和你一起分析网站 - 之携程(机票价格)
前几天在网上看到有人说不清楚怎么爬携程的机票价钱,然后自己去大概看了一下,大概知道是怎么回事,现在和大家分享一下分析的过程。
准备工作
我用到Chrome浏览器,Python里的requests库作为发请求的工具。
本次分析的网址是 http://flights.ctrip.com/itinerary/oneway/szx-hak?date=2019-02-01 深圳到海口的机票查询
分析过程
寻找URL
网页:
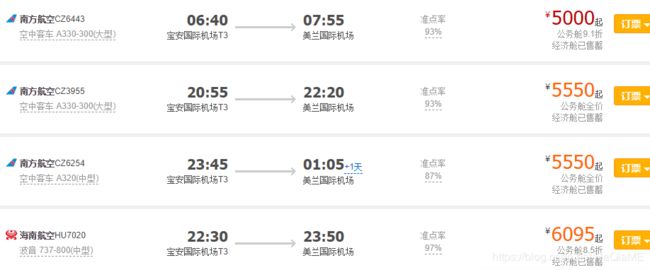
之后谷歌浏览器F12里Network标签看一下

通常机票价格这种东西都是通过ajax动态拉数据的,而且刷新页面的时候也可以明显感觉到页面的其它部分先刷新出来,而机票信息是延迟出现的,也可以说明是ajax动态获取的。
可以看到记录很多,那要怎么找到机票价格的那条记录呢?可以直接用谷歌的过滤XHR过滤出所有的ajax请求。
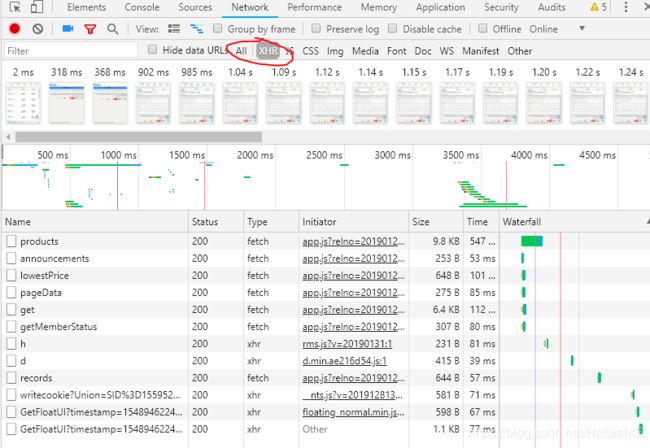
直接过滤了很多请求,只剩一点点了。这个时候最简单的就是直接一个一个看,分析各个请求的响应是不是我们要找的那个带有价格的相应。

很快可以找到,products这个请求就是包含所有价格信息的请求,我也要爬的话也是爬这个请求。
其实还有很多方法,比如说我们逐个block掉每一个ajax请求,再刷新,如果页面无法正常显示价格信息,那么是哪个请求也就一目了然了。
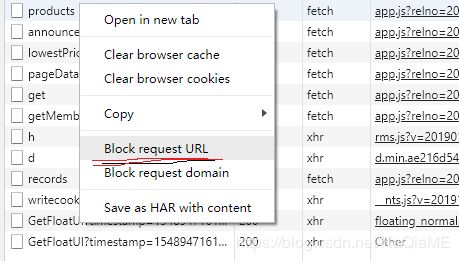
模拟请求
此时我们已经找到了需要模拟的请求和一些http的参数信息。
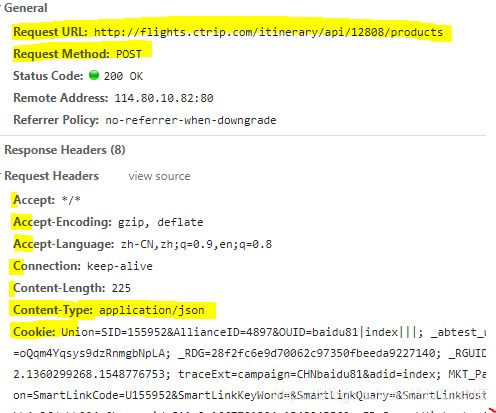
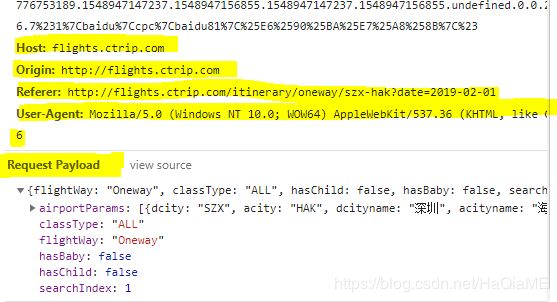
我们需要关注的信息都在图中标记出来了。(以下内容需要先了解HTTP协议知识)
1、URL http://flights.ctrip.com/itinerary/api/12808/products
2、POST 请求方式
3、其他头部和参数信息。。。
经过测试呢,发现携程后台关注的有:header有Content-Type,Origin,Referer,User-Agent,参数信息payload
(不要问我怎么测试的,因为我是一个一个试的,如果有好方法还望告知。)
Python 爬虫实例
import requests
url = r'http://flights.ctrip.com/itinerary/api/12808/products'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3559.6 Safari/537.36','Referer': 'http://flights.ctrip.com/itinerary/oneway/szx-hak?date=2019-02-01','Origin': 'http://flights.ctrip.com','Cookie': 'Union=SID=155952&AllianceID=4897&OUID=baidu81|index|||; _abtest_userid=2a37843e-d51d-454c-ba6d-eefa4d9c90a1; _RSG=oQqm4Yqsys9dzRnmgbNpLA; _RDG=28f2fc6e9d70062c97350fbeeda9227140; _RGUID=9dbcdb48-84c3-46b2-a573-5e5ab0c5bf67; _ga=GA1.2.1360299268.1548776753; traceExt=campaign=CHNbaidu81&adid=index; MKT_Pagesource=PC; StartCity_Pkg=PkgStartCity=2; Session=SmartLinkCode=U155952&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=&SmartLinkLanguage=zh; gad_city=246c9f05866ade9bb4e3fdabb004e6be; _gid=GA1.2.1667701804.1548945569; FD_SearchHistorty={"type":"S","data":"S%24%u6DF1%u5733%28SZX%29%24SZX%242019-01-31%24%u6D77%u53E3%28HAK%29%24HAK%24%24%24"}; _RF1=121.35.182.69; _bfi=p1%3D10320673302%26p2%3D10320673302%26v1%3D25%26v2%3D24; _gat=1; _bfa=1.1548776750288.32qtq1.1.1548779881067.1548945551633.3.27; _bfs=1.7; Mkt_UnionRecord=%5B%7B%22aid%22%3A%224897%22%2C%22timestamp%22%3A1548947156839%7D%5D; _jzqco=%7C%7C%7C%7C1548945585011%7C1.1062907472.1548776753189.1548947147237.1548947156855.1548947147237.1548947156855.undefined.0.0.25.25; __zpspc=9.4.1548945570.1548947156.7%231%7Cbaidu%7Ccpc%7Cbaidu81%7C%25E6%2590%25BA%25E7%25A8%258B%7C%23','Content-Type': 'application/json'}
payload = '{"flightWay":"Oneway","classType":"ALL","hasChild":false,"hasBaby":false,"searchIndex":1,"airportParams":[{"dcity":"SZX","acity":"HAK","dcityname":"深圳","acityname":"海口","date":"2019-02-01","dcityid":30,"acityid":42}]}'
r = requests.post(url, headers = headers, data = payload)
with open(r"e:\1.txt", 'w') as f:
f.write(r.content)这样爬取携程机票价格的第一步就完成了。
接下来的工作主要就是分析cookie的来源和payload的组成以及响应信息的结构。
总结
不知是不是我技艺不精,目前为止,携程在这个页面的反爬虫机制不是很完善,但是不知道会不会在cookie做很多限制。总之多多练习就明白各个网站的组成。ps:本文仅供学习参考。