReader,PrintWriter等等。
字节流适用于非文本文件(.jpg、.mp3、.mp4、.avi、.doc、.ppt……);字符型适用于文本文件(.txt、.java、.c……)。不能使用字符流来处理图片等文件。
我们称FileInputStream、FileOutputStream、FileReader、FileWriter等为节点流,可以从或向一个特定的地方(节点)读写数据。而其他的流则为处理流,对一个已存在的流的连接和封装(套上),通过所封装的流的功能调用实现数据读写。
FileReader读入数据的操作
读入的文件必须存在,否则会报FileNotFoundException。
步骤:
1. 提供File对象,指明要操作的文件。
2. 提供FileReader对象,用于数据的读入。
read() 返回读入的一个字符的字节码,如果到达文件末尾则返回-1。
read(char[]) 返回读入字符的个数,字符存在数组里面,如果到达文件末尾则返回-1。
3. 进行读入操作。
4. 流资源关闭。
public static void readFile() {
File file = new File("hello.txt"); //指定要读取的文件
if (file.exists()) {
FileReader reader = null;
try {
reader = new FileReader(file);
/*方式一
int data;
while ((data = reader.read()) != -1) {
System.out.print((char) data);
}*/
//方式二
int number;
char[] ch = new char[10];
while ((number = reader.read(ch)) != -1) {
for(int i = 0;i < number; i++)
System.out.print(ch[i]);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (reader != null) {
reader.close(); //关闭流
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
FileWriter写出数据的操作
如果对应的文件在硬盘中不存在,则创建此文件。
如果对应的文件在硬盘中存在:
如果使用的构造器是 FileWriter(file) 或 FileWriter(file, false),则对原来的文件覆盖。
如果使用的构造器是 FileWriter(file, true),则在原来的文件追加内容。
public static void writeFile() {
File file = new File("writeFile.txt"); //指定要写入的文件
FileWriter writer = null;
try {
writer = new FileWriter(file);
writer.write(new Date().toString()+"\n"); //写入内容
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
writer.close(); //关闭流
} catch (IOException e) {
e.printStackTrace();
}
}
}
FileInputStream和FileOnputStream复制文件操作
public static void copyFile(String srcPath, String destPath) {
File source = new File(srcPath); //源文件
File dest = new File(destPath); //目标文件
if (source.exists()) {
FileInputStream input = null;
FileOutputStream output = null;
try {
input = new FileInputStream(source);
output = new FileOutputStream(dest);
byte[] buffer = new byte[1024];
int number;
while ((number = input.read(buffer)) != -1) { //读取
output.write(buffer, 0, number); //写入
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (input != null) {
input.close(); // 关闭流
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (output != null) {
output.close(); // 关闭流
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
String srcParh = "source.txt";
String destPath = "dest.txt";
copyFile(srcParh, destPath);
}
BufferedInputStream和BufferedOutputStream复制文件操作
为了提高效率,我们可以在FileInputStream和FileOutputStream外面套上一层缓冲流BufferedInputStream、BufferedOutputStream。因为其内部提供了缓冲区,这样可以明显提高运行速度。
public static void BuffercopyTest(String srcPath, String destPath) {
File source = new File(srcPath);
File dest = new File(destPath);
if(source.exists()) {
BufferedInputStream input = null;
BufferedOutputStream output = null;
try {
FileInputStream fis = new FileInputStream(source);
FileOutputStream fos = new FileOutputStream(dest);
//造缓冲流
input = new BufferedInputStream(fis); //把FileInputStream放进去
output = new BufferedOutputStream(fos); //把FileOutputStream放进去
byte[] buffer = new byte[1024];
int number;
while ((number = input.read(buffer)) != -1) {
output.write(buffer, 0, number);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(input != null)
input.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(output != null)
output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
采用FileInputStream和FileOnputStream复制70MB的视频所耗的时间:718 ms
加上BufferedInputStream和BufferedOutputStream复制70MB的视频所耗的时间:141 ms
有一个细节:关闭外层流的同时,内层流也会自动关闭,所以内层流的关闭可以省略。
BufferedReader和BufferedWriter复制文本文件操作
public static void BuffercopyText(String srcPath, String destPath) {
BufferedReader reader = null;
BufferedWriter writer = null;
try {
reader = new BufferedReader(new FileReader(new File(srcPath)));
writer = new BufferedWriter(new FileWriter(new File(destPath)));
/* 方式一
char[] ch = new char[10];
int number;
while ((number = reader.read(ch)) != -1) {
writer.write(ch, 0, number);
}*/
// 方式二(这种方式没有换行)
String data;
while ((data = reader.readLine()) != null) {
writer.write(data+"\n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(reader != null)
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(writer != null)
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
获取文本上字符出现的次数
注意当HashMap有相同的key时会替换value。
public static void countTest(String srcPath, String deetPath) {
Map<String, Integer> map = new HashMap<String, Integer>();
BufferedReader reader = null;
BufferedWriter writer = null;
try {
reader = new BufferedReader(new FileReader(new File(srcPath)));
writer = new BufferedWriter(new FileWriter(new File(deetPath)));
int data;
while ((data = reader.read()) != -1) {
String string = String.valueOf((char)data);
if(map.get(string) == null) {
map.put(string, 1);
}else {
map.put(string, map.get(string)+1);
}
}
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for(Map.Entry<String, Integer> entry : entrySet) {
switch (entry.getKey()) {
case " ":
writer.write("blankspace= "+entry.getValue());
break;
case "\n":
writer.write("newline= "+entry.getValue());
break;
case "\r":
writer.write("Enter= "+entry.getValue());
break;
case "\t":
writer.write("tab= "+entry.getValue());
break;
default:writer.write(entry.getKey()+"= "+entry.getValue());
break;
}
writer.newLine(); //换行
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(reader != null)
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(writer != null)
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
转换流InputStreamReader和OutputStreamWriter
转换流提供了在字节流和字符流之间的转换。当字节流中的数据都是字符时,转换成字符流操作更高效。很多时候我们使用转换流来处理文件乱码问题,实现编码和解码的功能。
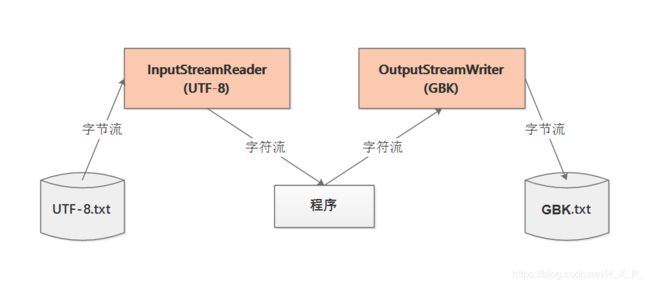
InputStreamReader:将InputStream转换成Reader
OutputStreamWriter:将OutputStream转换成Writer
//使用系统默认的字符集
InputStreamReader isr = new InputStreamReader(new FileInputStream(new File(srcPath)));
//使用指定的字符集GBK
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(new File(destPath),"GBK");
BufferedReader reader = new BufferedReader(isr);
BufferedWriter writer = new BufferedWriter(osw);
标准输入输出流
System.in和System.out方便代表了系统标准输入和输出,对应的设备是键盘和显示器。System.in的类型是InputStream,System.out的类型是PrintStream。
从键盘读入数据:
//方式一
Scanner scanner = new Scanner(Systrm.in);
String string = scanner.next();
//方式二
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
String data = br.readLine();
打印流PrintStream和PrintWriter
打印流PrintStream和PrintWriter提供了一系列重载的print()和println(),实现将基本数据类型的数据格式转化为字符串输出。
PrintStream和PrintWriter的输出不会抛出IOException异常。二者都有自动flush功能。
public static void printTest(String scrPath) {
PrintStream stream = null;
try {
FileOutputStream output = new FileOutputStream(new File(scrPath));
//创建打印输出流,设置为自动刷新模式(写入换行符或字节'\n'时都会刷新缓冲区
stream = new PrintStream(output, true);
if (stream != null) {
//把标准输出流(控制台输出)改成文件
System.setOut(stream);
}
for (int i = 0; i < 50; i++) {
System.out.print((char) i); //输出ASCII
if(i % 10 ==0)
System.out.println(); //换行
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (stream != null) {
stream.close(); // 关闭流
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
对象流ObjectInputStream和ObjectOutputStream
对象流用于存储和读取基本数据类型数据或对象的处理流。它的强大之处就是可以把Java中的对象写入数据源中,也能把对象从数据源中还原回来。
序列化:用ObjectOutputStream类保存基本数据类型或对象的机制。
反序列化:用ObjectInputStream类读取基本数据类型或对象的机制。
对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久的保存在磁盘中,或通过网络将这种二进制流传输到另一个网络节点,当其他程序获取这种二进制流就可以恢复成原来的Java对象。
序列化的好处在于可以将任何实现了Serializable的接口的对象转化成字节数据,使其在保存和传输时可被还原。
如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的这个类,必须实现Serializable、Externalizable接口之一,否则会抛出NotSerializableException异常。
我们来序列化下面的Good对象,除了当前Good类需要实现Serializable接口外,还必须保证其内部所有属性也必须是可序列化的(默认情况下,基本数据类型是可序列化的)。但是ObjectInputStream和ObjectOutputStream不能序列化 static 和 transient 修饰的成员变量。
class Good implements Serializable{
//serialVersionUID可以随便,用于标识对象
public static final long serialVersionUID = 123456789L;
private int price;
private String name;
public Good(String name,int price) {
this.price=price;
this.name=name;
}
public int getPrice() { return price; }
public void setPrice(int price) { this.price = price; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
}
凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态常量。serialVersionUID用来表明类的不同版本间的兼容性,简言之,其目的是以序列化对象进行版本控制,有关各版本反序列化时是否兼容。如果类没有显式定义这个静态变量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID可能发生变化,进而会抛出InvalidCastException。
public static void ObjectSerialized() {
ObjectOutputStream output = null;
try {
output = new ObjectOutputStream(new FileOutputStream("object.dat"));
output.writeObject(new Good("computer", 3000));
output.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (output != null) {
try {
output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
System.out.println("对象序列化成功!开始反序列化……");
ObjectInputStream input = null;
try {
input = new ObjectInputStream(new FileInputStream("object.dat"));
Good good = (Good)input.readObject();
System.out.println(good);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (input != null) {
try {
input.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
运行结果:
对象序列化成功!开始反序列化……
[computer: 3000]
多线程搜索文件的关键字
对于许多线程问题,可以通过使用一个或多个队列以优雅且安全的方式将其形式化。生产者线程向队列插人元素,消费者线程则取出它们。使用队列,可以安全地从一个线程向另一个线程传递数据。(668)
下面的程序展示了如何使用阻塞队列来控制一组线程。程序在一个目录及它的所有子目录下搜索所有文件,打印出包含指定关键字的行。
import java.io.*;
import java.util.*;
import java.util.concurrent.*;
public class test {
private static final int FILE_QUEUE_SIZE = 10;
private static final int SEARCH_THREADS = 100;
private static final File DUMMY = new File("");
private static BlockingQueue<File> queue = new ArrayBlockingQueue<>(FILE_QUEUE_SIZE);
public static void main(String[] args) {
try (Scanner in = new Scanner(System.in)) {
System.out.print("Enter base directory (e.g. /opt/jdkl.8.0/src): ");
String directory = in.nextLine();
System.out.print("Enter keyword (e.g. volatile): ");
String keyword = in.nextLine();
Runnable enumerator = () -> {
try {
enumerate(new File(directory)); //搜索所有的文件
queue.put(DUMMY); //结束标记
} catch (InterruptedException e) {
e.printStackTrace();
}
};
new Thread(enumerator).start();
for (int i = 1; i <= SEARCH_THREADS; i++) {
Runnable searcher = () -> { //多线程搜索关键字
try {
boolean done = false;
while (!done) {
File file = queue.take();
if (file == DUMMY) {
queue.put(file);
done = true;
} else
search(file, keyword);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
};
new Thread(searcher).start();
}
}
}
/**
* Recursively enumerates all files in a given directory and its subdirectories.
*
* @paran directory the directory in which to start
*/
public static void enumerate(File directory) throws InterruptedException {
File[] files = directory.listFiles();
for (File file : files) {
if (file.isDirectory())
enumerate(file);
else
queue.put(file);
}
}
/**
* Searches a file for a given keyword and prints all matching lines.
*
* @param file the file to search
* @param keyword the keyword to search for
*/
public static void search(File file, String keyword) throws IOException {
try (Scanner in = new Scanner(file, "UTF-8")) {
int lineNumber = 0;
while (in.hasNextLine()) {
lineNumber++;
String line = in.nextLine();
if (line.contains(keyword))
System.out.printf("56s:%d:%s%n", file.getPath(), lineNumber, line);
}
}
}
}
生产者线程枚举在所有子目录下的所有文件并把它们放到一个阻塞队列中。这个操作很快,如果没有上限的话,很快就包含了所有找到的文件。
我们同时启动了大量搜索线程。每个搜索线程从队列中取出一个文件,打开它,打印所有包含该关键字的行,然后取出下一个文件。我们使用一个小技巧在工作结束后终止这个应用程序。为了发出完成信号,枚举线程放置一个虚拟对象到队列中(DUMMY)当搜索线程取到这个虚拟对象时,将其放回并终止。
如有错误请大家指出了(ง •̀_•́)ง (*•̀ㅂ•́)و