python3爬虫系列20之反爬需要登录的网站三种处理方式
python3爬虫系列20之反爬需要登录的网站三种处理方式
1.前言
在上一篇文章中,讲了python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用,实际上这是属于反爬中的一个了,在数据采集的过程中,基本上经常遇到这些情况,所以,如果要写持久型采集方案,多要采用这些方式。
在以往的案例中,我们都是爬那些不需要登录或者登陆要求不高的网站。
那么当你在爬某些网站的时候,需要你登录才可以获取数据,怎么办?
登录的常见方法无非是这两种
- 1、让你输入 帐号和密码登录
- 2、让你输入 帐号密码+验证码登录
今天先说第一种问题的处理办法。
第一招Cookie法:requests直接携带cookies信息
简单来说
你平常在网站的时,你只要登录一次,就可以一直看到你想要的内容,过了一阵子才需要再次登录。或者下次打开仍然在登录状态中的?
因为就是每一个使用这个网站的人,服务器都会给他一个 Cookie,那么下次你再请求数据的时候,你顺带把这个 Cookie 传过去,服务器一看有登录过直接返回数据给他。
【Cookie 的时长周期是服务器那边决定的,有的时候过去了就需要重新登录。】
拿去某个网站的个人Cookie 信息?
首先使用你的账号密码,登录该爬虫目标网站,然后点开如下:
目标网站:https://www.zhihu.com/people/787656329/activities
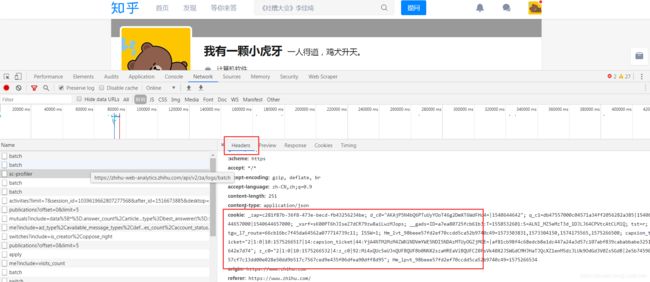
复制出Cookie 信息。
写代码:
import requests
#get请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
#把拿到的Cookie塞进来
'cookie': '_zap=c281f87b-36f8-473e-becd-fb43256234be; d_c0="AKAjP5N4bQ6PTuUyYOoT46g2DmXT6WdFHd4=|1540644642"; q_c1=db47557000c04571a34ff2056282a385|1540644657000|1540644657000;xxxx'
}
url='https://www.zhihu.com/people/787656329/activities' # 主页地址
session = requests.Session()
# 直接发送requests.Session的get去登录
response = session.get(url, headers=headers)
print(response.text)
运行一下;

可以发现不用输入账号密码登录就可以直接拿到自己的个人信息。
第二招表单请求法:post携带参数请求
做个web开发的都知道,表单请求实际上就是post携带参数发出请求去。
所以我们要把账号密码等写入参数中,打包扔给post带走。

要把账号密码等写入参数中:
发送有参数的post请求
import requests
session = requests.session()
url = 'http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LIcAc'
postdata = {
'username': 'xxxx',
'password': 'xxxxx'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36'}
response = session.post(url, data=postdata, headers=headers)
print(response.content)
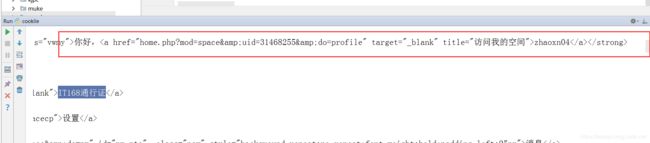
运行一下:

拿到信息:
第三招Selenium 自动登录法:
Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。
Selenium 自动登录很简单:
基本上步骤就是:
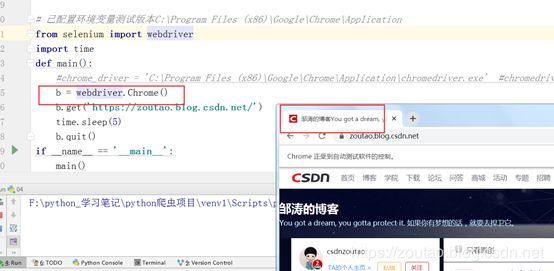
获取到两个输入框的元素,再获取到登录按钮,往输入框写你的帐号密码,自动点击登录。登录完之后拿到 Cookie信息,有了 Cookie 就可以继续爬虫。拿你想要的数据了。
driver = webdriver.Chrome() # 或填入chromedriver.exe的绝对路径
url='https://passport.csdn.net/login?code=public'
driver.get(url)
driver.find_element_by_id('all').send_keys('xxxx@qq.com') # 账号
driver.find_element_by_id('password-number').send_keys('xxxxxxx') # 密码
driver.find_element_by_class_name('btn.btn-primary').click() # 登录按钮
然后就进来了
其实三种方法中,前两种可以应用基本不需要验证码的网站了,然后第三种方法一般用在一些比较难的登录网站中。关于它的实战,下一篇。
番外:自动化selenium库的安装
什么是 selenium ?
其实它就是一个自动化测试工具,支持各种主流的浏览器
类似按键精灵,可以直接运行在浏览器上。
因为做 Python 爬虫时候,多多少少要用到自动化测试软件的 selenium 库,所以特意补上安装和配置selenium (好吧,实际上是为了凑字数。。。)。
我们先来安装一下:
pip install selenium
接着我们还要下载浏览器驱动:
默认是支持的Firefox Driver,但是我用的是 Chrome 浏览器。
所以下载的是 Chrome 驱动,当然你用别的浏览器也阔以,去相应的地方下载就行了。
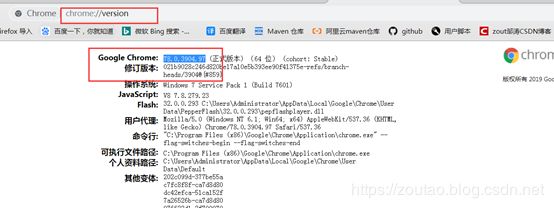
所以,首先需要查看你的Chrome版本,在浏览器中输入chrome://version/
获取Chrome版本号
驱动所有版本地址:(2选一)
https://chromedriver.storage.googleapis.com/index.html
https://npm.taobao.org/mirrors/chromedriver/
下载一个对应的:
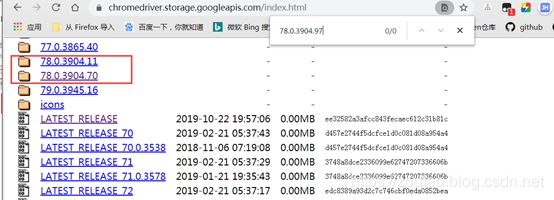
直接按照浏览器版本去找对应的driver(只对应大版本就行),不用再费心去对应了
点击notes.txt就可查看其对应的版本号,如下:

下载下来,然后安装,你可以在pycharm里面测试版本是否正确了?
pycharm里面测试:
from selenium import webdriver
import time
def main():
chrome_driver = 'H:\python3anzhuang\chromedriver_win32\chromedriver.exe' #chromedriver的文件位置
b = webdriver.Chrome(executable_path = chrome_driver)
b.get('https://zoutao.blog.csdn.net/')
time.sleep(5)
b.quit()
if __name__ == '__main__':
main()
然后会出现这样的效果:

那就ok了。
报错解决
报错如下:
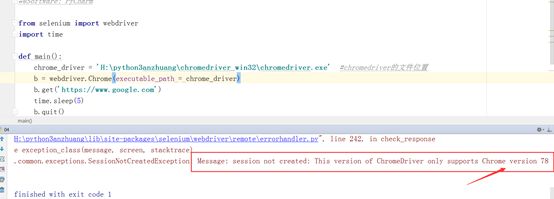
这就表示你安装的驱动版本跟你的浏览器版本不对应。重新去下载。
2.chromedriver.exe环境路径报错。
进入环境变量编辑界面,添加到用户变量即可,双击PATH,将你的文件位置(C:\Program Files (x86)\Google\Chrome\Application\)添加到后面。
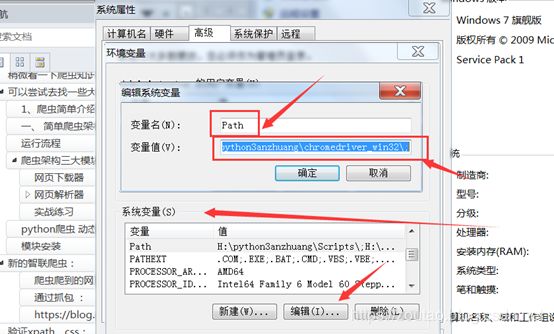
完成后在cmd下输入chromedriver验证是否安装成功:(任意路径下输入)

如果你配置了环境变量和下载看对的驱动,运行代码的时候还是出现如下错误:
selenium.common.exceptions.WebDriverException: Message: ‘chromedriver’ executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home

解决办法:
要么指定路径,

那么代码每次都需要指定exe的路径:

要么就是:
把驱动这个东西,默认放到chrome的文件路径下去,
默认的路径为:C:\Program Files (x86)\Google\Chrome\Application
从网上下载对应版本的chromedriver之后,里面的内容仅为一个.exe文件,将其解压在chrome的安装目录下(C:\Program Files (x86)\Google\Chrome\Application),然后再配置环境变量
- 进入我的电脑->属性->高级系统设置->环境变量
- 修改path在最后面添加 ;C:\Program Files (x86)\Google\Chrome\Application\
- OK。然后重启一下pycharm,在运行测试代码。安装与配置就到此结束。。

代码就可以不用写exe的路径了:

算了,安装这种小事情,我懒得写了,直接去
安装参考:https://www.cnblogs.com/lfri/p/10542797.html
selenium的使用方法
selenium 提供了挺多方法给我们获取的数据。
想要在页面【获取一个元素】的时候,使用这些方法
• find_element_by_id
• find_element_by_name
• find_element_by_xpath
• find_element_by_link_text
• find_element_by_partial_link_text
• find_element_by_tag_name
• find_element_by_class_name
• find_element_by_css_selector
想要在页面【获取多个元素】,就可以这样:
• find_elements_by_name
• find_elements_by_xpath
• find_elements_by_link_text
• find_elements_by_partial_link_text
• find_elements_by_tag_name
• find_elements_by_class_name
• find_elements_by_css_selector
返回的是一个list列表。
我还是不适合写这种安装步骤啥的文章,太鸡儿墨迹了。。。