走进RecyclerView未解之迷 ------ 原理和优化
(前言暂位符号)
View holder究竟是什么?
Problem
- View holder 和 item view 是什么关系? 一对一?一对多?多对一?
- View holder 解决的是什么问题?
- View holder 和 ListView 的 item view 的复用有什么关系?
没有实现 View holder 的 getView() 的例子如下,大量的 findViewById() 方法被调用,看似不是很大的开销,但其方法的底层实现是深度优先搜索,时间复杂度是O(n)。
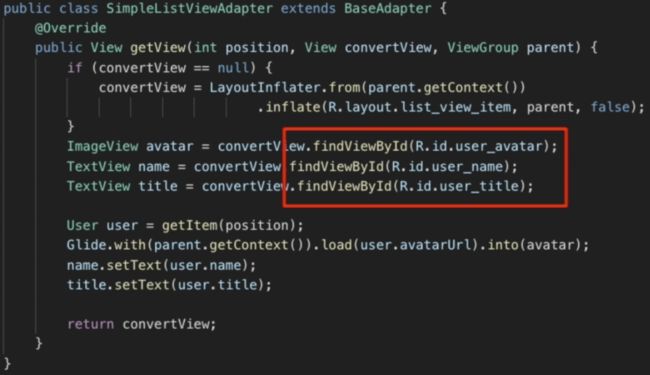
完全可以避免以上不必要开支,见下例子,通过setTag()、getTag()复用view,只有在第一次convertView为空的时候去创建ViewHolder,并调用findViewById将convertView中的view赋值到holder中,并且将holder存起来留给下次复用,避免重复找view操作。这也是 ViewHolder名字的来历:用来保存View的容器。
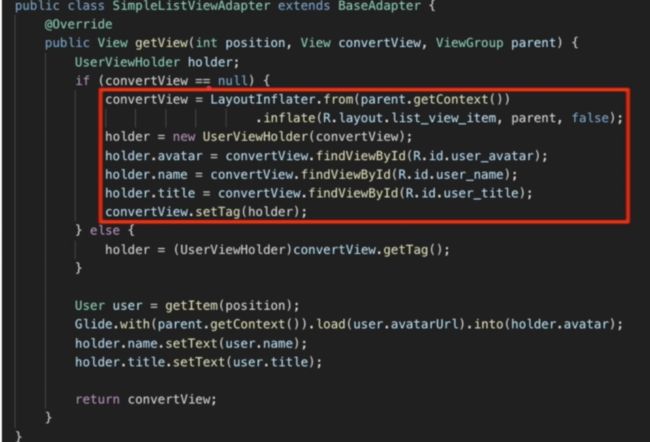
setTag() 为什么可以绑定convertView和holder?其实这里的内部实现很简单,把任意一个对象Object作为参数(成员变量)存到View当中,另一种方法则是用Key、Value的方式进行绑定。
ANSWER
-
Item view 和 view holder 是一一对应的关系;
-
View holder解决的是防止重复进行
findViewById,提升效率; -
没什么关系,对比以上2个例子,第一个效率不高的
getView()方法中可见即使没有使用View holder的存在,但是通过convertView的空判断选择创建或直接findViewById,这就是在复用,只是比较耗性能!
ViewHolder的最佳实践
ViewType种类过多,尽量减少在onBindViewHolder(VireHolder holder, int position)里if else的冗杂判断,可将具体的数据绑定逻辑放到 ViewHolder内部。
缓存机制
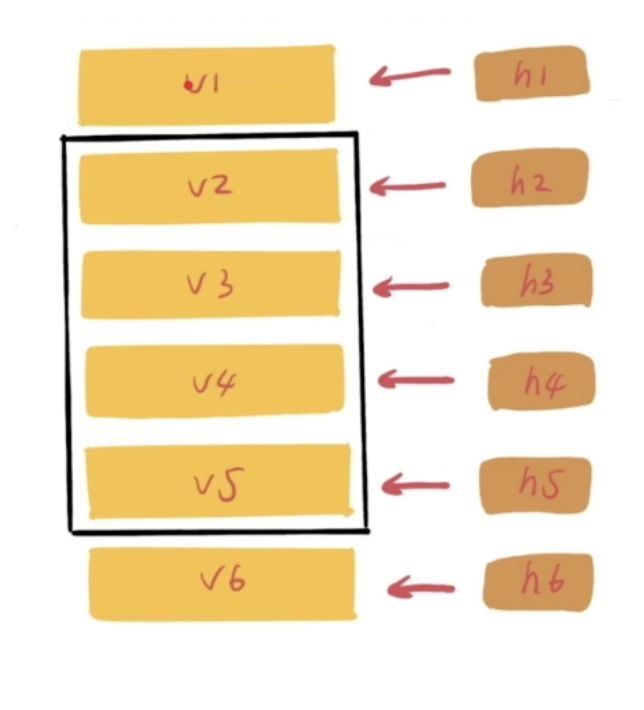
1. ListView
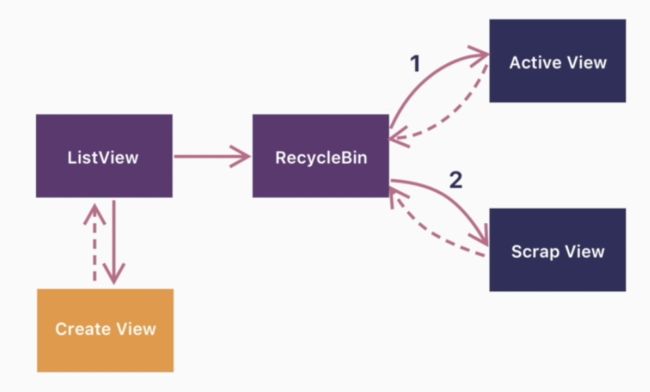
如下图,RecyclerBin是ListView的回收站,专门负责管理ListView的缓存。RecyclerBin中有两层缓存:
- Active View:活跃View,正在屏幕中展示的View;
- Scrap View:废弃View,已经从屏幕移出去的item view,已经被回收掉了;
结合下图理解,当ListView需要创建一个view,也就是Adapter.getView时,首先从两层缓存中找,如果没有就创建一个view返回。
结合下图再来加深一下ListView的二层缓存理解:屏幕内外的View,和复用、缓存有什么关系?
Android系统的屏幕刷新机制16.6ms/1帧,每次刷新的时候会把最新的View渲染到屏幕上,也就是说在下一帧画面时,ListView会将**屏幕上所有的item**的数据清空,再根据最新的业务逻辑状态结合ListView内部机制(及layout、draw等等),重新绘制到屏幕上。
那么,被清空的这些item呢?例如滑动列表,数据没变,只是item的位置改变!因此这些item view是可以拿回来继续复用的,并不需要重新bind数据,即ListView直接跳过adapter.getView步骤的。正因为ListView内部已经处理过了,也无需开发者在getView中处理这些逻辑。
诶嘿,上述讲解还有一个重点:凡是跳过getView 方法的item不需要重新bind数据,那么执行过getView 方法的item view是肯定要重新bind数据的!
再来看Srap View,上滑动列表后,右再回到原来位置,这时ListView会在Scrap View,即被废弃的View中找到item view,既然是脏数据,找到后就需要重新bind数据。(注:如果脏数据中没有找到,就重新创建)
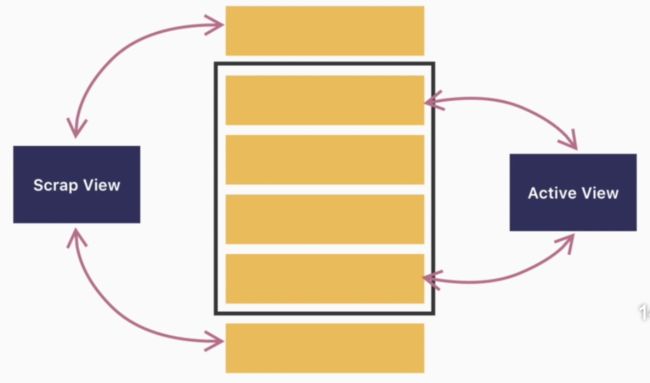
留一个问题:Srap View内部使用的什么数据结构?
2. RecyclerView
如下图,这对比起来相较于ListView似乎复杂了些,但其实二者还是有些许相同之处,只是RV的缓存机制更加完善高效。
RecyclerView内部是由Recycler来管理缓存机制,注意:RecyclerView和ListView缓存本质上很重要的一点差异,前者缓存的是ViewHolder、而后者缓存的是View对象!但是但是,在文章一开始我们就分析过ViewHolder和item view的关系,一一对应,相互绑定的,其实差别也不大。
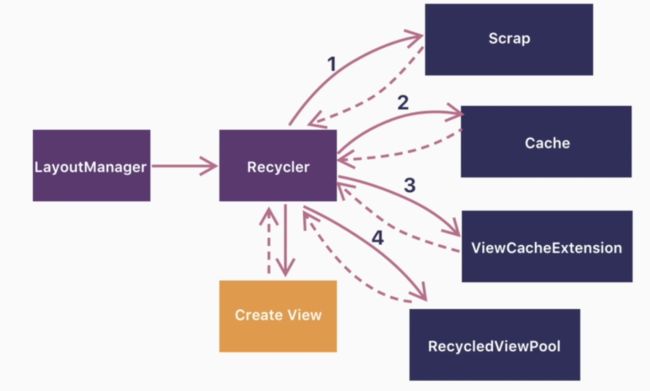
RV接收到创建一个item view的需求时,首先从四层缓存中找,没找到才会去创建。来看这四层缓存:
- Scrap: 虽然名字叫“废弃”,但实则对标ListView中的Active View,即屏幕内的item view;
- Cache: 同上,对标于ListView中的Scrap View,即屏幕外的item view;
- ViewCacheExtension:(用户自定义过,才会走这层,否则直接跳过)
- RecycledViewPool: Pool池子,看到这个定义不由得想起线程池,其实也是一个类似概念;
从下图屏幕的角度,来理解这四层缓存:

首先来看第一层 Scrap,即屏幕内的item view,回顾ListView讲解的缓存内容,这部分是可以直接被复用的。注意:这类型“可以直接被复用的view” 是通过数据集的position来查找对应的viewholder。例如在滑动的过程中需要position为5的view(注意:position为5的item view一直在屏幕内的!只是每次刷新数据重新渲染),这时可以直接去Scrap干净数据中找,直接拿来复用,跳过bind数据步骤。
再来看第二层 Cache,即刚移出屏幕的item view,直接被回收到Cache,再拿来复用时就需要重新bind数据。例如往上滑动列表,position为2、3的item view被移出屏幕(被回收到Cache),再往下滑,position为2、3的item view在Cache中找到拿回来复用。同Scrap一样,也是通过position找到viewholder,直接拿回来复用,无需重新bind数据,即跳过onBindViewHolder方法。
第三层 ViewCacheExtension,说实话使用场景很少,估计很多人闻所未闻,其API设计更是有些奇怪,要知道RecyclerView的缓存机制目标是ViewHolder,读取ViewHolder中有效信息(可从它获取item view)。但是ViewCacheExtension源码自行实现返回的对象却是item view,那ViewHolder?ViewCacheExtension内部还会去检查item view 是否绑定ViewHolder,没有绑定则直接crash。
第四层 RecycledViewPool ,内部保存的都是被废弃的脏(dirty)数据,通过viewType 找到对应数据后需要重新绑定数据(注意这一层缓存是通过viewType查找),即虽然缓存读取跳过了onCreateViewHolder步骤,但是需要重新绑定数据onBindViewHolder。
底层的数据结构?
拓展:ViewCacheExtension使用?
- 广告卡片
- 每一页一共有4哥广告
- 这些广告短期内不会发生变化
- 每次滑入一个广告卡片,一般情况下都需要重新绑定
- Cache只关心position,不关心view type
- RecycledViewPool 只关心view type,都需要重新绑定
- 在ViewCacheExtension 里保持4个广告Card缓存
注意:列表中item/广告 的impression统计:
- ListView 通过
getView()统计,该方法被调用就相当于item view曝光; - RecyclerView 通过
onBindViewHolder()方法统计?数据有误!经过上述缓存讲解,在第二层Cache时,item重新曝光,在Cache中找到并复用item,此方法并不会被调用,因此数据会有些许不精准。- 可通过
onViewAttachedToWindow()统计;
- 可通过
RecyclerView 性能优化策略
1. 在onBindViewHolder里设置点击监听?
OnClickListener对象多次被创建,观察者模式
在onCreateViewHolder里设置点击监听,View、ViewHolder、View.OnClickListener三者一一对应!
2. LinerLayoutManager.setInitialPrefetchItemCount()
- 用户滑动到横向滑动的item RecyclerView的时候,由于需要创建更复杂的RV以及多个子View,可能会导致页面卡顿;
- 由于RenderThread的存在,RV会进行prefetch
LinerLayoutManager.setInitialPrefetchItemCount()横向列表初次显示时可见的item个数- 只有LinerLayoutManager才有这个API
- 只有嵌套在内部的RV才会生效,在外部的RV调用此方法是无效的
3. RecyclerView.setHasFixedSize()
//伪代码解释
void onContentsChanged() {
if(mHasFiedSize) {
layoutChildren();
} else {
requestLayout();
}
}
如果Adapter的数据变化(例如item增加、删除)不会导致RV的大小变化,那么可以为RV设置此属性;这样当RV内部的item变化时,可简化重走整个绘制过程。
4. 多个RecyclerView公用RecycledViewPool

重合的viewtype,即可走第四层缓存复用item
使用方法
RecyclerView.RecycledViewPool recycledViewPool =
new RecyclerView.RecycledViewPool();
rv1.setRecycledViewPool(recycledViewPool);
rv2.setRecycledViewPool(recycledViewPool);
rv3.setRecycledViewPool(recycledViewPool);
DiffUtil
1. 介绍
- DiffUtil is a utility class that can calculate the difference between two lists and output a list of update operations that converts the first list into the second one.
- 计算两个不同列表的差异;
- 输出一系列更新操作:第一个列表转换成第二个列表;
- 局部更新方法 notifyItemXXX() 不适用于所有情况。
notifyDataSetChange()会导致整个布局重新绘制,所有ViewHolder被重新绑定,而且会失去可能的动画效果。- DiffUtil 适用于整个页面需要刷新,但是有部分数据可能相同的情况。
内部算法 Myers Diff Algorith 是动态规划,不要求掌握其具体实现,给出的链接是对该算法的可视化讲解,感兴趣的朋友可以深入研究下:Myers Diff Algorithm - Code & Interactive Visualization

2.原理
那具体怎么运用DiffUtil到实际操作中,首先来介绍一个 重点抽象类DiffUtil.Callback,实现Callback里的方法告诉系统如何计算:
//DiffUtil.class
public abstract static class Callback {
public abstract int getOldListSize();
public abstract int getNewListSize();
public abstract boolean areItemsTheSame(int oldItemPosition, int newItemPosition);
public abstract boolean areContentsTheSame(int oldItemPosition, int newItemPosition);
@Nullable
public Object getChangePayload(int oldItemPosition, int newItemPosition) {
return null;
}
}
- getOldListSize() :返回旧数据集的 size。
- getNewListSize() :返回新数据集的 size。
- areItemsTheSame(int oldItemPosition, int newItemPosition) :比较两个位置的对象是否是同一个item。注意这里指的是逻辑(业务)上判断,而并非内存地址。
- 举个例子,比较两个人是否相同,可以通过身份证ID作为唯一标识。
- areContentsTheSame(int oldItemPosition, int newItemPosition) :比较两个 item 的数据内容是相同。注意该方法被调用的前提:只有当
areItemsTheSame()返回true时会调用。- 举个例子,还是两个人之间的比较,只有当这2个人的身份证ID都相同,也就是
areItemsTheSame()返回true时此方法才会被调用,这个时候再来做这2个人具体信息比较,例如姓名、性别、出身地等等。
- 举个例子,还是两个人之间的比较,只有当这2个人的身份证ID都相同,也就是
- getChangePayload(int oldItemPosition, int newItemPosition) : 【不是抽象方法】返回这个 item 更新相关的信息。注意该方法被调用的前提:当
areItemsTheSame()返回 true ,并且areContentsTheSame()返回 false 时被调用。- 在上个例子的基础上,这两个人身份证ID相同,比较信息内容时有不同点,则此方法会被调用,并且返回需要更新的信息,例如名字的纠正。
以上几个方法的调用前提、顺序通过下图总结归纳:

3.实践
上代码,实现一个简单的UserDiffCallback例子,来比较两个用户列表:
public class UserDiffCallback extends DiffUtil.Callback {
private List<User> oldList;
private List<User> newList;
public UserDiffCallback(List<User> oldList, List<User> newList) {
this.oldList = oldList;
this.newList = newList;
}
@Override
public int getOldListSize() {return oldList.size();}
@Override
public int getNewListSize() {return newList.size();}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
//唯一标识符比较
return oldList.get(oldItemPosition).id == newList.get(newItemPosition).id;
}
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
final User oldUser = oldList.get(oldItemPosition);
final User newUser = newList.get(oldItemPosition);
//内容比较
//优化:可以在User类中实现equals方法,根据Model自身特性实现比较“相等”逻辑判断
return oldUser.id == newUser.id &&
oldUser.name.equals(newUser.name) &&
oldUser.sex.equals(newUser.sex) &&
oldUser.address.equals(newUser.address);
}
}
上述UserDiffCallback类继承于DiffUtil.Callback抽象类,并实现了其中4个抽象方法,其中areItemsTheSame()、areContentsTheSame() 实现不同层度的item比较逻辑。此例子简单易懂,无需多余赘述,值得注意的是上述例子并未实现getChangePayload()方法。
如果没有实现此方法,那么就享受不到“增量更新”的便利,例如User类中可能只有名字name字段修改了,其余的数据都未变化,由于此方法没有被实现,因此整个item还是会被重新刷新。也就是“增量更新”和“全量更新”的区别。
如下代码,我们来实现getChangePayload()方法,其内部主要逻辑看似与内容比较方法areContentsTheSame()相似,但还有一点不同是:将两个对象的差异部分存储到Bundle中返回。
public class UserDiffCallback extends DiffUtil.Callback {
......
@Nullable
@Override
public Object getChangePayload(int oldItemPosition, int newItemPosition) {
final User oldUser = oldList.get(oldItemPosition);
final User newUser = newList.get(oldItemPosition);
final Bundle payload = new Bundle();
if(oldUser.id != newUser.id){
payload.putInt(User.KEY_ID, newUser.id);
}
if(oldUser.sex != newUser.sex){
payload.putString(User.KEY_SEX, newUser.sex);
}
if(oldUser.address != newUser.address){
payload.putString(User.KEY_ADDRESS, newUser.address);
}
if(payload.size() == 0){
return null;
}
return payload;
}
......
}
外界调用
实现了 DiffUtil.Callback 后,我们就可以在自定义Adapter中根据自身逻辑选择使用增量更新来update列表,封装方法如下:
public class ShowcaseAdapter extends RecyclerView.Adapter<ShowcaseAdapter.ViewHolder> {
private List<User> userList;
ShowcaseAdapter(List<User> userList){
this.userList = userList;
}
......
public void swapData(List<User> newList, boolean diff){
if(diff){
DiffUtil.Callback diffUtilCallback;
DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(
new UserDiffCallback(userList, newList), false);
userList = newList;
//增量更新
diffResult.dispatchUpdatesTo(this);
} else {
userList = newList;
//全量更新
notifyDataSetChanged();
}
}
}
看以上swapData(List 方法封装设计:
- 第一个参数newList,故名思义则是新列表;
- 第二个参数diff 指定是否使用**“增量更新”的方式更新数据,若不需要则直接将新数据替代旧数据列表,进行“全量更新”**;
那么,来看**“增量更新”**的具体操作,此时就使用到了之前封装的 “计算两个列表差异”的工具类UserDiffCallback:
- 调用官方API
DiffUtil.calculateDiff()方法,即计算需要进行更新操作的列表,而此方法返回的结果则是:旧列表转换成新列表需要更新的部分。- 第一个参数传入自定义工具类UserDiffCallback(待计算的2个列表);
- 第二个参数比较特殊,涉及到列表特征和算法内部计算:如果此RV的 新旧列表的约束条件、位置相同,则传入false,这样内部计算时会取消掉item移动的检测,这种检测会花费O(n^2)时间,n代表item移动、添加、删除的数量。
- 新列表还是赋值到旧列表;
- 获取到 DiffUtil 计算出的列表需要更新结果diffResult后,调用diffResult的
dispatchUpdatesTo()方法,即所谓的“增量更新”,将列表更换的差异分发给Adapter,使其根据接收到的差异数据做更新。(而并非“全量更新”中的所有item刷新)
总结
getChangePayload() 返回的差异数据 DiffResult,DiffResult 再分发给 notifyItemRangeChanged(position, count, payload) 方法,最终交给 Adapter 的 onBindViewHolder(… List< Object > payloads) 处理。
4. 异步计算Diff
DiffUtil 一般通过这四个方法通知 Adapter 来更新数据。
-
notifyItemChanged()
-
notifyItemMoved()
-
notifyItemRangeChanged()
-
notifyItemRangeInserted()
-
notifyItemRangeRemoved()
DiffUtil 的效率?
上述例子调用calculate 计算方法是在主线程
Android系统每次刷新频率是 1帧/16.6ms,若计算时间过长反而会导致掉帧现象,本想是RV的优化?却…
因此在列表数据比较大的时候,异步计算Diff。 说到异步,这事儿就好办了,以下三个方法推荐:
- 使用 Thread/Handler 将 DiffResult 发送到主线程;
- 使用 RxJava/courtinous 将 calculateDiff 操作放到后台线程;
- 使用Google 提供的 AsyncListDiffer(Executor) / ListAdapter
前两种方式不必多少,来看下第三种官方推荐,可查看:
- https://developer.android.com/reference/android/support/v7/recyclerview/extensions/AsyncListDiffer
- https://developer.android.com/reference/android/support/v7/recyclerview/extensions/ListAdapter