Hive实战
实战一:创建表
数据集:movies.csv
用,隔开,三列数据分别表示movie_id,movie_name,genres(电影id,电影名字,电影风格)

数据集:rating.csv
用,隔开,四列数据分别表示user_id,movie_id,rating,timestamp
1.在hive根目录下命令行输入hive
2.shell创建表
HDFS创建目录:/hive/rating_table 和 /hive/movie_table
将数据集movie.csv上传到/hive/movie_table
将数据集rating.csv上传到/hive/rating_table
在终端输入以下sql语句:
create external table movie_table
(
movieId STRING,
title STRING,
genres STRING
)
row format delimited fields terminated by ','
stored as textfile
location '/hive/movie_table';然后在另一个终端执行:
hive -f create_rating_table;
3.查询是否已经见表
hive> show tables;4.查看表的描述
hive> desc movie_table;
OK
movieid string
title string
genres string
Time taken: 0.134 seconds, Fetched: 3 row(s)5.查询表的内容
hive> select * from movie_table limit 10;
OK
movieId title genres
1 Toy Story (1995) Adventure|Animation|Children|Comedy|Fantasy
2 Jumanji (1995) Adventure|Children|Fantasy
3 Grumpier Old Men (1995) Comedy|Romance
4 Waiting to Exhale (1995) Comedy|Drama|Romance
5 Father of the Bride Part II (1995) Comedy
6 Heat (1995) Action|Crime|Thriller
7 Sabrina (1995) Comedy|Romance
8 Tom and Huck (1995) Adventure|Children
9 Sudden Death (1995) Action
Time taken: 0.145 seconds, Fetched: 10 row(s)
实战二:两张表的join
设置b为小表
select /* +MAPJOIN(b)*/ b.userid, a.title, b.rating
from movie_table a
join rating_table b
where a.movieid == b.movieid
limit 10;![]()
实战四:两表join的结果存到一个新表中
create table behavior_table as
select /* +MAPJOIN(b)*/ b.userid, a.title, b.rating
from movie_table a
join rating_table b
on a.movieid == b.movieid
limit 10;对应表的数据位置:/user/hive/warehouse/behavior_table
默认分隔符:^A:hadoop fs -text /user/hive/warehouse/behavior_table/000000_0| awk -F'^A' '{print $1}'
behavior_table为内表,删除之后数据也随之丢失
hive> drop table behavior_table;检验:hadoop fs -ls /user/hive/warehouse 查看此目录下为空
实战五:数据导出(本地、HDFS)
本地:1.txt文件夹是程序创建,无需手动创建
hive> insert overwrite local directory '/usr/local/src/test2/09.Hive/1.txt'
hive> select userid, title from behavior_table;查看数据:cat /usr/local/src/test2/09.Hive/1.txt/00000-0
HDFS:/behavior_table文件夹是程序创建,无需手动创建
hive> insert overwrite directory '/behavior_table'
hive> select userid, title from behavior_table;查看数据:hadoop fs -text /behavior_table/000000-0 | head
事件六:时间戳转换
数据集:ratings.csv、convert_ts.py
python文件
import sys
import time
file_name = sys.argv[1]
with open(file_name, 'r') as fd:
for line in fd:
ss = line.strip().split(',')
if len(ss) == 4:
user_id = ss[0].strip()
movie_id = ss[1].strip()
rating = ss[2].strip()
timestamp = ss[3].strip()
time_local = time.localtime(long(timestamp))
dt = time.strftime("%Y-%m", time_local)
print '\t'.join([user_id, movie_id, rating, dt])命令行输入:
python convert_ts.py ratings.csv > ratings.csv.format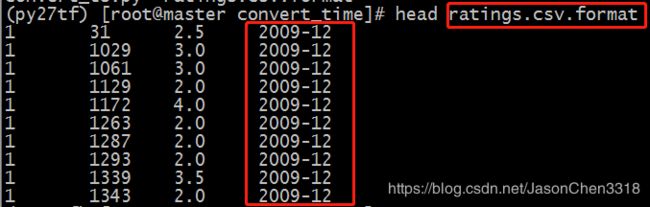
查看不重复的项有多少个
cat ratings.csv.format | awk -F\\t "{print $NF}" | sort | uniq | wc -l
实践七:创建partition表
create_rating_table_p.sql
create external table rating_table_p
(userId STRING,
movieId STRING,
rating STRING
)
partitioned by (dt STRING)
row format delimited fields terminated by '\t'
lines terminated by '\n';hive -f create_rating_table_p.sql查看:
hive> desc rating_table_p;
OK
userid string
movieid string
rating string
dt string
# Partition Information
# col_name data_type comment
dt string
Time taken: 0.099 seconds, Fetched: 9 row(s)把2008年8月的数据集中到一个文件中
cat ratings.csv.format | grep "2008-08" > 2008-08.data
cat ratings.csv.format | grep "2008-03" > 2008-03.data往表中插数据
hive> load data local inpath '/usr/test2/09.Hive/hive_test_7/01/2008-08.data'
hive> overwrite into table rating_table_p partition(dt='2008-08');同样再插入2008-03的数据
查看分区:
hive> show partitions rating_table_p;查看数据:
hive> select * from rating_table_p where dt = '2008-08' limit 10;
OK
68 260 3.0 2008-08
68 318 4.0 2008-08
68 367 3.0 2008-08
68 457 4.0 2008-08
68 480 4.0 2008-08
68 539 3.5 2008-08
68 586 3.5 2008-08
68 914 4.0 2008-08
68 1035 4.0 2008-08
68 1951 4.0 2008-08查看HDFS目录:
[root@master convert_time]# hadoop fs -ls /user/hive/warehouse/rating_table_p
Found 2 items
drwxr-xr-x - root supergroup 0 2019-05-26 13:01 /user/hive/warehouse/rating_table_p/dt=2008-03
drwxr-xr-x - root supergroup 0 2019-05-26 13:00 /user/hive/warehouse/rating_table_p/dt=2008-08一个分区对应着HDFS上的一个文件夹