Flink集成Redis组件,使用异步IO能完全解决性能瓶颈问题?
基于上述的问题,我们先来对异步IO有个大致的认识,了解的同学可以选择跳过。
流计算系统中经常需要与外部系统(Redis、MySQL等)进行交互,我们通常的做法如向数据库发送用户a的查询请求,然后等待结果返回,在这之前,我们的程序无法发送用户b的查询请求。这是一种同步访问方式,如下图所示。

图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。也就是说,你可以连续地向数据库发送用户a、b、c等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。这也正是 Async I/O 的实现原理。
说到这里,其实大部分开发者可以想到,使用多线程缓解这个问题,但这存在一个很大的缺陷:编程模型会变得更加复杂,因为必须在算子中实现线程,必须与检查点进行协调,如果这样做的话,Flink的checkpoint机制其实是没有很好的运用的。
进入正题,当时接到的需求如下:
1.数据源:从 kafka 接入实时数据。
2.解析json,取到所需要的字段数据,其中有一个userName的字段,截取前七位,作为redis的key。
3.通过key去redis查询该条数据对应的省份和城市。
4.每五分钟作为一个时间窗口,keyby后reduce进行计算。
5.将结果保存至oracle数据库。
当然,我们这次讨论的重点是步骤 2和3,也就是Flink与Redis集成的部分,以下是我开发测试的一个心路历程,欢迎大家提取一些自己的见解。
- 第一步是 kafka 接入,process中未做任何处理,每秒数据量大概在 12000/s。

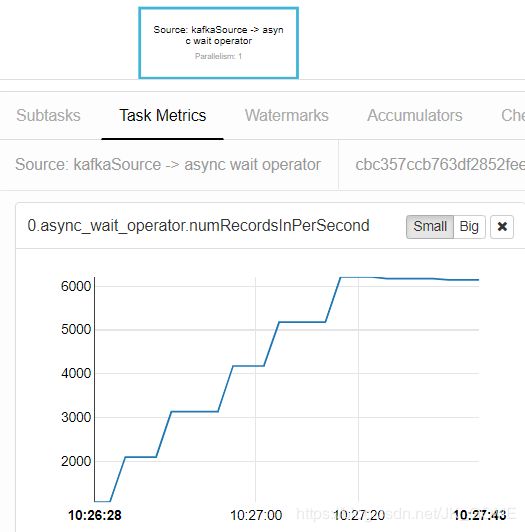
- 第二步测试读取 Redis ,获得省份城市,一个并发度每秒处理数据量大概在 140/s,产生严重的背压。所以,如果我们想处理 12000/s的数据量,大概需要设置process算子的并行度为 85,也就是使用了 85 个slot,这对于集群来说是很不合理的。


- 第三步测试异步IO读取redis,一个并发度处理能力大概在 6000/s,确实相对于同步有了很大的提升。
public class TestSlot {
private static Logger LOGGER = LoggerFactory.getLogger(TestSlot.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource inputStream = KafkaReader.getKafkaSource(env, "dfsawf",
"CSLog");
AsyncDataStream.unorderedWait(inputStream,
new MyRichAsyFunction(), 2, TimeUnit.SECONDS, 40).setParallelism(1);
env.execute("JFYINTERNAL1");
}
} public class MyRichAsyFunction extends RichAsyncFunction> {
private static final Logger LOGGER = LoggerFactory.getLogger(MyRichAsyFunction.class);
private transient JedisCluster jedisCluster;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
jedisCluster = JedisClusterUtils.getJedisClusterConn();
}
@Override
public void asyncInvoke(String input, ResultFuture> resultFuture) throws Exception {
JSONObject rootObject = JSONObject.parseObject(input);
CompletableFuture.supplyAsync(new Supplier() {
@Override
public String get() {
Object userName = rootObject.getOrDefault("userName", "");
Object provinceName = rootObject.getOrDefault("province", "");
if (("".equals(provinceName) || provinceName == null) && !"".equals(userName)) {
String phoneNum = userName.toString().substring(0, 7);
String provinceCode = jedisCluster.hget("up_sf##" + phoneNum, "provinceCode");
}
return "";
}
}).thenAccept((String result) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(rootObject, result)));
});
}
@Override
public void timeout(String input, ResultFuture> resultFuture) throws Exception {
LOGGER.error("timeout !");
}
@Override
public void close() throws Exception {
super.close();
if (jedisCluster != null) {
jedisCluster.close();
}
}
} - 第四步,因为一个并发度,异步IO可以处理6000/s,所以,如果我们想处理 12000/s的数据量,大概需要设置process算子的并行度为 3,就能消费得过来了,是这样吗?接下来,我们设置并发度为3,效果如下,并没有像我们预期那样,每个slot的消费能力都是 6000/s。
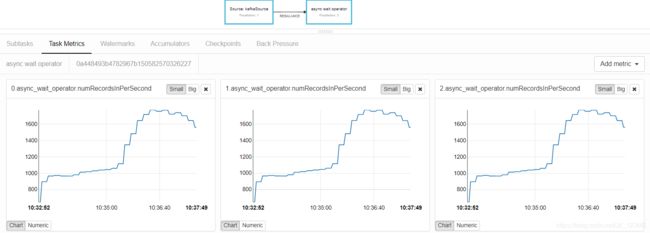
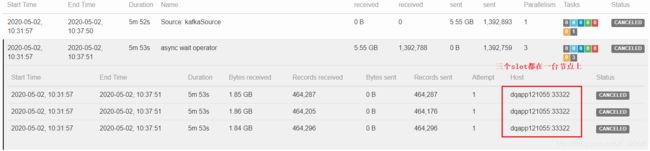
基于上述的一些测试,可以大至定位到问题所在,在使用异步IO的时候,一个slot的处理能力是 6000/s,但增大slot对处理能力没有影响。只有当slot在不同机器上时,消费能力才有提升。起初一直是纠结在 redis的连接数,和异步IO的capacity上,但经过测试不是这些原因。
同步请求 redis 时,处理能力大概 140/s, 6000/140 = 40,也就是我们异步的能力是 40,这是因为我们 TaskManager 节点的 CPU 核数是 40,导致我们并发线程的能力瓶颈就是 40 个。

综上,我们异步请求 redis 的瓶颈其实是在我们开辟线程的能力上,是硬件导致的问题。这也就能解释,为什么 slot 在不同机器上时,处理能力能提升一些,而在一个机器上,无论怎样加大slot,都没有作用。