java实现在线预览的功能(一)word转html
java将word文档转为html实现在线预览
该功能是用poi实现的转换,所以需要下载相对应的jar包
jar包链接:https://pan.baidu.com/s/1WrWEzX9BO5iX4r-rMna-4g 提取码:x7iq
如果需要下载更高版本: https://mvnrepository.com/ 此为mvn仓库地址
大概聊聊为什么做这个功能,这个功能是在做项目时,需要将上传的附件进行在线预览,也尝试了一些方法,但是都没有解决,也看过一些将office文件转为pdf格式的,但是需要下载openOffice软件,或者pdf.js插件等等 所以就换了一种方式,word常用两种格式,一种doc,一种docx。
注意: 我做的项目因为在数据库存的是相对路径,转换后的html也放在这个路径之下,所以这个方法有四个参数,如果你存的是绝对路径,name只需要两个参数,后面的last和typeLength不需要
1、是doc格式转为html
补充: 导包的路径
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.List;
import java.util.UUID;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.apache.commons.io.FileUtils;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.converter.PicturesManager;
import org.apache.poi.hwpf.converter.WordToHtmlConverter;
import org.apache.poi.hwpf.usermodel.Picture;
import org.apache.poi.hwpf.usermodel.PictureType;
import org.apache.poi.xwpf.converter.core.BasicURIResolver;
import org.apache.poi.xwpf.converter.core.FileImageExtractor;
import org.apache.poi.xwpf.converter.xhtml.XHTMLConverter;
import org.apache.poi.xwpf.converter.xhtml.XHTMLOptions;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.w3c.dom.Document;
直接上代码,需要创建一个doc文档,然后写上word文档doc格式,这里就不给大家截图创建word文档了
/**
* word文档 doc格式转为html
* @param rootPath
* 项目的路径
* @param fileUrl
* 数据库存放文件的相对路径 (例:/file/aa.doc)
* @param last
* 获取fileUrl的长度
* @param typeLength
* 文件类型的长度
* @return
* 返回html的路径
*/
public static String docToHtml(String rootPath,String fileUrl,int last,int typeLength) {
InputStream input = null;
String htmlUrl = "";
// 下面有很多try catch 如果感觉麻烦就直接用一个 ,catch里面变为Exception即可
try {
input = new FileInputStream(rootPath + fileUrl);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
}
// HWPFDocument是poi中用来读取doc文件的
HWPFDocument wordDocument = null;
try {
wordDocument = new HWPFDocument(input);
} catch (IOException e1) {
e1.printStackTrace();
}
// 官网地址:http://poi.apache.org/apidocs/dev/org/apache/poi/hwpf/converter/WordToHtmlConverter.html
// 用来将word转为html
WordToHtmlConverter wordToHtmlConverter = null;
try {
wordToHtmlConverter = new WordToHtmlConverter(DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument());
} catch (ParserConfigurationException e1) {
e1.printStackTrace();
}
// setPicturesManager用来处理图片
wordToHtmlConverter.setPicturesManager(new PicturesManager() {
public String savePicture(byte[] content, PictureType pictureType,
String suggestedName, float widthInches, float heightInches) {
return suggestedName;
}
});
wordToHtmlConverter.processDocument(wordDocument);
List pics = wordDocument.getPicturesTable().getAllPictures();
if (pics != null) {
for (int i = 0; i < pics.size(); i++) {
Picture pic = (Picture) pics.get(i);
try {
pic.writeImageContent(new FileOutputStream(rootPath
+ pic.suggestFullFileName()));
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 该Document接口表示整个HTML或XML文档。从概念上讲,它是文档树的根,并提供对文档数据的主要访问。
Document htmlDocument = wordToHtmlConverter.getDocument();
// 字节数组输出流
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
// 以文档对象模型(DOM)树的形式充当转换源树的持有者。
DOMSource domSource = new DOMSource(htmlDocument);
// 充当转换结果的持有者,可以是XML,纯文本,HTML或其他形式的标记。
StreamResult streamResult = new StreamResult(outStream);
TransformerFactory tf = TransformerFactory.newInstance();
// 处理来自各种源的XML,并将转换输出写入各种接收器。
Transformer serializer = null;
try {
serializer = tf.newTransformer();
} catch (TransformerConfigurationException e1) {
e1.printStackTrace();
}
// 设置对转换有效的输出属性
serializer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
serializer.setOutputProperty(OutputKeys.INDENT, "yes");
serializer.setOutputProperty(OutputKeys.METHOD, "html");
try {
serializer.transform(domSource, streamResult);
} catch (TransformerException e) {
e.printStackTrace();
}
try {
outStream.close();
} catch (IOException e1) {
e1.printStackTrace();
}
String content = new String(outStream.toByteArray());
// 对url的解释 数据库存的地址是相对路径,打算将html也放再这个路径里面,所以需要将文件的名字和后缀去掉,-32是文件通过uuid动态创建的
String url = fileUrl.substring(0, last - typeLength - 32);
// 设置文件名称
String s = UUID.randomUUID().toString();
// 去掉-
String aString = s.substring(0,8)+s.substring(9,13)+s.substring(14,18)+s.substring(19,23)+s.substring(24);
// 设置html文件的名称
String htmlName = aString + ".html";
// 打算存入数据库的相对路径,该路径返回前端页面,直接在前面拼接项目路径即可
htmlUrl = url + htmlName;
String Path = (rootPath + url).replace("\\", "/");
try {
/**
* FileUtils.writeStringToFile(file, data, encoding),把字符串写进对应的文件中
* file是新建的文件 data是写入的内容 encoding是编码格式
*/
FileUtils.writeStringToFile(new File(Path, htmlName),content, "utf-8");
} catch (IOException e) {
e.printStackTrace();
}
return htmlUrl;
}
在最后一步用到了FileUtils.writeStringToFile()这个方法,如果需要查看更多FileUtils的方法,可以在https://blog.csdn.net/li575098618/article/details/49785277 这里进行查看,这位大佬总结的很详细。
然后我们写一个main测试一下,我们的文件名称是通过uuid动态创建的
public static void main(String[] args) {
// 项目中应该这样获取 String rootPath = request.getSession().getServletContext().getRealPath("");
String rootPath = "E:/test";
String fileUrl = "/doc/2d0f29b8628c4cde8048ba09be6f7ffd.doc";
// 截取文件后缀
int begin = fileUrl.lastIndexOf(".");
int last = fileUrl.length();
String type = fileUrl.substring(begin, last);
int typeLength = type.length();
String htmlUrl = docToHtml(rootPath, fileUrl, last, typeLength);
System.out.println(htmlUrl); //输出结果为: /doc/5198c3b9f6e04458901bacbf98bf4776.html
}
看文件夹下:
打开html文件查看结果
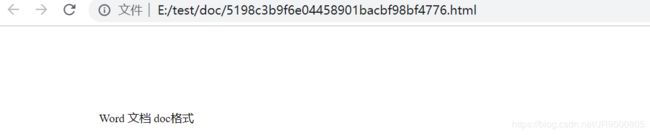
web工程只需要将返回的文件路径加上项目的路径即可
项目实测结果:

2、docx格式转为html
因为很多和doc中的解释差不多,就不啰嗦了,直接上代码
/**
* word文档 docx格式转为html
* @param rootPath
* 项目的路径
* @param fileUrl
* 数据库存放文件的相对路径 (例:/file/aa.doc)
* @param last
* 获取fileUrl的长度
* @param typeLength
* 文件类型的长度
* @return
* 返回html的路径
*/
public static String docxToHtml(String rootPath,String fileUrl,int last, int typeLength) throws IOException {
String url = fileUrl.substring(0, last - typeLength - 32);
String htmlPath = (rootPath + url).replace("\\", "/");
String s = UUID.randomUUID().toString();
// 去掉-
String aString = s.substring(0,8)+s.substring(9,13)+s.substring(14,18)+s.substring(19,23)+s.substring(24);
String htmlName = aString + ".html";
String imagePath = htmlPath + "image";
String htmlUrl = url + htmlName;
// 判断html文件是否存在
File htmlFile = new File(htmlPath + htmlName);
// 1) 加载word文档生成 XWPFDocument对象
InputStream input = new FileInputStream(rootPath + fileUrl);
XWPFDocument document = new XWPFDocument(input);
// 2) 解析 XHTML配置 (这里设置URIResolver来设置图片存放的目录)
File imgFolder = new File(imagePath);
XHTMLOptions options = XHTMLOptions.create();
options.setExtractor(new FileImageExtractor(imgFolder));
// html中图片的路径 相对路径
options.URIResolver(new BasicURIResolver("image"));
options.setIgnoreStylesIfUnused(false);
options.setFragment(true);
// 3) 将 XWPFDocument转换成XHTML
// 生成html文件上级文件夹
File folder = new File(htmlPath);
if (!folder.exists()) {
folder.mkdirs();
}
OutputStream out = new FileOutputStream(htmlFile);
XHTMLConverter.getInstance().convert(document, out, options);
return htmlUrl;
}
我们在写一个main测试一下,和doc的差不多
public static void main(String[] args) {
// 项目中应该这样获取 String rootPath = request.getSession().getServletContext().getRealPath("");
String rootPath = "E:/test";
String fileUrl = "/doc/3f9d29b8628c4cde8048ba09be6f666j.docx";
// 截取文件后缀
int begin = fileUrl.lastIndexOf(".");
int last = fileUrl.length();
String type = fileUrl.substring(begin, last);
int typeLength = type.length();
//String htmlUrl = docToHtml(rootPath, fileUrl, last, typeLength);
try {
String htmlUrl = docxToHtml(rootPath, fileUrl, last, typeLength);
System.out.println(htmlUrl); // 控制台输出 /doc/5ee643de6ba64fa589ec34cbddda3097.html
} catch (IOException e) {
e.printStackTrace();
}
}
看本地产生的文件

点击html查看是否转换完成
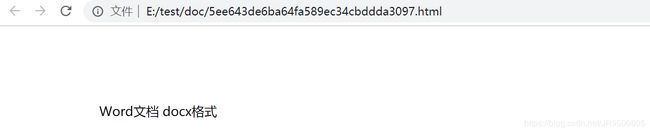
web工程只需要将返回的文件路径加上项目的路径即可
项目实测结果:

这篇文章也就到此结束了,感谢你们能看完我写的文章