自己写的cs231n的作业,希望给点意见,支出错误和不足.谢谢
[TOC]
features.ipynb内容:
Image features exercise
Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the assignments page on the course website.
We have seen that we can achieve reasonable performance on an image classification task by training a linear classifier on the pixels of the input image. In this exercise we will show that we can improve our classification performance by training linear classifiers not on raw pixels but on features that are computed from the raw pixels.
All of your work for this exercise will be done in this notebook.
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# for auto-reloading extenrnal modules
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
Load data
Similar to previous exercises, we will load CIFAR-10 data from disk.
from cs231n.features import color_histogram_hsv, hog_feature
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000):
# Load the raw CIFAR-10 data
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# Subsample the data
mask = range(num_training, num_training + num_validation)
X_val = X_train[mask]
y_val = y_train[mask]
mask = range(num_training)
X_train = X_train[mask]
y_train = y_train[mask]
mask = range(num_test)
X_test = X_test[mask]
y_test = y_test[mask]
return X_train, y_train, X_val, y_val, X_test, y_test
X_train, y_train, X_val, y_val, X_test, y_test = get_CIFAR10_data()
Extract Features
For each image we will compute a Histogram of Oriented
Gradients (HOG) as well as a color histogram using the hue channel in HSV
color space. We form our final feature vector for each image by concatenating
the HOG and color histogram feature vectors.
Roughly speaking, HOG should capture the texture of the image while ignoring
color information, and the color histogram represents the color of the input
image while ignoring texture. As a result, we expect that using both together
ought to work better than using either alone. Verifying this assumption would
be a good thing to try for the bonus section.
The hog_feature and color_histogram_hsv functions both operate on a single
image and return a feature vector for that image. The extract_features
function takes a set of images and a list of feature functions and evaluates
each feature function on each image, storing the results in a matrix where
each column is the concatenation of all feature vectors for a single image.
from cs231n.features import *
#num_color_bins = 40 # Number of bins in the color histogram
num_color_bins = 50
feature_fns = [hog_feature, lambda img: color_histogram_hsv(img, nbin=num_color_bins)]
X_train_feats = extract_features(X_train, feature_fns, verbose=True)
X_val_feats = extract_features(X_val, feature_fns)
X_test_feats = extract_features(X_test, feature_fns)
# Preprocessing: Subtract the mean feature
mean_feat = np.mean(X_train_feats, axis=0, keepdims=True)
X_train_feats -= mean_feat
X_val_feats -= mean_feat
X_test_feats -= mean_feat
# Preprocessing: Divide by standard deviation. This ensures that each feature
# has roughly the same scale.
std_feat = np.std(X_train_feats, axis=0, keepdims=True)
X_train_feats /= std_feat
X_val_feats /= std_feat
X_test_feats /= std_feat
# Preprocessing: Add a bias dimension
X_train_feats = np.hstack([X_train_feats, np.ones((X_train_feats.shape[0], 1))])
X_val_feats = np.hstack([X_val_feats, np.ones((X_val_feats.shape[0], 1))])
X_test_feats = np.hstack([X_test_feats, np.ones((X_test_feats.shape[0], 1))])
Done extracting features for 1000 / 49000 images
Done extracting features for 2000 / 49000 images
Done extracting features for 3000 / 49000 images
.
.
.
Done extracting features for 46000 / 49000 images
Done extracting features for 47000 / 49000 images
Done extracting features for 48000 / 49000 images
Train SVM on features
Using the multiclass SVM code developed earlier in the assignment, train SVMs on top of the features extracted above; this should achieve better results than training SVMs directly on top of raw pixels.
# Use the validation set to tune the learning rate and regularization strength
from cs231n.classifiers.linear_classifier import LinearSVM
#learning_rates = [1e-9, 1e-8, 1e-7]
#regularization_strengths = [1e4,1e5, 1e6, 1e7]
regularization_strengths = [5e3,1e4,5e5, 5e6, 1e7]
learning_rates = [5e-9, 3e-8, 1e-7, 5e-7]
results = {}
best_val = -1
best_svm = None
pass
################################################################################
# TODO: #
# Use the validation set to set the learning rate and regularization strength. #
# This should be identical to the validation that you did for the SVM; save #
# the best trained classifer in best_svm. You might also want to play #
# with different numbers of bins in the color histogram. If you are careful #
# you should be able to get accuracy of near 0.44 on the validation set. #
################################################################################
for lr in learning_rates:
for reg_str in regularization_strengths:
svm = LinearSVM()
loss_hist = svm.train(X_train_feats, y_train, learning_rate=lr, reg=reg_str,
num_iters=1500, verbose=False)
y_train_pred = svm.predict(X_train_feats)
accuracy_train = np.mean(y_train == y_train_pred)
y_val_pred = svm.predict(X_val_feats)
accuracy_val = np.mean(y_val == y_val_pred)
results[(lr, reg_str)] = (accuracy_train, accuracy_val)
if accuracy_val > best_val:
print "lr:",lr
print "reg:", reg_str
best_val = accuracy_val
best_svm = svm
################################################################################
# END OF YOUR CODE #
################################################################################
# Print out results.
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print 'lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_accuracy, val_accuracy)
print 'best validation accuracy achieved during cross-validation: %f' % best_val
lr: 5e-09
reg: 5000.0
lr: 5e-09
reg: 10000.0
lr: 5e-09
reg: 5000000.0
lr: 1e-07
reg: 500000.0
cs231n/classifiers/linear_svm.py:85: RuntimeWarning: overflow encountered in double_scalars
reg_loss = 0.5 * reg * np.sum(W * W)
cs231n/classifiers/linear_svm.py:85: RuntimeWarning: overflow encountered in multiply
reg_loss = 0.5 * reg * np.sum(W * W)
cs231n/classifiers/linear_svm.py:130: RuntimeWarning: overflow encountered in multiply
dW += reg * W
cs231n/classifiers/linear_svm.py:83: RuntimeWarning: invalid value encountered in less
margin[margin<0] = 0 # np.where(margin>0, margin, 0)
cs231n/classifiers/linear_svm.py:124: RuntimeWarning: invalid value encountered in greater
mask_margin[margin>0] = 1
cs231n/classifiers/linear_classifier.py:71: RuntimeWarning: invalid value encountered in subtract
self.W = self.W - learning_rate * grad
lr 5.000000e-09 reg 5.000000e+03 train accuracy: 0.114796 val accuracy: 0.117000
lr 5.000000e-09 reg 1.000000e+04 train accuracy: 0.126265 val accuracy: 0.127000
lr 5.000000e-09 reg 5.000000e+05 train accuracy: 0.126959 val accuracy: 0.120000
lr 5.000000e-09 reg 5.000000e+06 train accuracy: 0.419857 val accuracy: 0.427000
lr 5.000000e-09 reg 1.000000e+07 train accuracy: 0.416857 val accuracy: 0.426000
lr 3.000000e-08 reg 5.000000e+03 train accuracy: 0.081469 val accuracy: 0.076000
lr 3.000000e-08 reg 1.000000e+04 train accuracy: 0.092224 val accuracy: 0.093000
lr 3.000000e-08 reg 5.000000e+05 train accuracy: 0.421184 val accuracy: 0.425000
lr 3.000000e-08 reg 5.000000e+06 train accuracy: 0.412673 val accuracy: 0.399000
lr 3.000000e-08 reg 1.000000e+07 train accuracy: 0.389306 val accuracy: 0.385000
lr 1.000000e-07 reg 5.000000e+03 train accuracy: 0.103980 val accuracy: 0.089000
lr 1.000000e-07 reg 1.000000e+04 train accuracy: 0.128490 val accuracy: 0.107000
lr 1.000000e-07 reg 5.000000e+05 train accuracy: 0.425878 val accuracy: 0.436000
lr 1.000000e-07 reg 5.000000e+06 train accuracy: 0.365449 val accuracy: 0.378000
lr 1.000000e-07 reg 1.000000e+07 train accuracy: 0.361735 val accuracy: 0.376000
lr 5.000000e-07 reg 5.000000e+03 train accuracy: 0.409694 val accuracy: 0.426000
lr 5.000000e-07 reg 1.000000e+04 train accuracy: 0.421327 val accuracy: 0.421000
lr 5.000000e-07 reg 5.000000e+05 train accuracy: 0.403143 val accuracy: 0.407000
lr 5.000000e-07 reg 5.000000e+06 train accuracy: 0.105918 val accuracy: 0.096000
lr 5.000000e-07 reg 1.000000e+07 train accuracy: 0.100265 val accuracy: 0.087000
best validation accuracy achieved during cross-validation: 0.436000
# Evaluate your trained SVM on the test set
y_test_pred = best_svm.predict(X_test_feats)
test_accuracy = np.mean(y_test == y_test_pred)
print test_accuracy
0.421
# An important way to gain intuition about how an algorithm works is to
# visualize the mistakes that it makes. In this visualization, we show examples
# of images that are misclassified by our current system. The first column
# shows images that our system labeled as "plane" but whose true label is
# something other than "plane".
examples_per_class = 8
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for cls, cls_name in enumerate(classes):
idxs = np.where((y_test != cls) & (y_test_pred == cls))[0]
idxs = np.random.choice(idxs, examples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt.subplot(examples_per_class, len(classes), i * len(classes) + cls + 1)
plt.imshow(X_test[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls_name)
plt.show()

Inline question 1:
Describe the misclassification results that you see. Do they make sense?
Neural Network on image features
Earlier in this assigment we saw that training a two-layer neural network on raw pixels achieved better classification performance than linear classifiers on raw pixels. In this notebook we have seen that linear classifiers on image features outperform linear classifiers on raw pixels.
For completeness, we should also try training a neural network on image features. This approach should outperform all previous approaches: you should easily be able to achieve over 55% classification accuracy on the test set; our best model achieves about 60% classification accuracy.
print X_train_feats.shape
(49000, 195)
from cs231n.classifiers.neural_net import TwoLayerNet
input_dim = X_train_feats.shape[1]
hidden_dim = 500
num_classes = 10
#net = TwoLayerNet(input_dim, hidden_dim, num_classes)
best_net = None
best_stats = None
################################################################################
# TODO: Train a two-layer neural network on image features. You may want to #
# cross-validate various parameters as in previous sections. Store your best #
# model in the best_net variable. #
################################################################################
best_acc = -1
input_size = 32 * 32 * 3
learning_rate_choice = [1.8,1.7, 1.6, 1.5]
reg_choice = [0.01, 0.011]
num_iters_choice = [800]
for learning_rate_curr in learning_rate_choice:
for reg_cur in reg_choice:
for num_iters_curr in num_iters_choice:
print
print "current training learning_rate:",learning_rate_curr
print "current training reg:",reg_cur
net = TwoLayerNet(input_dim, hidden_dim, num_classes)
stats = net.train(X_train_feats, y_train, X_val_feats, y_val,
num_iters=num_iters_curr, batch_size=1500,
learning_rate=learning_rate_curr, learning_rate_decay=0.95,
reg=reg_cur, verbose=True)
val_acc = (net.predict(X_val_feats) == y_val).mean()
print "current val_acc:",val_acc
if val_acc>best_acc:
best_acc = val_acc
best_net = net
best_stats = stats
print
print "best_acc:",best_acc
print "best learning_rate:",best_net.hyper_params['learning_rate']
print "best reg:",best_net.hyper_params['reg']
print
################################################################################
# END OF YOUR CODE #
################################################################################
current training learning_rate: 1.8
current training reg: 0.01
iteration 0 / 800: loss 2.302590
iteration 100 / 800: loss 1.455167
iteration 200 / 800: loss 1.427213
iteration 300 / 800: loss 1.430055
iteration 400 / 800: loss 1.407665
iteration 500 / 800: loss 1.455174
iteration 600 / 800: loss 1.361302
iteration 700 / 800: loss 1.352902
current val_acc: 0.577
best_acc: 0.577
best learning_rate: 1.8
best reg: 0.01
current training learning_rate: 1.8
current training reg: 0.011
iteration 0 / 800: loss 2.302591
iteration 100 / 800: loss 1.544071
iteration 200 / 800: loss 1.471075
iteration 300 / 800: loss 1.429699
iteration 400 / 800: loss 1.425746
iteration 500 / 800: loss 1.413695
iteration 600 / 800: loss 1.404900
iteration 700 / 800: loss 1.394854
current val_acc: 0.561
current training learning_rate: 1.7
current training reg: 0.01
iteration 0 / 800: loss 2.302590
iteration 100 / 800: loss 1.488707
iteration 200 / 800: loss 1.454584
iteration 300 / 800: loss 1.368391
iteration 400 / 800: loss 1.359419
iteration 500 / 800: loss 1.375673
iteration 600 / 800: loss 1.400355
iteration 700 / 800: loss 1.355049
current val_acc: 0.577
current training learning_rate: 1.7
current training reg: 0.011
iteration 0 / 800: loss 2.302591
iteration 100 / 800: loss 1.522634
iteration 200 / 800: loss 1.476987
iteration 300 / 800: loss 1.477775
iteration 400 / 800: loss 1.406658
iteration 500 / 800: loss 1.417113
iteration 600 / 800: loss 1.424151
iteration 700 / 800: loss 1.467979
current val_acc: 0.569
current training learning_rate: 1.6
current training reg: 0.01
iteration 0 / 800: loss 2.302590
iteration 100 / 800: loss 1.506576
iteration 200 / 800: loss 1.455776
iteration 300 / 800: loss 1.461364
iteration 400 / 800: loss 1.366618
iteration 500 / 800: loss 1.411004
iteration 600 / 800: loss 1.372812
iteration 700 / 800: loss 1.387114
current val_acc: 0.583
best_acc: 0.583
best learning_rate: 1.6
best reg: 0.01
current training learning_rate: 1.6
current training reg: 0.011
iteration 0 / 800: loss 2.302591
iteration 100 / 800: loss 1.466752
iteration 200 / 800: loss 1.460388
iteration 300 / 800: loss 1.391446
iteration 400 / 800: loss 1.370959
iteration 500 / 800: loss 1.410860
iteration 600 / 800: loss 1.414151
iteration 700 / 800: loss 1.416123
current val_acc: 0.581
current training learning_rate: 1.5
current training reg: 0.01
iteration 0 / 800: loss 2.302590
iteration 100 / 800: loss 1.488719
iteration 200 / 800: loss 1.442920
iteration 300 / 800: loss 1.421011
iteration 400 / 800: loss 1.421810
iteration 500 / 800: loss 1.408096
iteration 600 / 800: loss 1.351295
iteration 700 / 800: loss 1.362655
current val_acc: 0.586
best_acc: 0.586
best learning_rate: 1.5
best reg: 0.01
current training learning_rate: 1.5
current training reg: 0.011
iteration 0 / 800: loss 2.302591
iteration 100 / 800: loss 1.481648
iteration 200 / 800: loss 1.464853
iteration 300 / 800: loss 1.436531
iteration 400 / 800: loss 1.423766
iteration 500 / 800: loss 1.394977
iteration 600 / 800: loss 1.397767
iteration 700 / 800: loss 1.444636
current val_acc: 0.571
#自己加的(insert by myself)
# Plot the loss function and train / validation accuracies
#根据上面的确定大致范围进行微调
test_net = TwoLayerNet(input_dim, hidden_dim, num_classes)
test_stats = test_net.train(X_train_feats, y_train, X_val_feats, y_val,
num_iters=800, batch_size=1500,
learning_rate=1.6, learning_rate_decay=0.95,
reg=0.01, verbose=True)
print "acc:", (test_net.predict(X_val_feats) == y_val).mean()
print "learning_rate:",test_net.hyper_params['learning_rate']
print "reg:",test_net.hyper_params['reg']
print
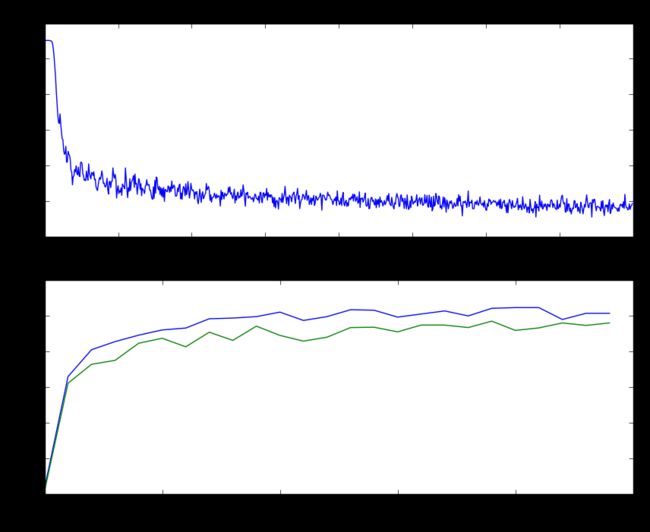
plt.subplot(2, 1, 1)
plt.plot(test_stats['loss_history'])
plt.title('Loss history')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.subplot(2, 1, 2)
plt.plot(test_stats['train_acc_history'], label='train')
plt.plot(test_stats['val_acc_history'], label='val')
plt.title('Classification accuracy history')
plt.xlabel('Epoch')
plt.ylabel('Clasification accuracy')
plt.show()
iteration 0 / 800: loss 2.302590
iteration 100 / 800: loss 1.488089
iteration 200 / 800: loss 1.470812
iteration 300 / 800: loss 1.441917
iteration 400 / 800: loss 1.404342
iteration 500 / 800: loss 1.411365
iteration 600 / 800: loss 1.352144
iteration 700 / 800: loss 1.384254
acc: 0.574
learning_rate: 1.6
reg: 0.01
# Run your neural net classifier on the test set. You should be able to
# get more than 55% accuracy.
test_acc = (best_net.predict(X_test_feats) == y_test).mean()
print test_acc
test_acc = (test_net.predict(X_test_feats) == y_test).mean()
print test_acc
0.563
0.553
Bonus: Design your own features!
You have seen that simple image features can improve classification performance. So far we have tried HOG and color histograms, but other types of features may be able to achieve even better classification performance.
For bonus points, design and implement a new type of feature and use it for image classification on CIFAR-10. Explain how your feature works and why you expect it to be useful for image classification. Implement it in this notebook, cross-validate any hyperparameters, and compare its performance to the HOG + Color histogram baseline.
Bonus: Do something extra!
Use the material and code we have presented in this assignment to do something interesting. Was there another question we should have asked? Did any cool ideas pop into your head as you were working on the assignment? This is your chance to show off!